Snowflake Data Clustering: Expert advice to tune query performance
 John Ryan
John Ryan
Snowflake data clustering is one of the most powerful techniques to maximize query performance, and yet it's by far the most misunderstood Snowflake feature available.
In this article, we'll explain:
Why does Data Clustering matter?
What do we mean by partition elimination
What is a cluster key and which pitfalls to avoid with data clustering
Snowflake Data Clustering: Why it Matters
Data clustering has a massive impact upon Snowflake query performance. Take for example the SQL statement below:
select count(*)
from snowflake_sample_data.tpcds_sf100tcl.web_sales
where ws_web_page_sk = 3752;
The above query fetches a single row from a table with 72 billion entries, with nearly five terabytes of storage. The screenshot below shows the query performance.
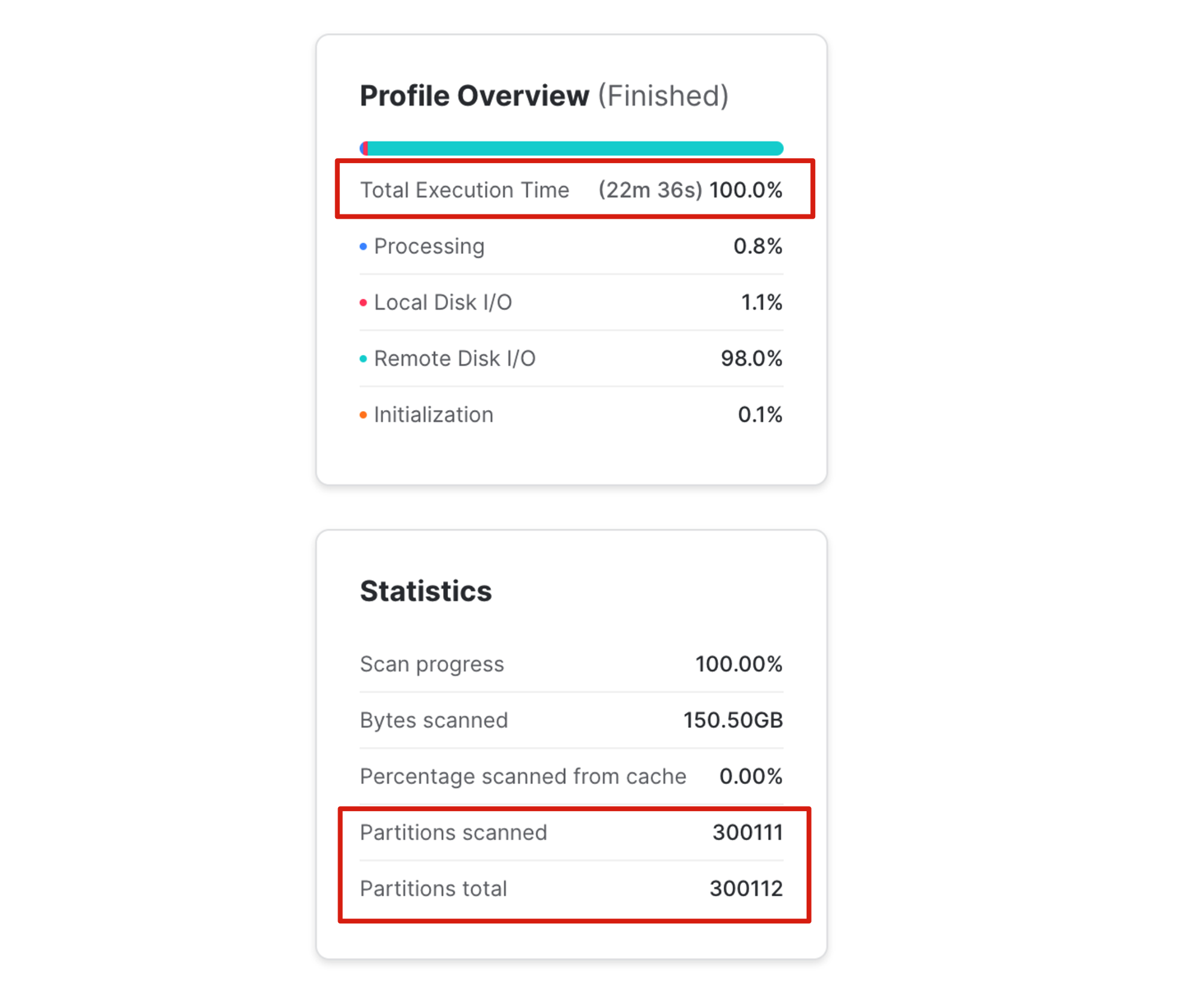
Notice the query took over twenty minutes to complete and scanned over 300,000 micro-partitions - effectively a full table scan. It also spent 98% of the wait time, waiting for Remote Disk I/O which is the slowest form of data storage when compared to super-fast Local Disk I/O which is stored in solid state disk (SSD).
