Exploring Retrieval-Augmented Generation (RAG) using Large Language Models
 Varun Vij
Varun Vij
Recently, I explored the world of Retrieval-Augmented Generation (RAG) and was amazed by its potential to enhance Large Language Models (LLMs). RAG is a method that combines retrieval systems with the generative power of LLMs, creating a robust tool for generating accurate and contextually relevant responses.
Why RAG Matters
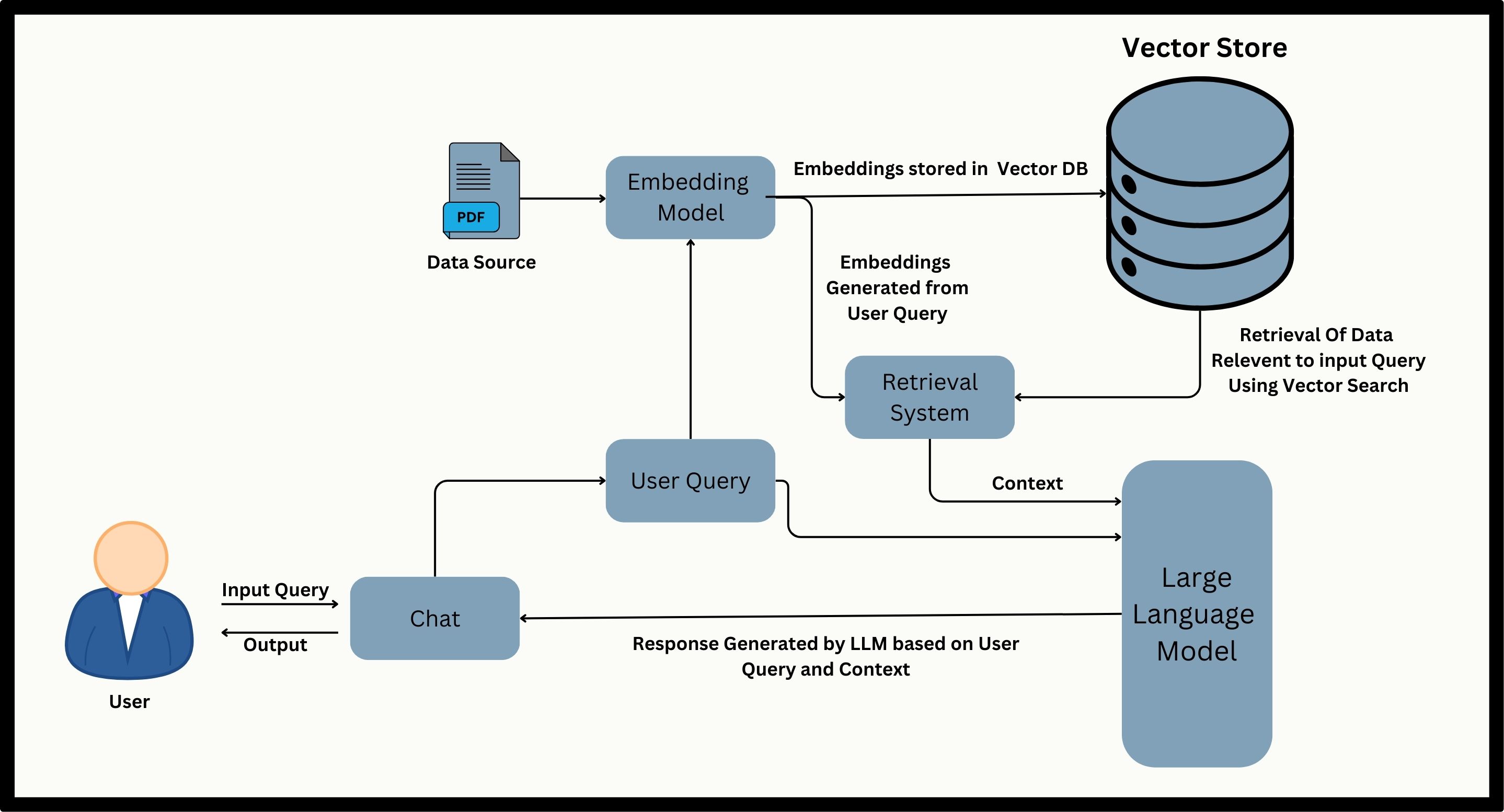
RAG enhances traditional LLMs by integrating retrieval mechanisms. This approach allows RAG to access extensive external knowledge sources, retrieve relevant information, and incorporate it into its responses. As a result, RAG produces answers that are more precise and contextually relevant, making LLMs more effective and versatile.
The significance of RAG lies in its ability to address some inherent limitations of traditional LLMs. While LLMs are robust, they often rely on static training data that may become outdated. RAG dynamically retrieves current information from external sources, ensuring that responses are both up-to-date and contextually accurate. This capability is particularly beneficial for tasks requiring specific and recent knowledge that an LLM alone might lack.
