How to Build an Image Caption Generator App Using AI with HuggingFace and Gemini
 Shivam Katare
Shivam Katare
AI is changing our daily lives, helping with many tasks and sparking new ideas. Today, we're joining this trend to start an exciting project. In this tutorial, I'll show you how to build an AI Image Captioner – a tool that uses the HuggingFace Model and Google Gemini.
By the end of this tutorial, you'll have created an AI app that makes realistic, human-like captions for images, showing the amazing power of AI.
Let's begin!
Project Setup
Create Next JS Project
First, let's set up our Next.js project with TypeScript, Tailwind, and Shadcn UI. Open your terminal and run:
yarn create next-app@latest image-captioner --typescript --tailwind --eslint
Run the shadcn-ui init command to setup your project:
npx shadcn-ui@latest init
You will be asked a few questions to configure components.json:
Which style would you like to use? › Default
Which color would you like to use as base color? › Slate
Do you want to use CSS variables for colors? › no / yes
This command creates a new Next.js project with TypeScript, Shadcn, and Tailwind support.
We will use a few components from Shadcn later, so you can download all of them by running the following command:
npx shadcn-ui@latest add card switch slider label button
Install Dependencies
Our app requires several packages, so now we'll install them by running the following commands:
react-dropzone: For handling file uploads.
yarn add react-dropzoneHuggingFace Inference: To convert images to text descriptions.
yarn add @huggingface/inferenceGoogle Generative AI: For generating creative captions based on the image description.
yarn add @google/generative-aireact-hot-toast: For displaying notifications.
yarn add react-hot-toast
Setup Environment variables
When building applications that interact with external APIs or contain sensitive information, it's crucial to use environment variables. This practice enhances security and makes your application more configurable across different environments (development, staging, production).
For our AI Image Captioner app, we need to set up environment variables for the Hugging Face and Google Gemini API keys.
Next.js has built-in support for environment variables. Here's how to set them up:
Create a file named
.env.localin the root of your project.Add your API keys to this file:
NEXT_PUBLIC_HF_ACCESS_TOKEN="your_huggingface_token_here" NEXT_PUBLIC_GEMINI_API_KEY="your_gemini_api_key_here"
Steps to Get a Hugging Face Token
Visit the Hugging Face website: https://huggingface.co/
If you don't have an account, click on "Sign Up" to create one.
If you do, click "Login."Once logged in, click on your profile picture in the top-right corner.
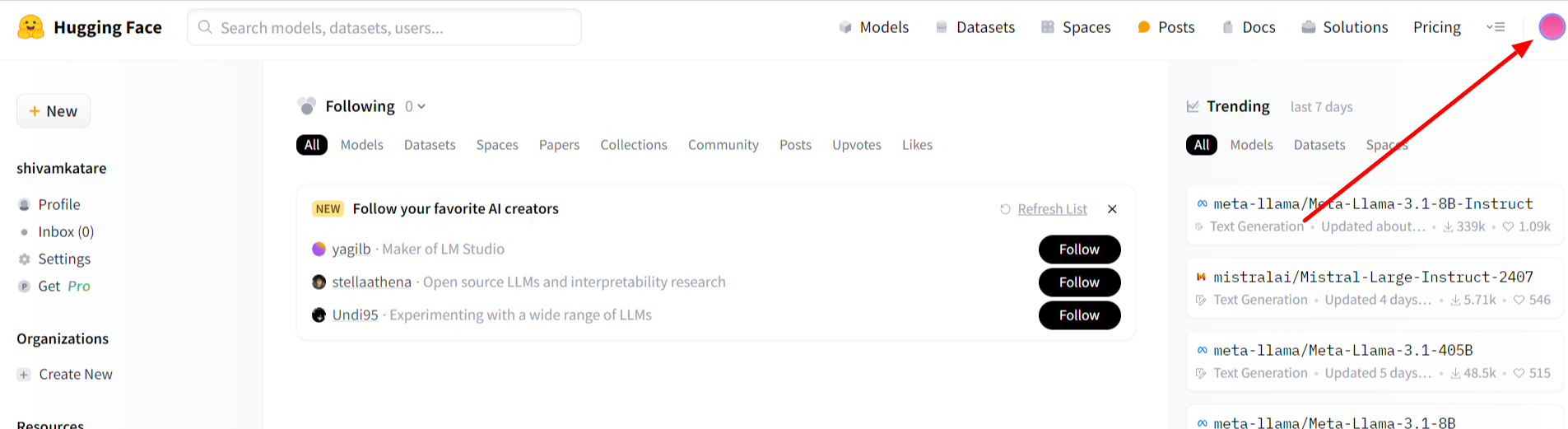
From the dropdown menu, select "Settings."In the left sidebar, click on "Access Tokens."
Click on the "New token" button.
Give your token a name (e.g., "AI Image Captioner") and select the appropriate permissions(You can give more permission as per your need).
