Container Networking Explained (Part IV)
 Ranjan Ojha
Ranjan OjhaIf you have been following along the series, you should have a good understanding the basic building blocks that make up container networking. veth, bridge and iptables makeup the bulk of single host container networking stack in both Docker and Kubernetes. However, these are not the only blocks we have available for creating container networks. In the following few segments we will be exploring some more blocks available for us.
Note: It is recommended to run these experiments inside of a VM. I am currently running all my experiments on a kvm using libvirt, connected to default bridge. This setup is recommended because we need to configure external routing system and I would like everyone to have a common system.
MACVLAN Interface
MACVLAN is also a virtual interface that works with network namespaces. These virtual interface allow a single physical interface to serve multiple network interfaces each with their own MAC address.

The idea for using macvlan interface for container networking to exponse the containers or pods to the external networking interface. Remember how when we had veth, bridge pairs, the container network was internal and we needed to setup manual iptables rules to expose the containers to the external network. With macvlan each container is visible to external network as a separate device. Running such a configuration has few benefits over default option.
For one, you can utilize the already present network infrastructure. If you already have a networking team in your organization and don't want to go through the overhead of cluster administrator also looking into additional network configuration then you can opt for this option. The other option is by creating a more direct connection with the external network you eliminate an additional layer of indirection. This helps reduce the overall load on the network allowing for higher throughput.
Setting up containers
As is typical, I will start by creating network namespaces, which will act as our containers. I have also made a small modification to my echo-server such that now I can pass in a message at start time.
But onwards with the commands which hopefully by now you should understand well enough.
Setting up macvlan
fedora@fedora:~$ sudo ip netns add container
fedora@fedora:~$ sudo ip link add mvlan link enp1s0 type macvlan
fedora@fedora:~$ sudo ip link set mvlan netns container
fedora@fedora:~$ sudo ip netns exec container ip link set lo up
fedora@fedora:~$ sudo ip netns exec container ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host proto kernel_lo
valid_lft forever preferred_lft forever
6: mvlan@if2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 16:c5:98:b7:9b:d4 brd ff:ff:ff:ff:ff:ff link-netnsid 0
Setting IP
With veth, bridge combination we had been doing, we had to do static IP allocation. However, with macvlan we also have the chance to use dhcp to dynamically allocate IP. For this however we will need to run a dedicated dhcp client in each container. For the purpose of demonstration, in this container we will run dhclient to obtain IP address, but will be relying on static IP allocation on remaining of exercise.
Note: Currently, Docker macvlan network doesn't support
dhcp. Instead users should configure the ip inclusion and exclusion range. Further information about running macvlan in Docker can be foundhere.
fedora@fedora:~$ sudo ip netns exec container dhclient
fedora@fedora:~$ sudo ip netns exec container ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host proto kernel_lo
valid_lft forever preferred_lft forever
6: mvlan@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 16:c5:98:b7:9b:d4 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.122.53/24 brd 192.168.122.255 scope global dynamic mvlan
valid_lft 3653sec preferred_lft 3653sec
inet6 fe80::14c5:98ff:feb7:9bd4/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
Before moving forward with any other exercises. I need to address the elephant in the room. macvlan interface infact has different modes it can operate in. Each of these modes change how the interface behaves, which we will be looking at.
Modes of macvlan
For every exercies below, we will assume that container-1 and contanier-2 network namespaces are present.
fedora@fedora:~$ sudo ip netns add container-1
fedora@fedora:~$ sudo ip netns add container-2
Bridge mode
This is the default mode Docker and macvlan cni plugin in Kubernetes will start you with.
