Implémenter du LLM, RAG, et des vecteurs en Golang
 Anthony DASSÉ
Anthony DASSÉ
Dans le premier article (disponible ici : Développer sa première application Golang avec Langchain et un LLM), nous avons vu comment utiliser les APIs offertes par Langchain pour poser une simple question au LLM, puis une question avec du contexte.
Cette injection de contexte peut rapidement devenir problématique lorsque la base de connaissance source devient conséquente 🤯. En effet, nous pourrions naïvement penser à charger l'intégralité de nos documents dans le contexte, mais cela atteindrait rapidement une limite en termes de performances.
C'est là qu'intervient le RAG 🦹.
Dans cet article, nous allons faire nos premiers pas avec ce nouveau concept.
Les différentes sources sont disponibles sur le 🦊Repository Gitlab.
Comment cela fonctionne ?
RAG pour Retrieval Augmented Generation, c'est un processus consistant à optimiser le résultat d'un LLM. Ce principe vient donc combiner les connaissance du LLM avec nos propres informations (nos documents, base de connaissance).
L'intérêt du RAG c'est de ne pas avoir à réentraîner le modèle, ce qui permet d'économiser beaucoup de ressources.
Ci-dessous un schéma que nous allons utiliser le long de cet article :
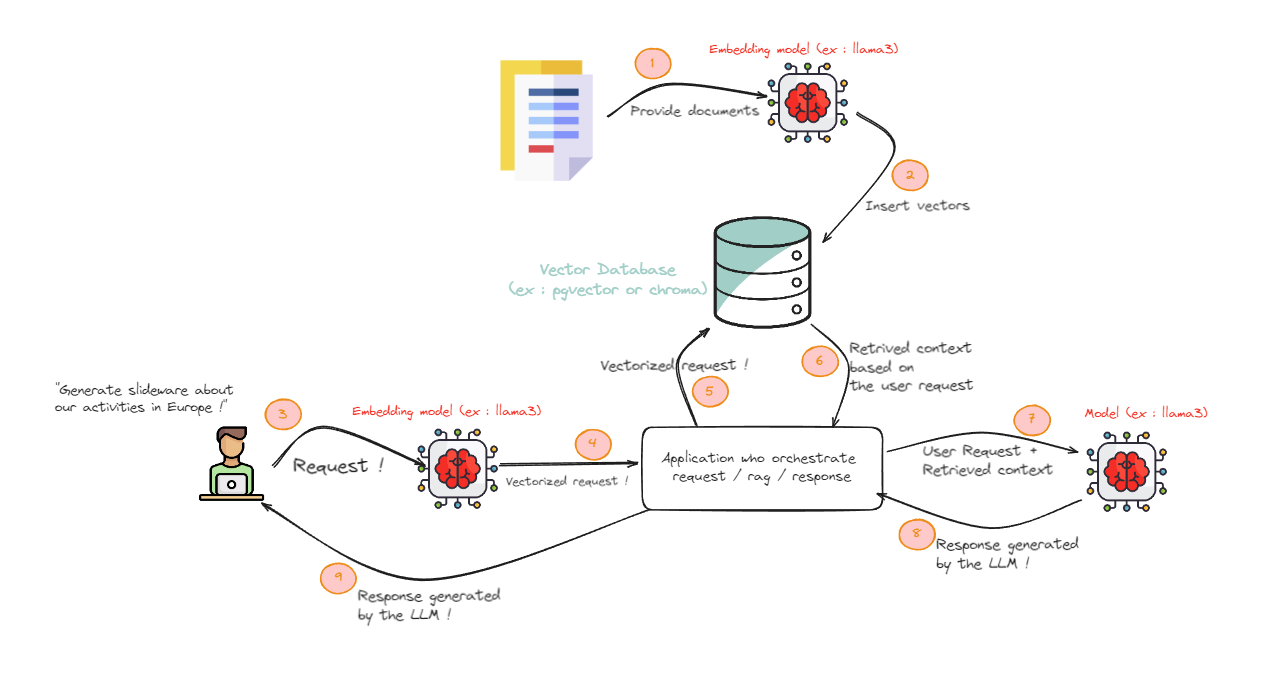
Deux grosses phases sont présentes : la phase d'alimentation de la base de connaissance et la seconde, l'utilisation de cette base de connaissance pour la phase de RAG.
Avant d'aller plus loin, je dois parler d'une chose ( que vous avez dû voir dans le schéma). La base de données utilisée pour stocker notre base de connaissance doit pouvoir contenir des vecteurs ( oui oui , le truc mathématique 📐là ..) afin de pouvoir être utilisé.