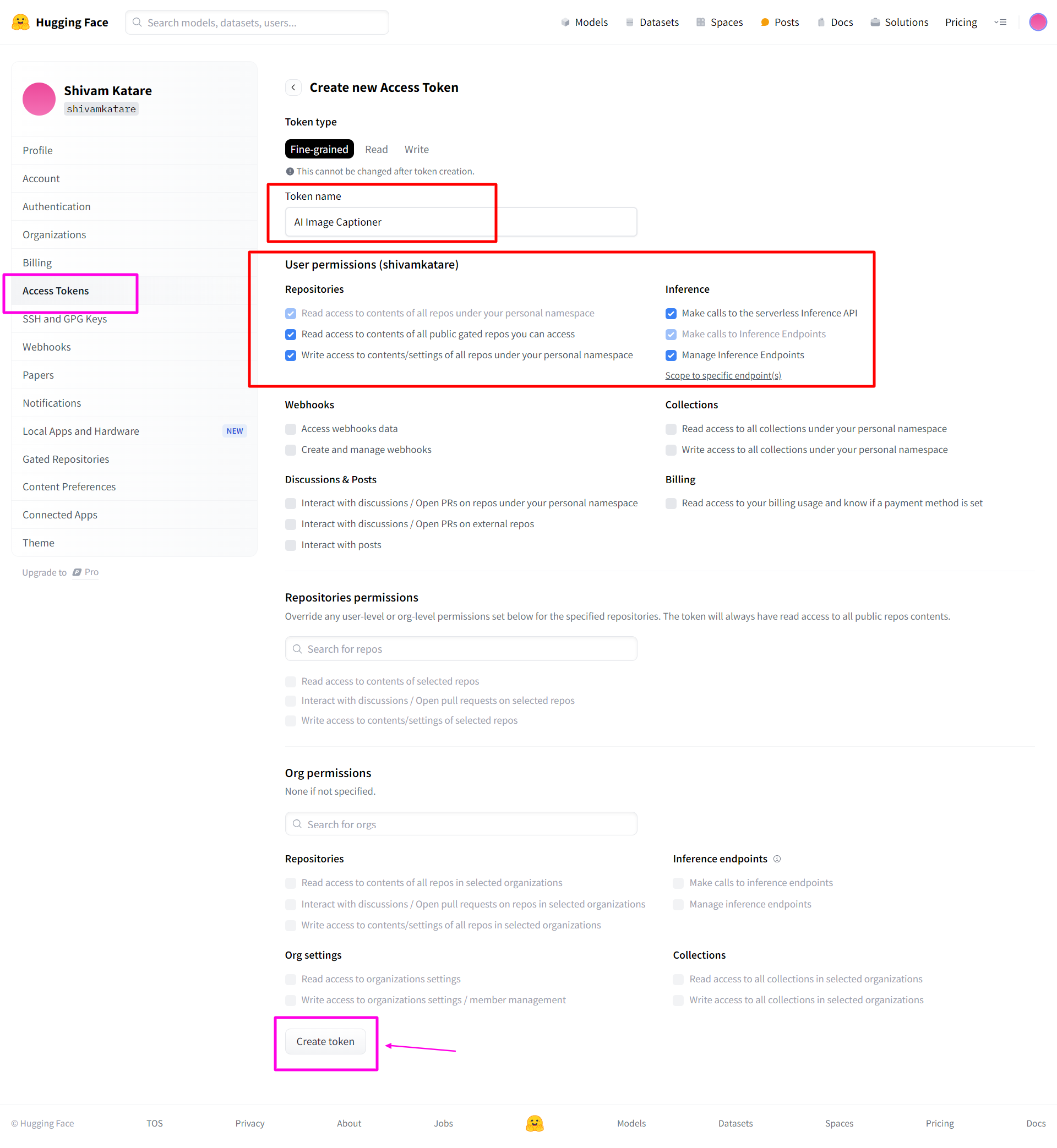
Click "Generate a token."Copy the generated token immediately". This is the only time you'll see it in full(Make sure to save it somewhere safe).
Steps to get Gemini Key
Go to the Google AI Studio website here
If you're not already signed in to a Google account, you'll be prompted to do so.
Once signed in, you should see a page titled "API keys."