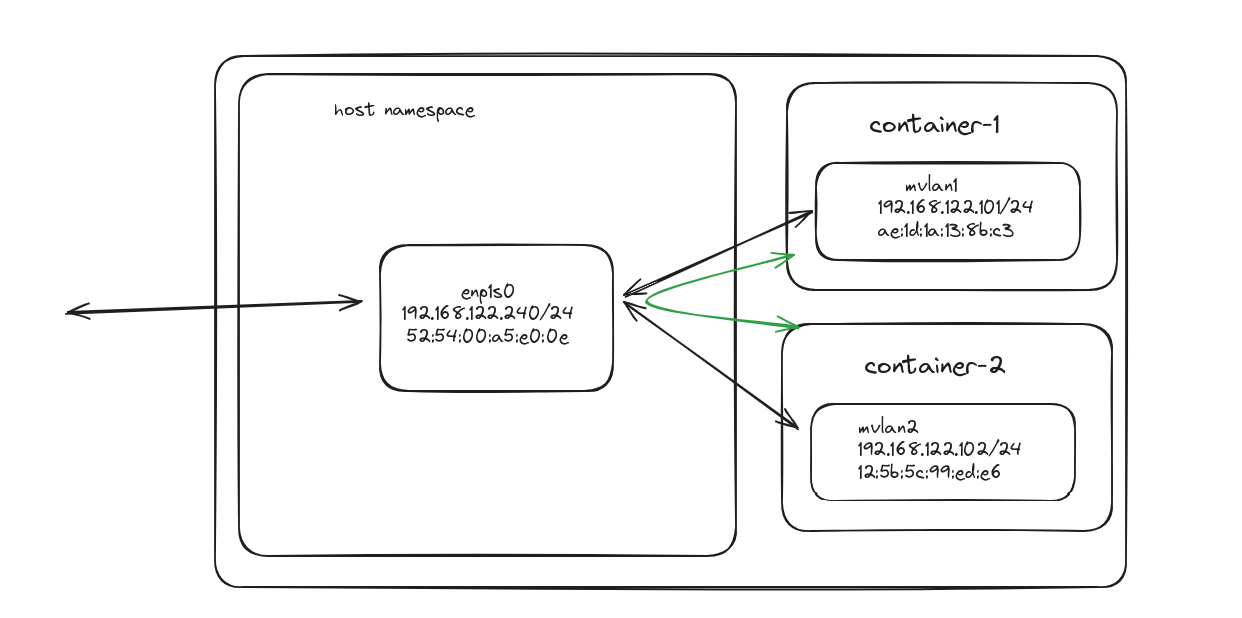
In this mode, the interface in host device acts as a bridge device we have been using. Allowing all traffic between containers to pass between it. However, you have to note that container to host communication is not allowed. This restriction comes from the Linux kernel itself as it doesn't allow direct communication between any macvlan child interfaces and host interface.
fedora@fedora:~$ sudo ip link add mvlan1 link enp1s0 type macvlan mode bridge
fedora@fedora:~$ sudo ip link add mvlan2 link enp1s0 type macvlan mode bridge
fedora@fedora:~$ sudo ip link set mvlan1 netns container-1
fedora@fedora:~$ sudo ip link set mvlan2 netns container-2
fedora@fedora:~$ sudo ip netns exec container-1 ip link set lo up
fedora@fedora:~$ sudo ip netns exec container-2 ip link set lo up
fedora@fedora:~$ sudo ip netns exec container-1 ip a add 192.168.122.101/24 dev mvlan1
fedora@fedora:~$ sudo ip netns exec container-2 ip a add 192.168.122.102/24 dev mvlan2
fedora@fedora:~$ sudo ip netns exec container-1 ip link set mvlan1 up
fedora@fedora:~$ sudo ip netns exec container-2 ip link set mvlan2 up
fedora@fedora:~$ sudo ip netns exec container-1 ip r add default via 192.168.122.1 dev mvlan1 src 192.168.122.101
fedora@fedora:~$ sudo ip netns exec container-2 ip r add default via 192.168.122.1 dev mvlan2 src 192.168.122.102
fedora@fedora:~$ sudo ip netns exec container-1 ping 192.168.122.102 -c3
PING 192.168.122.102 (192.168.122.102) 56(84) bytes of data.
64 bytes from 192.168.122.102: icmp_seq=1 ttl=64 time=0.199 ms
64 bytes from 192.168.122.102: icmp_seq=2 ttl=64 time=0.061 ms
64 bytes from 192.168.122.102: icmp_seq=3 ttl=64 time=0.062 ms
--- 192.168.122.102 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2037ms
rtt min/avg/max/mdev = 0.061/0.107/0.199/0.064 ms
fedora@fedora:~$ sudo ip netns exec container-2 ping 192.168.122.101 -c3
PING 192.168.122.101 (192.168.122.101) 56(84) bytes of data.
