Running Hugging Face Models on Lilypad Network: A Complete Guide
 Narbeh Shahnazarian
Narbeh Shahnazarian
Introduction
In this guide we are going to be exploring the intersection of AI and blockchain technology with Lilypad Network and Hugging Face. If you recall from my previous blog post, Lilypad Network is a serverless, distributed compute network enabling users to preform internet scale data processing. The network allows users to offload compute jobs to network participants who "rent out" their resources (i.e. CPU and GPU) to execute their computations for a fee. The most prominent types of jobs that would fit the bill are AI/ML oriented tasks such as training a model or running inference against one since these typically require a large monetary investment in infrastructure to actually operate. With Lilypad you don't need to make a big monetary investment and can instead rent out resources from a network of hosts for a small fee!
Hugging Face is one of the leading open platforms for Ai/ML development and hosts many different products that help developers fast track building their next great AI project. Of the many products Hugging Face offers, the best
(imo) is the open collection of datasets and models which we are going to utilize here.
So you may be wondering what we're actually going to be building, right? We are going to be building a python app to run inference against a Hugging Face model to tell us whether a given statement is bullish or bearish.
i.e "Lilypad is awesome" -> bullish or "I don't like where the world is heading" -> Bearish
Once we've built the app we'll containerize it with Docker. Finally we'll ask the Lilypad Network to execute a run of our app to infer it's bullish (or bearish) sentiment against some input to pave the way for anyone to use our bullish-bearish classifier in a decentralized way.
Prerequisites
To be able to follow along with this guide, you'll need a couple of things:
A Docker account with Docker Hub Desktop installed
The Lilypad CLI installed on your machine. See this guide on how to install
A Metamask wallet with Arbitrum Sepolia Eth and some LP test token. See this guide to set this up
A Python development environment (for this guide I tested against version Python 3.9.6)
If you're ever stuck you can check out the demo repo I've built that's has the final version of what we're going to be building.
Step 1 - Building our App
Ok so let's getting cooking here with our simple app to classify a given statement as bullish or bearish. What we're going to do first is spin up a new python project and then build it out step by step
Open a new terminal and go to your usual working directory. Create a new directory called
bullish-bearish-classifiermdkir bullish-bearish-classifier-demoTraverse into it and initialize it as a new git directory
cd bullish-bearish-classifier-demo && git initNow open up your favourite code editor and let's start building out our app!
First thing we'll want to do is create a requirements.txt file so that we can specify what python libraries we want to use. Create that file and add the following contents to it:
sentencepiece==0.1.*
torch==2.0.*
transformers==4.*
numpy==1.22.0
Next let's bring in the Hugging Face model we want to run our inference against and in this case I'm going to use Google/flan-t5-small which is a text2text-generation model. Now if you are a AI/ML buff you might be wondering why I'm using a text2text model when I technically should lean towards a classification model like bart-large-mnli. The answer simply comes down the flan-t5-small being a smaller model which will help optimize the performance of our eventual container further along in this guide.
Ok, now let's actually build out our classifier which we are going to call inference.py. Create the file and paste the following code:
import argparse
from transformers import pipeline
def main():
parser = argparse.ArgumentParser()
parser.add_argument("statement", type=str, help="The statement to be classified")
args = parser.parse_args()
# Grab the statement from the users provided input
statement = args.statement
# initialize the model
pipe = pipeline("text2text-generation",
model="google/flan-t5-small")
classification_labels = ['positive', 'negative']
# Construct a query we can supply to the model from the input the user gives us
input = f'Statement: ${statement}. Is the statement positive or negative?'
# Generate the text response from the output
output = pipe(input, max_new_tokens=20)
# Grab the generated text
classification = output[0]['generated_text']
# Output whether the classification was bullish (i.e positive) or bearish (i.e. negative)
if classification == classification_labels[0]:
data = {"data" : "bullish"}
else:
data = {"data" : "bearish"}
print(data)
if __name__ == '__main__':
main()
As you can see this app is a simple script that expects a single argument, statement, and will return whether that statement is considered bullish or bearish. Let's confirm it's working by pulling in our requirements and running the app. Open your terminal and run the following commands:
Pull in libraries
pip3 install --no-cache-dir --upgrade -r requirements.txt
Run the script
python3 inference.py "The world is a wonderful place"
Expected output
{ 'data' : 'bullish' }
Awesome!