In this blog, I will share what I’ve learned about RAG and how it can be applied effectively. I’ll walk you through a project where I used RAG principles with Langchain and other tools to build a system for processing PDF documents and retrieving information from a vector store. This project demonstrates the real-world benefits of RAG.
Implementing RAG with Langchain
Objective: To develop a system capable of extracting information from PDF documents and providing accurate, contextually relevant answers to user queries through conversational interaction.
Technologies:
Langchain: A versatile framework for building language model applications, and managing prompts, chains, and agents.
Google Palm Embeddings: Used to generate numerical representations (embeddings) of text chunks for efficient similarity search.
FAISS: A library optimized for searching and clustering high-dimensional vectors, essential for finding relevant information within the embedding space.
Streamlit: A rapid application development framework for creating user-friendly interfaces.
Workflow:
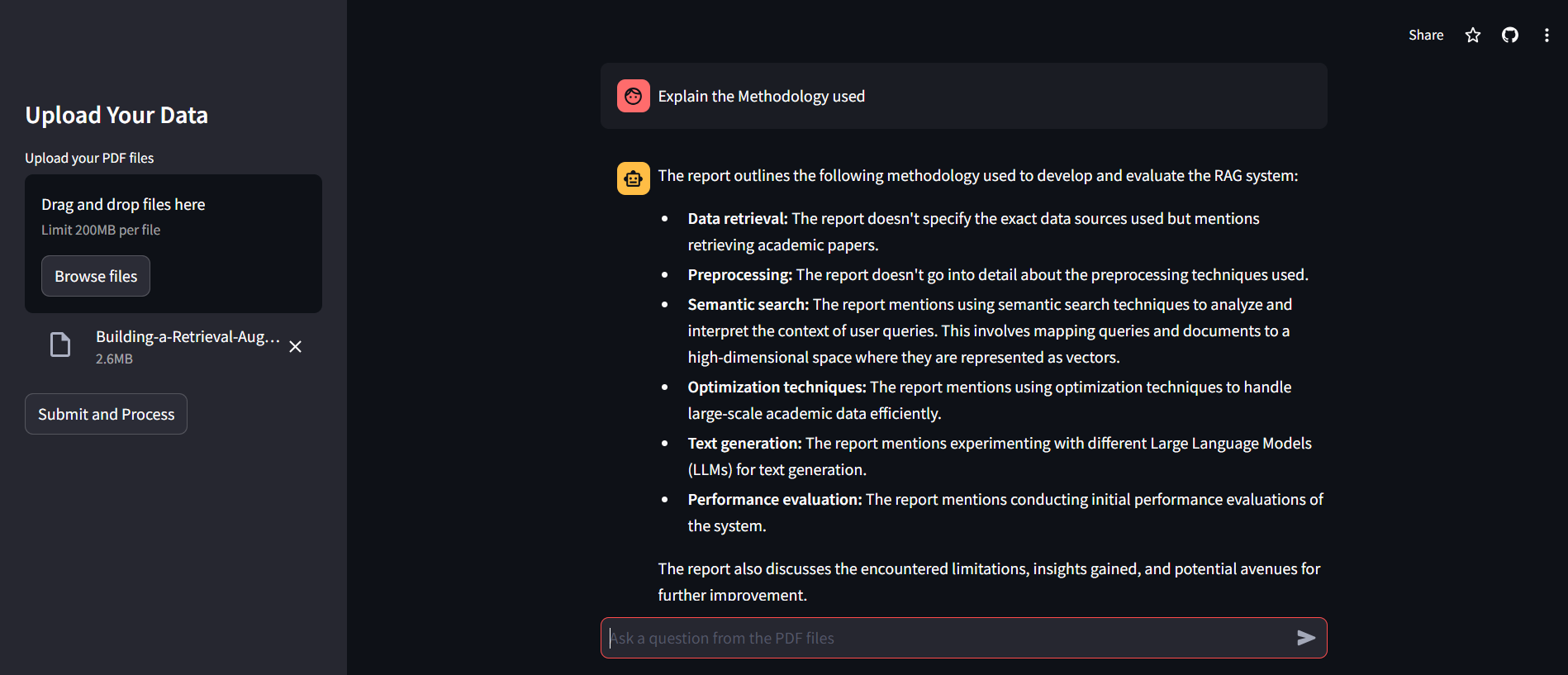
Document Upload: Users can upload one or multiple PDF files to the system via the Streamlit interface.
Text Extraction: PDF content is processed to extract textual information using the pdfplumber library.
Text Chunking: The extracted text is divided into smaller, manageable chunks to facilitate efficient embedding generation.
Embedding Creation: Google Palm Embeddings are generated for each text chunk to create numerical representations.
Vector Store Creation: Embeddings are stored in a FAISS vector store for fast similarity search.
Conversational Retrieval: A Langchain-based conversational retrieval chain is established. This chain enables the system to retrieve relevant information from the vector store based on user queries and generate informative responses.
Combining these technologies and following the outlined workflow, the system effectively transforms PDF documents into a searchable knowledge base that can be queried through natural language conversations.
