Machine Learning : Deep Learning - ANN (Part 26)
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim MitulDeep Learning is the most exciting and powerful branch of Machine Learning.
Deep Learning models can be used for a variety of complex tasks:
Artificial Neural Networks for Regression and Classification
Convolutional Neural Networks for Computer Vision
Recurrent Neural Networks for Time Series Analysis
Self Organizing Maps for Feature Extraction
Deep Boltzmann Machines for Recommendation Systems
Auto Encoders for Recommendation Systems
Internet started on 80s but Deep learning has started to evolve now. Why?

because the memory we can use has increased now.
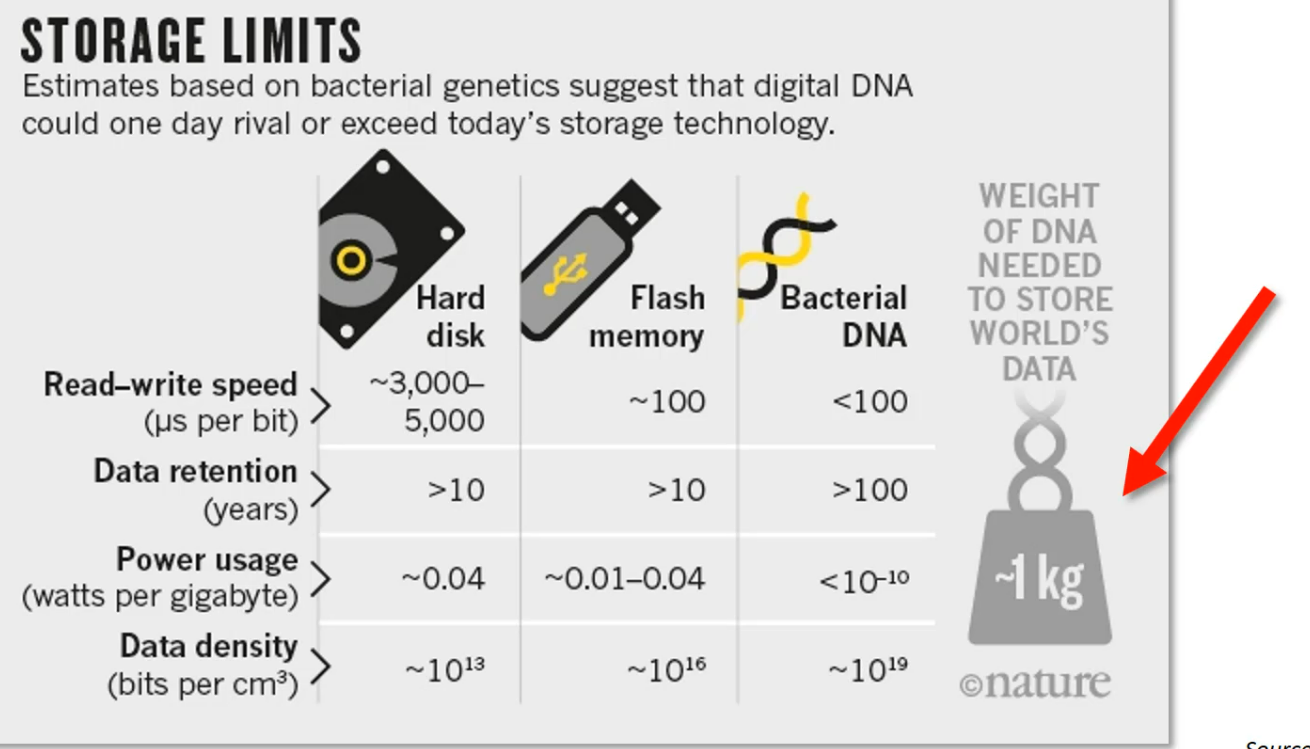
In the near future you can store all of the world's data in DNA storages
Artificial Neural Networks- ANN
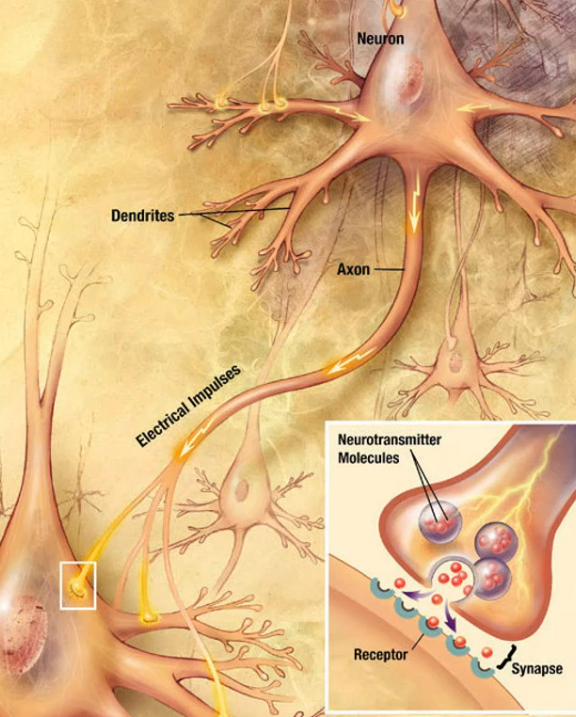
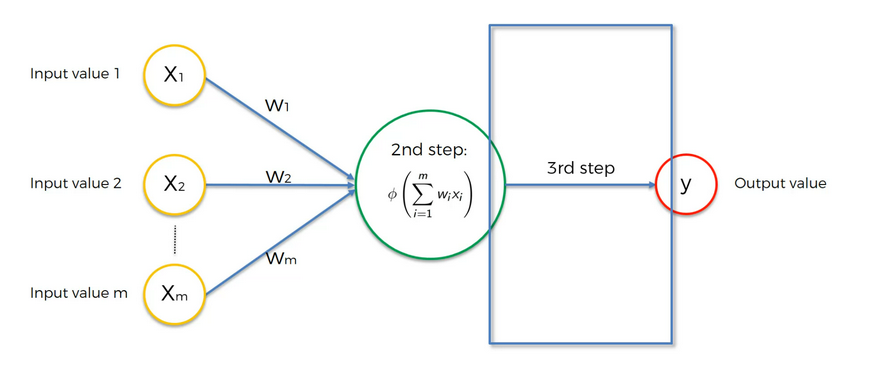
The Neuron
Deep learning uses Neural Networks which mimics the Human neuron
our goal is to create something close to human neurons.
Image of two neurons (drawn earlier)
again this is how we define neurons
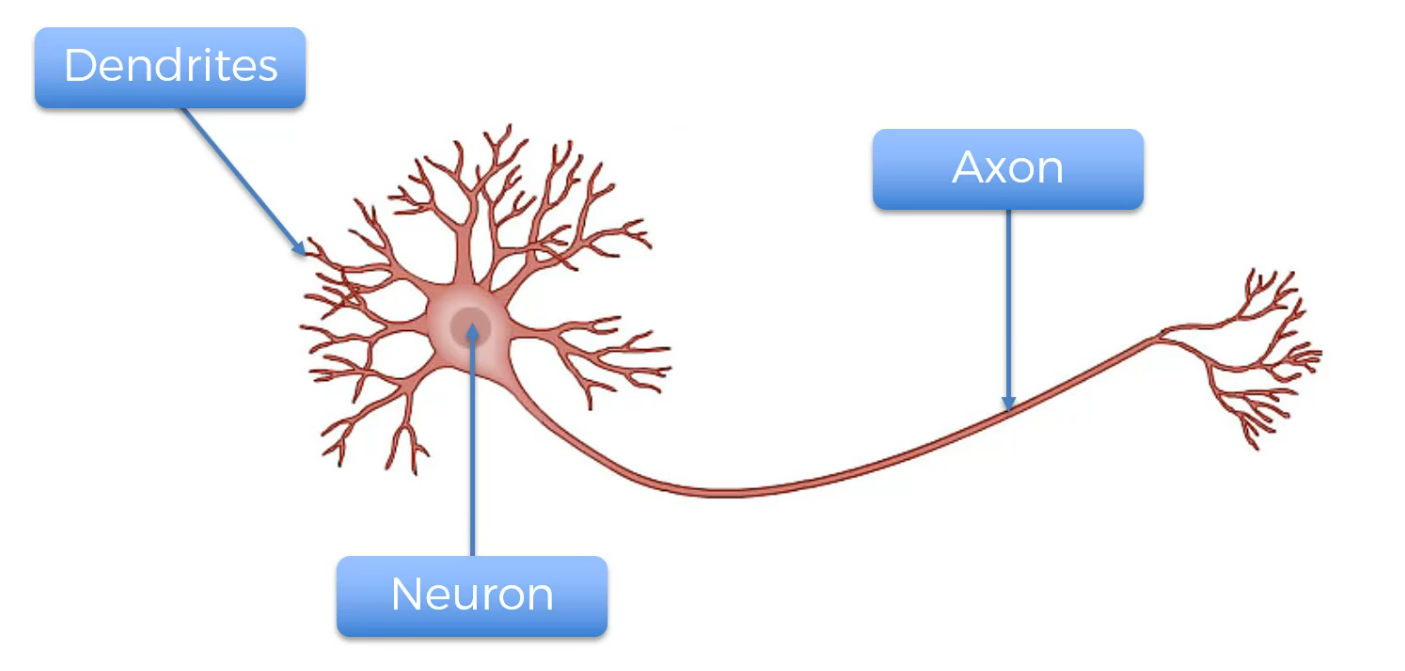
Dendrites receive info and Axon passes info.
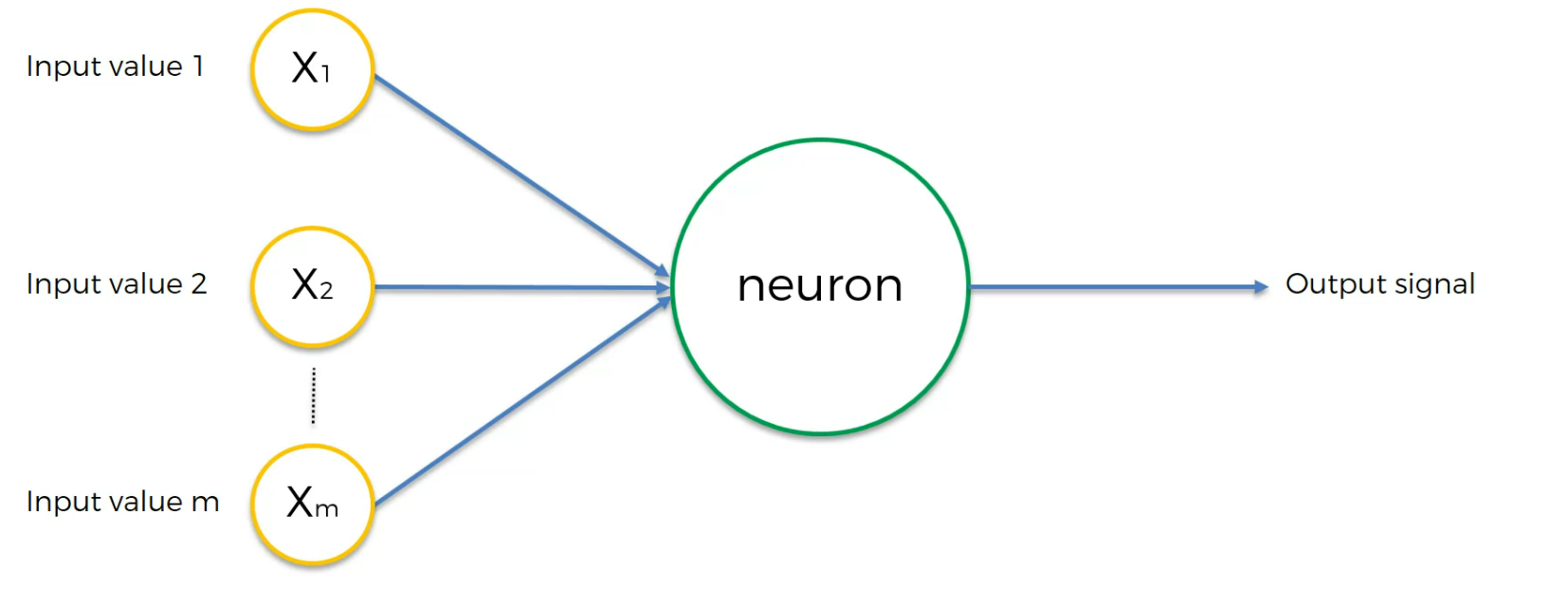
this can be seen as
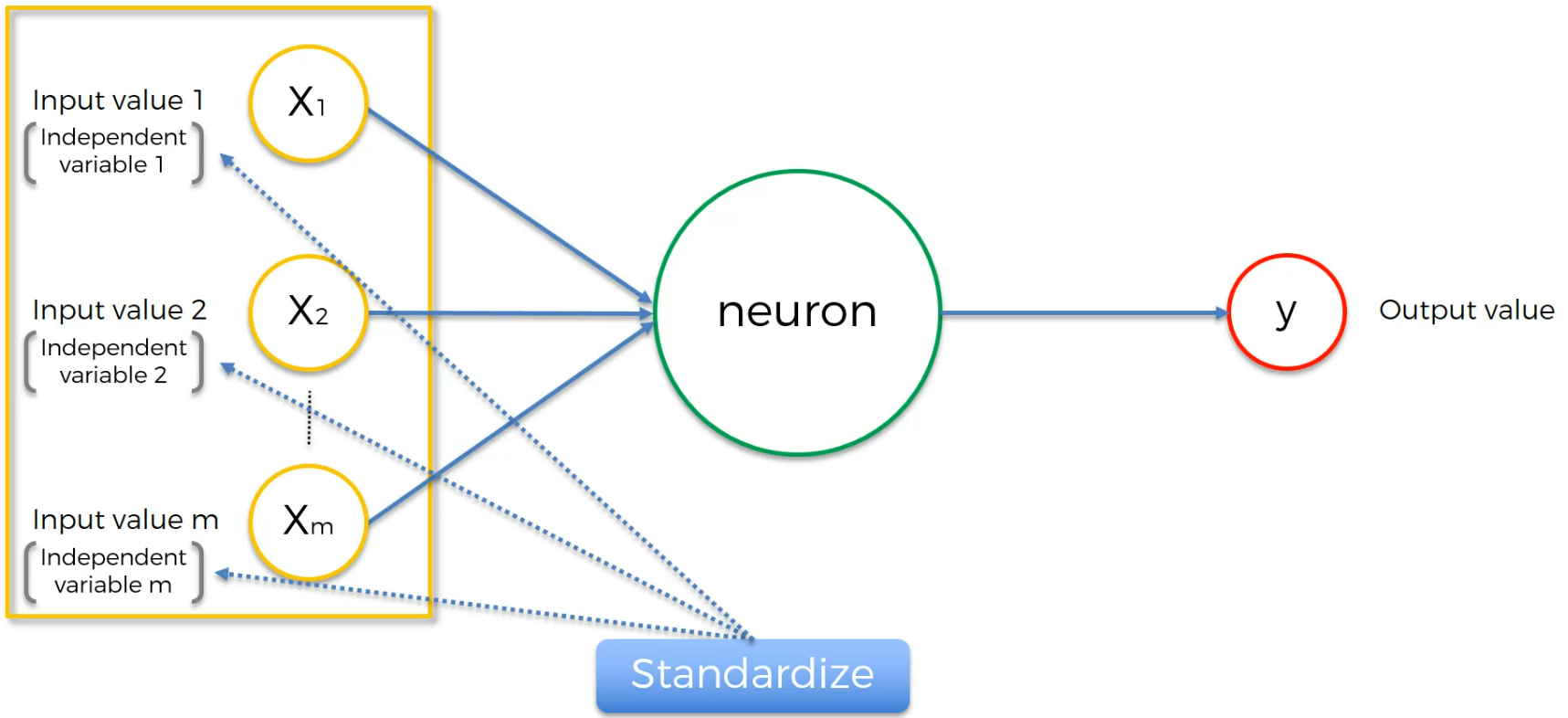
we have to standardize (Standardizing and normalizing is not same.Read this out) the input values.
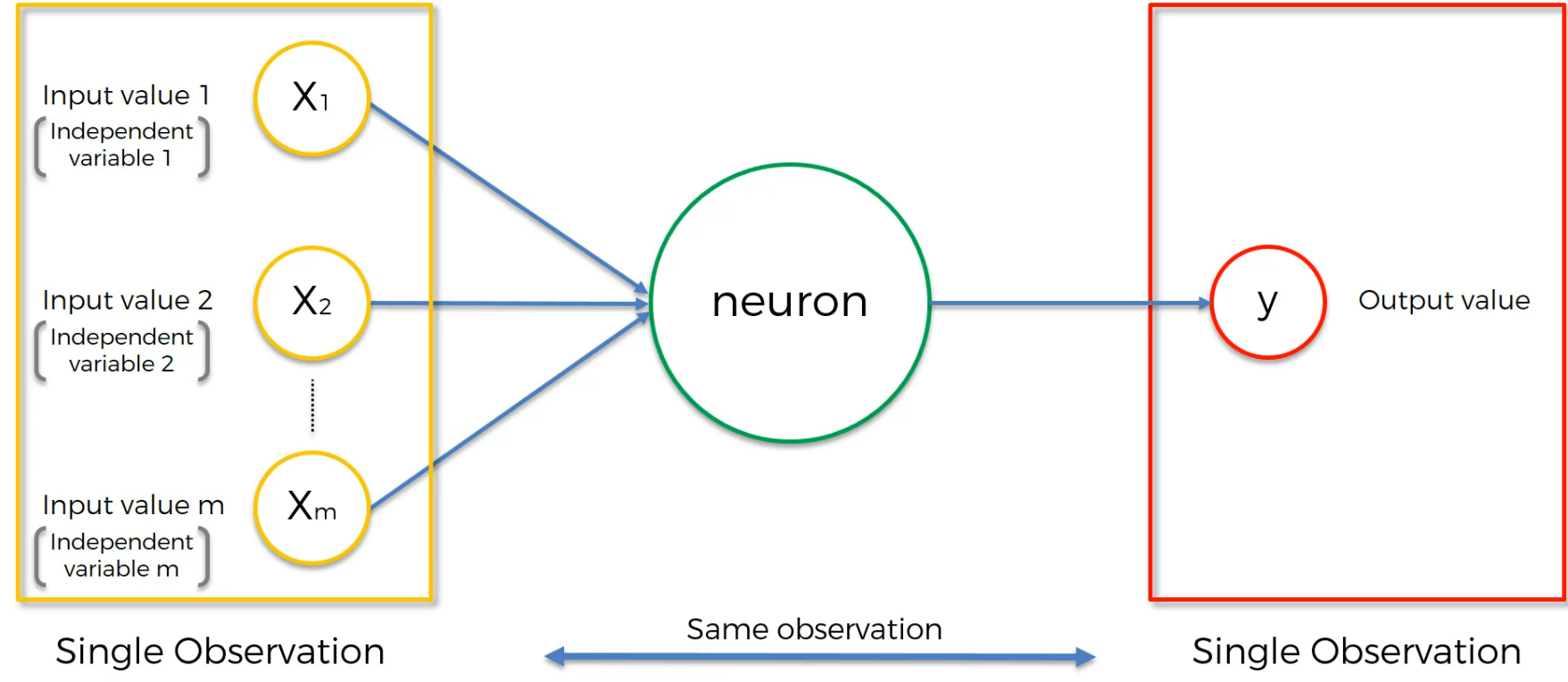
1 layer of input and 1 layer of output.
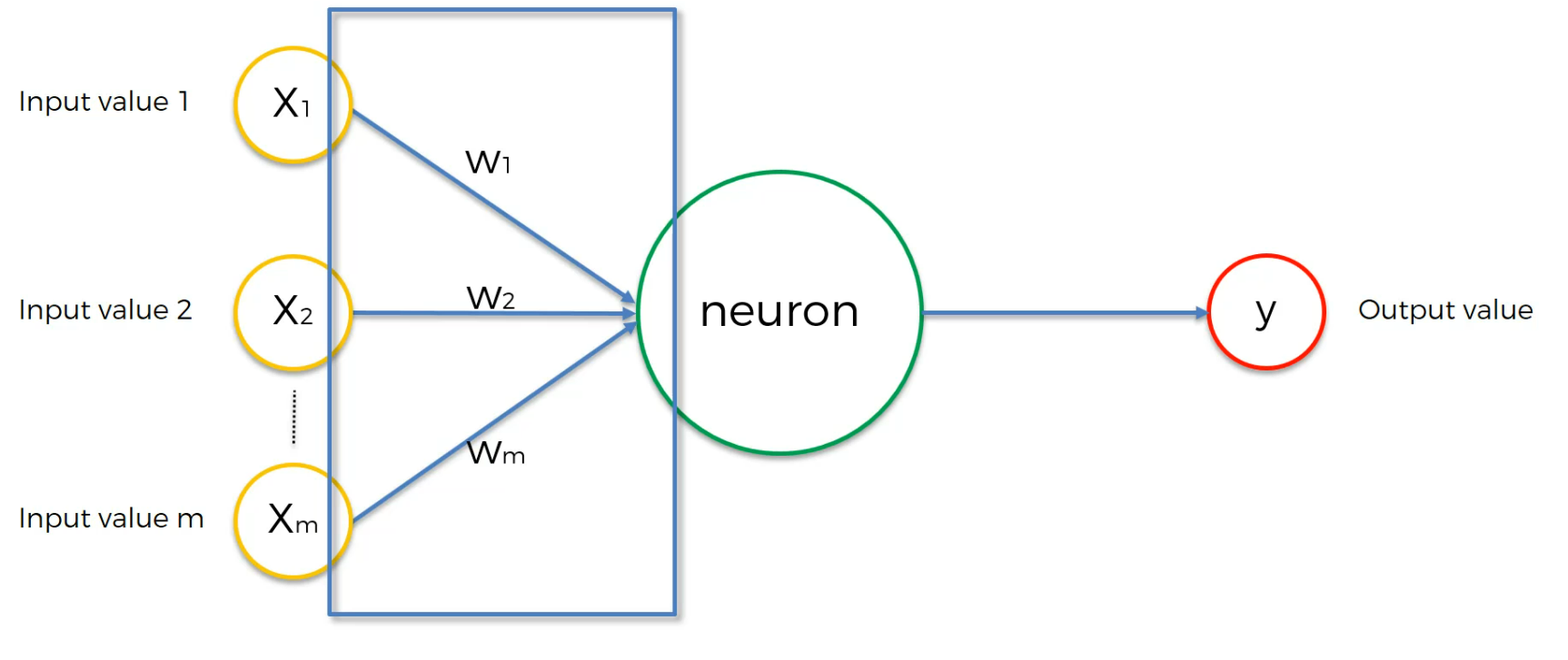
The inputs passes weights and that's how we basically modify the model.
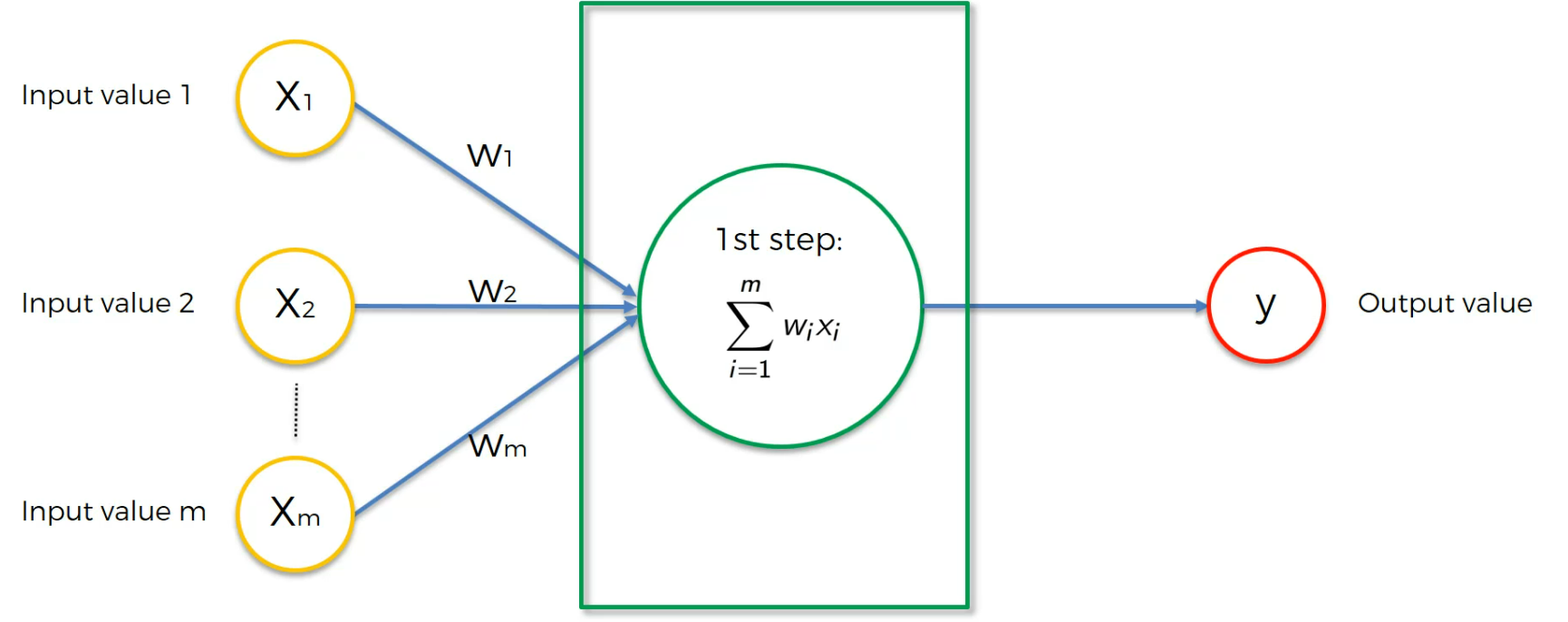
in the neuron, all the weights adds up (Weighted sum)
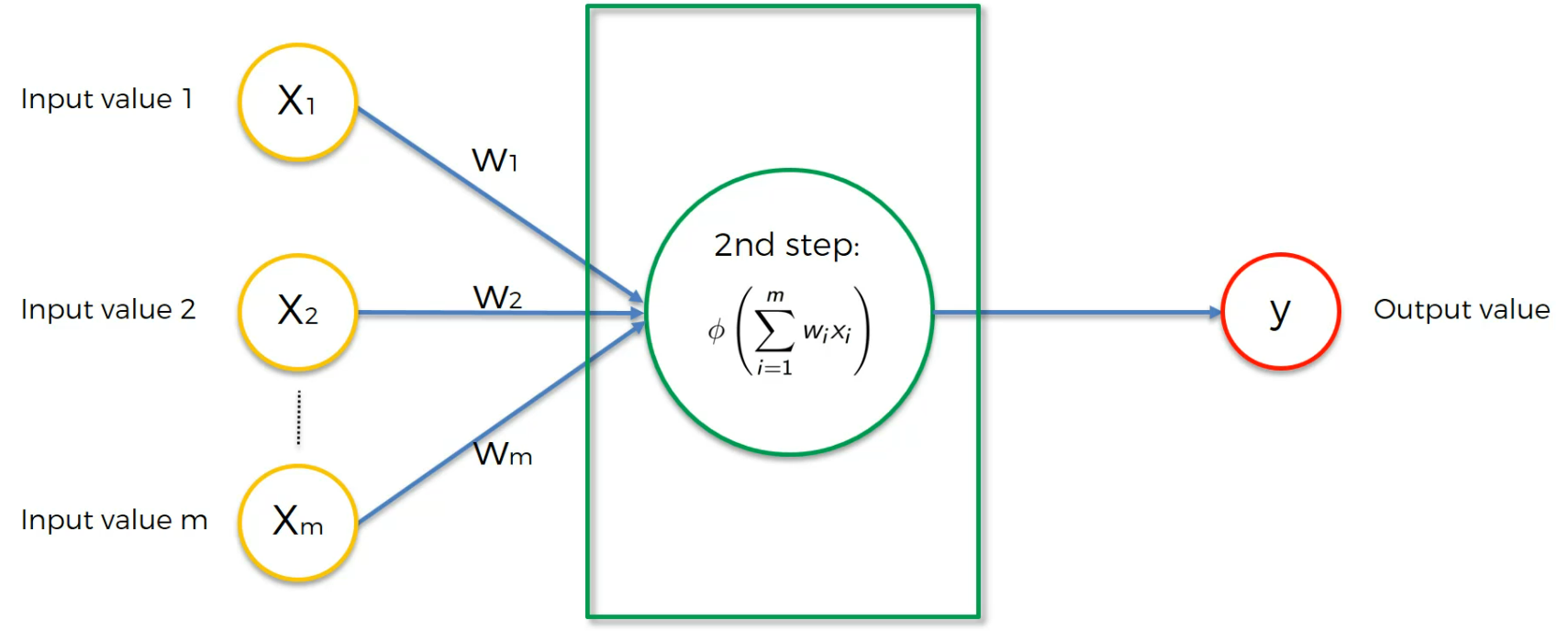
Then we run an activation function.
