Data Modelling.
 Anjola. A
Anjola. AWhen creating a database with many entities, storage size and query time are key considerations any database administrator should have. This also applies to people learning the tools used for querying databases i.e. SQL - Structured Querying Language. One way to ensure storage efficiency is through proper data modelling.
Data modelling defines all entities, including their structure, storage, and use in a business context. For example, if creating a school database, some expected entities would be; students, teachers, guardians, etc. The blueprint for mapping out these definitions is called a schema.
A data model schema is a pictorial representation of a database and the relationships between entities. It shows all existing entities, their organization and how each is connected. This article will explore two main (dimensional model) designs, star schema & snowflake schema. This is because the structure of dimensional models is the most commonly used in data analysis and business intelligence.
Star Schema.
A star schema consists of a fact table and dimension tables (describing each category in the fact table). For instance, we have a primary school database that stores information about students, academic and non-academic staff. All tables surrounding the 'Fact Table' are dimension tables.
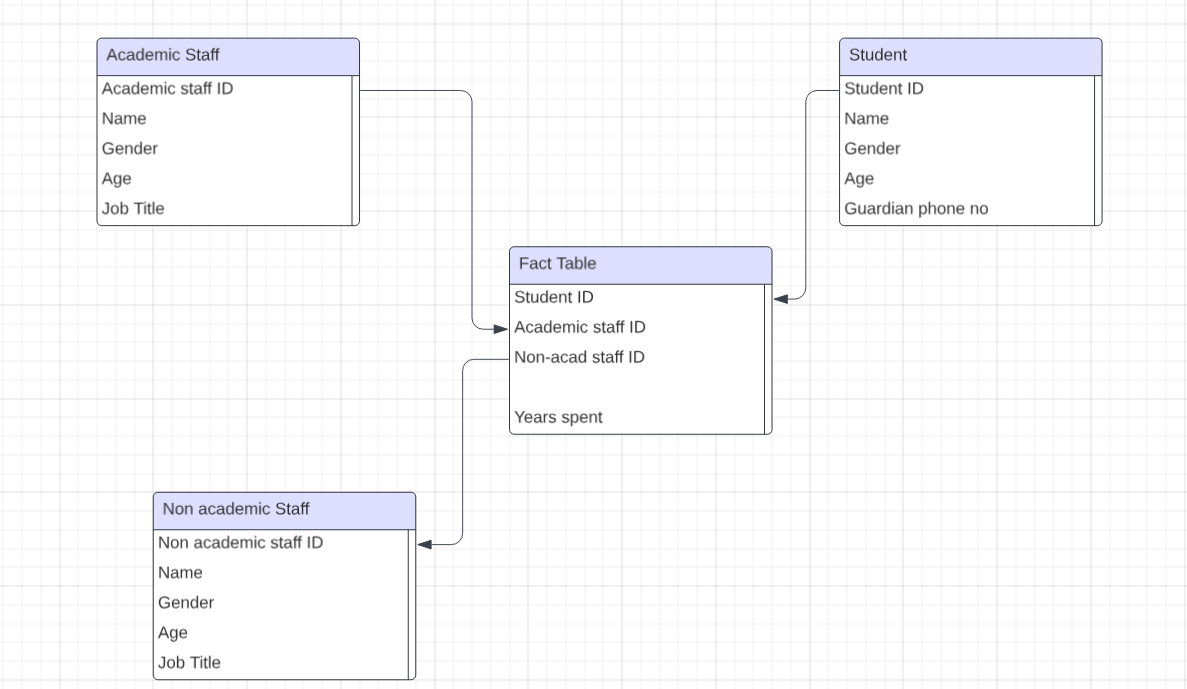
In a star schema, the need for joining tables is eliminated because every dimension table is linked to the fact table as a foreign key.
However, the issue of redundant(repeated) data and data inconsistency arises. As a result, a lot of storage space is consumed to accommodate this. This form of data structure is denormalized and affects the quality of any analysis results.
