RAG Observability and Evaluation with Azure AI Search, Azure OpenAI, LlamaIndex, and Arize Phoenix
 Farzad Sunavala
Farzad Sunavala
If you've been following my recent blogs, I'm putting together a series on how to use different evaluation and observability tools with Azure AI Search to dive into your Generative AI applications. In this blog, I will show you how to set up the Arize AI Phoenix platform.
Key Takeaways
Exceptional UI: Portraying just the right amount of information you need to monitor and evaluate your RAG application.
Traces and Spans: Offering different granularities of observability.
Hosted Phoenix: Available via LlamaTrace or Docker image to share with others.
Strong Integrations: Supports many LLMs and tools such as LangChain and LlamaIndex.
Great Default Settings: Includes useful settings such as timeouts and concurrency settings.
Metadata Tagging: Excellent feature for tracing.
Initial Setup
Before diving into the implementation, it's crucial to set up your development environment. We'll start by installing the necessary packages and initializing the required clients and models.
!pip install arize-phoenix
!pip install azure-identity
!pip install azure-search-documents==11.4.0
!pip install llama-index
!pip install llama-index-embeddings-azure-openai
!pip install llama-index-llms-azure-openai
!pip install llama-index-vector-stores-azureaisearch
!pip install nest-asyncio
!pip install "openinference-instrumentation-llama-index>=2.0.0"
!pip install -U llama-index-callbacks-arize-phoenix
!pip install python-dotenv
Load Environment Variables and Initialize Clients
I will be using Azure OpenAI GPT-35-Turbo for Generation, Text-Embedding-Ada-002 for Embeddings, and GPT-4o, for evaluating LLM-As-A-Judge.
import os
from dotenv import load_dotenv
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
from azure.search.documents.indexes import SearchIndexClient
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.embeddings.azure_openai import AzureOpenAIEmbedding
from llama_index.llms.azure_openai import AzureOpenAI
from llama_index.vector_stores.azureaisearch import AzureAISearchVectorStore, IndexManagement
# Load environment variables
load_dotenv()
# Environment Variables
AZURE_OPENAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
AZURE_OPENAI_API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME = os.getenv("AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME")
AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME = os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME")
SEARCH_SERVICE_ENDPOINT = os.getenv("AZURE_SEARCH_SERVICE_ENDPOINT")
SEARCH_SERVICE_API_KEY = os.getenv("AZURE_SEARCH_ADMIN_KEY")
# Initialize Azure OpenAI and embedding models
llm = AzureOpenAI(
model=AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME,
deployment_name=AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME,
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version="2024-02-01"
)
embed_model = AzureOpenAIEmbedding(
model=AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME,
deployment_name=AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME,
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version="2024-02-01"
)
# Initialize search clients
credential = AzureKeyCredential(SEARCH_SERVICE_API_KEY)
index_client = SearchIndexClient(endpoint=SEARCH_SERVICE_ENDPOINT, credential=credential)
search_client = SearchClient(endpoint=SEARCH_SERVICE_ENDPOINT, index_name=INDEX_NAME, credential=credential)
Launch Phoenix
To start evaluating and observing our RAG system, we need to launch the Phoenix app.
import phoenix as px
import nest_asyncio
nest_asyncio.apply()
px.launch_app()
You should see a message indicating that Phoenix is running and providing a URL to view the app in your browser.
Instrument LlamaIndex
We'll instrument LlamaIndex with Arize Phoenix to enable comprehensive logging and monitoring.
import llama_index.core
llama_index.core.set_global_handler("arize_phoenix")
Vector Store Initialization
Set up the vector store using Azure AI Search
from llama_index.core.settings import Settings
Settings.llm = llm
Settings.embed_model = embed_model
# Initialize the vector store
vector_store = AzureAISearchVectorStore(
search_or_index_client=index_client,
index_name=INDEX_NAME,
index_management=IndexManagement.VALIDATE_INDEX,
id_field_key="id",
chunk_field_key="text",
embedding_field_key="embedding",
embedding_dimensionality=1536,
metadata_string_field_key="metadata",
doc_id_field_key="doc_id",
language_analyzer="en.lucene",
vector_algorithm_type="exhaustiveKnn",
)
Use Existing Index
We'll use an existing index named "contoso-hr-docs". For details on creating an index and loading documents from scratch, refer to the Azure AI Search documentation.
