Mastering Vector Embeddings: Search Text, Audio, Video, and Images with Ease
 Damilare Samuel
Damilare Samuel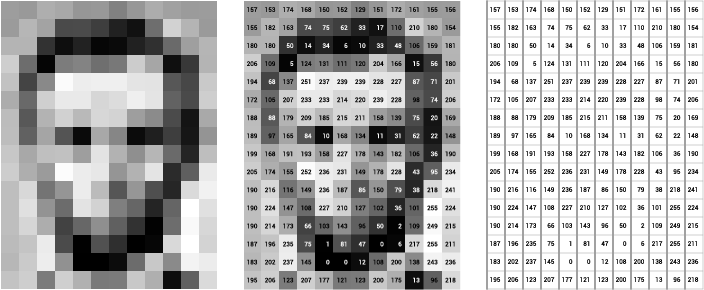
Introduction
Vector embeddings are fundamental in artificial intelligence (AI). Unlike humans, computers cannot process words, text, or images directly. They can only process numbers in binary formats. This is where embeddings come into play. Embeddings convert complex data such as text, images, audio, and videos into numerical representations, enabling machines to understand and process this data.
It is important to understand what embeddings are to appreciate vector embeddings. Embeddings represent high-dimensional data in a lower-dimensional space that captures the meaning, semantics, and relationships between the data. The purpose of this article is to explain how to create vector embeddings for various data types and demonstrate similarity search using Qdrant.
Overall, working with vector embeddings entails:
Choosing an appropriate embedding model for the data type.
Generating embeddings from the raw data.
Storing the embeddings in a vector database (in this guide, we’ll use Qdrant).
Performing similarity searches or other operations on the embeddings.
The Importance of Vector Embeddings
The following advantages of vector embeddings make them a vital tool in many data science and artificial intelligence domains:
Semantic Understanding: Embeddings capture meaning and context, enabling more nuanced analysis.
Feature Extraction: Embeddings automatically learn important features from raw data.
Similarity Comparisons: They allow for efficient similarity calculations between data points.
Transfer Learning: Pre-trained embeddings can be used across different tasks and domains.
Dimensionality Reduction: By using vector embeddings, complicated and high-dimensional data can be represented in a more comprehensible format. Processing and evaluating big collections require this effective representation.
Personalization and Recommendation Systems: Embeddings facilitate the development of complex recommendation systems in e-commerce and content platforms. By seeing trends and preferences in user behavior, they may provide recommendations that are more pertinent and tailored to the individual.
Data Visualization and Clustering: High-dimensional data can be visualized in lesser dimensions using vector embeddings. In exploratory data analysis, where finding clusters and patterns is crucial, this is helpful.
Example 1
# install the model; (this assumes you’re using python) pip install transformers # initialize the model Example 1 with Sentence BERT from transformers import BertModel, BertTokenizer import torch # Load pre-trained model and tokenizer model_name = 'bert-base-uncased' tokenizer = BertTokenizer.from_pretrained(model_name) model = BertModel.from_pretrained(model_name) # Define sentences to embed sentences = ["Hugging Face provides a variety of models for text embeddings.", "BERT is one of the most popular models for generating embeddings."] # Tokenize sentences inputs = tokenizer(sentences, return_tensors='pt', padding=True, truncation=True, max_length=128) # Generate embeddings with torch.no_grad(): outputs = model(**inputs) embeddings = outputs.last_hidden_state # Extract the embeddings for the [CLS] token (representative of the whole sentence) cls_embeddings = embeddings[:, 0, :] print(cls_embeddings)Example 2
from sentence_transformers import SentenceTransformer def get_sbert_embedding(text): # Load the SBERT model model = SentenceTransformer('all-MiniLM-L6-v2') # Generate embedding embedding = model.encode(text) return embedding # Example usage text = "Vector embeddings are fascinating!" embedding = get_sbert_embedding(text) print(f"Sentence-BERT embedding shape: {embedding.shape}")Example 3Example 3
from sentence_transformers import SentenceTransformer # Load the pre-trained model model = SentenceTransformer("infgrad/stella_en_1.5B_v5", trust_remote_code=True).cuda() # Define sentences to embed sentences = [ "Hugging Face provides a variety of models for text embeddings.", "Sentence transformers are optimized for generating high-quality sentence embeddings." ] # Generate embeddings embeddings = model.encode(sentences) # Print the embeddings for sentence, embedding in zip(sentences, embeddings): print(f"Sentence: {sentence}") print(f"Embedding: {embedding[:10]}...") # Display the first 10 dimensions for brevity print()
2. Audio Embeddings
These are audio data. They are the vector embeddings of the signals from the audio that capture the relevant features and characteristics of the audio. Examples of this kind of data include music embeddings, speech embeddings, and so on. Popular embedding models include VGGish and YAMNET.