Then we pass it to the output layer
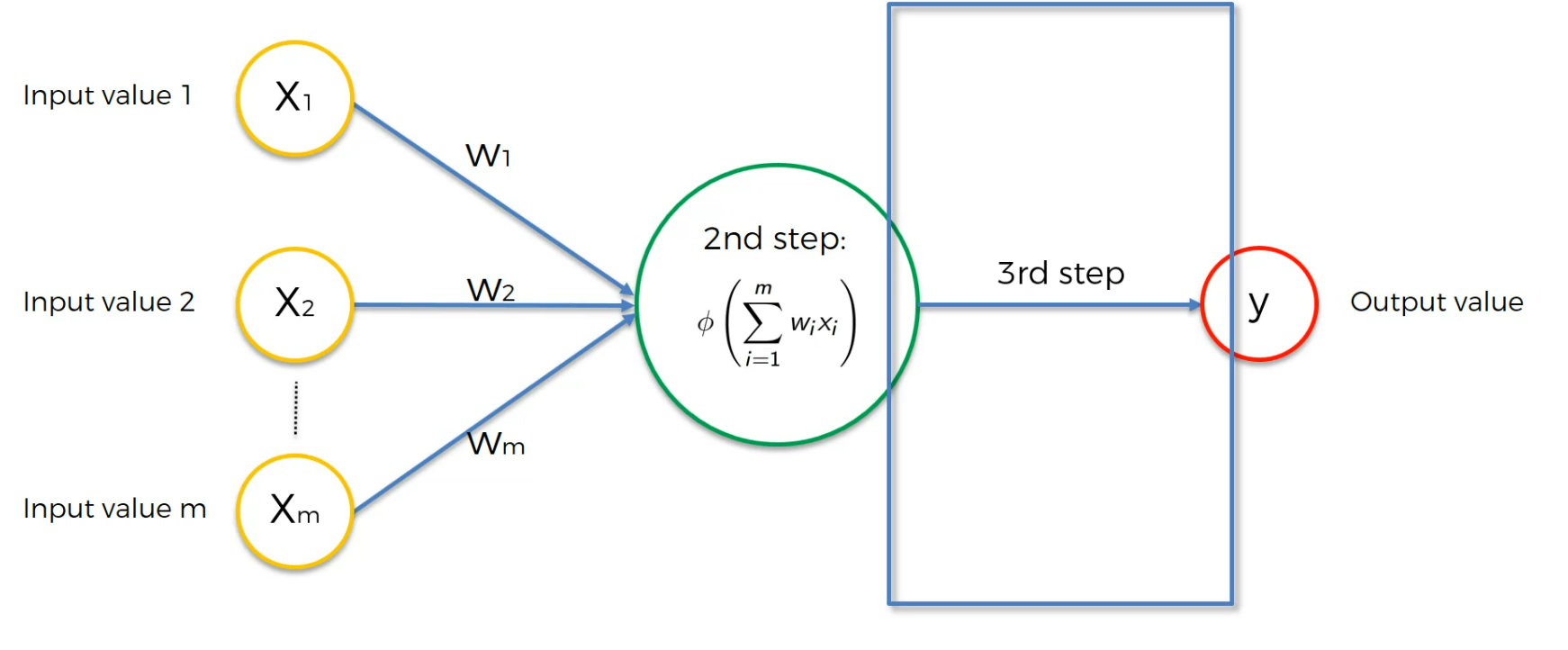
Activation function
Let's analyze 4 popular activation function
Threshold function
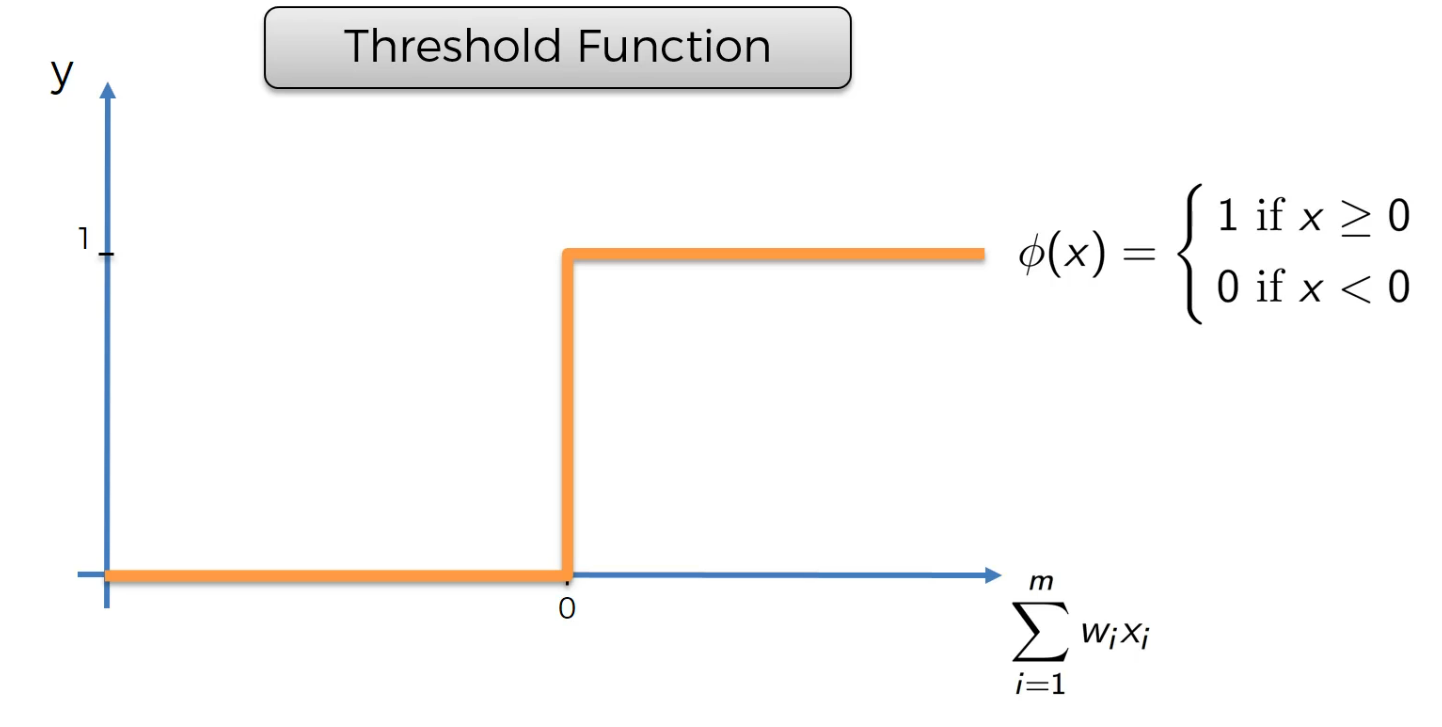
depending on the value of x, we get 1 or 0
Sigmoid
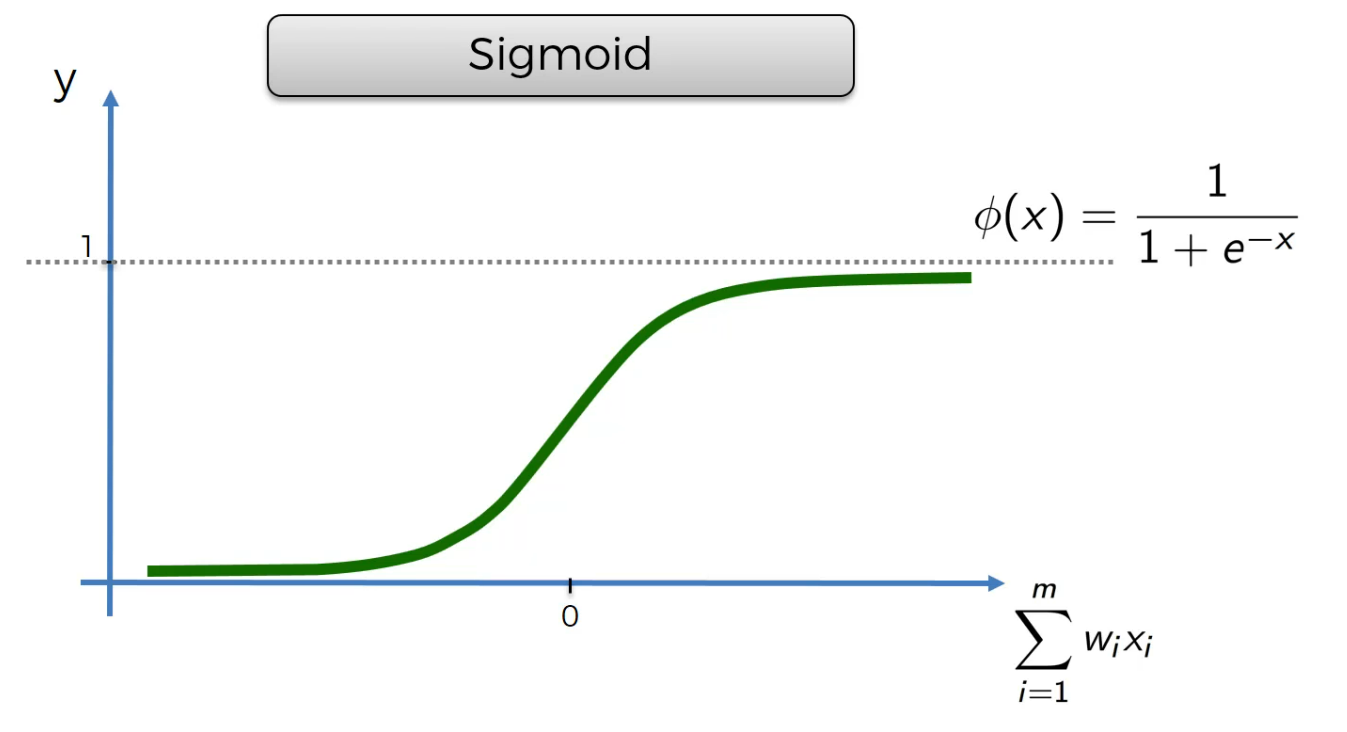
This is very famous one used in final layer.
Rectifer
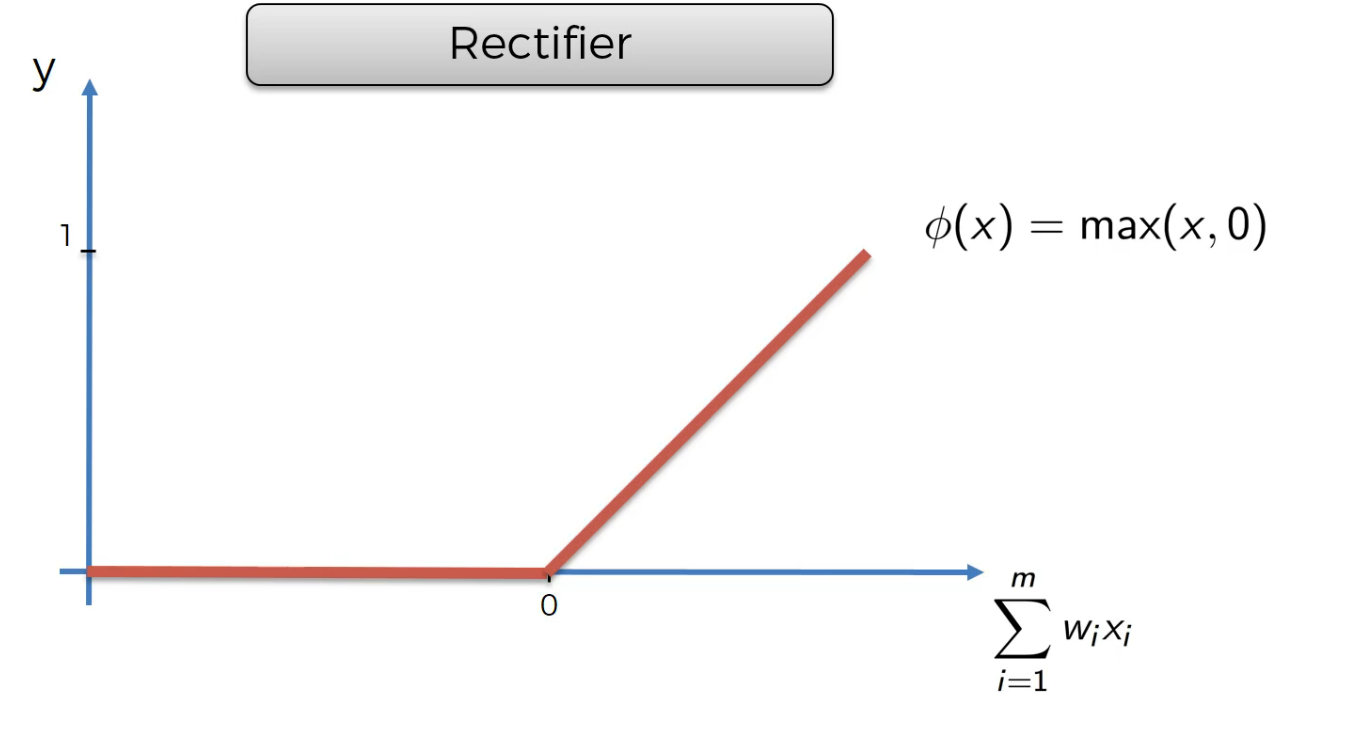
this is very famous in ANN.
Hiperbolic Tangent
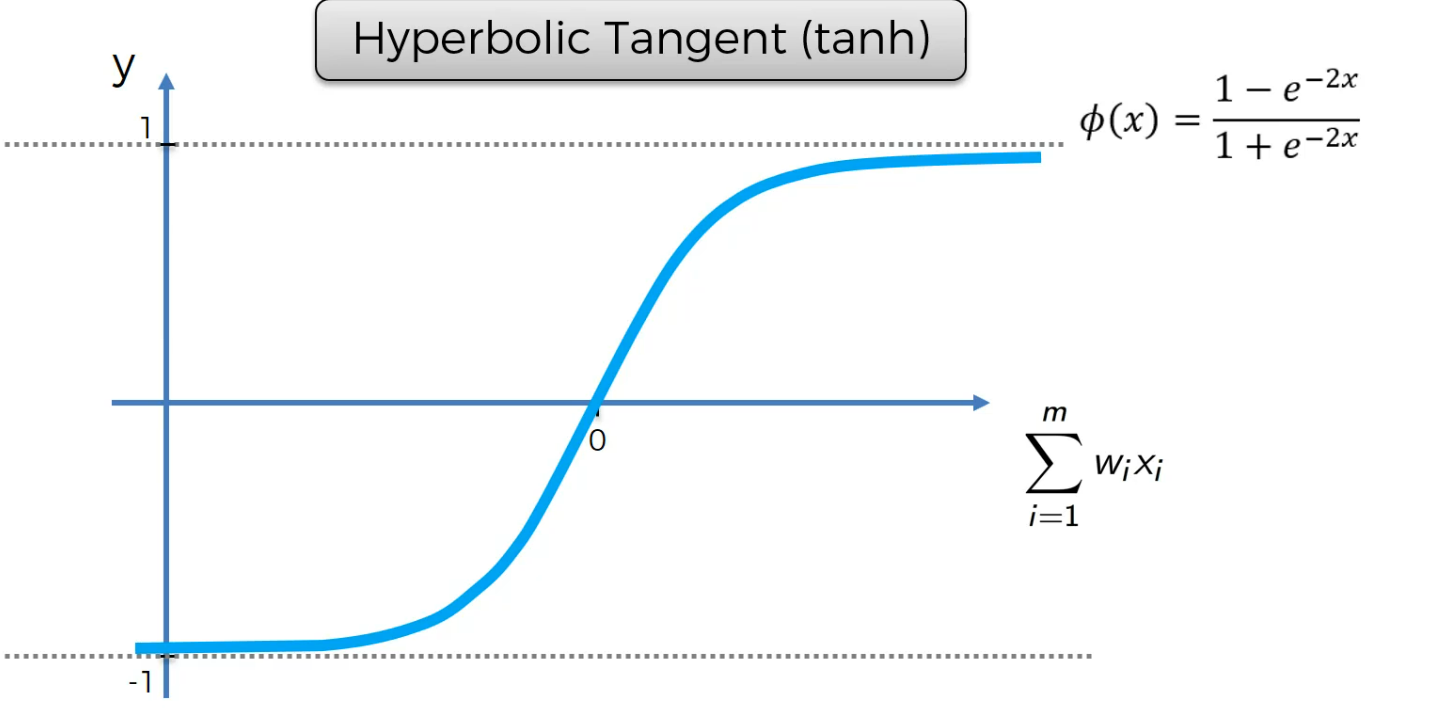
The activation function decides whether a neuron should be activated or not by calculating the weighted sum and further adding bias to it. The purpose of the activation function is to introduce non-linearity into the output of a neuron
This is how it works. In the hidden layer (for example), rectifier activation function is used and in output layer, sigmoid activation function is used.
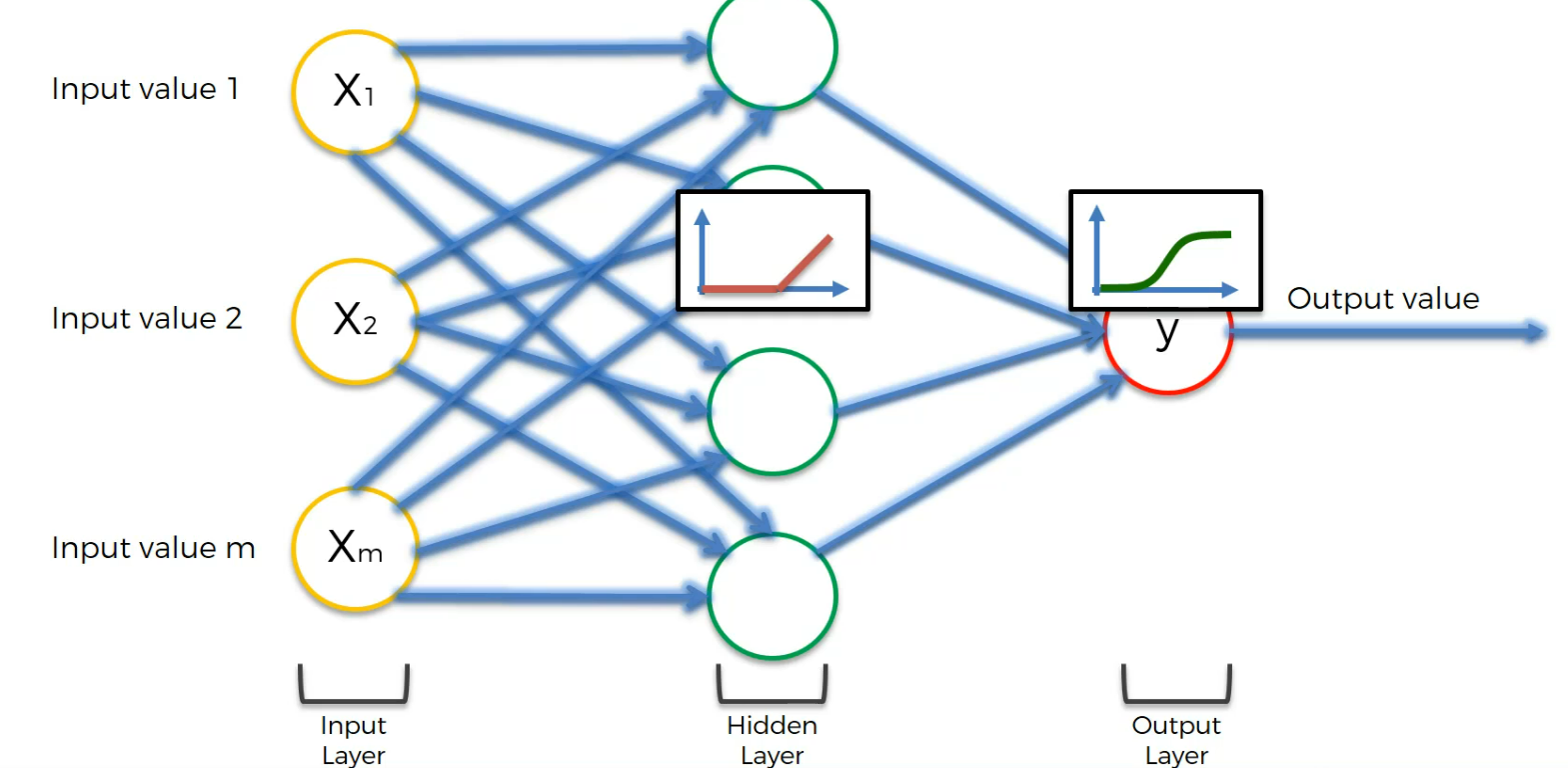
How do Neural Network work?
Let's assume that we are going to valuate the value of a property

Assume we have Area, Bedrooms , Distance to city and Age are our input values
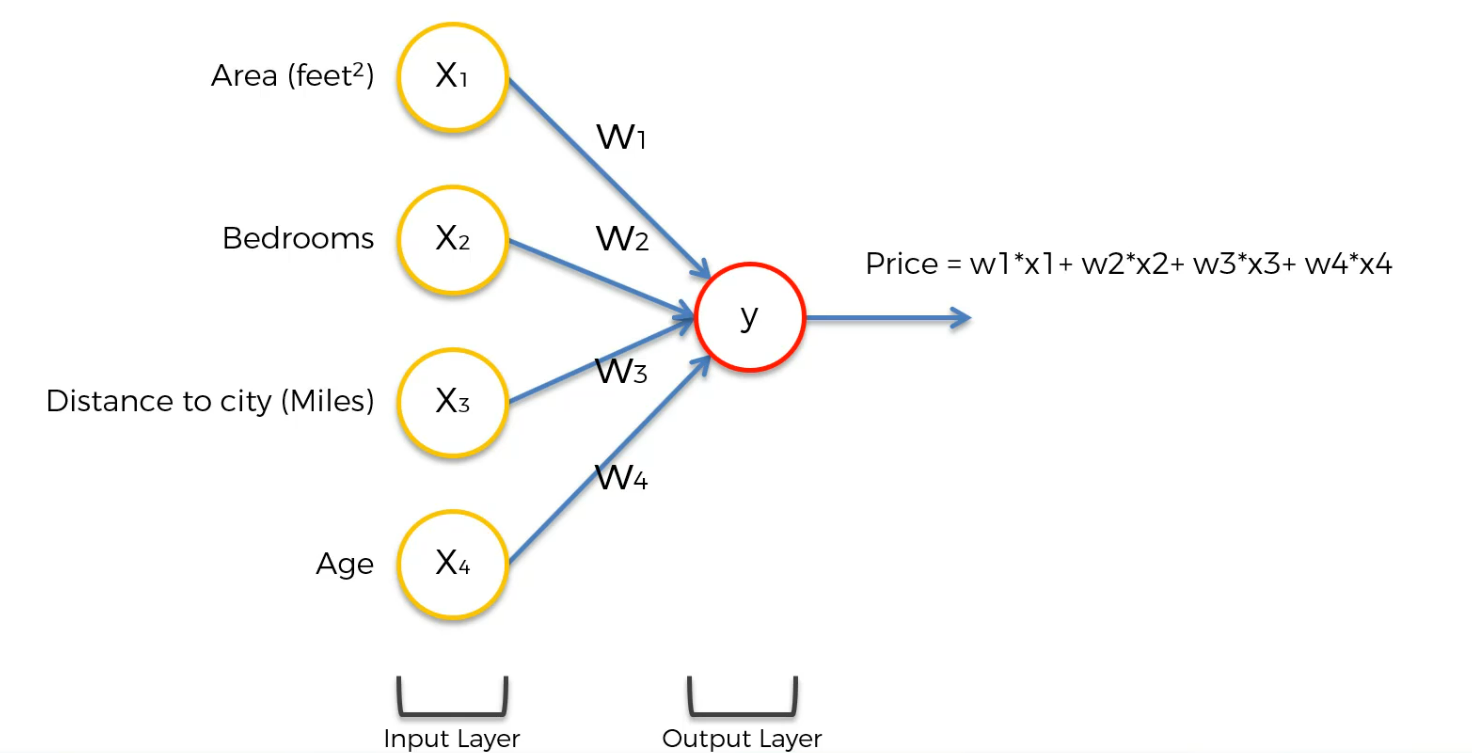
So, this can be the solution. You can basically use most of the ML Models here.
But in Neural network, we have hidden layer which is something special.
Let's see how to use that.
