Guía para hacer un Análisis Exploratorio de Datos en R
 Gabriel Saco
Gabriel Saco
En este artículo, te guiaré de manera práctica sobre cómo realizar un Análisis Exploratorio de Datos en R. Este análisis es una etapa fundamental, pero puede tener una metodología diferente, dependiendo de la base datos con la que se trabaje. Su objetivo es proporcionar una comprensión profunda de la estructura, características y relaciones dentro del conjunto de datos, así como identificar patrones.
El Análisis Exploratorio de Datos permite detectar valores atípicos, errores y tendencias que podrían influir en los resultados del análisis posterior. Además, facilita la generación de hipótesis y la selección de métodos analíticos apropiados. En resumen, un análisis efectivo es crucial para garantizar la validez y fiabilidad de cualquier modelo predictivo o análisis estadístico que se construya posteriormente.
Para seguir este tutorial, te recomendamos descargar la base de datos que utilizaremos. Una vez que hayas descargado la base de datos, sigue los pasos a continuación para abrirla y comenzar el análisis en RStudio. A lo largo de este artículo, te proporcionaremos instrucciones detalladas y ejemplos de código que te permitirán replicar y adaptar tus propios conjuntos de datos.
Etapa 1: Procesamiento de los datos
Paso 1: Preparación del Entorno
Primero, limpiamos el entorno de trabajo para evitar conflictos con datos o variables previas. Luego, cargamos la base de datos utilizando el siguiente código:
rm(list=ls())
votes <- readRDS("/Users/gabrielsaco/Desktop/votes.rds")
Paso 2: Entender el Conjunto de Datos
La columna vote en nuestro conjunto de datos contiene los siguientes valores que representan el voto de cada país:
1 = Sí
2 = Abstenerse
3 = No
8 = No presente
9 = No es miembro