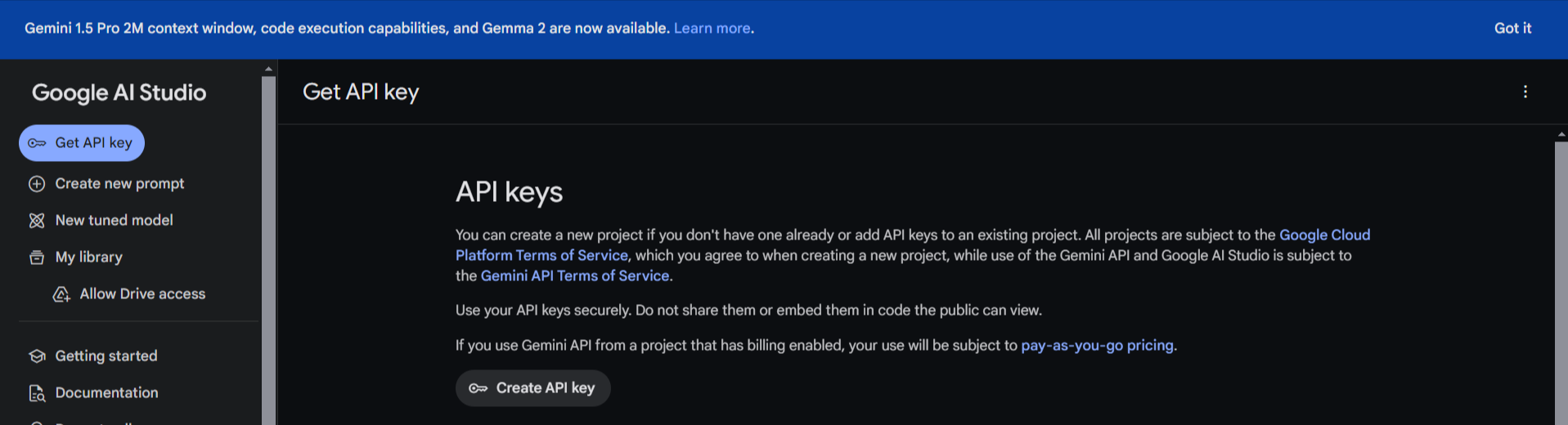
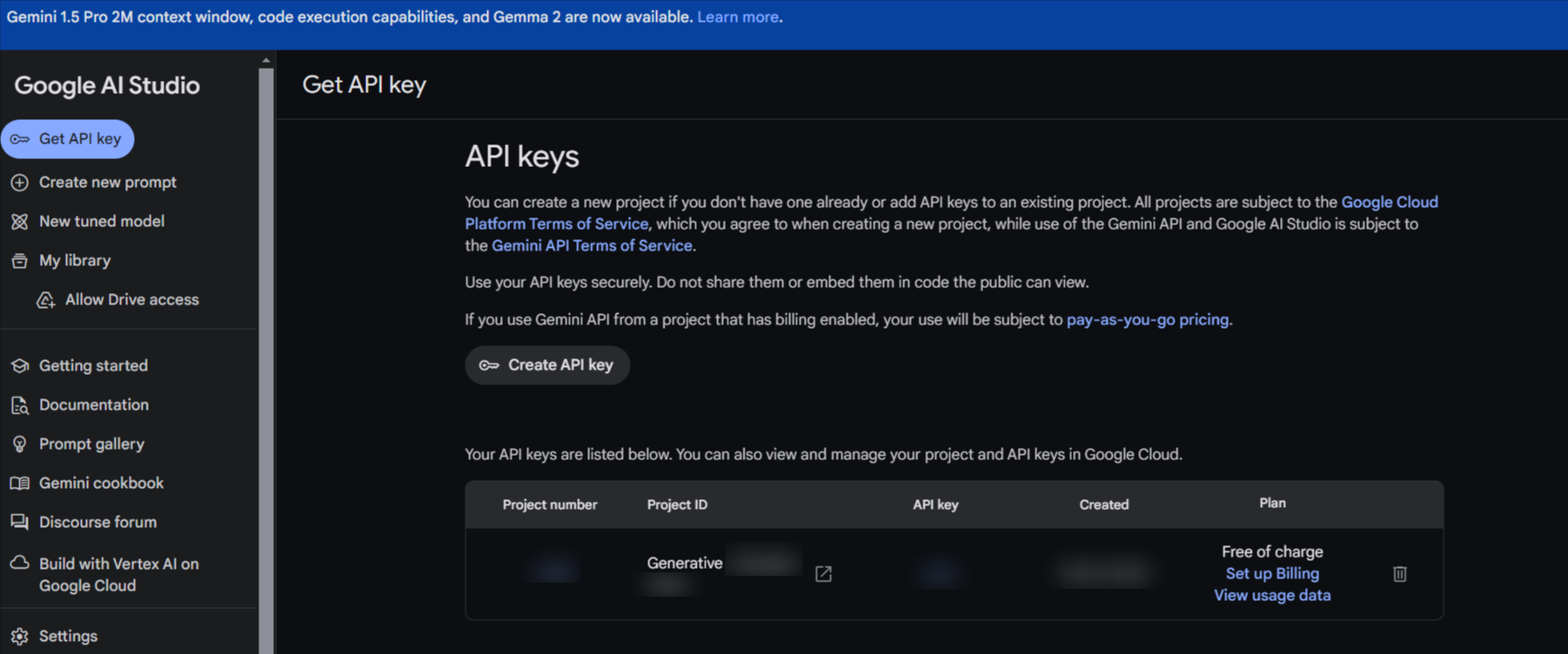
Click on the "Create API key" button.
A new API key will be generated. Copy this key immediately
You can also give your API key a name for easier management.
HuggingFace Overview
Hugging Face is a company that has built a platform offering a variety of pre-trained models for natural language processing (NLP) tasks such as text generation, translation, sentiment analysis, and more. Hugging Face offers several libraries and tools like:
Datasets
Transformers
Tokenizers
Hugging Face Hub etc

But, today we are going to focus on Transformers Library. Their transformers library provides access to LLM models and makes it easy to integrate them into our applications.