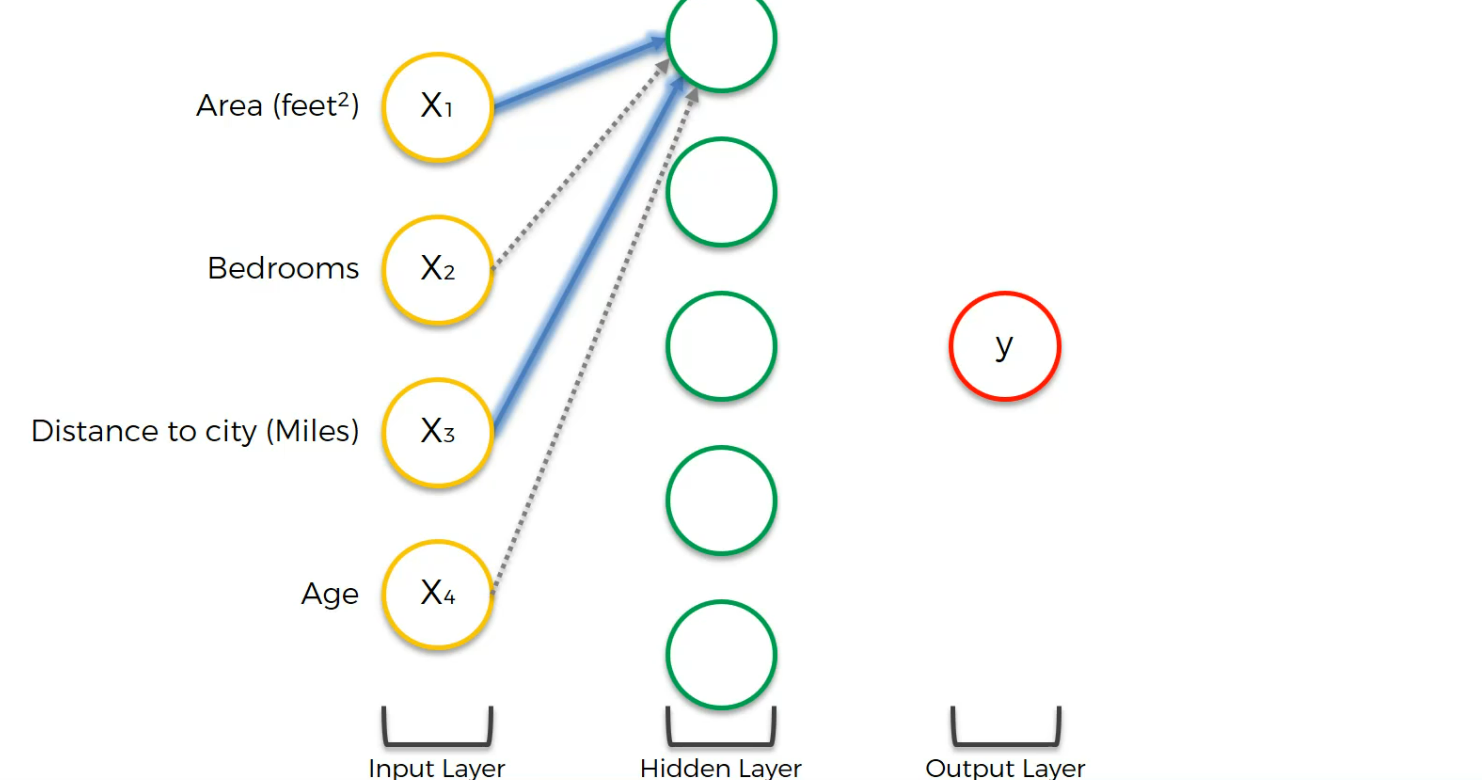
Assume that these values are linked to the first neuron of hidden layer. Also, assume some weights of input are non-zero and some have zero.
Now, we can design that neuron in such a manner that it will activate only when a certain level of input is met.
Assume that, we have made this neuron focused on Area and Distance to city only
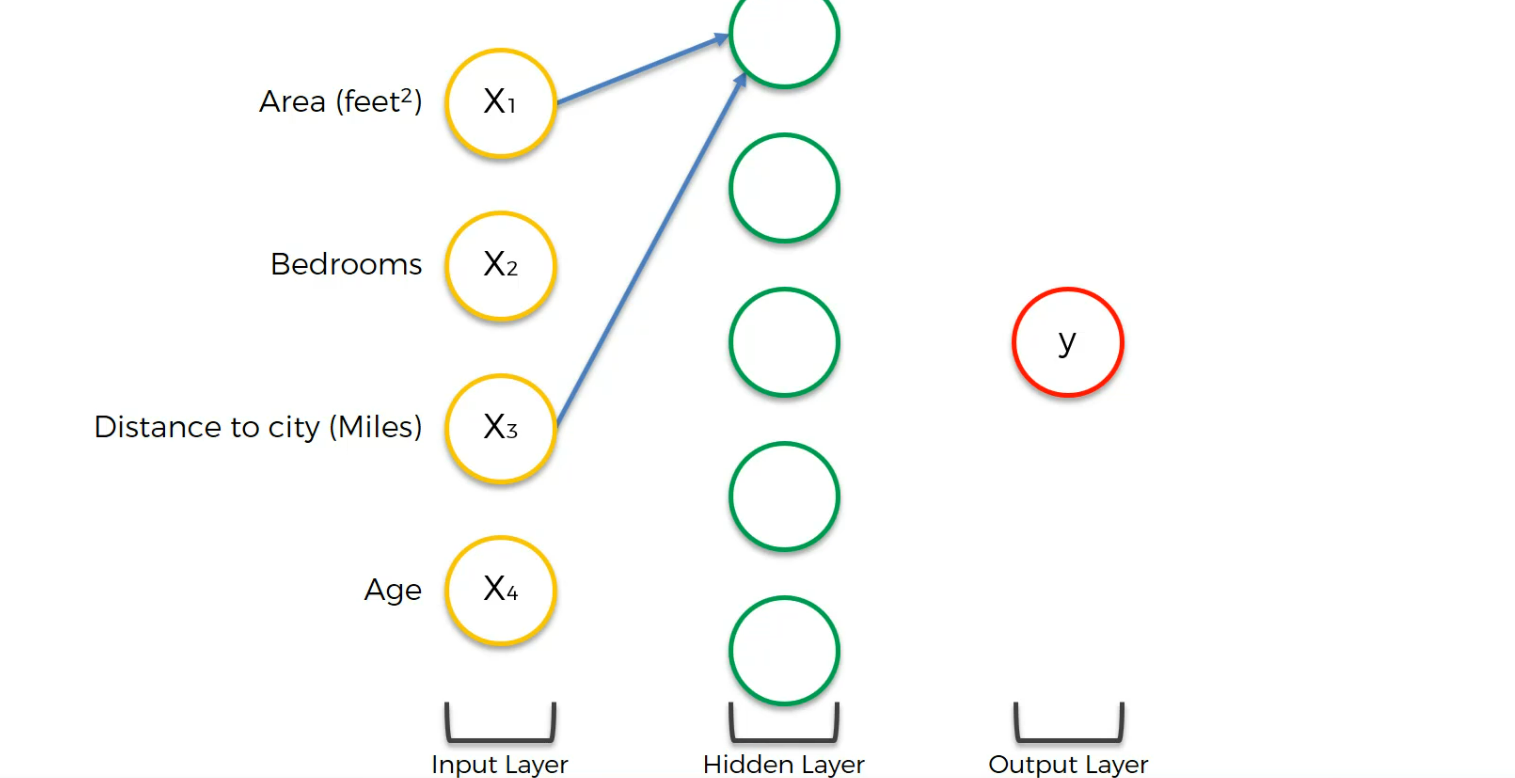
Now, we did set the middle neuron to focus on Area, bedroom and age
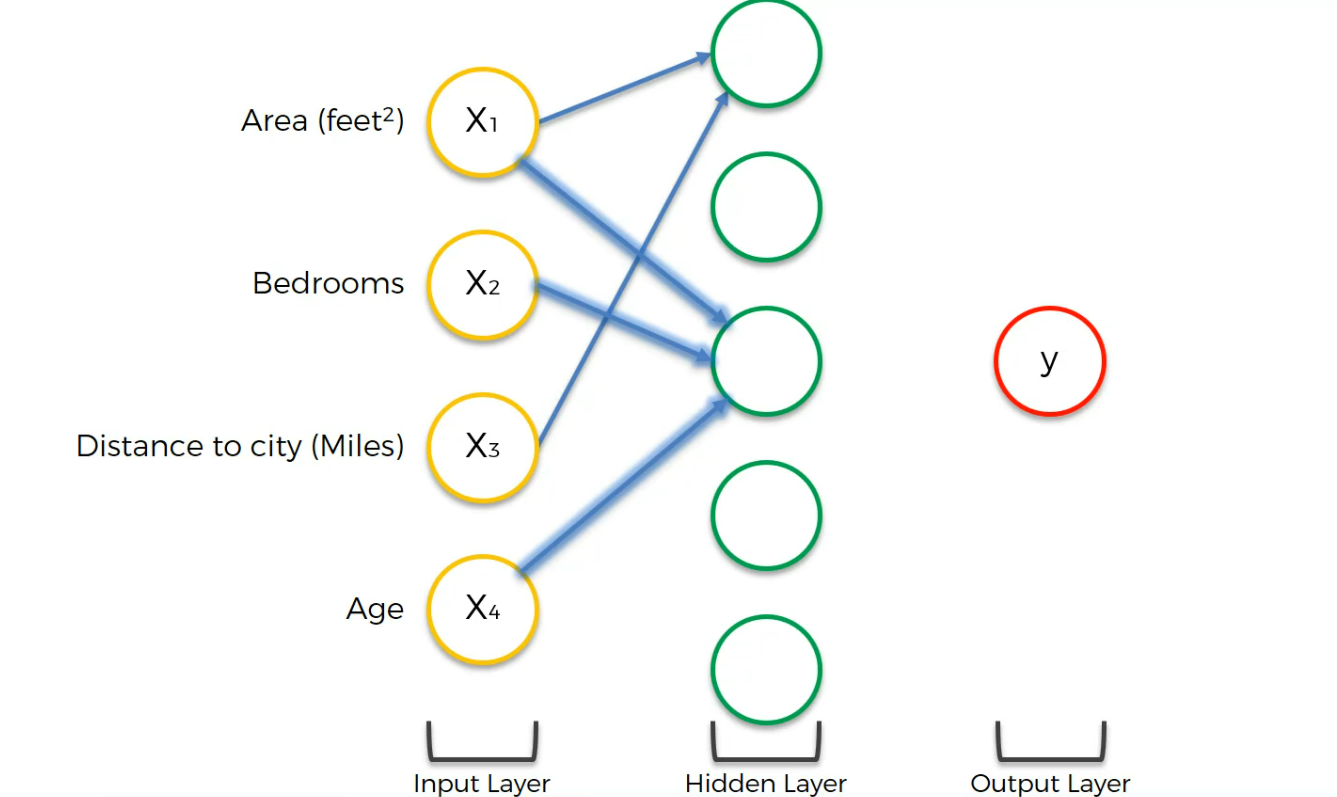
the last one connected to Age
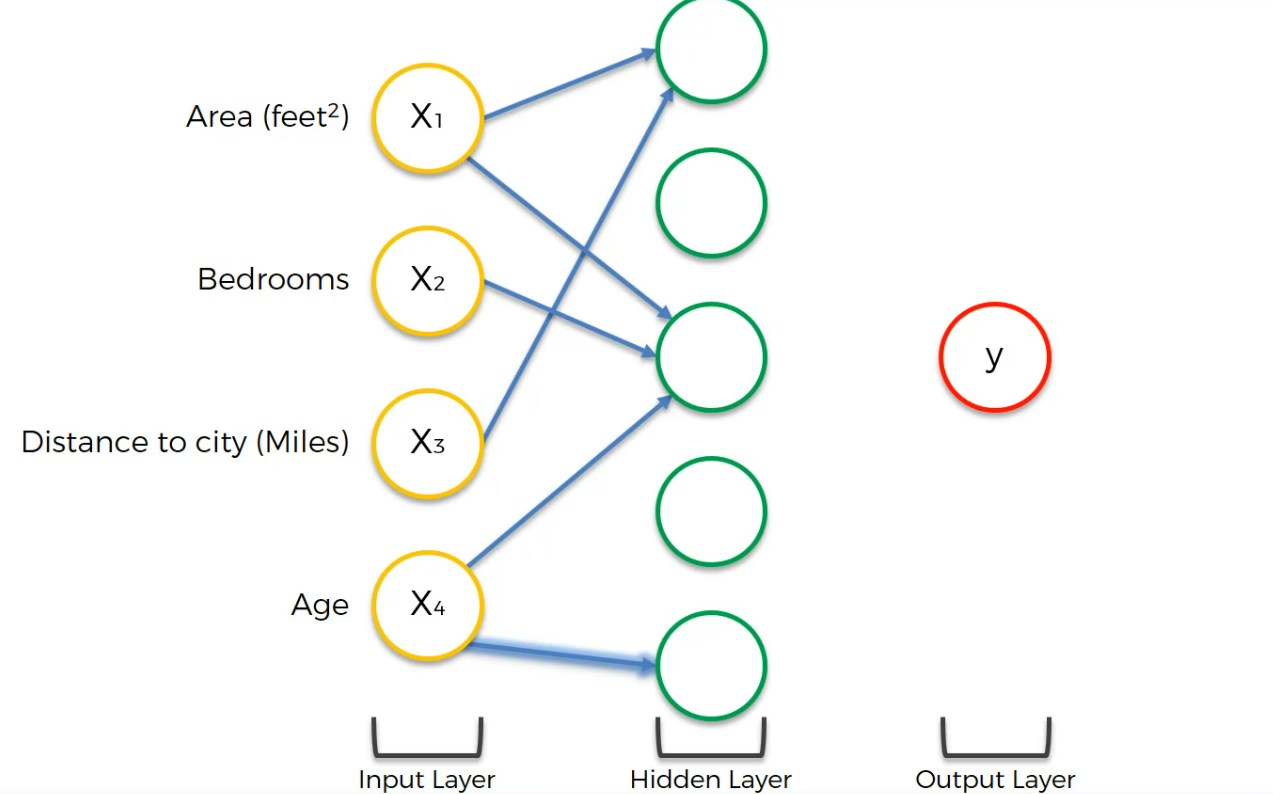
The second one with Bedroom and Distance to city
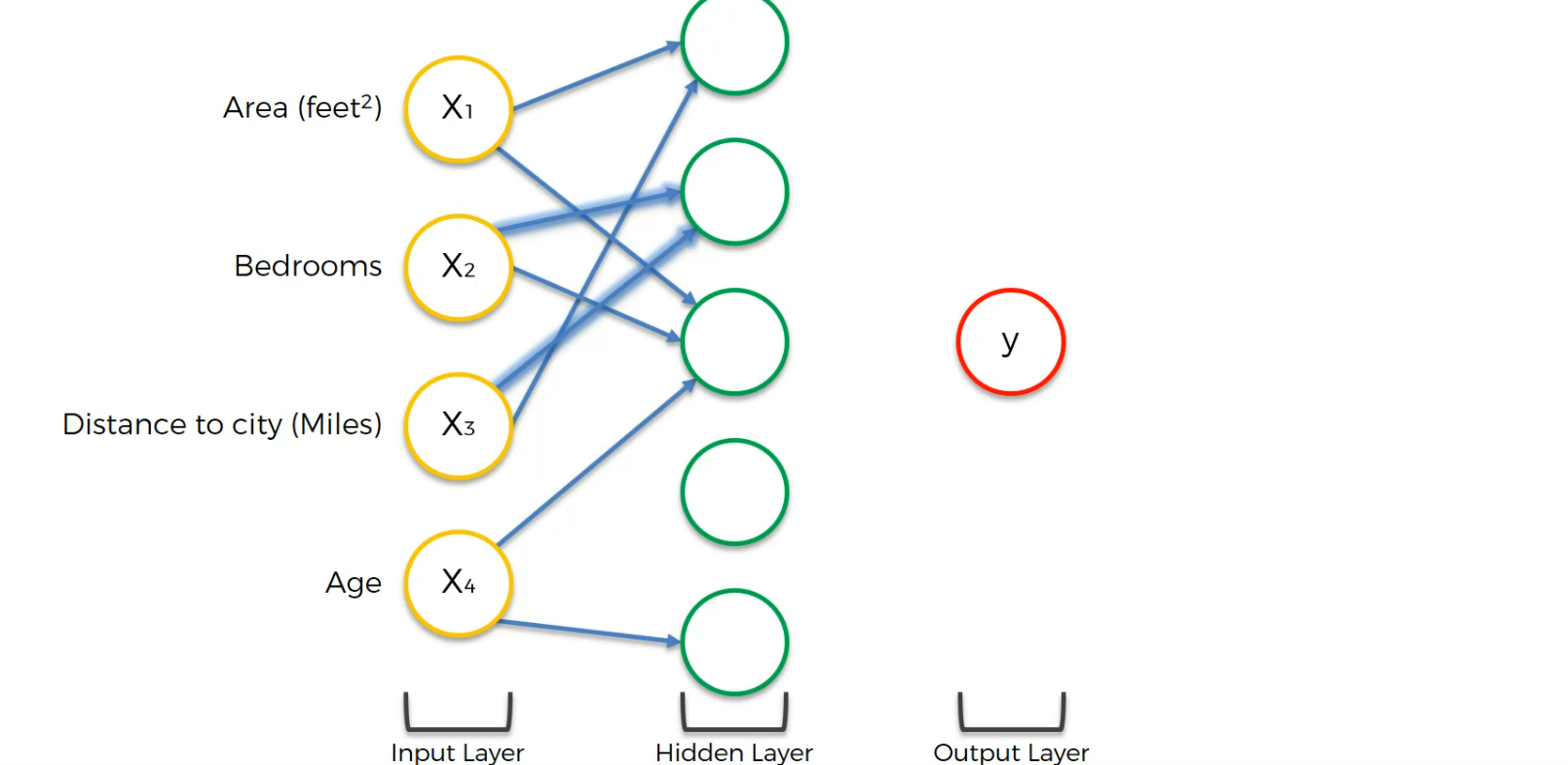
The fourth one with all of the input neurons
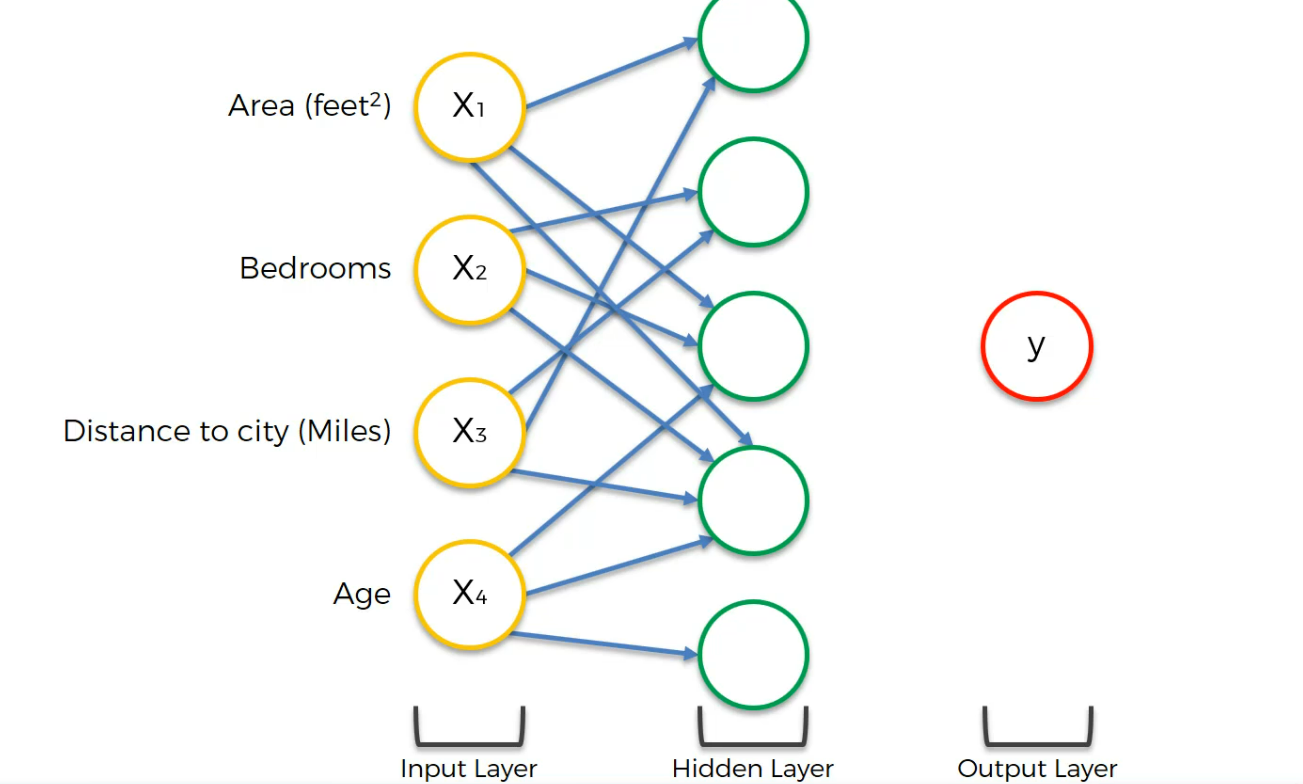
Finally the output layer is connected to all hidden layer neurons
How to Neural Networks Learn?
In general two ways to learn. One is to hard code and give all of the rules and second one is to design the neural network so that it can learn itself.
what happens in NN is
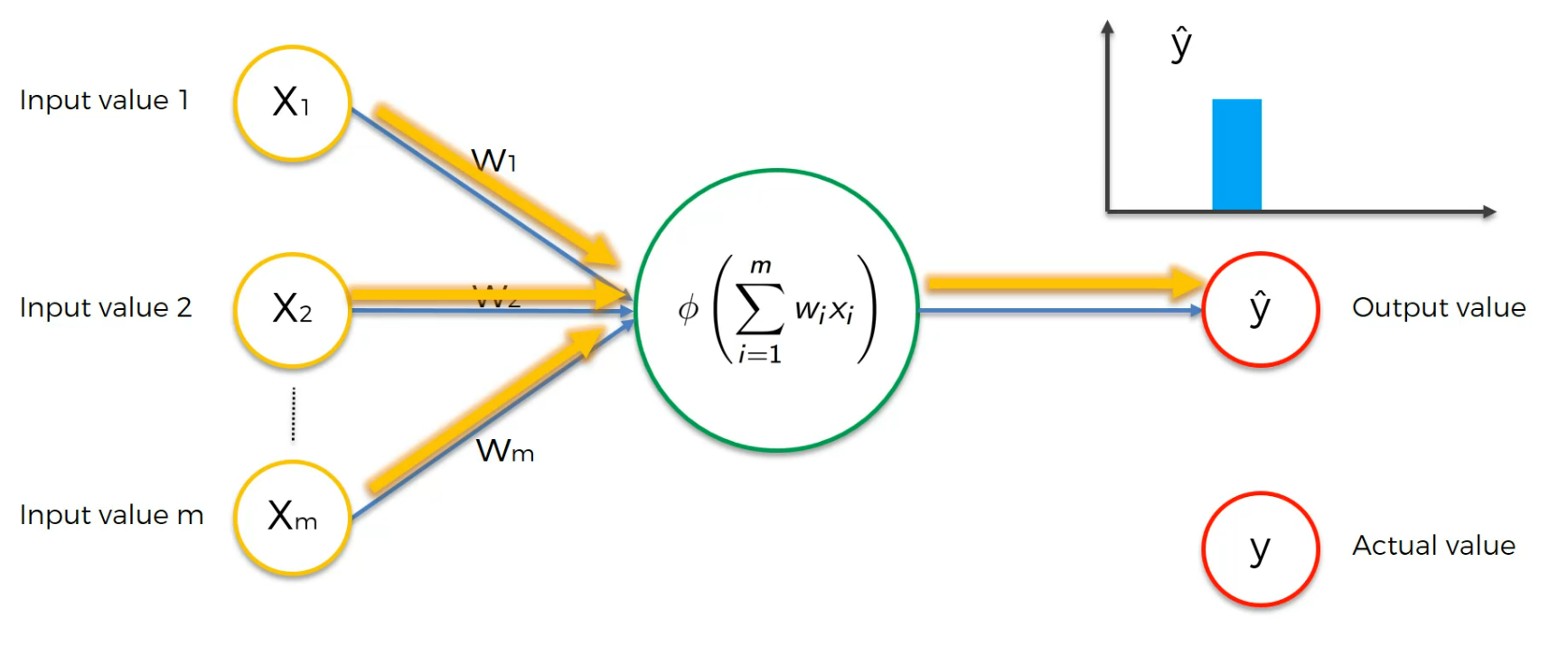
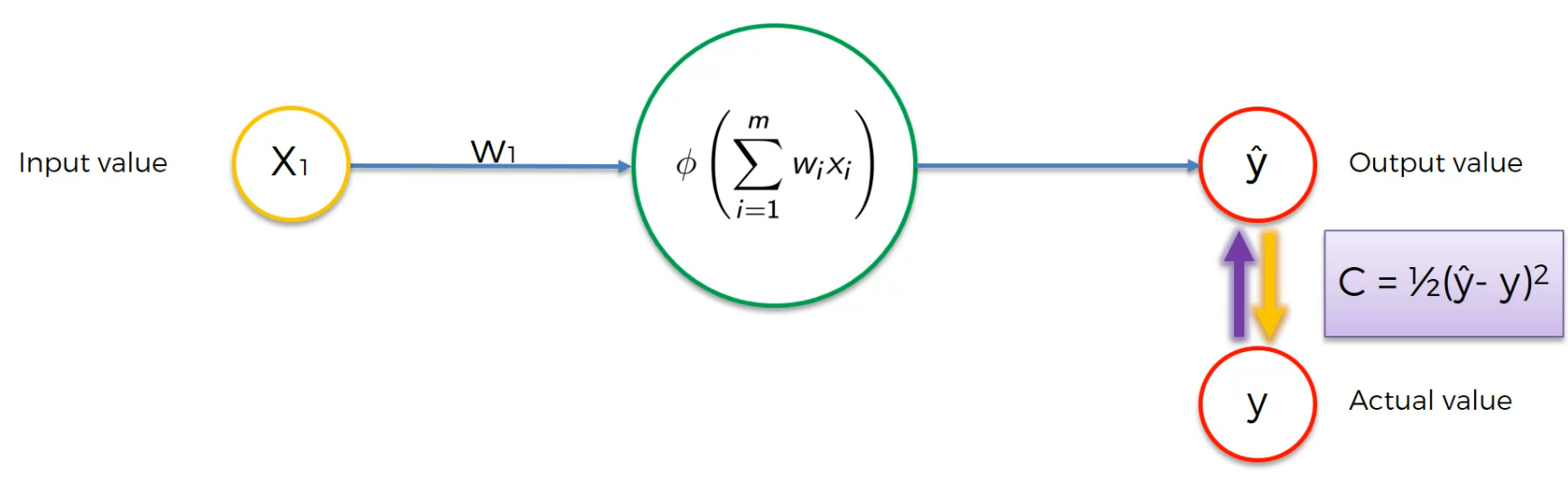
We get an output value and we have actual value
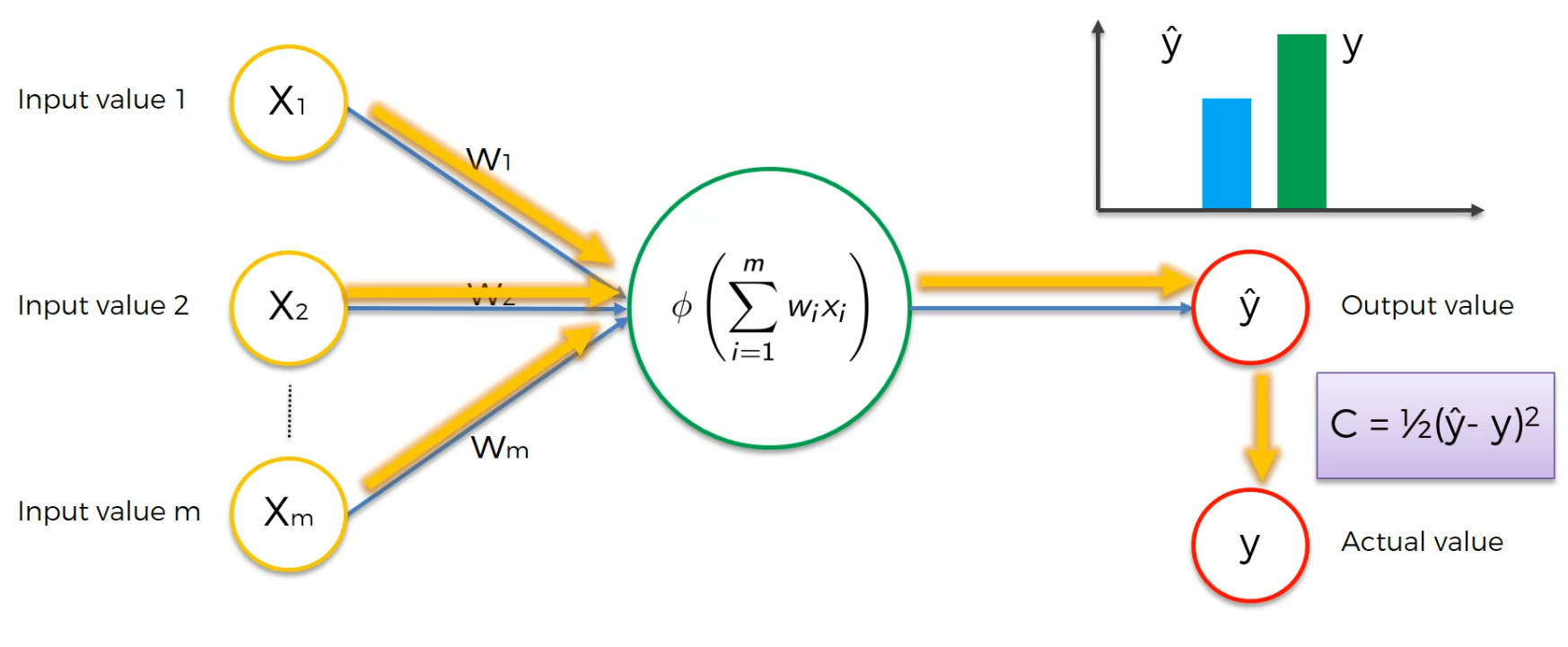
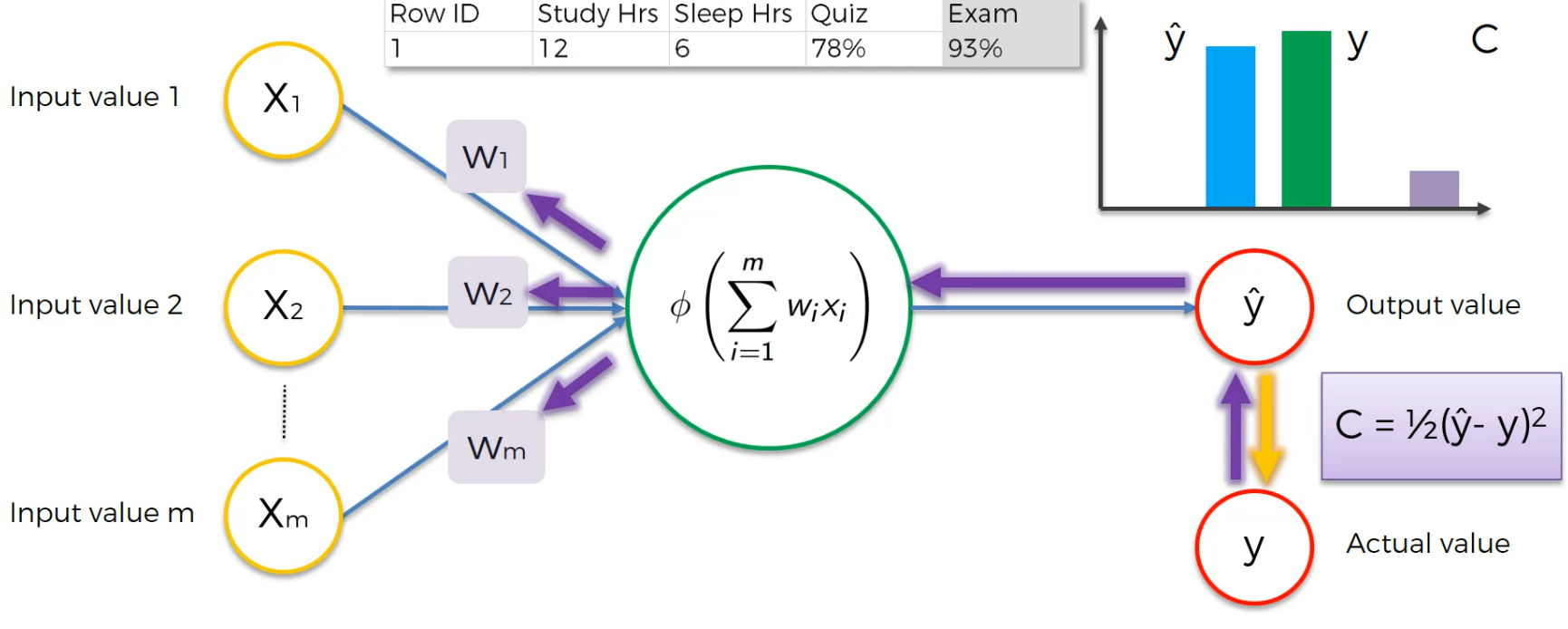
Here using this Cost function , C,we find the error.