Nuestro objetivo es limpiar los datos eliminando las observaciones que no son de interés ("No presente" y "No es miembro"). También, tenemos una columna session que indica el número de sesión de la ONU. Dado que la ONU comenzó a votar en 1946 y celebra una sesión al año, podemos calcular el año de una resolución sumando 1945 al número de sesión.
Además, la columna ccode contiene códigos de países, los cuales no son ideales para el análisis, ya que preferimos trabajar con nombres de países reconocibles. Utilizaremos el paquete countrycode para traducir estos códigos.
Paso 3: Procesamiento de Datos
Utilizaremos las bibliotecas dplyr y countrycode para filtrar y transformar los datos. A continuación, se muestra cómo hacerlo:
library(dplyr)
library(countrycode)
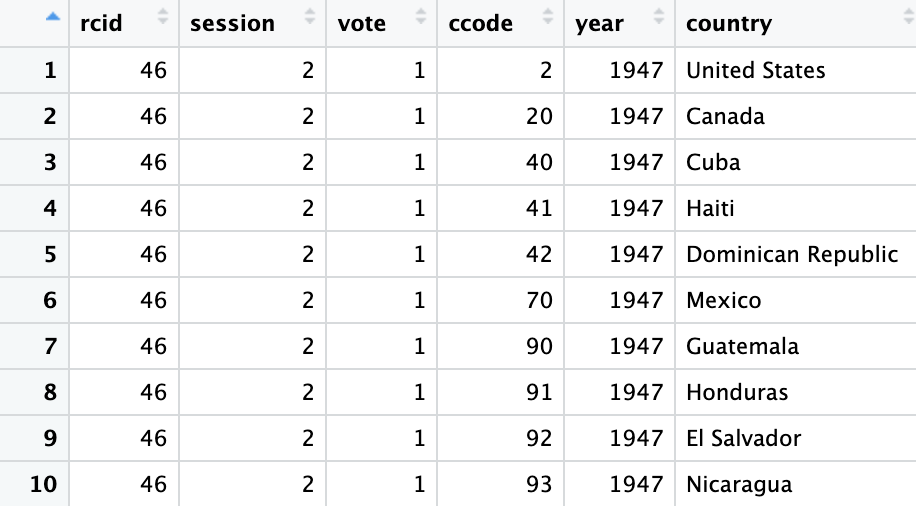
votes_processed <- votes %>%
filter(vote <= 3) %>%
mutate(year = session + 1945,
country = countrycode(ccode, "cown", "country.name"))
Paso 4: Cálculo del Porcentaje de Votos "Sí"
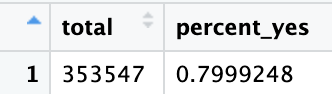
En este análisis, nos centraremos en el porcentaje de votos que son "Sí" como una métrica de la "amabilidad" de los países. Empezaremos por encontrar este resumen para todo el conjunto de datos:
votes_summary <- votes_processed %>%
summarize(total = n(), percent_yes = mean(vote == 1))
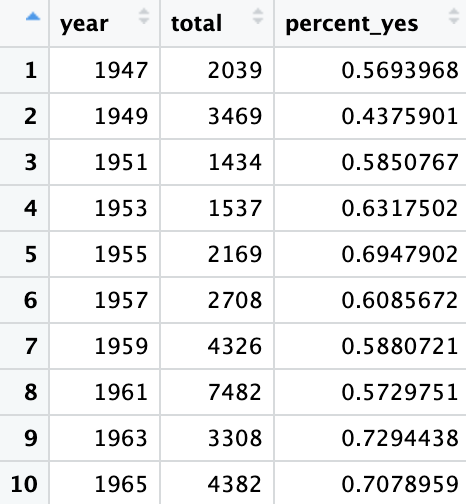
La función summarize() es especialmente útil porque se puede usar dentro de grupos. Por ejemplo, si queremos saber cómo cambió la "amabilidad" promedio de los países de un año a otro, podemos agrupar los datos por año:
per_year <- votes_processed %>%
group_by(year) %>%
summarize(total = n(), percent_yes = mean(vote == 1))
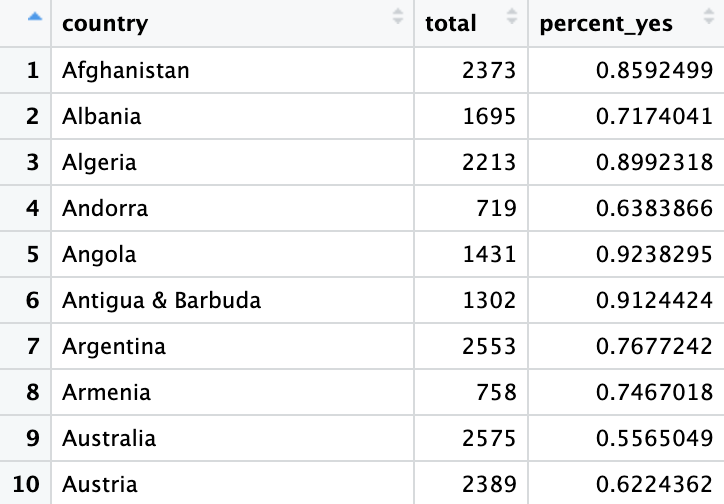
De manera similar, podríamos usar summarize() para analizar los patrones de votación de cada país:
per_country <- votes_processed %>%
group_by(country) %>%
summarize(total = n(), percent_yes = mean(vote == 1))