Now compare the above Query Profile to exact same query executed on clustered table:
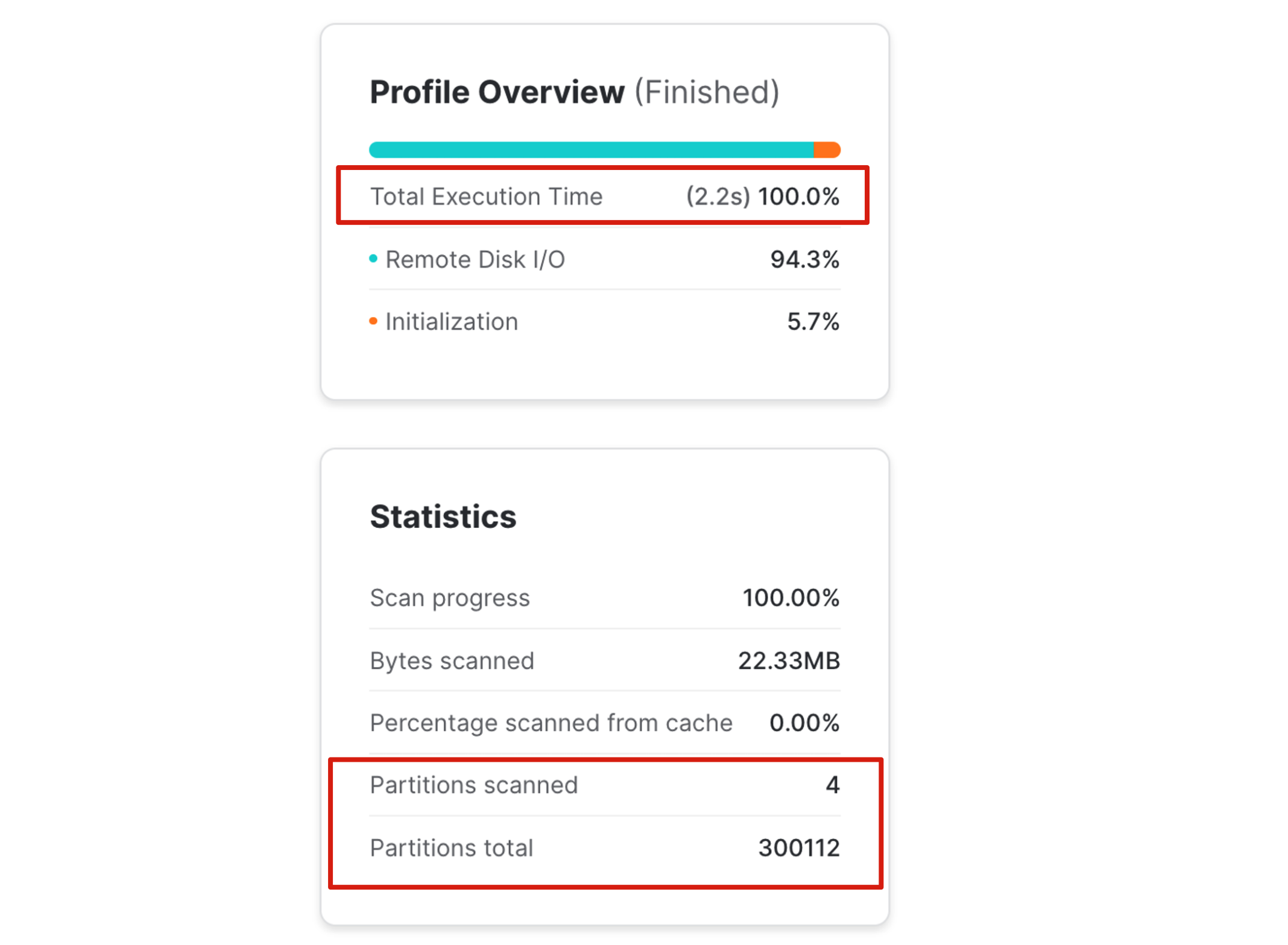
The same query was over 600 times faster at just 2.2 seconds compared to 22m 36s. To check the reason for this astonishing performance we need only to look at the Partitions Scanned. Just 4 of 300,112 - just 0.0013% of the table.