64 bytes from 192.168.122.101: icmp_seq=1 ttl=64 time=0.034 ms
64 bytes from 192.168.122.101: icmp_seq=2 ttl=64 time=0.022 ms
64 bytes from 192.168.122.101: icmp_seq=3 ttl=64 time=0.048 ms
--- 192.168.122.101 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2032ms
rtt min/avg/max/mdev = 0.022/0.034/0.048/0.010 ms
fedora@fedora:~$ sudo ip netns exec container-2 ping 192.168.122.240 -c3
PING 192.168.122.240 (192.168.122.240) 56(84) bytes of data.
From 192.168.122.102 icmp_seq=1 Destination Host Unreachable
From 192.168.122.102 icmp_seq=2 Destination Host Unreachable
From 192.168.122.102 icmp_seq=3 Destination Host Unreachable
--- 192.168.122.240 ping statistics ---
3 packets transmitted, 0 received, +3 errors, 100% packet loss, time 2038ms
pipe 3
And as expected ping to host doesn't work.
VEPA
Virtual Ethernet Port Aggregator (VEPA), is a mode that moves the switching logic out of the host device and onto the network device. This frees up host device from having to perform additional network switching so could theoritically decrease system load, but whether this makes any significant differences is something I have yet to evaluate. This is also the default mode for when you create macvlan using iproute2.

There is an obvious overhead in all the traffic from containers flowing through enp1s0 interface but the added benefit is that since all the communication with host now happens from external device it's possible to communicate with host.
Another gotcha to look out for is the fact that when the containers are communicating with each other or the host, the packet is sent down the same interface it came out in the switch. This behaviour is disabled by default. To allow for such traffic flow, you need to enable hairpin mode in the port of the switch (L2), or have an external router forward the traffic back (L3).
fedora@fedora:~$ sudo ip link add mvlan1 link enp1s0 type macvlan mode vepa
fedora@fedora:~$ sudo ip link add mvlan2 link enp1s0 type macvlan mode vepa
fedora@fedora:~$ sudo ip link set mvlan1 netns container-1
fedora@fedora:~$ sudo ip link set mvlan2 netns container-2
fedora@fedora:~$ sudo ip netns exec container-1 ip link set lo up
fedora@fedora:~$ sudo ip netns exec container-2 ip link set lo up
fedora@fedora:~$ sudo ip netns exec container-1 ip a add 192.168.122.101/24 dev mvlan1
fedora@fedora:~$ sudo ip netns exec container-2 ip a add 192.168.122.102/24 dev mvlan2
fedora@fedora:~$ sudo ip netns exec container-1 ip link set mvlan1 up
fedora@fedora:~$ sudo ip netns exec container-2 ip link set mvlan2 up
fedora@fedora:~$ sudo ip netns exec container-1 ip r add default via 192.168.122.1 dev mvlan1 src 192.168.122.101
fedora@fedora:~$ sudo ip netns exec container-2 ip r add default via 192.168.122.1 dev mvlan2 src 192.168.122.102
We now need to setup hairpin mode. This largely depends on how you have setup your network infrastructure. This is where the recommendation I gave in the beginning comes into play. Since I am running all my experiments in a vm which is connected to default NAT bridge in libvirt I need to set the hairpin mode to the vnet device connecting my vm to the default virbr0 bridge. If you have many vnet devices, you can run sudo virsh dumpxml <vm-name>, then search for your network interface, it should have a section like this,
<interface type='network'>
<mac address='52:54:00:a5:e0:0e'/>
<source network='default' portid='761dfda7-a6e8-4e21-8aa0-a8d2ee59cd05' bridge='virbr0'/>
<target dev='vnet0'/>
<model type='virtio'/>
<alias name='net0'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
Looking at this, I know that my vm is using vnet0 to communicate with virbr0 the default bridge. I can then enable hairpin mode by,
➜ web-server:$ sudo ip link set vnet0 type bridge_slave hairpin on
Back inside our vm our containers now should be able to ping each other, including host.
fedora@fedora:~$ sudo ip netns exec container-1 ping 192.168.122.102 -c3
PING 192.168.122.102 (192.168.122.102) 56(84) bytes of data.