Hasta aquí, hemos procesado nuestros datos para el análisis exploratorio. Hemos añadido columnas importantes (year, country) y calculado métricas relevantes (percent_yes, total). Además, hemos filtrado datos que no son relevantes para nuestro análisis y mejorado la presentación de algunas variables.
En la siguiente sección del artículo, continuaremos con el análisis exploratorio, explorando visualizaciones y estadísticas descriptivas para entender mejor nuestro conjunto de datos.
Etapa 2: Visualización de los datos
Ahora usaremos el paquete ggplot2 para convertir los resultados en una visualización del porcentaje de votos a favor a lo largo del tiempo.
library(ggplot2)
ggplot(per_year, aes(year, percent_yes)) +
geom_point() + geom_smooth()
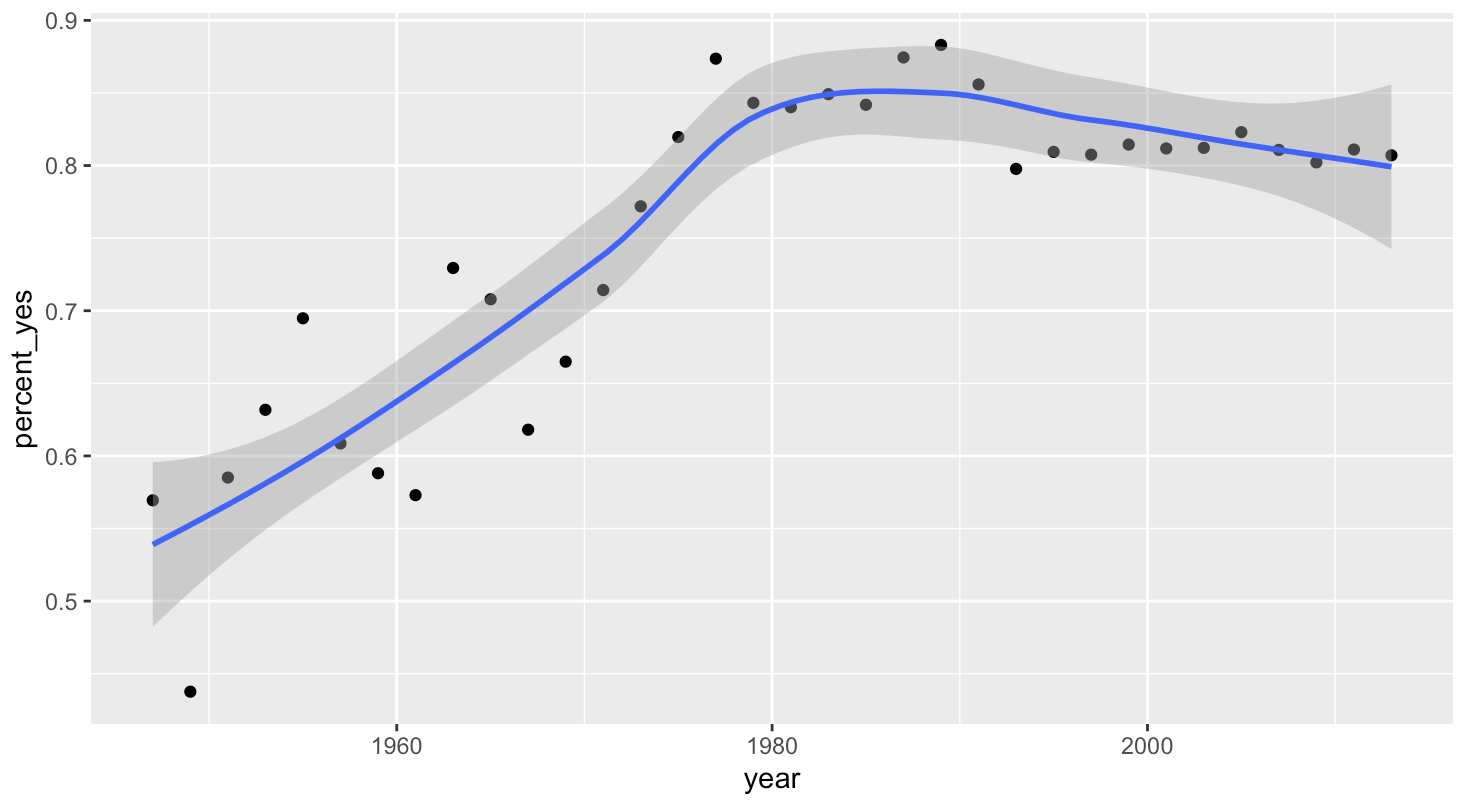
Está más interesado en las tendencias de votación dentro de países específicos que en la tendencia general. Por lo tanto, en lugar de resumir solo por año, haga un resumen por año y país, construyendo un conjunto de datos que muestre qué fracción de las veces cada país vota "sí" cada año.
per_year_country <- votes_processed %>%
group_by(year, country) %>%
summarize(total = n(),
percent_yes = mean(vote == 1))
Ahora que tiene el porcentaje de veces que cada país votó "sí" dentro de cada año, puede trazar la tendencia para un país en particular. En este caso, observará la tendencia solo para Perú. Esto implicará usar filter() en tus datos antes de dárselos a ggplot2.
peru_per_year <- per_year_country %>%
filter(country == "Peru")
ggplot(peru_per_year, aes(x=year, y= percent_yes)) + geom_line()
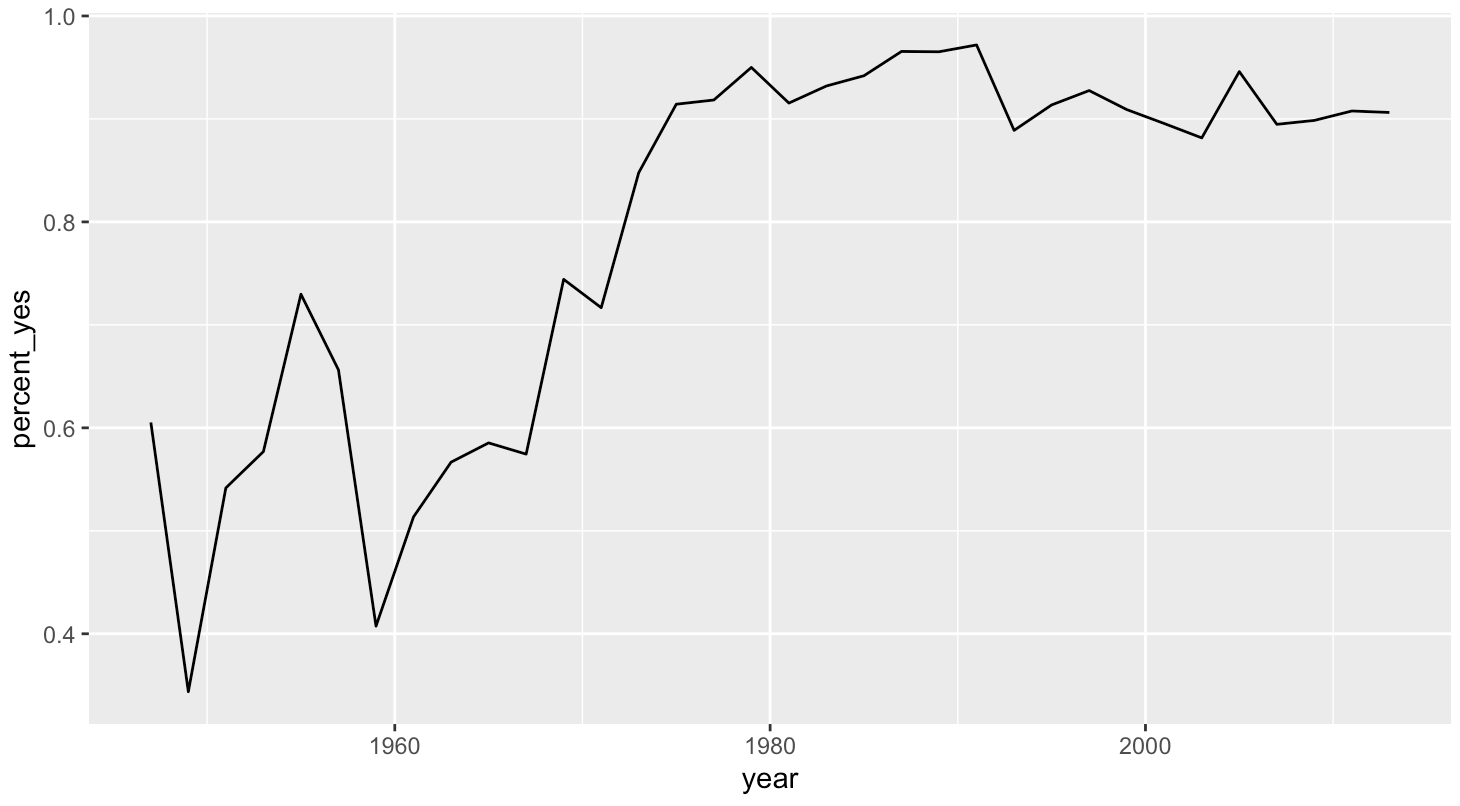
Aunque trazar solo un país a la vez es interesante, lo que realmente quieres es comparar las tendencias entre países. Por ejemplo, supongamos que desea comparar las tendencias de votación de Estados Unidos, Reino Unido, Francia e India.