What is Snowflake Partition Elimination?
The diagram below illustrates natural data clustering. In this example, Sale Transaction data is loaded into a Snowflake table.
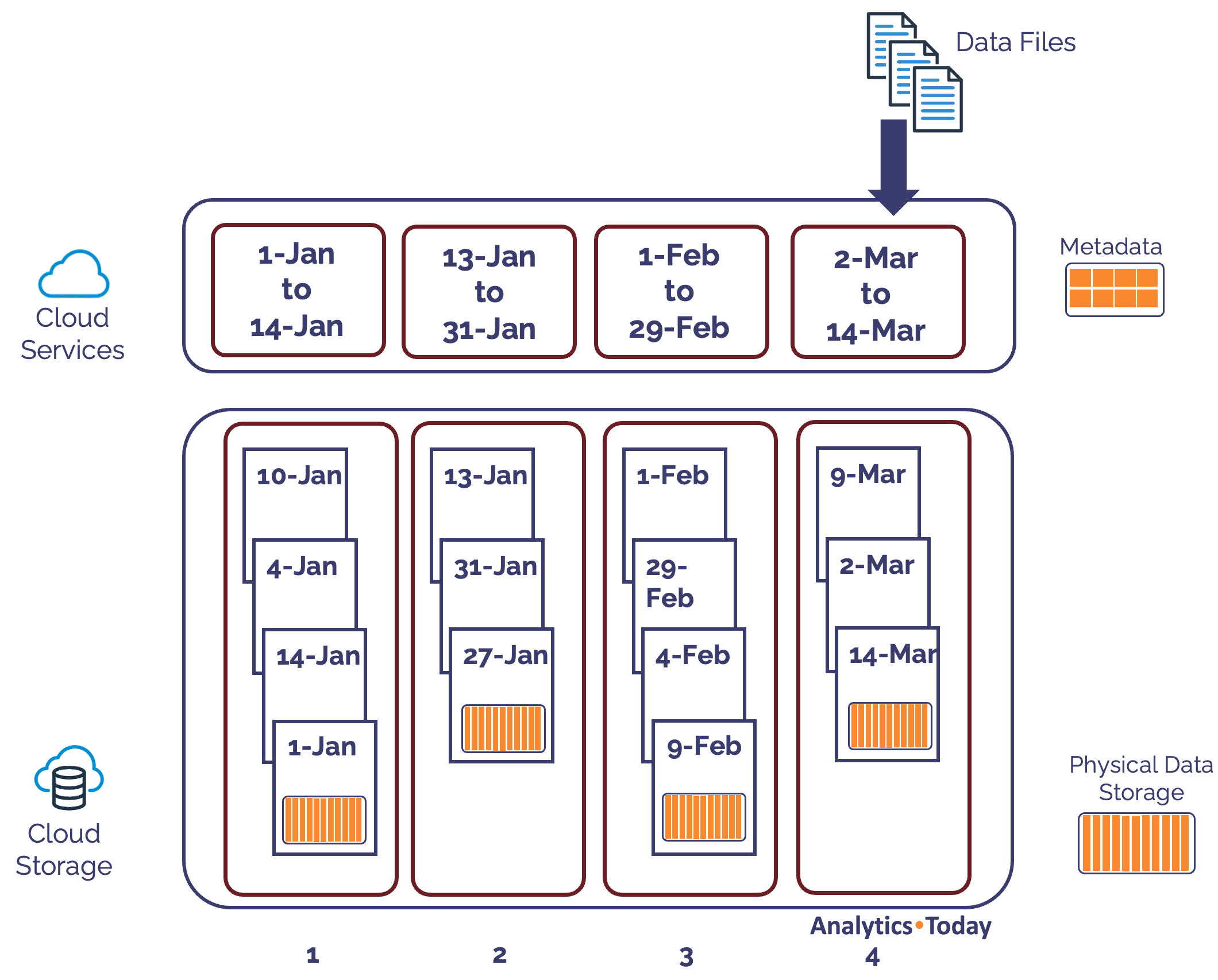
The diagram above illustrates just four of the the total 300,000 micro-partitions, and each entry includes multiple rows. In fact, a single micro-partition can hold thousands of rows as the data is highly compressed on load.