Les vecteurs et leurs utilisations
L'idée principale est de pouvoir stocker les données dans un format facilement requêtable et surtout où il est simple de retrouver des similarités (retrouver des informations proches), pour cela la meilleure façon : un vecteur mathématique.
Ci-dessous une série de vecteurs représentés de façon simpliste ( sur 2 dimensions , dans la base ça sera plus de 1000 dimensions).
Nous pouvons représenter ici nos données de la sorte :
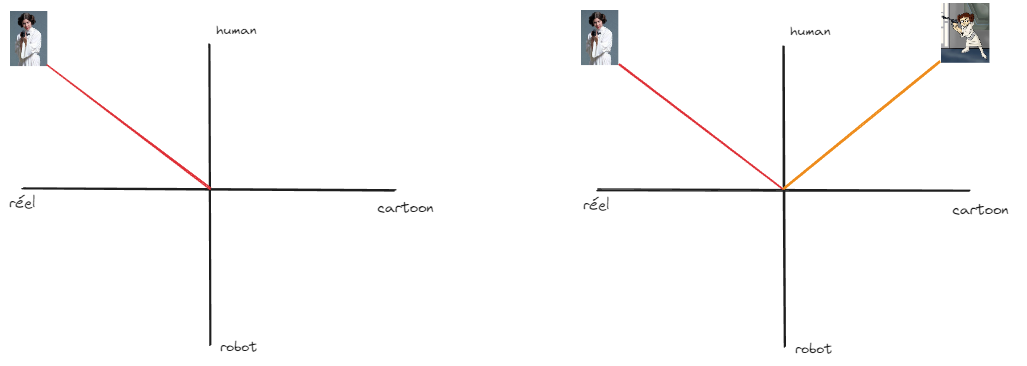
Ici deux Leia , une assez réelle car jouée par une actrice, l'autre provenant d'un cartoon. Les deux sont définies comme humaine dans le Lore Star Wars.
On peut en rajouter deux autres :
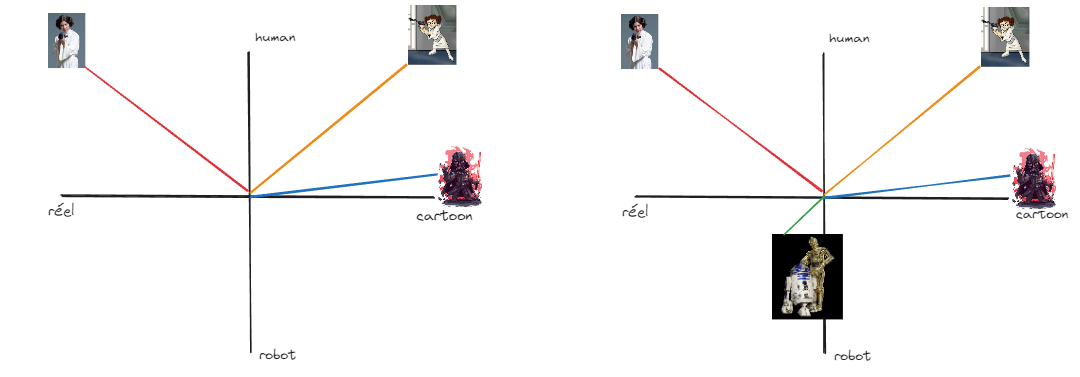
Ici : Dark Vador est en mode cartoon, et il est mi-humain .. mi-robot. Notre duo de Droids sont des robots ... assez réels car joué par des acteurs mais pouvant être en image de synthèses selon les films.
Donc là, nous avons notre base de connaissance avec nos données sous forme de vecteur. Il est donc maintenant possible de faire une recherche par similarité.
Généralement, nous utilisons une recherche par cosine (rien de méchant ... je vais expliquer).