In simple terms, You can think of Hugging Face as a platform similar to npm, but specifically for large language models (LLMs) and other machine learning models. Just like npm is a package manager for JavaScript libraries and tools, Hugging Face provides a repository and tools for accessing, sharing, and managing machine learning models and datasets.
Gemini Overview

Google Gemini is a group of advanced AI models that can understand and process different types of information like text, code, audio, images, and video. Created by Google DeepMind, it works well on devices ranging from smartphones to powerful data centers. Gemini is designed to be a versatile AI assistant, helping with creative tasks, research, and productivity.
Building the Image Captioner Component
Let's create our main ImageCaptioner component. We'll break it down into sections:
File Upload with react-dropzone
We use react-dropzone to handle file uploads. It provides a simple interface for drag-and-drop or click-to-upload functionality.
import React from 'react'
function ImageCaptioner() {
const onDrop = useCallback((acceptedFiles: File[]) => {
if (acceptedFiles && acceptedFiles[0]) {
setImage(acceptedFiles[0]);
}
}, []);
const { getRootProps, getInputProps, isDragActive } = useDropzone({
onDrop,
accept: {
'image/png': ['.png'],
'image/jpeg': ['.jpg', '.jpeg'],
}
});
return (
<div>Caption</div>
)
}
export default ImageCaptioner
Here, we set up a callback function called onDrop that springs into action when a file is uploaded. It checks if there's a valid file and, if so, sets it as our image. We then use the useDropzone hook to configure our upload area.
We tell it to use our onDrop function and specify that we only want to accept PNG and JPEG images – no surprises for our image captioning algorithm! The hook gives us some helpful properties like getRootProps and getInputProps, which we'll use to build our actual dropzone UI.
While our current return statement is just a placeholder, in the final version, we'll use these properties to create an interactive area where users can drag and drop their images or click to select a file. It's all about making the upload process as smooth as possible for our users!
Image to Text with HuggingFace
To create captions from an image, we need to use an AI model that reads images and converts them into text. For this, we'll use one of the HuggingFace model called blip-image-captioning-large. Now, to convert our images into text, we'll write a function to handle this task. First, let's define a few state variables.
const [image, setImage] = useState<File | null>(null);
const [captions, setCaptions] = useState<string[]>([]);
const [loading, setLoading] = useState<boolean>(false);
Image state to set the images
Captions for setting up the captions
and, loading will deal with loading states
Now let's define a function.
const generateCaption = async () => {
if (!image) return;
setLoading(true);
try {
const hf = new HfInference(process.env.NEXT_PUBLIC_HF_ACCESS_TOKEN);
const result = await hf.imageToText({
model: 'Salesforce/blip-image-captioning-large',
data: image,
});
const initialCaption = result.generated_text;
} catch (error) {
toast.error('Error generating captions. Please try again.');
setCaptions([]);
} finally {
setLoading(false);
}
};
The function
generateCaptionfirst checks if there's an image to work with. If not, it returns. If there is an image, it proceeds.The function then sets
setLoading(true)to show it's work in progress.Next, it uses HfInference to analyze the image. It will use our HuggingFace token to work. Make sure to import
HfInferenceimport { HfInference } from '@huggingface/inference';The AI looks at the image using a model
Salesforce/blip-image-captioning-largeto describe the imageThen, it generates an image and data will store in
initialCaptionvariable.If there's an error, the function shows an error message.
Finally, the function sets
setLoading(false)to show it's done.
Now, this function and model are only capable of describing the image. This means if you use this function as it is, you'll only get a brief description of the image, which we can't really call a caption. To create captions with different tones, languages, and variations, we will now use Gemini.
Caption Generation with Google Gemini
Now, create a function called generateCaptionVariants (or any name that suits you best) which will take an initialCaption string as a parameter. This initialCaption will come from our previous function. Before that, add more state variables.
const [tone, setTone] = useState<string>('Neutral');
const [useHashtags, setUseHashtags] = useState<boolean>(false);
const [useEmojis, setUseEmojis] = useState<boolean>(false);
const [language, setLanguage] = useState<string>('English');
const [variants, setVariants] = useState<number>(1)
Now define a function.
const generateCaptionVariants = async (initialCaption: string) => {
const API_KEY = process.env.NEXT_PUBLIC_GEMINI_API_KEY;
if (!API_KEY) {
toast.error("Gemini API key is not set");
}
const genAI = new GoogleGenerativeAI(API_KEY || '');
const model = genAI.getGenerativeModel({ model: "gemini-pro" });
const prompt = `Generate ${variants} ${tone.toLowerCase()} captions in ${language} based on the following image description. ${useHashtags ? 'Include relevant hashtags.' : ''} ${useEmojis ? 'Include appropriate emojis.' : ''} Keep each caption concise and engaging.