At this point we've built a script that run locally and classifies a statement as bullish or bearish using a Hugging Face model. Great Job! Be sure to push this to a new public GitHub repo and don't forget to add a .gitignore file if you do. Here's one you can copy if you'd like
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
In the next section, we are going to take our app one step further by containerizing it with Docker and optimizing it to eventually run on the Lilypad Network.
Step 2 - Containerizing our App
Now that we have the core of our app set let's take it one step further and containerize it with Docker. The reason we're doing this is so that we can eventually run it through Lilypad which allows users to run compute jobs against docker containers and/or arbitrary WASM. Under the hood Lilypad utilizes the Bacalhau Network to do the heavy lifting of actually running the jobs that are submitted for processing. Bacalhau does have some limitations though, in particular it doesn't allow for ingress/egress (or at least limits it) which means we can't make network calls from our containerized app. Consequently, when we eventually run our app through Lilypad we'll need to respect that same constraint as well.
To note, if we just containerized our app as is, we wouldn't be able to run it through Lilypad because of the way we have things setup with Hugging Face. At the moment, anytime we run our classifier app, under the covers Hugging Face will try and pull the model from it's in house repository via a network call which will cause our app to fail. Fear not though, as there is a way forward!
What we're going to do to mitigate the networking limitation is to create a mini script to download our model locally (i.e. into our container) so that we don't have to make any extra network calls at runtime to pull this in from Hugging Face. To do this, create a new file called download_model.py and paste in the following code:
from transformers import pipeline
# Download the model files and save them to ./local-flan-t5-small
pipe = pipeline("text2text-generation", model="google/flan-t5-small")
pipe.save_pretrained("./local-flan-t5-small")
Next we'll need to update inference.py slightly to adjust for the following:
Read the
google/flan-t5-smallmodel from our local copy located in./local-flan-t5-smallUpdate our code to read in the
statementinput as an environment variable. This is so it'll be easier to pass this in as input through Lilypad later onAdd code to write our response to a file again for convenience when running our app through Lilypad later on
With those changes our inference.py file will now look like this
import os
import json
from transformers import pipeline
def main():
# Take in the statement to classify as a env variable
statement = os.getenv('STATEMENT', 'DEFAULT_STATEMENT')
# initialize the model
pipe = pipeline("text2text-generation",
model="./local-flan-t5-small")
classification_labels = ['positive', 'negative']
# Construct a query we can supply to the model from the input the user gives us
input = f'Statement: ${statement}. Is the statement positive or negative?'
# Generate the text response from the output
output = pipe(input, max_new_tokens=20)
# Grab the generated text
classification = output[0]['generated_text']
# Create the directory to write our response to
output_path = f'/outputs/response.json'
os.makedirs(os.path.dirname(output_path), exist_ok=True)
# Output whether the classification was bullish (i.e positive) or bearish (i.e. negative)
if classification == classification_labels[0]:
data = {"data" : "bullish"}
else:
data = {"data" : "bearish"}
# Write the result to /outputs/response.json
with open(output_path, 'w') as file:
json.dump(data, file, indent=4)
print(data)
if __name__ == '__main__':
main()
Ok now that we made those tweaks, let's actually containerize our app. To do that what we'll do is create a new Dockerfile in the root of our project and populate it with the following:
# Base our app on the pytorch image so that we don't need to pull libraries through network calls
FROM pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
# Create a new user, set up a home directory, set the userid and set the name
RUN useradd -m -u 1000 user
# Change the working directory to /app
WORKDIR /app
# Copy over the requirements.txt file to the workding directory
COPY --chown=user ./requirements.txt requirements.txt
# install our dependencies
RUN pip install --no-cache-dir --upgrade -r requirements.txt
# copy everything over to the working directory
COPY --chown=user . /app
# Run our script to download google/flan-t5-small to our container
RUN python3 download_model.py
# Set a default statement if the user doesn't provide one during a run
ENV DEFAULT_STATEMENT="Lilypad is awesome"
# Tell our container how to start the app i.e. run inference.py
ENTRYPOINT ["python3", "inference.py"]
# set the STATEMENT ENV Variable to default to start
ENV STATEMENT="${DEFAULT_STATEMENT}"
Now that we have our Dockerfile ready, let's build our image, tag it and push it to Docker Hub. To do that make sure your Docker Daemon is running (i.e. have Docker Desktop running) and preform the following commands in your terminal:
Build the image adjusting the command for your docker alias
docker build --no-cache -t <your-docker-alias>/bullish-bearish-classifier-demo:latest .
