Delving Deeper into the MIPS Pipeline
 Jyotiprakash Mishra
Jyotiprakash MishraPipelining is an implementation technique that allows multiple instructions to overlap in execution by exploiting parallelism. This technique is pivotal in creating fast CPUs today.
Understanding Pipelining Through an Analogy
Think of a pipeline as similar to an automobile assembly line. In an assembly line, various steps contribute to the construction of a car, with each step operating in parallel but on different cars. Similarly, in a computer pipeline, each step completes a part of an instruction. These steps, called pipe stages or pipe segments, work in parallel on different parts of different instructions. The stages are connected, forming a pipeline where instructions enter at one end, move through the stages, and exit at the other end, much like cars moving through an assembly line.
Throughput in Pipelining
In an automobile assembly line, throughput is the number of cars produced per hour, determined by how frequently a completed car exits the line. In a computer pipeline, throughput is determined by how often an instruction exits the pipeline. Since all pipeline stages are interconnected, they must be ready to proceed simultaneously. The time required for an instruction to move one step down the pipeline is a processor cycle, usually equal to one clock cycle. The length of this cycle is determined by the slowest pipeline stage, similar to how the longest step in an assembly line sets the pace for the entire line.
Balancing Pipeline Stages
The goal of a pipeline designer is to balance the length of each pipeline stage, akin to balancing the time for each step in an assembly line. If perfectly balanced, the time per instruction on a pipelined processor, under ideal conditions, is equal to:
$$\text{Time per instruction on unpipelined machine} \div \text{Number of pipeline stages}$$
Ideally, this results in a speedup proportional to the number of pipeline stages. However, perfect balance is rare, and pipelining introduces some overhead, so the time per instruction will not reach its absolute minimum but can be close.
Benefits of Pipelining
Pipelining reduces the average execution time per instruction. This can be viewed as decreasing the number of clock cycles per instruction (CPI), reducing the clock cycle time, or a combination of both. Typically, pipelining is seen as reducing the CPI if the starting point is a processor that takes multiple clock cycles per instruction. If the processor takes one long clock cycle per instruction, pipelining decreases the clock cycle time.
A Simple Implementation of a RISC Instruction Set
To grasp how a RISC (Reduced Instruction Set Computer) instruction set can be implemented in a pipelined manner, it's crucial first to understand its non-pipelined implementation. This section presents a basic implementation where each instruction requires a maximum of five clock cycles. While this unpipelined implementation is neither the most economical nor the highest performing, it is designed to transition smoothly to a pipelined version, resulting in a much lower CPI (Clock Cycles Per Instruction).
In implementing this instruction set, several temporary registers are introduced. These registers, not part of the architecture, simplify the transition to pipelining. Our focus is on an integer subset of a RISC architecture, encompassing load-store word, branch, and integer ALU (Arithmetic Logic Unit) operations.
Every instruction in this RISC subset can be executed in at most five clock cycles, as detailed below:
1. Instruction Fetch Cycle (IF)
Operations:
Send the program counter (PC) to memory.
Fetch the current instruction from memory.
Update the PC to the next sequential address by adding 4 (since each instruction is 4 bytes).
2. Instruction Decode/Register Fetch Cycle (ID)
Operations:
Decode the instruction.
Read the registers corresponding to the register source specifiers from the register file.
Perform an equality test on the registers for a possible branch.
Sign-extend the offset field of the instruction if needed.
Compute the possible branch target address by adding the sign-extended offset to the incremented PC.
Decoding is performed in parallel with reading registers due to fixed-field decoding in RISC architecture, where register specifiers are located at fixed positions. Although this may result in reading an unused register, it doesn’t impact performance but does consume energy, which power-sensitive designs might avoid. The immediate portion of an instruction is also in a fixed location, allowing the sign-extended immediate to be calculated during this cycle.
3. Execution/Effective Address Cycle (EX)
Operations:
The ALU operates on the operands prepared in the prior cycle, performing one of the following based on the instruction type:
Memory reference: The ALU adds the base register and the offset to form the effective address.
Register-Register ALU instruction: The ALU performs the operation specified by the ALU opcode on the values read from the register file.
Register-Immediate ALU instruction: The ALU performs the operation specified by the ALU opcode on the first value read from the register file and the sign-extended immediate.
In a load-store architecture, the effective address and execution cycles can be combined into a single clock cycle, as no instruction simultaneously calculates a data address and performs an operation on the data.
4. Memory Access Cycle (MEM)
Operations:
For load instructions, memory performs a read using the effective address computed in the previous cycle.
For store instructions, memory writes the data from the second register read from the register file using the effective address.
5. Write-Back Cycle (WB)
Operations:
- For Register-Register ALU instructions or load instructions, write the result into the register file. The result can come from the memory system (for a load) or the ALU (for an ALU instruction).
In this implementation:
Branch instructions require 2 cycles.
Store instructions require 4 cycles.
All other instructions require 5 cycles.
Assuming a branch frequency of 12% and a store frequency of 10%, the typical instruction distribution results in an overall CPI of 4.54. Although this implementation is not optimal in terms of performance or hardware usage, it serves as a foundation for developing a pipelined version, which we will focus on next.
The Classic Five-Stage Pipeline for a RISC Processor
Pipelining the execution of instructions in a RISC (Reduced Instruction Set Computer) processor can be accomplished with minimal changes by simply initiating a new instruction on each clock cycle. This design approach results in each of the clock cycles from the previous section becoming a pipe stage, or a cycle in the pipeline. The following figure illustrates this typical pipeline structure, where although each instruction takes five clock cycles to complete, the hardware initiates a new instruction during each clock cycle, executing parts of five different instructions simultaneously.
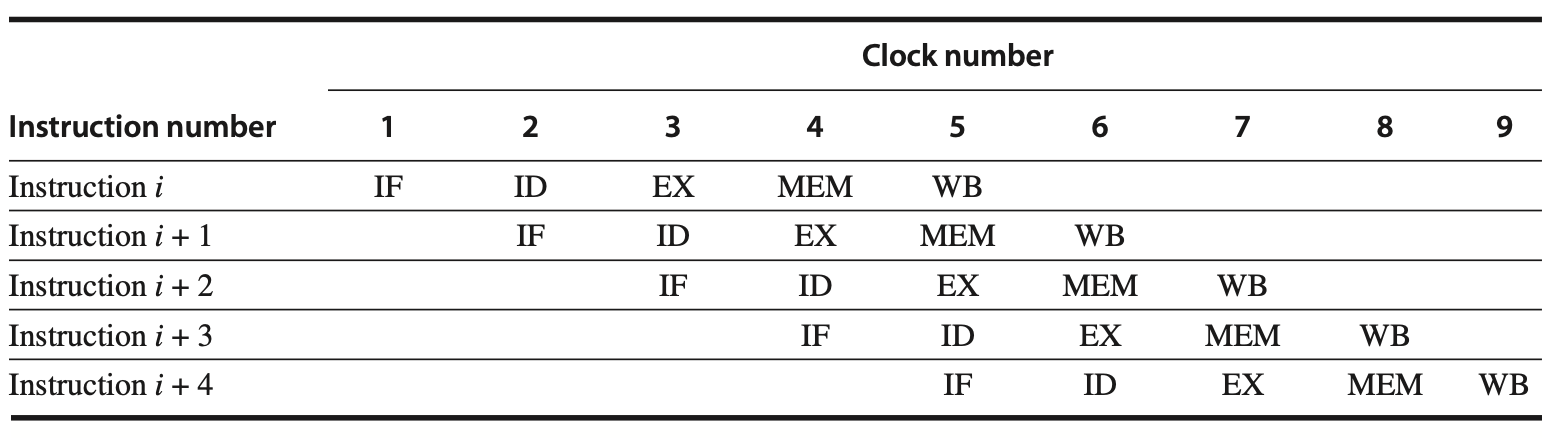
Figure: Simple RISC pipeline. On each clock cycle, a new instruction is fetched and enters a five-cycle execution process. If an instruction is initiated with each clock cycle, the processor's performance can reach up to five times that of a non-pipelined processor. The stages in the pipeline are named similarly to the cycles in an unpipelined implementation: IF (instruction fetch), ID (instruction decode), EX (execution), MEM (memory access), and WB (write-back).
While this might seem straightforward, implementing pipelining introduces several challenges. In this and the following sections, we will address these challenges to make our RISC pipeline functional.
Ensuring Proper Resource Utilization
In every clock cycle, we need to ensure that no two operations compete for the same data path resource simultaneously. For instance, a single ALU cannot compute an effective address and perform a subtract operation at the same time. Therefore, we must design the pipeline to prevent such conflicts. The simplicity of a RISC instruction set makes resource evaluation relatively straightforward. The following figure shows a simplified version of a RISC data path in pipeline fashion.
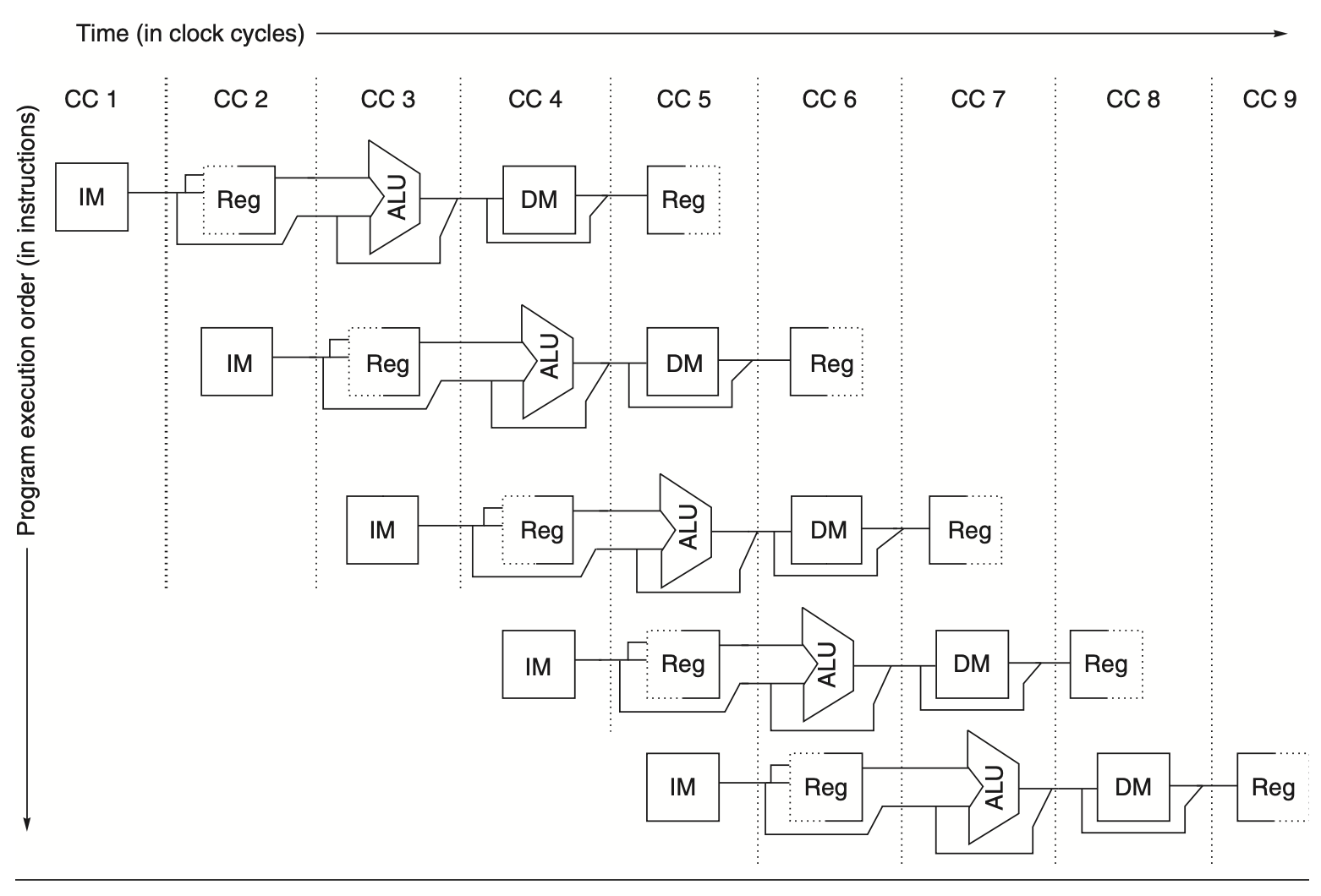
Figure: The pipeline can be visualized as a series of data paths staggered over time. This illustrates how the parts of the data path overlap, with clock cycle 5 (CC 5) representing the steady-state condition. The register file, used as a source in the ID stage and as a destination in the WB stage, appears twice. It is depicted as being read in one part of the stage and written in another, indicated by a solid line on either the right or left side and a dashed line on the opposite side. The abbreviations used are IM for instruction memory, DM for data memory, and CC for clock cycle.
Three key observations support the minimal conflicts in this pipeline design:
Separate Instruction and Data Memories: We use separate caches for instructions and data, eliminating conflicts between instruction fetch and data memory access. However, this design increases the memory system's bandwidth demand by five times, which is a trade-off for higher performance.
Dual-Stage Register File Usage: The register file is used in two stages—reading in ID and writing in WB. These uses are distinct, so we show the register file in two places. To handle reads and writes to the same register, we perform the write in the first half of the clock cycle and the read in the second half.
Program Counter (PC) Management: The PC must be incremented and stored every clock cycle during the IF stage to start a new instruction each cycle. An adder computes the potential branch target during ID. Although a branch does not change the PC until the ID stage, which introduces a problem, we will address this issue later.
Pipeline Registers and Data Flow
Ensuring that instructions in different pipeline stages do not interfere with each other is crucial. This is achieved by introducing pipeline registers between successive stages. These registers store the results from a given stage at the end of each clock cycle, providing input to the next stage in the subsequent cycle. The following figure illustrates the pipeline with these registers.
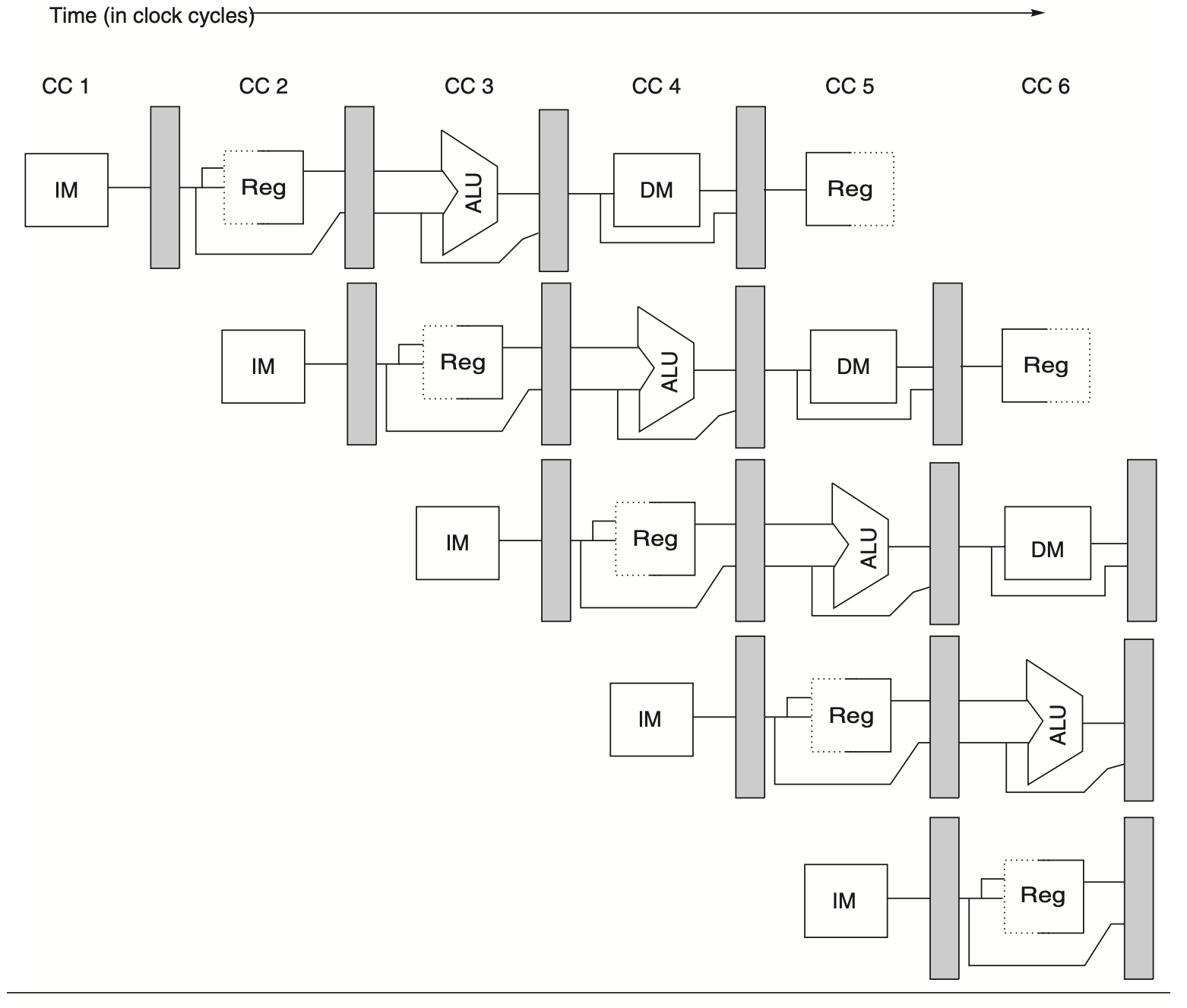
Figure: A diagram illustrating the pipeline registers between consecutive pipeline stages. These registers prevent interference between different instructions in adjacent stages of the pipeline. Additionally, they are crucial for transferring data from one stage to the next for a given instruction. The edge-triggered nature of the registers—meaning their values change instantly on a clock edge—is essential. Without this feature, data from one instruction could disrupt the execution of another.
While many figures omit pipeline registers for simplicity, they are essential for proper pipeline operation. Pipeline registers also carry intermediate results across stages that are not directly adjacent. For example:
The register value to be stored during a store instruction is read during ID but used in MEM, passing through two pipeline registers.
The result of an ALU instruction is computed during EX but stored in WB, also passing through two pipeline registers.
Pipeline registers are often named by the stages they connect, such as IF/ID, ID/EX, EX/MEM, and MEM/WB.
Basic Performance Issues in Pipelining
Pipelining enhances the CPU's instruction throughput—the number of instructions completed per unit of time—though it does not reduce the execution time of an individual instruction. In fact, pipelining often slightly increases the execution time of each instruction due to the overhead involved in controlling the pipeline. Despite this, the increased instruction throughput results in faster program execution and lower total execution time, even though no single instruction executes more quickly.
However, the fact that the execution time of each instruction does not decrease imposes practical limits on the depth of a pipeline, as will be discussed in the next section. Beyond pipeline latency, performance limits also arise from imbalance among pipeline stages and pipelining overhead. Performance is reduced by stage imbalance because the clock speed is constrained by the time required for the slowest pipeline stage. Pipelining overhead is a result of the combination of pipeline register delay and clock skew. Pipeline registers introduce setup time, which is the duration a register input must remain stable before the clock signal triggers a write, as well as propagation delay within the clock cycle. Clock skew, the maximum delay between clock arrivals at any two registers, also contributes to the minimum clock cycle duration. Once the clock cycle time is reduced to the sum of the clock skew and latch overhead, further pipelining ceases to be beneficial, as there is no remaining time in the cycle for useful work.
Performance of Pipelines with Stalls
Stalls cause pipeline performance to deviate from the ideal scenario. Let’s examine a basic equation for determining the actual speedup achieved by pipelining, using the formula from the prior section:
$$\text{Speedup from pipelining} = \frac{\text{Average instruction time unpipelined}}{\text{Average instruction time pipelined}}$$
$$= \frac{\text{CPI unpipelined} \times \text{Clock cycle unpipelined}}{\text{CPI pipelined} \times \text{Clock cycle pipelined}}$$
$$= \frac{\text{CPI unpipelined}}{\text{CPI pipelined}} \times \frac{\text{Clock cycle unpipelined}}{\text{Clock cycle pipelined}}$$
Pipelining is essentially a method to reduce the CPI or the clock cycle duration. Typically, we use CPI to compare pipelines, so let’s begin with that premise. The ideal CPI for a pipelined processor is nearly always 1. Thus, the pipelined CPI can be calculated as follows:
$$\text{CPI pipelined} = \text{Ideal CPI} + \text{Pipeline stall clock cycles per instruction}$$
$$= 1 + \text{Pipeline stall clock cycles per instruction}$$
Assuming we ignore the cycle time overhead of pipelining and the stages are perfectly balanced, the cycle time for both processors can be considered equal, leading to:
$$\text{Speedup} = \frac{\text{CPI unpipelined}}{1 + \text{Pipeline stall cycles per instruction}}$$
A simple yet significant scenario is when all instructions require the same number of cycles, which should also equal the number of pipeline stages (also known as the depth of the pipeline). In this scenario, the unpipelined CPI equals the depth of the pipeline, resulting in:
$$\text{Speedup} = \frac{\text{Pipeline depth}}{1 + \text{Pipeline stall cycles per instruction}}$$
If there are no stalls in the pipeline, this intuitive result indicates that pipelining can enhance performance by the depth of the pipeline.
Alternatively, considering pipelining as a way to improve the clock cycle time, we can assume that both the unpipelined and pipelined processors have a CPI of 1. This leads to:
$$\text{Speedup from pipelining} = \frac{\text{CPI unpipelined}}{\text{CPI pipelined}} \times \frac{\text{Clock cycle unpipelined}}{\text{Clock cycle pipelined}}$$
$$= \frac{1}{1 + \text{Pipeline stall cycles per instruction}} \times \frac{\text{Clock cycle unpipelined}}{\text{Clock cycle pipelined}}$$
In situations where pipeline stages are perfectly balanced and there is no overhead, the clock cycle time for the pipelined processor is less than that of the unpipelined processor by a factor equivalent to the pipeline depth:
$$\text{Clock cycle pipelined} = \frac{\text{Clock cycle unpipelined}}{\text{Pipeline depth}}$$
$$\text{Pipeline depth} = \frac{\text{Clock cycle unpipelined}}{\text{Clock cycle pipelined}}$$
This yields the following result:
$$\text{Speedup from pipelining} = \frac{1}{1 + \text{Pipeline stall cycles per instruction}} \times \frac{\text{Clock cycle unpipelined}}{\text{Clock cycle pipelined}}$$
$$= \frac{1}{1 + \text{Pipeline stall cycles per instruction}} \times \text{Pipeline depth}$$
Therefore, in the absence of stalls, the speedup equals the number of pipeline stages, aligning with our intuition for the ideal scenario.