Creating Audio Embeddings; We can do this using the TensorFlow framework and the YAMNET model.
Example 1
import tensorflow as tf
import tensorflow_hub as hub
# Load the YAMNET model
model = hub.load('https://tfhub.dev/google/yamnet/1')
# Load an audio file
audio, sample_rate = tf.audio.decode_wav(tf.io.read_file('audio_sample.wav'))
audio = tf.squeeze(audio, axis=-1)
# Generate embeddings
scores, embeddings, log_mel_spectrogram = model(audio)
print(f"Audio embedding shape: {embeddings.shape}")
Example 2
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
def get_vggish_embedding(audio_path):
# Load the VGGish model
model = hub.load('https://tfhub.dev/google/vggish/1')
# Load and preprocess audio file
audio, sample_rate = tf.audio.decode_wav(tf.io.read_file(audio_path))
audio = tf.squeeze(audio, axis=-1)
# Ensure audio is the correct length (0.96 seconds)
audio = audio[:int(0.96 * sample_rate)]
if len(audio) < int(0.96 * sample_rate):
audio = tf.pad(audio, [[0, int(0.96 * sample_rate) - len(audio)]])
# Generate embedding
embedding = model(audio)
return embedding.numpy()
# Example usage
audio_path = "sample_audio.wav"
vggish_embedding = get_vggish_embedding(audio_path)
print(f"VGGish embedding shape: {vggish_embedding.shape}")
3. Image Embeddings
They are vector representations of images that capture visual features and semantic information. These embeddings convert image data into numbers for the models. Examples of models that can be used for this task include VGG16, ResNet50, VisualBERT, CLIP, etc.
Creating Image Embeddings: We can create image embeddings using various models such as CLIP, VisualBERT, and so on.
VisualBERT: VisualBERT is a model that understands and performs tasks requiring both visual and textual information. It is trained on datasets that include images alongside written descriptions or questions. It learns about the relationship between an image’s visual content and its textual content. They are also known as multimodal embeddings because, when given a picture and text, VisualBERT generates embeddings that capture both visual and linguistic information.
CLIP: CLIP (Contrastive Language-Image Pretraining) is an OpenAI model capable of understanding both images and text. It learns how to connect visual and textual information. It is trained using a large collection of photos and associated text descriptions. It learns to match images to descriptions and distinguish between various images and words. When you enter a picture or text, CLIP generates a numerical representation of it (embedding). These embeddings can subsequently be utilized to identify similarities between images and texts, as well as to perform image categorization and retrieval.
Example 1
# Implementation from transformers import VisualBertModel, BertTokenizer, VisualBertForQuestionAnswering, VisualBertConfig from transformers import ViTFeatureExtractor from PIL import Image import torch import requests # Load pre-trained VisualBERT model and feature extractor visualbert_model_name = 'uclanlp/visualbert-vqa' feature_extractor_model_name = 'google/vit-base-patch16-224' tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') visualbert_model = VisualBertModel.from_pretrained(visualbert_model_name) feature_extractor = ViTFeatureExtractor.from_pretrained(feature_extractor_model_name) # Load and preprocess the image url = 'https://example.com/path/to/your/image.jpg' image = Image.open(requests.get(url, stream=True).raw) inputs = feature_extractor(images=image, return_tensors="pt") # Tokenize the text input text = "Describe the image" text_inputs = tokenizer(text, return_tensors='pt') # Combine image and text inputs inputs.update(text_inputs) # Generate embeddings with torch.no_grad(): outputs = visualbert_model(**inputs) embeddings = outputs.last_hidden_state print(embeddings)Example 2
# install necessary libraries pip install transformers torchvision ftfy regex tqdm pip install git+https://github.com/openai/CLIP.git # Implementation import torch import clip from PIL import Image import requests # Load the pre-trained CLIP model model, preprocess = clip.load("ViT-B/32") # Load and preprocess the image url = 'https://example.com/path/to/your/image.jpg' image = Image.open(requests.get(url, stream=True).raw) image_input = preprocess(image).unsqueeze(0) # Generate image embeddings with torch.no_grad(): image_features = model.encode_image(image_input) print(image_features)
4. Video Embeddings
They represent the content of video clips in a compact vector form, capturing both spatial and temporal information. In other words, video embeddings turn videos into numbers. In this type of embedding, we have video-frame embeddings and video-sequence embeddings.
Video-frame Embeddings: These represent individual frames or images from videos. Models like VGG16 and ResNet50 can be used.
Video Sequence Embeddings: These represent sequences of video frames. Models like C3D and two-stream can be used.