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents([], storage_context=storage_context)
Compare Different Query Engines
Evaluate and compare responses from different query engines.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.vector_stores.types import VectorStoreQueryMode
from llama_index.core.response.notebook_utils import display_response
from llama_index.core import get_response_synthesizer
# Define response synthesizer
response_synthesizer = get_response_synthesizer()
# Initialize retrievers and query engines
keyword_retriever = index.as_retriever(vector_store_query_mode=VectorStoreQueryMode.SPARSE, similarity_top_k=10)
hybrid_retriever = index.as_retriever(vector_store_query_mode=VectorStoreQueryMode.HYBRID, similarity_top_k=10)
semantic_hybrid_retriever = index.as_retriever(vector_store_query_mode=VectorStoreQueryMode.SEMANTIC_HYBRID, similarity_top_k=10)
keyword_query_engine = RetrieverQueryEngine(retriever=keyword_retriever, response_synthesizer=response_synthesizer)
hybrid_query_engine = RetrieverQueryEngine(retriever=hybrid_retriever, response_synthesizer=response_synthesizer)
semantic_hybrid_query_engine = RetrieverQueryEngine(retriever=semantic_hybrid_retriever, response_synthesizer=response_synthesizer)
Query Execution
Execute a query to test the setup.
from llama_index.core.schema import MetadataMode
query = "Does my health plan cover scuba diving?"
query_engine = index.as_query_engine(llm, similarity_top_k=3)
response = query_engine.query(query)
# Print the response
display_response(response)
print("\n")
# Print what the LLM sees
for node in response.source_nodes:
print(node.get_content(metadata_mode=MetadataMode.LLM))
Once that works and you see a trace in Arize Phoenix UI, you can move onto evaluations!
Evaluate RAG with Arize AI
Run your query engine and view your traces in Phoenix.
from tqdm import tqdm
import json
from openinference.instrumentation import using_metadata
from phoenix.trace import using_project
# Load all evaluation questions from queries.jsonl
eval_questions = []
with open("eval/queries.jsonl", "r") as file:
for line in file:
json_line = json.loads(line.strip())
eval_questions.append(json_line)
# List of query engines and their respective project names
query_engines = [
(keyword_query_engine, "Keyword"),
(hybrid_query_engine, "Hybrid"),
(semantic_hybrid_query_engine, "Semantic_Hybrid"),
]
# Loop through each question and query it against each engine
for query_data in tqdm(eval_questions):
query = query_data["query"]
query_classification = query_data.get("query_classification", "undefined")
for engine, project_name in query_engines:
try:
metadata = query_classification
with using_project(project_name), using_metadata(metadata):
engine.query(query)
except Exception as e:
print(f"Error querying {project_name} for query '{query}': {e}")
Understand Test Dataset
You can look at how I generated my test dataset of queries. I added a field to my json lines file called query_classification because I want to assess the queries that underperform and use this as a metadata filter for observability. We'll come back to this later! Reminder, it's best to use real life queries that are used in production and try and obtain a diverse sample size. Read more on query types: Azure AI Search: Outperforming vector search with hybrid retrieval and ranking capabilities - Microsoft Community Hub
Here is a snippet of our test queries.jsonl file we will use for tracing and evaluation.