64 bytes from 192.168.122.102: icmp_seq=1 ttl=64 time=0.504 ms
64 bytes from 192.168.122.102: icmp_seq=2 ttl=64 time=0.277 ms
64 bytes from 192.168.122.102: icmp_seq=3 ttl=64 time=0.167 ms
--- 192.168.122.102 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2056ms
rtt min/avg/max/mdev = 0.167/0.316/0.504/0.140 ms
fedora@fedora:~$ sudo ip netns exec container-1 ping 192.168.122.240 -c3
PING 192.168.122.240 (192.168.122.240) 56(84) bytes of data.
64 bytes from 192.168.122.240: icmp_seq=1 ttl=64 time=0.231 ms
64 bytes from 192.168.122.240: icmp_seq=2 ttl=64 time=0.281 ms
64 bytes from 192.168.122.240: icmp_seq=3 ttl=64 time=0.304 ms
--- 192.168.122.240 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2064ms
rtt min/avg/max/mdev = 0.231/0.272/0.304/0.030 ms
Private
This mode is similar to VEPA in that the switching/routing decision is made externally. However, like the name implies it keeps the interfaces isolated from each other. Even with hairpin mode enabled.

fedora@fedora:~$ sudo ip link add mvlan1 link enp1s0 type macvlan mode private
fedora@fedora:~$ sudo ip link add mvlan2 link enp1s0 type macvlan mode private
fedora@fedora:~$ sudo ip link set mvlan1 netns container-1
fedora@fedora:~$ sudo ip link set mvlan2 netns container-2
fedora@fedora:~$ sudo ip netns exec container-1 ip link set lo up
fedora@fedora:~$ sudo ip netns exec container-2 ip link set lo up
fedora@fedora:~$ sudo ip netns exec container-1 ip a add 192.168.122.101/24 dev mvlan1
fedora@fedora:~$ sudo ip netns exec container-2 ip a add 192.168.122.102/24 dev mvlan2
fedora@fedora:~$ sudo ip netns exec container-1 ip link set mvlan1 up
fedora@fedora:~$ sudo ip netns exec container-2 ip link set mvlan2 up
fedora@fedora:~$ sudo ip netns exec container-1 ip r add default via 192.168.122.1 dev mvlan1 src 192.168.122.101
fedora@fedora:~$ sudo ip netns exec container-2 ip r add default via 192.168.122.1 dev mvlan2 src 192.168.122.102
fedora@fedora:~$ sudo ip netns exec container-1 ping 192.168.122.102 -c3
PING 192.168.122.102 (192.168.122.102) 56(84) bytes of data.
From 192.168.122.101 icmp_seq=1 Destination Host Unreachable
From 192.168.122.101 icmp_seq=2 Destination Host Unreachable
From 192.168.122.101 icmp_seq=3 Destination Host Unreachable
--- 192.168.122.102 ping statistics ---
3 packets transmitted, 0 received, +3 errors, 100% packet loss, time 2063ms
pipe 3
fedora@fedora:~$ sudo ip netns exec container-1 ping 192.168.122.240 -c3
PING 192.168.122.240 (192.168.122.240) 56(84) bytes of data.
From 192.168.122.101 icmp_seq=1 Destination Host Unreachable
From 192.168.122.101 icmp_seq=2 Destination Host Unreachable
From 192.168.122.101 icmp_seq=3 Destination Host Unreachable
--- 192.168.122.240 ping statistics ---
3 packets transmitted, 0 received, +3 errors, 100% packet loss, time 2077ms
pipe 3
Ofcourse, if you have configured the routes and nameservers, you do have connection to external internet
fedora@fedora:~$ sudo ip netns exec container-1 curl example.com -I
HTTP/1.1 200 OK
Accept-Ranges: bytes
Age: 422143
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Tue, 30 Jul 2024 15:57:57 GMT
Etag: "3147526947+gzip"
Expires: Tue, 06 Aug 2024 15:57:57 GMT
Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
Server: ECAcc (dcd/7D3C)
X-Cache: HIT
Content-Length: 1256
Passthru
We have one more mode, the passthru mode. However I won't expand into much detail. Going through the Linux Kernel Patch note, that introduced this feature. It seems it has use mainly to allow the host device to control the MAC Address of guest device. Also it allows only 1 device to bind per interface.