Example 1
import torch
from torchvision.models.video import r3d_18
from torchvision import transforms
import cv2
def get_i3d_embedding(video_path):
# Load pre-trained I3D model
model = r3d_18(pretrained=True)
model = torch.nn.Sequential(*list(model.children())[:-1])
model.eval()
# Preprocess video
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((112, 112)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.43216, 0.394666, 0.37645], std=[0.22803, 0.22145, 0.216989]),
])
# Load video and extract frames
cap = cv2.VideoCapture(video_path)
frames = []
while len(frames) < 16: # I3D expects 16 frames
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = transform(frame)
frames.append(frame)
cap.release()
# Pad if necessary
if len(frames) < 16:
frames += [frames[-1]] * (16 - len(frames))
# Stack frames and generate embedding
video_tensor = torch.stack(frames).unsqueeze(0).permute(0, 2, 1, 3, 4)
with torch.no_grad():
embedding = model(video_tensor)
return embedding.squeeze().numpy()
# Example usage
video_path = "sample_video.mp4"
i3d_embedding = get_i3d_embedding(video_path)
print(f"I3D embedding shape: {i3d_embedding.shape}")
Example 2
import torch
from torchvision.models.video import c3d
from torchvision import transforms
import cv2
def get_c3d_embedding(video_path):
# Load pre-trained C3D model
model = c3d(pretrained=True)
model = torch.nn.Sequential(*list(model.children())[:-1])
model.eval()
# Preprocess video
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((112, 112)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.43216, 0.394666, 0.37645], std=[0.22803, 0.22145, 0.216989]),
])
# Load video and extract frames
cap = cv2.VideoCapture(video_path)
frames = []
while len(frames) < 16: # C3D expects 16 frames
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = transform(frame)
frames.append(frame)
cap.release()
# Pad if necessary
if len(frames) < 16:
frames += [frames[-1]] * (16 - len(frames))
# Stack frames and generate embedding
video_tensor = torch.stack(frames).unsqueeze(0).permute(0, 2, 1, 3, 4)
with torch.no_grad():
embedding = model(video_tensor)
return embedding.squeeze().numpy()
# Example usage
video_path = "sample_video.mp4"
c3d_embedding = get_c3d_embedding(video_path)
print(f"C3D embedding shape: {c3d_embedding.shape}")
Storing Embeddings in Qdrant
What Is Qdrant?
Qdrant is a vector similarity engine, an open-source database, or simply put, a tool that helps us store, manage, and search for vector embeddings efficiently. It can be used in various AI applications and sectors such as e-commerce, healthcare, education, semantic analysis, and so on.
What is Similarity Search?
This is quite important for machines as it is a powerful way for them to find the most similar vectors to a query vector. This is particularly useful in recommendation systems, search engines, semantic analysis, and so on.
Similarity search measures for vector embeddings using these methods:
Cosine Similarity
Euclidean Distance
Dot Product
# Setting Up Qdrant
This can be done using Docker.
docker pull qdrant/qdrant
docker run -p 6333:6333 qdrant/qdrant
Inserting Embeddings into Qdrant
This can be done using the Qdrant Python client.
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, PointStruct
client = QdrantClient("localhost", port=6333)
# Create a collection
client.recreate_collection(
collection_name="my_embeddings",
vectors_config=VectorParams(size=768, distance="Cosine")
)
# Insert embeddings
client.upsert(
collection_name="my_embeddings",
points=[
PointStruct(id=1, vector=embedding1.tolist(), payload={"text": "Sample text 1"}),
PointStruct(id=2, vector=embedding2.tolist(), payload={"text": "Sample text 2"}),
]
)
Conclusion
Vector embeddings have revolutionized how we process and understand data, and there will only be more improvement as the world of AI evolves. In this article, you learned what vector embeddings are, the different types, and how they are created. We demonstrated how to store different types of vector embeddings in Qdrant and showed how to perform similarity searches using Qdrant. These techniques enable AI applications like search engines, recommendation systems, educational apps, etc. By mastering the techniques used in creating and using vector embeddings across different data types, you’ll be well-equipped to tackle a wide range of modern machine learning and information retrieval (IR) tasks.
Note: This article was first published on Medium.
References
Subscribe to my newsletter
Read articles from Damilare Samuel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Damilare Samuel
Damilare Samuel
Senior Python Developer | AI Researcher | Tech Instructor & Mentor Passionate about leveraging the power of AI and Python to solve complex problems. Dedicated to teaching and mentoring the next generation of tech enthusiasts. Always exploring new innovations and sharing knowledge. Follow me for more insights and tutorials on AI, Python, and tech trends.