The Major Hurdle of Pipelining—Pipeline Hazards
Pipeline hazards are situations that prevent the next instruction in the instruction stream from executing during its designated clock cycle, thereby reducing the performance from the ideal speedup gained by pipelining. There are three main types of hazards:
Structural Hazards: These occur due to resource conflicts when the hardware cannot support all possible combinations of instructions simultaneously in overlapped execution.
Data Hazards: These arise when an instruction depends on the results of a previous instruction in a manner exposed by the overlapping of instructions in the pipeline.
Control Hazards: These stem from the pipelining of branches and other instructions that modify the program counter (PC).
To handle hazards, pipelines often need to be stalled. This means some instructions in the pipeline must be delayed while others proceed. For the pipelines discussed here, when an instruction is stalled, all subsequent instructions—those not as far along in the pipeline—are also stalled. However, instructions that were issued earlier and are farther along in the pipeline must continue to progress; otherwise, the hazard will never be resolved. Consequently, no new instructions are fetched during a stall.
Structural Hazards
In a pipelined processor, the concurrent execution of instructions requires both the pipelining of functional units and the duplication of resources to support all possible combinations of instructions in the pipeline. When certain combinations of instructions cannot proceed due to resource conflicts, a structural hazard occurs.
Structural hazards most commonly arise when a functional unit is not fully pipelined. Consequently, a sequence of instructions using that unit cannot advance at a rate of one per clock cycle. Another source of structural hazards is the insufficient duplication of resources to allow all instruction combinations to execute simultaneously. For example, if a processor has only one register-file write port but needs to perform two writes in one clock cycle, a structural hazard will result.
When instructions encounter this hazard, the pipeline stalls one instruction until the necessary unit becomes available, increasing the CPI from its ideal value of 1. Some pipelined processors share a single-memory pipeline for both data and instructions, causing conflicts when an instruction requires a data memory reference while a subsequent instruction needs an instruction reference. This situation is illustrated in the following figure. To resolve this, the pipeline stalls for one clock cycle during the data memory access. This stall, often called a pipeline bubble or simply a bubble, moves through the pipeline occupying space without performing useful work. Another type of stall related to data hazards will be discussed later.
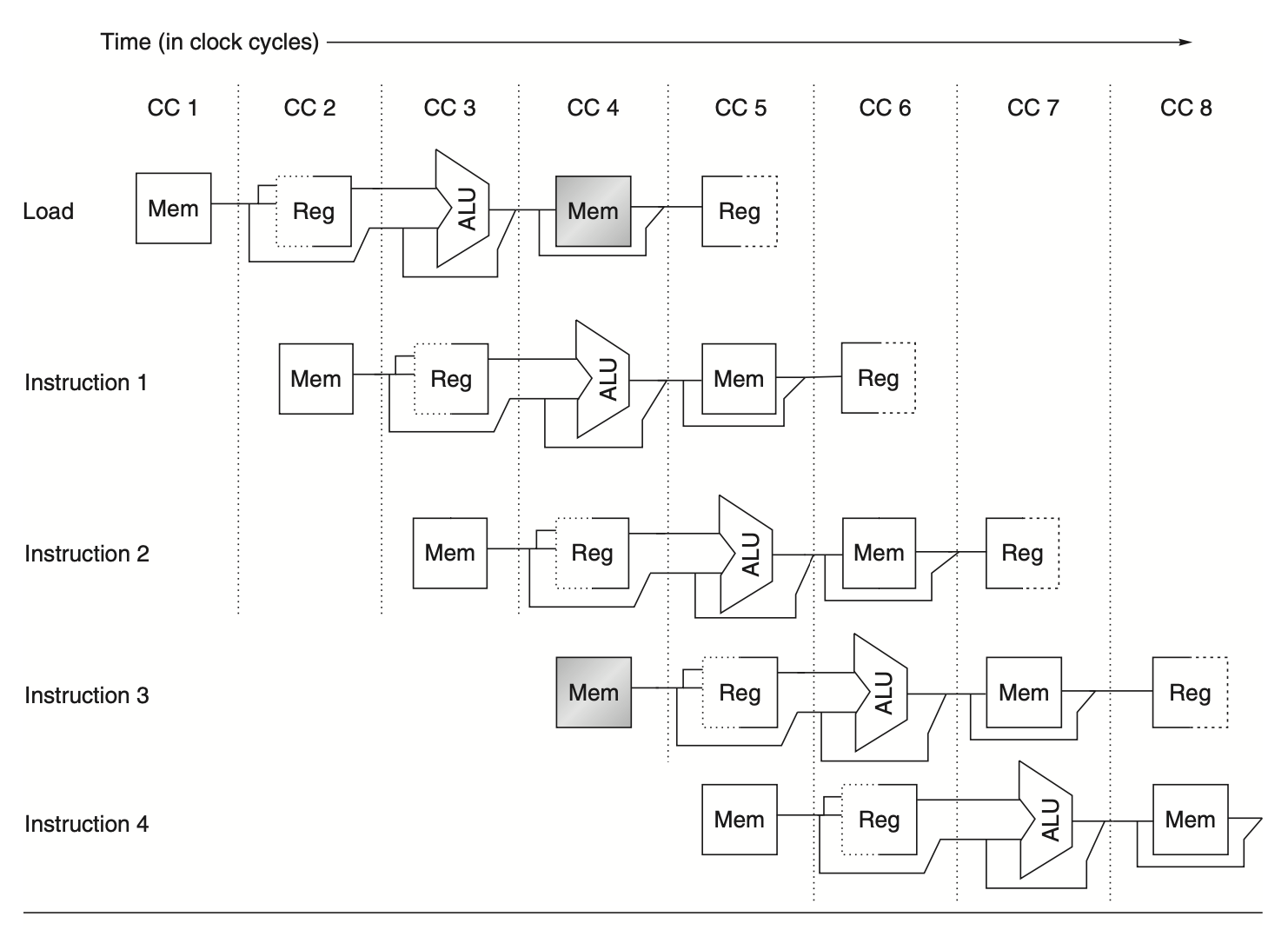
Figure: When a processor has only one memory port, a conflict arises each time a memory reference is made. For instance, in this scenario, the load instruction accesses the memory for data while instruction 3 simultaneously attempts to fetch an instruction from the memory.
Designers often represent stall behavior with a simple diagram showing only the pipeline stage names, as seen in the following figure. This figure illustrates the stall by marking the cycle with no action and shifting instruction 3 to the right, delaying its start and finish by one cycle. The bubble effectively occupies the instruction slot as it progresses through the pipeline.
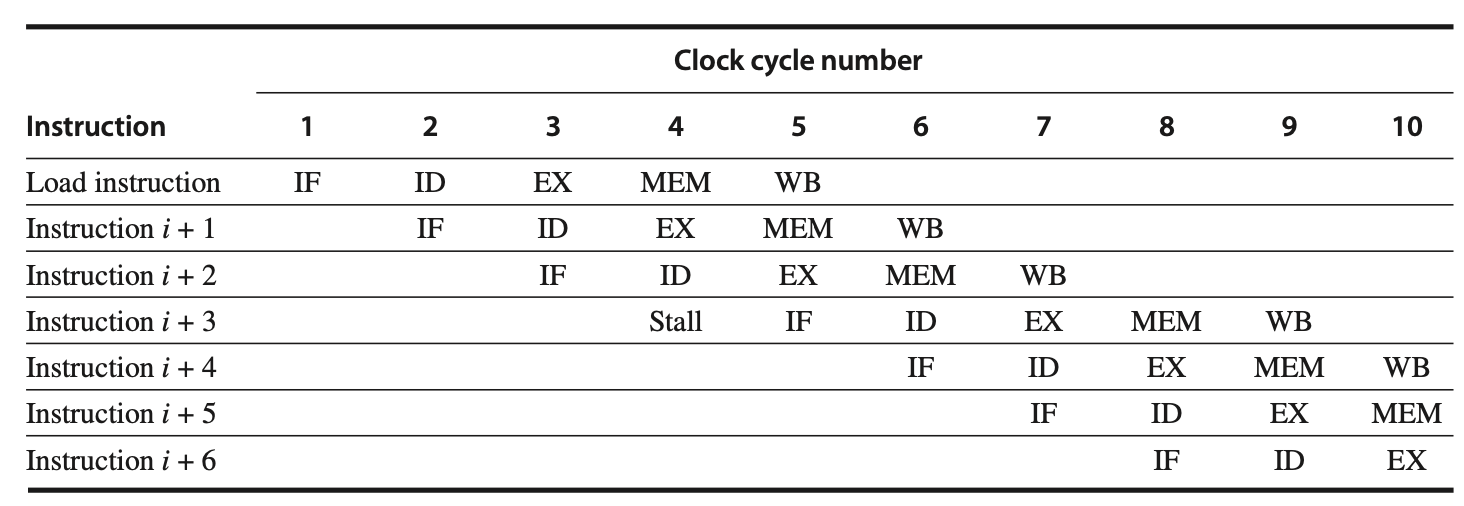
Figure: A pipeline stalled due to a structural hazard—handling a load with a single memory port. In this example, the load instruction effectively takes over an instruction-fetch cycle, leading to a pipeline stall. As a result, no instruction is initiated during clock cycle 4 (which would normally start instruction ( i + 3 )). With the fetch instruction stalled, all preceding instructions in the pipeline continue as usual. The stall cycle progresses through the pipeline, preventing any instruction from completing on clock cycle 8. Pipeline diagrams may sometimes show the stall occupying an entire horizontal row, moving instruction 3 to the next row. Regardless of the depiction, the result is the same: instruction ( i + 3 ) doesn't start execution until cycle 5. We use the format above because it occupies less space in the figure. Note that this illustration assumes that instructions ( i + 1 ) and ( i + 2 ) do not involve memory references.
All else being equal, a processor without structural hazards will always have a lower CPI. So why would designers permit structural hazards? The main reason is cost reduction. Pipelining all functional units or duplicating them can be prohibitively expensive. For example, processors that support an instruction and a data cache access every cycle to avoid the previously mentioned structural hazard require double the total memory bandwidth and often higher bandwidth at the pins. Similarly, fully pipelining a floating-point (FP) multiplier requires many gates. If the structural hazard is infrequent, the cost to avoid it may not be justified.
Data Hazards
A significant effect of pipelining is altering the relative timing of instructions by overlapping their execution. This overlap introduces data and control hazards. Data hazards occur when the pipeline changes the order of read/write accesses to operands, differing from the order seen by sequentially executing instructions on an unpipelined processor. Consider the following pipelined execution sequence:
DADD R1, R2, R3
DSUB R4, R1, R5
AND R6, R1, R7
OR R8, R1, R9
XOR R10, R1, R11
All instructions following the DADD depend on its result. As shown in the following figure, the DADD instruction writes the value of R1 during the WB stage, but the DSUB instruction reads the value during its ID stage. This issue is known as a data hazard. If precautions are not taken, the DSUB instruction will read an incorrect value. The value used by the DSUB is not deterministic: an interrupt between DADD and DSUB could result in DSUB using the updated R1 from DADD, leading to unpredictable behavior, which is unacceptable.
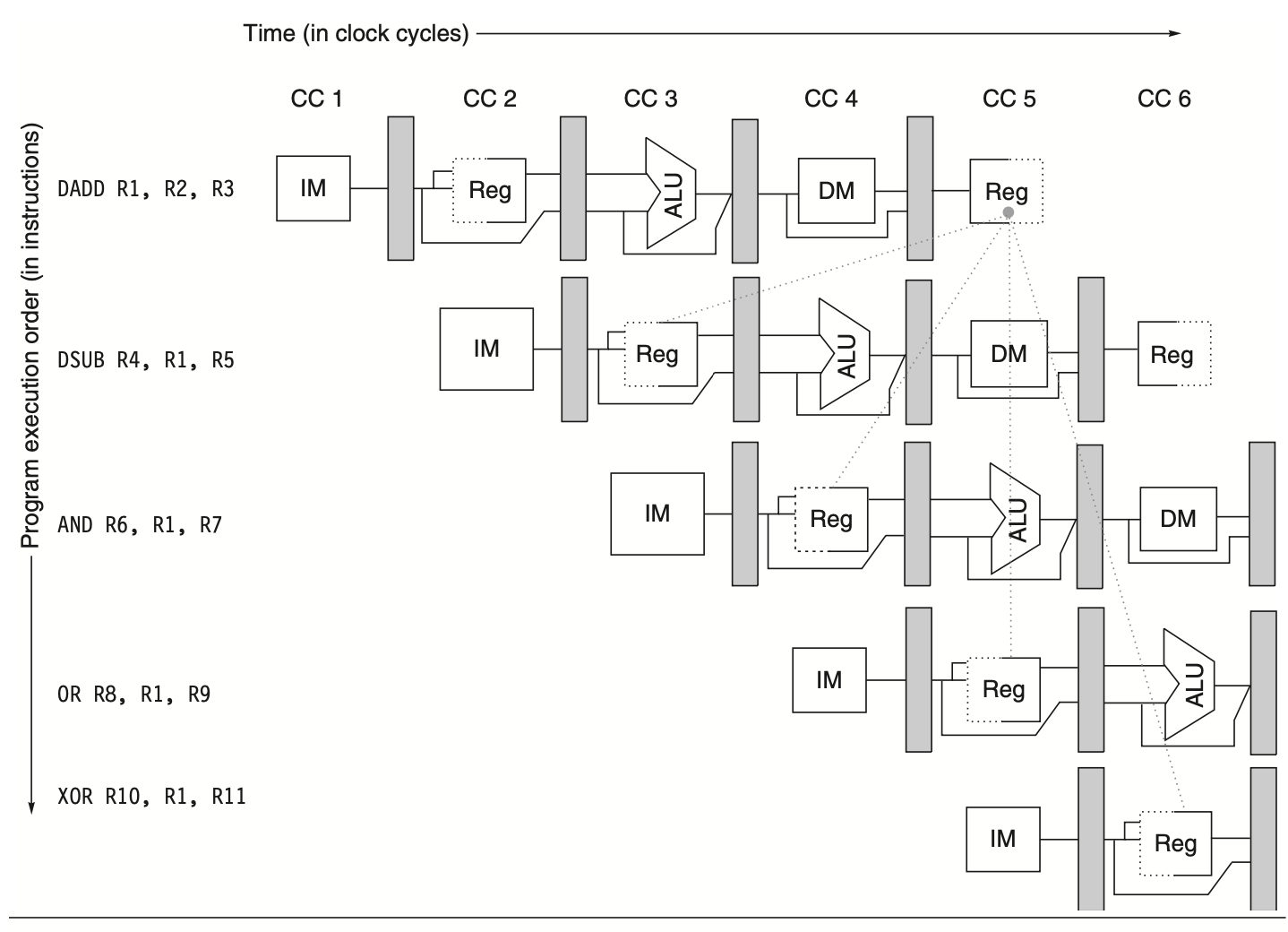
Figure: Using the result of the DADD instruction in the subsequent three instructions creates a hazard because the register write occurs after these instructions attempt to read it.
The AND instruction also suffers from this hazard since the write to R1 completes at the end of clock cycle 5, while AND reads during clock cycle 4, resulting in wrong data. The XOR instruction operates correctly because it reads R1 in clock cycle 6, after the write. Similarly, the OR instruction avoids hazards by performing register file reads in the second half of the cycle and writes in the first half.
Minimizing Data Hazard Stalls by Forwarding
Data hazards like those in the above figure can be mitigated using a hardware technique called forwarding (also known as bypassing or short-circuiting). The key insight in forwarding is that the result is not needed by the DSUB until after DADD produces it. By moving the result from where DADD stores it to where DSUB needs it, stalls can be avoided. Forwarding operates as follows:
The ALU result from both the EX/MEM and MEM/WB pipeline registers is fed back to the ALU inputs.
If the forwarding hardware detects that the previous ALU operation has written to a register needed by the current ALU operation, control logic selects the forwarded result as the ALU input instead of the value from the register file.
With forwarding, if the DSUB is stalled, DADD will complete, and the bypass won't be activated. This relationship holds even if an interrupt occurs between the two instructions.
As shown in the above figure, forwarding may involve results from an instruction started 2 cycles earlier. The following figure illustrates this example with bypass paths and highlights the timing of register reads and writes. This sequence executes without stalls.
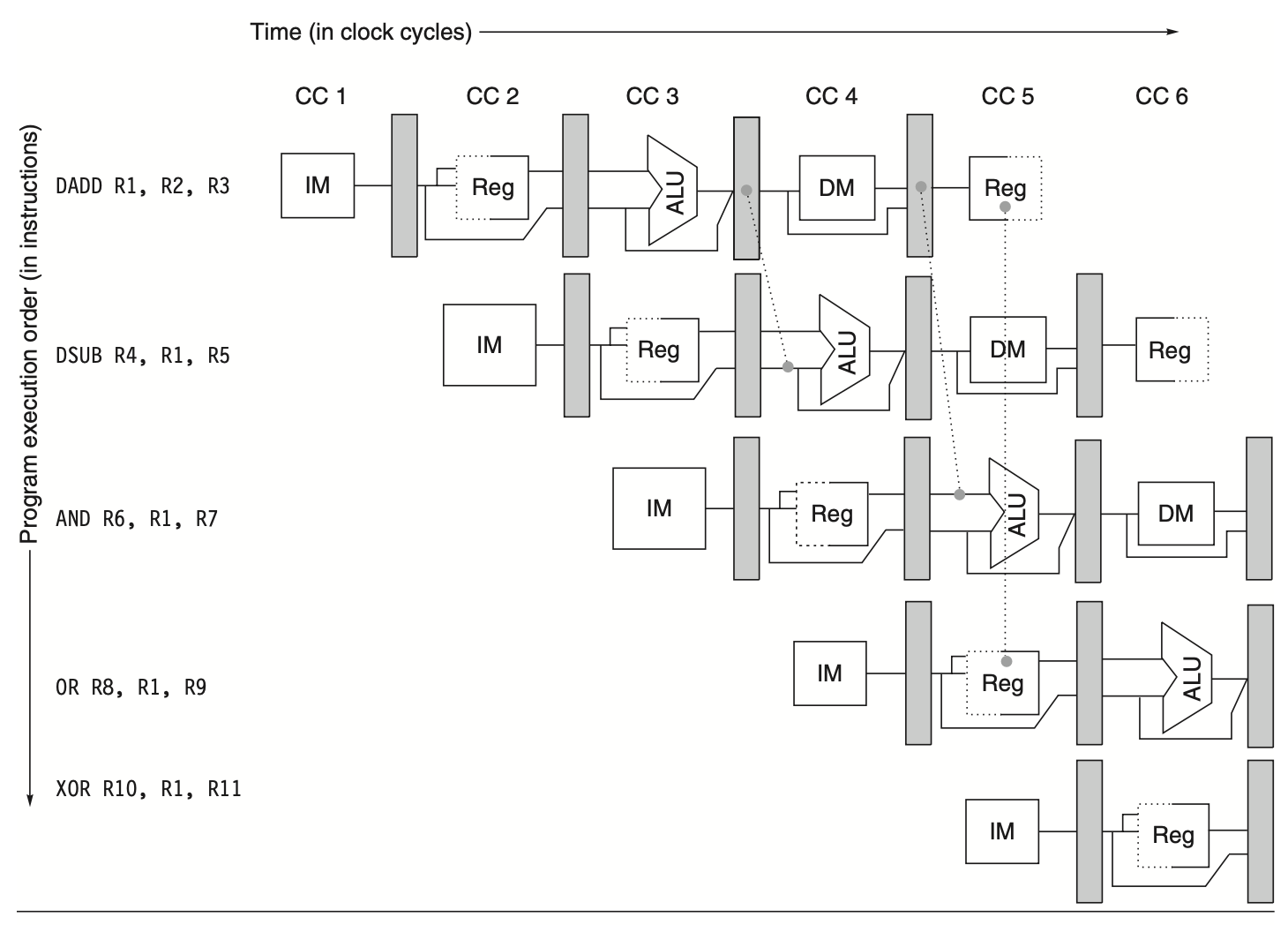
Figure: A sequence of instructions dependent on the DADD result employs forwarding paths to circumvent the data hazard. The DSUB and AND instructions obtain their inputs by forwarding from the pipeline registers to the first ALU input. The OR instruction gets its result by forwarding through the register file, facilitated by reading the registers in the second half of the cycle and writing in the first half, as indicated by the dashed lines on the registers. The forwarded result can be directed to either ALU input; in fact, both ALU inputs can use forwarded inputs from either the same pipeline register or from different pipeline registers. This would happen, for instance, if the AND instruction were AND R6, R1, R4.
Forwarding can also pass results directly to the required functional unit. For example:
DADD R1, R2, R3
LD R4, 0(R1)
SD R4, 12(R1)
To prevent stalls in this sequence, values from the ALU and memory unit outputs are forwarded from pipeline registers to ALU and data memory inputs. The following figure shows the forwarding paths for this example.