Now, this cost function(C) is passed to the output value and then it goes to the hidden layer and then to the input layer's weight.
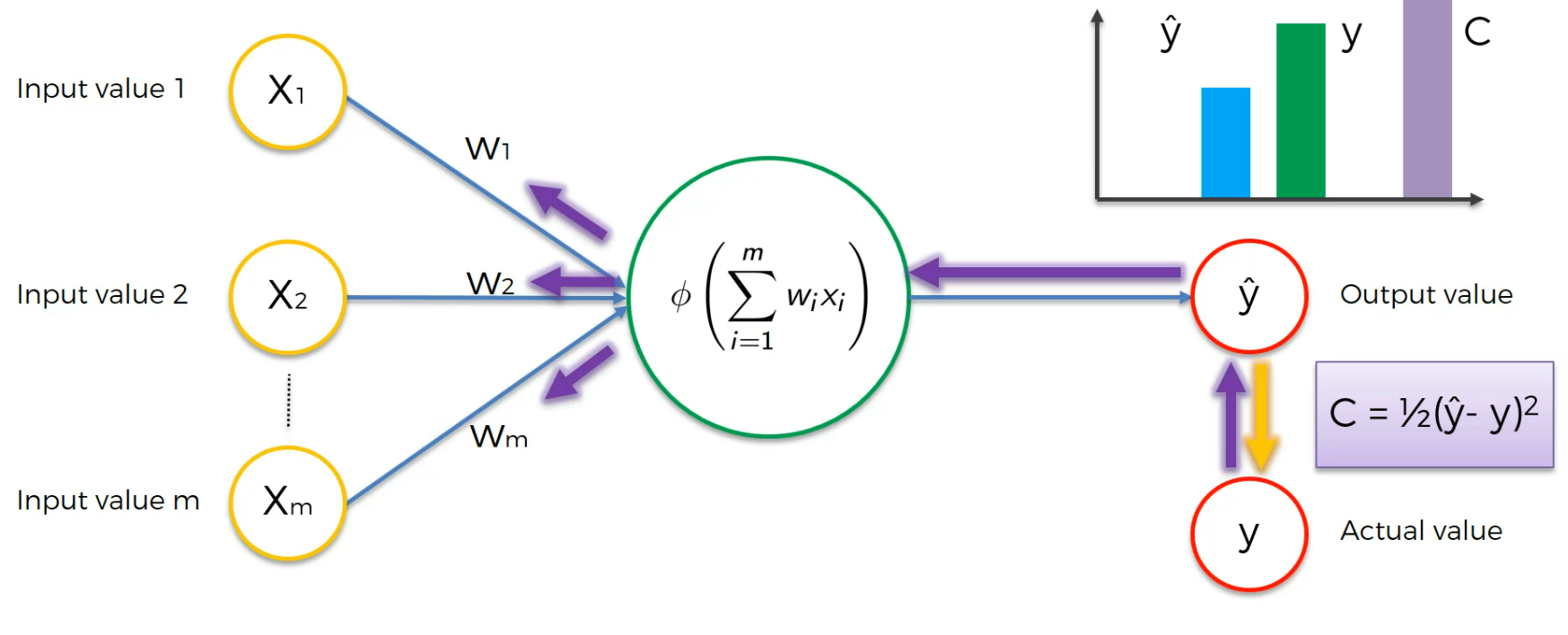
The weights get updated
Our goal is to minimize the cost function and thus we modify the weight (Not the input value).
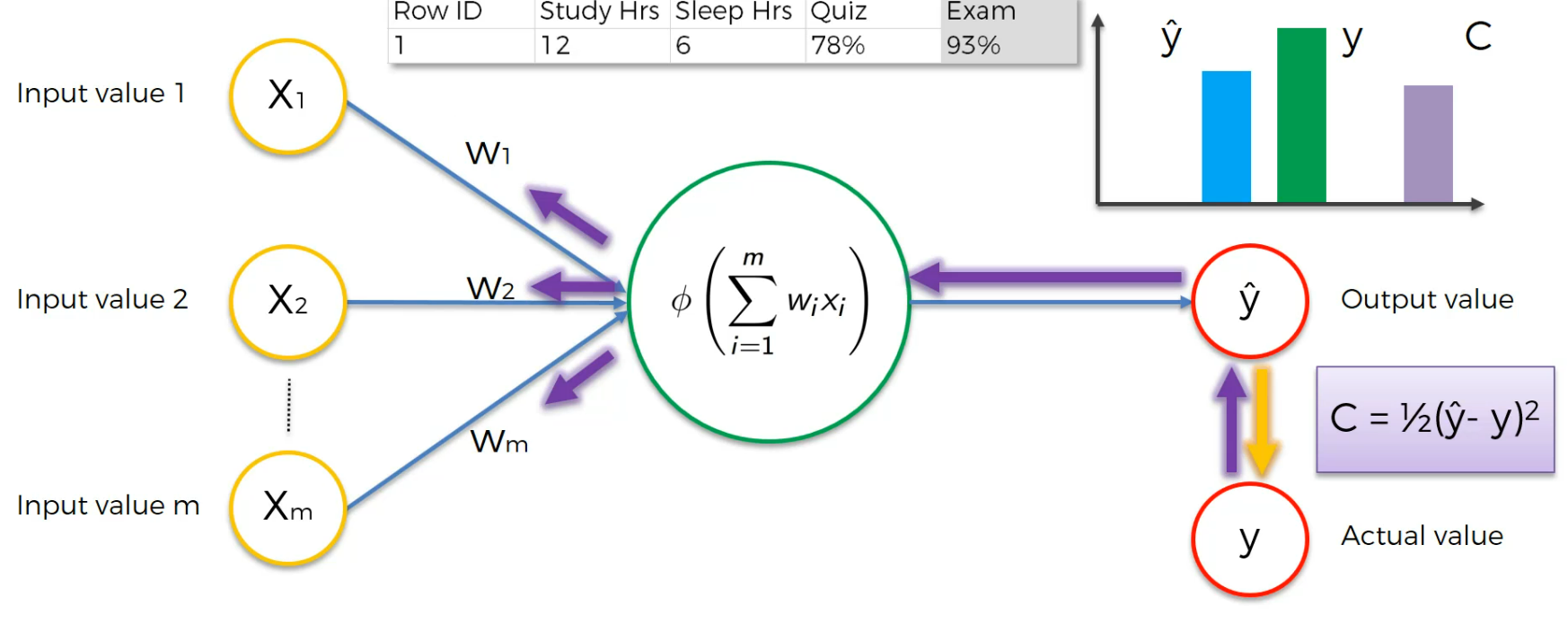
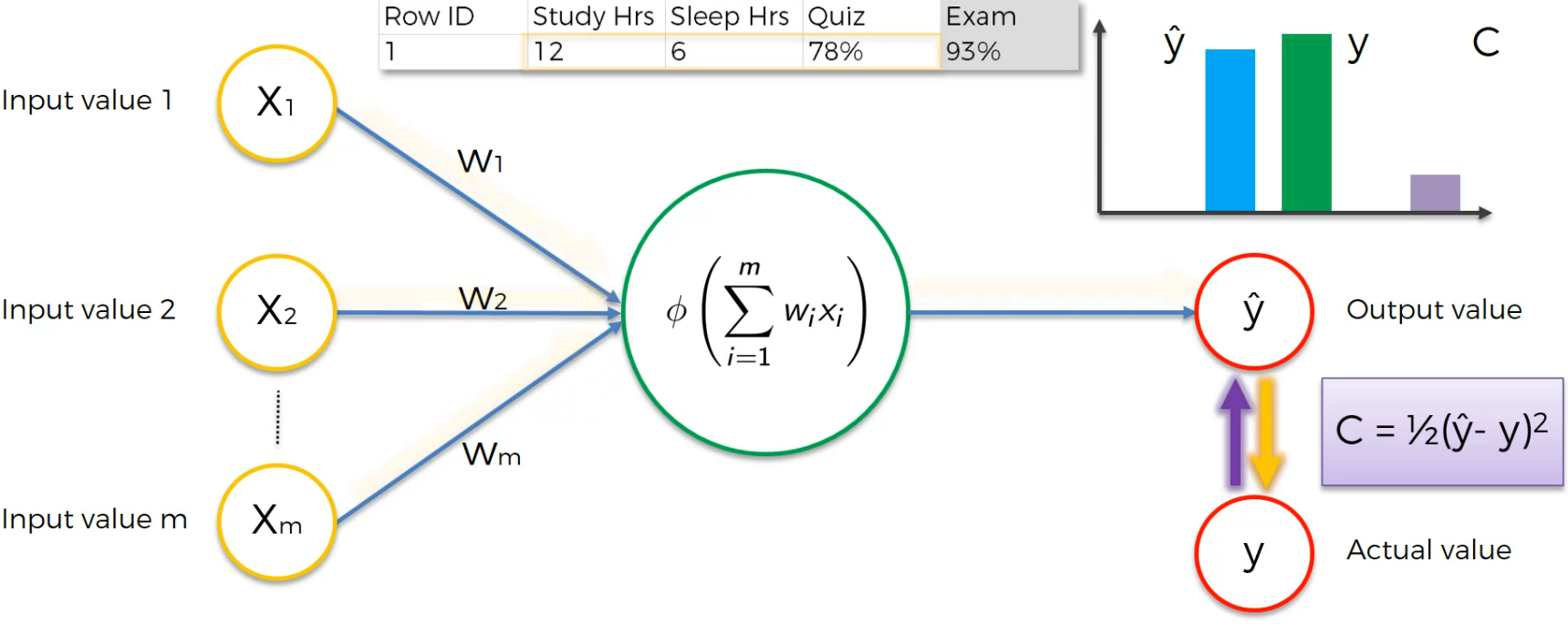
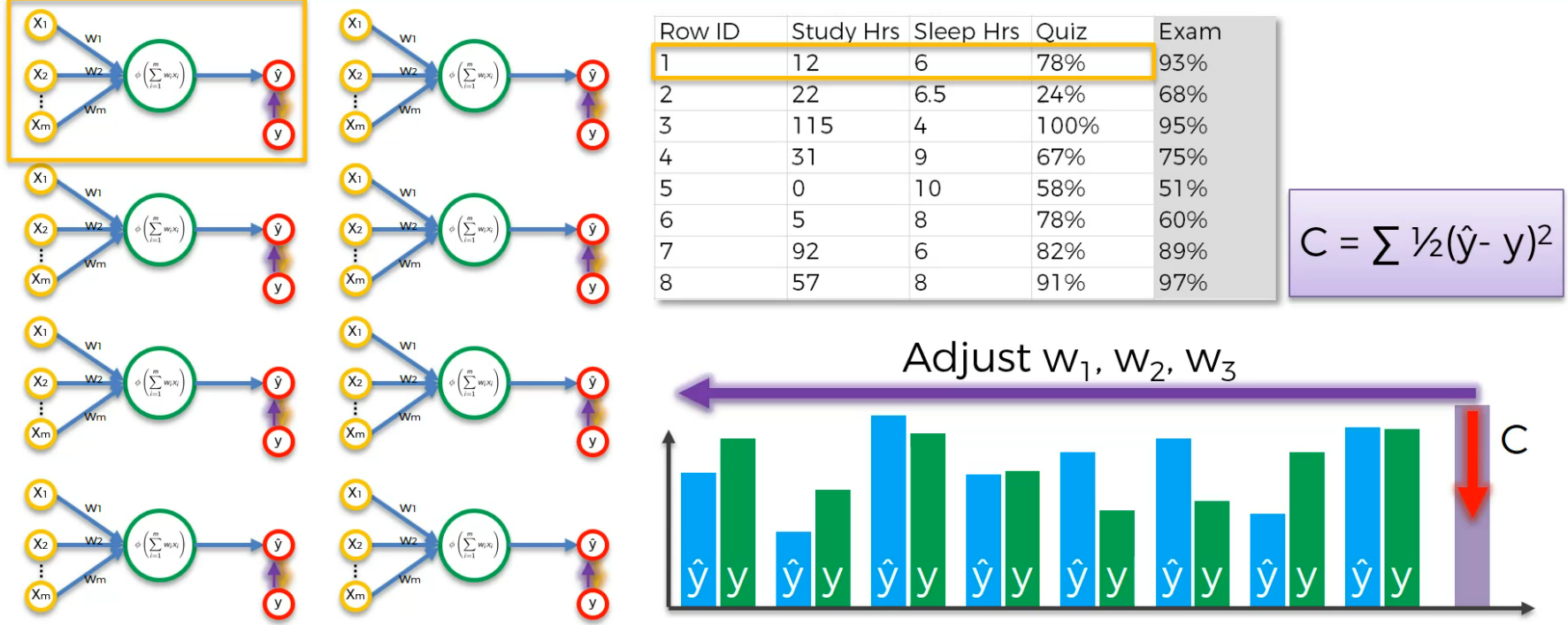
Assume this is a case:
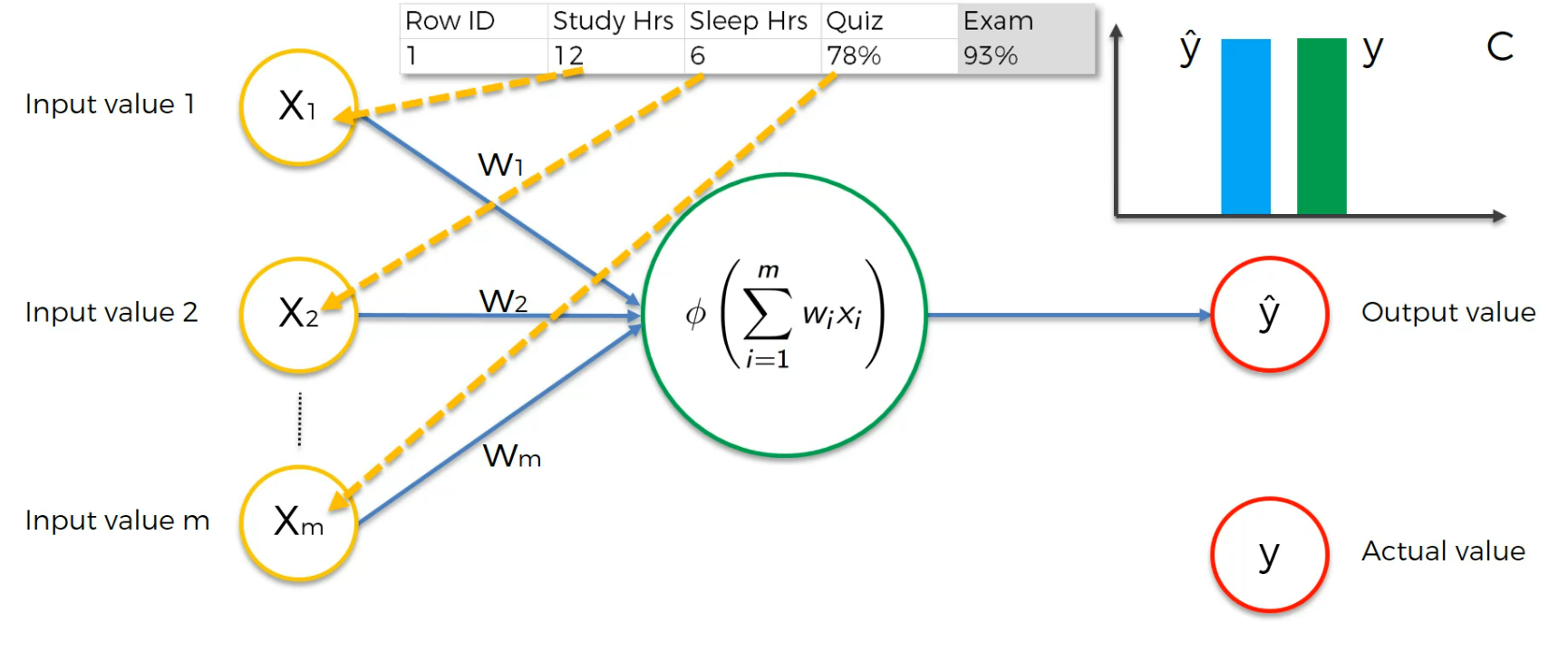
Here the input neurons are Study hr, Sleep Hrs, Quiz and based on that, we got 93% which is actual value.
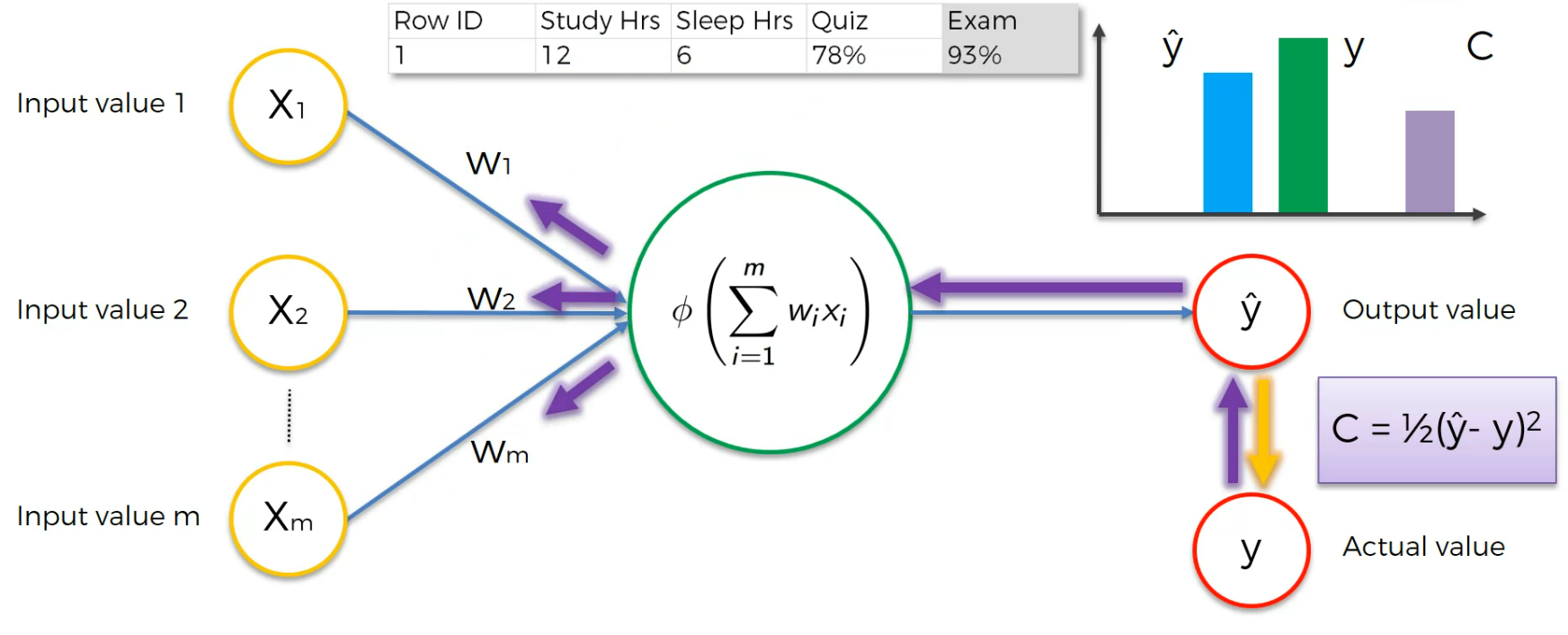
After training we get a cost function and we modify the weights to lessen the Cost function.
Now we feed the input neurons again with modified weights
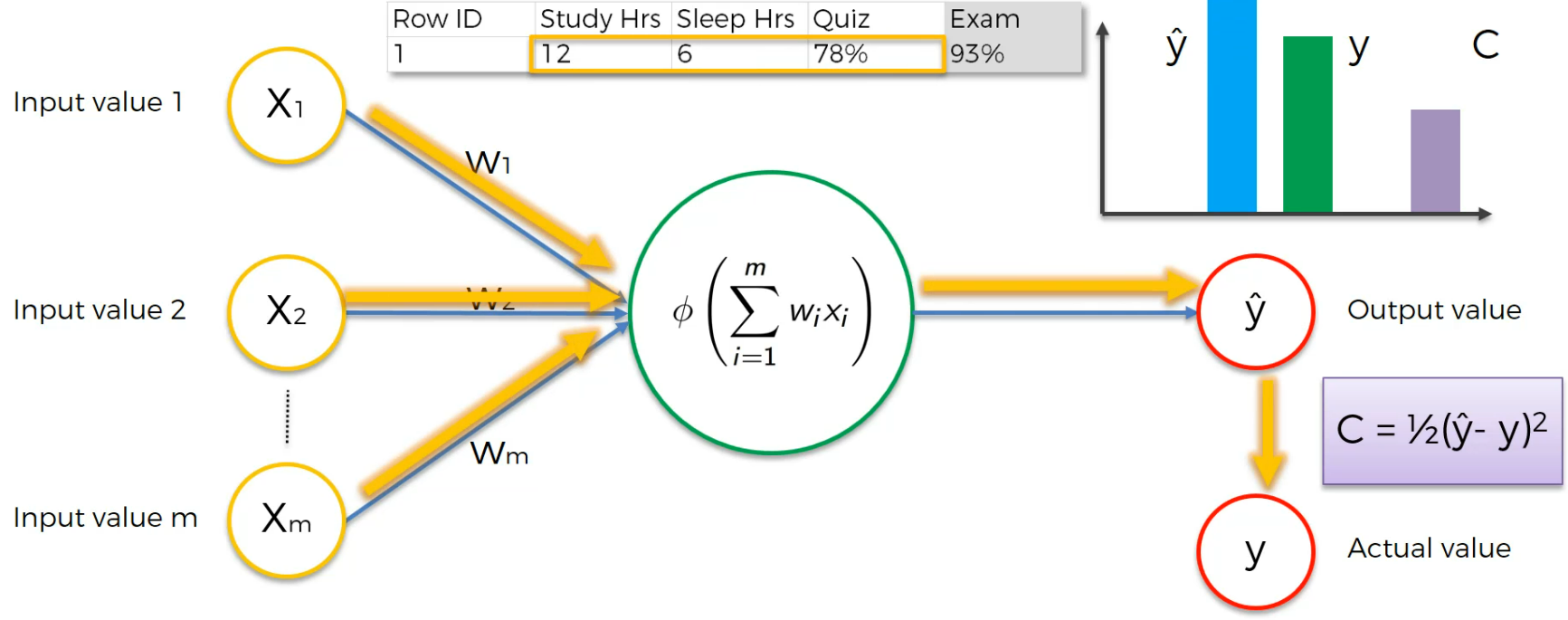
We again modify the weights to adjust the cost function.
