Machine Learning and Deep Learning Models in NLP
 Jyoti Maurya
Jyoti Maurya
Natural Language Processing (NLP) leverages various machine learning (ML) and deep learning (DL) models to understand, interpret, and generate human language. Below table shows the ML and DL models categorized based on various NLP tasks
| Task | ML Model | DL Model |
| Text Classification | Naive Bayes, SVM, Logistic Regression, K-Nearest Neighbors (KNN), Decision Trees, Random Forest, Gradient Boosting Machines (GBM), XGBoost | FastText, Deep Averaging Networks (DAN), Hierarchical Attention Networks (HAN), XLNet, DistilBERT |
| Sentiment Analysis | Naive Bayes, SVM, Logistic Regression, AdaBoost, Linear Discriminant Analysis (LDA), Extra Trees, k-Means Clustering (unsupervised) | TextCNN, ELMo, ALBERT, ELECTRA, RoBERTa |
| Named Entity Recognition | CRF, HMM, Maximum Entropy Markov Models (MEMM), Perceptron Tagger, Support Vector Machines (SVM) with custom kernels | BiLSTM-CNN-CRF, Flair Embeddings, SpaCy's Transformer, FLAIR, LUKE |
| Machine Translation | IBM Model 1-5 (Statistical), Moses (Phrase-based SMT), Phrase-Based Statistical MT | Attention Mechanism (Bahdanau and Luong), OpenNMT, MarianNMT, BART, mBART (multilingual BART) |
| Question Answering | Memory Networks, DrQA (Document Reader QA), Information Retrieval-based | BiDAF (Bi-Directional Attention Flow), ELMo-based QA models, ALBERT for QA, T5 (Text-to-Text Transfer Transformer), Reformer |
| Text Generation | Markov Chains, Hidden Semi-Markov Models, N-gram Model | RNN-RBM, Char-RNN, Transformer-XL, GPT-Neo, CTRL |
| Text Summarization | Latent Semantic Analysis (LSA), K-means Summarizer, Extractive Methods | Pointer-Generator Networks, BERTSUM, UniLM, ProphetNet, BigBird |
| Speech Recognition and Processing | Dynamic Time Warping (DTW), Gaussian Mixture Model (GMM), HMM | Deep Speech, Jasper (Just Another Speech Recognizer), Transformer Transducer, Conformer (Convolution-augmented Transformer), DeepMind's WaveNet |
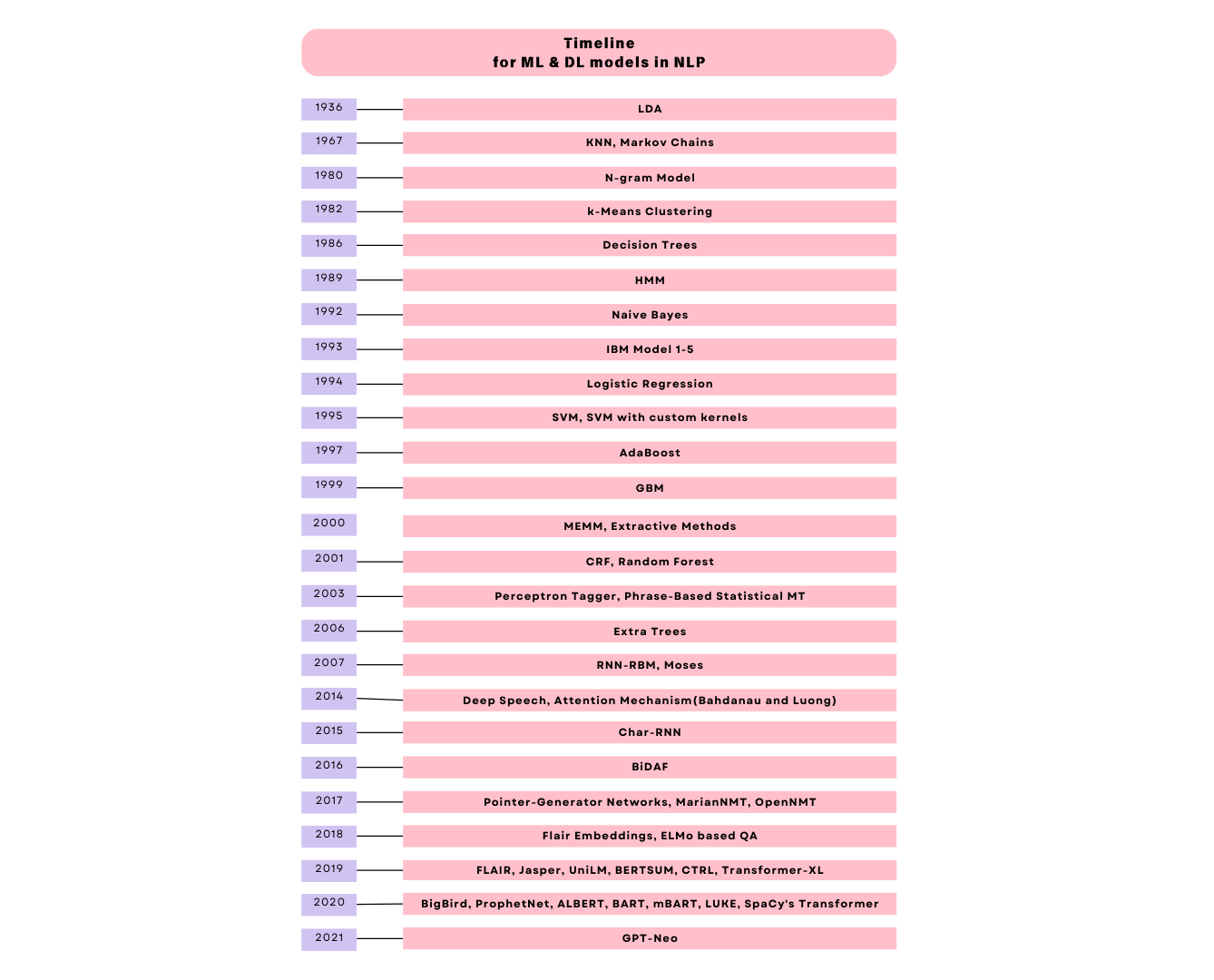
The following diagram shows the timeline of development of these ML and DL models.
ML Models
1. Text Classification
Naive Bayes: Naive Bayes is a probabilistic classifier based on Bayes' Theorem, assuming independence between features. It calculates the probability of each class given a set of features and assigns the class with the highest probability. Despite its simplicity, it performs surprisingly well on various text classification tasks due to the often-strong independence assumptions. [1]
SVM: SVM is a powerful classifier that works by finding the hyperplane that best separates the data into different classes. It can handle high-dimensional spaces and is effective in cases where the number of dimensions exceeds the number of samples. SVMs are particularly known for their robustness in text classification tasks. [2]
Logistic Regression: Logistic Regression is a linear model used for binary classification. It estimates the probability that a given input belongs to a certain class using the logistic function. The model is simple, easy to implement, and interpretable, making it a popular choice for text classification. [3]
K-Nearest Neighbors (KNN): KNN is a non-parametric, instance-based learning algorithm. For classification, it assigns the class of the majority of the k-nearest neighbors of a data point in the feature space. It is simple and effective for small datasets, though computationally intensive for large ones. [4]
Decision Trees: Decision Trees are a non-parametric supervised learning method used for classification and regression. They work by splitting the data into subsets based on the value of input features, resulting in a tree-like structure of decisions. They are easy to interpret and visualize but can be prone to overfitting. [5]