Initial caption: "${initialCaption}"
Please provide the captions in a numbered list format.`;
try {
const result = await model.generateContent(prompt);
const response = result.response;
const generatedText = response.text();
const variantCaptions = generatedText.split('\n')
.filter(line => line.trim().match(/^\d+\./))
.map(line => line.replace(/^\d+\.\s*/, '').trim());
return variantCaptions;
} catch (error) {
toast.error('Error generating captions. Please try again. Or use your Huggingface Token.');
}
};
const generateCaptionVariants = async (initialCaption: string) => {
// Code here
};
Here's what it does step by step:
- It first checks for the Gemini API key:
const API_KEY = process.env.NEXT_PUBLIC_GEMINI_API_KEY;
if (!API_KEY) {
toast.error("Gemini API key is not set");
}
If the API key isn't set, it shows an error message.
- It then sets up the Gemini AI model:
const genAI = new GoogleGenerativeAI(API_KEY || '');
const model = genAI.getGenerativeModel({ model: "gemini-pro" });
This creates an instance of the Gemini AI model that we'll use to generate captions. googleGenerativeModel you need to import it:import { GoogleGenerativeAI } from "@google/generative-ai";
- Add a prompt for the AI:
const prompt = `Generate ${variants} ${tone.toLowerCase()} captions in ${language} based on the following image description. ${useHashtags ? 'Include relevant hashtags.' : ''} ${useEmojis ? 'Include appropriate emojis.' : ''} Keep each caption concise and engaging.
Initial caption: "${initialCaption}"
Please provide the captions in a numbered list format.`;
This prompt tells the AI what kind of captions to generate, including the number of variants, tone, language, and whether to include hashtags or emojis.
- It then tries to generate content using this prompt:
try {
const result = await model.generateContent(prompt);
const response = result.response;
const generatedText = response.text();
const variantCaptions = generatedText.split('\n')
.filter(line => line.trim().match(/^\d+\./))
.map(line => line.replace(/^\d+\.\s*/, '').trim());
return variantCaptions;
} catch (error) {
toast.error('Error generating captions. Please try again. Or use your Huggingface Token.');
}
Here's what this part does:
It sends the prompt to the AI model and waits for a response.
It takes the generated text and splits it into lines.
It filters these lines to only keep those that start with a number (like "1.", "2.", etc.).
It then removes the numbers and any leading/trailing spaces from each line.
Finally, it returns this array of captions.
If there's an error at any point, it shows an error message suggesting to try again or use a Huggingface Token instead.
This function is asynchronous, meaning it returns a promise that resolves to the array of generated captions when the operation is complete.
Now use generateCaptionVariants function inside generateCaption function after, where intialCaption variable is defined.
/* previous code as it is */
const initialCaption = result.generated_text;
const variantCaptions = await generateCaptionVariants(initialCaption);
setCaptions(variantCaptions || []);
toast.success('Captions generated successfully!');
This line extracts the generated text from the result object and assigns it to the initialCaption variable.
const variantCaptions = await generateCaptionVariants(initialCaption);
The above line calls the generateCaptionVariants function, passing the initialCaption as an argument. The function is asynchronous, so it uses await to wait for the function to complete and return the generated caption variants. The result is stored in the variantCaptions variable.
setCaptions(variantCaptions || []);
This line updates the state with the generated caption variants. If variantCaptions is null or undefined, it sets the state to an empty array [].
At the end, a success notification to the user, indicating that the captions have been generated successfully.
UI Components with shadcn/ui
We're almost done with the logic part, now let's set up our UI.
<div className="max-w-2xl mx-auto p-6">
{/* ... */}
</div>
The entire component is wrapped in a container div with a maximum width of 2xl (from Tailwind), centered with auto margins, and padding of 6 units.
- Image Upload Section:
<div
{...getRootProps()}
className="border-2 border-dashed border-gray-300 rounded-lg p-8 text-center cursor-pointer hover:border-gray-400 transition-colors"
>
<input {...getInputProps()} />
<CloudIcon className="mx-auto h-12 w-12 text-gray-400 mb-4" />
{isDragActive ? (
<p>Drop the image here ...</p>
) : (
<p>Drag 'n' drop an image here, or click to select</p>
)}
</div>
This section creates a drag-and-drop area for image upload. It uses the getRootProps() and getInputProps() functions from react-dropzone. The UI changes based on whether an image is being dragged over the area (isDragActive).
- Image Preview:
{image && (
<div className="mt-4 text-center">
<img src={URL.createObjectURL(image)} alt="Preview" className="max-w-full max-h-64 mx-auto object-contain" />
</div>
)}
If an image is selected (image is truthy), it displays a preview of the image.
- Tone and Language Selection:
<div className="grid grid-cols-2 gap-4 mt-6">
{/* Tone selection */}
<div className="space-y-2">
{/* ... */}
</div>
{/* Language selection */}
<div className="space-y-2">
{/* ... */}
</div>
</div>
This section creates a two-column grid for selecting the tone and language for the caption. It uses custom Select, SelectTrigger, SelectValue, SelectContent, and SelectItem components.
- Number of Variants Slider:
<div className="mt-6 space-y-2">
<Label>Number of Variants: {variants}</Label>
<Slider
value={[variants]}
onValueChange={(value: any) => setVariants(value[0])}
min={1}
max={5}
step={1}
/>
</div>
This creates a slider to select the number of caption variants to generate, using a shadcn Slider component.