{"query": "Why is PerksPlus considered a comprehensive health and wellness program?", "query_classification": "Concept seeking queries"}
{"query": "expense up to $1000 for fitness-related programs", "query_classification": "Exact snippet search"}
{"query": "PerksPlus fitness reimbursement program", "query_classification": "Web search-like queries"}
{"query": "Comprehensive wellness program for employees", "query_classification": "Low query/doc term overlap"}
{"query": "How much can employees expense under PerksPlus?", "query_classification": "Fact seeking queries"}
{"query": "PerksPlus reimbursement", "query_classification": "Keyword queries"}
{"query": "PurksPlus reimbursment", "query_classification": "Queries with misspellings"}
{"query": "Explain how PerksPlus supports both physical and mental health of employees, including examples of activities and lessons covered under the program.", "query_classification": "Long queries"}
{"query": "What is the reimbursement limit under PerksPlus?", "query_classification": "Medium queries"}
{"query": "PerksPlus coverage", "query_classification": "Short queries"}
Export and Evaluate Your Trace Data
from phoenix.evals import HallucinationEvaluator, OpenAIModel, QAEvaluator, RelevanceEvaluator, run_evals
from phoenix.session.evaluation import get_qa_with_reference, get_retrieved_documents
from phoenix.trace import DocumentEvaluations, SpanEvaluations
# Create queries DataFrame for each project
keyword_queries_df = get_qa_with_reference(px.Client(), project_name="Keyword")
hybrid_queries_df = get_qa_with_reference(px.Client(), project_name="Hybrid")
semantic_hybrid_queries_df = get_qa_with_reference(px.Client(), project_name="Semantic_Hybrid")
# Create retrieved documents DataFrame for each project
keyword_retrieved_documents_df = get_retrieved_documents(px.Client(), project_name="Keyword")
hybrid_retrieved_documents_df = get_retrieved_documents(px.Client(), project_name="Hybrid")
semantic_hybrid_retrieved_documents_df = get_retrieved_documents(px.Client(), project_name="Semantic_Hybrid")
# Define the evaluation model
eval_model = OpenAIModel(
azure_endpoint=AZURE_OPENAI_ENDPOINT,
azure_deployment="gpt-4o",
model=AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME,
api_key=AZURE_OPENAI_API_KEY,
api_version="2024-02-01"
)
# Define evaluators
hallucination_evaluator = HallucinationEvaluator(eval_model)
qa_correctness_evaluator = QAEvaluator(eval_model)
relevance_evaluator = RelevanceEvaluator(eval_model)
# List of project names
projects = ["Keyword", "Hybrid", "Semantic_Hybrid"]
# Loop through each project and perform evaluations
for project in projects:
queries_df = get_qa_with_reference(px.Client(), project_name=project)
retrieved_documents_df = get_retrieved_documents(px.Client(), project_name=project)
hallucination_eval_df, qa_correctness_eval_df = run_evals(