countries <- c("United States", "United Kingdom",
"France", "India")
countries4 <- per_year_country %>%
filter(country %in% countries)
ggplot(countries4, aes(x=year, y=percent_yes, color = country)) + geom_line()
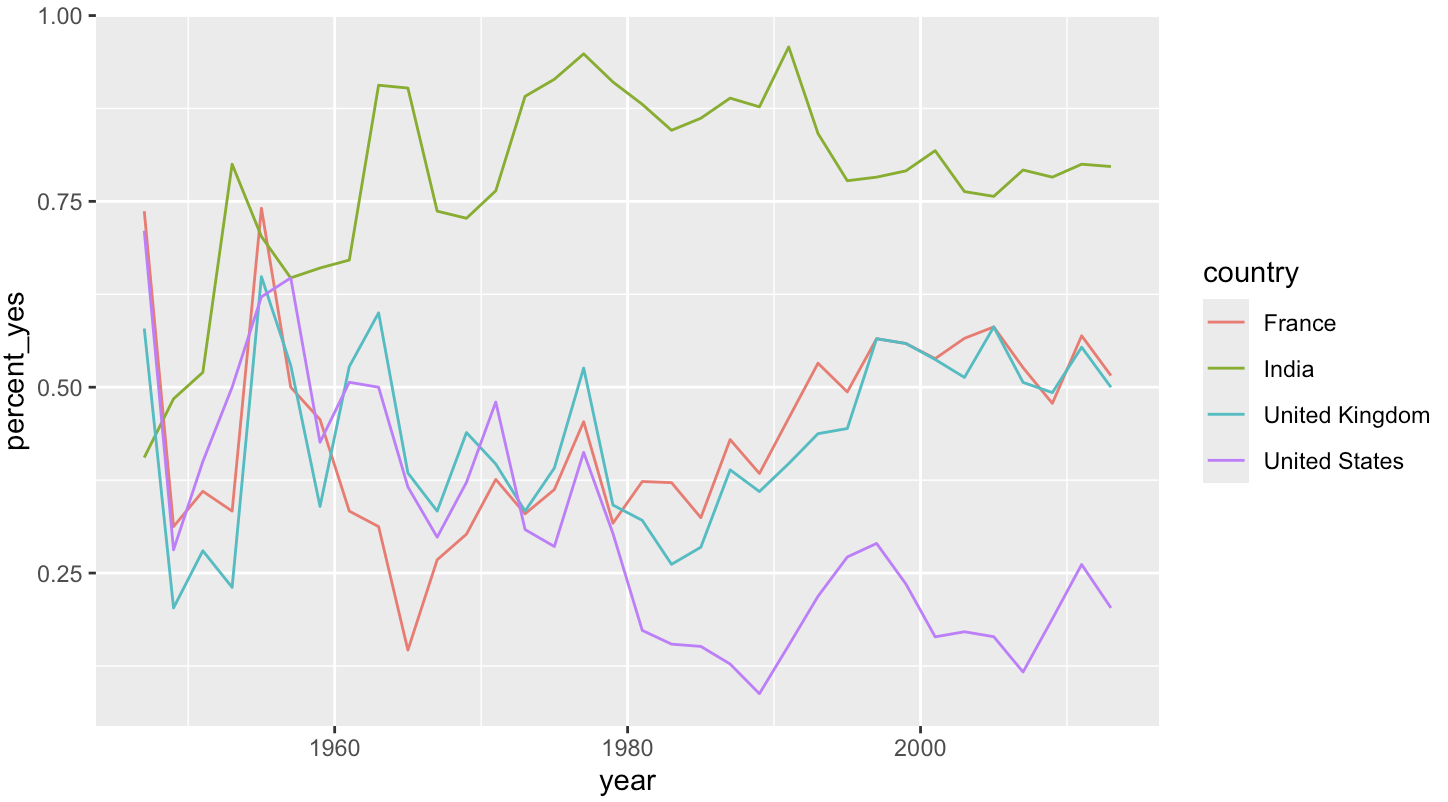
Etapa 3: Regresiones lineales
Una regresión lineal es un modelo que nos permite examinar cómo cambia una variable con respecto a otra ajustando una línea de mejor ajuste. Se hace con la función lm() en R. Aquí, ajustará una regresión lineal solo al porcentaje de votos a favor de Perú.