- Toggle Switches:
<div className="mt-6 space-y-4">
{/* Include Hashtags switch */}
<div className="flex items-center space-x-2">
{/* ... */}
</div>
{/* Include Emojis switch */}
<div className="flex items-center space-x-2">
{/* ... */}
</div>
</div>
These are toggle switches for including hashtags and emojis in the generated captions, using a shadcn Switch component.
- Generate Caption Button:
<Button
onClick={generateCaption}
disabled={!image || loading}
className="w-full mt-6"
>
{loading ? 'Generating...' : 'Generate Caption'}
</Button>
This button triggers the caption generation. It's disabled if there's no image or if it's currently loading.
- Generated Captions Display:
{captions.map((caption, index) => (
<Card key={index} className="mt-4">
<CardContent className="p-4">
<p className="text-sm">{caption}</p>
<Button
variant="ghost"
size="sm"
className="mt-2"
onClick={() => handleCopy(caption)}
>
<CopyIcon className="h-4 w-4 mr-2" />
Copy
</Button>
</CardContent>
</Card>
))}
This section maps over the captions array and displays each generated caption in a card. Each card includes the caption text and a "Copy" button to copy the caption.
The UI will look something like this.
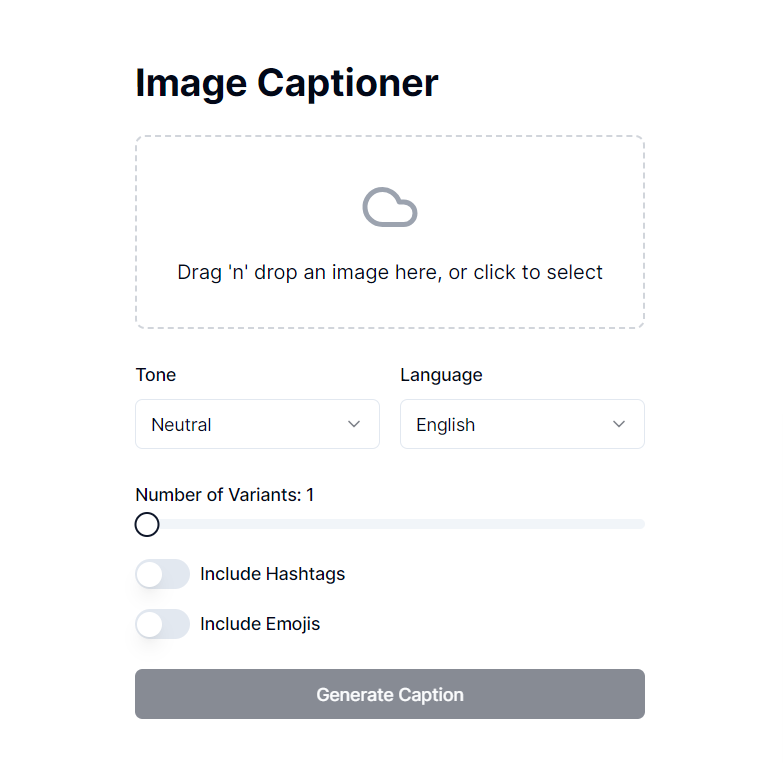
Complete code:
import React, { useState, useCallback } from 'react';
import { useDropzone } from 'react-dropzone';
import { HfInference } from '@huggingface/inference';
import { Button } from "@/components/ui/button";
import { GoogleGenerativeAI } from "@google/generative-ai";
import { Switch } from "@/components/ui/switch";
import { Slider } from "@/components/ui/slider";
import { Select, SelectContent, SelectItem, SelectTrigger, SelectValue } from "@/components/ui/select";
import { Card, CardContent } from "@/components/ui/card";
import { Label } from "@/components/ui/label";
import { CloudIcon, CopyIcon } from "lucide-react";
import toast, {Toaster} from 'react-hot-toast';
const languages = ['English', 'Hindi', 'Spanish', 'French', 'Russian'];
const tones = [
'Neutral',
'Funny',
'Happy',
'Sad',
/* as much as you want */
];
const ImageCaptioner: React.FC = () => {
const [image, setImage] = useState<File | null>(null);
const [captions, setCaptions] = useState<string[]>([]);
const [loading, setLoading] = useState<boolean>(false);
const [tone, setTone] = useState<string>('Neutral');
const [useHashtags, setUseHashtags] = useState<boolean>(false);
const [useEmojis, setUseEmojis] = useState<boolean>(false);
const [language, setLanguage] = useState<string>('English');
const [variants, setVariants] = useState<number>(1);
const onDrop = useCallback((acceptedFiles: File[]) => {
if (acceptedFiles && acceptedFiles[0]) {
setImage(acceptedFiles[0]);
}
}, []);
const { getRootProps, getInputProps, isDragActive } = useDropzone({
onDrop, accept: {
'image/png': ['.png'],
'image/jpeg': ['.jpg', '.jpeg'],
}
});
const generateCaptionVariants = async (initialCaption: string) => {
const API_KEY = process.env.NEXT_PUBLIC_GEMINI_API_KEY;
if (!API_KEY) {
toast.error("Gemini API key is not set");
}
const genAI = new GoogleGenerativeAI(API_KEY || '');
const model = genAI.getGenerativeModel({ model: "gemini-pro" });
const prompt = `Generate ${variants} ${tone.toLowerCase()} captions in ${language} based on the following image description. ${useHashtags ? 'Include relevant hashtags.' : ''} ${useEmojis ? 'Include appropriate emojis.' : ''} Keep each caption concise and engaging.
