Feature Scaling in Machine Learning
 Utkal Kumar Das
Utkal Kumar Das
What is Feature scaling?
Feature scaling is a method used to normalize the range of independent variables or features of data. By scaling the features, we ensure that each feature contributes equally to the result, improving the performance and accuracy of machine learning models.
In data processing, it is also known as data normalization and is crucial for algorithms that are sensitive to the magnitudes of data, such as gradient descent and k-nearest neighbors.
In this blog, we will look up on the need of Feature Scaling, it's importance and different types of feature scaling used in Machine learning.
Need of Feature Scaling in ML
When the data includes different features which have significantly different ranges, some features may disproportionately influence the model's output, potentially impacting the it's performance and accuracy. To enhance both efficiency and accuracy, it is essential to transform these numerical features to a common scale using feature scaling techniques.
For example, to build a machine learning model to predict price of houses including features as number of bedrooms (0-5), size (in 1000 sqft.), age of the house (1-100 years) and many more.
The machine learning model assign weights (\(w\)) to the independent variables according to their data points. If the difference between the data points is high, the model will provide more weight (\(w\)) to the larger magnitudes, which might confuse our model to consider this feature as a better one. The model with large weights (\(w\)) assigned to a some feature can often produce poor results.
To understand better, let's take an example -
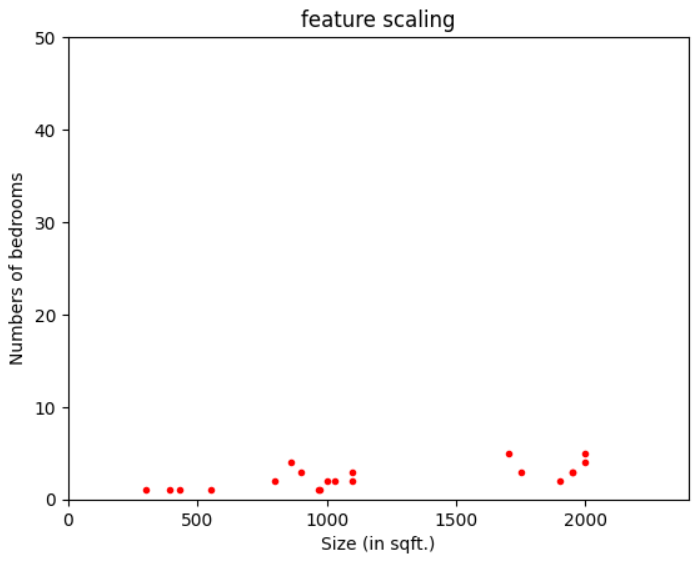
This is a plot between two features (number of bedrooms and size) of the houses, which will be used to build a model to predict the housing prices. Clearly, we can see both the features have different ranges.
size (in sqft.)- \(300\leq x_{1}\leq2000\)
numberof bedrooms- \(1\leq x_{2}\leq5\)
If we train our machine learning model on this dataset, then it might assign heavy weight (\(w\)) to the \(x_{1}\) (size), as it has larger magnitudes, which might lessen the contribution of \(x_{2}\) (no. of bedrooms) to the housing prices. So, the model might produce poor results.
To train our machine learning model to produce more accurate results, we need to do feature scaling on the features.
Types of Feature Scaling
There are 3 types of feature scaling we use -
Min-max Normalization
Mean Normalization
Standardization
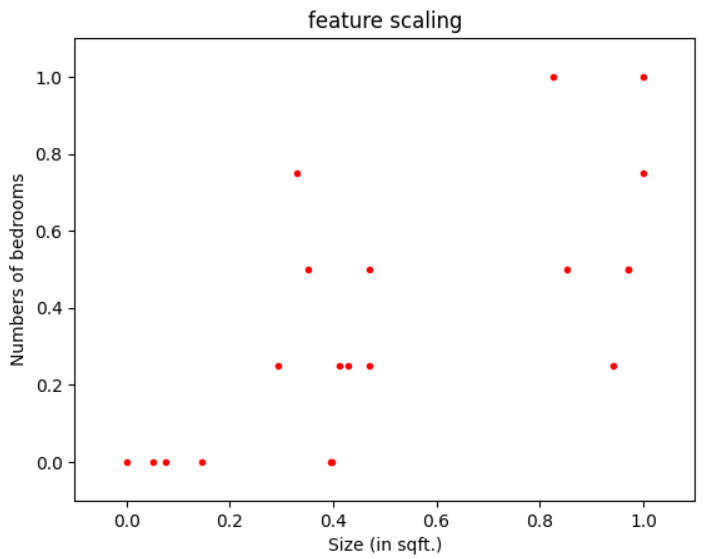
Min-max Normalization
This technique rescales a feature with a distribution value between 0 and 1.