peru_per_year <- per_year_country %>%
filter(country == "Peru")
peru_reg = lm(percent_yes ~ year, peru_per_year)
En la última sección, se ajusta un modelo lineal. Ahora, usarás la función tidy() en el paquete broom para convertir ese modelo en un marco de datos ordenado
library(broom)
print(tidy(peru_reg))

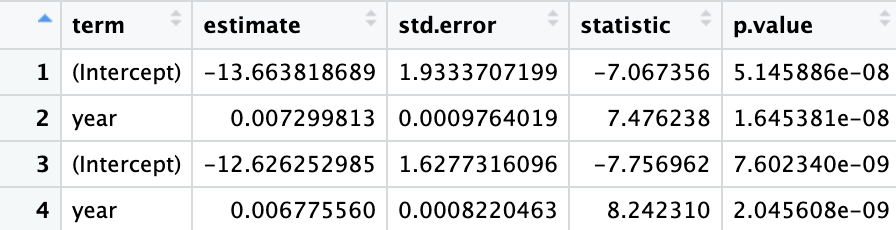
Una ventaja importante de cambiar los modelos a marcos de datos ordenados es que se pueden combinar. En una sección anterior, ajusta un modelo lineal al porcentaje de votos a favor de cada año en los Peru. Ahora ajustará el mismo modelo para Chile y combinará los resultados de ambos países.
chile_per_year <- per_year_country %>%
filter(country == "Chile")
chile_reg = lm(percent_yes ~ year, chile_per_year)
peru_tidied = tidy(peru_reg)
chile_tidied = tidy(chile_reg)
mix = bind_rows(peru_tidied, chile_tidied)
print(mix)
En este momento, el marco de datos per_year_country tiene una fila por par de países y votos. Para que pueda modelar cada país individualmente, va a "anidar" todas las columnas además del país, lo que dará como resultado un marco de datos con una fila por país. Los datos de cada país individual se almacenarán en una columna de lista llamada datos.
library(tidyr)
per_year_country %>%
nest(-country)

Ahora tiene una versión ordenada de cada modelo almacenada en la columna ordenada. Desea combinar todos ellos en un marco de datos grande, de forma similar a cómo combinó anteriormente los modelos ordenados de Perú y Chile. Recordemos que la función unnest() de tidyr logra esto.
country_coef <- per_year_country %>%
nest(-country) %>%
mutate(model = map(data, ~ lm(percent_yes ~ year, data = .)),
tidied = map(model, tidy)) %>%
unnest(tidied)
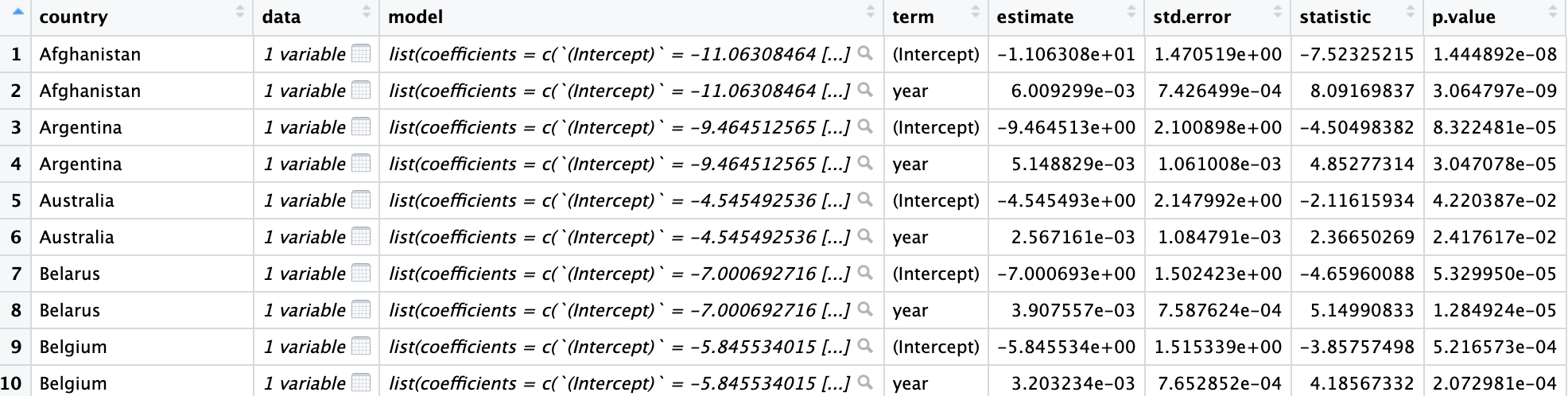
Actualmente tiene los términos de intersección y pendiente para cada modelo por país. Probablemente, estés más interesado en cómo cambia cada uno con el tiempo, por lo que debes centrarte en los términos de la pendiente.