Random Forest: Random Forest is an ensemble learning method that constructs multiple decision trees during training and outputs the mode of the classes for classification. It improves the robustness and accuracy of individual decision trees by averaging their results, reducing overfitting. [6]
Gradient Boosting Machines (GBM): GBM is an ensemble technique that builds trees sequentially, with each tree correcting the errors of the previous one. This boosting method can create strong predictive models by combining the strengths of many weak learners. It is particularly effective in handling various types of data and tasks. [7]
XGBoost: XGBoost is an optimized implementation of gradient boosting designed for speed and performance. It includes several advanced features such as regularization to prevent overfitting, parallel computation, and efficient handling of missing data, making it highly effective for a wide range of applications. [8]
2. Sentiment Analysis
Naive Bayes [1]
SVM [2]
Logistic Regression [3]
AdaBoost: AdaBoost, short for Adaptive Boosting, combines multiple weak classifiers to form a strong classifier. It adjusts the weights of incorrectly classified instances so that subsequent classifiers focus more on these harder cases. It is effective in improving the performance of weak classifiers and is versatile in various classification tasks. [9]
Linear Discriminant Analysis (LDA): LDA is a dimensionality reduction technique and a classifier that finds the linear combinations of features that best separate different classes. It assumes normally distributed data and equal covariance matrices for classes. LDA is useful for reducing the feature space while maintaining class-discriminatory information. [10]
Extra Trees: Extra Trees is an ensemble method similar to Random Forest but differs in the way it splits nodes. It uses random splits for each feature, making the model less biased and reducing variance. This randomness can lead to improved performance and faster computations. [11]
k-Means Clustering (unsupervised): k-Means is an unsupervised learning algorithm used for clustering. It partitions the dataset into k clusters by minimizing the within-cluster variance. Each data point is assigned to the nearest cluster centroid, and the centroids are iteratively updated until convergence. It is simple and effective for clustering large datasets. [12]
3. Named Entity Recognition (NER)
CRF: CRF is a statistical modeling method used for structured prediction, commonly applied to sequence labeling tasks like NER. It models the conditional probability of the label sequence given the observed sequence, considering the context of neighboring labels. This allows CRFs to capture dependencies between labels, improving accuracy over simpler models like HMMs. [13]
HMM: HMM is a statistical model that represents sequences of observable events generated by hidden states. Each state has a probability distribution over the possible observations. HMMs are widely used for sequence labeling tasks such as part-of-speech tagging and NER due to their ability to model sequential data. [14]
Maximum Entropy Markov Models (MEMM): MEMM combines the advantages of Maximum Entropy models and HMMs for sequence labeling. Unlike HMMs, MEMMs do not assume independence between features and can incorporate a rich set of features, improving performance on tasks like NER by modeling the probability of the next state given the current state and observation. [15]
Perceptron Tagger: The Perceptron Tagger is a linear classifier used for sequence labeling tasks. It uses the perceptron algorithm to predict the sequence of labels for a given sequence of inputs. The model is simple and fast, making it suitable for real-time applications like NER and part-of-speech tagging. [16]
Support Vector Machines (SVM) with custom kernels [2]
4. Machine Translation
