DocAi - PDFs, Scanned Docs to Structured Data
 Kriti
Kriti
Problem Statement
The 'Why' of this AI solution is very important and prevalent across multiple fields.
Imagine you have multiple scanned PDF documents:
Where customers make some manual selections, add signature/dates/customer information OR
You have multiple pages of written documentation that has been scanned and want a solution that obtains text from these documents OR
You are simply looking for an AI backed avenue that provides an interactive mechanism to query documents that do not have a structured format
Dealing with such scanned/mixed/unstructured Documents can be tricky, and extracting crucial information from them could be manual, hence error prone and cumbersome.
The solution below leverages the power of OCR [Optical character recognition] and LLM [Large Language Models] in order to obtain text from such documents and query them to obtain structured trusted information.
High Level Architecture
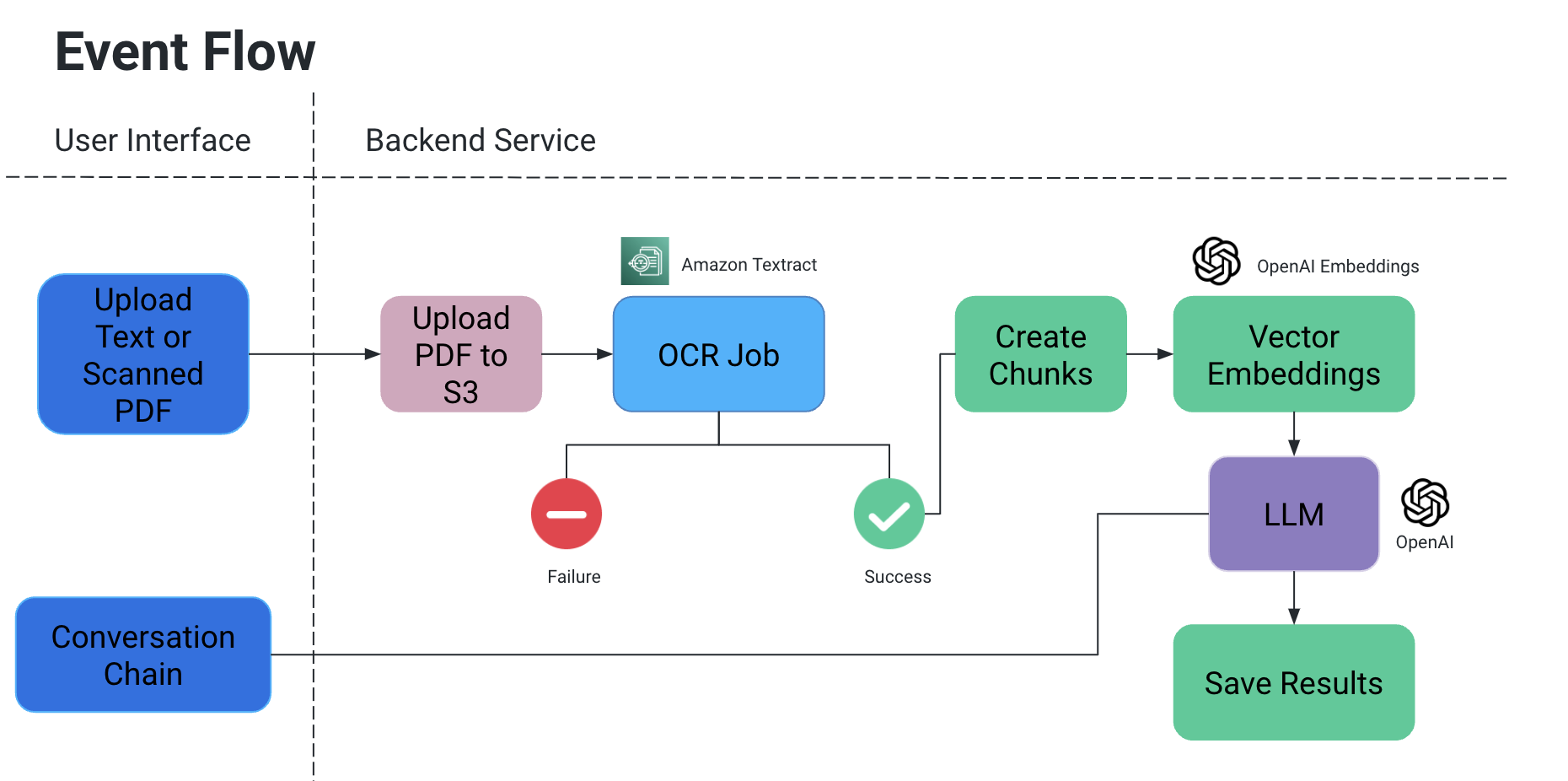
User Interface
The user interface allows for uploading PDF/Scanned Documents (it can be further expanded to other document types as well)
Streamlit is being leveraged for the user interface:
It is an open source Python Framework and is extremely easy to use
As changes are performed, they reflect in the running apps - making this a fast testing mechanism
Community support for Streamlit is fairly strong and growing
Conversation Chain
This is essentially required to incorporate ChatBots which can answer follow up questions and provide chat history
We leverage LangChain for interfacing with the AI model we use; for the purposed of this project we have tested with OpenAI and Mistral AI
Backend Service
Flow of Events
User uploads a PDF/scanned document, which then gets uploaded to an S3 bucket
An OCR service then retrieves this file from the S3 bucket and processes it to extract text from this document
Chunks of Text are created from the above output, and associated vector embeddings are created for them
Now this is very important, because you do not want context to be lost when chunks are split - they could be split mid sentence, without some punctuations the meaning could be lost etc
So to counter it, we create overlapping chunks
The Large Language Model that we use takes these embeddings as input and we have two functionalities:
Generate specific output:
If we have specific kind of information that is needed to be pulled out from documents, we can provide query in-code to the AI model, obtain data and store it in structured format
Avoid AI hallucinations, by explicitly adding in-code query with conditions to not make up certain values and only use the context of the document
We can store it as a file in S3/locally OR write to a Database
Chat
- Here we provide the avenue for the end user to initiate a chat with Ai for obtaining specific information in context of the document
OCR Job
We are using Amazon Textract for optical recognition on these documents
It works great with documents which also have tables/forms etc
If working on a POC - leverage the free tier for this service
Vector Embeddings
A very easy way to understand vector embeddings is to translate words or sentences into numbers which capture the meaning and relationships of this context
Imagine you have a word "ring" which is an ornament, in terms of the word itself, one of its close match is "sing". But in terms of the meaning of the word we would want it to match something like "jewelry", "finger", "gemstones" or perhaps something like "hoop", "circle" etc.
Thus when we create vector embedding of "ring" - we basically are filling it up with tons of information of its meaning and relationships
And this information along with the vector embeddings of other words/statements in a document ensure that the correct meaning of the word "ring" in context is picked
We used OpenAIEmbeddings for creating Vector Embeddings
LLM
There are multiple large language models which can we used for our scenario
In the scope of this project, testing with OpenAI and Mistral AI has been done
For MistralAI, HuggingFace was leveraged
Use Cases and Tests
We performed the following Tests:
Signatures, handwritten dates/texts was read using OCR
Hand-selected options in the document
Digital selections made on top of the document
Unstructured data parsed to obtain tabular content (add to text file/db etc)
Future Scope
We can further expand the use cases for the above project to incorporate images, integrating with documentation stores like Confluence/Drive etc to pull information regarding a specific topic from multiple sources, adding a stronger avenue to do comparative analysis between two documents etc
Subscribe to my newsletter
Read articles from Kriti directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by