Real-Time Streaming Analytics Pipeline with Kinesis, Flink, and OpenSearch 🚀
 Tanishka Marrott
Tanishka Marrott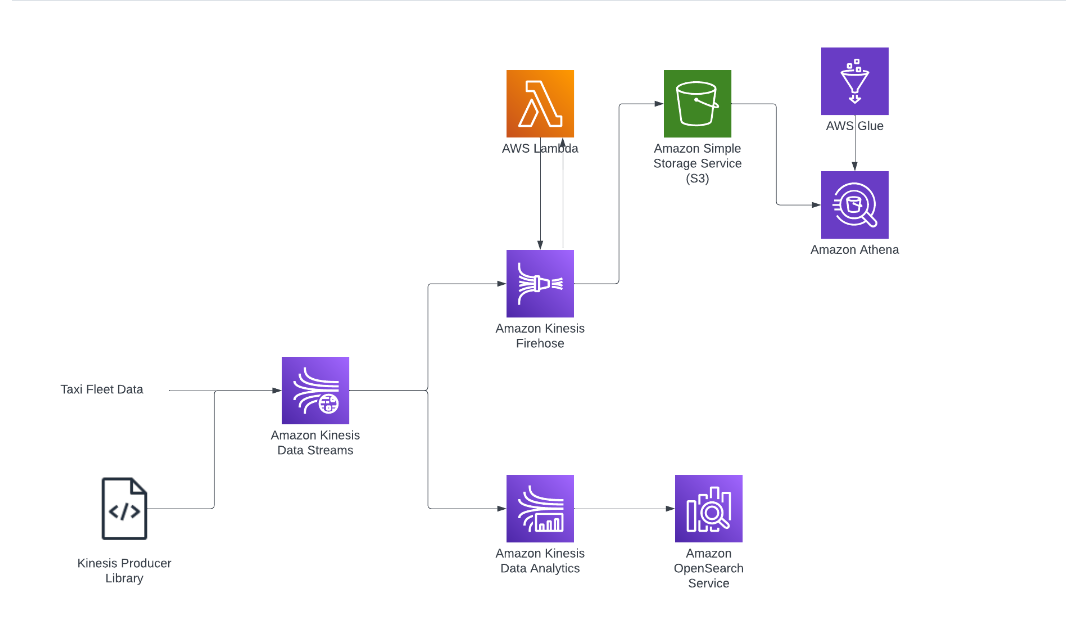
Hi there 👋, I'm Tanishka Marrott
Today, I'll be taking you through an exciting journey where we've seamlessly integrated the primary phases of data ingestion, processing, storage, and visualization into a single cohesive pipeline using AWS services like Kinesis, Lambda, Glue, and OpenSearch.
Key Focus:
➡️ We've optimized for non-functional aspects like scalability and performance throughout.
Project Workflow
Here's an overview of our Streaming Analytics pipeline:
Link to the repo :- Real-time Streaming Analytics with Kinesis Repo
Data Ingestion Layer
We've utilized Kinesis Data Streams for capturing and storing real-time streaming data. For the implementation details, please check out the file --> EnhancedProducer.java.
How does the Kinesis producer workflow look like? 🤔
Initialize the Producer Configuration:
- Set crucial parameters like timeouts and max connections to optimize Kinesis' performance.
KinesisProducerConfiguration config = new KinesisProducerConfiguration()
.setRecordMaxBufferedTime(3000)
.setMaxConnections(1)
.setRequestTimeout(60000)
.setRegion(REGION)
.setRecordTtl(30000);
Instantiate the Producer Instance:
- With all necessary configurations specified, we'll create the producer instance.
try (KinesisProducer producer = new KinesisProducer(config)) {
// Producer logic here
}
Read Data from the Telemetry CSV File:
- Standardize the format, making it suitable for streaming.
List<Trip> trips = TripReader.readFile(new File("data/taxi-trips.csv"));
Set Up ExecutorService:
- Manage multiple threads for increased concurrency and throughput.
ExecutorService executor = Executors.newFixedThreadPool(coreCount * 2);
Asynchronous Data Ingestion:
- Utilize
CompletableFuturefor making the data ingestion process fully asynchronous.