IBM Model 1-5 (Statistical): IBM Models 1-5 are a series of statistical translation models developed for machine translation. They introduce various complexities and refinements, from simple word-to-word alignment (Model 1) to more sophisticated phrase structures (Model 5). These models laid the groundwork for statistical machine translation by formalizing the probabilistic framework for translation tasks. [17]
Moses (Phrase-based SMT): Moses is an open-source toolkit for phrase-based statistical machine translation. It translates text by splitting sentences into sequences of phrases and translating each phrase independently. The toolkit incorporates various advanced techniques like reordering and tuning, making it a powerful tool for building translation systems. [18]
Phrase-Based Statistical MT [18]
5. Question Answering (QA)
Memory Networks: Memory Networks are designed to reason with inference components and a long-term memory. They read and write to memory and use attention mechanisms to focus on relevant information when answering questions. This architecture is particularly effective for tasks requiring contextual understanding and multi-step reasoning. [19]
DrQA (Document Reader QA): DrQA is a QA system developed by Facebook AI Research that combines a document retriever and a document reader. The retriever finds relevant documents from a large corpus, and the reader extracts precise answers from these documents. DrQA has been used in open-domain QA tasks, demonstrating high accuracy and efficiency. [20]
Information Retrieval-based: Information Retrieval-based QA systems rely on retrieving relevant documents or passages from a large corpus in response to a query. These systems use various retrieval algorithms to rank and select the most relevant texts, which are then used to generate answers. This approach is effective for quickly finding information in large datasets. [21]
6. Text Generation
Markov Chains: Markov Chains are mathematical systems that undergo transitions from one state to another on a state space. They rely on the Markov property, which states that the next state depends only on the current state. Markov Chains are used for text generation by modeling the probability of a sequence of words and generating new sequences based on these probabilities. [22]
Hidden Semi-Markov Models: Hidden Semi-Markov Models extend HMMs by allowing the hidden states to follow semi-Markov processes. This means the duration of staying in a state can vary, enabling better modeling of time-series data where state durations are not constant. These models are used in various applications, including speech and handwriting recognition. [23]
N-gram Model: N-gram models are probabilistic language models that predict the next item in a sequence based on the previous N-1 items. They are simple yet effective for tasks like text generation and speech recognition. By capturing local context, N-gram models can generate coherent and contextually relevant text sequences. [24]
7. Text Summarization
Latent Semantic Analysis (LSA): LSA is a technique that applies singular value decomposition to term-document matrices, reducing the dimensionality and capturing the latent structure of the data. It is used for text summarization by identifying the most significant components that represent the document's content, enabling the extraction of key sentences for the summary. [25]
K-means Summarizer: The k-Means Summarizer clusters sentences from a document into k clusters and selects a representative sentence from each cluster to form the summary. This approach ensures that the summary covers diverse aspects of the document. It is simple and effective for producing concise and comprehensive summaries. [12]
Extractive Methods: Extractive summarization methods select and extract sentences directly from the source text to create a summary. These methods often rely on scoring sentences based on features like sentence position, term frequency, and similarity to the title. Extractive methods are straightforward and maintain the original text's fidelity, making them popular for summarization tasks. [25]