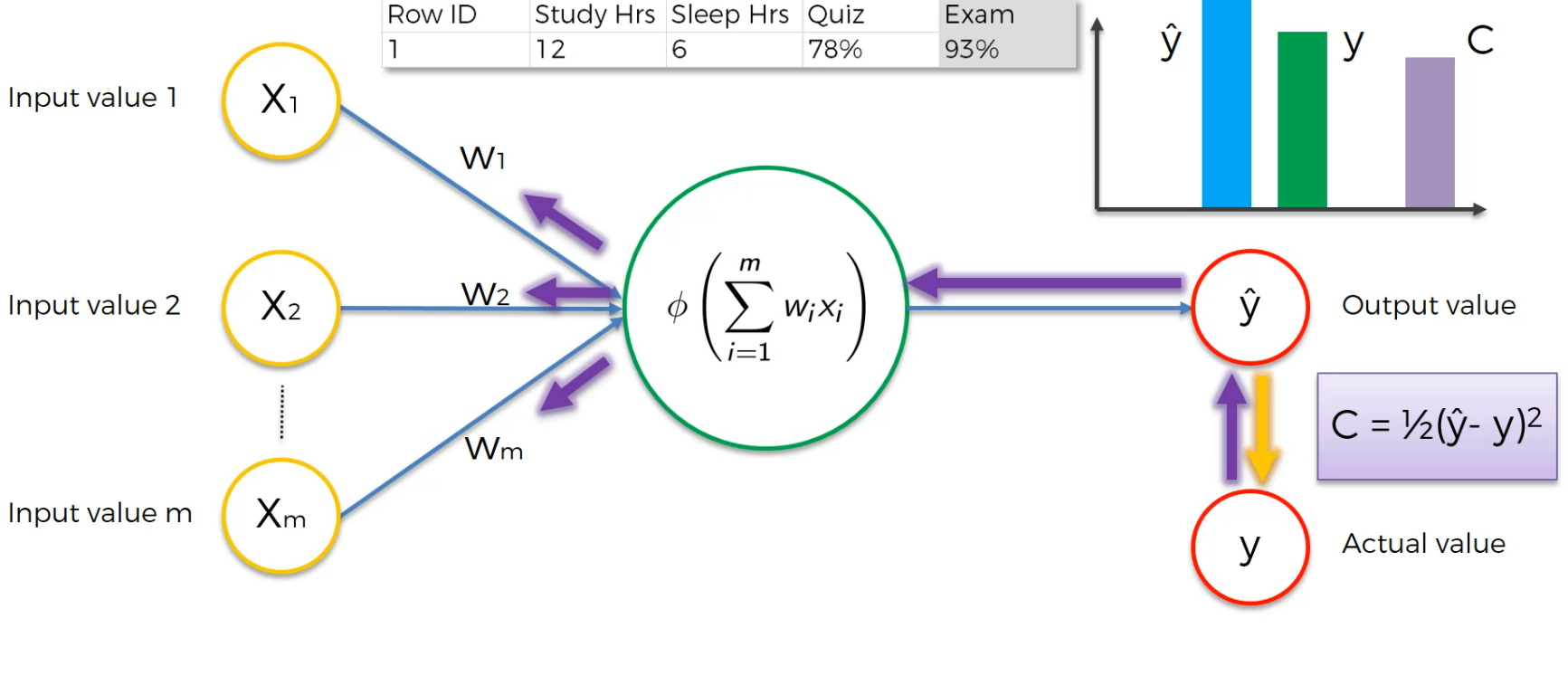
Again, if we run it and depending on the cost function, we modify the weight.
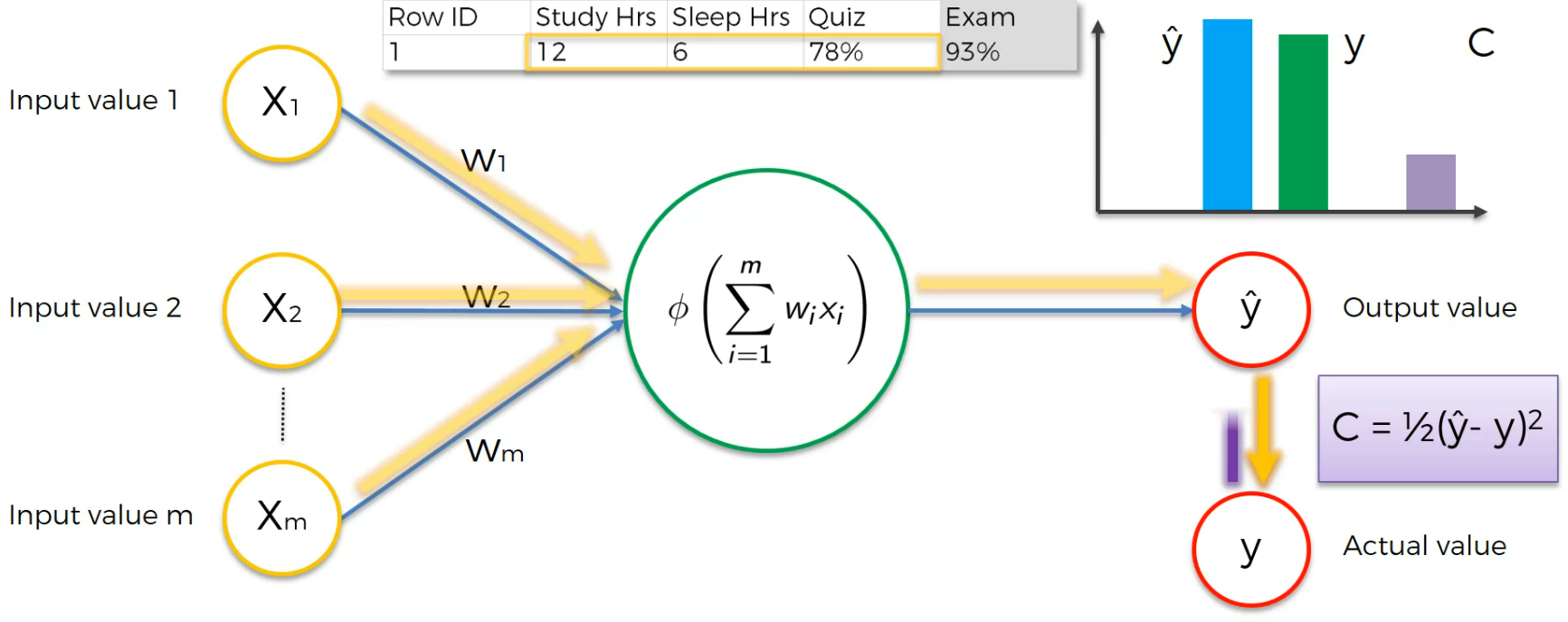
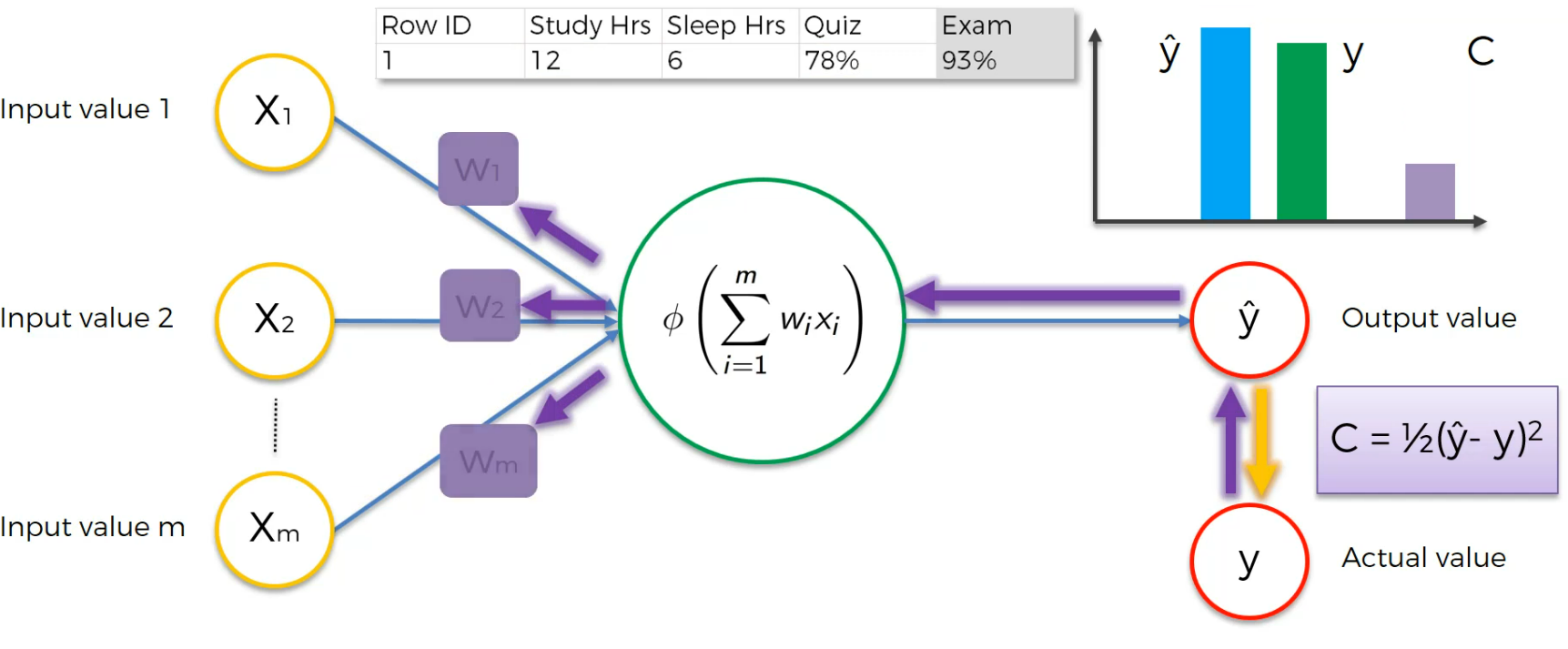
We run this again,
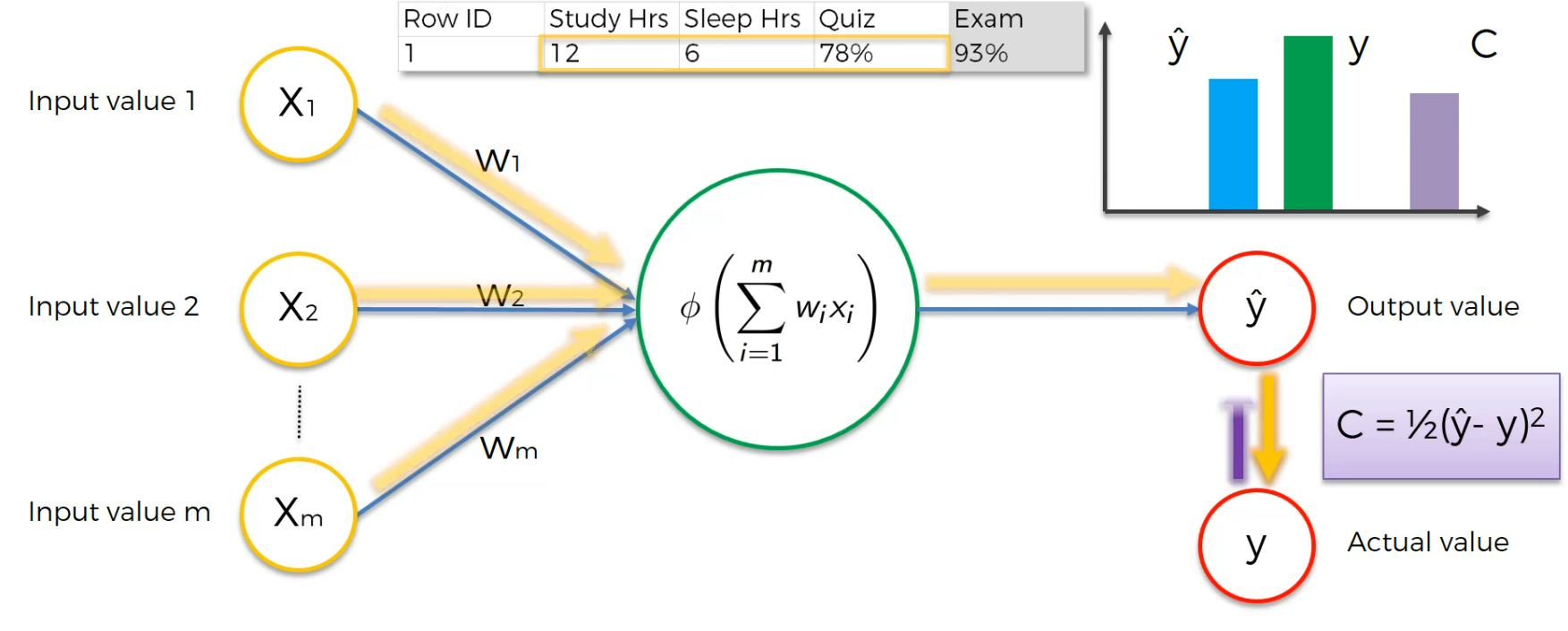
Again,
Again,
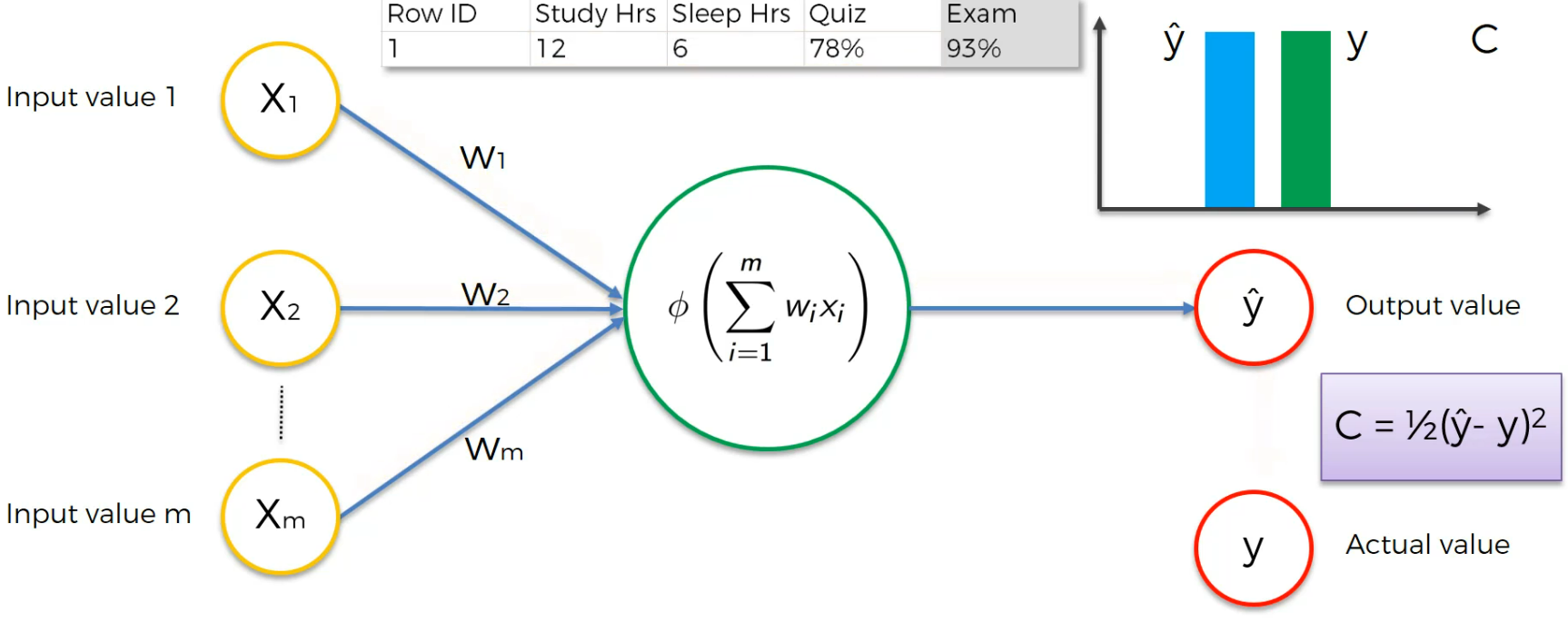
Now, here we go!
The cost function is 0 here (Generally never happens) and Output value is equal to Actual Value.
What about data with multiple rows?
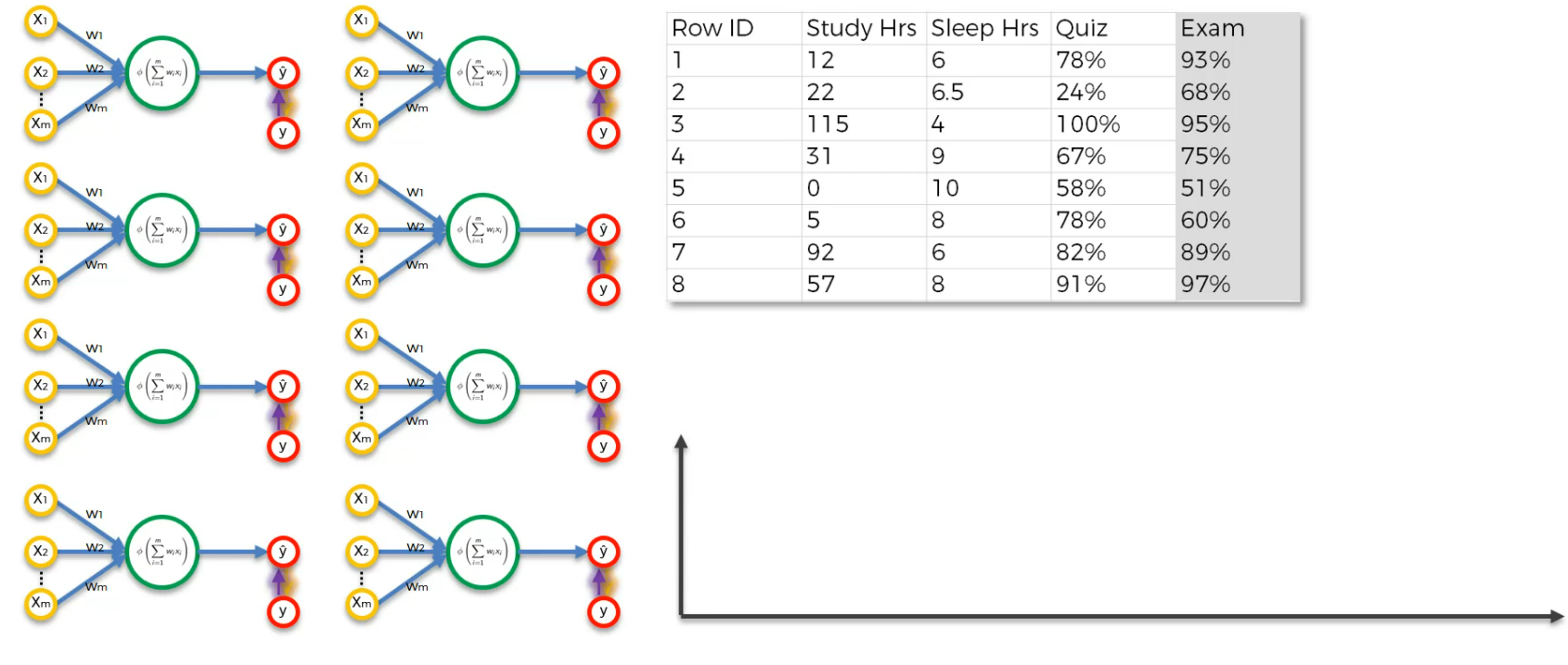
So, every row is trained on the same Neural Network but different times
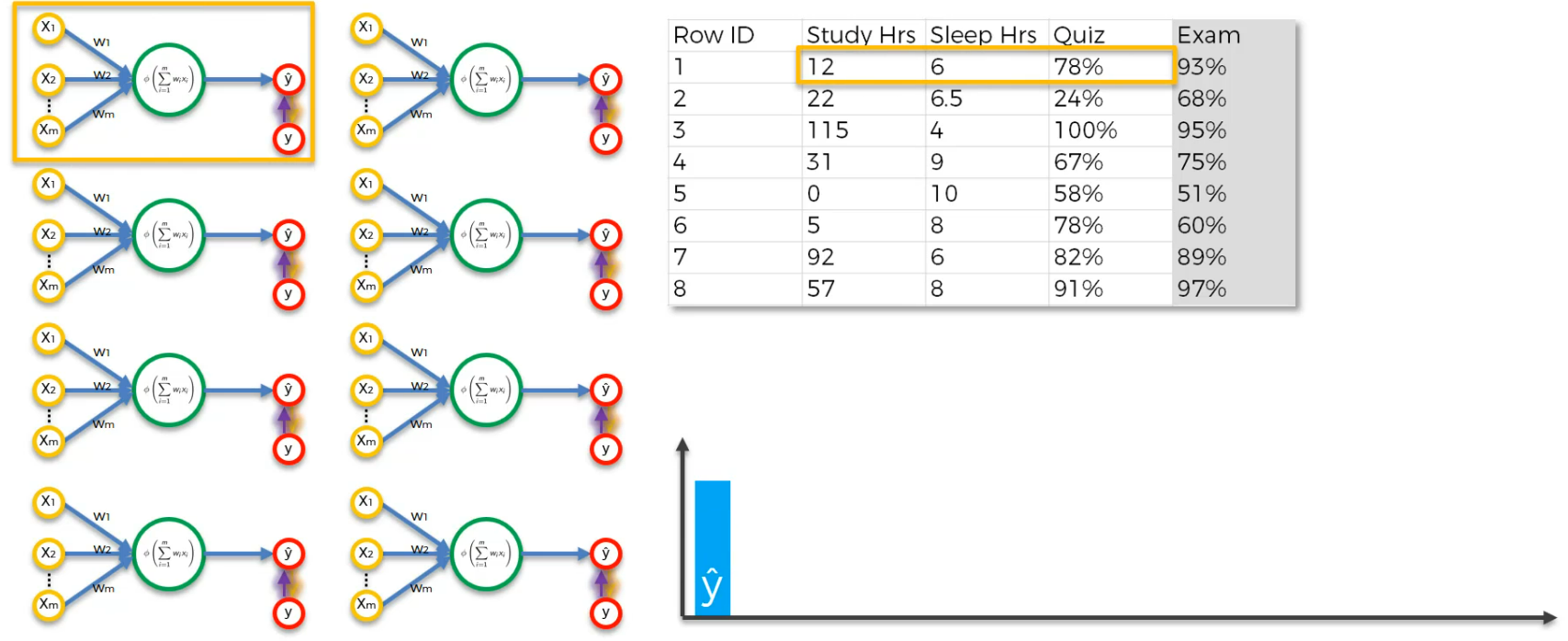
So, when we run the the first row, we get the output as this.
For the second row,
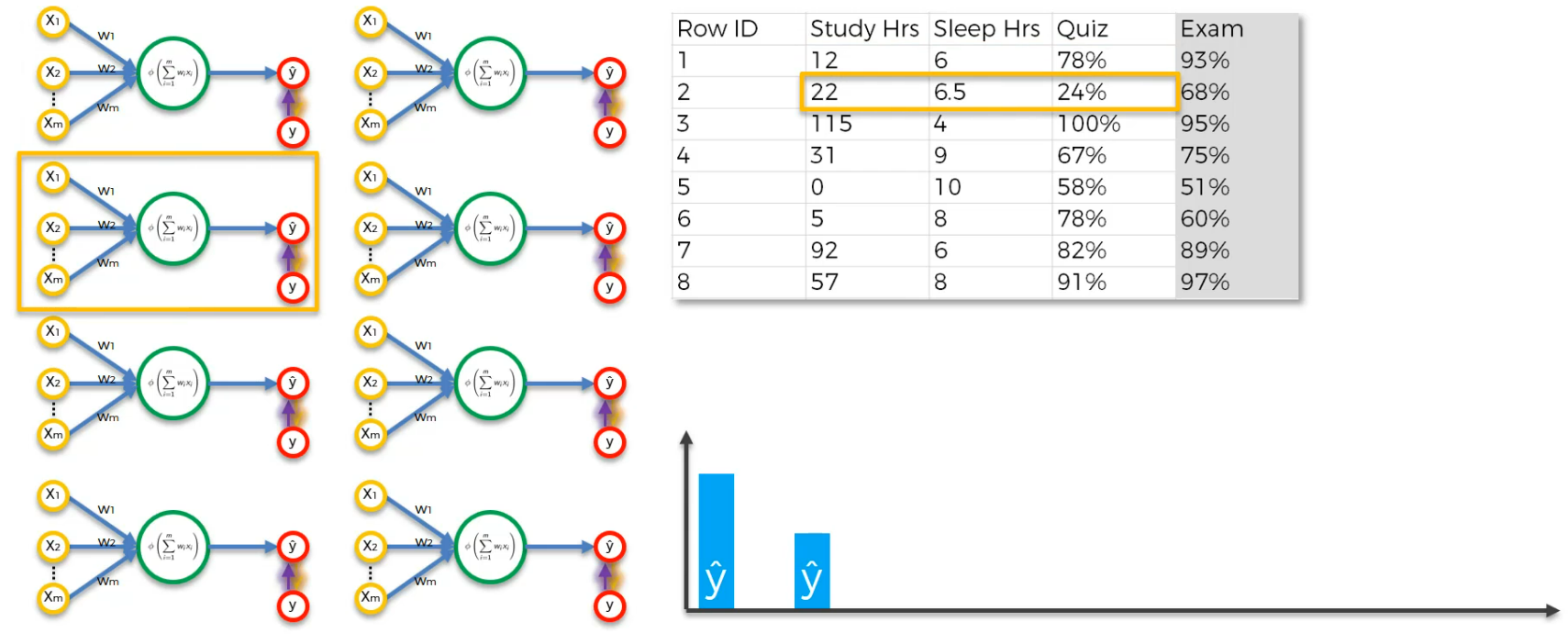
So, after running all rows, here is the graph
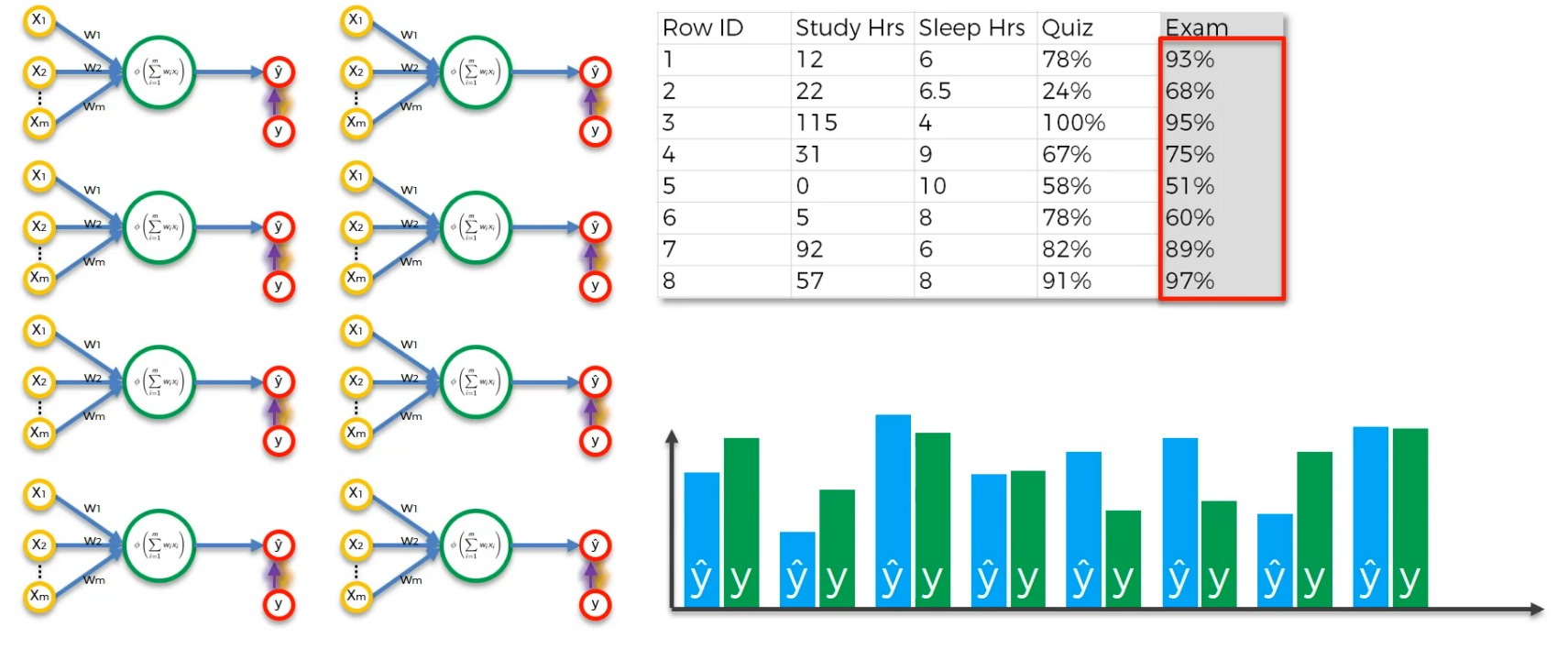
Output value as y cap and y as actual value (Exam)
Now, let's have the cost function, C
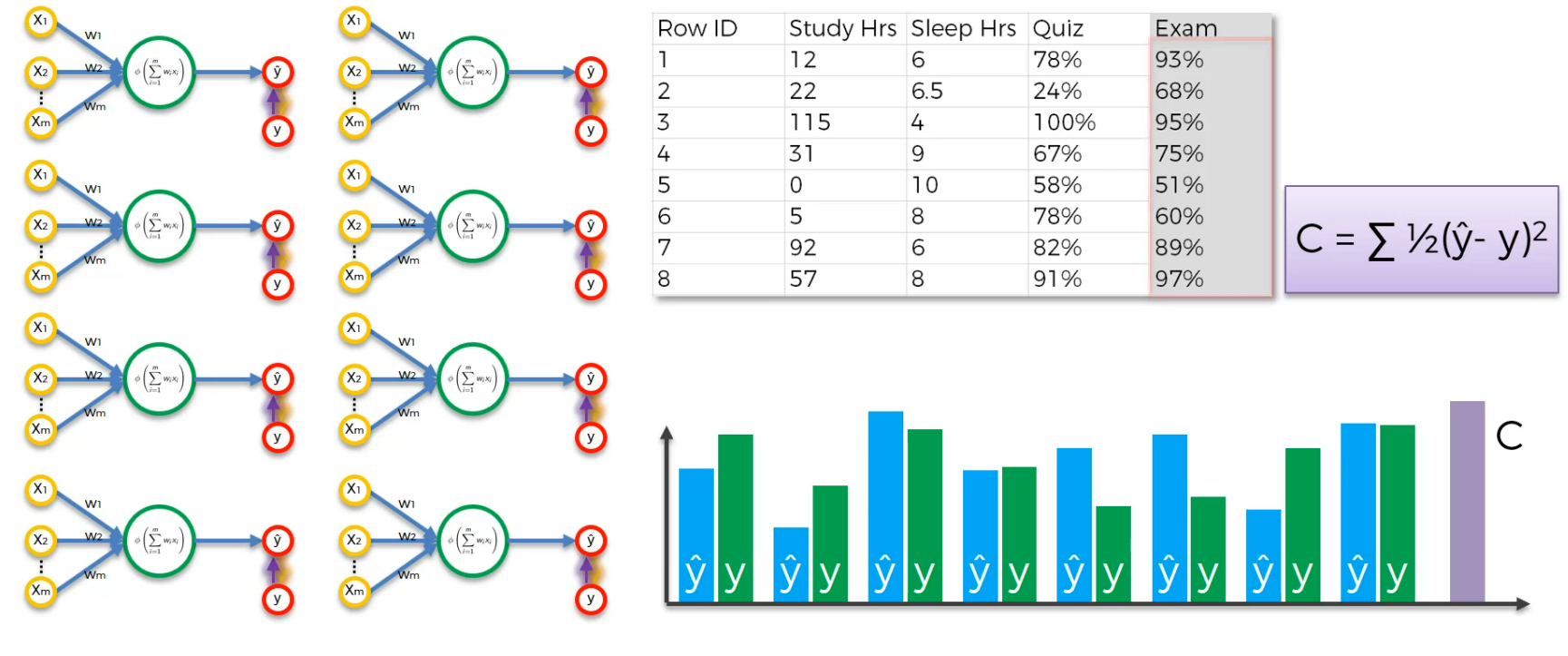
Now, we will update the weights to minimize the cost.