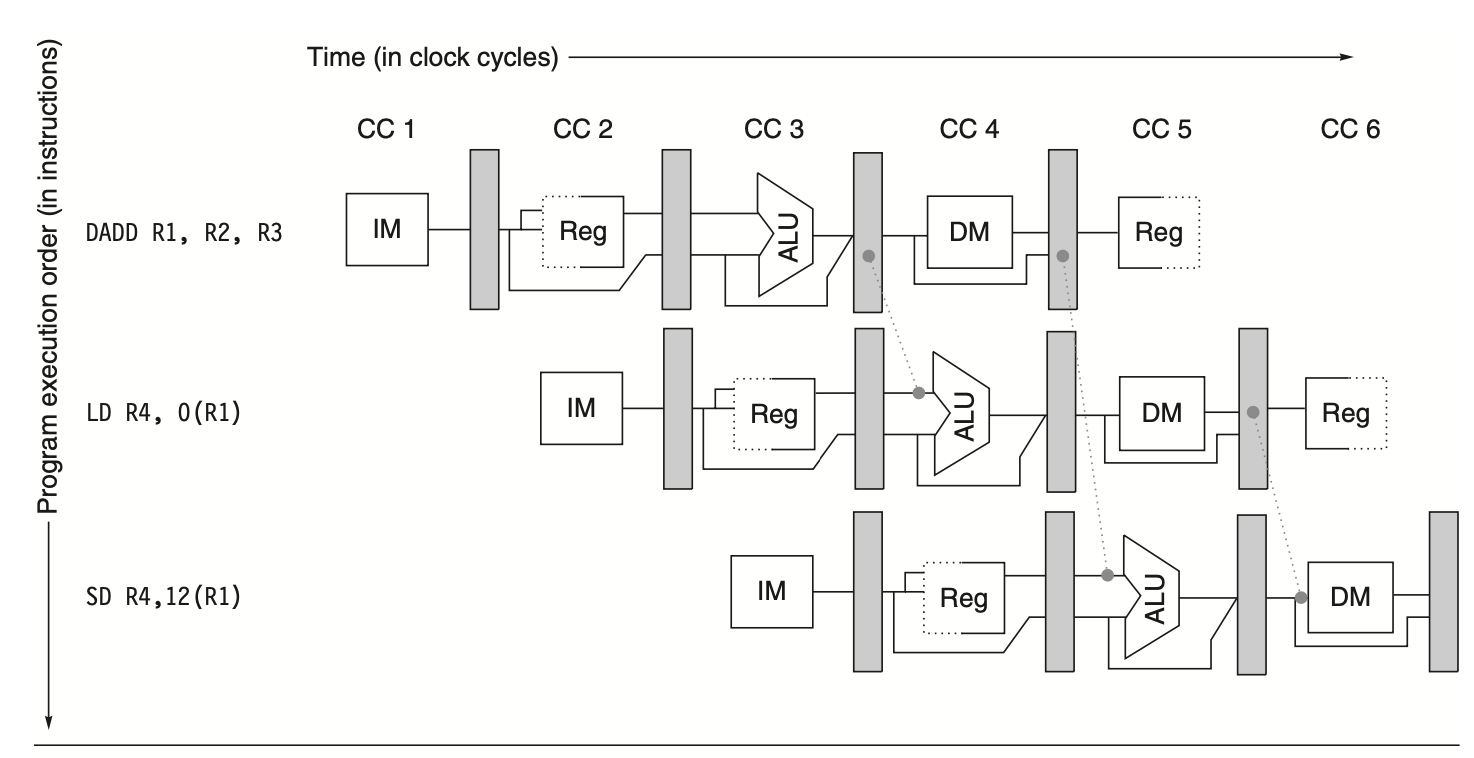
Figure: Forwarding operands required by stores during MEM stage. The load result is forwarded from the memory output to the memory input for storage. Additionally, the ALU output is forwarded to the ALU input for address calculation of both the load and the store, similar to forwarding for another ALU operation. If the store instruction depends on an immediately preceding ALU operation (not depicted above), the result must be forwarded to avoid a stall.
Data Hazards Requiring Stalls
Not all data hazards can be resolved by bypassing. Consider the following sequence:
LD R1, 0(R2)
DSUB R4, R1, R5
AND R6, R1, R7
OR R8, R1, R9
In the following figure, the pipelined data path with bypass paths is shown. Unlike back-to-back ALU operations, the LD instruction doesn't have data until the end of clock cycle 4 (its MEM cycle), while DSUB needs it at the beginning. This load data hazard cannot be eliminated with simple hardware, as it would require a backward-in-time forwarding path.
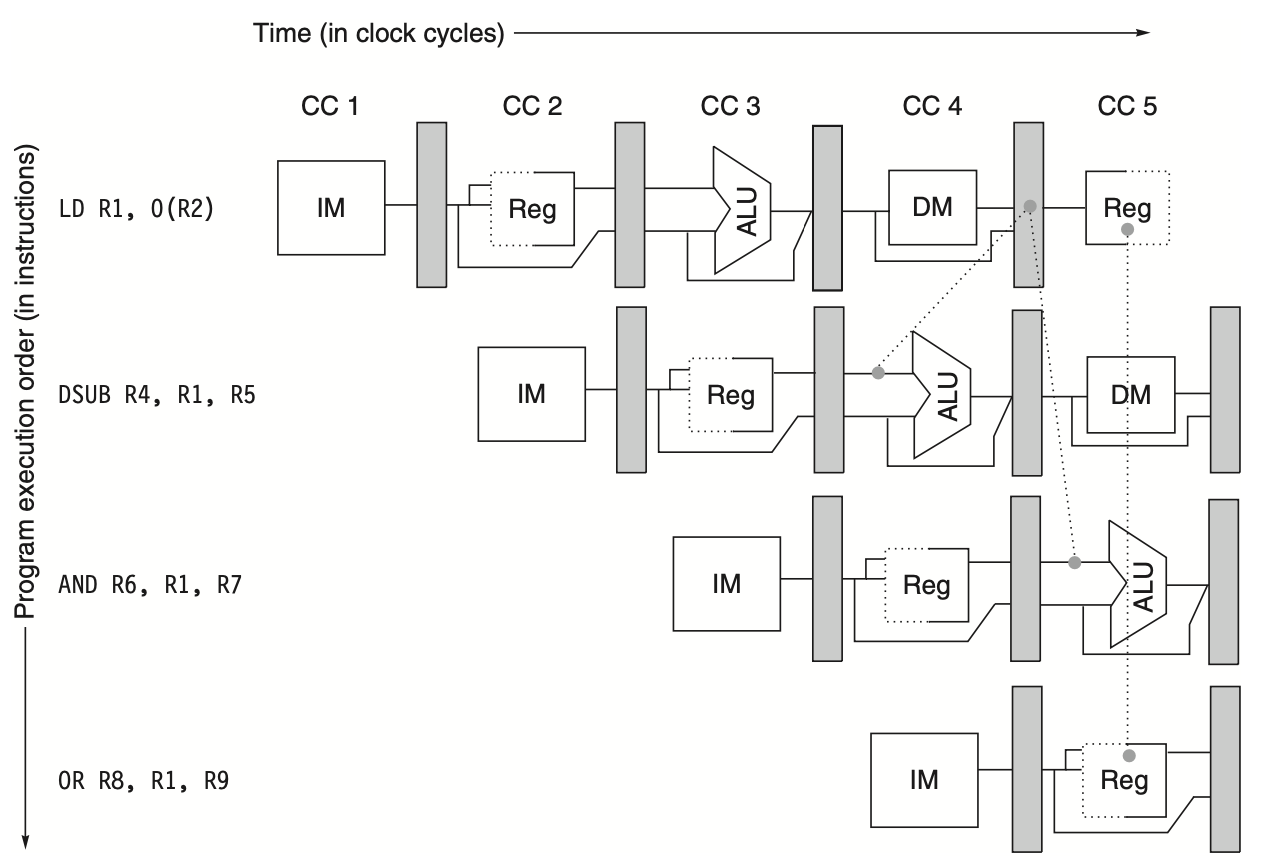
Figure: The load instruction can forward its results to the AND and OR instructions, but not to the DSUB instruction, as that would require forwarding the result before it is produced.
The result from LD can be forwarded to the AND operation, which starts 2 cycles later. Similarly, the OR instruction receives the value through the register file. However, the DSUB instruction receives the forwarded result too late.
The LD instruction introduces a delay or latency that forwarding alone cannot eliminate. Instead, a pipeline interlock is added to detect hazards and stall the pipeline until the hazard is cleared. This interlock causes a stall or bubble, increasing the CPI for the stalled instruction by the stall length (1 clock cycle in this case).
The follownig figure shows the pipeline before and after the stall using pipeline stage names. The stall delays instructions starting with DSUB by 1 cycle, allowing forwarding to AND through the register file and eliminating the need for forwarding to OR. The bubble increases the sequence's completion time by one cycle, with no instructions starting in clock cycle 4 or finishing in cycle 6.
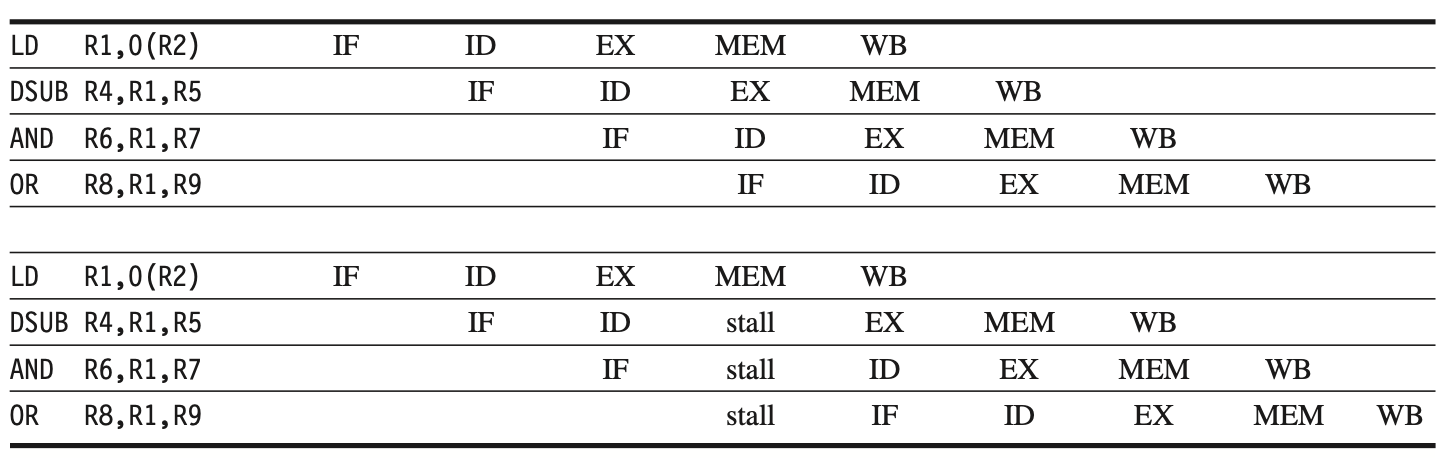
Figure: The top half illustrates the necessity of a stall: The MEM cycle of the load instruction generates a value required in the EX cycle of the DSUB instruction, which happens simultaneously. This issue is resolved by introducing a stall, as depicted in the bottom half.
Branch Hazards
Control hazards, particularly those caused by branch instructions, can lead to significant performance losses in a MIPS pipeline, even more so than data hazards. When a branch is executed, it may change the Program Counter (PC) to a new address or continue to the next sequential instruction. A branch that changes the PC to its target address is called a "taken branch," while a branch that does not is an "untaken" or "not taken" branch. Typically, if instruction (i) is a taken branch, the PC does not change until the end of the Instruction Decode (ID) stage, after completing the address calculation and comparison.
Simplest Method for Handling Branches
The following figure illustrates the simplest method for handling branches: redoing the instruction fetch once a branch is detected during the ID stage. This approach effectively makes the first Instruction Fetch (IF) cycle a stall, as it performs no useful work. If the branch is untaken, repeating the IF stage is unnecessary since the correct instruction was fetched initially. Despite this, this method results in a performance loss of 10% to 30%, depending on the branch frequency. To mitigate this loss, several techniques are employed.
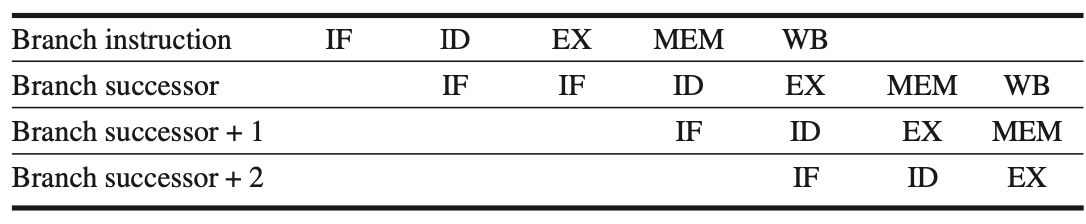
Figure: illustrates that a branch causes a one-cycle stall in the five-stage pipeline. When a branch instruction is encountered, the subsequent instruction is fetched but then ignored. The fetch process restarts once the branch target is determined. If the branch is not taken, the second instruction fetch for the branch successor is unnecessary and redundant. This issue will be addressed in further discussions.
Reducing Pipeline Branch Penalties
To address pipeline stalls caused by branch delays, four simple compile-time schemes are discussed. These methods involve static actions for each branch, fixed throughout execution. Software can minimize the branch penalty by leveraging knowledge of the hardware scheme and branch behavior.
1. Freezing or Flushing the Pipeline
The simplest solution is to freeze or flush the pipeline, holding or deleting any instructions after the branch until the branch destination is known. This method is attractive due to its simplicity in both hardware and software. However, it results in a fixed branch penalty that cannot be reduced by software.
2. Predicted-Not-Taken Scheme
A higher-performance method is to treat every branch as not taken, allowing the hardware to continue as if the branch were not executed. The processor state is not changed until the branch outcome is confirmed. In the simple five-stage pipeline, this scheme involves fetching instructions as if the branch were a normal instruction. If the branch is taken, the fetched instruction is turned into a no-op, and the fetch restarts at the target address. The following figure shows both scenarios.
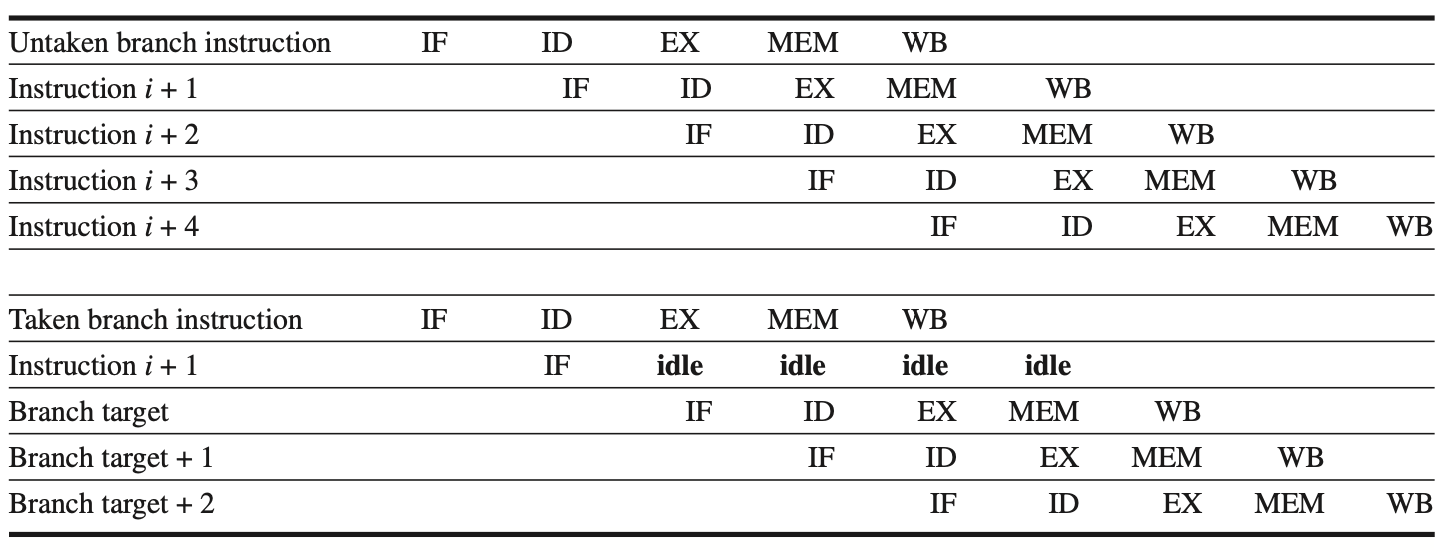
Figure: explains the predicted-not-taken scheme and its impact on the pipeline when the branch is either untaken (top) or taken (bottom).
When the Branch is Untaken: Determined during the ID stage, the pipeline fetches the fall-through instruction and continues execution without any interruptions.
When the Branch is Taken: The pipeline restarts the fetch at the branch target. This restart causes all subsequent instructions in the pipeline to stall for one clock cycle.
3. Predicted-Taken Scheme
An alternative approach is to assume every branch is taken, starting to fetch and execute at the target address as soon as the branch is decoded and the target address is computed. In our five-stage pipeline, this scheme offers no advantage since the target address is known no earlier than the branch outcome. However, in processors with implicitly set condition codes or more powerful branch conditions, the target address might be known before the branch outcome, making this scheme beneficial. The compiler can improve performance by organizing code to align with the hardware's choice.
4. Delayed Branch
A fourth scheme, heavily used in early RISC processors, is the delayed branch. This technique works well in the five-stage pipeline. In a delayed branch, the execution cycle with a branch delay of one is:
Branch instruction
Sequential successor 1
Branch target if taken
The sequential successor, in the branch delay slot, is executed regardless of whether the branch is taken. The following figure illustrates the pipeline behavior with a branch delay. Most processors with delayed branch use a single instruction delay; other techniques are employed for longer branch penalties.
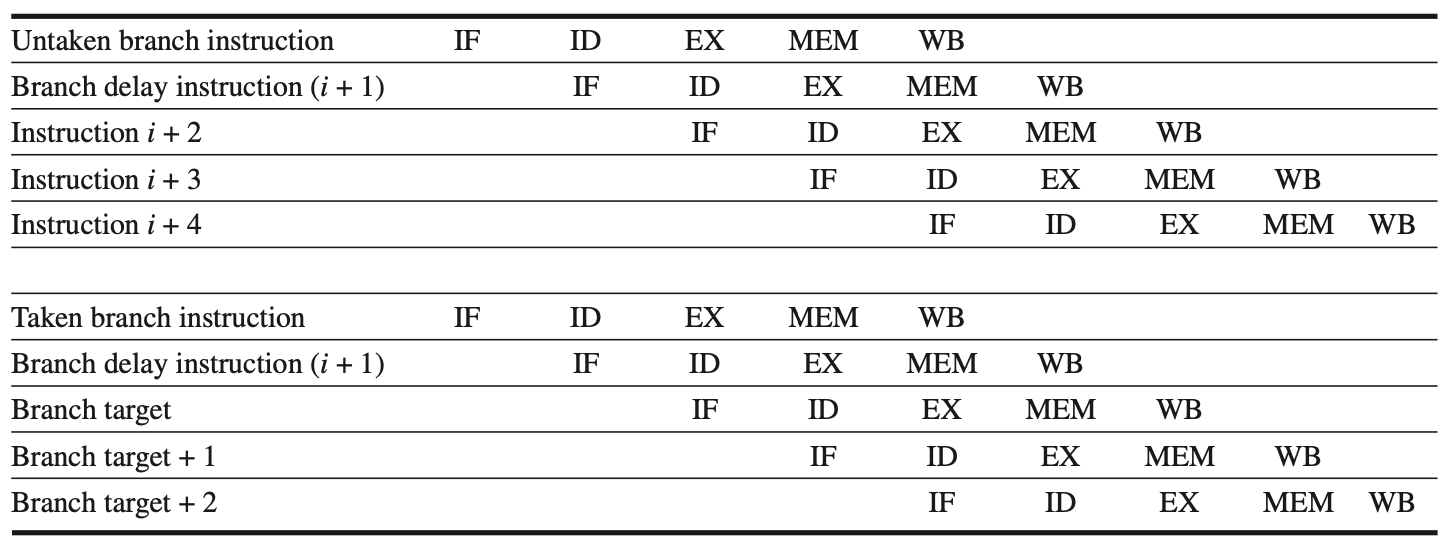
Figure: describes how a delayed branch operates, whether the branch is taken or not.
Execution of Delay Slot Instructions: In MIPS, which has one delay slot, the instructions in the delay slot are always executed.
If the Branch is Untaken: Execution proceeds with the instruction following the branch delay instruction.
If the Branch is Taken: Execution continues at the branch target.
Ambiguity with Branches in Delay Slot: If the instruction in the branch delay slot is also a branch, the situation becomes unclear. Specifically, if the initial branch is not taken, it is uncertain what should happen to the branch in the delay slot. Due to this confusion, architectures with delay branches often prohibit placing a branch instruction in the delay slot.
The compiler's job is to ensure the successor instructions are valid and useful. Various optimizations are used, as shown in the following figure. The limitations on delayed-branch scheduling arise from the restrictions on instructions scheduled into delay slots and the ability to predict at compile time whether a branch is likely to be taken. To improve the compiler's ability to fill branch delay slots, most processors with conditional branches have introduced a canceling or nullifying branch. In a canceling branch, the instruction includes the predicted branch direction. If the branch behaves as predicted, the instruction in the branch delay slot is executed as usual. If the branch is incorrectly predicted, the instruction in the branch delay slot is turned into a no-op.