country_coef %>%
filter(term == "year")
No todas las pendientes son significativas, y puede usar el valor p para adivinar cuáles lo son y cuáles no. Sin embargo, cuando tienes muchos valores p, como uno para cada país, te encuentras con el problema de las pruebas de hipótesis múltiples, en las que tienes que establecer un umbral más estricto. La función p.adjust() es una forma sencilla de corregir esto, donde p.adjust(p.value) en un vector de valores p devuelve un conjunto en el que puede confiar. Aquí agregará dos pasos para procesar el conjunto de datos: usar una mutate() para crear la nueva columna de valor p ajustado y filtrar para filtrar los que están por debajo de un umbral de 0,05.
filtered <- country_coef %>%
filter(term == "year") %>%
mutate(p.adjusted = p.adjust(p.value)) %>%
filter(p.adjusted < .05)
Etapa 4: Fusionar bases de datos
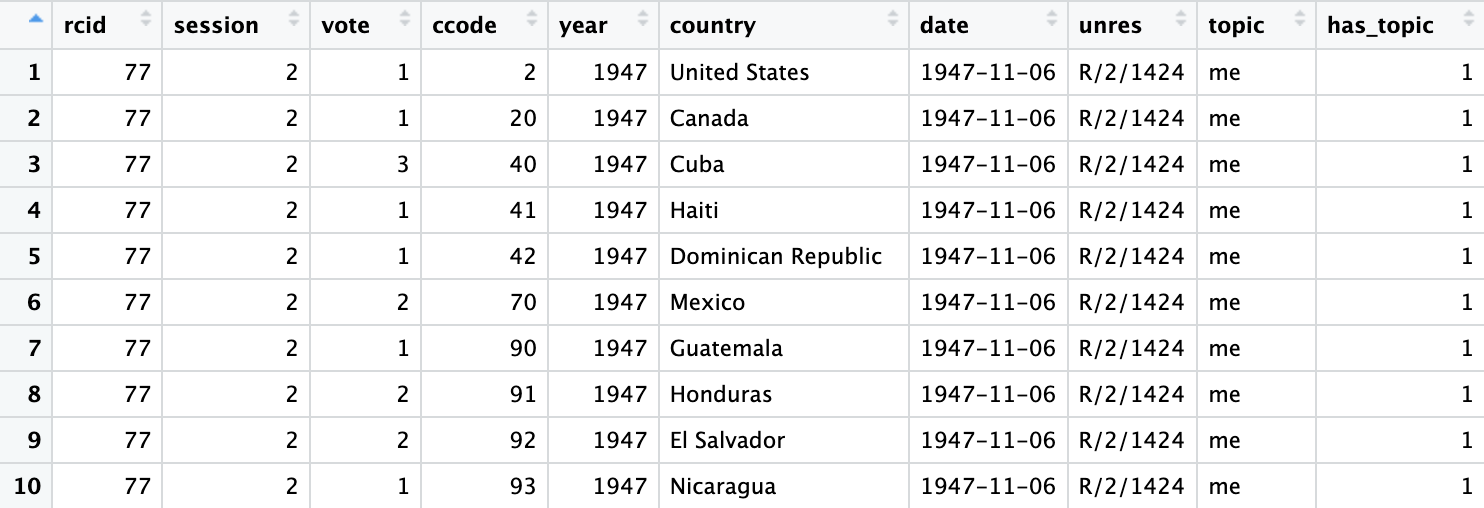
En el primer capítulo, creó el conjunto de datos votes_processed, que contiene información sobre los votos de cada país. Ahora combinará eso con el nuevo conjunto de datos de descripciones, que incluye información sobre temas sobre cada país, para que pueda analizar los votos dentro de temas particulares. Para ello, harás uso de la función inner_join() de dplyr.
description <- readRDS("~/Desktop/descriptions.rds")
votes_joined <- votes_processed %>%
inner_join(description, by = c("rcid","session"))
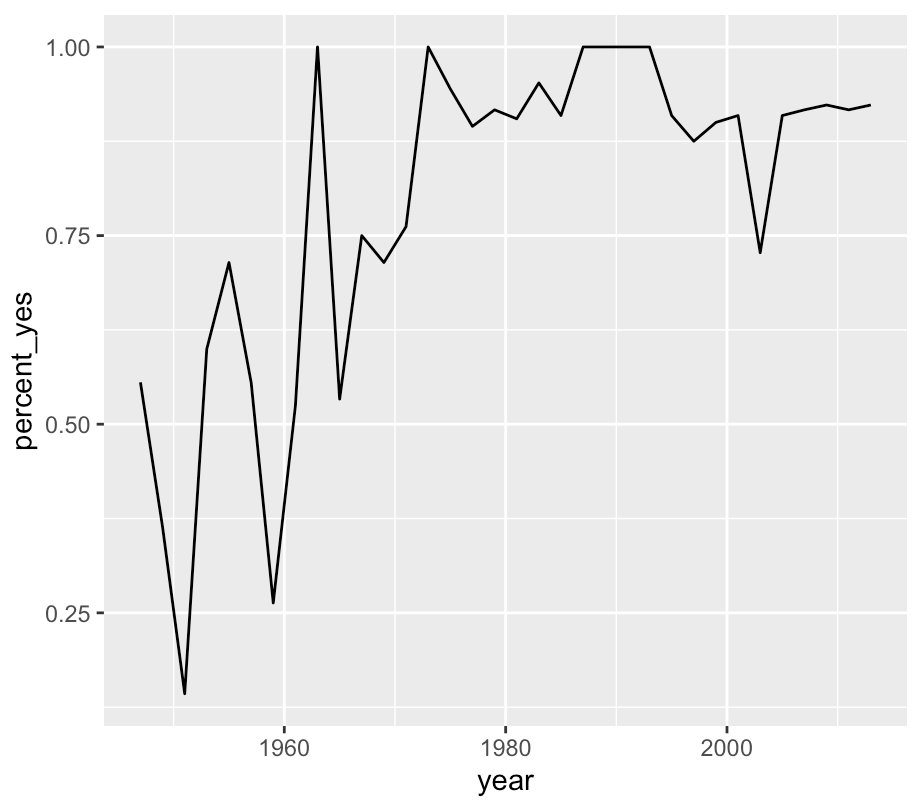
En la parte anterior, graficó el porcentaje de votos cada año en los que Peru votó "sí". Ahora creará el mismo gráfico, pero solo para los votos relacionados con el colonialismo.