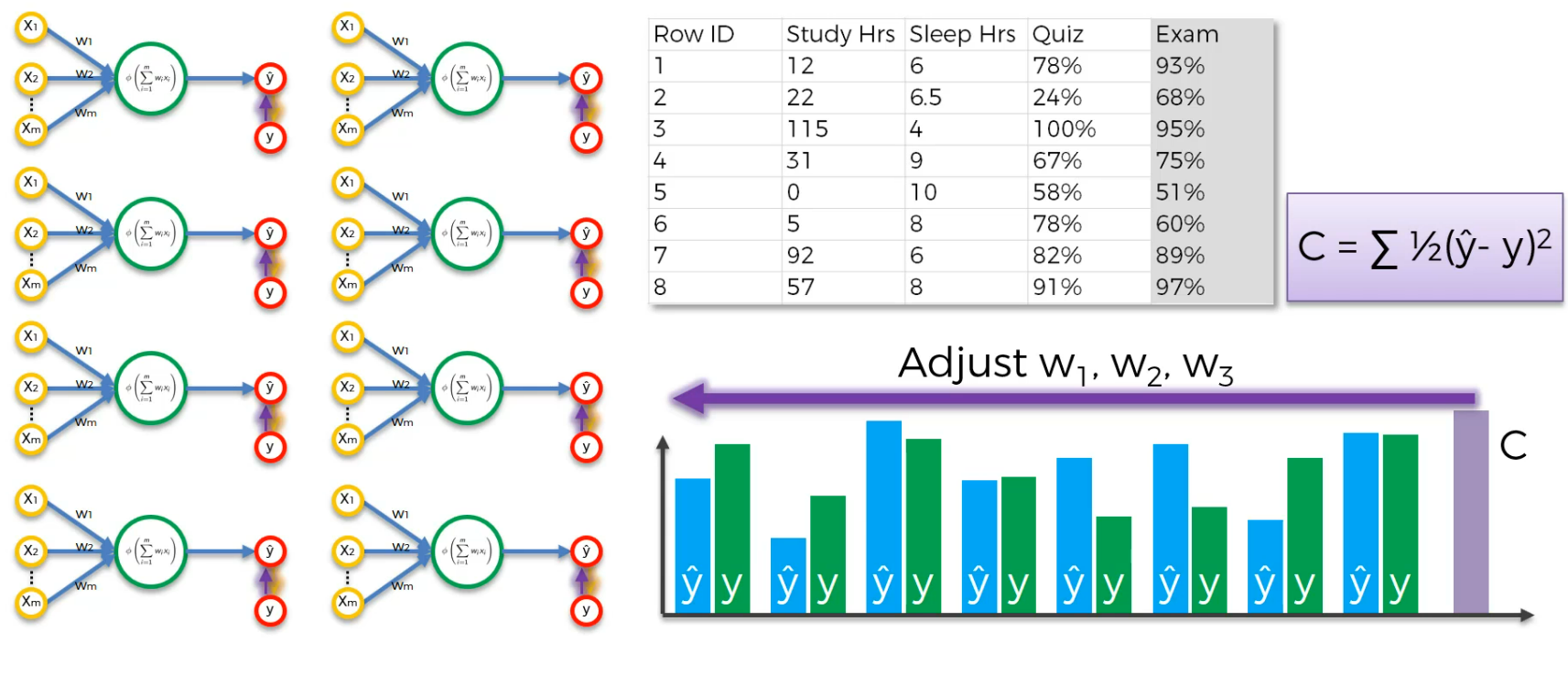
So, we will train again and again with modified weights.
Gradient Descent
We learned the weights gets adjusted. but how?
Let's learn it
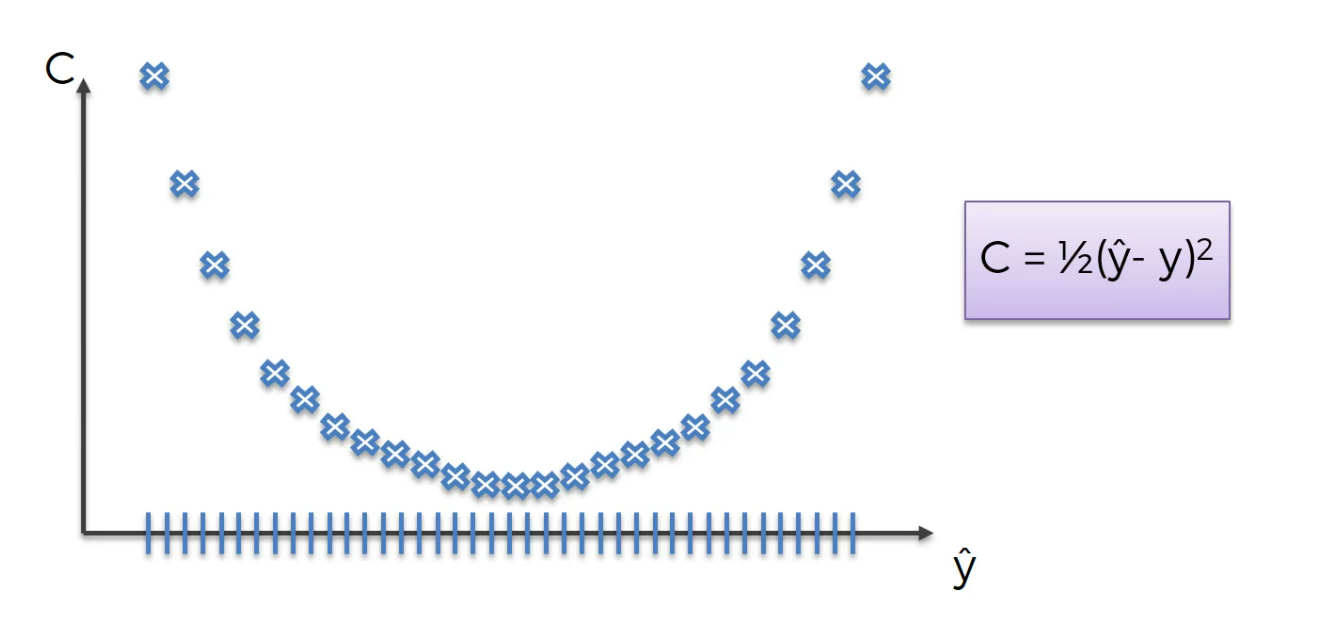
Let's check a graph where we have plotted 1000 weights
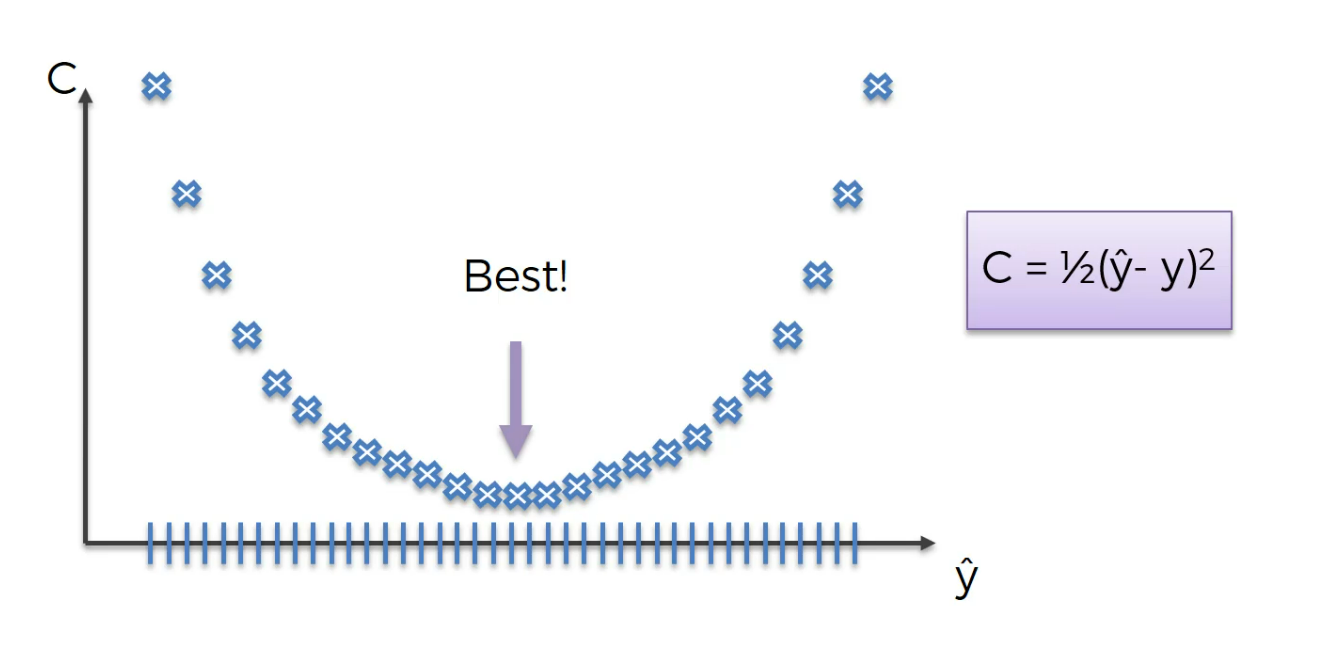
The best weight will be here
Let's check an example of 25 weights
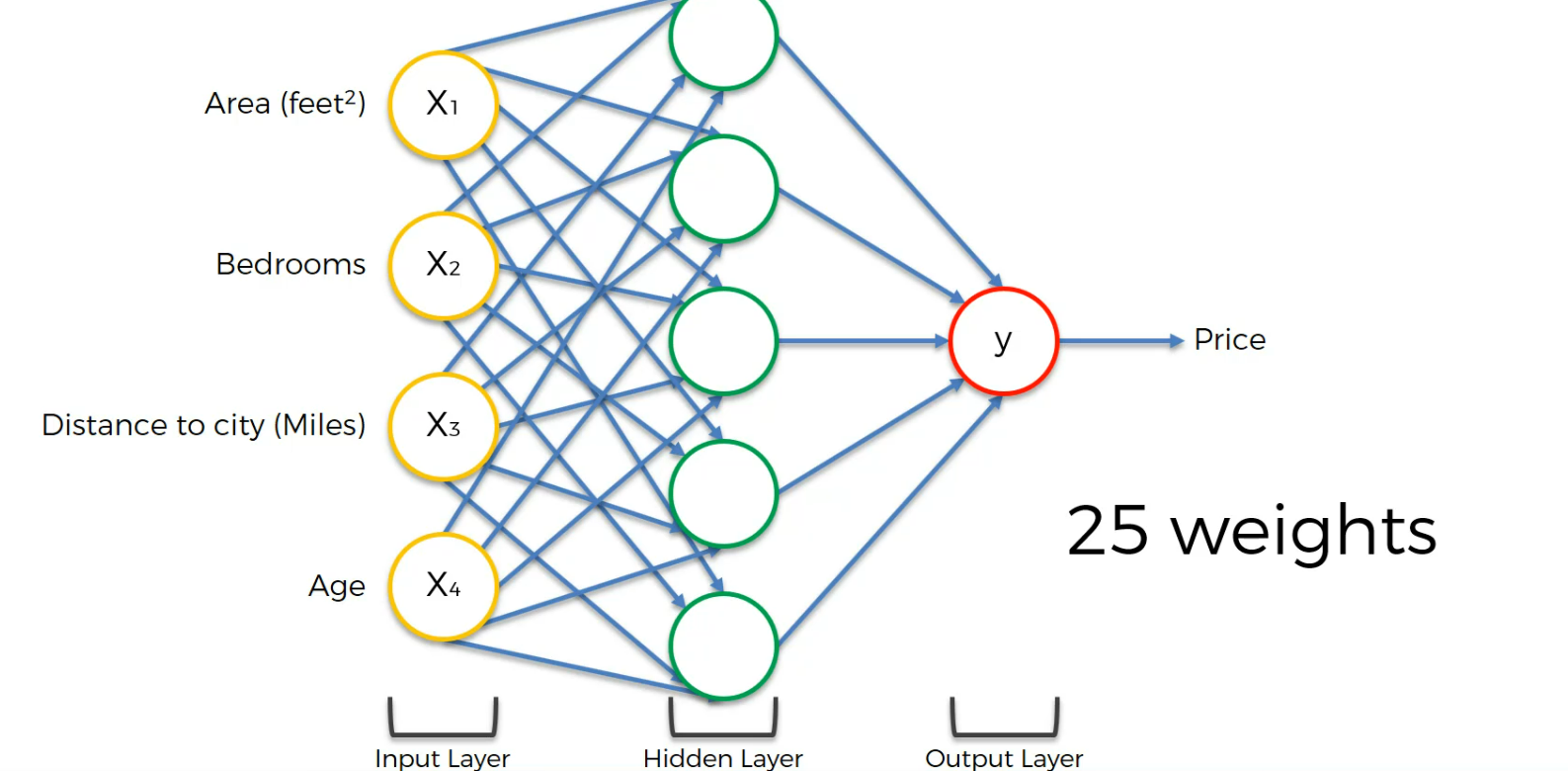
25 weights lead us to 1000 combinations

the faster super computer can operate at a speed of 93 petaflops.
which is 93*10^5 Floating operation per seconds
Let's say hypothetically that it can do one, test one, combination for our neural network in one flop, basically in one floating operation.
That means it will still require 10 to the power of 75 divided by 93 times 10 to the power of 15 seconds to run all of those tests,
So that means one, or approximately 10 to the power of 58 seconds and that is the same as 10 to the power of 50 years. That is a huge number that is longer than the universe has existed

So there we go this is a no no even on the worlds fastest super computer Sunway TaihuLight. So we have to come up with a very different approach how we're going to find the optimal weight.
We just tested for a simpler neural network.
What about if the neural network looks like something like this? Right? Or even greater than that?
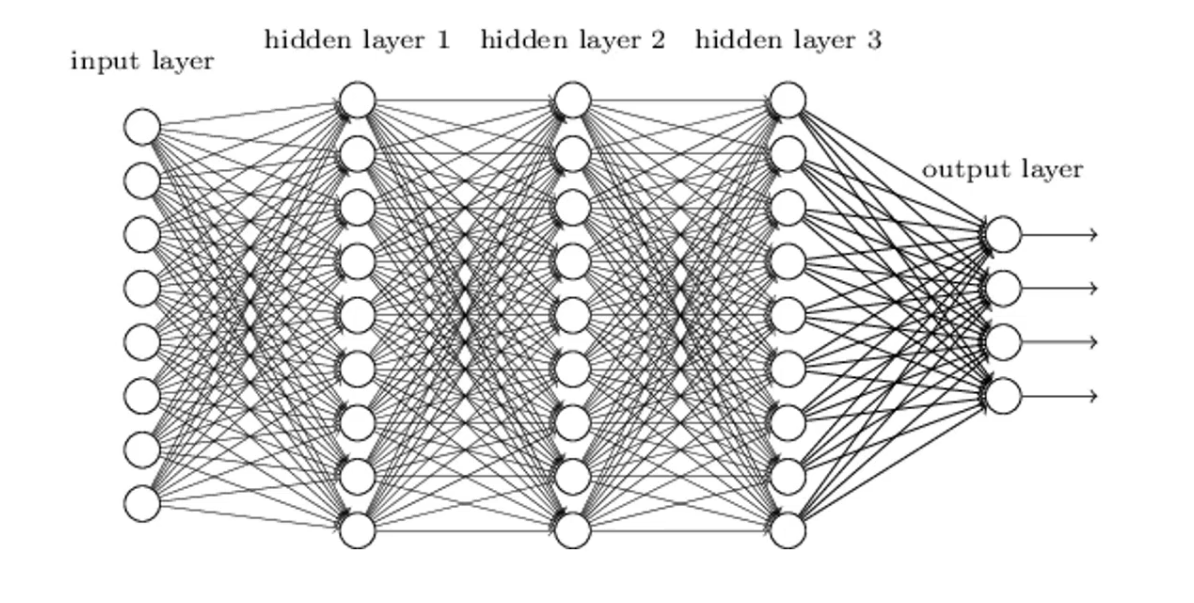
Haha!
Let's learn how to make it easier and optimize the weights
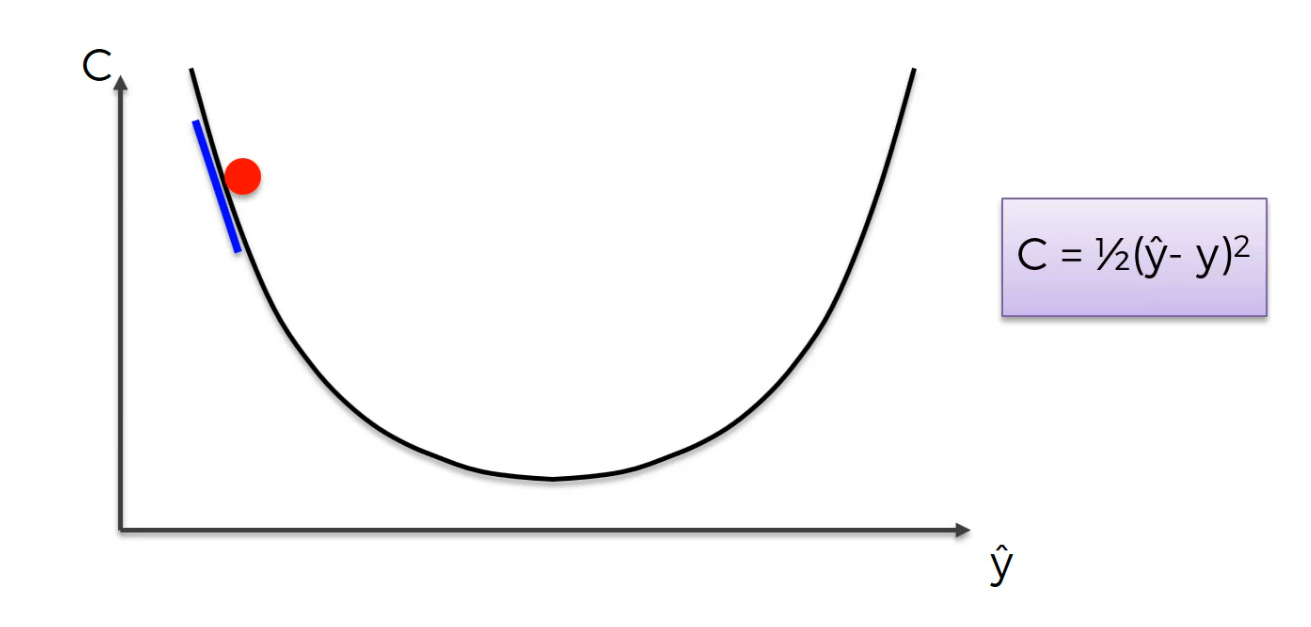
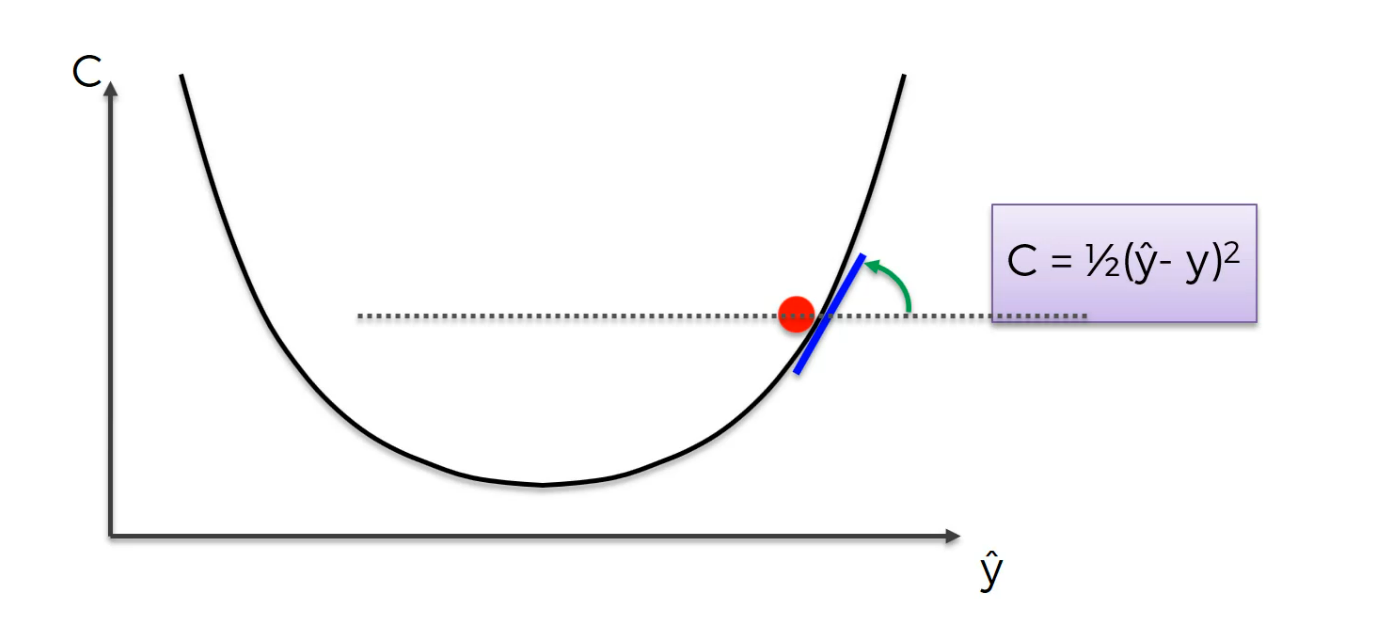
So, let's say we start somewhere, you gotta start somewhere, so we start over there and from that point in the top left what we're going to do is we're going to look at the angle of our cost function at that point.
basically you just need to differentiate, find out what the slope is in that specific point and find out if the slope is positive or negative. If the slope is negative like in this case, means that you're going downhill.
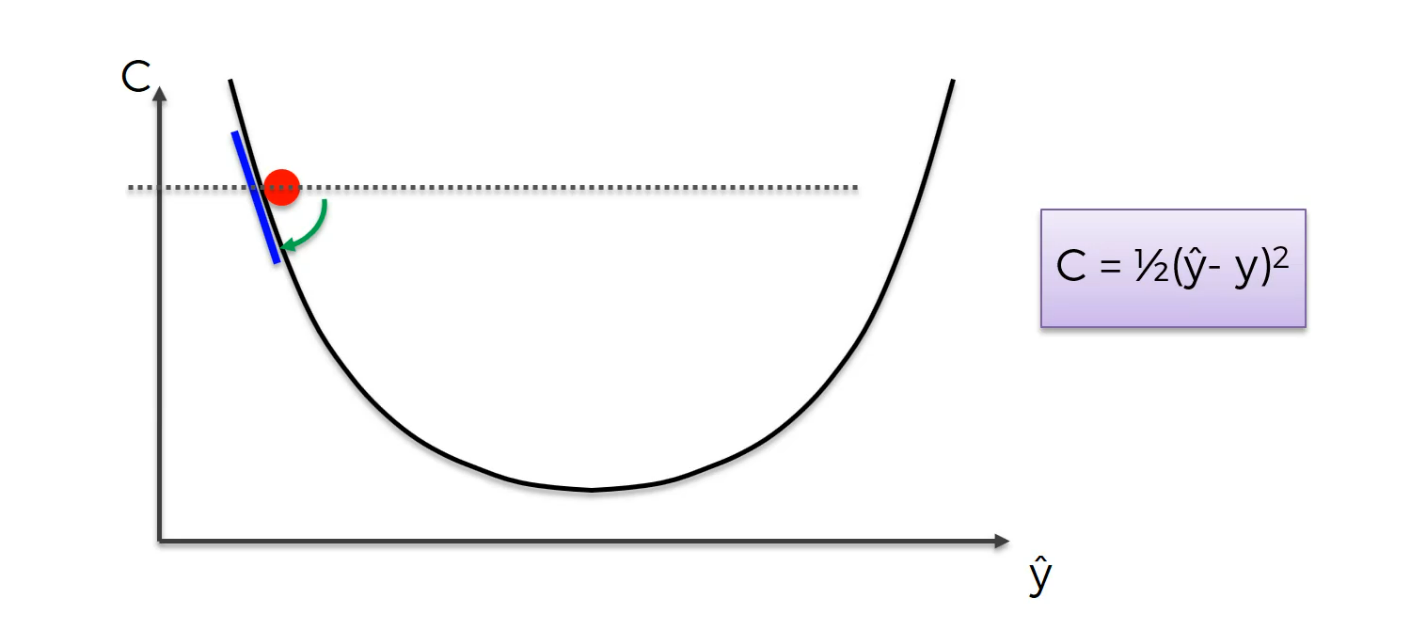
So to the right is downhill to the left is uphill.And from there it means you need to go right basically you need to go downhill and that's what we're going to do.