Before we push our image, let's test run it locally just to be sure it functions as we expect. To do that run the following command:
docker run -e STATEMENT="Bitcoin is going to be a trillion dollar asset" -e HF_HUB_OFFLINE=1 <your-docker-alias>/bullish-bearish-classifier:latest
You should expect to see output printed to your console that looks like this:
{ 'data': 'bullish' }
Now that we've verified that our app builds and container runs let's actually go through the motions to push it to Docker Hub. So what we'll want do is tag the image we built by first copying it's id (click on Images, and click on your image name e.g. <your-docker-alias>/bullish-bearish-classifier-demo:latest)

Then run the following command in your terminal adjusting for your image-id and docker alias:
docker tag <image-id> <your-docker-alias>/bullish-bearish-classifier-demo:latest
Now that we've tagged the image, let's actually go ahead and push:
docker push <your-docker-alias>/bullish-bearish-classifier-demo:latest
After this completes, you should now be able to go to Docker Hub and view your image. Here's my image for a reference of what it should look like
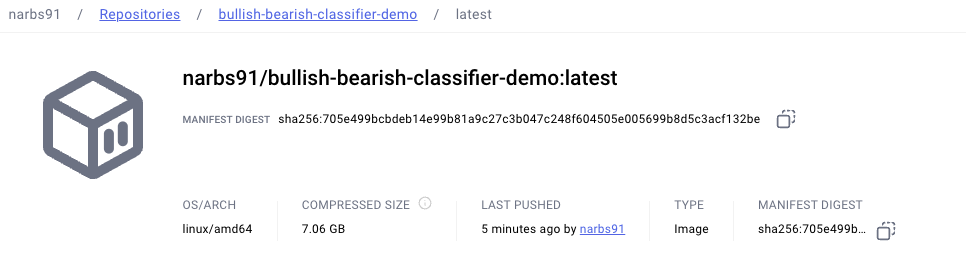
A couple of things to note here are that the image is public (i.e can be pulled by anyone) and that the architecture of our image is built for linux/amd64. This is an important as Bacalhau has the limitation of only being able to support public images that are linux/amd64 based according to it's documentation.
Phew! That was a lot coding and DevOps to get to here, cheers to you if you've stuck around this long 🍻
Take a breather and come back so we can configure our app to actually run through the Lilypad Network in the final two sections (remember to push your code to your repo!)
Step 3 - Building a Lilypad Job Module
Alrighty, we're almost at the finish line here and only have a couple more things to do as we've done most of the heavy lifting in the previous two sections. What we have essentially built thus far in Lilypad lingo is what's called a Job Module. A Job Modules are basically open containerized apps (via Docker) or WASM workloads that the Lilypad team and people like you create to run AI inference, training, or any other arbitrary compute tasks. To complete our Job Module what we need to do is add a configuration file written as a .tmpl so that when we run our job through Lilypad, it knows all the parameters and instructions to pass along to the Bacalhau Network to run our compute job.