8. Speech Recognition and Processing
Dynamic Time Warping (DTW): Dynamic Time Warping (DTW) is an algorithm used to measure the similarity between two temporal sequences that may vary in speed. It finds the optimal alignment between the sequences by warping the time axis. DTW is widely used in speech recognition to align spoken words with stored templates, accounting for variations in speaking speed and tempo. The algorithm calculates a distance measure that can be used to identify the closest matching template, making it effective for tasks such as isolated word recognition. [26]
Gaussian Mixture Model (GMM): Gaussian Mixture Models (GMMs) are probabilistic models that represent the distribution of data points as a mixture of several Gaussian distributions. In speech recognition, GMMs are often used to model the spectral properties of speech signals. Each Gaussian component represents a different phonetic unit or state of the speech signal. GMMs are used in combination with Hidden Markov Models (HMMs) to model the probability of different sound units over time, providing a robust framework for continuous speech recognition. [27]
HMM: Hidden Markov Models (HMMs) are statistical models used to represent systems that are characterized by a set of hidden states, each of which produces observable outputs. In speech recognition, HMMs model the sequence of speech sounds, where each state corresponds to a phoneme or a part of a phoneme. The transitions between states are governed by probabilities, and each state has a probability distribution over possible observations (e.g., spectral features of the speech signal). HMMs are effective in capturing the temporal dynamics of speech and are widely used in combination with GMMs to form the backbone of many traditional speech recognition systems. [14]
DL Models
1. Text Classification
FastText: A library for efficient learning of word representations and text classification, developed by Facebook AI Research. It uses shallow neural networks and is optimized for speed and memory efficiency. [28]
Deep Averaging Networks (DAN): A simple neural network model that averages word embeddings and feeds them into a feedforward neural network for classification. [29]
Hierarchical Attention Networks (HAN): A model that uses a hierarchical structure to capture word and sentence level context, utilizing attention mechanisms at each level. [30]
XLNet: A generalized autoregressive pretraining method that captures bidirectional context using a permutation-based training objective, leading to better performance than BERT on many tasks. [31]
DistilBERT: A smaller, faster, and lighter version of BERT, designed to perform almost as well as BERT while being more efficient in terms of speed and computational resources. [32]
2. Sentiment Analysis
TextCNN: A convolutional neural network model for sentence classification that captures local features of phrases through convolutional filters. [33]
ELMo: Contextual word representations that capture syntax and semantics, derived from a deep, bidirectional LSTM trained on a large text corpus. [34]
ALBERT: A smaller and faster version of BERT that uses parameter reduction techniques to lower memory consumption and increase training speed. [35]
ELECTRA: A pre-training approach that trains a model to distinguish real input tokens from fake ones generated by a small generator network, leading to more sample-efficient training. [36]
RoBERTa: An optimized version of BERT with improved training techniques, such as longer training times, larger batches, and removal of the next sentence prediction objective. [37]
3. Named Entity Recognition (NER)