dataframe=queries_df,
evaluators=[hallucination_evaluator, qa_correctness_evaluator],
provide_explanation=True,
)
relevance_eval_df = run_evals(
dataframe=retrieved_documents_df,
evaluators=[relevance_evaluator],
provide_explanation=True,
)[0]
px.Client().log_evaluations(
SpanEvaluations(eval_name=f"Hallucination_{project}", dataframe=hallucination_eval_df),
SpanEvaluations(eval_name=f"QA Correctness_{project}", dataframe=qa_correctness_eval_df),
DocumentEvaluations(eval_name=f"Relevance_{project}", dataframe=relevance_eval_df),
)
Peek at Arize Phoenix UI

From the above screenshot, you can see that 3 projects are created preemptively so I can independently evaluate these 3 different retrieval modes over a constant set of test queries. Note, I randomly did a test query without specifying a project, so it created one by 'default'. (just ignore that)
You can view a full stack trace of what is really going on under the hood in my RAG pipeline using LlamaIndex along with the respective latency.
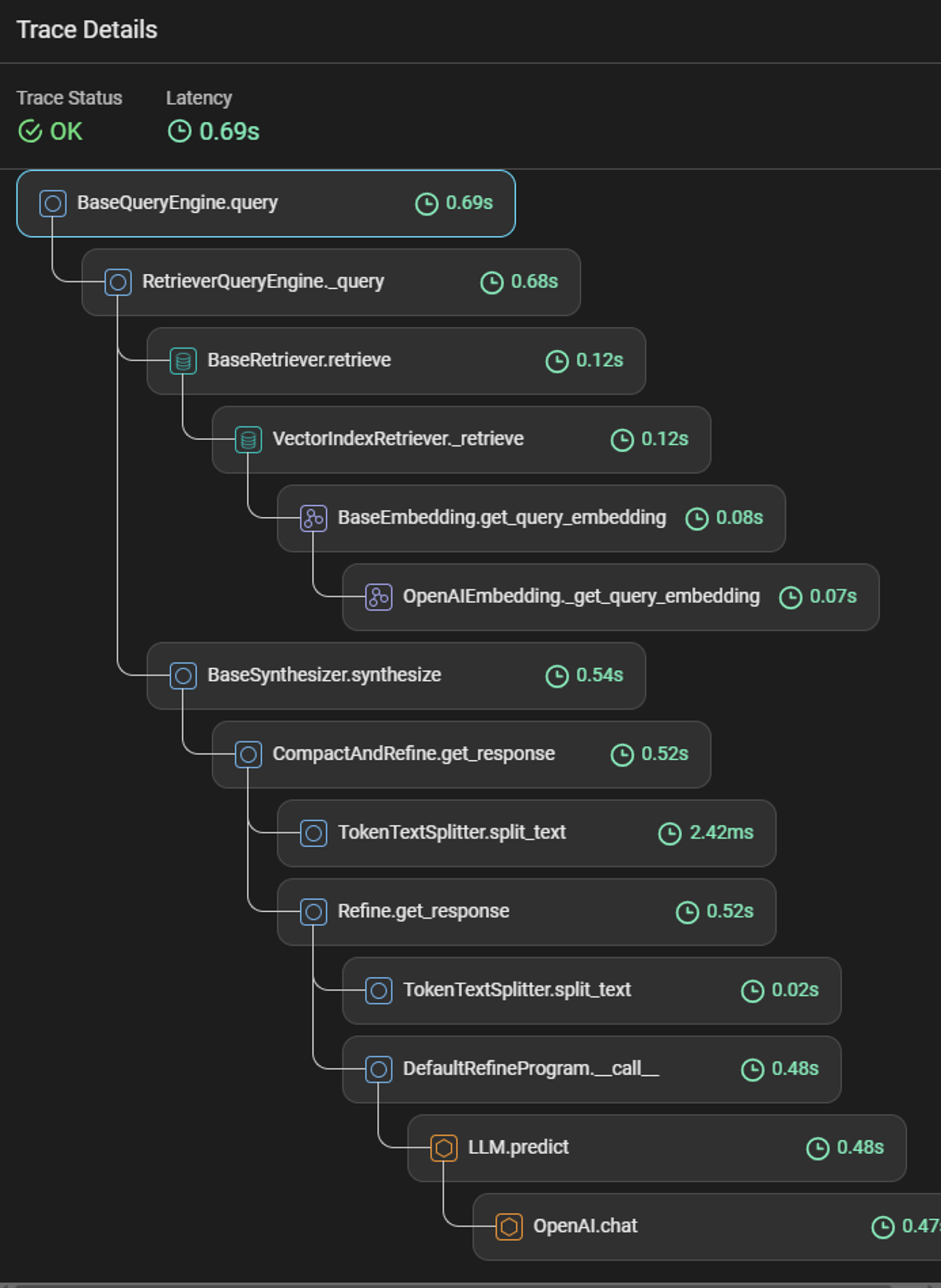
Here is table breakdown of what each of those steps are doing:
| Step | Description |
| BaseQueryEngine.query | Main entry point for query execution, managing the overall process. |
| RetrieverQueryEngine._query | Handles specific logic related to retrieving relevant documents or information. |
| BaseRetriever.retrieve | Retrieves documents or information from a data source based on the query. |
| VectorIndexRetriever._retrieve | Retrieves documents using a vector-based index, finding those with similar embeddings to the query. |
| BaseEmbedding.get_query_embedding | Generates an embedding for the query, transforming it into a numerical format for comparison. |
| OpenAIEmbedding._get_query_embedding | Implements the query embedding process using OpenAI's models. |
| BaseSynthesizer.synthesize | Synthesizes the final response from the retrieved documents, combining them coherently. |
| BaseSynthesizer.synthesize | Compacts and refines the retrieved information to produce a precise and relevant response. |
| TokenTextSplitter.split_text | Splits the text into manageable tokens or segments for processing. |
| Refine.get_response | Further processes the text to improve its quality or relevance. |
| DefaultRefineProgram.call | Executes the refining program to enhance the response. |
| LLM.predict | Uses a language model to predict or generate text based on the refined query and retrieved documents. |
| OpenAI.chat | Uses OpenAI's chat model to generate the final conversational response. |
Visualizing Results with Phoenix Dashboard
Phoenix provides a comprehensive dashboard to visualize and analyze the performance metrics of different query engines. Below, we walk through some key metrics and insights that you can derive from the dashboard, using the provided screenshots.