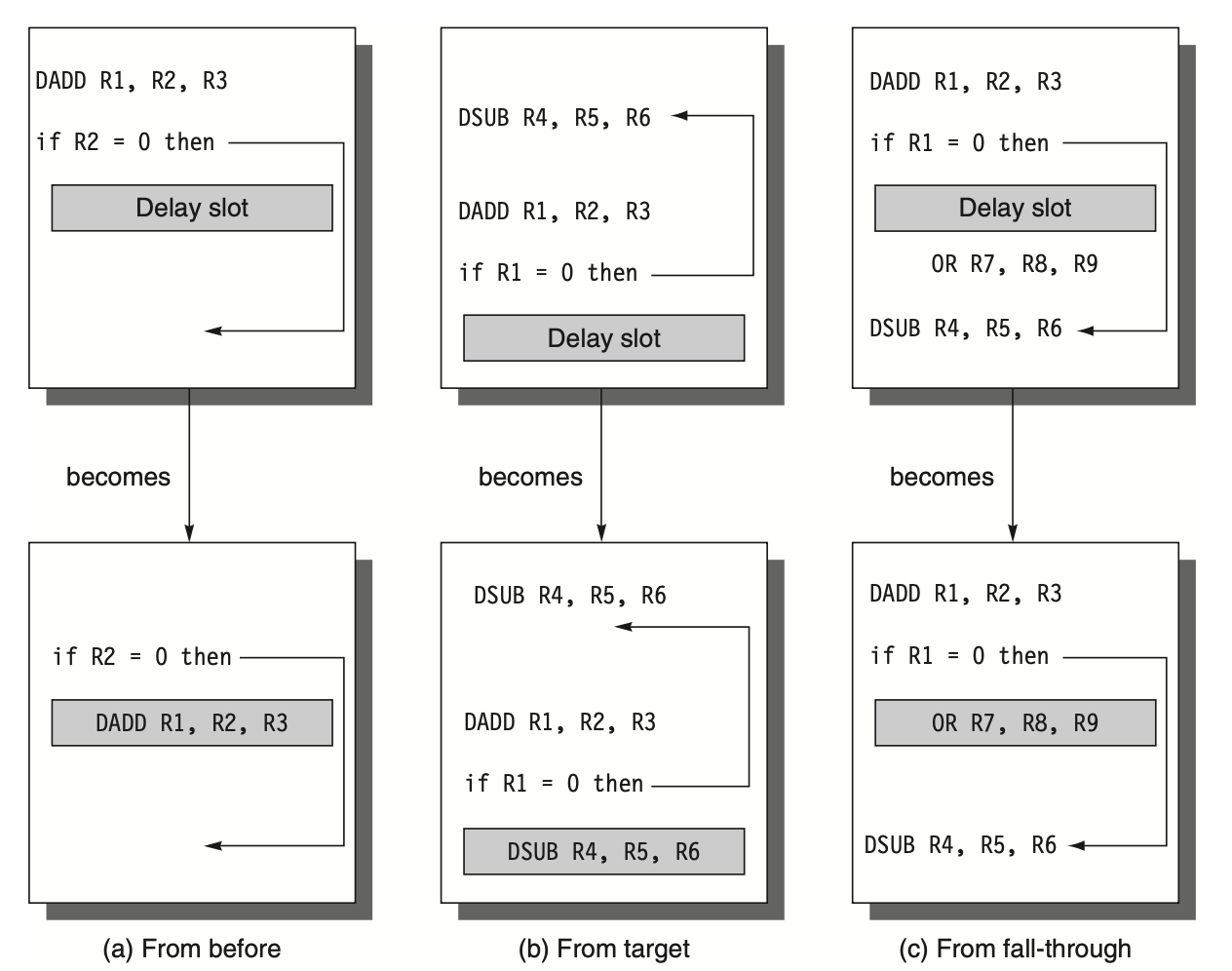
Figure: discusses how to schedule instructions in the branch delay slot. The figure shows the code before and after scheduling in the top and bottom boxes of each pair, respectively.
Strategy (a): The delay slot is filled with an independent instruction from before the branch, which is the optimal approach.
Strategy (b): If strategy (a) isn't feasible due to dependencies (e.g., the use of R1 in the branch condition prevents moving the DADD instruction whose destination is R1), the delay slot is filled with an instruction from the branch target. This typically involves copying the target instruction, as it can be reached via another path. This strategy is preferred when the branch is highly likely to be taken, such as in loop branches.
Strategy (c): The delay slot is filled with an instruction from the not-taken fall-through path. To make this optimization valid for both (b) and (c), it must be acceptable to execute the moved instruction even if the branch goes in an unexpected direction. "Acceptable" means that although the work is unnecessary, the program will still execute correctly. For instance, in (c), if R7 were an unused temporary register when the branch goes in an unexpected direction, the program's correctness would not be affected.
Performance of Branch Schemes
To determine the effective performance of different branch handling schemes, we consider the pipeline speedup with branch penalties, assuming an ideal CPI (Clock Cycles Per Instruction) of 1. The pipeline speedup formula is:
$$\text{Pipeline speedup} = \frac{\text{Pipeline depth}}{1 + \text{Pipeline stall cycles from branches}}$$
Given that:
$$\text{Pipeline stall cycles from branches} = \text{Branch frequency} \times \text{Branch penalty}$$
We derive the speedup as:
$$\text{Pipeline speedup} = \frac{\text{Pipeline depth}}{1 + \text{Branch frequency} \times \text{Branch penalty}}$$
Branch frequency and branch penalty can arise from both unconditional and conditional branches. However, conditional branches are more frequent and thus have a greater impact on performance.
Reducing the Cost of Branches through Prediction
As pipelines become deeper and branch penalties increase, traditional methods like delayed branches become insufficient. More aggressive branch prediction techniques are necessary to maintain performance. These techniques fall into two categories: low-cost static schemes using compile-time information and dynamic strategies based on program behavior. Let's explore both approaches.
Static Branch Prediction
Static branch prediction can be improved using profile information from earlier runs of the program. Branch behavior is often bimodally distributed, meaning that an individual branch is usually either highly biased towards being taken or not taken. The following figure demonstrates the success of this strategy. Even with different input data, the accuracy of profile-based prediction changes only slightly.
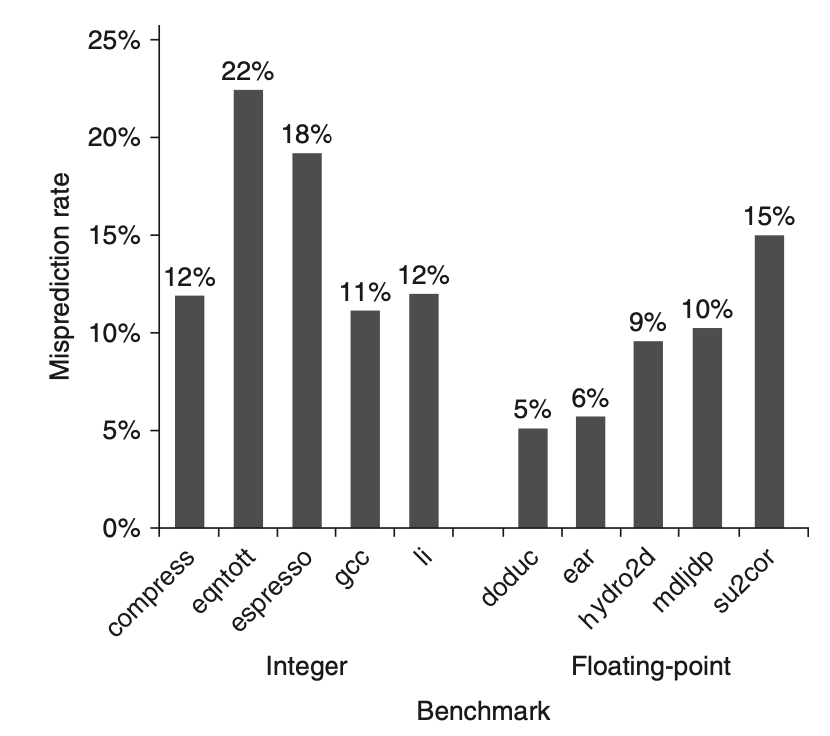
Figure: indicates that the misprediction rate for a profile-based predictor on SPEC92 benchmarks varies significantly.
Floating-Point Programs: These programs exhibit a better performance with an average misprediction rate of 9% and a standard deviation of 4%.
Integer Programs: These have a higher average misprediction rate of 15% with a standard deviation of 5%.
The overall performance is influenced by both the accuracy of the prediction and the branch frequency, which ranges from 3% to 24%.
The effectiveness of a branch prediction scheme depends on both its accuracy and the frequency of conditional branches, which varies from 3% to 24% in SPEC benchmarks. The higher misprediction rate in integer programs, which typically have a higher branch frequency, is a major limitation of static branch prediction. This leads us to dynamic branch prediction methods, employed by most recent processors.
Dynamic Branch Prediction and Branch-Prediction Buffers
The simplest dynamic branch-prediction scheme is a branch-prediction buffer or branch history table. This small memory is indexed by the lower portion of the branch instruction address and contains a bit indicating whether the branch was recently taken. This simple buffer does not have tags and primarily reduces branch delay when it is longer than the time to compute possible target PCs.
The prediction in the buffer is a hint assumed to be correct, and fetching begins in the predicted direction. If the hint is wrong, the prediction bit is inverted and stored back. The buffer acts like a cache where every access is a hit. The performance of this buffer depends on how often the prediction is for the relevant branch and how accurate it is when matched.
Improving the Prediction Scheme
The 1-bit prediction scheme has a performance shortcoming: even if a branch is almost always taken, it will likely be predicted incorrectly twice when it is not taken because the misprediction flips the prediction bit. To address this, 2-bit prediction schemes are often used. In a 2-bit scheme, a prediction must miss twice before changing, as shown in the following figure.
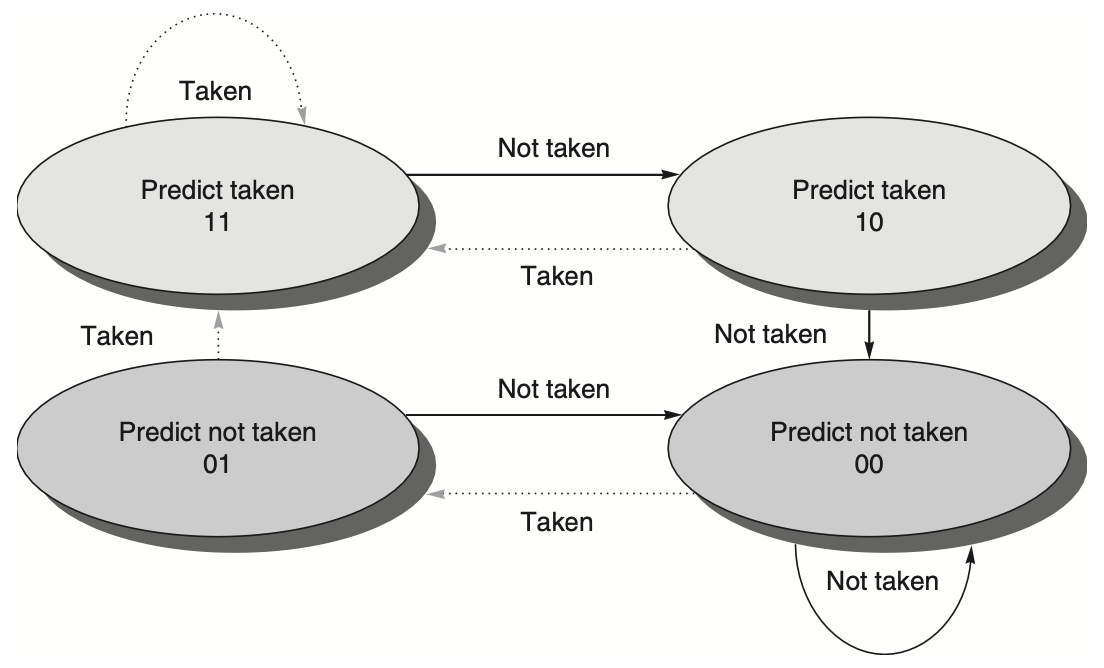
Figure: explains the use of a 2-bit prediction scheme to improve branch prediction accuracy. By utilizing 2 bits instead of 1, branches that are strongly biased towards being taken or not taken are mispredicted less frequently compared to a 1-bit predictor. The 2-bit scheme encodes four states in the system. This scheme is a specialized version of a more general approach using an \(n\)-bit saturating counter for each entry in the prediction buffer. With an \(n\)-bit counter, values range from 0 to \(2^n - 1\). When the counter value is greater than or equal to half its maximum value \(2^n / 2\), the branch is predicted as taken; otherwise, it is predicted as untaken. Studies show that 2-bit predictors perform almost as well as more complex \(n\)-bit predictors, leading most systems to prefer 2-bit branch predictors over the more general \(n\)-bit predictors.
A branch-prediction buffer can be implemented as a small special "cache" accessed with the instruction address during the IF stage or as a pair of bits attached to each block in the instruction cache. If a branch is predicted as taken, fetching begins from the target as soon as the PC is known; otherwise, sequential fetching and executing continue. If the prediction is wrong, the prediction bits are updated accordingly.
Prediction Accuracy
What kind of accuracy can be expected from a branch-prediction buffer using 2 bits per entry in real applications? The following figure shows that for the SPEC89 benchmarks, a 4096-entry branch-prediction buffer achieves prediction accuracy ranging from over 99% to 82%, with a misprediction rate of 1% to 18%. Although a 4K entry buffer was considered small by 2005 standards, a larger buffer could yield better results.
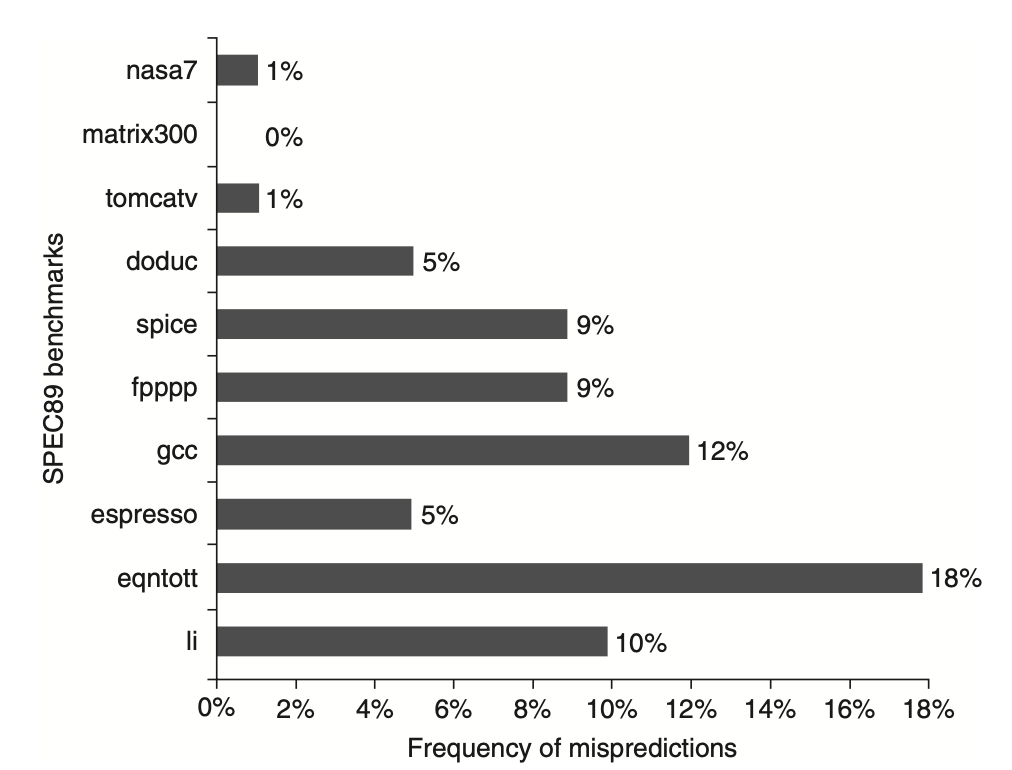
Figure: highlights the prediction accuracy of a 4096-entry 2-bit prediction buffer for SPEC89 benchmarks.
Integer Benchmarks: The misprediction rate for integer benchmarks (such as gcc, espresso, eqntott, and li) is substantially higher, averaging 11%.
Floating-Point Programs: These programs have a significantly lower misprediction rate, averaging 4%. Even when excluding the floating-point kernels (nasa7, matrix300, and tomcatv), floating-point benchmarks still demonstrate higher accuracy than integer benchmarks.
These findings are derived from a branch prediction study conducted using the IBM Power architecture with optimized code. Although the data pertain to an older subset of SPEC benchmarks, newer and larger benchmarks are expected to exhibit slightly worse behavior, particularly for integer benchmarks.
As we strive to exploit more Instruction-Level Parallelism (ILP), the accuracy of branch prediction becomes critical. The accuracy of predictors for integer programs, which typically have higher branch frequencies, is lower than for loop-intensive scientific programs. We can improve this by increasing the buffer size or enhancing the accuracy of each prediction scheme. The following figure shows that a 4K entry buffer performs comparably to an infinite buffer for SPEC benchmarks, indicating that hit rate is not the major limiting factor. Simply increasing the number of bits per predictor without changing the structure has little impact. Therefore, enhancing the accuracy of each predictor is key to better performance.
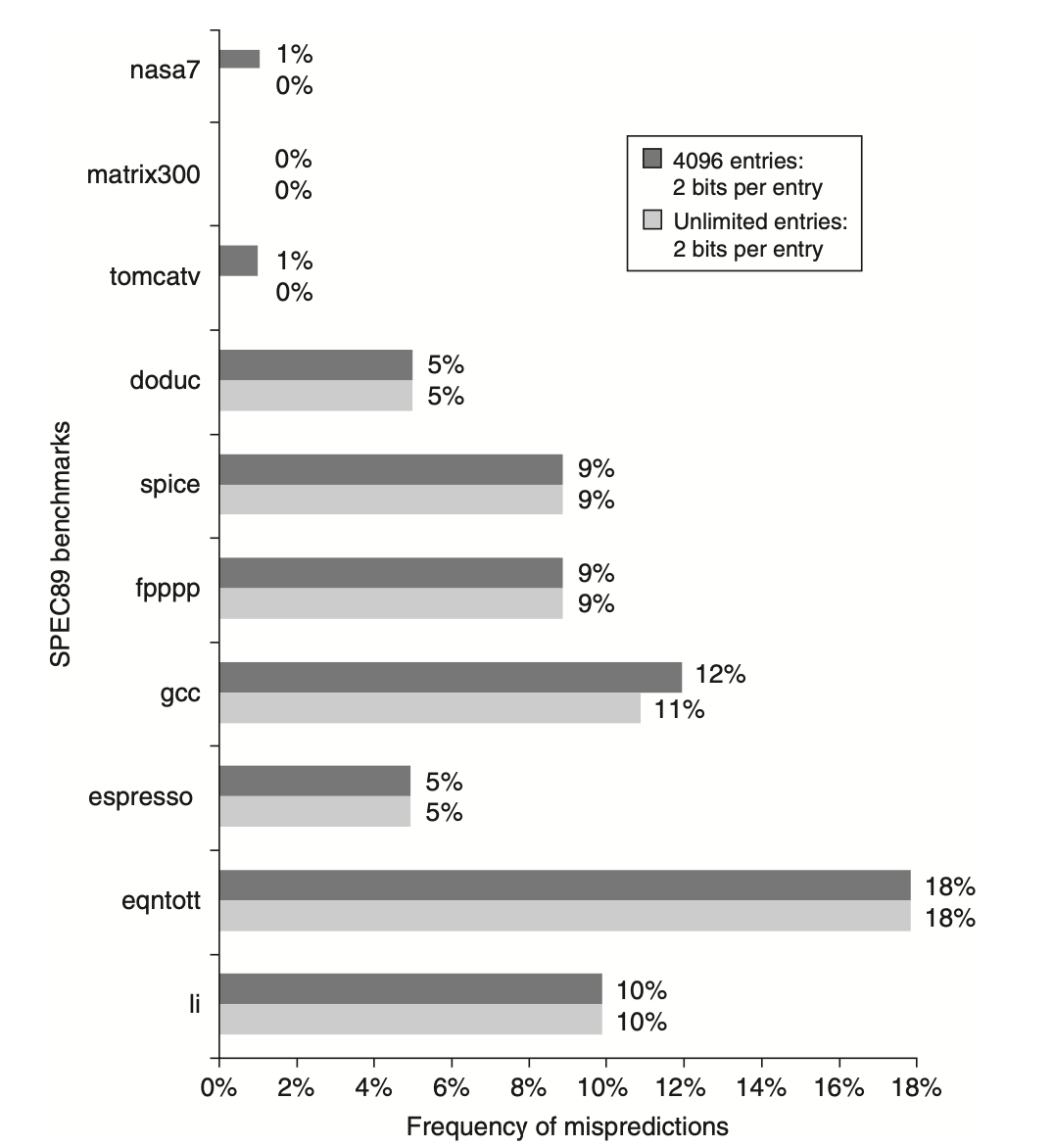
Figure: compares the prediction accuracy of a 4096-entry 2-bit prediction buffer with an infinite buffer for SPEC89 benchmarks. Although the data pertains to an older version of a subset of SPEC benchmarks, the results suggest that comparable accuracy can be achieved for newer versions. It is estimated that an 8K-entry buffer may be required to match the performance of an infinite 2-bit predictor.
Challenges in Implementing Pipelining
While pipelining improves CPU performance by overlapping the execution of instructions, it introduces several challenges, particularly when handling exceptional situations and accommodating different instruction sets. This section explores these complications in detail.
Dealing with Exceptions
Handling exceptional situations in a pipelined CPU is difficult because overlapping instructions make it challenging to determine whether an instruction can safely change the CPU state. In a pipelined CPU, an instruction is executed in stages over several clock cycles. Other instructions in the pipeline might raise exceptions, forcing the CPU to abort the in-progress instructions.
Types of Exceptions and Requirements
The terminology for exceptional situations—where the normal execution order of instructions changes—varies among CPUs. Common terms include interrupt, fault, and exception. Here, we use the term "exception" to encompass all these mechanisms, which include:
I/O device requests
Invoking an operating system service from a user program
Tracing instruction execution
Breakpoints (programmer-requested interrupts)
Integer arithmetic overflow
Floating-point (FP) arithmetic anomalies
Page faults (data not in main memory)
Misaligned memory accesses (if alignment is required)
Memory protection violations
Using undefined or unimplemented instructions
Hardware malfunctions
Power failures
Although "exception" covers all these events, each event has specific characteristics determining the necessary hardware actions. These characteristics can be categorized along five semi-independent axes:
Synchronous vs. Asynchronous:
Synchronous: The event occurs at the same place every time the program runs with the same data and memory allocation.
Asynchronous: Caused by external devices, asynchronous events (except for hardware malfunctions) can usually be handled after the current instruction completes, making them easier to manage.