Ci-dessous notre Use Case et son application à la base vectorielle :
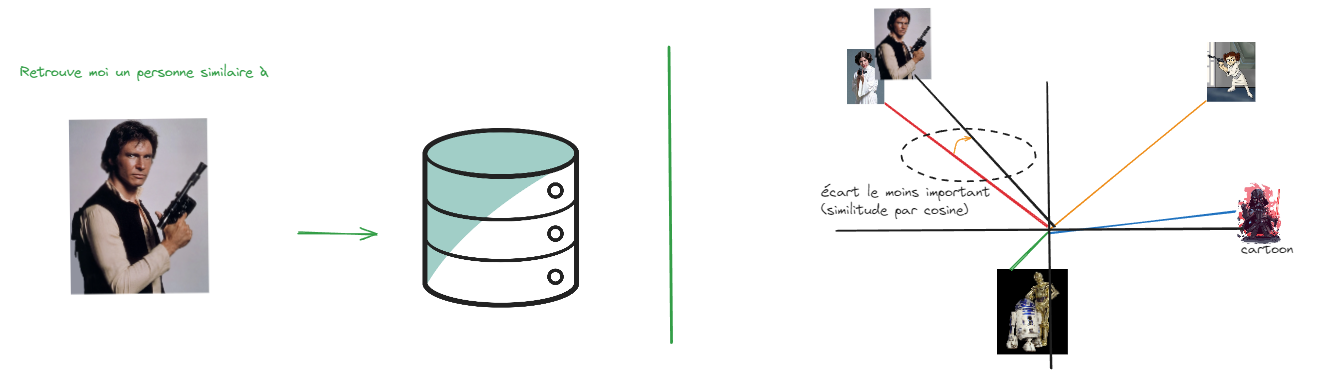
Je recherche 1 personnage le plus proche de Han Solo. Via les dimensions sur lesquelles nous avons définis nos vecteurs, le personnage le plus proche est Leia (version film).
Dans notre exemple, je recherche qu'un résultat, il va donc prendre le plus proche , mais je peux demander les 5 plus proches. Le résultat avec Leia aura un très bon score car très proche et les autres un score moins bon. Ce score (allant de 0 à 1) peut être filtré afin d'obtenir que des résultats cohérents ( je veux que des scores >= 0.80 par exemple).
La formule mathématique appliquée ici :
Soit deux vecteurs A et B, le cosinus de leur angle θ s'obtient en prenant leur produit scalaire divisé par le produit de leurs normes :
- cos𝜃=𝐴⋅𝐵‖𝐴‖‖𝐵‖
.
Les explications ci-dessus sont inspirées d'un talk de David Pilato que je vous recommande fortement : La recherche à l’ère de l’IA (pilato.fr).
Phase d'alimentation
Dans cette partie nous allons nous concentrer sur la phase d'embedding (alimentation) :
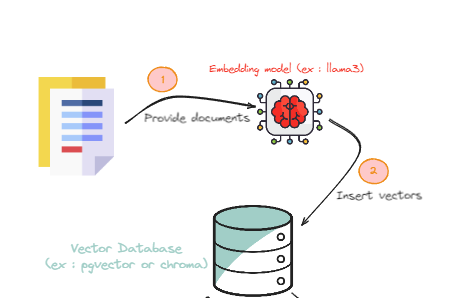
Fournir des documents à un modèle LLM pour les "transformer" en vecteurs
Les vecteurs sont stockés dans la base de données.
Dans cet exemple, nous utilisons PgVector pour stocker nos données.
C'est une base de données Postgresql avec l'extension Vector.
Les ressources nécessaires pour lancer cette base en local (avec Docker) sont disponibles dans le répertoire ressources/pgvector (création de l'image, démarrage ..).
Côté code
Dans le fichier Golang loader.go (point d'entrée de la phase d'embedding), nous mettons en place une fonction qui chargera les documents à partir d'un fichier PDF.
Langchaingo propose nativement une fonction qui charge un fichier PDF (actuellement il est aussi possible de charger du html ou markdown) et retourne une collection de documents. La stratégie de découpage est simple, une page PDF est égal à un document (nous aurions préféré un découpage par chapitre mais pour la démonstration c'est très bien).
func fetchDocumentsFromPdf(filepath string, ctx context.Context) []schema.Document {
file, err := os.Open(filepath)
if err != nil {
log.Fatalln("Error opening file: ", err)
}
fileStat, err := file.Stat()
if err != nil {
log.Fatalln("Error while retrieving file information: ", err)
}
pdfDocuments := documentloaders.NewPDF(file, fileStat.Size())
docs, err := pdfDocuments.Load(ctx)
if err != nil {
log.Fatalln("Error loading document: ", err)
}
return docs
}
Les metadatas de chaque documents comprennent le numéro de page du PDF et le nombre de pages au total.
Dans votre fonction main vous pouvez utiliser la fonction de la sorte (nous utiliserons le résultat un peu plus tard).
func main(){
ctx := context.Background()
docsFromPdf := fetchDocumentsFromPdf("./files/example.pdf", ctx)
log.Println("Number of documents loaded from the pdf file: ", len(docsFromPdf))
log.Println("Metatada in documents loaded from the pdf file: ", docsFromPdf[0].Metadata)
}
Ok, mais du coup si je veux récupérer des données d'une source non supportée par la librairie, je ne peux pas ☹️?