Note: macvlan exposes interfaces for use with network namespacing. If you want to use macvlan features in vm setting, you should use macvtap instead. Which provides you with a
tapfile the hypervisor can read and write to.
And this all about using macvlan drivers to allow containers to communicate on the external network directly. These drivers are currently very rarely used, but perhaps in systems where there is very strict network requirements that are better handled by using regular networking devices rather than creating another virtual network inside host vms.
But macvlan isn't the only way we can expose our containers to external networks.
IPVLAN interface
We also have the possibility of using ipvlan for similar purpose as macvlan. The major difference between these 2 interface is that ipvlan has no layer 2 networking of it's own. It infact uses the l2 of the host device. This is also why ipvlan interfaces share mac address with their link interface.

In addition to the bridge, private, vepa modes that macvlan had, ipvlan also adds additional L2, L3, and L3s mode.
According the Linux Kernel driver docs, one should choose ipvlan over macvlan if the following condition applies,
The Linux host that is connected to the external switch / router has policy configured that allows only one mac per port.
No of virtual devices created on a master exceed the mac capacity and puts the NIC in promiscuous mode and degraded performance is a concern.
If the slave device is to be put into the hostile / untrusted network namespace where L2 on the slave could be changed / misused.
I will let you be the judge of when to use ipvlan, but if we were to use ipvlan here is how you would configure it for L2 bridge mode.
fedora@fedora:~$ sudo ip link add ipvlan1 link enp1s0 type ipvlan mode l2 bridge
fedora@fedora:~$ sudo ip link add ipvlan2 link enp1s0 type ipvlan mode l2 bridge
fedora@fedora:~$ sudo ip link set ipvlan1 netns container-1
fedora@fedora:~$ sudo ip link set ipvlan2 netns container-2
fedora@fedora:~$ sudo ip netns exec container-1 ip a add 192.168.122.101/24 dev ipvlan1
fedora@fedora:~$ sudo ip netns exec container-2 ip a add 192.168.122.102/24 dev ipvlan2
fedora@fedora:~$ sudo ip netns exec container-1 ip link set lo up
fedora@fedora:~$ sudo ip netns exec container-1 ip link set ipvlan1 up
fedora@fedora:~$ sudo ip netns exec container-2 ip link set lo up
fedora@fedora:~$ sudo ip netns exec container-2 ip link set ipvlan2 up
fedora@fedora:~$ sudo ip netns exec container-1 ip r add default via 192.168.122.1 dev ipvlan1 src 192.168.122.101
fedora@fedora:~$ sudo ip netns exec container-2 ip r add default via 192.168.122.1 dev ipvlan2 src 192.168.122.102
The commands for creating the containers in other mode is the same above with just the first 2 lines changed.
Understanding ipvlan layer modes
While much of what ipvlan is similar to macvlan it has these extra layer modes.
L2
In L2 layer mode, all the processing is done in the ipvlan interface itself, then handed out to the parent interface for switching and routing. In terms of container networking this means all the processing is done in container and just sent to the out queue of host interface. This is possible as the host and container share the mac address.
L3
In L3 layer mode, all the processing upto layer 3 is done in ipvlan interface, but any L2 decisions are handed out to the parent interface. In terms of container networking, all the routing decision is made inside container using it's routing table, then for L2 transmission the packet is pushed into host interface where further processing is done before the packet is put into output queue.
L3S
This mode acts similar to L3 besides the fact that iptables conn-tracking works. conn-tracking is a way for Linux kernel to relate related network packets. For instance, it would relate all the ip packets for your 1 http request. There is a overhead when compared to L3 as you also need to do the conn-tracking. So it's chosen only when conn-tracking is needed. It stands for L3-Symmetric.
Understanding ipvlan mode flags
Similar to macvlan, ipvlan also has additional mode flags that decide on how the parent interface should handle switching.
Bridge
The default mode for ipvlan., In this mode, the parent layer handles all the switching as a bridge.
Private
Similar to in macvlan, all the interfaces have no communication in between them.
VEPA
Similar to macvlan, all the switching decisions are passed to the network device instead. The issue here is that both our container and host share the same mac address. This will make the switch/router send a redirect message.
Subscribe to my newsletter
Read articles from Ranjan Ojha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by