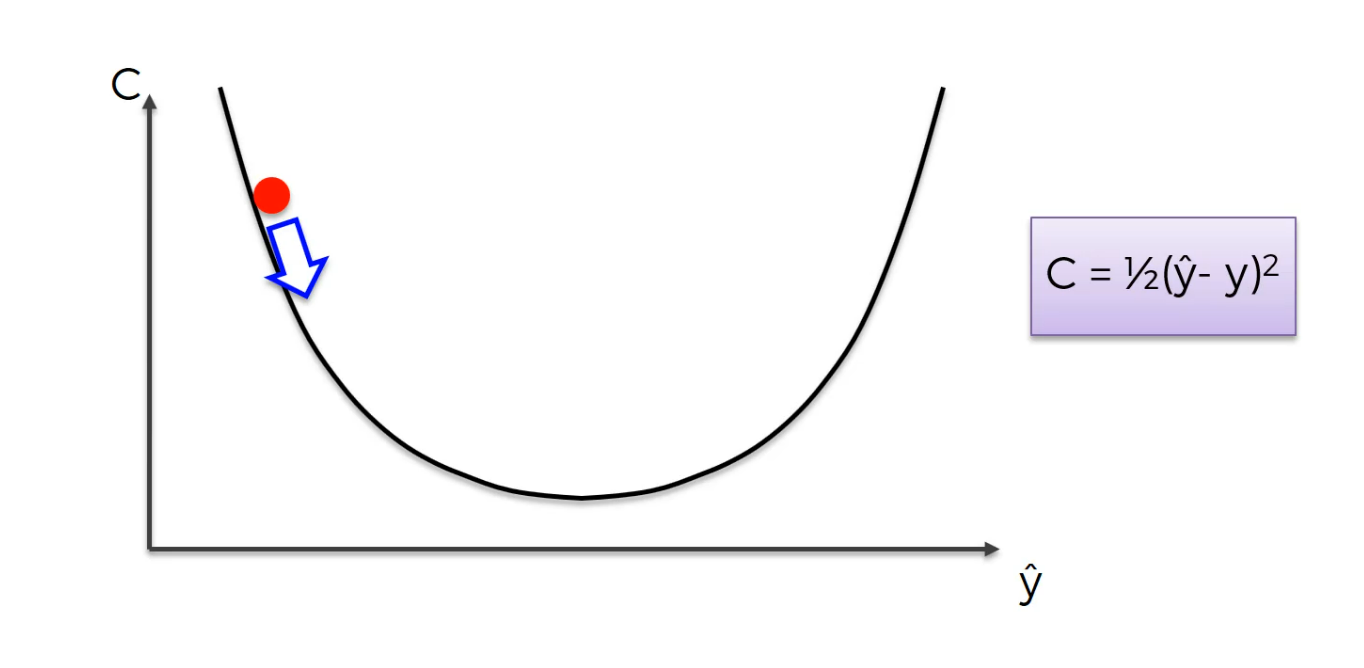
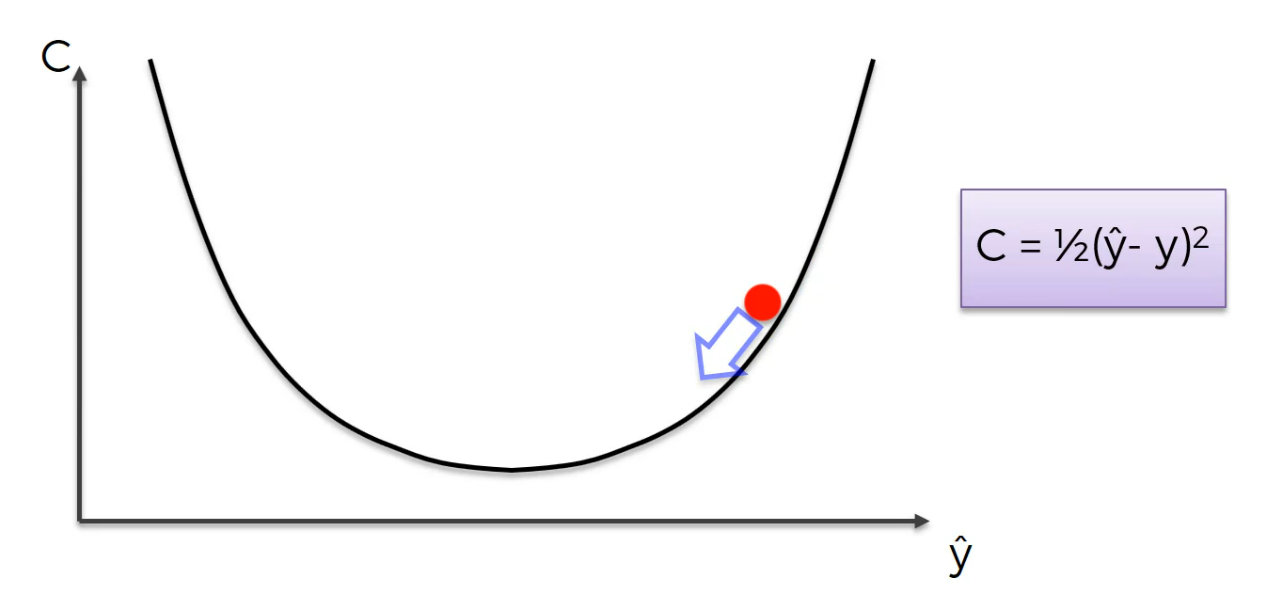
we took a step and now we are here.
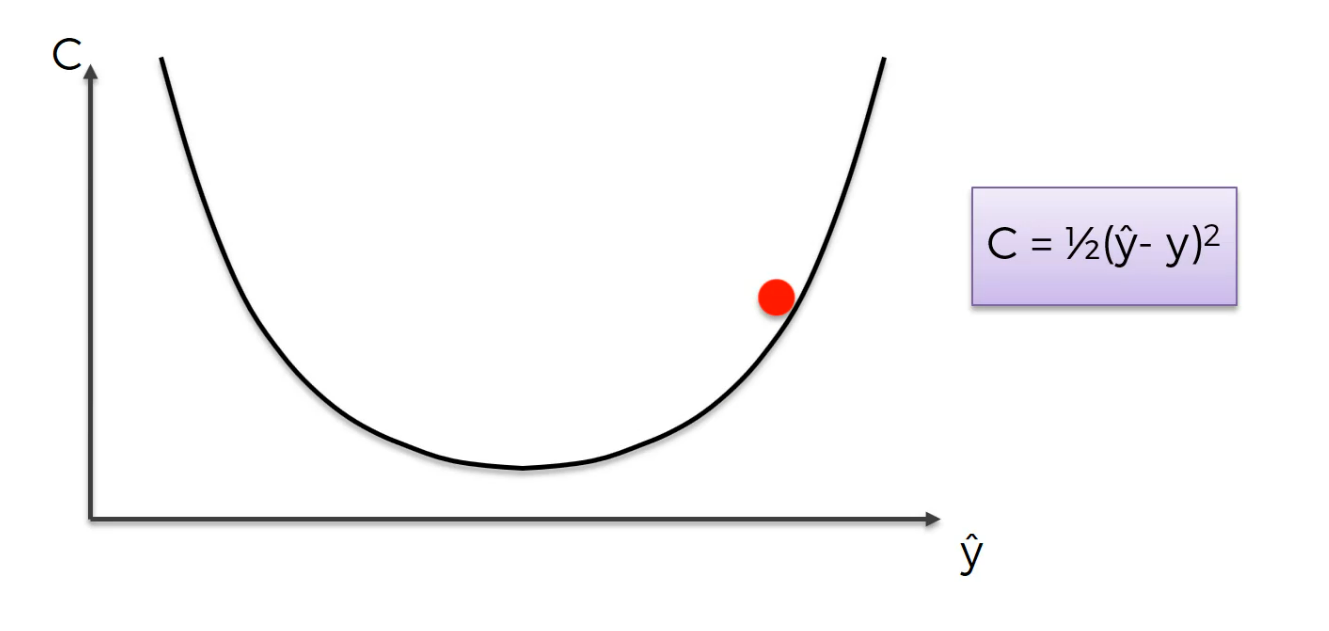
Again same thing you calculate the slope this time the slope is positive meaning right is uphill left is downhill and you need to go left.Again same thing you calculate the slope this time the slope is positive meaning right is uphill left is downhill and you need to go left.
now here,
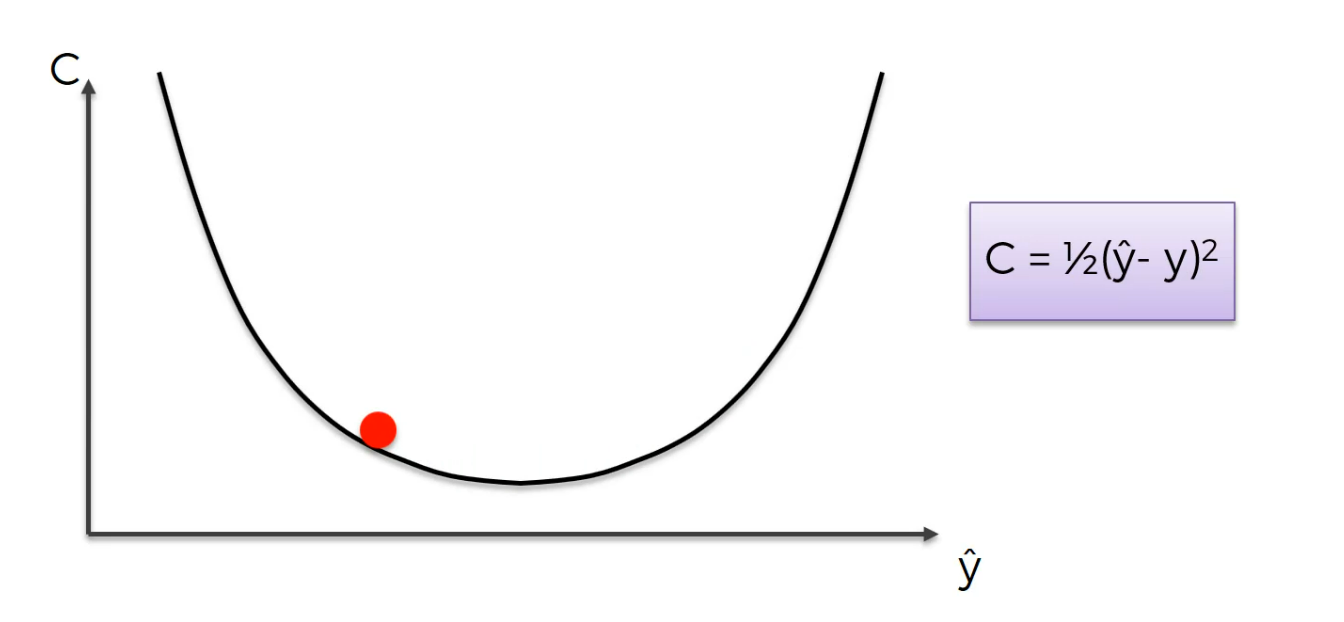
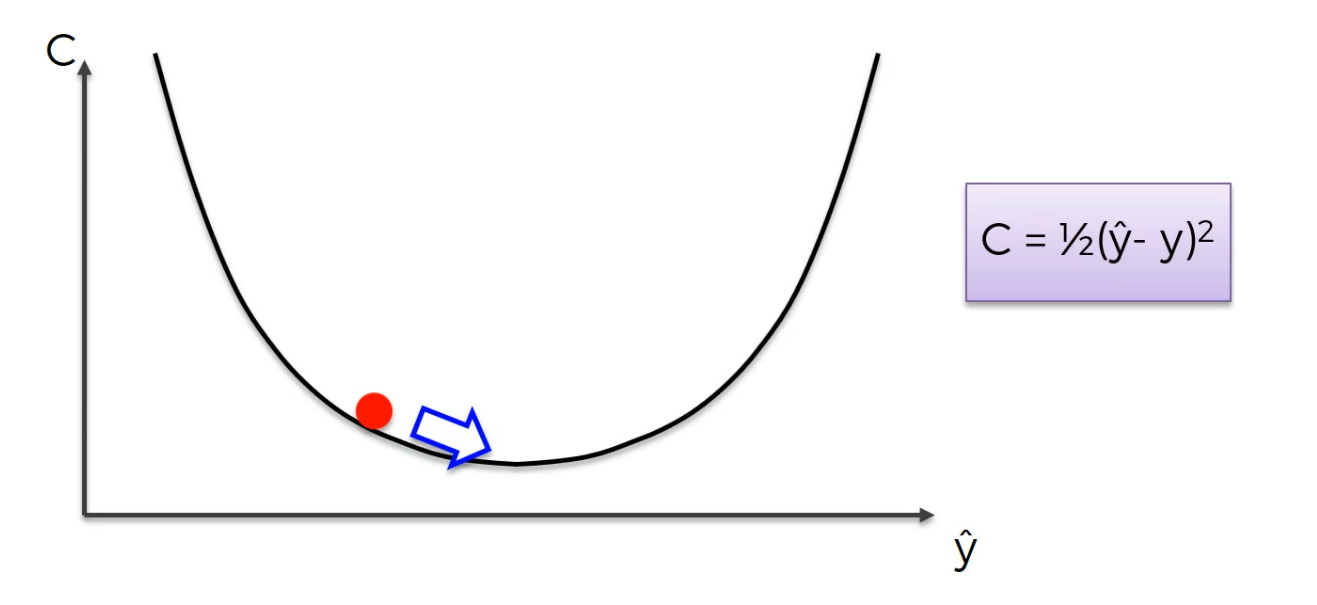
and then
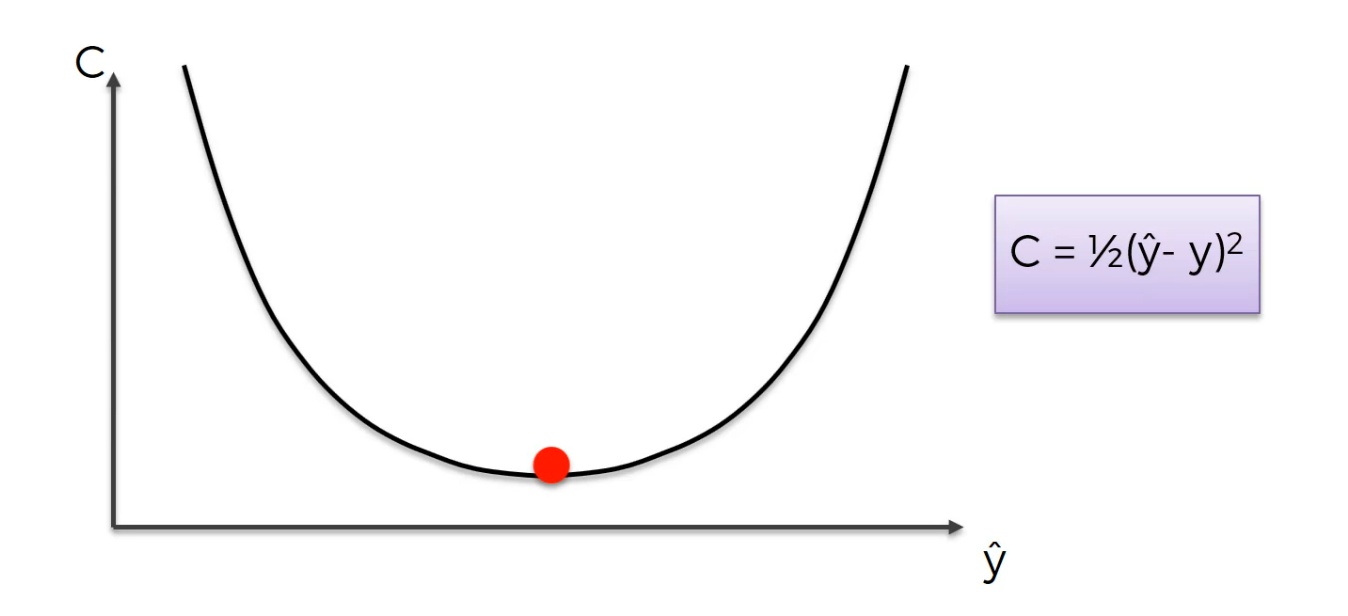
This is the best weight.
so this is what happened
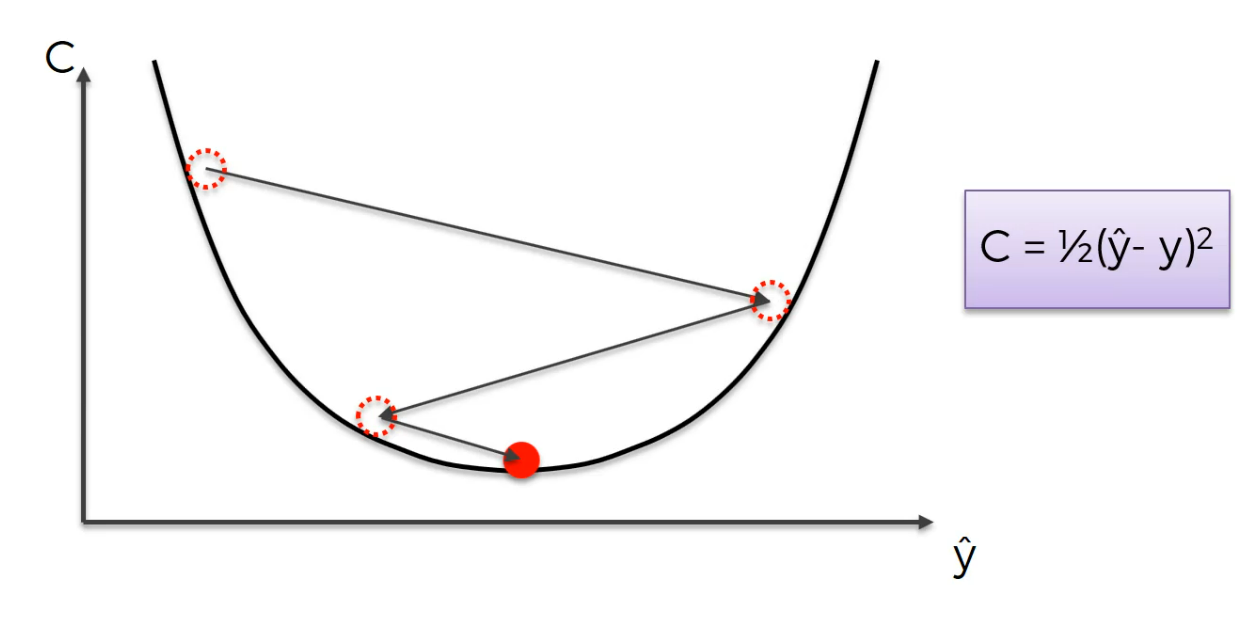
This was an example of 1D
This is gradient descent in 2D
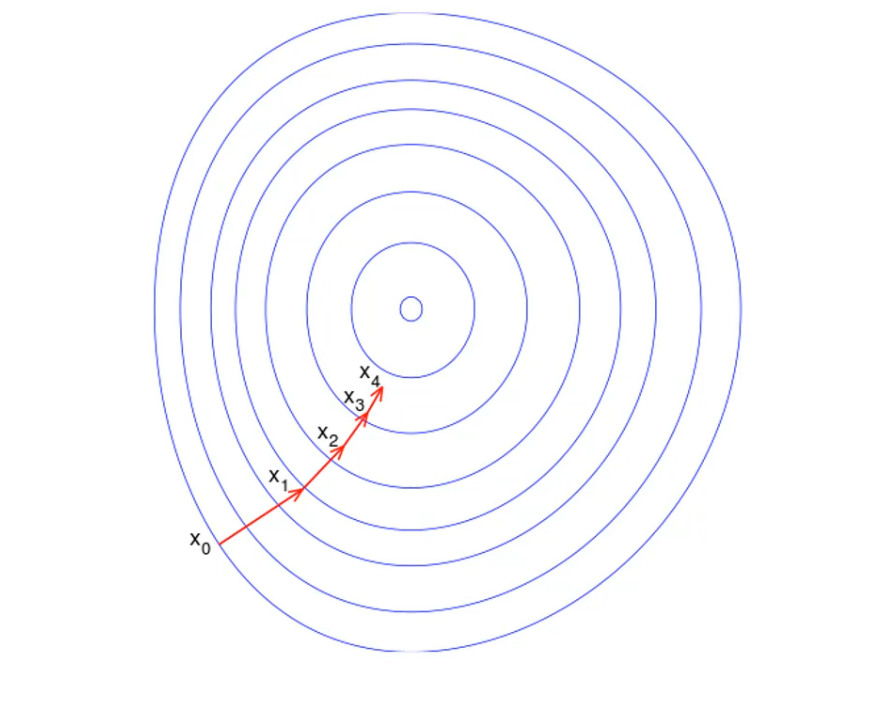
this is gradient descent in 3D
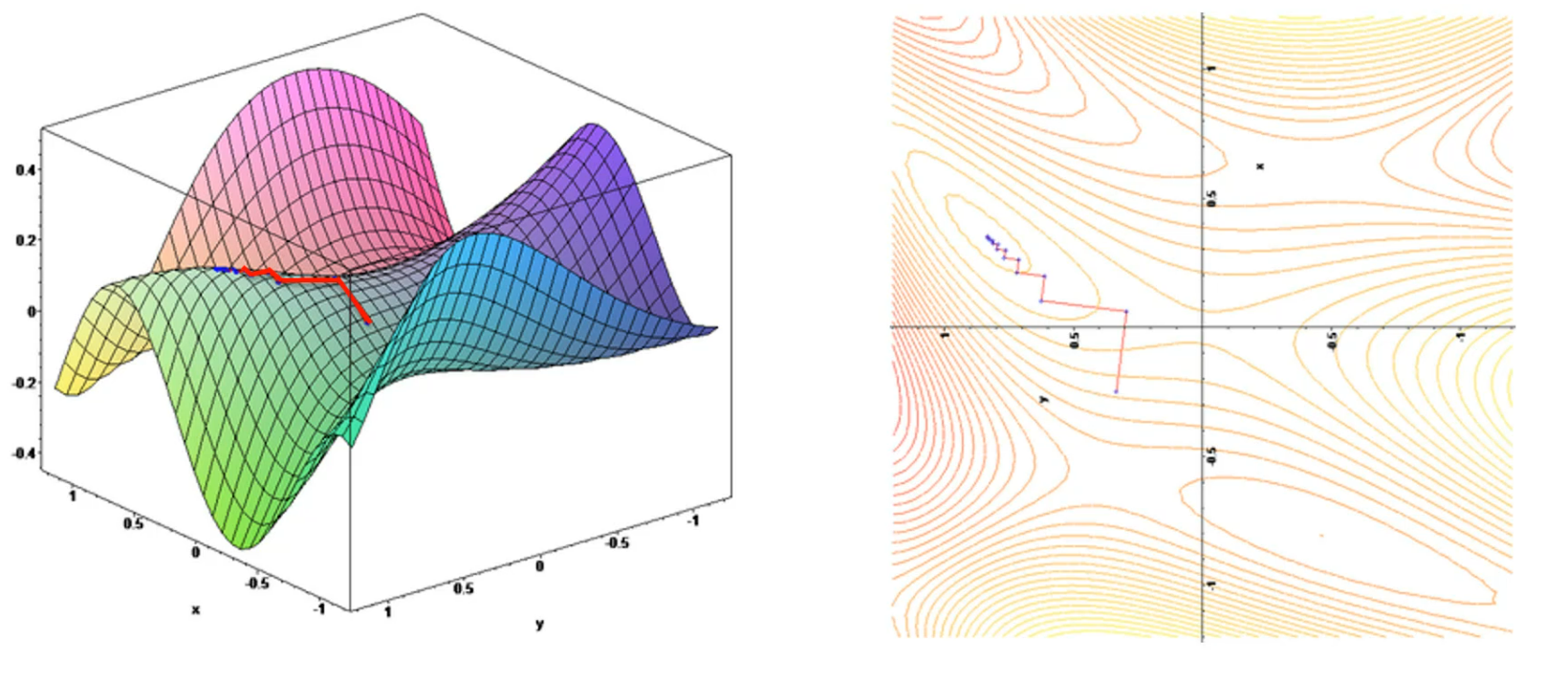
Stochastic gradient descent
We have till now worked with a graph where it was convex and had only a global minima.
but what if the function is not convex?
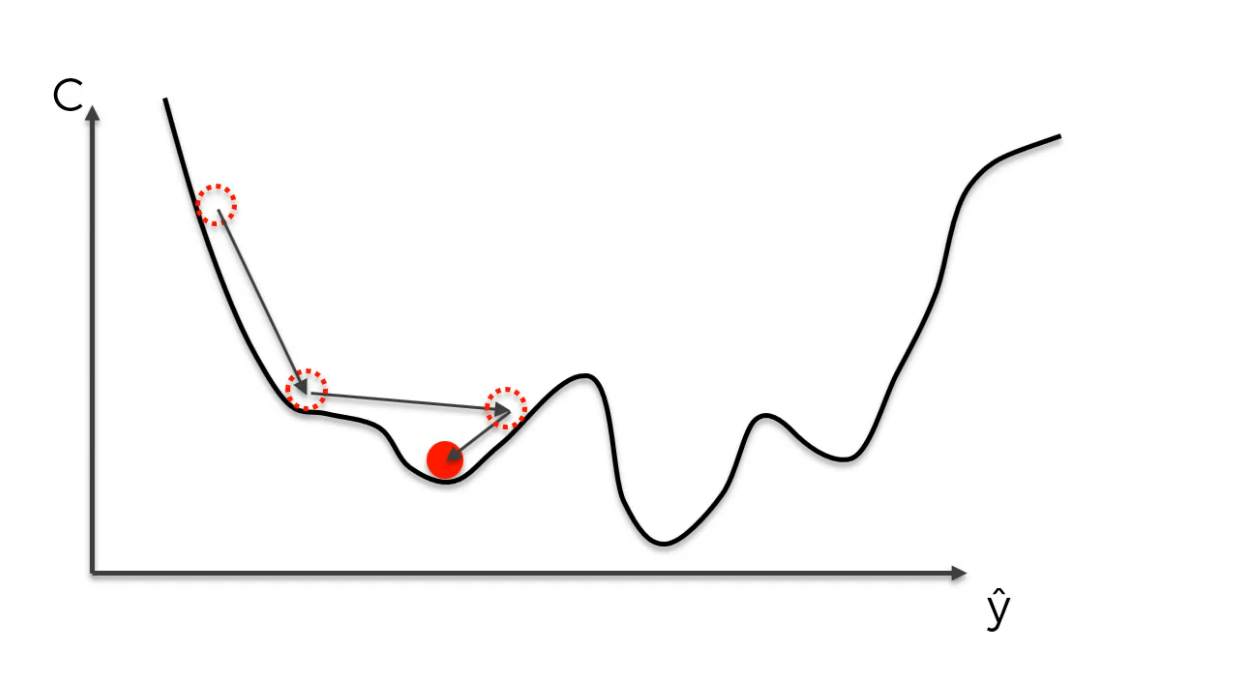
then we may find the local minima rather than global minima
So, to solve this issue. In Stochastic Gradient descent, when we run the neural network for each row, we adjust the weights at the same time.