La réponse est : bien sûr que si ! et voici un exemple.
La fonction si dessous est à rajouter dans le fichier loader.go.
func fetchDocumentsFromWhatYouWant() []schema.Document {
docs := []schema.Document{
{
PageContent: `Anthony is a developer from Brittany (where it never rains)!
He tinkers with things like prototypes in Golang, IOT, Kubernetes.
Beer and aperitifs are his friends. Anthony is a boy.
`,
Metadata: map[string]any{
"source": "fetchDocumentsFromWhatYouWant",
"source_date": "202407",
},
},
{
PageContent: `Radia Perlman, born in 1951, is a computer programmer and network engineer.
As one of the most influential women in computer science, she has made significant contributions to the field.
`,
Metadata: map[string]any{
"source": "fetchDocumentsFromWhatYouWant",
"source_date": "202407",
},
},
}
return docs
}
Dans cette fonction, je génère statiquement des documents avec leurs métadatas; mais vous pouvez très bien récupérer des informations depuis une API, une base de données ... ce que vous voulez.
Ensuite, vous pouvez gérer vos propres metadatas afin de rajouter des informations sur les données ou la source de celle-ci.
Maintenant, vous pouvez rajouter l'appel de cette fonction dans votre fonction main et vous avez un chargement de données issu de deux sources :
func main(){
ctx := context.Background()
docsFromPdf := fetchDocumentsFromPdf("./files/example.pdf", ctx)
log.Println("Number of documents loaded from the pdf file: ", len(docsFromPdf))
log.Println("Metatada in documents loaded from the pdf file: ", docsFromPdf[0].Metadata)
docsFromOtherSource := fetchDocumentsFromWhatYouWant()
log.Println("Number of documents loaded from the pdf file: ", len(docsFromOtherSource))
log.Println("Metatada in documents loaded from the pdf file: ", docsFromOtherSource[0].Metadata)
docsFromPdf = append(docsFromPdf, docsFromOtherSource...)
}
Le travail n'est pas fini ! il faut maintenant gérer la phase d'embedding.
A la suite de notre fonction main, vous pouvez rajouter les séquence ci-dessous :
//model initialization
llms, err := ollama.New(ollama.WithModel("llama3"))
if err != nil {
log.Fatal("Error during LLM initialization: ", err)
}
e, err := embeddings.NewEmbedder(llms)
if err != nil {
log.Fatal("Error during Embeder initialization: ", err)
}
Ici j'utilise Llama3 comme modèle d'embedding. Attention, ne pas oublier de démarrer ollama et de charger le bon modèle ( comment faire ? vous avez un exemple dans le premier article de la série 👉 ICI 👈)
Je vais initialiser la connexion à la base de données (de vôtre côté ... bien vérifier que la base est démarrée 😉) avec le composant d'embedding.
store, err := pgvector.New(
ctx,
pgvector.WithConnectionURL("postgres://testuser:password@localhost:5432/testdb?sslmode=disable"),
pgvector.WithEmbedder(e),
)
if err != nil {
log.Fatal("Error during PgVector initialization: ", err)
}
Nous nous rapprochons de la fin, nous allons vectoriser + charger les données dans PgVector :
// store vectors !
log.Println("Store data (vectors) on the database")
store.AddDocuments(context.Background(), docs)
Selon le modèle utilisé, la quantité de documents et la machine utilisée pour cette phase ... cela peut-être plus ou moins long.
Et comme j'aime bien tester que l'insertion s'est bien déroulée; je fais simplement un test de similarité en lui demandant de me retrouver les 2 documents les plus proches de cette requête : only women.
test, err := store.SimilaritySearch(ctx, "only women", 2)
if err != nil {
log.Fatal(err)
}
log.Println(test)
Pour les petits curieux ! Côté base de données, mes vecteurs sont stockés de la sorte :

Une collection de vecteur représentée par un ID, mon vecteur, le document en question, les métadatas, et l'id de mon entrée en base de données.
Phase de prompt
Nous allons donc pouvoir exploiter notre base de connaissance chargée.