Notice that Snowflake appends additional rows as they arrive which means the data for January is held in the first two micro-partitions, then February and March. This is purely accidental and the result of data arriving each day.
Notice also that Snowflake stores data at two levels:
Cloud Services: Which includes the highest and lowest value for every column in each micro-partition. This is relatively small data volumes and is used by the Snowflake Query Optimizer to automatically tune performance.
Cloud Storage: Which holds the physical data stored in 16MB variable length micro-partitions.
Now, let's assume you execute the following query.
select *
From sales
where sale_date = '09-Feb-24';
The diagram below illustrates how Snowflake is able to execute automatic partition elimination using the tiny metadata in Cloud Services.
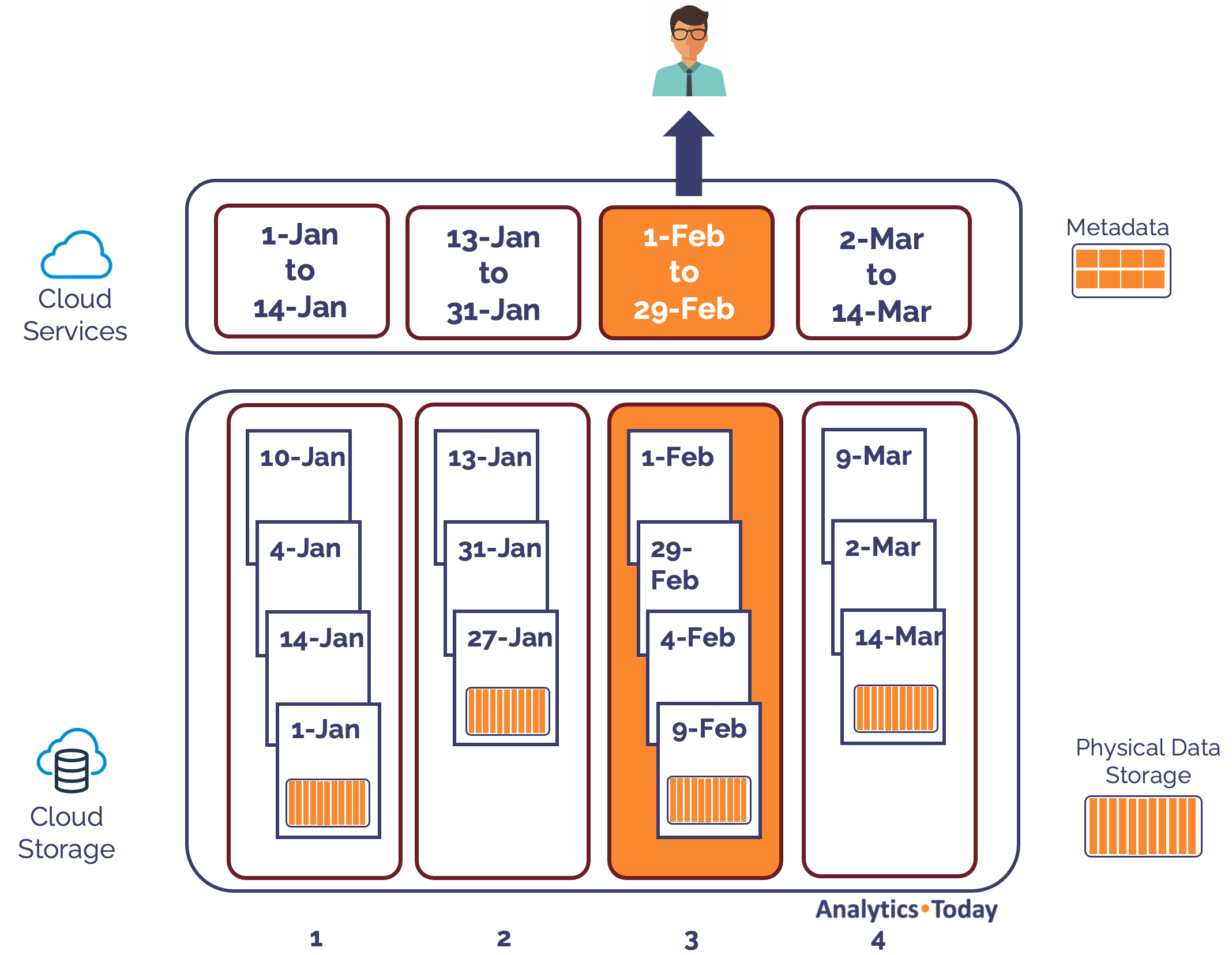
Ironically, unlike a traditional database index which records where the data is held, the Snowflake metadata records where it might be. Snowflake doesn't actually know whether micro-partition 3 includes data for 9th February, but it does know it can exclude all the others.