Initial caption: "${initialCaption}"
Please provide the captions in a numbered list format.`;
try {
const result = await model.generateContent(prompt);
const response = result.response;
const generatedText = response.text();
const variantCaptions = generatedText.split('\n')
.filter(line => line.trim().match(/^\d+\./))
.map(line => line.replace(/^\d+\.\s*/, '').trim());
return variantCaptions;
} catch (error) {
toast.error('Error generating captions. Please try again. Or use your Huggingface Token.');
throw error;
}
};
const generateCaption = async () => {
if (!image) return;
setLoading(true);
try {
const hf = new HfInference(process.env.NEXT_PUBLIC_HF_ACCESS_TOKEN);
const result = await hf.imageToText({
model: 'Salesforce/blip-image-captioning-large',
data: image,
});
const initialCaption = result.generated_text;
const variantCaptions = await generateCaptionVariants(initialCaption);
setCaptions(variantCaptions || []);
toast.success('Captions generated successfully!');
} catch (error) {
toast.error('Error generating captions. Please try again.');
setCaptions([]);
} finally {
setLoading(false);
}
};
const handleCopy = (caption: string) => {
navigator.clipboard.writeText(caption);
toast.success('Captions copied successfully!');
};
return (
<div className="max-w-2xl mx-auto p-6">
<h1 className="text-3xl font-bold mb-6">Image Captioner</h1>
<div
{...getRootProps()}
className="border-2 border-dashed border-gray-300 rounded-lg p-8 text-center cursor-pointer hover:border-gray-400 transition-colors"
>
<input {...getInputProps()} />
<CloudIcon className="mx-auto h-12 w-12 text-gray-400 mb-4" />
{isDragActive ? (
<p>Drop the image here ...</p>
) : (
<p>Drag 'n' drop an image here, or click to select</p>
)}
</div>
{image && (
<div className="mt-4 text-center">
<img src={URL.createObjectURL(image)} alt="Preview" className="max-w-full max-h-64 mx-auto object-contain" />
</div>
)}
<div className="grid grid-cols-2 gap-4 mt-6">
<div className="space-y-2">
<Label htmlFor="tone">Tone</Label>
<Select onValueChange={setTone} value={tone}>
<SelectTrigger>
<SelectValue placeholder="Select tone" />
</SelectTrigger>
<SelectContent>
{tones.map((t) => (
<SelectItem key={t} value={t}>{t}</SelectItem>
))}
</SelectContent>
</Select>
</div>
<div className="space-y-2">
<Label htmlFor="language">Language</Label>
<Select onValueChange={setLanguage} value={language}>
<SelectTrigger>
<SelectValue placeholder="Select language" />
</SelectTrigger>
<SelectContent>
{languages.map((lang) => (
<SelectItem key={lang} value={lang}>{lang}</SelectItem>
))}
</SelectContent>
</Select>
</div>
</div>
<div className="mt-6 space-y-2">
<Label>Number of Variants: {variants}</Label>
<Slider
value={[variants]}
onValueChange={(value: any) => setVariants(value[0])}
min={1}
max={5}
step={1}
/>
</div>
<div className="mt-6 space-y-4">
<div className="flex items-center space-x-2">
<Switch id="hashtags" checked={useHashtags} onCheckedChange={setUseHashtags} />
<Label htmlFor="hashtags">Include Hashtags</Label>
</div>
<div className="flex items-center space-x-2">
<Switch id="emojis" checked={useEmojis} onCheckedChange={setUseEmojis} />
<Label htmlFor="emojis">Include Emojis</Label>
</div>
</div>
<Button
onClick={generateCaption}
disabled={!image || loading}
className="w-full mt-6"
>
{loading ? 'Generating...' : 'Generate Caption'}
</Button>
{captions.map((caption, index) => (
<Card key={index} className="mt-4">
<CardContent className="p-4">
<p className="text-sm">{caption}</p>
<Button
variant="ghost"
size="sm"
className="mt-2"
onClick={() => handleCopy(caption)}
>
<CopyIcon className="h-4 w-4 mr-2" />
Copy
</Button>
</CardContent>
</Card>
))}
<Toaster />
</div>
);
};
export default ImageCaptioner;
The Output
Add an image and your choices👇
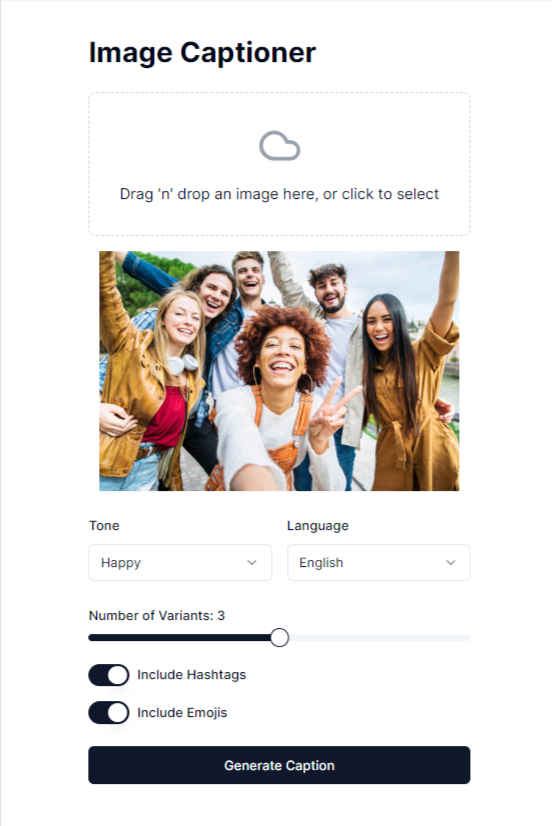
And it will generate beautiful captions.