User Requested vs. Coerced:
User Requested: Directly asked for by the user task and predictable. These are treated as exceptions because the same mechanisms for saving and restoring state are used.
Coerced: Caused by hardware events beyond the user program's control, making them unpredictable and harder to implement.
User Maskable vs. User Nonmaskable:
- User Maskable: Can be disabled by a user task, controlling whether the hardware responds to the exception.
Within vs. Between Instructions:
Within Instructions: Occur during the middle of execution and are typically synchronous. These are harder to handle because the instruction must be stopped and restarted.
Between Instructions: Recognized between instructions and easier to manage. Asynchronous exceptions within instructions arise from catastrophic situations (e.g., hardware malfunction) and always cause program termination.
Resume vs. Terminate:
Resume: Program execution continues after the interrupt.
Terminate: Program execution stops after the interrupt. Terminating exceptions are easier to implement since the CPU need not restart the program after handling the exception.
Implementing exceptions that occur within instructions and must be resumed is particularly challenging. This requires another program to save the executing program's state, correct the exception cause, and restore the state before retrying the instruction that caused the exception. This process must be invisible to the executing program. A pipeline that allows handling exceptions, saving the state, and restarting without affecting program execution is considered restartable. While early supercomputers and microprocessors often lacked this property, almost all modern processors support it, especially for the integer pipeline, as it is necessary for implementing virtual memory.
Stopping and Restarting Execution in Pipelined CPUs
Handling exceptions in pipelined CPUs is particularly challenging due to two properties: they often occur within instructions and must be restartable. For instance, a virtual memory page fault during a data fetch in the MEM stage of a MIPS pipeline requires restarting the pipeline in the correct state. This necessitates safely shutting down the pipeline and saving the state. Here, we discuss the steps and considerations for stopping and restarting execution in a pipelined CPU.
Steps to Handle Exceptions
When an exception occurs, the pipeline control can safely save the pipeline state by taking the following steps:
Force a Trap Instruction:
- Insert a trap instruction into the pipeline on the next Instruction Fetch (IF) cycle.
Turn Off Writes:
- Until the trap is taken, disable all writes for the faulting instruction and all subsequent instructions in the pipeline. This can be achieved by placing zeros into the pipeline latches for all instructions starting from the one that generated the exception. This prevents any state changes for incomplete instructions before the exception is handled.
Save the PC:
- Once the exception-handling routine in the operating system gains control, it saves the Program Counter (PC) of the faulting instruction. This PC will be used to return from the exception later.
Handling Delayed Branches
When delayed branches are used, re-creating the processor state with a single PC becomes impossible because the instructions in the pipeline may not be sequentially related. To address this, we need to save and restore multiple PCs, corresponding to the length of the branch delay plus one.
Returning from Exceptions
After handling the exception, special instructions are used to return the processor to normal operation by reloading the PCs and restarting the instruction stream. In MIPS, the instruction "Return From Exception" (RFE) is used for this purpose. If the pipeline can be stopped so that the instructions before the faulting instruction are completed and those after it can be restarted from scratch, the pipeline is said to have precise exceptions.
Precise vs. Imprecise Exceptions
Ideally, the faulting instruction should not have changed the state, and handling some exceptions correctly requires that the faulting instruction has no effects. However, for some exceptions, such as floating-point exceptions, the faulting instruction may write its result before the exception can be handled. In such cases, the hardware must be able to retrieve the source operands, even if the destination is one of the source operands. Floating-point operations often complete out of order, complicating the retrieval process.
To manage this, many high-performance CPUs offer two modes of operation:
Precise Exception Mode:
- Ensures precise exceptions but allows less overlap among floating-point instructions, making it slower and primarily useful for debugging.
Performance Mode:
- Faster, allowing more overlap but potentially resulting in imprecise exceptions.
Supporting precise exceptions is essential in many systems, especially those with demand paging or IEEE arithmetic trap handlers. For integer pipelines, precise exceptions are easier to implement, and supporting virtual memory strongly motivates their inclusion. Consequently, designers and architects typically ensure precise exceptions for integer pipelines.
Handling Exceptions in the MIPS Pipeline
Managing exceptions in the MIPS pipeline involves ensuring that exceptions are handled precisely and in order, even when multiple instructions are in execution. Here, we explore how exceptions are managed in the MIPS pipeline, with examples illustrating potential issues and solutions.
Example of Multiple Exceptions
Consider the following sequence of instructions:
LD IF ID EX MEM WB
DADD IF ID EX MEM WB
In this example:
The
LDinstruction might cause a data page fault in the MEM stage.The
DADDinstruction might cause an arithmetic exception in the EX stage.
Both exceptions could occur simultaneously because multiple instructions are in execution at different pipeline stages. The typical approach to handle this situation is to deal with the data page fault first and restart execution. The arithmetic exception will reoccur (assuming the software is correct), and it can be handled independently.
Out-of-Order Exceptions
In reality, exceptions might occur out of order. For example:
The
LDinstruction could encounter a data page fault in the MEM stage.The
DADDinstruction could encounter an instruction page fault in the IF stage.
Although the instruction page fault occurs first (caused by the later instruction), the pipeline must handle the exception caused by the earlier LD instruction first to maintain precise exceptions.
Managing Precise Exceptions
To handle precise exceptions, the pipeline employs an exception status vector:
Exception Status Vector:
All exceptions caused by an instruction are posted in a status vector associated with that instruction.
This status vector travels with the instruction through the pipeline stages.
Disabling Writes:
- Once an exception is indicated in the status vector, any control signal that might cause data to be written (register writes and memory writes) is turned off.
Handling Stores:
- Since a store instruction can cause an exception during the MEM stage, the hardware must prevent the store from completing if it raises an exception.
Exception Handling Process
When an instruction reaches the WB stage (or is about to leave the MEM stage), the following steps occur:
Checking Exception Status:
The exception status vector is checked to determine if any exceptions are posted.
Exceptions are handled in the order they would occur in an unpipelined processor, starting with the earliest instruction.
Ensuring Order:
This process ensures that exceptions are seen on instruction
ibefore any are seen on instructioni+1.Any actions taken in earlier pipeline stages on behalf of instruction
imay be invalidated, but since writes were disabled, no state changes could have occurred.
Complexity with Floating-Point Operations
Maintaining this precise model for floating-point (FP) operations is more challenging due to their longer execution times and potential for out-of-order completion. We will explore these complexities in more detail in subsequent sections.
Instruction Set Complications in Pipelining
In MIPS architecture, no instruction produces more than one result, and results are written only at the end of an instruction's execution. When an instruction completes successfully, it is termed as "committed." In the MIPS integer pipeline, all instructions are committed at the end of the MEM stage (or the beginning of the WB stage), ensuring no state changes before this point. This makes handling precise exceptions straightforward. However, some processors have instructions that modify the state mid-execution, before the instruction and its predecessors are guaranteed to complete. This introduces complexities in maintaining precise exceptions.
Example: Autoincrement Addressing in IA-32
In the IA-32 architecture, autoincrement addressing modes update registers mid-execution. If an instruction with this behavior is aborted due to an exception, the processor state will be altered. Identifying the exact instruction that caused the exception without additional hardware support results in imprecise exceptions because the instruction will be partially complete. Restarting the instruction stream after such imprecise exceptions is challenging.
Alternatively, we could avoid state updates before the instruction commits, but this is difficult and costly due to potential dependencies on the updated state. For example, consider a VAX instruction that autoincrements the same register multiple times. To maintain a precise exception model, most processors with such instructions can back out any state changes made before the instruction is committed. If an exception occurs, the processor resets the state to its value before the interrupted instruction started.
Complex Instructions: VAX and IBM 360
Instructions that update memory state during execution, such as string copy operations on the VAX or IBM 360, further complicate the situation. To interrupt and restart these instructions, they use general-purpose registers as working registers. The state of the partially completed instruction is always in the registers, which are saved and restored on an exception, allowing the instruction to continue.
In the VAX, an additional state bit records when an instruction has started updating the memory state. This bit helps the CPU determine whether to restart the instruction from the beginning or from the middle after an exception. The IA-32 string instructions also use registers as working storage, ensuring the state of such instructions is preserved and restored.
Condition Codes
Condition codes present another set of difficulties. Many processors set condition codes implicitly as part of the instruction. This decouples the condition evaluation from the actual branch, but it can cause scheduling issues for pipeline delays between setting the condition code and the branch. Most instructions that set the condition code cannot be used in delay slots between the condition evaluation and the branch.
In processors with condition codes, the branch condition evaluation must be delayed until all previous instructions have had a chance to set the condition code. Explicitly set condition codes allow scheduling the delay between the condition test and the branch, but pipeline control must still track the last instruction that sets the condition code. Essentially, the condition code must be treated as an operand that requires hazard detection for RAW hazards with branches, similar to how MIPS handles register hazards.
Multicycle Operations
Pipelining multicycle operations, such as the following VAX instructions, presents significant challenges:
MOVL R1, R2 ; moves between registers
ADDL3 42(R1), 56(R1)+, @(R1) ; adds memory locations
SUBL2 R2, R3 ; subtracts registers
MOVC3 @(R1)[R2], 74(R2), R3 ; moves a character string
These instructions differ drastically in the number of clock cycles required, ranging from one to hundreds, and the number of data memory accesses, ranging from zero to hundreds. The resulting data hazards are complex and can occur both between and within instructions. Simply making all instructions execute for the same number of clock cycles is impractical as it introduces numerous hazards and bypass conditions, leading to an extremely long pipeline.
To address this, the VAX 8800 designers pipelined the microinstruction execution. Microinstructions are simpler instructions used in sequences to implement more complex instructions. This approach simplifies pipeline control. Since 1995, Intel IA-32 microprocessors have adopted this strategy, converting IA-32 instructions into microoperations and then pipelining the microoperations.
In comparison, load-store processors, which have simple operations with similar amounts of work, are easier to pipeline. Recognizing the relationship between instruction set design and pipelining efficiency, architects can design architectures for more effective pipelining.
Extending the MIPS Pipeline to Handle Multicycle Operations
To enhance the MIPS pipeline for floating-point (FP) operations, it's essential to consider the impracticality of completing all FP operations within 1 or 2 clock cycles. Achieving such rapid completion would necessitate either a slow clock or a substantial amount of logic in the FP units. Instead, the FP pipeline can accommodate longer latencies for operations. This can be visualized by imagining FP instructions following the same pipeline as integer instructions, with two significant changes:
The EX cycle can be repeated as many times as needed to complete the operation, with the number of repetitions varying for different operations.
There may be multiple FP functional units.
A stall will occur if issuing an instruction causes either a structural hazard for the functional unit it uses or a data hazard.
Functional Units in the MIPS Implementation
For the purpose of this discussion, let's assume four separate functional units in the MIPS implementation:
Main Integer Unit: Handles loads, stores, integer ALU operations, and branches.
FP and Integer Multiplier.
FP Adder: Handles FP add, subtract, and conversion.
FP and Integer Divider.
If the execution stages of these functional units are not pipelined, the resulting pipeline structure will be as shown in the following figure. Because EX is not pipelined, no other instruction using that functional unit may issue until the previous instruction leaves EX. Consequently, if an instruction cannot proceed to the EX stage, the entire pipeline behind that instruction will be stalled.
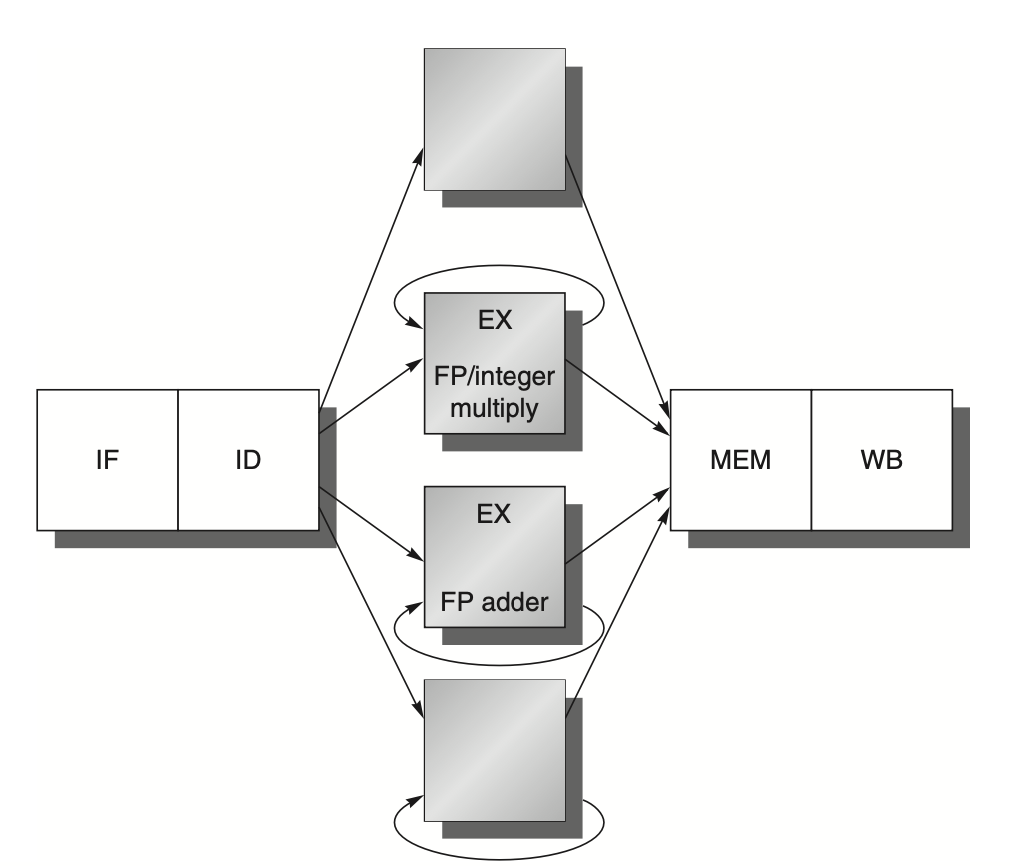
Figure: The MIPS pipeline includes three additional floating-point functional units that are not pipelined. In this configuration, only one instruction can issue per clock cycle, and all instructions must pass through the standard pipeline stages for integer operations. When a floating-point (FP) operation reaches the EX stage, it loops through the necessary functional units until the operation is complete. Once the FP operation finishes the EX stage, it proceeds to the MEM and WB stages to complete its execution.
Generalizing the FP Pipeline Structure
To allow pipelining of some stages and multiple ongoing operations, we must define both the latency of the functional units and the initiation or repeat interval.
Latency: The number of intervening cycles between an instruction that produces a result and an instruction that uses the result.
Initiation or Repeat Interval: The number of cycles that must elapse between issuing two operations of a given type.
The following figure defines the latencies and initiation intervals for various operations.
Integer ALU Operations: Latency of 0, as the results can be used in the next clock cycle.
Loads: Latency of 1, as their results can be used after one intervening cycle.

Figure: Latencies and initiation intervals for functional units.
Operations consume their operands at the beginning of EX, so latency is typically the number of stages after EX that an instruction produces a result. For example, ALU operations have zero stages, and loads have one stage. Stores, however, consume the value being stored one cycle later, making their latency for the value being stored one cycle less.
The pipeline latency is effectively one cycle less than the depth of the execution pipeline, which is the number of stages from the EX stage to the stage that produces the result. For instance, the FP add has four stages, while the FP multiply has seven stages. To achieve a higher clock rate, designers need to place fewer logic levels in each pipe stage, resulting in more stages for complex operations, and hence longer latencies.
Pipeline Structure and Implementation
The example pipeline structure in the above figure allows:
Up to four outstanding FP adds.
Seven outstanding FP/integer multiplies.
One FP divide.
The following figure extends this pipeline structure, adding pipeline stages and registers to implement the repeat interval. Each stage that takes multiple clock cycles, such as the divide unit, is further subdivided to show the latency. Only one operation may be active in these stages at a time.
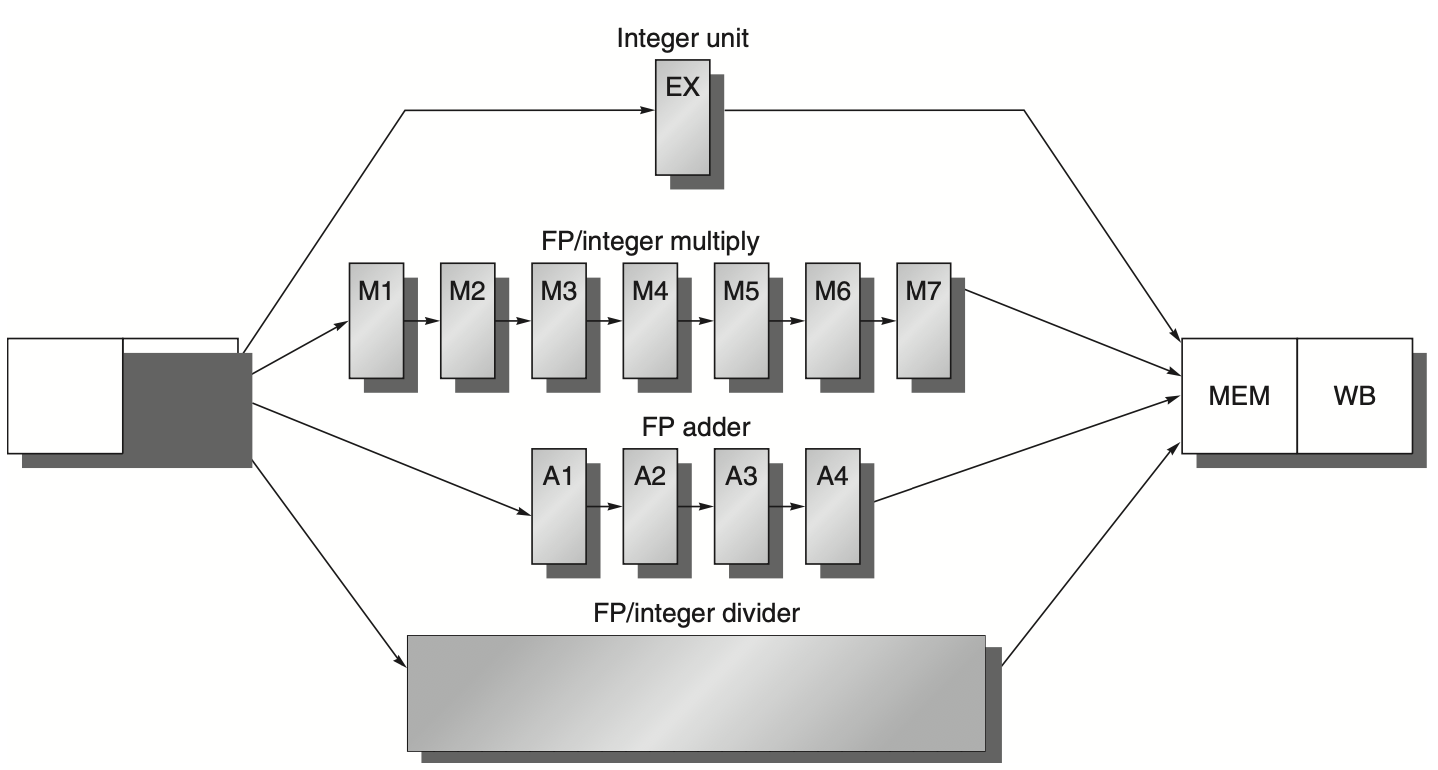
Figure: The pipeline supporting multiple outstanding floating-point (FP) operations features a fully pipelined FP multiplier and adder with depths of seven and four stages, respectively. The FP divider is not pipelined and requires 24 clock cycles to complete. The latency between issuing an FP operation and using its result without incurring a Read-After-Write (RAW) stall depends on the number of cycles spent in the execution stages. For instance, the result of an FP add can be used by the fourth subsequent instruction. In contrast, for integer ALU operations, the execution pipeline depth is always one, allowing the next instruction to use the results immediately.
To accommodate this structure, additional pipeline registers are introduced (e.g., A1/A2, A2/A3, A3/A4). The ID/EX register must be expanded to connect ID to EX, DIV, M1, and A1. We can refer to the portion of the register associated with one of the next stages with notations such as ID/EX, ID/DIV, ID/M1, or ID/A1. The pipeline register between ID and the other stages may be considered logically separate registers and might be implemented as such.
Since only one operation can be in a pipeline stage at a time, control information is associated with the register at the head of the stage.
Hazards and Forwarding in Longer Latency Pipelines
Implementing hazard detection and forwarding in pipelines with longer latency, such as those involving floating-point (FP) operations, introduces several complexities. Here, we explore the different aspects of handling these hazards and the strategies to manage them effectively.
Key Aspects of Hazard Detection and Forwarding
Structural Hazards:
- Structural hazards can occur because the divide unit is not fully pipelined. These hazards must be detected, and instructions must be stalled accordingly.
Register Write Conflicts:
- Instructions with varying execution times can result in multiple register writes in a single cycle. This can exceed the available write ports, leading to conflicts.
Write After Write (WAW) Hazards:
- WAW hazards are possible as instructions may not reach the Write-Back (WB) stage in order. Note that Write After Read (WAR) hazards are not an issue since register reads always occur in the Instruction Decode (ID) stage.
Out-of-Order Completion and Exceptions:
- Instructions can complete out of order, causing issues with exceptions, which is discussed later.
Frequent Stalls for Read After Write (RAW) Hazards:
- Due to longer operation latencies, stalls for RAW hazards become more frequent.
The increase in stalls due to longer operation latencies is fundamentally similar to that in integer pipelines. To understand the new problems in this FP pipeline and potential solutions, let's first examine the impact of RAW hazards. The follwing figure illustrates a typical FP code sequence and the resultant stalls. At the end of this section, we will review the performance of this FP pipeline for our SPEC subset.