So for this step you can approach it in a couple of ways:
a) We can create the template in our main repo where we built our buillish-bearish-classifier-demo app
b) Or, you can create a brand new repo to house the configuration
I will assume you chose option a) for the rest of this guide but the core principals remain the same if you go with b). So go ahead and create a new file called lilypad_module.json.tmpl and copy over the following code into that file:
{
"machine": {
"gpu": 1,
"cpu": 1000,
"ram": 100
},
"job": {
"APIVersion": "V1beta1",
"Spec": {
"Deal": {
"Concurrency": 1
},
"Docker": {
"Entrypoint": [
"python3",
"inference.py"
],
"EnvironmentVariables": [
{{ if .STATEMENT }}"{{ subst "STATEMENT=%s" .STATEMENT }}"{{else}}"STATEMENT=Lilypad is Awesome"{{ end }},
"HF_HUB_OFFLINE=1"
],
"Image": "<your-docker-alias>/bullish-bearish-classifier-demo:latest@sha256:<your-SHA256-hash>"
},
"Engine": "Docker",
"Network": {
"Type": "None"
},
"Outputs": [
{
"Name": "outputs",
"StorageSource": "IPFS",
"Path": "/outputs"
}
],
"PublisherSpec": {
"Type": "IPFS"
},
"Resources": {
"GPU": "1"
},
"Timeout": 1800,
"Verifier": "Noop"
}
}
}
There's a lot going on in this file but here's a breakdown of what each of the fields represents at a high level:
Machine: Specifications about the specs of the machine that you are requesting to run your job
Job: The specification of the job that you want to run that's submitted to the Bacalhau Network
APIVersion: Specifies the API version for the job
Spec: Contains the detailed job specifications
- Deal: Sets the concurrency to 1, ensuring only one job instance runs at a time
Docker: Configures the Docker container for the job
Entrypoint: Defines the command to be executed in the container. This is essentially what we had in our Dockerfile if you recall
EnvironmentVariables: This can be utilized to set env vars for the containers runtime, in the example above we use Go templating to set the STATEMENT variable dynamically (this why we changed
inference.pyread its user input) from the CLI as well as setting HF_HUB_OFFLINE to 1 telling Hugging Face to run our with locally cached files to avoid it doing a network call to pull in the modelImage: Specifies the image to be used (
<your-docker-alias>/bullish-bearish-classifier-demo:latest@sha256:<your-SHA256-hash>), It's important to note to reference the SHA256 hash if you are using Docker which can be found though clicking into the details of your image on Docker Hub and copying the manifest digest
Engine: In our example we are using Docker as the container runtime
Network: Specifies that the container does not require networking, here setting "type" to "none"
Outputs: Specifies the name and location of where the output of our job will be placed. Look back at the
inference.pyfile and note the output directory we set to write our json dataPublisherSpec: Sets the method for publishing job results to IPFS (also supports S3)
Resources: Indicates we need some additional GPU resources to do this job, here I specified 1 GPU resource
Timeout: Sets the maximum duration for the job to 1800 seconds
Verifier: Specifies "Noop" as the verification method, meaning no verification is performed
If you're interested in seeing the specifications more in depth, you can check out the code for Machine and Job respectively.
Go ahead and push this change up to your repo at this point in time. Once you do you'll need to create a release version in GitHub and apply a tag to it. Lilypad will need this information so that it can cache your repo locally when you use the CLI so that it can process your configuration file. You can follow this guide to create a GitHub release if you've never created one before. Be sure to take note of the tag you attach to the release as we'll need to use it in the next and final section
Step 4 - Running our Job Module on the Lilypad Network
Wow, it's been quite a journey building our app, containerizing it and prepping it for being run on the Lilypad Network. To take us across the finish line, let's actually run our bullish-bearish-classifier through Lilypad!
Assuming you have the Lilypad CLI installed and your Metamask Wallet properly funded, running our inference workload is as easy as the following command:
lilypad run github.com/your-github-alias/your-repo-name:<your-tag> -i STATEMENT="The world is a wonderful place"
Let's breakdown the command a bit so you get an idea of what's going on:
lilpad run: command for lilypad to run a workloadgithub.com/your-github-alias/your-repo-name:<your-tag>: the url pointing to your repo that contains thelilypad_module.json.tmplconfiguration file-i STATEMENT="The world is a wonderful place": The-iis a flag to indicate you are passing in an input which in this case is the ENV variable STATEMENT set to the string "The world is a wonderful place"
*Note that at the moment of writing this guide there are some issues with jobs making it through to run, so if you do get some failed runs just keep trying. A failed run could have something like a network error pop up or a result that reports your output can be opened but no files actually exist.
If all goes well, you should see output like the following.