We call this ability to prune the micro-partitions, partition elimination.
What is Snowflake Data Clustering?
Data Clustering simply refers to the fact that data is often randomly distributed across the Snowflake micro-partitions, but in this case, the data was naturally clustered by date.
Data Clustering therefore refers to the fact that entries for the same date or month are clustered together in a small number of micro-partitions which in turn maximizes the chance of partition elimination and therefore query performance.
What is a Snowflake Cluster Key?
For situations where data is periodically loaded by transaction date, natural clustering works well, however there are situations where this is not effective. These include:
Large Volume Data Migrations: I worked with customers migrating terabyte size tables from Netezza and they unloaded the data to thousands of data files and then bulk loaded them into Snowflake. In this case, files don't arrive in transaction order and this disrupts natural clustering.
Using Snowpipe: Another cluster switched from end of day incremental loads to hourly loads using Snowpipe and were shocked to find their query performance degraded. While Snowpipe is incredibly fast at loading data, it achieves this using parallel loading which again tends to disrupt natural clustering.
Querying against other keys: For example, when data is loaded in DATE sequence, but most queries are by CUSTOMER_ID. While this tends to favour queries filtering by DATE, it means the more frequent queries by CUSTOMER are slower and need to perform a full table scan.
Random Updates: Tends to disrupt clustering and leads to a gradual reduction in query performance.
To ensure data remains clustered and maximize query performance, Snowflake introduced the clustering key which keeps data clustered by one or more columns.
The SQL code below illustrates how to add a cluster key to an existing table:
alter table sales
cluster by (c_custkey);
What does Snowflake Cluster By actually do?
The most important fact about the CLUSTER BY clause is it doesn't actually cluster the data. Not immediately.
Remember, data clustering is not the same as a database index, and the alter table command returns within milliseconds, but clustering a table with billions of rows could take hours.
The CLUSTER BY clause simply indicates that the table should be sorted by the given key - in the above case the C_CUSTKEY column.
Snowflake periodically starts the automatic clustering service which effectively sorts the data. Be aware though, this is not a full sort of every row, it's effectively a partition level sort to group together rows with the same key.
Should you SORT data rather then CLUSTER it?
Yes, and no. Yes, you should perform the initial clustering operation by sorting the data, but after the initial sort operation, you should simply allow the background automatic clustering service to maintain clustering.
The reasons for the initial sort rather than clustering include:
It's faster: Sorting even a huge terabyte size table will take around 20 minutes to complete compared to background clustering which takes around four hours.
It's cheaper: As my benchmark below shows, the initial sort operation is around six times cheaper than background clustering.
However, for ongoing clustering, the automatic clustering service has the advantage that it doesn't require a full lock on the table for the duration of the sort and it only clusters micro-partitions not rows and is therefore way more efficient to complete.
Comparing Clustering with Sorting
As a benchmark test, I executed the following query on an X2LARGE warehouse.
create or replace table store_sales_sort_by_sold_date_item
as select *
from snowflake_sample_data.tpcds_sf10tcl.store_sales
order by ss_sold_date_sk
, ss_item_sk;
Although this still spilled over 3TBs of storage, it completed in 22m 7s and cost just 12 credits.
The same operation using an automatic clustering operation took over four hours to complete and cost 69 credits.
Why do Random Updates disrupt Clustering?
The diagram below illustrates how data is inserted into Snowflake and appended with new micro-partitions which has no impact upon existing clustered data.