peru_co_per_year <- votes_joined %>%
filter(country == "Peru", co == 1) %>%
group_by(year) %>%
summarize(percent_yes = mean(vote == 1))
ggplot(peru_co_per_year, aes(year, percent_yes)) +
geom_line()
Con el fin de representar los datos unidos de votación-tema de una forma ordenada para que podamos analizar y graficar por tema, necesitamos transformar los datos para que cada fila tenga una combinación de país-voto-tema. Esto cambiará los datos de tener seis columnas (me, nu, di, hr, co, ec) a tener dos columnas (topic y has_topic).
votes_joined %>%
gather(topic, has_topic, me:ec)
votes_gathered <- votes_joined %>%
gather(topic, has_topic, me:ec) %>%
filter(has_topic == 1)
Hay un paso más de limpieza de datos para que esto sea más interpretable. En este momento, los temas están representados por códigos de dos letras:
me: Conflicto palestino
nu: Armas nucleares y material nuclear
di: Control de armamentos y desarme
hr: Derechos humanos
co: Colonialismo
ce: Desarrollo económico
Para que pueda interpretar los datos más fácilmente, vuelva a codificar los datos para reemplazar estos códigos con su nombre completo. Puedes hacerlo con la función recode() de dplyr, que reemplaza los valores por los que especifiques:
votes_tidied <- votes_gathered %>%
mutate(topic = recode(topic,
me = "Palestinian conflict",
nu = "Nuclear weapons and nuclear material",
di = "Arms control and disarmament",
hr = "Human rights",
co = "Colonialism",
ec = "Economic development"))
En los ejercicios anteriores, resumió el conjunto de datos de votos por país, por año, y por combinación de país y año. Ahora que tiene el tema como una variable adicional, puede resumir los votos para cada combinación de país, año y tema (por ejemplo, para los Perú en 2013 sobre el tema de las armas nucleares).
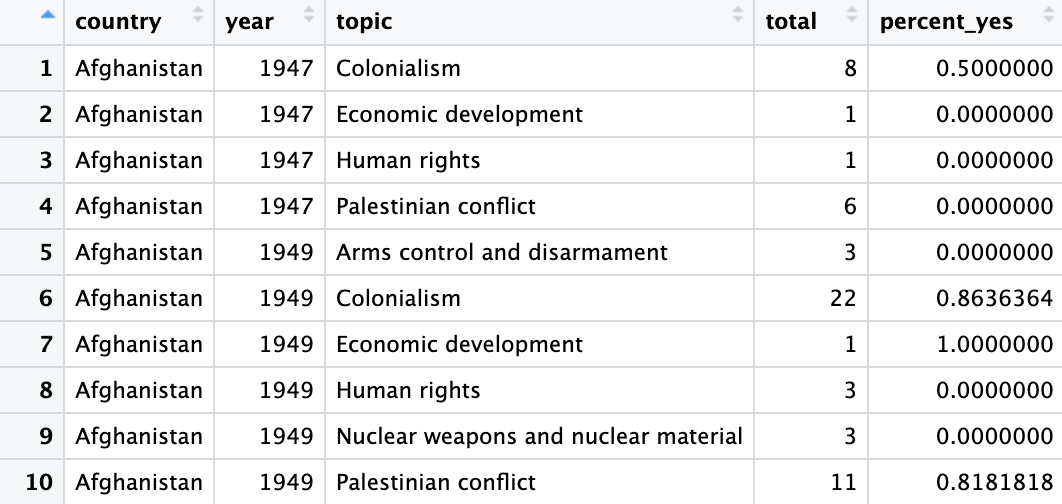
by_country_year_topic <- votes_tidied %>%
group_by(country, year, topic) %>%
summarize(total = n(), percent_yes = mean(vote == 1)) %>%
ungroup()
En el último capítulo, construyó un modelo lineal para cada país anidando los datos en cada país, ajustando un modelo a cada conjunto de datos y, a continuación, ordenando cada modelo y desanidando los coeficientes.