- Utilize
trips.forEach(trip -> CompletableFuture.runAsync(() -> sendRecord(producer, trip, 0, 100), executor));
Data Integrity and Reliability:
- Check responses, log successful shard IDs, and capture error messages for failed ones.
private static void sendRecord(KinesisProducer producer, Trip trip, int attemptCount, long backoff) {
// Send record logic here
}
Graceful Shutdown:
- Ensure all tasks are completed by properly shutting down the Executor Service and Kinesis Producer.
executor.shutdown();
producer.flushSync();
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow();
}
Design Decisions for the Ingestion Layer 🛠️
A → On-Demand Capacity Mode for KDS:
📍 Our data stream scales automatically with workload variations, so no manual handling of shard capacities is needed. It automatically scales based on the influx of streaming data 👍.
B → Optimized Thread Management:
Initially used solely ExecutorService but faced blocking issues with Future.get(). Transitioned to CompletableFuture for a fully asynchronous workflow, improving efficiency and throughput.
C → Dynamically Sized Thread Pool:
Used a factor of 2 * number of CPU cores to handle both CPU-bound and I/O-bound threads effectively. This ensures resource efficiency and performance optimization.
D → Retry + Progressive Backoff Mechanism:
Implemented to handle errors gracefully, ensuring operational stability and service continuity. This approach minimizes system workload, improves data consistency, and defines a predictable retry policy.
Data Transformation Layer for Workflow #1:
Services Utilized: Kinesis Data Firehose + Glue
Why Firehose and Glue?
Glue: Acts as a central metadata repository through the data catalog, enhancing Athena's querying capabilities.
Firehose: Loads streaming data into S3, referencing the schema definitions stored in Glue.
Data Transformations Using Lambda:
Lightweight processing logic to avoid bottlenecks and high memory usage.
Offloaded complex data processing to Flink in KDA for efficiency.
Non-Functional Enhancements:
Buffer Size and Interval Configurations: Trade-off between latency and cost.
Data Compression and Formats: Used Snappy for compression and Parquet for columnar storage to reduce data size and improve query performance.
Error Handling: Segregated error outputs in S3 for faster troubleshooting and recovery.
Stream Processing & Visualization
Key Service: Kinesis Data Analytics (KDA)
Workflow #2:
Streaming data is processed by a Flink SQL application deployed on KDA Studio.
Processed data is sent to OpenSearch for visualization and analytics of historic data.
Why Flink over SQL?
Flink excels at real-time insights and stateful computations on streaming data.
OpenSearch complements Flink by providing search and analytics capabilities for historic data.
Optimizing Non-Functional Aspects:
KDA Parallelism: Auto-scales based on workload requirements, ensuring efficient resource utilization.
Logging and Monitoring: Implemented for troubleshooting and recovery.
Checkpointing: Configured for data recovery and consistency.
Cost Alerts and IAM Policies: Ensured budget considerations and access security.
Conclusion:
Thank you for accompanying me on this journey! Here’s a quick recap of what we built today:
Workflow - 1: Data Ingestion to Storage
Ingested data via Kinesis Data Streams
Transferred to S3 via Firehose
Managed schema in Glue
Enriched and standardized data via Lambda
Stored in S3
Workflow - 2: Stream Processing and Visualization
Flink application on KDA Studio for real-time processing
Aggregated data
S3 as durable data store
Visualized data with OpenSearch
Acknowledgements: Special thanks to AWS Workshops for their resources and support in this project's development.
About: This project focuses on real-time data streaming with Kinesis, using Flink for advanced processing, and OpenSearch for analytics. This architecture handles the complete lifecycle of data from ingestion to actionable insights, making it a comprehensive solution.
Feel free to reach out with any questions or feedback! Let's connect on LinkedIn and check out my GitHub for more projects.
Topics
OpenSearch
Data Engineering
Cloud Computing
AWS Lambda
Kinesis Data Streams
Apache Flink
AWS Glue
Real-Time Analytics
Happy Coding! 🚀
Subscribe to my newsletter
Read articles from Tanishka Marrott directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tanishka Marrott
Tanishka Marrott
I'm a results-oriented cloud architect passionate about designing resilient cloud solutions. I specialize in building scalable architectures that meet business needs and are agile. With a strong focus on scalability, performance, and security, I ensure solutions are adaptable. My DevSecOps foundation allows me to embed security into CI/CD pipelines, optimizing deployments for security and efficiency. At Quantiphi, I led security initiatives, boosting compliance from 65% to 90%. Expertise in data engineering, system design, serverless solutions, and real-time data analytics drives my enthusiasm for transforming ideas into impactful solutions. I'm dedicated to refining cloud infrastructures and continuously improving designs. If our goals align, feel free to message me. I'd be happy to connect!