BiLSTM-CNN-CRF: A model that combines Bidirectional LSTM (BiLSTM) for capturing context, CNN for character-level features, and CRF for sequence prediction, achieving state-of-the-art performance in NER tasks. [38]
Flair Embeddings: Contextual string embeddings that use character-level language models to produce word embeddings, which can be used in various NLP tasks including NER. [39]
SpaCy's Transformer: An extension of the SpaCy library that leverages transformer-based models for enhanced NLP tasks, including NER. [40]
FLAIR: A simple framework for state-of-the-art NLP, including pre-trained NER models that utilize contextual string embeddings. [41]
LUKE (Language Understanding with Knowledge-based Embeddings): A model that enhances transformer-based architectures by incorporating entity-aware self-attention and pre-trained embeddings from a knowledge graph. [42]
4. Machine Translation
Attention Mechanism (Bahdanau and Luong): Mechanisms that improve the performance of seq2seq models by allowing the decoder to focus on different parts of the source sentence during translation. [43,44]
OpenNMT: An open-source neural machine translation framework that supports both research and production needs, offering highly efficient and customizable training and inference. [45]
MarianNMT: An efficient neural machine translation framework written in C++, optimized for speed and memory usage, and supporting advanced features like model ensembling and mixed precision training. [46]
BART (Bidirectional and Auto-Regressive Transformers): A denoising autoencoder for pretraining sequence-to-sequence models, useful for tasks like machine translation and text generation. [47]
mBART (multilingual BART): A multilingual extension of BART that supports multiple languages, making it useful for multilingual machine translation tasks. [48]
5. Question Answering (QA)
BiDAF (Bi-Directional Attention Flow): A model designed for QA tasks that uses bidirectional attention flow to focus on relevant parts of the context and question, capturing intricate relationships between them. [49]
ELMo-based QA models: QA models that leverage ELMo embeddings to provide deep contextual understanding of both questions and passages, improving answer extraction. [50]
ALBERT for QA: A variant of ALBERT fine-tuned for QA tasks, leveraging its parameter-efficient architecture for effective question understanding and answer extraction. [51]
T5 (Text-to-Text Transfer Transformer): A unified framework that treats all NLP tasks as text-to-text problems, making it highly versatile and effective for QA tasks. [52]
Reformer: A more memory-efficient transformer that uses locality-sensitive hashing and reversible layers, making it suitable for handling longer contexts in QA tasks. [53]
6. Text Generation
RNN-RBM (Recurrent Neural Network - Restricted Boltzmann Machine): A generative model that combines the temporal dynamics of RNNs with the generative capabilities of RBMs for sequence modeling and text generation. [54]
Char-RNN: A character-level recurrent neural network model that generates text one character at a time, capable of learning the structure of text at a fine-grained level. [55]
Transformer-XL: An extension of the Transformer architecture that enables learning dependencies beyond a fixed length by segment-level recurrence and relative positional encoding. [56]
GPT-Neo: An open-source implementation of GPT-3, providing a large-scale autoregressive language model for text generation tasks. [57]
CTRL (Conditional Transformer Language Model): A transformer-based language model that generates text based on control codes, enabling more controlled and relevant text generation. [58]
7. Text Summarization
Pointer-Generator Networks: A model that combines standard sequence-to-sequence architecture with a pointer network to copy words from the source text, useful for abstractive summarization. [59]