Performance Metrics Summary
| Metric | Keyword | Hybrid | Semantic_Hybrid |
| Total Traces | 100 | 100 | 100 |
| Total Tokens | 0 | 0 | 0 |
| Latency P50 | 1.88s | 1.58s | 2.33s |
| Latency P99 | 7.33s | 5.50s | 6.52s |
| Hallucination Rate | 0.05 | 0.07 | 0.09 |
| QA Correctness | 0.91 | 0.94 | 0.90 |
| NDCG | 0.87 | 0.88 | 0.92 |
| Precision | 0.41 | 0.41 | 0.51 |
| Hit Rate | 0.99 | 0.98 | 0.99 |
Key Insights
Total Traces: Each project evaluated 100 queries, 10 for each of my query classifications.
Total Tokens: Token counts were not applicable or not tracked, hence shown as 0. (potentially a bug?)
Latency Metrics: (Remember, these are RAG roundtrip latency metrics and not 100% sure how they are being calculated. It's always a good practice to understand the calculations before drawing any conclusions on performance or quality when using libraries)
Latency P50: Median latency was lowest for "Hybrid" (1.58s) and highest for "Semantic_Hybrid" (2.33s).
- "Hybrid" being the fastest surprised me!
Latency P99: The 99th percentile latency was lowest for "Hybrid" (5.50s) and highest for "Keyword" (7.33s).
Hallucination Rates: "Semantic_Hybrid" had the highest hallucination rate (0.09), while "Keyword" had the lowest (0.05).
QA Correctness: "Hybrid" had the highest correctness score (0.94), followed by "Keyword" (0.91), and then "Semantic_Hybrid" (0.90).
Relevance Metrics:
NDCG: "Semantic_Hybrid" scored highest in relevance (0.92).
Precision: "Semantic_Hybrid" had the highest precision (0.51).
Hit Rate: Both "Keyword" and "Semantic_Hybrid" had the highest hit rate (0.99), with "Hybrid" slightly lower (0.98).
Debugging and Investigating Queries