country_topic_coefficients <- by_country_year_topic %>%
nest(-country, -topic) %>%
mutate(model = map(data, ~ lm(percent_yes ~ year, data = . )),
tidied = map(model, tidy)) %>%
unnest(tidied)
A lo largo de su historia, Vanuatu (una nación insular en el Océano Pacífico) cambió drásticamente su patrón de votación sobre el tema del conflicto palestino. Examinemos más de cerca los patrones de votación de este país. Recuerde que el conjunto de datos by_country_year_topic contenía una fila para cada combinación de país, año y tema. Puedes usar eso para crear un gráfico de la votación de Vanuatu, desglosado por tema.
vanuatu_by_country_year_topic <- by_country_year_topic %>%
filter(country == "Vanuatu")
ggplot(vanuatu_by_country_year_topic, aes(x=year, y=percent_yes)) +
facet_wrap(~ topic) + geom_line()
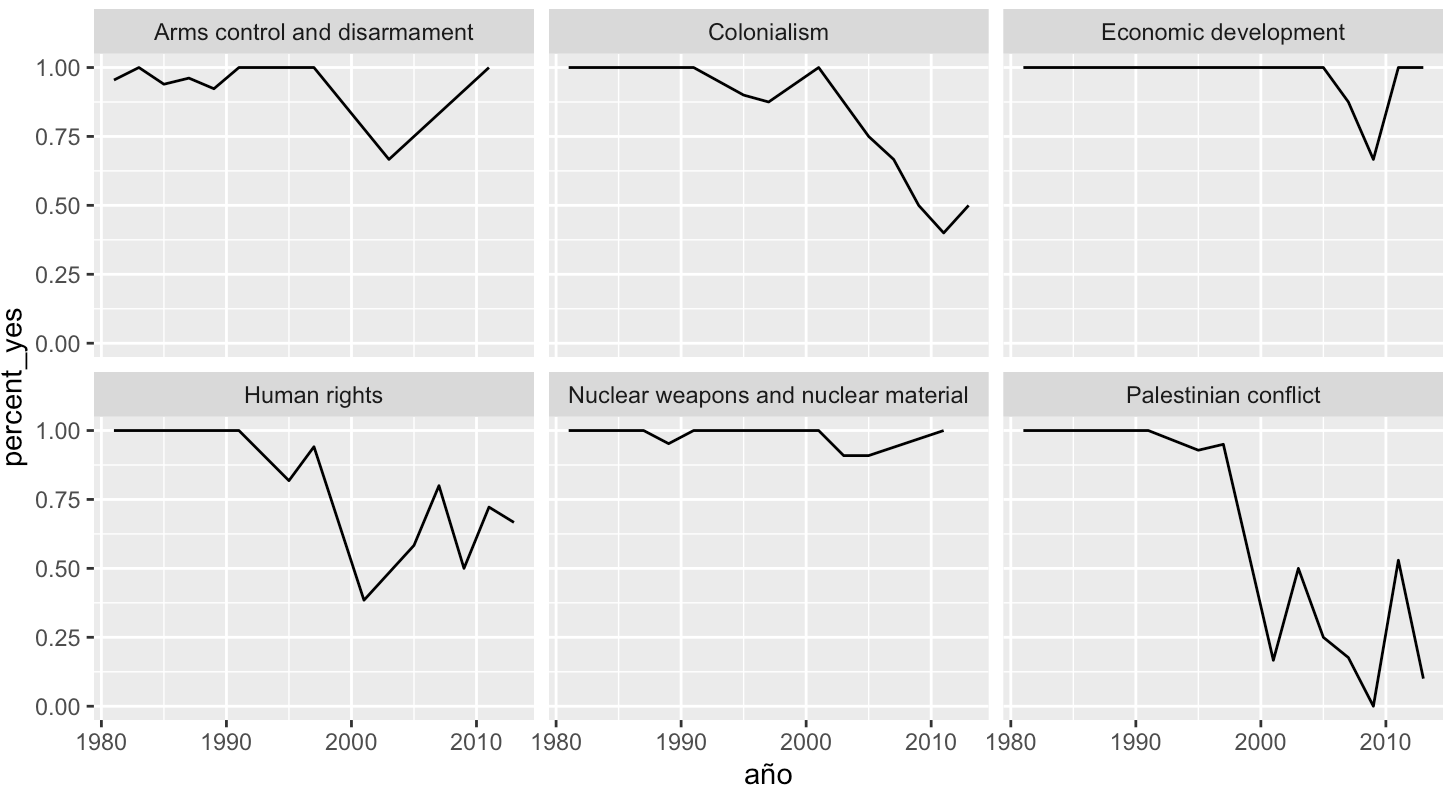
Este resultado es muy llamativo. Así como hallamos este resultado para Vanuatu, pueden haber patrones interesantes para otros países. Por ende, siempre el análisis exploratorio de datos es esencial. Resulta importante destacar que el análisis exploratorio de datos no es un proceso rígido, sino que debe adaptarse a la base de datos con la que se trabaja.
Subscribe to my newsletter
Read articles from Gabriel Saco directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by