BERTSUM: A variant of BERT fine-tuned for extractive summarization tasks, achieving state-of-the-art performance by leveraging BERT's deep contextual understanding [60]
UniLM: A transformer-based model pre-trained using three types of language modeling objectives (unidirectional, bidirectional, and sequence-to-sequence), making it versatile for summarization and other tasks. [61]
ProphetNet: A pre-trained sequence-to-sequence model designed for text generation and summarization, introducing future n-gram prediction to improve model coherence. [62]
BigBird: A transformer model designed to handle long documents efficiently using sparse attention mechanisms, making it suitable for tasks like document summarization. [63]
8. Speech Recognition and Processing
Deep Speech: An end-to-end deep learning model for automatic speech recognition (ASR), developed by Mozilla, which leverages RNNs and connectionist temporal classification (CTC) for transcribing speech to text. [64]
Jasper (Just Another Speech Recognizer): A convolutional neural network model optimized for ASR, designed to handle long-range dependencies in speech. [65]
Transformer Transducer: A transformer-based model for ASR that combines the strengths of transformers and RNN transducers, improving the efficiency and accuracy of speech recognition. [66]
Conformer (Convolution-augmented Transformer): A model that combines convolutional neural networks with transformers, capturing both local and global features of speech for improved ASR performance. [67]
DeepMind's WaveNet: A generative model for raw audio waveforms that produces highly realistic and natural-sounding speech, used for text-to-speech and speech synthesis applications. [68]
References
McCallum, A., & Nigam, K. (1998). A Comparison of Event Models for Naive Bayes Text Classification. AAAI-98 workshop on learning for text categorization, 752, 41-48.
Joachims, T. (1998). Text Categorization with Support Vector Machines: Learning with Many Relevant Features. European Conference on Machine Learning, 137-142.
Cox, D. R. (1958). The Regression Analysis of Binary Sequences. Journal of the Royal Statistical Society: Series B (Methodological), 20(2), 215-232.
Cover, T., & Hart, P. (1967). Nearest Neighbor Pattern Classification. IEEE Transactions on Information Theory, 13(1), 21-27.
Quinlan, J. R. (1986). Induction of Decision Trees. Machine Learning, 1(1), 81-106.
Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32.
Friedman, J. H. (2001). Greedy Function Approximation: A Gradient Boosting Machine. Annals of Statistics, 29(5), 1189-1232.
Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785-794.
Freund, Y., & Schapire, R. E. (1997). A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. Journal of Computer and System Sciences, 55(1), 119-139.
Fisher, R. A. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7(2), 179-188.
Geurts, P., Ernst, D., & Wehenkel, L. (2006). Extremely Randomized Trees. Machine Learning, 63(1), 3-42.
MacQueen, J. (1967). Some Methods for Classification and Analysis of Multivariate Observations. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, 281-297.
Lafferty, J., McCallum, A., & Pereira, F. (2001). Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. Proceedings of the Eighteenth International Conference on Machine Learning (ICML), 282-289.
Rabiner, L. R. (1989). A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77(2), 257-286.
McCallum, A., Freitag, D., & Pereira, F. (2000). Maximum Entropy Markov Models for Information Extraction and Segmentation. Proceedings of the Seventeenth International Conference on Machine Learning (ICML), 591-598.
Collins, M. (2002). Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms. Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1-8.
Brown, P. F., Pietra, S. A. D., Pietra, V. J. D., & Mercer, R. L. (1993). The Mathematics of Statistical Machine Translation: Parameter Estimation. Computational Linguistics, 19(2), 263-311.