On the bright side, since all the data is stored in one table, querying is much easier and faster. Assuming you want to access all the information linked to a particular academic staff, merely filtering using their ID will get the information needed.
Snowflake Schema.
Snowflake schema comprises fact, dimension and sub-dimension tables. From the diagram below, job title and gender are stored in different tables and referenced as foreign keys in the student, academic and non-academic tables.
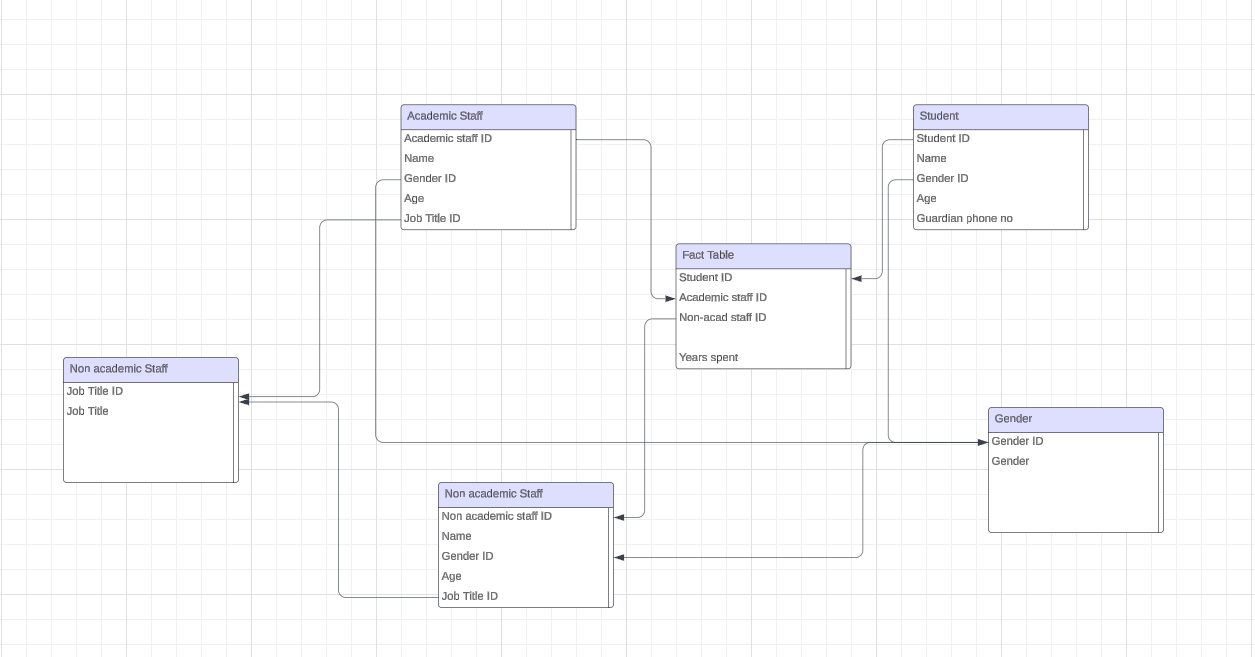
The snowflake schema schema is complex compared to and an extension of the star schema. This complexity is more evident with dimensions and (multiple) sub-dimensions in the database.
However, the normalization of the data eliminates redundancy and hence, guarantees data integrity, and consumes less storage space.
The major downside to the snowflake schema is that because (more) joins are required for analysis, querying time is extended.
The Tradeoff.
Determining the right schema to use depends on what matters to the data architect. If a system requires fast retrieval of data and is not 'keen' on the accuracy of results, a star schema is the most suitable. On the contrary, if ease of maintenance and data integrity are priorities, a snowflake is your best bet. Either way, you trade one benefit for the other.
You can learn more about the tradeoffs here. Thank you for reading xx.
Subscribe to my newsletter
Read articles from Anjola. A directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by