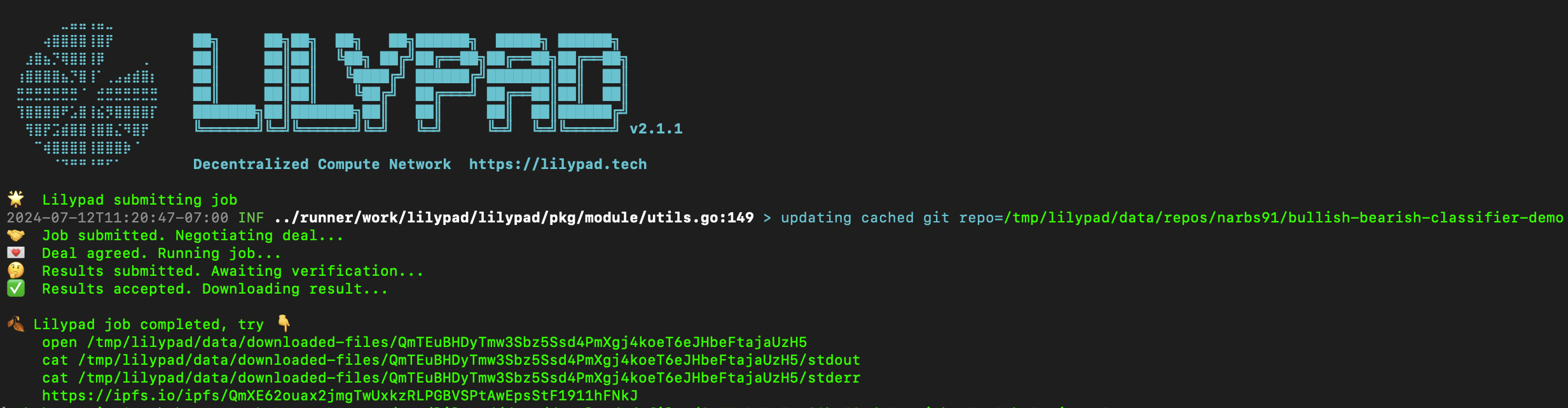
if you copy and run the open command the CLI spits out it'll open a finder window with the output of the run (recall we'd wrote a line in our inference.py script that output our json to the outputs folder):
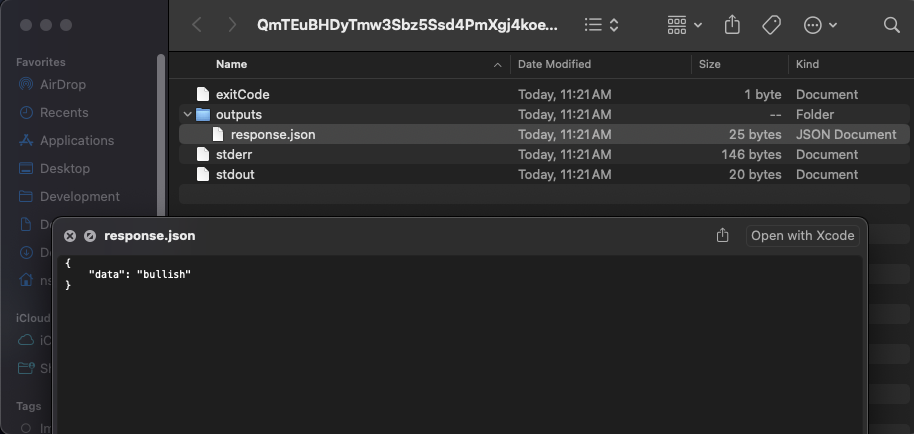
You can also look at the output on IPFS as the process also uploads the results there (since we specified it in our configuration) but note that due to the nature of the IPFS network it can be slow to load.
Troubleshooting
You are likely to face some issues as all of this is bleeding edge tech, here are some resources you can explore to see if you ever get stuck:
Join the Lilypad Discord to ask any specific questions to the team
-
Note: if the Lilypad Network is down for some reason and you need to test your container, you can run the job directly on Bacalhau if you install their CLI
For example, if you want to run the same classifier directly on Bacalhau, you can use the following command:
bacalhau docker run --wait --id-only --env STATEMENT="The world is a wonderful up place" --env HF_HUB_OFFLINE=1 <your-docker-alias>/bullish-bearish-classifier-demo:latest@sha256:<your-sha256-hash>Then when the command completes, it'll spit out a unique job-id which you can use to query your results:
bacalhau job get <your-job-id>
Closing Remarks
Congratulations! You are fully equipped to go create your own Job Module utilizing a Hugging Face Model to run on the Lilypad Network 🎉
Be sure to join the Lilypad Discord for support if you should ever need it and share your creations with the Lilypad team on X. Also, you can follow me on X for more great Web3 content like the long running weekly podcast I host through the Developer DAO called DevNTell giving founders and weekend hackers a space to share their work. If you end up building something amazing using this guide, do be sure to sign up to showcase it on DevNTell, I'd love to have you on!
Subscribe to my newsletter
Read articles from Narbeh Shahnazarian directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by