Koehn, P., Hoang, H., Birch, A., Callison-Burch, C., Federico, M., Bertoldi, N., ... & Herbst, E. (2007). Moses: Open Source Toolkit for Statistical Machine Translation. Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions, 177-180.
Weston, J., Chopra, S., & Bordes, A. (2015). Memory Networks. arXiv preprint arXiv:1410.3916.
Chen, D., Fisch, A., Weston, J., & Bordes, A. (2017). Reading Wikipedia to Answer Open-Domain Questions. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1870-1879.
Salton, G., Wong, A., & Yang, C. S. (1975). A Vector Space Model for Automatic Indexing. Communications of the ACM, 18(11), 613-620.
Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27(3), 379-423.
Yu, S. Z. (2010). Hidden Semi-Markov Models. Artificial Intelligence, 174(2), 215-243.
Brown, P. F., Della Pietra, V. J., deSouza, P. V., Lai, J. C., & Mercer, R. L. (1992). Class-Based n-gram Models of Natural Language. Computational Linguistics, 18(4), 467-479.
Deerwester, S., Dumais, S. T., Furnas, G. W., Landauer, T. K., & Harshman, R. (1990). Indexing by Latent Semantic Analysis. Journal of the American Society for Information Science, 41(6), 391-407.
Sakoe, H., & Chiba, S. (1978). Dynamic programming algorithm optimization for spoken word recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 26(1), 43-49. doi:10.1109/TASSP.1978.1163055.
Reynolds, D. A., & Rose, R. C. (1995). Robust text-independent speaker identification using Gaussian mixture speaker models. IEEE Transactions on Speech and Audio Processing, 3(1), 72-83. doi:10.1109/89.365379.
Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics, 5, 135-146.
Iyyer, M., Manjunatha, V., Boyd-Graber, J., & Daumé III, H. (2015). Deep Unordered Composition Rivals Syntactic Methods for Text Classification. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 1681-1691.
Yang, Z., Yang, D., Dyer, C., He, X., Smola, A., & Hovy, E. (2016). Hierarchical Attention Networks for Document Classification. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1480-1489.
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q. V. (2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding. Advances in Neural Information Processing Systems, 32, 5753-5763.
Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1746-1751.
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2227-2237.
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv preprint arXiv:1909.11942.
Clark, K., Luong, M.-T., Le, Q. V., & Manning, C. D. (2020). ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. arXiv preprint arXiv:2003.10555.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
Ma, X., & Hovy, E. (2016). End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1064-1074.
Akbik, A., Blythe, D., & Vollgraf, R. (2018). Contextual String Embeddings for Sequence Labeling. Proceedings of the 27th International Conference on Computational Linguistics, 1638-1649.
Explosion. (2020). spaCy: Industrial-strength Natural Language Processing in Python. Explosion AI. Retrieved from spaCy.
Akbik, A., Bergmann, T., & Vollgraf, R. (2019). Pooled Contextualized Embeddings for Named Entity Recognition. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 724-728.
Yamada, I., Asai, A., Shindo, H., Takeda, H., & Matsumoto, Y. (2020). LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 6442-6454.
Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv preprint arXiv:1409.0473.
Luong, M.-T., Pham, H., & Manning, C. D. (2015). Effective Approaches to Attention-based Neural Machine Translation. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 1412-1421.
Klein, G., Kim, Y., Deng, Y., Senellart, J., & Rush, A. M. (2017). OpenNMT: Open-Source Toolkit for Neural Machine Translation. Proceedings of ACL 2017, System Demonstrations, 67-72.
Junczys-Dowmunt, M., Grundkiewicz, R., Dwojak, T., Hoang, H., Heafield, K., Neckermann, T., ... & Birch, A. (2018). Marian: Fast Neural Machine Translation in C++. Proceedings of ACL 2018, System Demonstrations, 116-121.
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., ... & Zettlemoyer, L. (2020). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 7871-7880.