Detailed Code Walkthrough
This section dives into the code that powers the conversational retrieval system. We'll explore the key functionalities implemented in app.py and helper.py. You can get the complete code on my GitHub.
App Structure
The project is divided into two main files:
app.py: This file handles the user interface and interactions using Streamlit.helper.py: This file contains the core functions for processing PDFs, generating embeddings, and setting up the retrieval system.
Uploading and Processing PDF Files
In
app.py, users can upload their PDF documents using Streamlit's file uploader widget. Once the files are uploaded, they are processed to extract text.with st.sidebar: st.title("Upload Your Data") pdf_docs = st.file_uploader("Upload your PDF files", accept_multiple_files=True) if st.button("Submit and Process"): if pdf_docs: with st.spinner("Processing...."): vector_store = process_in_parallel(pdf_docs) st.session_state.conversation = get_conversationalchain(vector_store) st.success("Processing Complete") else: st.warning("Please upload PDF files.")The
process_pdfs_to_vector_storefunction inhelper.pyhandles the extraction of text from PDF documents and places it in a vector store.def process_pdfs_to_vector_store(pdf_docs): all_text_chunks = [] for pdf_doc in pdf_docs: text = get_pdf_text(pdf_doc) text_chunks = get_text_chunks(text) all_text_chunks.extend(text_chunks) vector_store = get_vector_store(all_text_chunks) return vector_storedef get_pdf_text(pdf_doc): text = "" with pdfplumber.open(pdf_doc) as pdf: for page in pdf.pages: text += page.extract_text() return text def get_text_chunks(text): text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20) chunks = text_splitter.split_text(text) return chunks
Creating the Vector Store
The extracted text is chunked using the RecursiveCharacterTextSplitter class, and embeddings for these chunks are generated using Google Palm Embeddings. These embeddings are then stored in a FAISS vector store.
def get_vector_store(text_chunks):
embeddings = GooglePalmEmbeddings()
vector_store = FAISS.from_texts(text_chunks, embedding=embeddings)
return vector_store
Setting Up the Conversational Chain
The conversational retrieval chain is established using the Langchain library. This setup allows the system to handle user queries and provide relevant responses by retrieving information from the vector store.
def get_conversational_chain(vector_store):
llm_model = ChatGoogleGenerativeAI(model='gemini-1.5-flash')
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversational_chain = ConversationalRetrievalChain.from_llm(llm=llm_model, retriever=vector_store.as_retriever(), memory=memory)
return conversational_chain
User Interaction and Chat Interface
The user interface in app.py allows users to input their queries, which are then processed by the conversational retrieval chain. The responses are displayed in a chat-like interface.
# Capture the user's question input from the chat input box
user_question = st.chat_input("Ask a question from the PDF files")
# Check if the user has entered a question
if user_question:
# Append the user's question to the session state's message list
st.session_state.messages.append({"role": "user", "content": user_question})
# Display the user's question in the chat interface
with st.chat_message("user"):
st.markdown(user_question)
# Check if there is an active conversation session
if st.session_state.conversation:
# Invoke the conversation object with the user's question
response = st.session_state.conversation.invoke({'question': user_question})
chat_history = response['chat_history']
# Format the chat history for display
formatted_chat_history = []
for message in chat_history:
if hasattr(message, 'content'):
# Determine the role of the message (user or assistant)
role = 'user' if message.__class__.__name__ == 'HumanMessage' else 'assistant'
formatted_chat_history.append({"role": role, "content": message.content})
Modifications and Improvements
To enhance this approach, consider the following additions and modifications:
Optimize Text Extraction and Chunking: Use efficient libraries and adjust chunk sizes for better performance.
Implement Distributed Processing: Utilize frameworks like Apache Spark or Dask to handle large-scale data more effectively.
Enhance User Interface: Add features like progress indicators, query autocomplete, and response feedback for a better user experience.
Support Multiple Document Types: Allow for various document formats and integrate additional APIs for broader data access.
Adopt Advanced Language Models: Use models like GPT-4 and custom embeddings to boost retrieval accuracy and overall effectiveness.
Conclusion
Retrieval-Augmented Generation (RAG) is a powerful method that significantly improves the performance of traditional LLMs by incorporating real-time information retrieval. This combination makes it possible to generate more accurate and relevant responses, especially for queries requiring up-to-date knowledge. RAG enhances the usefulness of LLMs in a variety of applications, providing more precise and context-aware interactions.
Those interested in exploring this approach further can find the complete code and details of my project on my GitHub.
Subscribe to my newsletter
Read articles from Varun Vij directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Varun Vij
Varun Vij
Hi there! I'm Varun, a dedicated professional in data science and AI. I began with Python, mastering data manipulation, analysis, and machine learning. My expertise extends to deep learning with TensorFlow and Keras, and I've worked on predictive analytics, computer vision, and NLP projects. I also excel in front-end development with the MERN stack and Next.js, enabling me to create interactive data visualizations and user-friendly interfaces. Additionally, I've developed blockchain prototypes and AI-driven applications, leveraging advanced tools for intelligent document querying and scalable web app development. Let's connect and explore the possibilities of data together!