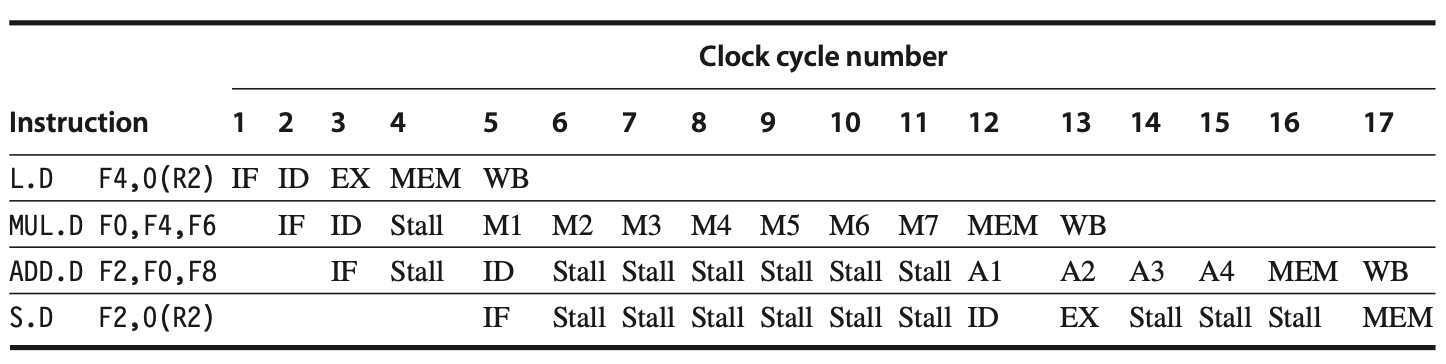
Figure: In a typical floating-point (FP) code sequence, the longer pipeline significantly increases the frequency of stalls compared to the shallower integer pipeline, primarily due to Read-After-Write (RAW) hazards. Each instruction in the sequence depends on the previous one and proceeds as soon as data are available, assuming the pipeline has full bypassing and forwarding capabilities. For example, an S.D instruction must be stalled for an additional cycle to prevent its MEM stage from conflicting with the ADD.D instruction. This situation could be easily managed with extra hardware.
Addressing Write Conflicts
Assuming the FP register file has only one write port, sequences of FP operations and FP loads along with FP operations can cause conflicts for the register write port. For instance, in the pipeline sequence shown in the following figure, all three instructions may reach WB in clock cycle 11, all wanting to write to the register file. With only a single write port, the processor must serialize instruction completion, representing a structural hazard.
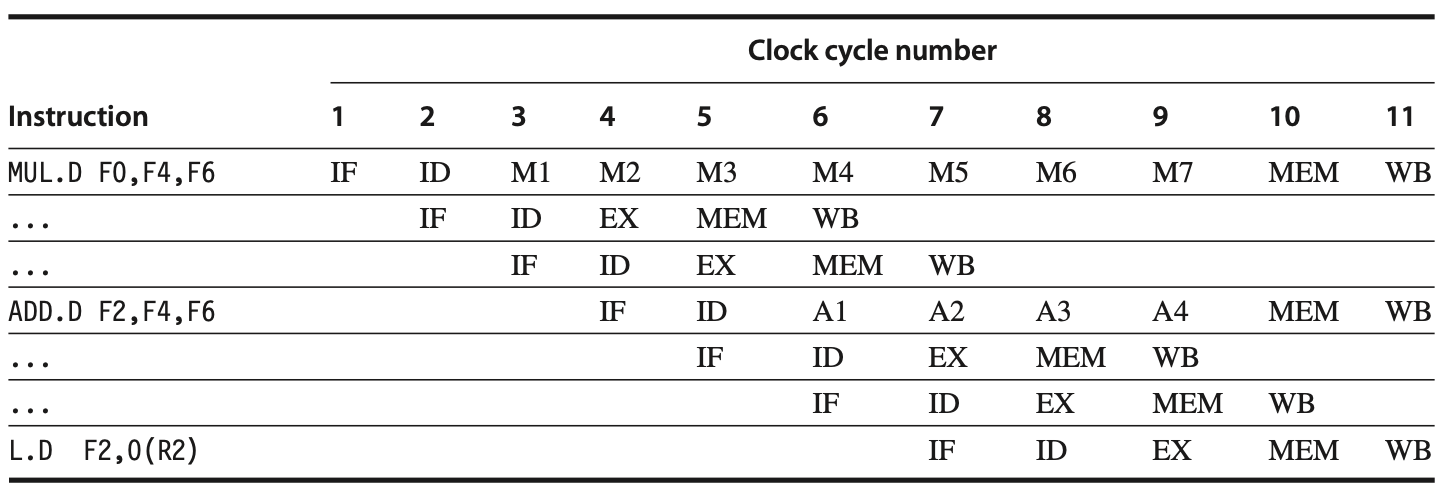
Figure: Three instructions attempt to perform a write-back to the floating-point (FP) register file simultaneously in clock cycle 11. This scenario, while significant, is not the worst-case scenario, as an earlier divide in the FP unit could also complete in the same clock cycle. Although the MUL.D, ADD.D, and L.D instructions are all in the MEM stage during clock cycle 10, only the L.D instruction actually uses the memory, ensuring no structural hazard exists for the MEM stage.
Solutions for Write Conflicts
Increasing Write Ports:
- One solution is to increase the number of write ports, but this can be inefficient as the additional ports would be rarely used, given the maximum steady-state requirement is typically one write port.
Detecting and Enforcing Write Port Access as a Structural Hazard:
Interlock Implementation at ID Stage:
- Track the use of the write port in the ID stage and stall an instruction before it issues if there is a conflict. This can be done using a shift register that indicates when already-issued instructions will use the register file. If the instruction in ID needs to use the register file simultaneously with an already issued instruction, the instruction in ID is stalled for a cycle. This approach maintains the simplicity of handling all interlock detection and stall insertion in the ID stage but adds the cost of the shift register and write conflict logic.
Stalling at MEM or WB Stage:
- Alternatively, stall a conflicting instruction when it tries to enter either the MEM or WB stage. This approach allows choosing which instruction to stall, potentially giving priority to the unit with the longest latency. However, it complicates pipeline control as stalls can now arise from multiple stages, causing possible trickle-back effects in the pipeline.
Handling WAW Hazards
WAW hazards occur when an instruction's result is overwritten by another instruction's result before the former is used. For example, if an L.D instruction is issued one cycle earlier with the destination register F2, it would create a WAW hazard by writing to F2 one cycle before an ADD.D instruction does.
Solutions for WAW Hazards
Delaying Issue of Conflicting Instructions:
- Delay the issue of the load instruction until the ADD.D instruction enters MEM. This ensures that the correct value is written to the register.
Preventing Write of Previous Instruction:
- Detect the hazard and change the control to prevent the ADD.D from writing its result. This allows the L.D to issue immediately. This rare hazard can be managed by either stalling the L.D or making the ADD.D a no-op, both of which can be easily detected during the ID stage.
Combined Hazard and Issue Logic
Implementing the hazard and issue logic in the FP pipeline involves:
Structural Hazard Check:
- Ensure the required functional unit is not busy and the register write port will be available when needed.
RAW Data Hazard Check:
- Ensure the source registers are not listed as pending destinations in any pipeline registers that will not be available when needed. This involves multiple checks depending on the source and destination instructions.
WAW Data Hazard Check:
- Check if any instruction in the pipeline stages A1 to A4, D, M1 to M7 has the same register destination as the instruction in ID. If so, stall the issue of the instruction in ID.
Although detecting hazards in multicycle FP operations is more complex, the underlying concepts remain the same as in the MIPS integer pipeline. Forwarding logic also follows similar principles, implemented by checking if the destination register in any of the EX/MEM, A4/MEM, M7/MEM, D/MEM, or MEM/WB registers matches a source register of a floating-point instruction. If so, the appropriate input multiplexer is enabled to choose the forwarded data.
Managing Hazards and Out-of-Order Completion in Longer Latency Pipelines
Handling long-running instructions in pipelines introduces complexities, especially with floating-point (FP) operations. Let's explore these challenges and the strategies to manage them effectively.
Out-of-Order Completion and Exceptions
Consider the following sequence of instructions:
DIV.D F0, F2, F4
ADD.D F10, F10, F8
SUB.D F12, F12, F14
Although this sequence looks straightforward with no dependences, the ADD.D and SUB.D instructions are expected to complete before the DIV.D, leading to out-of-order completion. This becomes problematic if the SUB.D causes an FP arithmetic exception after the ADD.D has completed but before the DIV.D has finished. This results in an imprecise exception, which we aim to avoid.
The issue arises because instructions complete out of order, and if an exception occurs, restoring the state to a precise point is challenging. Several approaches can address out-of-order completion:
Ignoring the Problem:
- Accept imprecise exceptions, as done in some older supercomputers and certain modern processors with a fast, imprecise mode and a slower, precise mode. However, this is generally unsuitable for systems requiring precise exceptions, such as those with virtual memory or adhering to the IEEE floating-point standard.
Buffering Results:
- Buffer the results of operations until all earlier issued operations are complete. While effective, this approach can become expensive due to the large number of results to buffer and the need for extensive comparators and multiplexers.
History File and Future File:
History File: Tracks original register values, allowing the system to roll back to the state before the exception.
Future File: Keeps newer register values and updates the main register file once all earlier instructions complete. On an exception, the main register file has the precise state.
Delayed Execution and Software Completion:
- Allow exceptions to be somewhat imprecise but keep enough information (such as PCs of instructions) to recreate a precise sequence post-exception. This involves software completing any uncompleted instructions and then restarting from the appropriate point.
Hybrid Scheme:
- Continue instruction issue only if it's certain that all prior instructions will complete without exceptions. This may involve stalling the CPU to maintain precise exceptions, requiring early detection of potential exceptions in the EX stage.
Performance Impact of FP Pipeline Hazards
The MIPS FP pipeline, as discussed above, can experience structural stalls, RAW hazards, and occasionally WAW hazards. The following figure details the stall cycles per FP operation, indicating that stall cycles generally correlate with the latency of the FP units, ranging from 46% to 59% of the functional unit's latency.
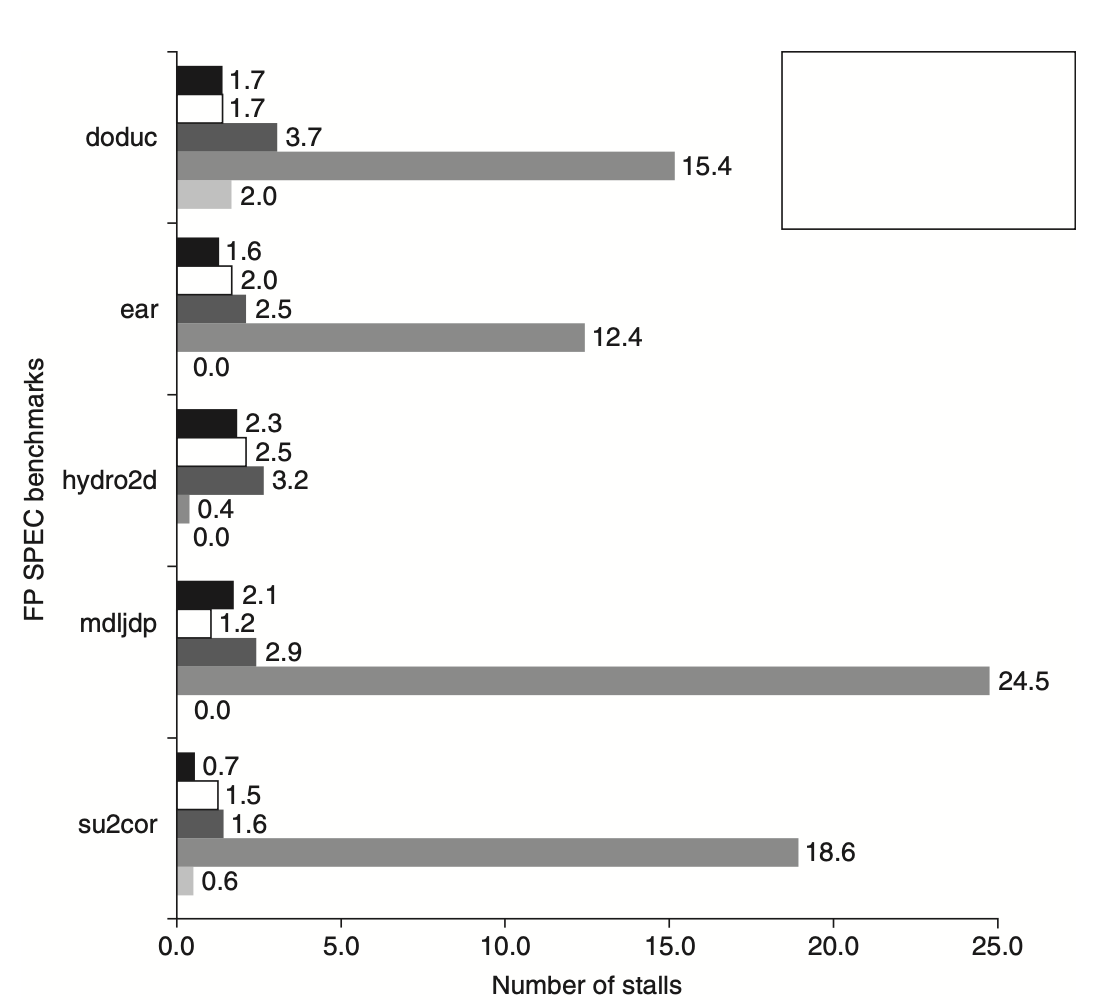
Figure: The average number of stalls per floating-point (FP) operation for each major type of FP operation in the SPEC89 FP benchmarks shows that the number of stalls due to Read-After-Write (RAW) hazards closely aligns with the latency of the FP unit. For instance, FP add, subtract, or convert operations average 1.7 cycles of stalls, which is 56% of their 3-cycle latency. Multiplication and division operations experience average stalls of 2.8 and 14.2 cycles, respectively, which corresponds to 46% and 59% of their respective latencies. Structural hazards for divides are infrequent due to the low frequency of divide operations.
Breakdown of Stalls in SPECfp Benchmarks
The following figure provides a comprehensive breakdown of integer and FP stalls for five SPECfp benchmarks, categorized into:
FP Result Stalls
FP Compare Stalls
Load and Branch Delays
FP Structural Delays
The compiler attempts to schedule both load and FP delays before scheduling branch delays. The total number of stalls per instruction varies from 0.65 to 1.21.
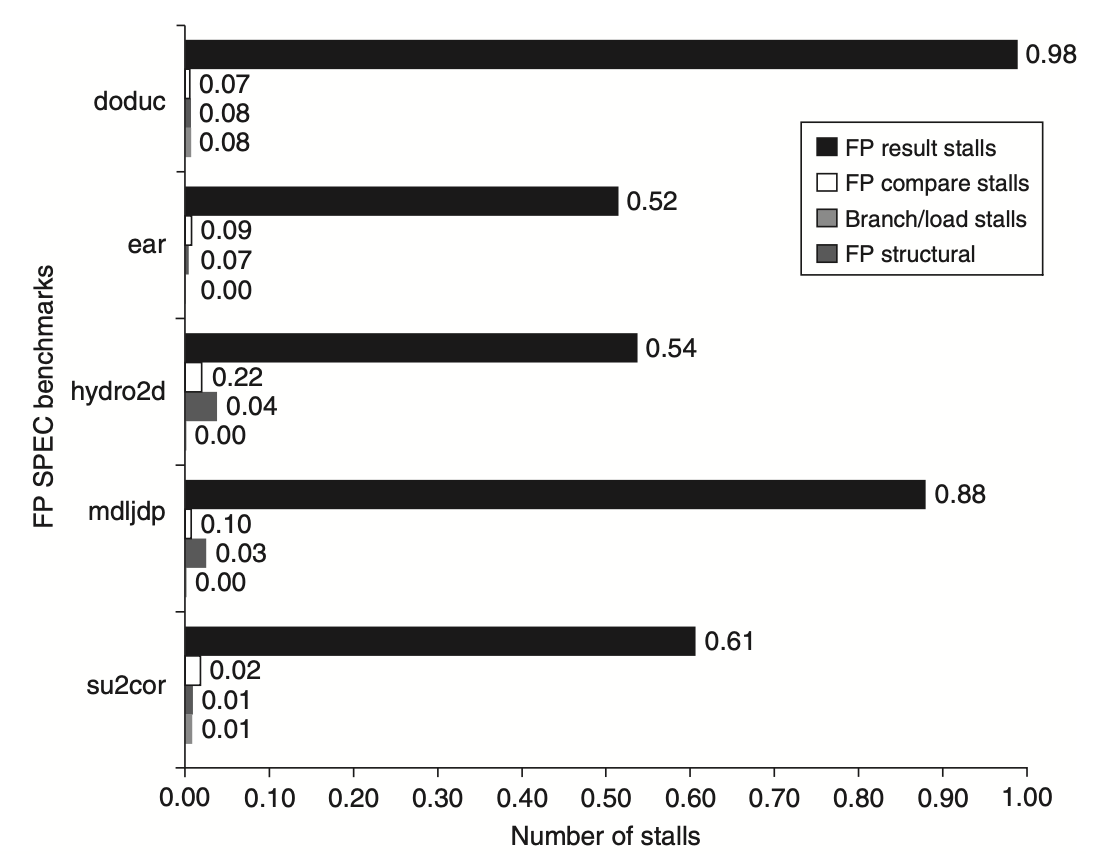
Figure: The stalls occurring in the MIPS floating-point (FP) pipeline for five of the SPEC89 FP benchmarks show that the total number of stalls per instruction ranges from 0.65 for su2cor to 1.21 for doduc, with an average of 0.87. FP result stalls are the most significant, averaging 0.71 stalls per instruction, which accounts for 82% of the stalled cycles. Comparisons generate an average of 0.1 stalls per instruction, making them the second largest source of stalls. The structural hazard for the divide operation is only significant for doduc.
The MIPS R4000 Pipeline
The MIPS R4000 processor family, which includes the 4400 model, implements the MIPS64 architecture with a deeper pipeline compared to the traditional five-stage design. This deeper pipeline, known as superpipelining, allows higher clock rates by breaking down the memory access stage into additional steps. In this section, we examine the pipeline structure and performance of the MIPS R4000, focusing on its eight-stage pipeline for both integer and floating-point (FP) operations.
The Eight-Stage Pipeline
The MIPS R4000 decomposes the traditional five-stage pipeline into eight stages to achieve higher performance. The stages are as follows:
IF (Instruction Fetch 1):
- The first half of the instruction fetch. This stage includes the Program Counter (PC) selection and the initiation of the instruction cache access.
IS (Instruction Fetch 2):
- The second half of the instruction fetch, completing the instruction cache access.
RF (Register Fetch):
- This stage involves instruction decoding, register fetching, hazard checking, and instruction cache hit detection.
EX (Execution):
- The execution stage includes effective address calculation, Arithmetic Logic Unit (ALU) operations, branch-target computation, and condition evaluation.
DF (Data Fetch 1):
- The first half of data cache access.
DS (Data Fetch 2):
- The second half of data cache access, completing the data fetch.
TC (Tag Check):
- This stage checks whether the data cache access was a hit.
WB (Write-Back):
- The write-back stage for loads and register-register operations.
Pipeline Operation and Delays
The deeper pipeline increases the latency for both load and branch operations, as well as the complexity of forwarding mechanisms. The following figure illustrates the pipeline structure and the overlap of successive instructions. Here, we detail the impact of these changes.

Figure: The R4000 utilizes an eight-stage pipeline structure with pipelined instruction and data caches. Each pipeline stage has a specific function: instruction fetch (IF), instruction fetch second half (IS), register fetch and instruction decode (RF), execution (EX), data fetch first half (DF), data fetch second half (DS), tag check (TC), and write-back (WB). The pipeline stages are demarcated by vertical dashed lines, indicating the boundaries and locations of pipeline latches. The instruction becomes available at the end of the IS stage, but the tag check occurs in RF, where registers are also fetched. The instruction memory is shown operating through RF. The TC stage is essential for data memory access, as writing data into the register is contingent upon confirming whether the cache access was a hit.
Load Delays
In the R4000 pipeline, load delays are increased to 2 cycles because the data value becomes available at the end of the DS stage. The following figures show the pipeline schedule when a use immediately follows a load, indicating that forwarding is required to access the result of a load instruction in subsequent cycles.
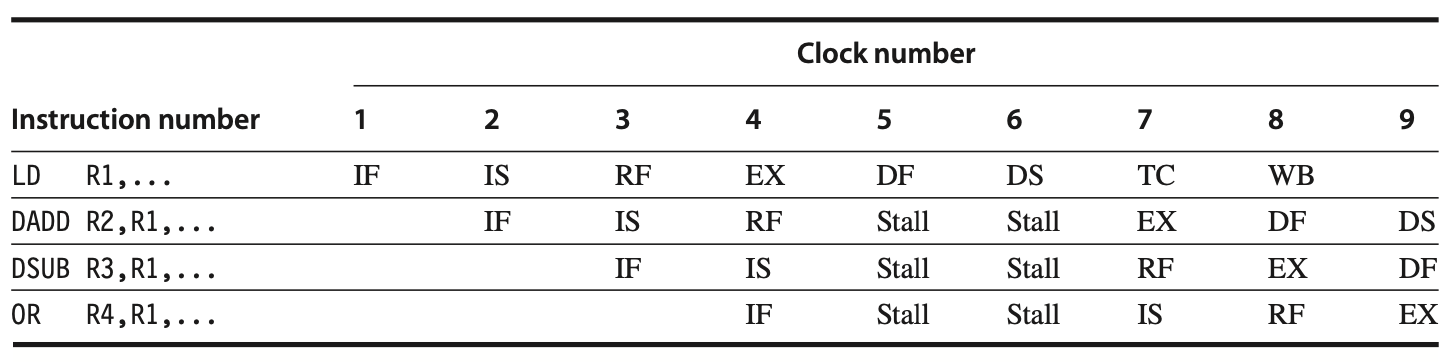
Figure: A load instruction immediately followed by its use results in a 2-cycle stall. Normal forwarding paths can be utilized after these 2 cycles, enabling the DADD and DSUB instructions to get the required value through forwarding after the stall. The OR instruction retrieves its value from the register file. If the two instructions following the load are independent and do not stall, the bypass can be directed to instructions occurring 3 or 4 cycles after the load.