Liu, Y., Lin, H., Goyal, N., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2020). Multilingual Denoising Pre-training for Neural Machine Translation. arXiv preprint arXiv:2001.08210.
Seo, M., Kembhavi, A., Farhadi, A., & Hajishirzi, H. (2017). Bidirectional Attention Flow for Machine Comprehension. International Conference on Learning Representations.
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2227-2237.
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv preprint arXiv:1909.11942.
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 21(140), 1-67.
Kitaev, N., Kaiser, Ł., & Levskaya, A
Sutskever, I., & Hinton, G. E. (2007). Learning Multilevel Distributed Representations for High-Dimensional Sequences. Proceedings of the Eleventh International Conference on Artificial Intelligence and Statistics, 548-555.
Karpathy, A., Johnson, J., & Fei-Fei, L. (2015). Visualizing and Understanding Recurrent Networks. arXiv preprint arXiv:1506.02078.
Dai, Z., Yang, Z., Yang, Y., Cohen, W. W., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2978-2988. doi:10.18653/v1/P19-1285
Black, S., Gao, L., Wang, P., Leahy, C., & Biderman, S. (2021). GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow. arXiv preprint arXiv:2104.08773.
Keskar, N. S., McCann, B., Varshney, L. R., Xiong, C., & Socher, R. (2019). CTRL: A Conditional Transformer Language Model for Controllable Generation. arXiv preprint arXiv:1909.05858.
See, A., Liu, P. J., & Manning, C. D. (2017). Get To The Point: Summarization with Pointer-Generator Networks. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1073-1083. doi:10.18653/v1/P17-1099
Liu, Y., & Lapata, M. (2019). Text Summarization with Pretrained Encoders. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 3730-3740. doi:10.18653/v1/D19-1387
Dong, L., Yang, N., Wang, W., Wei, F., Liu, X., Wang, Y., ... & Zhou, M. (2019). Unified Language Model Pre-training for Natural Language Understanding and Generation. Proceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS 2019), 13042-13054.
Qi, W., Yan, Y., Gong, Y., Liu, D., Duan, N., Chen, J., ... & Zhou, M. (2020). ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2401-2410. doi:10.18653/v1/2020.emnlp-main.182
Zaheer, M., Guruganesh, G., Dubey, K. A., Ainslie, J., Alberti, C., Ontanon, S., ... & Ahmed, A. (2020). Big Bird: Transformers for Longer Sequences. Advances in Neural Information Processing Systems (NeurIPS 2020), 33, 17283-17297.
Hannun, A., Case, C., Casper, J., Catanzaro, B., Diamos, G., Elsen, E., ... & Ng, A. Y. (2014). Deep Speech: Scaling up end-to-end speech recognition. arXiv preprint arXiv:1412.5567.
Li, J., Zhang, Y., Seki, H., Faria, A., Bhowmik, R., Sanabria, R., ... & Zhong, J. (2019). Jasper: An End-to-End Convolutional Neural Acoustic Model. Proceedings of Interspeech 2019, 71-75. doi:10.21437/Interspeech.2019-1819
Zhang, Y., Chen, X., Zhang, S., Liu, M., & Panayotov, V. (2020). Transformer Transducer: A Streamable Speech Recognition Model with Transformer Encoders and RNN-T Loss. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7829-7833. doi:10.1109/ICASSP40776.2020.9053795
Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y., Yu, J., ... & Wu, Y. (2020). Conformer: Convolution-augmented Transformer for Speech Recognition. Proceedings of Interspeech 2020, 5036-5040. doi:10.21437/Interspeech.2020-3015
van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., ... & Kavukcuoglu, K. (2016). WaveNet: A Generative Model for Raw Audio. arXiv preprint arXiv:1609.03499.
Subscribe to my newsletter
Read articles from Jyoti Maurya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jyoti Maurya
Jyoti Maurya
I create cross platform mobile apps with AI functionalities. Currently a PhD Scholar at Indira Gandhi Delhi Technical University for Women, Delhi. M.Tech in Artificial Intelligence (AI).