Note : In normal Batch gradient descent, we adjust the neural networks at the end of the training of the all rows.
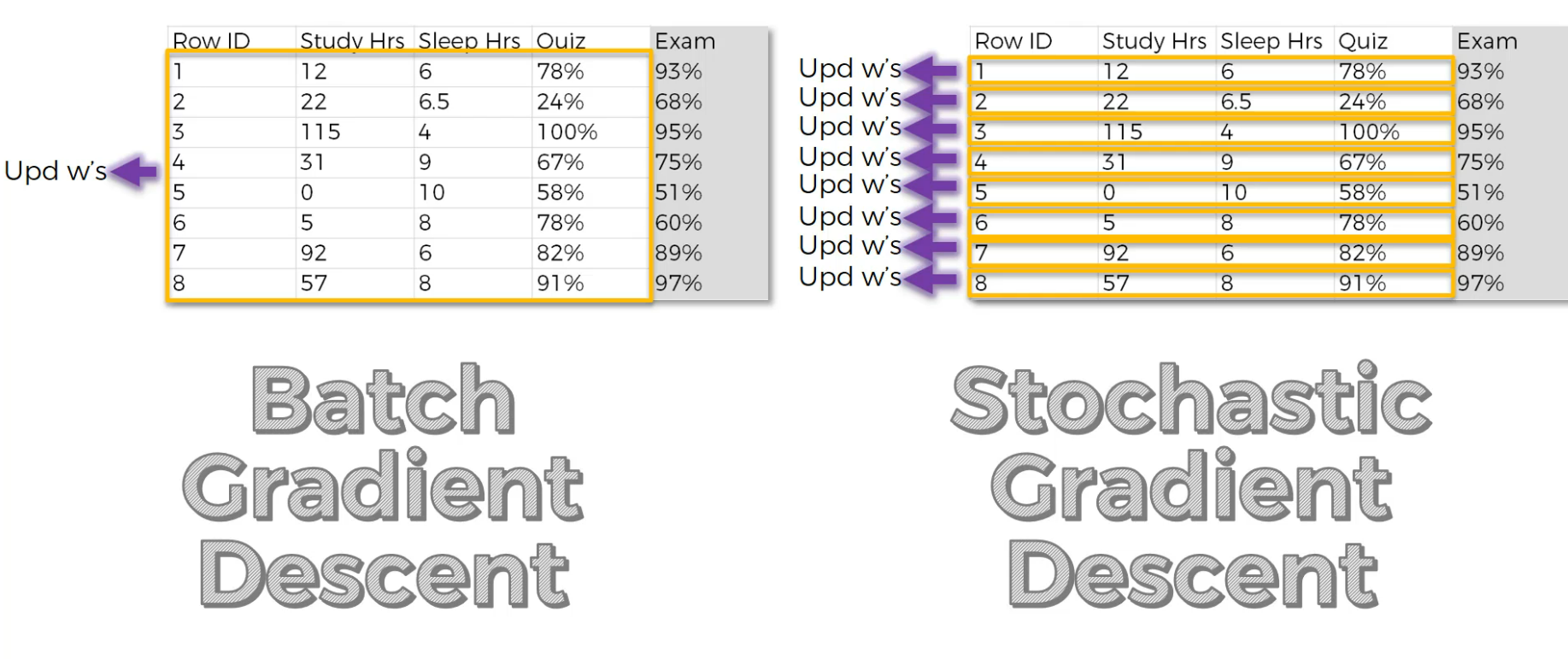
right shows , we update weight every time and in left shows, we update the weights once we run all of the rows.
Stochastic gradient descent is faster.
Read this out to learn more about gradient descent
Back propagation
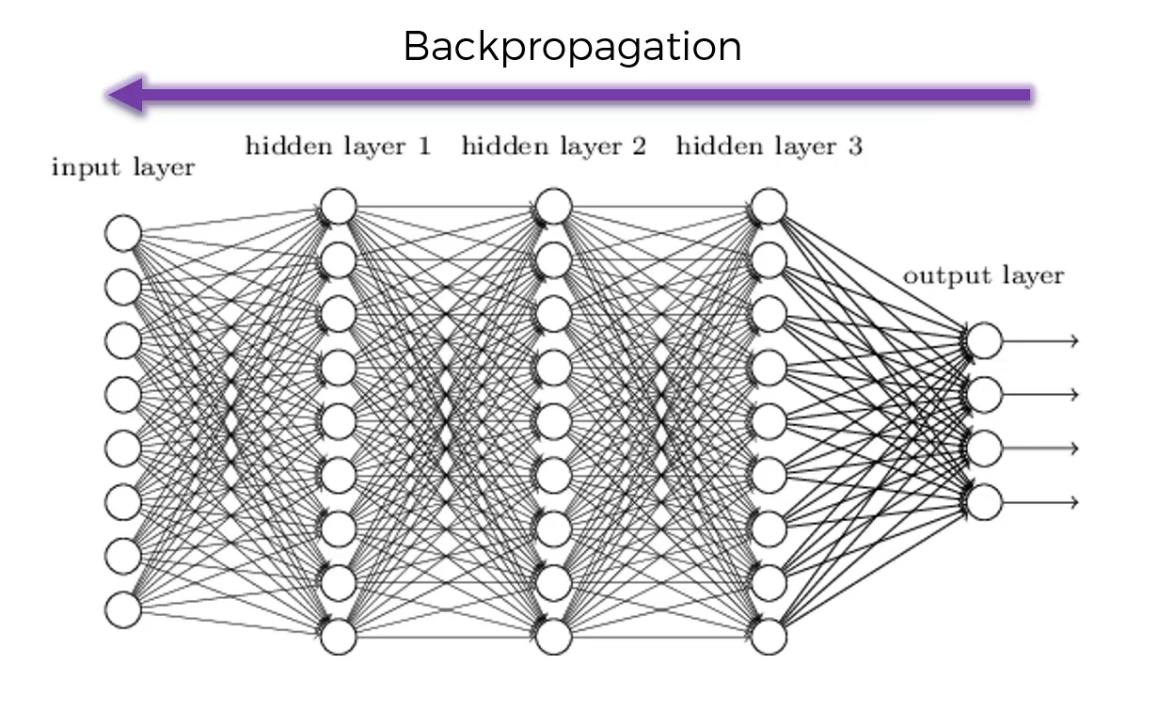
we do it to fine tune the weights

For back propagation, read this
Let's work with the ANN now
Problem statement: We have 10k customers.
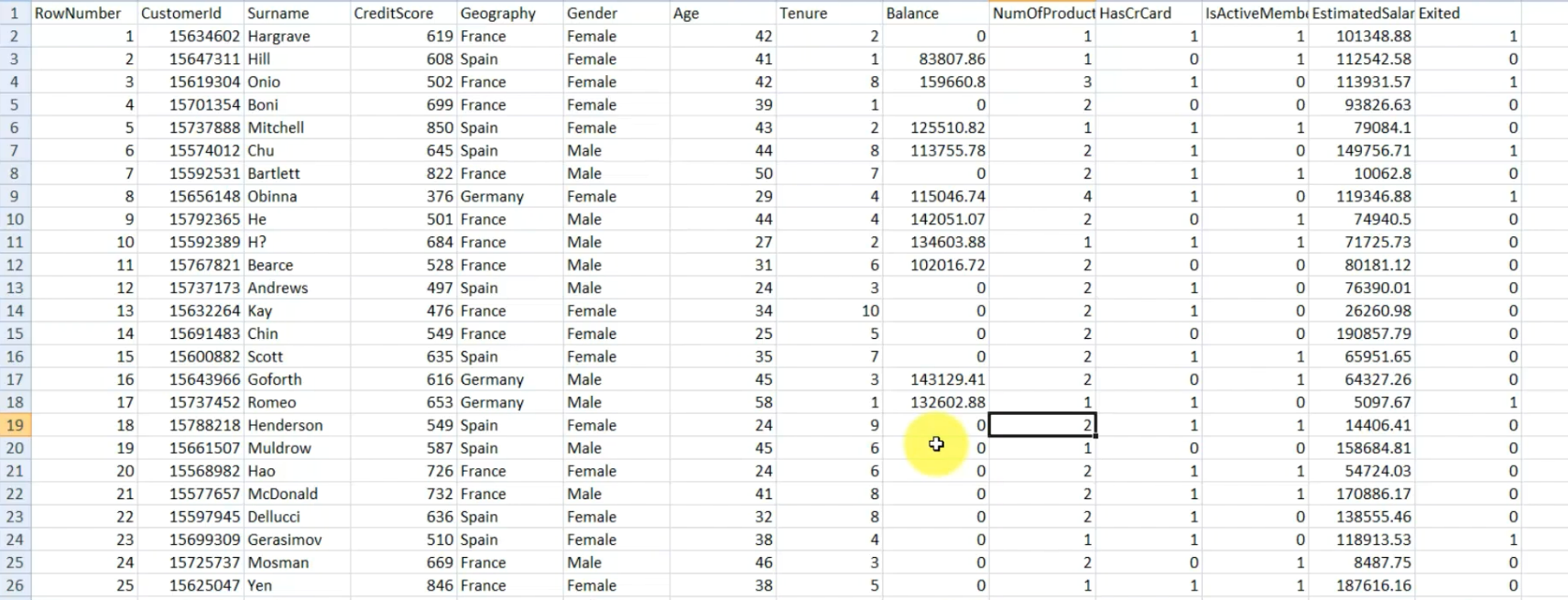
Well, the bank has been seeing unusual churn rates. So churn is when people leave the company and they've seen customers leaving at unusually high rates and they want to understand what the problem is and they want to assess and address that problem. And that's why they've hired you. To look into this dataset for them and give them some insights.
This bank looked in the dataset to see if the customers stayed (Exited = 0) or left (Exited = 1
So, of course, their interest is to keep the maximum customers and therefore they made this data set to understand the reason somehow, why customers leave the bank.
And mostly, once they managed to build a predictive model that can predict if any new customer leaves the bank, you know, model that was trained, of course on this data set, well, they will deploy this model on new customers and for all the customers where the model predicts that the customer leaves the bank, well, in that case they will be prepared and they might do some special offer to the customer so that it will stay in the bank, you see?
Importing the libraries
import numpy as np
import pandas as pd
We are importing Tensorflow for neural networks
import tensorflow as tf #importing tensorflow
Data Preprocessing
dataset =pd.read_csv('Churn_Modelling.csv') #importing the data
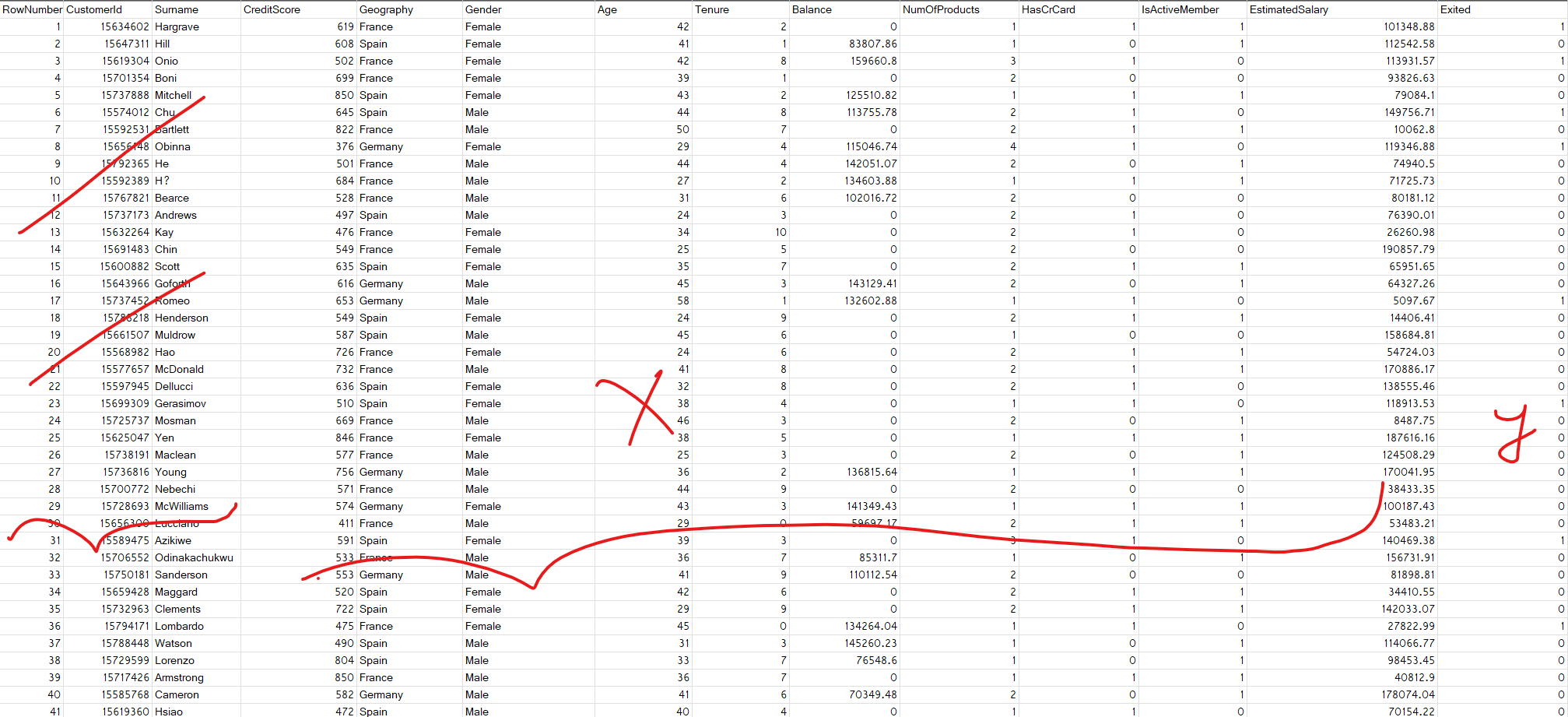
Here RowNumber CustomerId , Surname has no impact on if a user is going to exit or not.
So, we will take all rows but columns from index 3 to (last index -1).
X = dataset.iloc[:,3:-1].values
The last index is going to be used for y matrix
y = dataset.iloc[:,-1].values
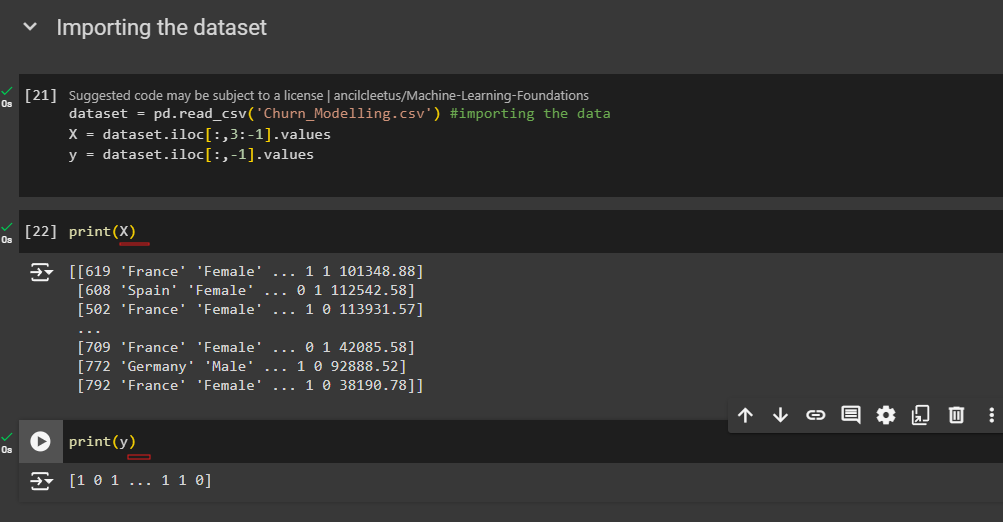
Note: There is no data missing here. So, keep this in mind.
Follow this repository for data preprocessing codes
Let's encode the categorical data (Gender)
from sklearn.preprocessing import LabelEncoder #import
#obect
le = LabelEncoder()
#Gender column is in index 2. So, we will use that column
X[:,2] =le.fit_transform(X[:,2])
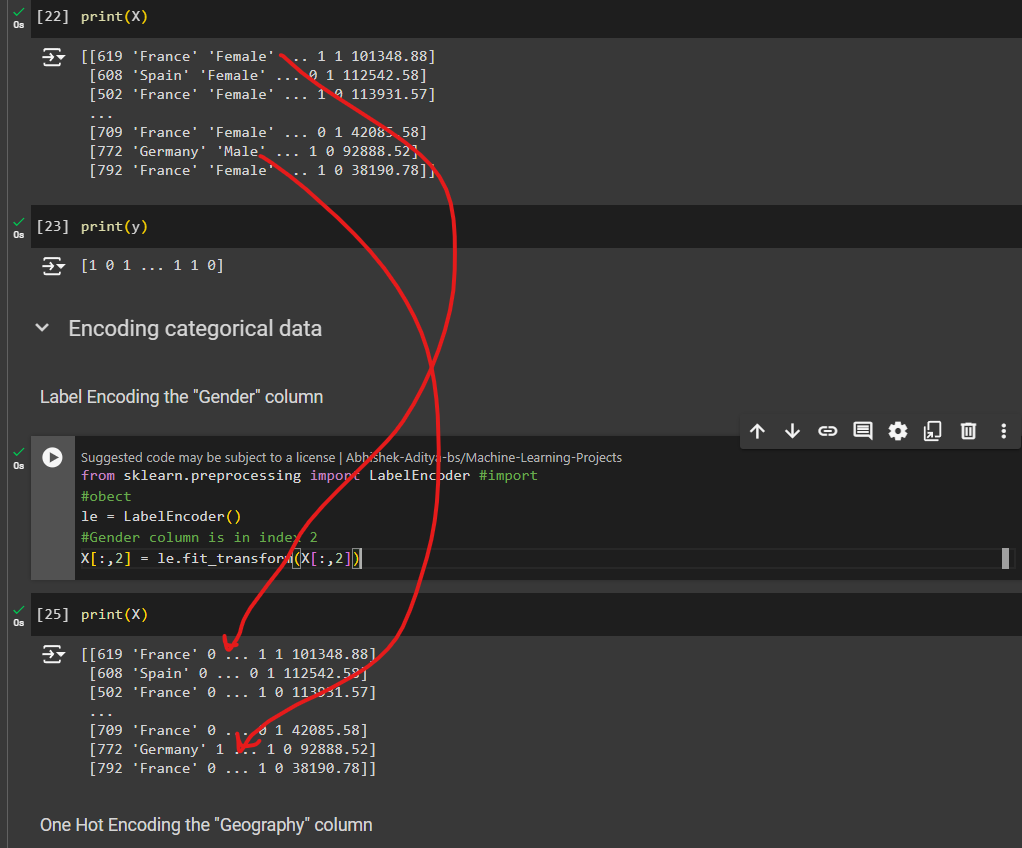
here female turned to 0 and male to 1
For country names we will use onehotencoding
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
We will apply this to column 1 index so use [1]
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])], remainder='passthrough')
X = np.array(ct.fit_transform(X))
once done, the dummy variables have moved to the first column
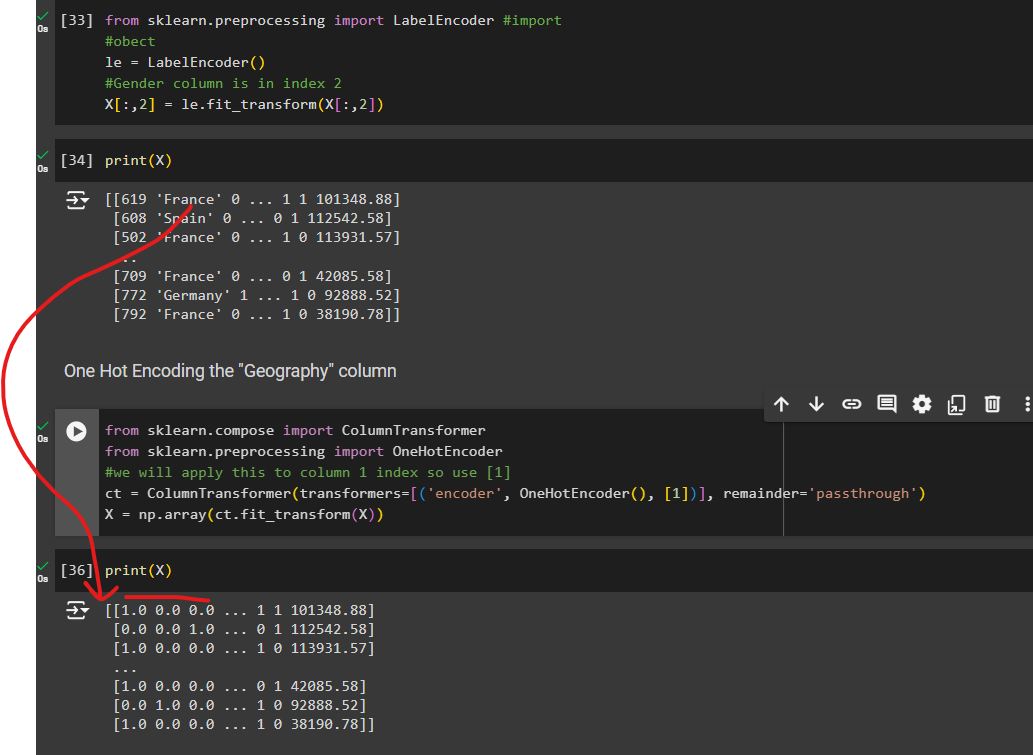
France turned to 1.0 0.0 0.0 and etc.
Then we split our dataset

Feature scaling (must)
We have to apply that to all of our features.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
We will feature scale to all of our features in Neural Network
X_train =sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Building ANN
ANN is a sequence of layers. So, we will create an object of that.
#obect of sequential class
ann = tf.keras.models.Sequential() #initializing the ANN
Adding first input layer
ann.add(tf.keras.layers.Dense(number of neurons, activation function))
we have to experiment how many number of neurons is good.
let's pick 6 neurons
ann.add(tf.keras.layers.Dense(units=6))
in hidden layer, we use rectifier activation function
We use Dense class to keep our neurons fully connected
ann.add(tf.keras.layers.Dense(units=6,activation='relu'))
Second layer
ann.add(tf.keras.layers.Dense(units=6,activation='relu'))
Output layer
ann.add(tf.keras.layers.Dense(units=1,activation='sigmoid'))
In the output layer we use sigmoid activation function and here we just need 1 neuron which can mean (0/1). This number can change as well depending on cases.
Training the ANN
The method to compile is compile()
ann.compile(optimizer, loss function, metrics parameter)
optimizer = 'adam' optimizer which will work with stochastic gradient descent
For binary classification,,
loss = 'binary_crossentropy'
for non-binary ones, we would use
loss = 'category_crossentropy'
Metrics, as I said, we can actually choose several metrics at the same time.
Therefore, in order to enter the values of this parameter well we have to enter them in a pair of square brackets which is supposed to be, you know the list of the different metrics with which you want to evaluate your ANN during the training, but we will only choose the main one. Here, that is accuracy
metrics = ['accuracy']
so, finally
ann.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
Let's run it
we want to do several prediction together . So, in batch. Classical batch size is 32
ann.fit(X, y, batch_size=?, epochs = ?)
You know, a neural network has to be trained over a certain amount of epochs so as to improve the accuracy over time. And we will clearly see that once we execute this cell.
Making the predictions and evaluating the model
Let's assume we have a new customer and now we will use this Neural Network to predict if the customer will leave or remain.
ann.predict([[2D array]])
France means 1.0,0.0, 0.0
Gender should be 1 as male
So, 2d array [[1, 0, 0, 600, 1, 40, 3, 60000, 2, 1, 1, 50000]]
As we scaled our features, we need to use those.
sc.transform use sc for scaling, transform need to be used . We don't need to fit it.
ann.predict(sc.transform([[1, 0, 0, 600, 1, 40, 3, 60000, 2, 1, 1, 50000]]))
as we used sigmoid activation, we will get probability

we get the probability 0.029
let's take a threshold 50% (.5)
if greater than 0.5, we will say true or else leave

Predicting the Test set results
y_pred=ann.predict(X_test) #ann.predict
y_pred=(y_pred>0.5) #if greater than 50% set 1 print(np.concatenate((y_pred.reshape(len(y_pred),1),y_test.reshape(len(y_test),1)),1))
Making the Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy_score(y_test, y_pred)
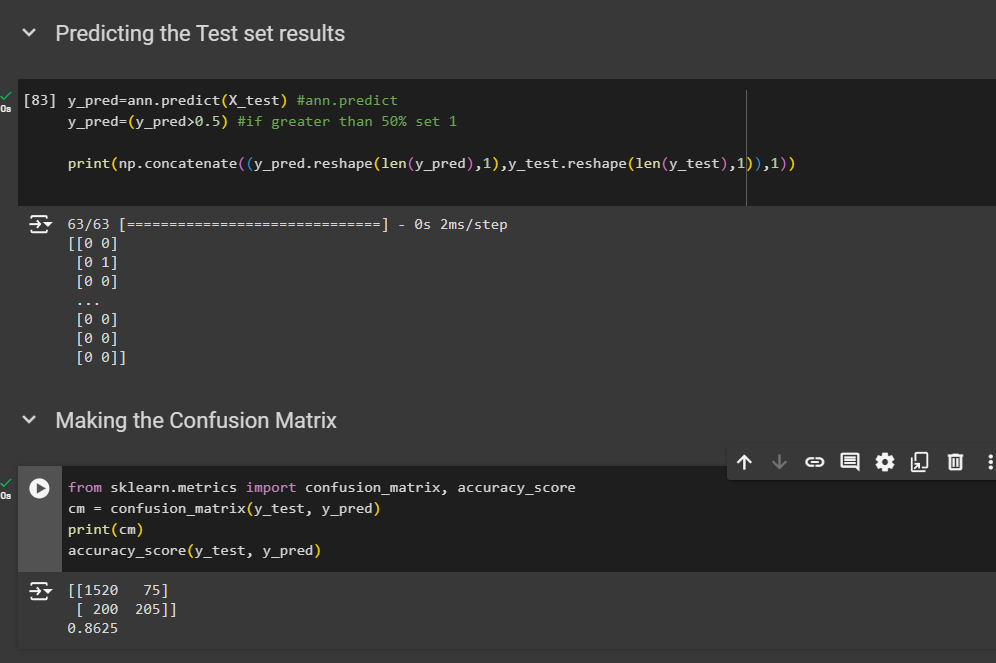
So, we got 86% prediction that folks are not leaving
Implement this code
This is another code to Build an ANN Regression model to predict the electrical energy output of a Combined Cycle Power Plant
Then complete the code
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by