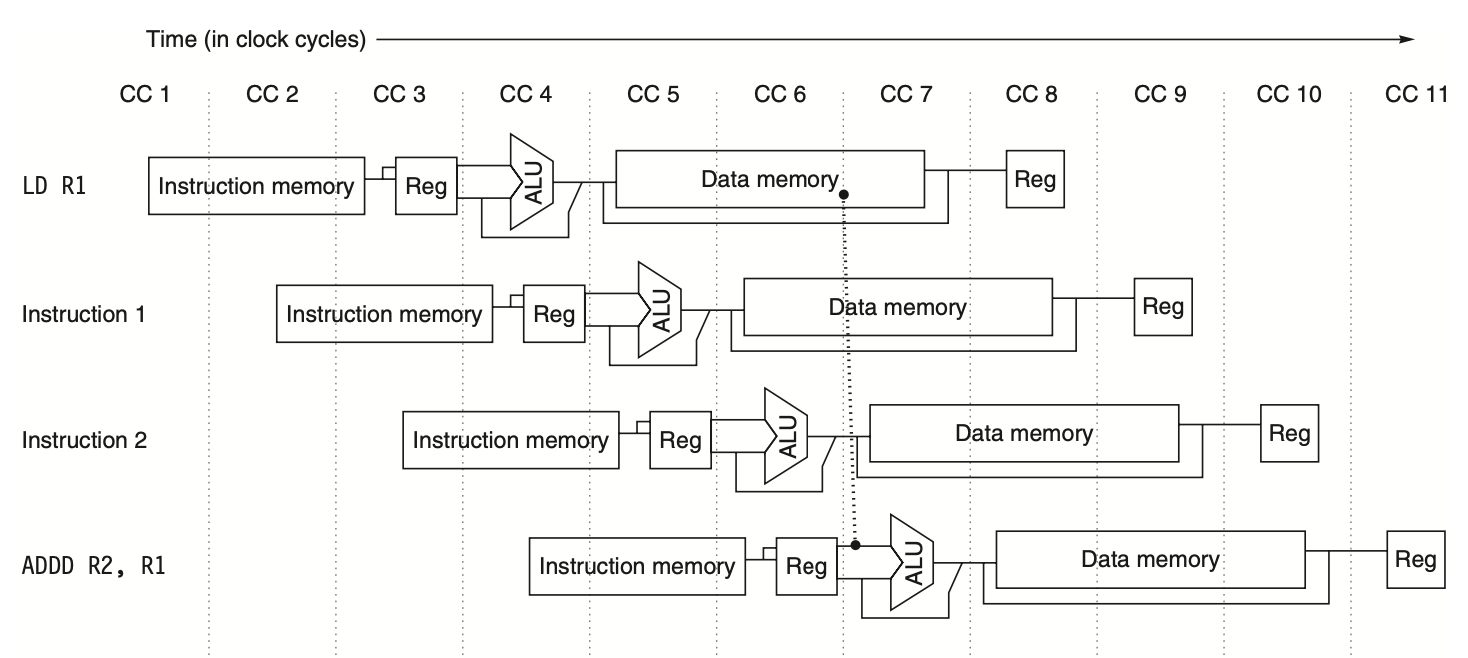
Figure: The R4000 integer pipeline's structure results in a 2-cycle load delay because the data value is available at the end of the DS stage and can be bypassed. If the tag check in the TC stage indicates a cache miss, the pipeline must be backed up by a cycle until the correct data is available.
Branch Delays
The basic branch delay in the R4000 pipeline is 3 cycles since the branch condition is computed during the EX stage. The MIPS architecture includes a single-cycle delayed branch. The R4000 employs a predicted-not-taken strategy for the remaining 2 cycles of the branch delay. The following figures demonstrates that untaken branches behave as 1-cycle delayed branches, while taken branches include a 1-cycle delay slot followed by 2 idle cycles. The instruction set includes a branch-likely instruction to help fill the branch delay slot. Pipeline interlocks enforce the 2-cycle branch stall penalty on taken branches and any data hazard stalls resulting from load uses.
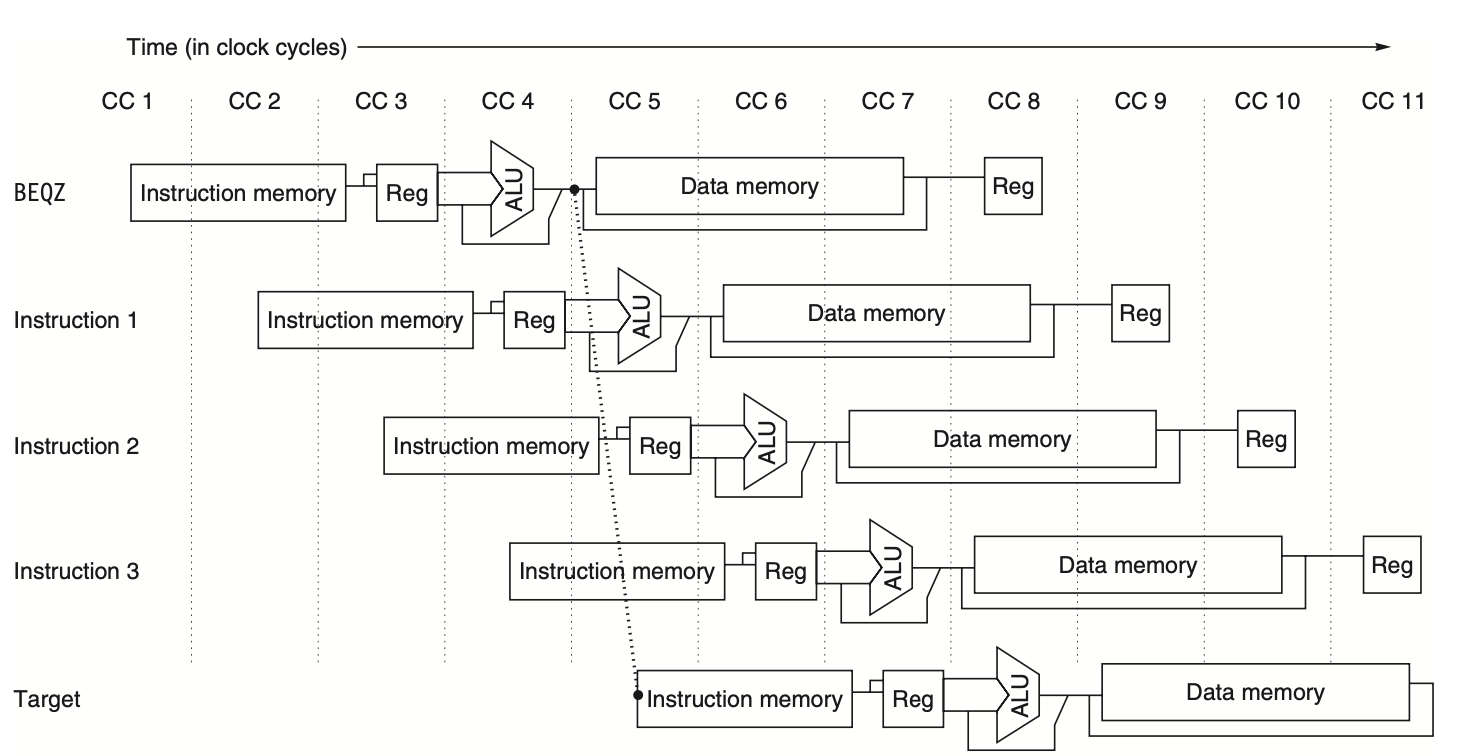
Figure: The basic branch delay in this pipeline is 3 cycles because the condition evaluation is carried out during the EX stage.
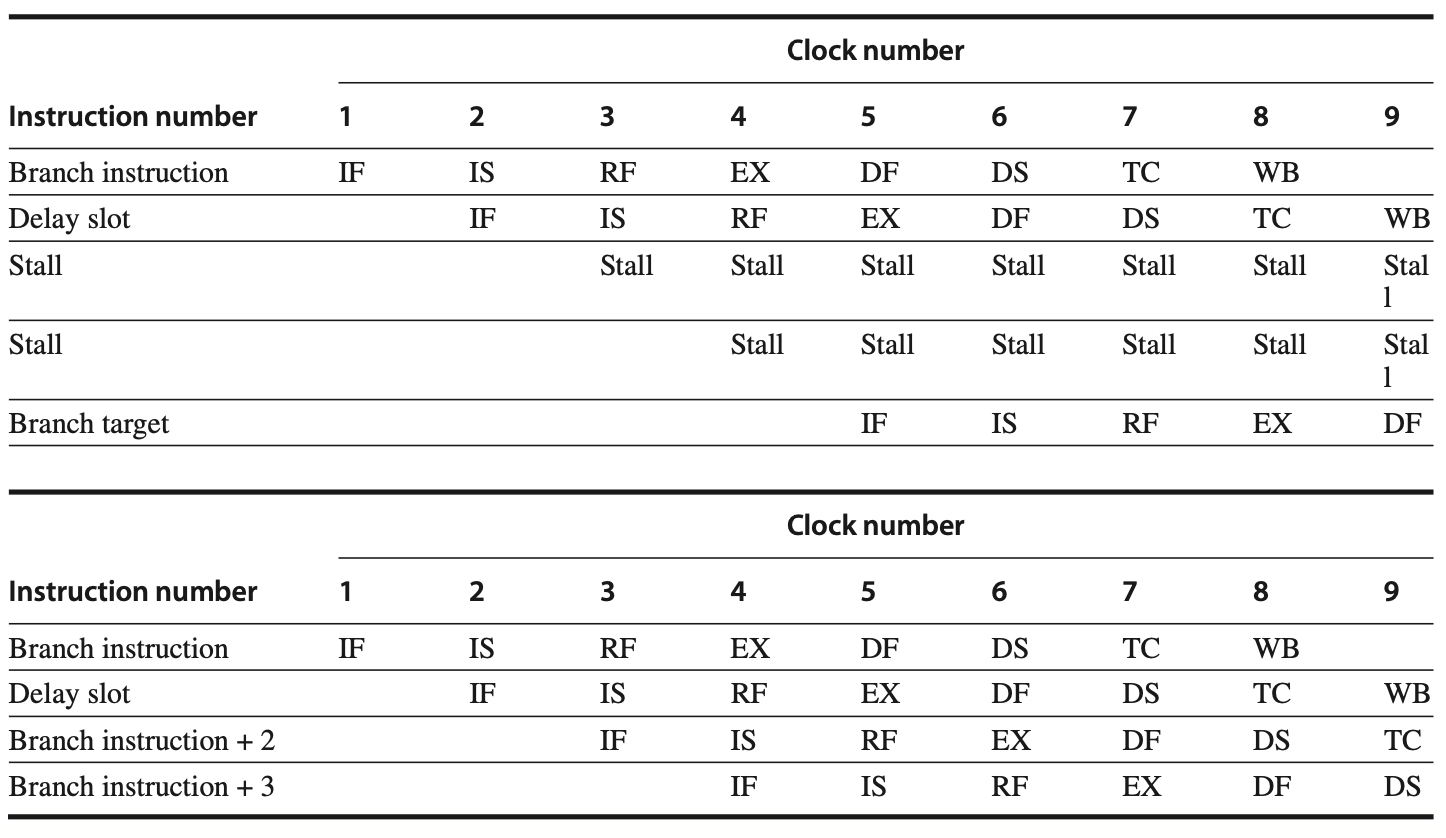
Figure: A taken branch, as illustrated in the top portion of the figure, incurs a 1-cycle delay slot followed by a 2-cycle stall. In contrast, an untaken branch, shown in the bottom portion, has only a 1-cycle delay slot. The branch instruction can either be an ordinary delayed branch or a branch-likely, which negates the instruction in the delay slot if the branch is not taken.
Increased Forwarding Complexity
The deeper pipeline necessitates more levels of forwarding for ALU operations. In the traditional five-stage MIPS pipeline, forwarding between two register-register ALU instructions could occur from the ALU/MEM or MEM/WB registers. In the R4000 pipeline, four potential sources for ALU bypassing exist: EX/DF, DF/DS, DS/TC, and TC/WB. This increased complexity ensures that data dependencies are correctly managed, maintaining the efficiency and accuracy of the pipeline.
The Floating-Point Pipeline in the MIPS R4000
The MIPS R4000 floating-point unit (FPU) is composed of three functional units: a floating-point divider, a floating-point multiplier, and a floating-point adder. The adder logic is also utilized in the final step of a multiply or divide operation. Double-precision floating-point (FP) operations can take from as few as 2 cycles (e.g., for a negate operation) up to 112 cycles (e.g., for a square root). The initiation rates for these units also vary. The FP functional unit comprises eight different stages, as shown in this figure, and these stages are combined in various orders to execute different FP operations.
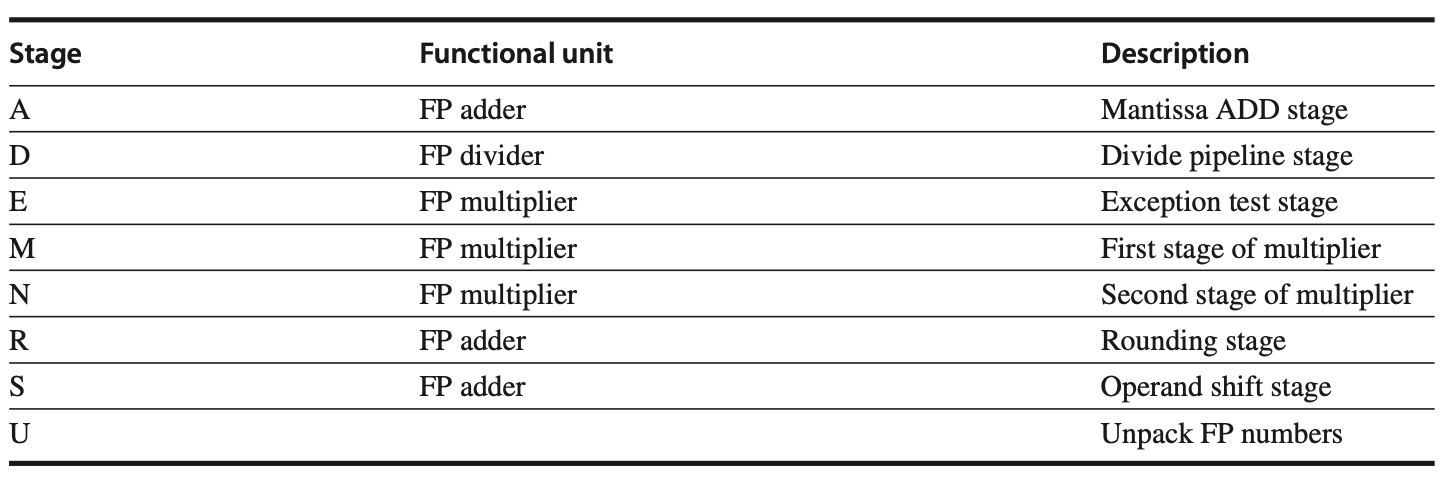
Figure: The R4000 floating-point pipelines utilize eight stages, enabling efficient handling of various FP operations. This design ensures that each stage can be used flexibly and combined in different sequences to execute a wide range of floating-point instructions effectively.
Each stage in the FP pipeline exists as a single copy, and different instructions may use a stage multiple times or in different sequences. The following figure provides details on the latency, initiation rate, and pipeline stages used by common double-precision FP operations. This information helps determine whether a sequence of different, independent FP operations can be issued without stalling. If a conflict for a shared pipeline stage arises, a stall will occur.
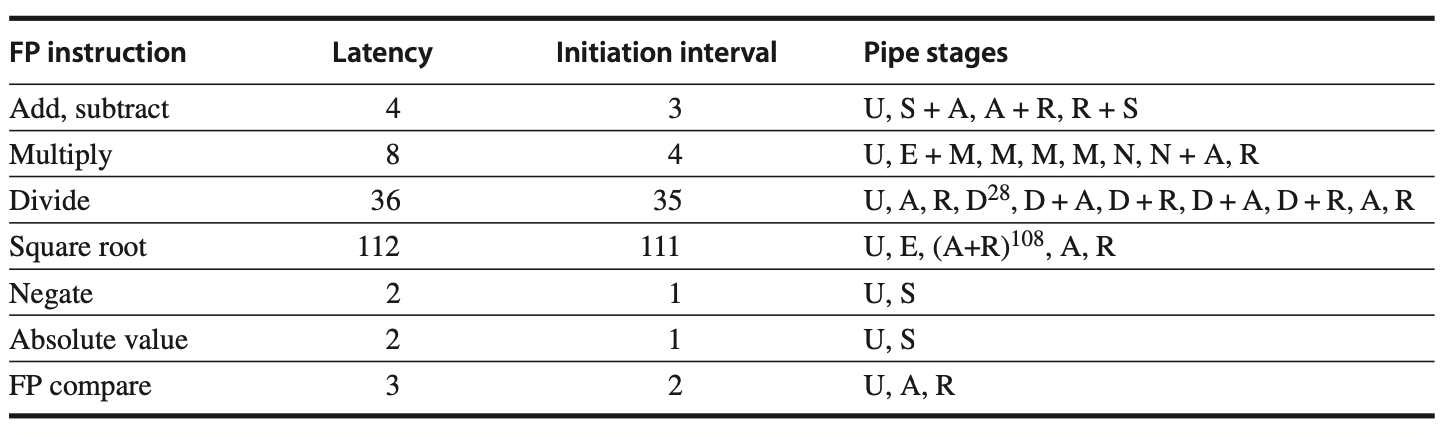
Figure: The latencies and initiation intervals for FP operations in the R4000 pipeline depend on the specific FP unit stages utilized by each operation. Latency values assume the destination instruction is an FP operation, and these values are reduced by one cycle when the destination is a store. The pipe stages are listed in the sequence used for each operation, with notation indicating the combined use of stages in a single cycle (e.g., S + A) or the repeated use of a stage (e.g., \(D^{28}\) for 28 consecutive cycles).
The following four figures illustrate four common two-instruction sequences: a multiply followed by an add, an add followed by a multiply, a divide followed by an add, and an add followed by a divide. These figures show the starting positions for the second instruction and whether it will issue or stall for each position. With three active instructions, the possibilities for stalls increase, making the analysis more complex.
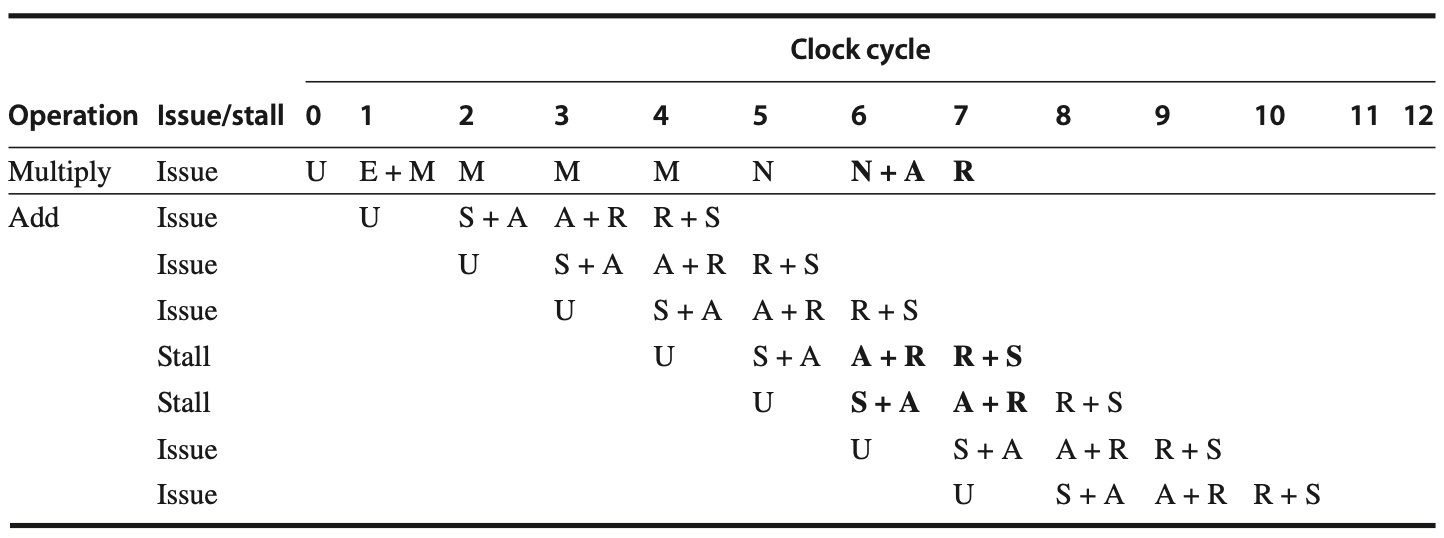
Figure: When an FP multiply is issued at clock cycle 0 and is followed by an FP add issued between clock cycles 1 and 7, the table shows whether the add instruction stalls based on its issue cycle. The add will stall if it is issued 4 or 5 cycles after the multiply, due to a conflict with the multiply's usage of shared pipeline stages. If the add is issued in cycle 4, it will stall for 2 cycles; if issued in cycle 5, it will stall for only 1 cycle. Other issue cycles for the add avoid stalls, ensuring the operations proceed without conflict.
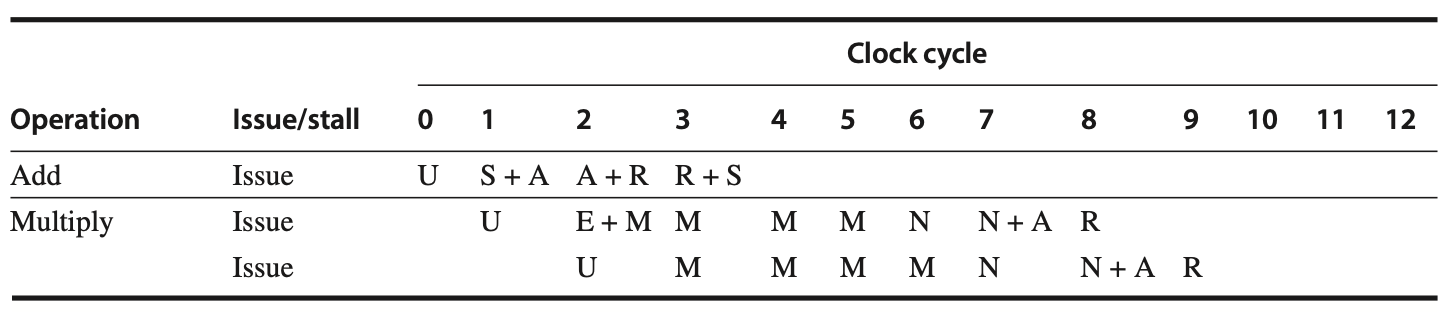
Figure: A multiply instruction that issues after an add can proceed without stalling. This occurs because the add, being a shorter instruction, clears the shared pipeline stages before the longer multiply instruction reaches them, thus avoiding any conflicts.