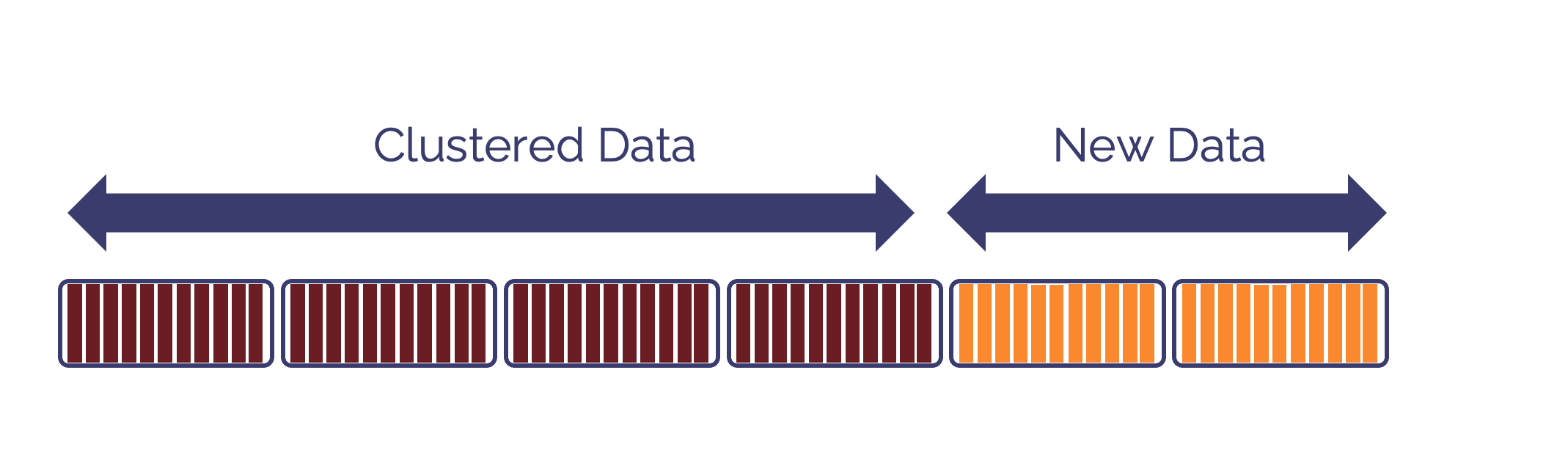
However, as the diagram below shows, when updates are applied this creates new versions of the existing (potentially clustered) micro-partitions, and this tends to disrupt clustering, especially when the same micro-partition is updated several times.
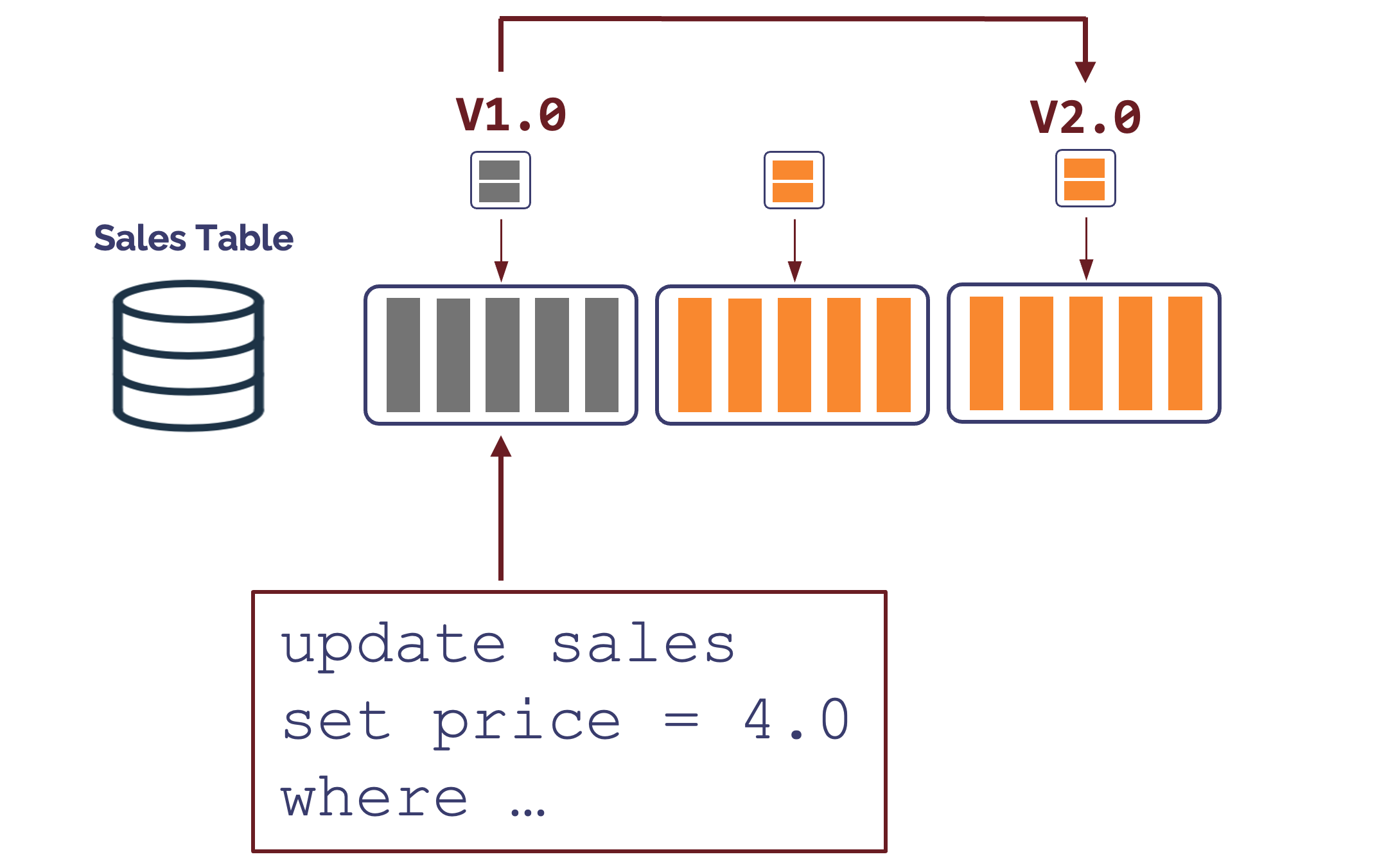