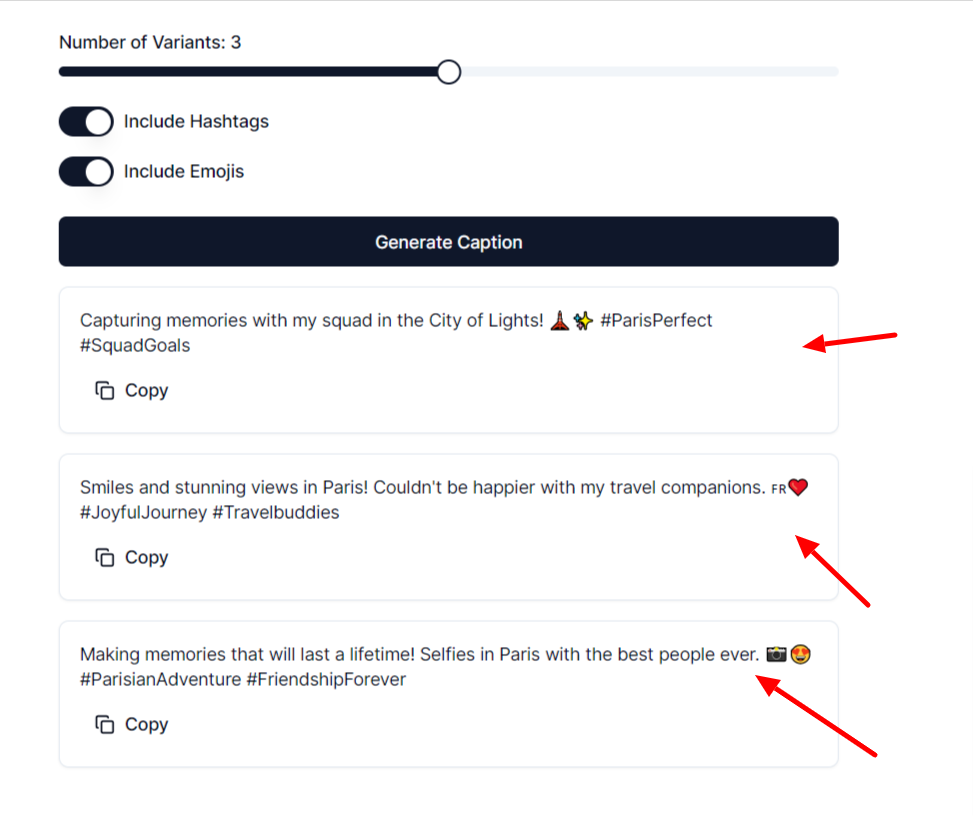
And that's it! We have successfully created an AI Image Captioner app that generates realistic, human-like-written captions.
Conclusion
In this tutorial, we successfully created an AI Image Captioner app using HuggingFace and Google Gemini. This app can generate realistic, human-like captions for images, showcasing the power of AI in enhancing user experiences.
By following the steps outlined, you now have a functional tool that can handle image uploads, convert images to text descriptions, and generate creative captions with various tones and languages.
Thanks for reading this blog. I hope you learned something new today. If you found this blog helpful, feel free to share it with your friends and community. I write blogs and share content on Open Source, and other web development-related topics.
Feel free to connect with me on my socials.
I'll see you in the next one.
Happy coding!
Subscribe to my newsletter
Read articles from Shivam Katare directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shivam Katare
Shivam Katare
👋 Hey there! I'm Shivam, a self-taught web developer from India. My passion lies in web development, and I thrive on contributing to open-source projects and writing technical blogs. 🚀 Teamwork fuels my creativity, and I take pride in building efficient, user-friendly solutions. Let's code together! 💻🌟