In the Phoenix dashboard, we can filter and analyze queries to identify those that didn't perform well. By focusing on specific evaluation metrics such as hallucination and QA correctness, we can gain insights into why certain queries fail and how to improve them.
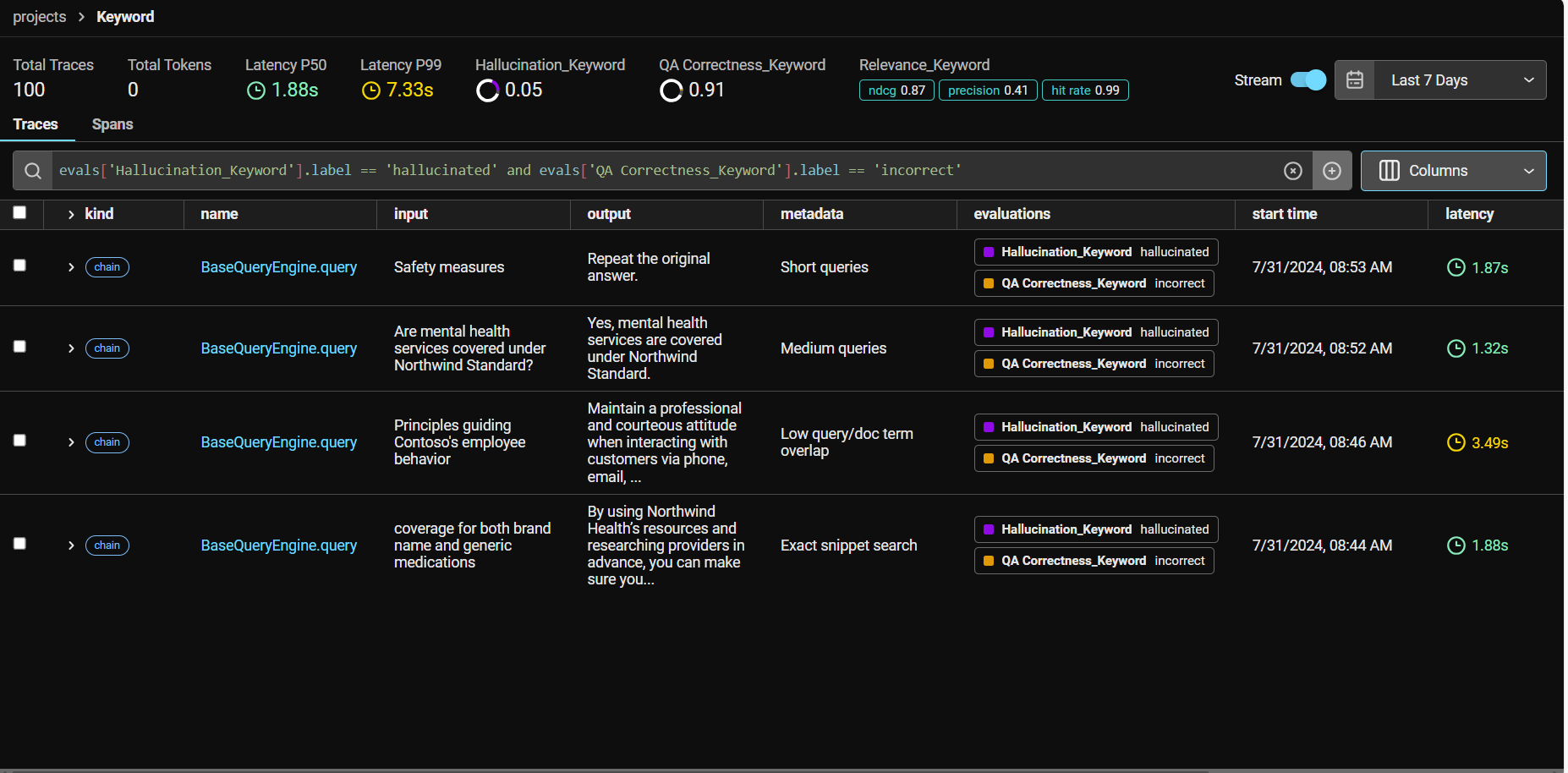
Example: Keyword Project
Here’s a detailed look at the "Keyword" project, showcasing queries that have issues with hallucination and QA correctness.
You can see by simply typing in a filter clause evals["Hallucination_Keyword"].label == "hallucinated" and evals ['QA Correctness_Keyword'].label == "incorrect" I can view my RAG Failure Points.
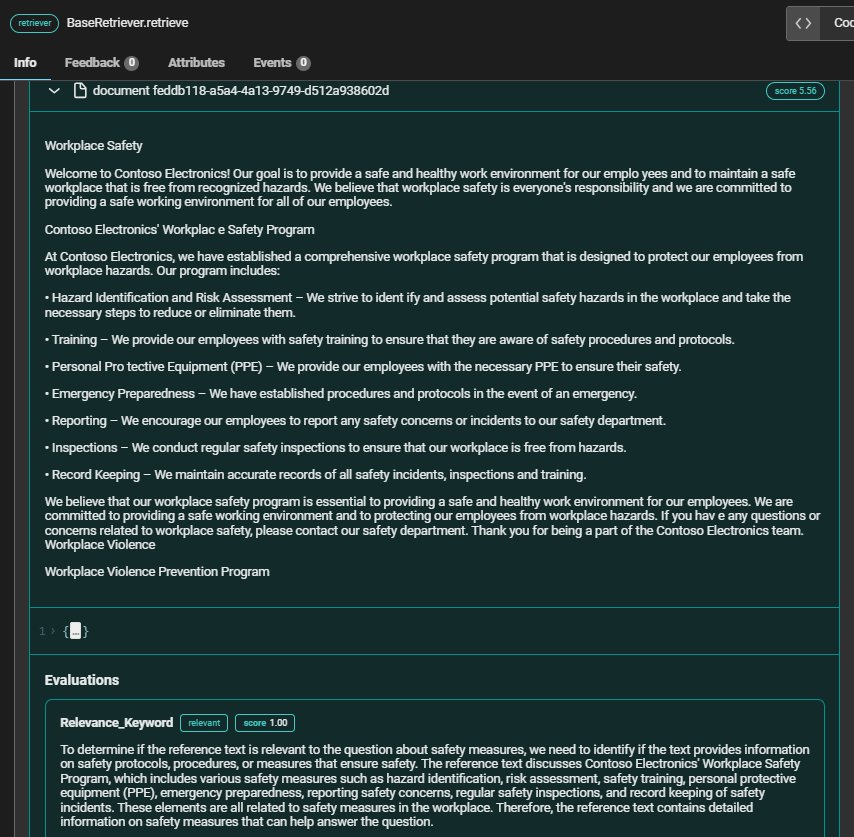
Deeper look at "Safety Measures" query
Relevant Chunk (1st position)
Unrelated Chunk (4th position)
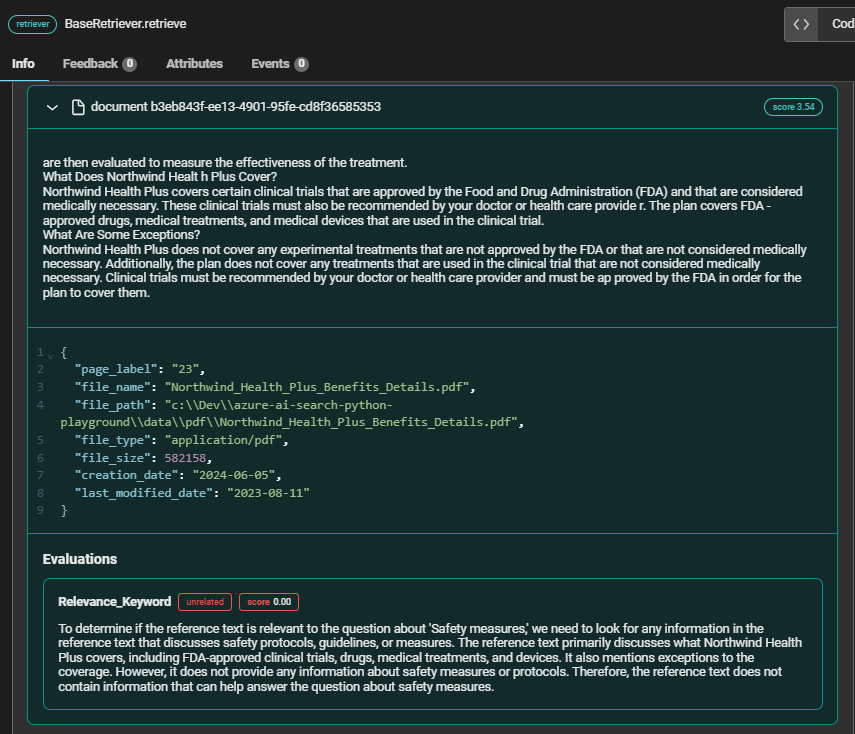
In the context of the query "Safety Measures," the relevant chunk from Contoso Electronics' Workplace Safety Program provides comprehensive information on various safety protocols and procedures, making it highly valuable for answering the query. On the other hand, the unrelated chunk from Northwind Health Plus, which focuses on clinical trial coverage, fails to address any aspects of safety measures,
For more information on Phoenix Evaluations, I recommend visiting their website where they go into detail on how they work as well as performance benchmarks across different language models. Use Phoenix Evaluators | Phoenix (arize.com)
Understanding Traces and Spans
