Lights, Camera, Algorithms: Developing a Content-Based Movie Recommendation System
 Amey Pote
Amey Pote
Hey there! I'm Amey Pote, and I recently developed a content-based movie recommendation system as part of my machine learning journey. I wanted to share my experience and the steps I took to build this system, leveraging advanced pre-processing techniques, machine learning methods, and text vectorization to provide highly personalized movie recommendations. Let's dive into the process!
Introduction
Recommendation systems have become a crucial part of our daily lives, whether it's for suggesting movies, products, or even friends on social media. They enhance user experience by providing personalized content based on individual preferences. In this blog, I'll walk you through how I built a movie recommendation system using a content-based approach.
Project Flow
To give you a clear picture of the entire process, here's a flow diagram of the project:

Step-by-Step Breakdown:
Data Collection: Gather the dataset.
Data Pre-processing: Clean and prepare the data.
Text Vectorization: Convert text to numerical form.
Similarity Calculation: Measure similarity between movies.
Recommendation Generation: Recommend movies based on similarity scores.
Dataset
I used a dataset downloaded from Kaggle, which contains information about various movies, including their titles, genres, and descriptions. This dataset was perfect for building a content-based recommendation system as it provided rich textual data that could be used to understand the similarities between different movies.
Data Pre-processing
Before diving into the recommendation model, it's essential to clean and pre-process the data. This step ensures that the textual data is in a suitable format for machine learning algorithms. Here are the key steps I followed:
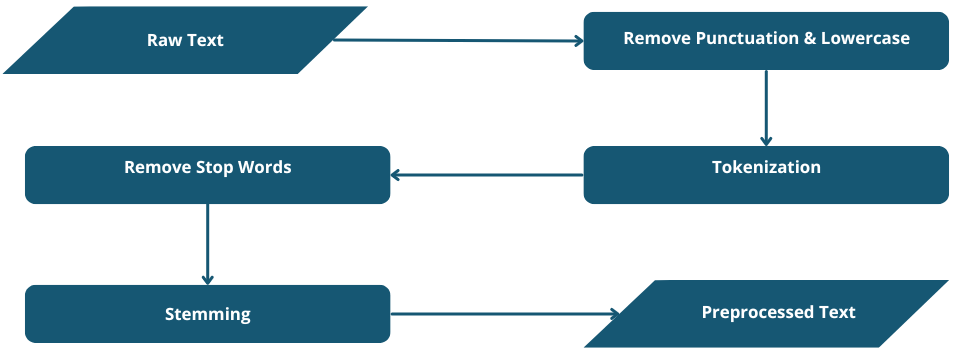
Removing Punctuation and Lowercasing: I removed all punctuation and converted the text to lowercase to ensure uniformity.
Tokenization: I split the text into individual words (tokens) to facilitate further processing.
Stop Words Removal: Common words that don't contribute much to the meaning (e.g., 'the', 'is', 'in') were removed to focus on more significant words.
Stemming: I used the Porter Stemmer to reduce words to their root forms. For example, 'running' and 'runner' become 'run'. This helps in reducing the vocabulary size and improving the model's performance.
Pre-processing Flow Diagram :
Text Vectorization
To convert the textual data into numerical form, I used the Count Vectorizer. This technique creates a matrix of token counts, representing the frequency of each word in the dataset. The resulting matrix is used to measure the similarity between different movies.
Text Vectorization Flow Diagram :

Building the Recommendation Model
With the pre-processed and vectorized data, I proceeded to build the recommendation model. I used the Cosine Similarity metric to measure the similarity between movie descriptions. Cosine Similarity calculates the cosine of the angle between two vectors, providing a measure of how similar they are. Here’s how I implemented it:
Vectorizing the Data: I transformed the movie descriptions into vectors using the Count Vectorizer.
Calculating Cosine Similarity: I computed the cosine similarity between all pairs of movie vectors. This resulted in a similarity matrix where each entry represents the similarity score between two movies.
Recommending Movies: For a given movie, I sorted the similarity scores in descending order and recommended the top N movies with the highest similarity scores.
Recommendation Model Flow Diagram :

Implementation
Here’s a high-level overview of the implementation steps in Python:
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from nltk.stem.porter import PorterStemmer
from nltk.corpus import stopwords
import string
# Load dataset
movies = pd.read_csv('movies.csv')
# Pre-processing function
def preprocess(text):
# Remove punctuation
text = text.translate(str.maketrans('', '', string.punctuation))
# Convert to lowercase
text = text.lower()
# Tokenize
words = text.split()
# Remove stop words
words = [word for word in words if word not in stopwords.words('english')]
# Stemming
stemmer = PorterStemmer()
words = [stemmer.stem(word) for word in words]
return ' '.join(words)
# Apply pre-processing
movies['processed_description'] = movies['description'].apply(preprocess)
# Vectorization
vectorizer = CountVectorizer()
vectors = vectorizer.fit_transform(movies['processed_description'])
# Calculate Cosine Similarity
similarity_matrix = cosine_similarity(vectors)
# Function to recommend movies
def recommend_movies(movie_title, num_recommendations=5):
movie_index = movies[movies['title'] == movie_title].index[0]
similarity_scores = list(enumerate(similarity_matrix[movie_index]))
similarity_scores = sorted(similarity_scores, key=lambda x: x[1], reverse=True)
recommended_movie_indices = [score[0] for score in similarity_scores[1:num_recommendations+1]]
return movies['title'].iloc[recommended_movie_indices]
# Example usage
recommendations = recommend_movies('The Matrix', 5)
print(recommendations)
Conclusion
Building this content-based movie recommendation system was an enriching experience. By leveraging text pre-processing, vectorization, and cosine similarity, I was able to create a model that provides personalized movie recommendations. This project not only enhanced my understanding of natural language processing and machine learning but also showcased the potential of content-based filtering in recommendation systems.
Subscribe to my newsletter
Read articles from Amey Pote directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by