While any updates to a table tend to disrupt data clustering, the diagram below illustrates a worst case I've seen during many customer visits.
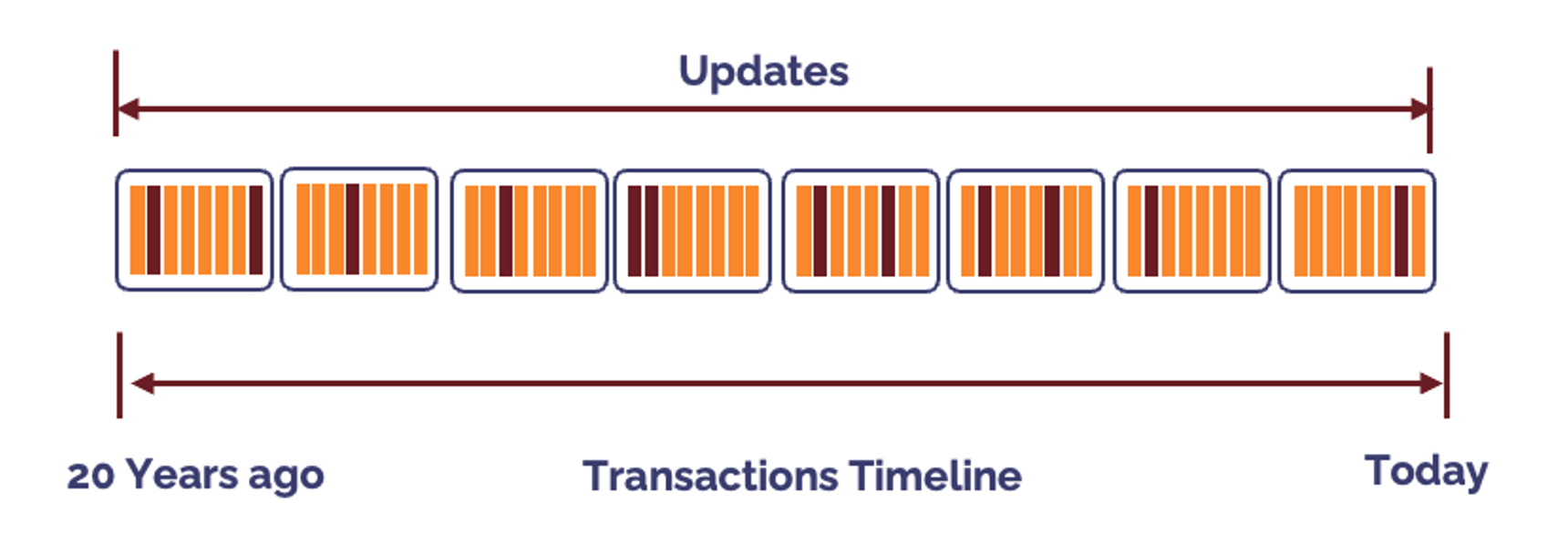
In the above case, the customer performed random updates across every micro-partition on table with over 20 years of history. They where confused, because the update only hit about 5% of the rows, but updated around 98% of the micro-partitions.