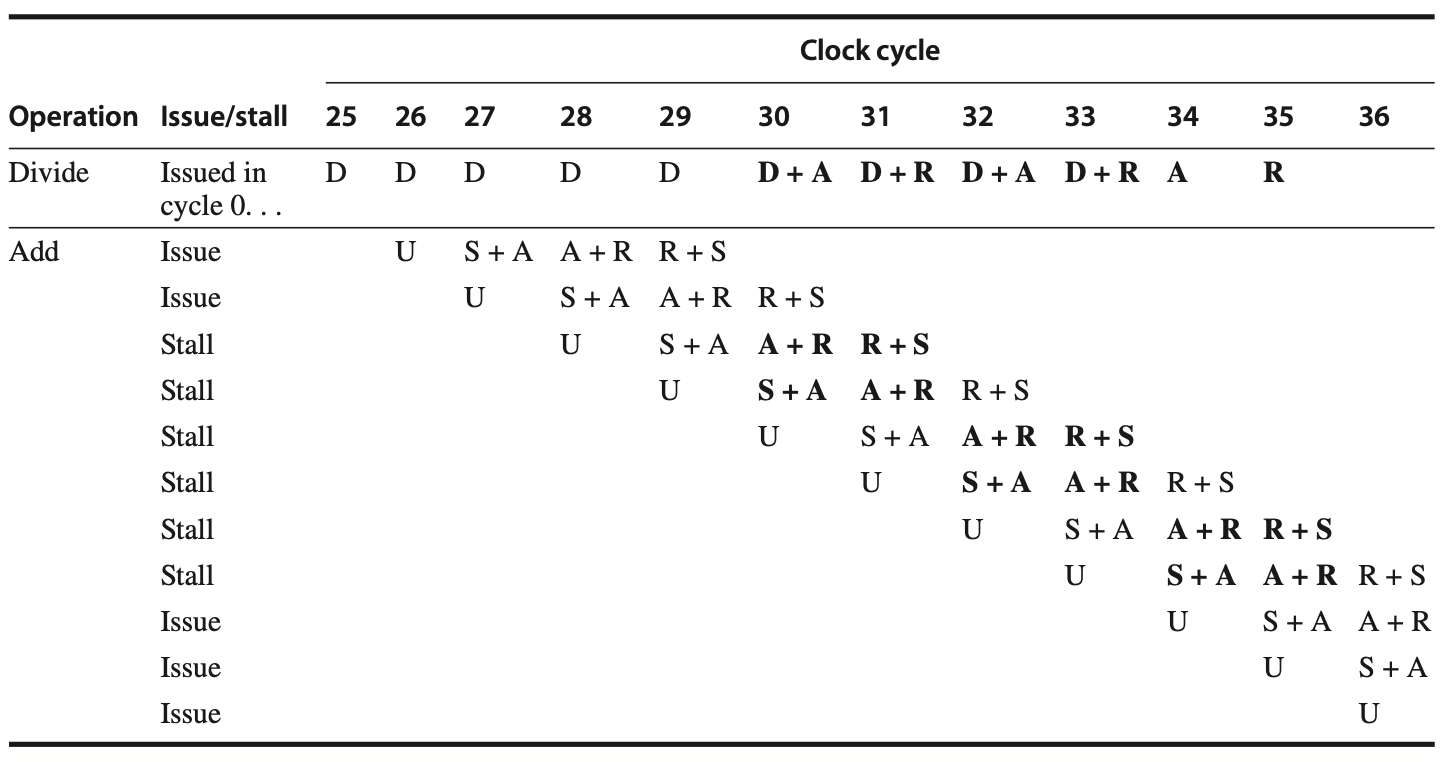
Figure: A floating-point (FP) divide can cause a stall for an add instruction that starts near the end of the divide operation. The divide begins at cycle 0 and completes at cycle 35, with the last 10 cycles of the divide making heavy use of the rounding hardware also needed by the add instruction. Consequently, an add instruction starting in any of cycles 28 to 33 will be stalled until cycle 36. However, if the add instruction starts immediately after the divide, it would not conflict, as the add could complete before the divide requires the shared stages. This behavior mirrors that seen for a multiply and add sequence. The example assumes exactly one add instruction reaching the U stage between clock cycles 26 and 35.
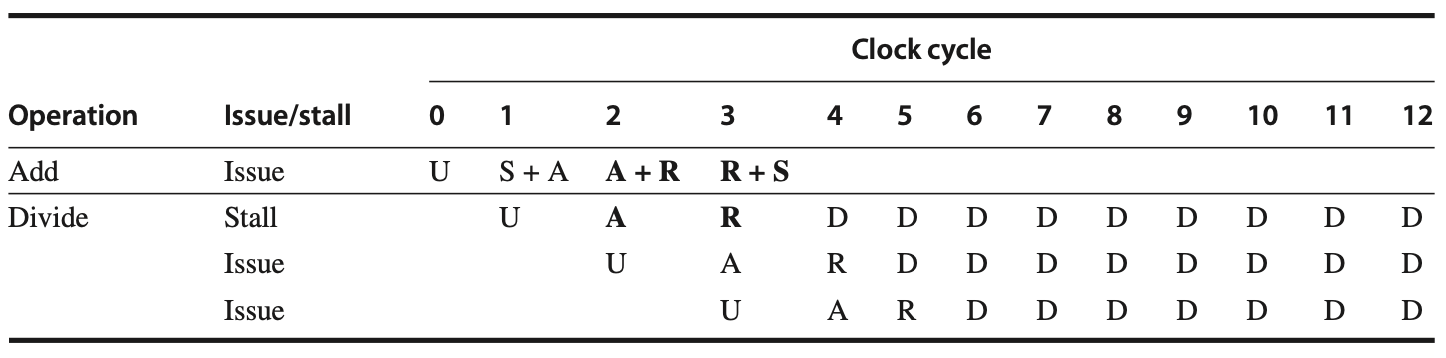
Figure: A double-precision add followed by a double-precision divide causes a stall only if the divide starts 1 cycle after the add. If the divide begins any time later, there is no conflict, and both operations can proceed without stalling.
Performance of the R4000 Pipeline
When evaluating the performance of the R4000 pipeline using the SPEC92 benchmarks, there are four primary causes of pipeline stalls or performance losses:
Load Stalls: Delays resulting from the use of a load result 1 or 2 cycles after the load.
Branch Stalls: Two-cycle stalls for every taken branch, along with unfilled or canceled branch delay slots.
FP Result Stalls: Stalls caused by Read-After-Write (RAW) hazards for an FP operand.
FP Structural Stalls: Delays due to issue restrictions arising from conflicts for functional units in the FP pipeline.
The following figures provide a breakdown of the pipeline Cycles Per Instruction (CPI) for the R4000 across the 10 SPEC92 benchmarks, presented both graphically and in tabular form. These data highlight the penalties associated with the deeper pipelining in the R4000. The pipeline has significantly longer branch delays compared to the classic five-stage pipeline, which substantially increases the cycles spent on branches, especially for integer programs with higher branch frequencies.
For FP programs, the latency of the FP functional units results in more result stalls than structural hazards. These structural hazards arise both from the initiation interval limitations and conflicts for functional units among different FP instructions. Consequently, reducing the latency of FP operations should be a primary focus. However, decreasing latency might increase structural stalls since many potential structural stalls are currently hidden behind data hazards.
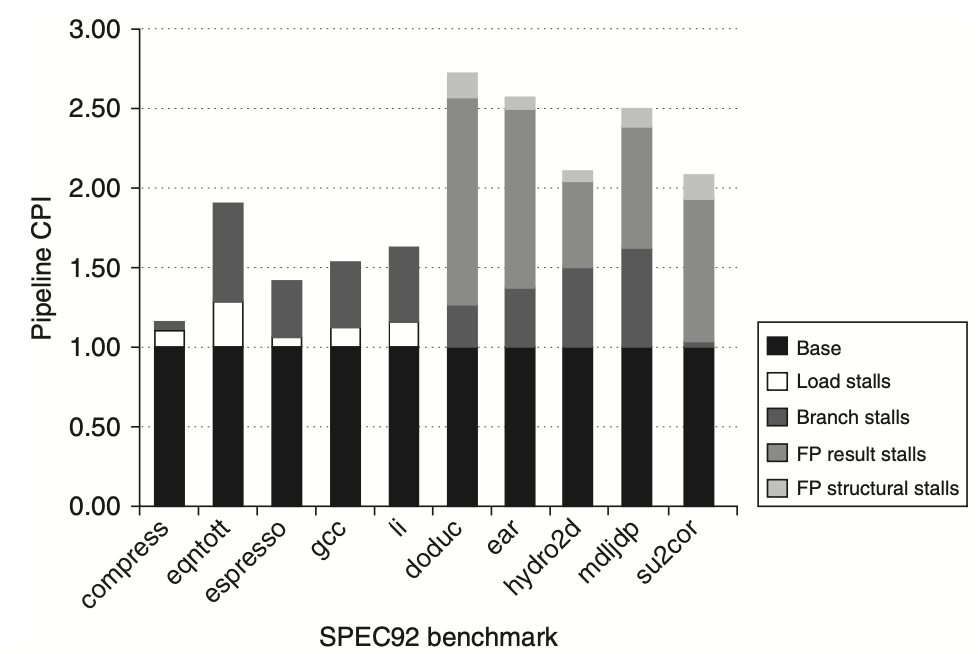
Figure: The pipeline CPI for 10 of the SPEC92 benchmarks, assuming a perfect cache, varies from 1.2 to 2.8. The leftmost five programs are integer programs, where branch delays are the major CPI contributor. The rightmost five programs are floating-point (FP) programs, with FP result stalls being the major contributor to CPI. Figure C.53 shows the numbers used to construct this plot.
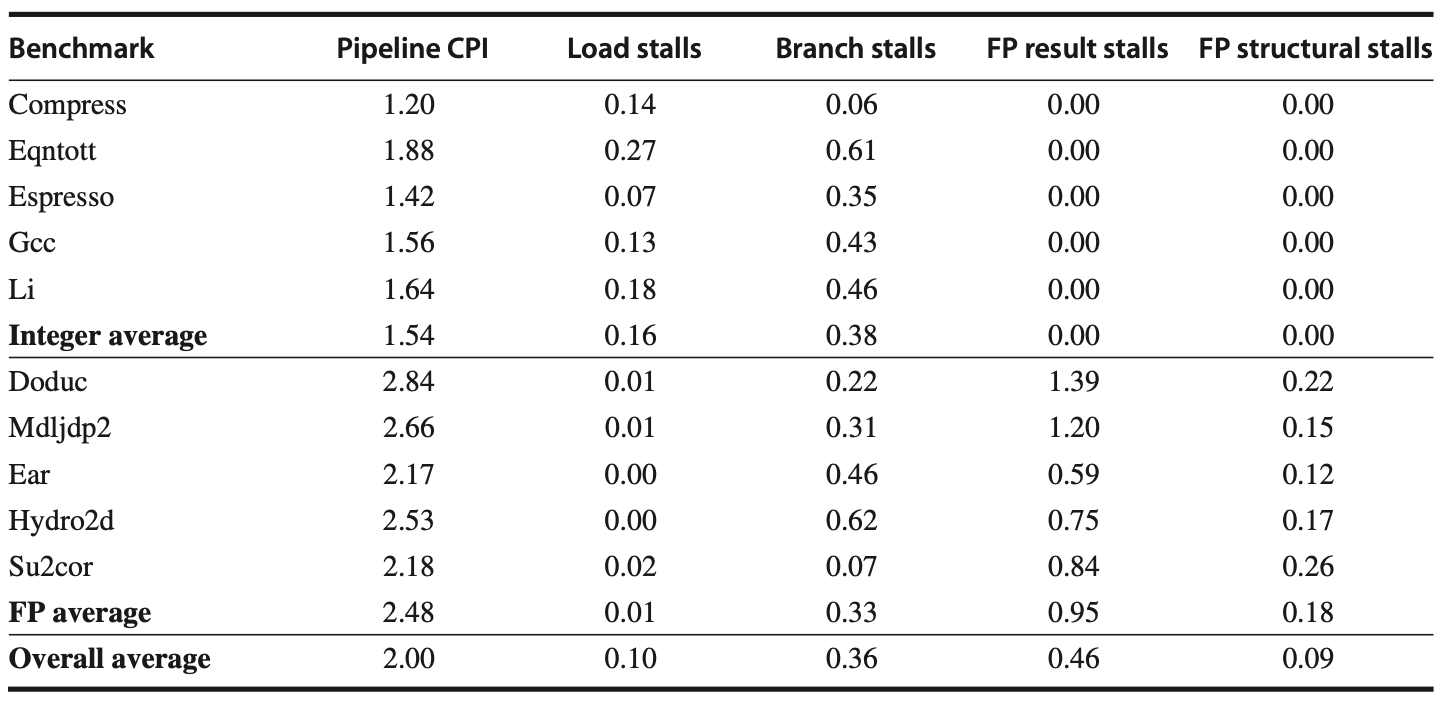
Figure: The total pipeline CPI and the contributions of the four major sources of stalls are shown. The major contributors are FP result stalls (both for branches and for FP inputs) and branch stalls, with loads and FP structural stalls adding less.
Practice
- Given the following MIPS assembly code:
LW R1, 0(R2)
ADD R3, R1, R4
SUB R5, R3, R6
AND R7, R5, R8
Explain how data forwarding can be used to prevent stalls in this MIPS pipeline sequence. Identify the dependencies and describe the forwarding paths needed to resolve them. Specifically, state:
Which data needs to be forwarded?
From which pipeline stage to which pipeline stage the data should be forwarded?
The control logic required to enable this data forwarding.
Additionally, calculate how many cycles would be needed to execute these instructions both with and without data forwarding.
Answer:
Data Dependencies:
ADD R3, R1, R4depends onLW R1, 0(R2)(R1).SUB R5, R3, R6depends onADD R3, R1, R4(R3).AND R7, R5, R8depends onSUB R5, R3, R6(R5).
Forwarding Paths:
LW to ADD: Forward the result of
LWfrom the MEM stage to the EX stage ofADD. One stall is required because theADDinstruction cannot use the result from theLWinstruction until the MEM stage ofLWis complete.ADD to SUB: Forward the result of
ADDfrom the EX stage to the EX stage ofSUB.SUB to AND: Forward the result of
SUBfrom the EX stage to the EX stage ofAND.
Control Logic:
The control logic must detect when the destination register of an instruction matches the source register of a subsequent instruction.
Enable the multiplexers to select the forwarded data instead of the data from the register file.
Ensure the correct data is forwarded at the right time to avoid hazards and maintain correct program execution.
With Data Forwarding (and 1 Stall after LW and EX to EX forwarding thereafter):
Cycle: 1 2 3 4 5 6 7 8 9
---------------------------------------------------------
LW IF ID EX MEM-| WB
ADD IF ID s |-->EX-| MEM WB
SUB IF s ID |--> EX-| MEM WB
AND s IF ID |--> EX MEM WB
Without Data Forwarding: In a MIPS pipeline without data forwarding, the instruction decode (ID) stage of an instruction can complete after the write-back (WB) stage of the previous instruction. This sequential execution is due to the need for the previous instruction to fully complete its data write before the subsequent instruction can access the updated data.
Cycle: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
----------------------------------------------------------------------------
LW IF ID EX MEM WB
ADD IF s s s ID MEM WB
SUB IF s s ID EX MEM WB
AND IF s s s ID EX MEM WB
Cycle Calculation:
With Data Forwarding: 9
Without Data Forwarding: 16
- Given the following MIPS assembly code:
BEQ R1, R2, TARGET
ADD R3, R4, R5
TARGET: SUB R6, R7, R8
Calculate the number of stalls required without using a delay slot.
If static branch prediction is used and the prediction is incorrect, how many flushes (and/or stalls) are required?
Modify the code to use a delay slot and demonstrate that this can be handled without any prediction, stalls, or flushes.
Answer:
alpha: BEQ R1, R2, TARGET
beta: ADD R3, R4, R5
gamma: TARGET: SUB R6, R7, R8
Branch Decision After EX of Alpha (No Prediction, 2 Stalls, branch not taken as decided)
- CPI: 1 base + 2 stalls = 3
Cycle: 1 2 3 4 5 6 7 8
-----------------------------------
alpha: IF ID EX MEM WB
beta: s s IF ID EX MEM WB
Branch Decision After EX of Alpha (No Prediction, 2 Stalls, branch taken as decided)
- CPI: 1 base + 2 stalls = 3
Cycle: 1 2 3 4 5 6 7 8
----------------------------------
alpha: IF ID EX MEM WB
gamma: s s IF ID EX MEM WB
Branch Decision After ID of Alpha (More Hardware in ID, 1 Stall, branch not taken as decided)
- CPI: 1 base + 1 stall = 2
Cycle: 1 2 3 4 5 6 7
---------------------------------
alpha: IF ID EX MEM WB
beta: s IF ID EX MEM WB
Branch Decision After ID of Alpha (More Hardware in ID, 1 Stall, branch taken as decided)
- CPI: 1 base + 1 stall = 2
Cycle: 1 2 3 4 5 6 7
---------------------------------
alpha: IF ID EX MEM WB
gamme: s IF ID EX MEM WB
Branch Decision After ID of Alpha (Static Prediction-Branch Taken, Decision is Correct, No Stall)
- CPI: 1
Cycle: 1 2 3 4 5 6
-----------------------------
alpha: IF ID EX MEM WB
gamma: IF ID EX MEM WB
Branch Decision After ID of Alpha (Static Prediction Branch Not Taken, Decision is Incorrect, One Flush)
- CPI: 1 base + 1 flush = 2
Cycle: 1 2 3 4 5 6 7
-------------------------------
alpha: IF ID EX MEM WB
beta: IF ID FLUSH
gamma: IF ID EX MEM WB
For any branch prediction (static or dynamic), if the prediction accuracy is \(x\%\), then the CPI is calculated as \(1 \text{ base cycle} + (1-x)\% \text{ for flushes}\). For example, if the accuracy is 90%, the CPI would be 1 + (1-0.9) = 1.1.
The pipeline diagram shows the execution of the instructions with the NOP after the branch instruction to handle the control hazard without requiring branch prediction and when branch decision is taken. The decision is confirmed after ID of alpha and gamma is loaded in IF of cycle 3.
Cycle: 1 2 3 4 5 6 7
---------------------------------
alpha: IF ID EX MEM WB
NOP: IF ID EX MEM WB
gamma: IF ID EX MEM WB
Given a 2-bit branch predictor initially in the state 00 (Strongly Not Taken), trace the predictor's state changes and accuracy through the following 10 branch executions:
Taken
Not Taken
Taken
Taken
Not Taken
Taken
Not Taken
Taken
Taken
Not Taken
What is the final state of the branch predictor?
What is the prediction accuracy throughout the trace?
Answer:
Legend
T: Taken
NT: Not Taken
State Transition Table:
| Cycle | State Before | Prediction | Actual Decision | State After | Correct Decision? |
| 1 | 00 | NT | T | 01 | No |
| 2 | 01 | NT | NT | 00 | Yes |
| 3 | 00 | NT | T | 01 | No |
| 4 | 01 | NT | T | 11 | No |
| 5 | 11 | T | NT | 10 | No |
| 6 | 10 | T | T | 11 | Yes |
| 7 | 11 | T | NT | 10 | No |
| 8 | 10 | T | T | 11 | Yes |
| 9 | 11 | T | T | 11 | Yes |
| 10 | 11 | T | NT | 10 | No |
Final State of the Branch Predictor: 10 (Weakly Taken)
Prediction Accuracy: 4 out of 10 correct
\(\text{Accuracy} = \frac{\text{Correct Predictions}}{\text{Total Predictions}} \times 100 = \frac{4}{10} \times 100 = 40\%\)
The CPI is \(\text{CPI} = 1 \text{ base cycle} + (1 - 0.4) = 1 + 0.6 = 1.6 \)
Subscribe to my newsletter
Read articles from Jyotiprakash Mishra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jyotiprakash Mishra
Jyotiprakash Mishra
I am Jyotiprakash, a deeply driven computer systems engineer, software developer, teacher, and philosopher. With a decade of professional experience, I have contributed to various cutting-edge software products in network security, mobile apps, and healthcare software at renowned companies like Oracle, Yahoo, and Epic. My academic journey has taken me to prestigious institutions such as the University of Wisconsin-Madison and BITS Pilani in India, where I consistently ranked among the top of my class. At my core, I am a computer enthusiast with a profound interest in understanding the intricacies of computer programming. My skills are not limited to application programming in Java; I have also delved deeply into computer hardware, learning about various architectures, low-level assembly programming, Linux kernel implementation, and writing device drivers. The contributions of Linus Torvalds, Ken Thompson, and Dennis Ritchie—who revolutionized the computer industry—inspire me. I believe that real contributions to computer science are made by mastering all levels of abstraction and understanding systems inside out. In addition to my professional pursuits, I am passionate about teaching and sharing knowledge. I have spent two years as a teaching assistant at UW Madison, where I taught complex concepts in operating systems, computer graphics, and data structures to both graduate and undergraduate students. Currently, I am an assistant professor at KIIT, Bhubaneswar, where I continue to teach computer science to undergraduate and graduate students. I am also working on writing a few free books on systems programming, as I believe in freely sharing knowledge to empower others.