$$x_{ scaled} = \frac{x - min(x)}{max(x) - min(x)}$$
Applying it to our considered example -
\(x_{1 scaled} = \frac{x_{1} - 300}{2000 - 300}\)
\(x_{2 scaled} = \frac{x_{2} - 1}{5- 1}\)
New ranges -
\(0 \leq x_{1 rescaled} \leq 1\)
\(0 \leq x_{2rescaled} \leq 1\)
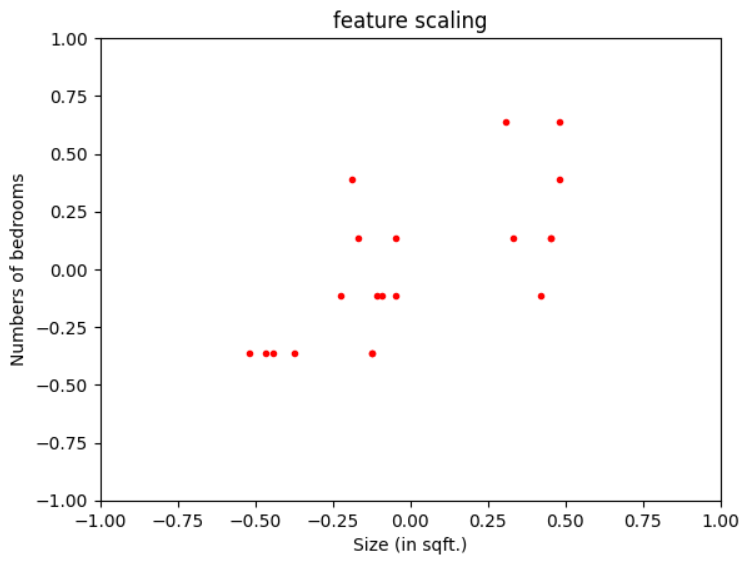
Mean Normalization
This technique calculates and subtracts the mean for every feature in a machine learning model and brings all the model into similar range.
$$x_{rescaled} = \frac{x - \mu}{max(x)-min(x)}$$
where, \(\mu\) is the mean of \(x\)
Applying it to our considered example -
\(x_{1rescaled} = \frac{x - 1183}{2000-300}\) (\(\mu_{x_{1}} = 1183\))
\(x_{2rescaled} = \frac{x - 2.45}{5-1}\) (\(\mu_{x_{2}} = 2.45\))
New ranges -
\(-0.519 \leq x_{1 rescaled} \leq 0.480\)
\(-0.362 \leq x_{2 rescaled} \leq 0.637\)
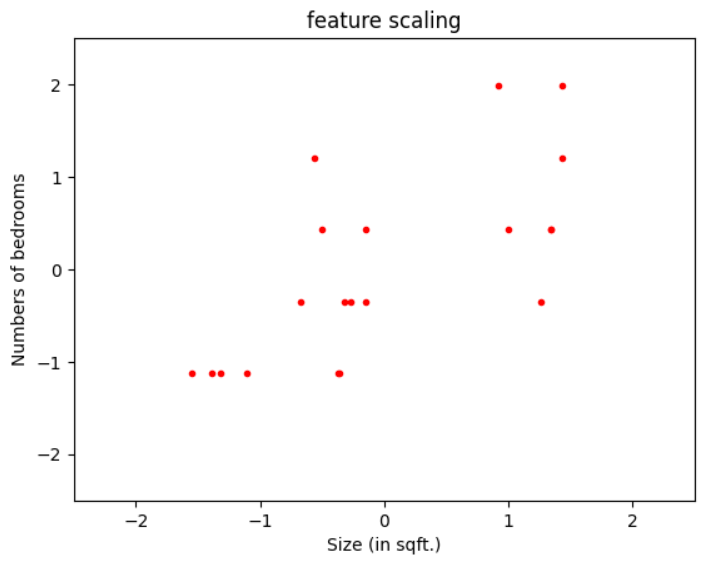
Standardization
When the same process as in mean normalization is done, and the standard deviation is used as the denominator, then this process is called standardization.
$$x_{rescaled} = \frac{x - \mu}{\sigma}$$
where,
\(\mu\) is the mean of x
\(\sigma\) is the standard deviation of x
This technique is mostly used when the distribution of data follows *Gaussian distribution.
*(a probability distribution that is symmetric about the mean, showing that data near the mean are more frequent in occurrence than data far from the mean - example)
Applying it to our example-
\(x_{1rescaled} = \frac{x - 1183}{569.485}\) (\(\mu_{1} = 1183\) and \(\sigma_{1} = 569.485\))
\(x_{2rescaled} = \frac{x - 2.45}{1.283}\) (\(\mu_{2} = 2.45 \) and \(\sigma_{2} = 1.283\))
New ranges -
\(-1.550 \leq x_{1 rescaled} \leq 1.434\)
\(-1.129 \leq x_{2 rescaled} \leq 1.986\)
Conclusion
By applying these techniques, we bring all features into similar ranges. This ensures that all features contribute equally to the output and enhance the performance of the machine learning model. By applying these techniques, we prevent any single feature from disproportionately influencing the model, leading to more balanced and accurate predictions. Feature scaling is thus a crucial step in the data preprocessing phase for building more accurate machine learning models.
If you have any questions or need further clarification on any of the topics discussed, feel free to leave a comment below or reach out to me directly. Let's learn and grow together!
LinkedIn- https://www.linkedin.com/in/utkal-kumar-das-785074289/
To further explore the world of machine learning, here are some recommended resources:
Coursera: Machine Learning by Andrew Ng- https://www.coursera.org/learn/machine-learning
Towards Data Science- https://towardsdatascience.com/
Subscribe to my newsletter
Read articles from Utkal Kumar Das directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Utkal Kumar Das
Utkal Kumar Das
🤖 Machine Learning Enthusiast | 🌐 aspiring Web Developer 🔍 Currently Learning Machine Learning 🚀 Future plans? Eyes set on mastering Competitive Programming, bagging internships, winning competitions, and crafting meaningful projects.