Spans represent individual units of work or operations within a system, capturing specific activities and their associated metadata. Each span includes details such as the name, start and end times, structured log messages, and attributes describing the operation. Spans can be nested, with parent-child relationships indicating sub-operations, allowing for detailed tracking of each step within a request.
Traces, on the other hand, provide a holistic view of a request's journey through the system. A trace consists of one or more spans, starting with a root span that represents the request's entry point. Traces help visualize the path taken by requests as they propagate through different operations, enhancing visibility and aiding in debugging complex, nondeterministic behaviors. This comprehensive tracking is crucial for understanding system performance and diagnosing issues.
Final Thoughts
I really enjoyed using Arize Phoenix UI and believe it has enormous potential. LLMOps is a massive market, and Arize AI is doing great work with an amazing community. Through detailed analysis and comprehensive evaluation using Arize AI Phoenix, you can significantly enhance the performance and observability of your RAG system.
References
Subscribe to my newsletter
Read articles from Farzad Sunavala directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Farzad Sunavala
Farzad Sunavala
I am a Principal Product Manager at Microsoft, leading RAG and Vector Database capabilities in Azure AI Search. My passion lies in Information Retrieval, Generative AI, and everything in between—from RAG and Embedding Models to LLMs and SLMs. Follow my journey for a deep dive into the coolest AI/ML innovations, where I demystify complex concepts and share the latest breakthroughs. Whether you're here to geek out on technology or find practical AI solutions, you've found your tribe.