In addition to being an expensive update operation, it also disrupted clustering which lead to high clustering costs.
Automatic Clustering: Drawbacks
The diagram below illustrates how the automatic clustering service, running in background, can struggle to keep up with updates.
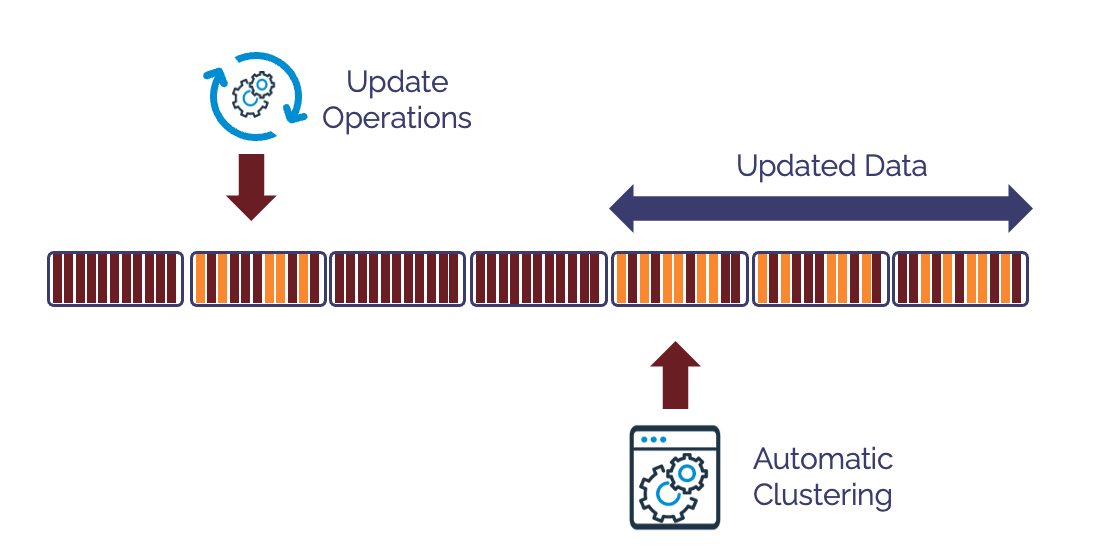
This can lead to unexpectedly high clustering cost because Automatic Clustering uses a optimistic locking mechanism, and this leads to abandoning clustering attempts if the data has been updated before the clustering operation can complete.
For this reason, it's therefore best to avoid cluster keys on tables with frequent update or delete operations.
How to Reduce Clustering Costs for Frequent Updates
The best practices to reduce clustering costs in situations with frequent updates involves pausing the background re-clustering. The SQL statements below show how to pause and then resume automatic clustering.
alter table sales suspend recluster;
alter table sales resume recluster;
Experience with many customers shows that query performance tends to gradually degrade with updates, and pausing the clustering operation during frequent updates has little impact upon query execution times.
The best practice is therefore to suspend clustering during the week and then resume clustering late on Friday which allows the automatic clustering service to catch up over the weekend.
Conclusion
It's clear that data clustering can have a huge impact upon Snowflake query performance by maximizing partition elimination. In this article we described the potential performance benefits described the best way to deploy clustering (with an initial sort operation), and described some of the challenges with cluster keys which can lead to high re-clustering costs.
In conclusion, Snowflake cluster keys can lead to huge query performance benefits, and using the guidelines in this article will help control costs.
Deliver more performance and cost savings with Altimate AI's cutting-edge AI teammates. These intelligent teammates come pre-loaded with the insights discussed in this article, enabling you to implement our recommendations across millions of queries and tables effortlessly. Ready to see it in action? Request a recorded demo by just sending a chat message (here) and discover how AI teammates can transform your data teams.
Subscribe to my newsletter
Read articles from John Ryan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
John Ryan
John Ryan
After 30 years of experience building multi-terabyte data warehouse systems, I spent five incredible years at Snowflake as a Senior Solution Architect, helping customers across Europe and the Middle East deliver lightning-fast insights from their data. In 2023, I joined Altimate.AI, which uses generative artificial intelligence to provide Snowflake performance and cost optimization insights and maximize customer return on investment.