Dans ce chapitre, nous nous concentrerons seulement sur cette partie :
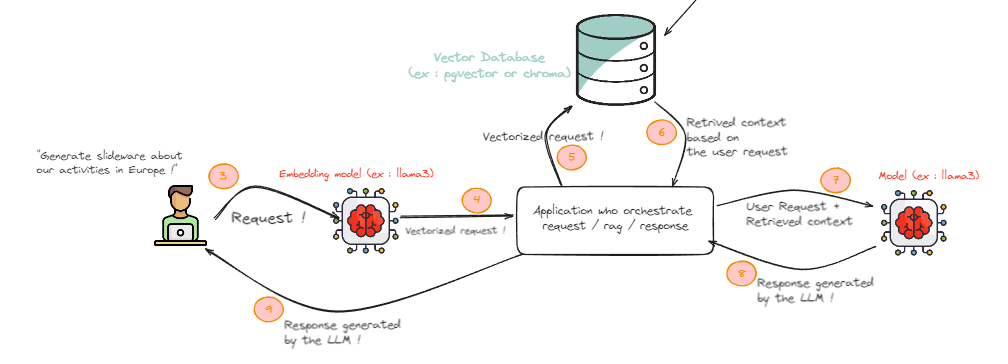
L'utilisateur réalise sa requête habituelle
La requête est vectorisée et préparée pour la phase de customisation du contexte
Cette requête vectorisée est comparée sur notre base de connaissance
Une liste de documents proches de notre requête est retournée
La requête initiale et les documents récupérés (utilisés comme contexte) sont envoyé au LLM dans un même prompt.
Le modèle retourne une réponse
Cette réponse est retournée à l'utilisateur
Pour cela, nous allons initialiser un fichier main.go avec ces fonctionnalités (que nous avons déjà vu 👀) :
Initialiser le LLM et le système d'embedding
Créer la connexion avec la base de données
func main(){
ctx := context.Background()
llm, err := ollama.New(ollama.WithModel("tinydolphin"))
if err != nil {
log.Fatal("Error during LLM initialization: ", err)
}
e, err := embeddings.NewEmbedder(llm)
if err != nil {
log.Fatal("Error during Embeder initialization: ", err)
}
store, err := pgvector.New(
ctx,
pgvector.WithConnectionURL("postgres://testuser:password@localhost:5432/testdb?sslmode=disable"),
pgvector.WithEmbedder(e),
)
if err != nil {
log.Fatal("Error during PgVector initialization: ", err)
}
}
Nous allons raffiner notre contexte en recherchant des documents pouvant aidés à la génération de la réponse.
docs, err := store.SimilaritySearch(ctx, "document about developer, golang or brittany", 7)
if err != nil {
log.Fatal("Error during SimilaritySearch : ", err)
}
Je peux soit reprendre le prompt initial, soit créer un nouveau prompt en appliquant des règles métiers (par exemple : filtrer sur les développeurs, les sujets parlant de Golang ou de la Bretagne).
Il est aussi possible d'ajouter un système de seuil sur le score pour récupérer les documents les plus intéressants.
Il est aussi possible d'utiliser un filtre, spécifiant quels metadatas récupérer. Par exemple, je ne veux récupérer que des documents provenant de tel ou tel source :
filter := map[string]any{"source": "fetchDocumentsFromWhatYouWant"}
docs, err = store.SimilaritySearch(ctx, "document about developer, golang or brittany", 7, vectorstores.WithFilters(filter))
if err != nil {
log.Fatal("Error during SimilaritySearch : ", err)
}
Et maintenant que nous avons nos documents, nous pouvons interroger notre LLM avec un contexte étoffé ( comme dans le chapitre du premier article) :
answer, err = chains.Call(context.Background(), stuffQAChain, map[string]any{
"input_documents": docs,
"question": "Who is Anthony ?",
})
if err != nil {
log.Fatal(err)
}
log.Println(answer)
Conclusion
Nous avons vu qu'il est simple d'utiliser notre propre base de connaissances pour étendre la puissance du modèle LLM avec Ollama, Langchain et une base de données PgVector.
Le choix de PgVector a été fait pour des raisons de simplicité, car je connais bien PostgreSQL. Il existe de nombreuses bases de données pouvant la remplacer (comme Pinecone, Chroma ou encore Elasticsearch) et qu'il sera intéressant d'explorer.
De même, le choix du modèle d'embedding était arbitraire. Il serait pertinent d'en tester plusieurs pour voir lequel est le plus performant.
Subscribe to my newsletter
Read articles from Anthony DASSÉ directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Anthony DASSÉ
Anthony DASSÉ
Architecte Solution passionné par les technologies et l’apprentissage continu, je valorise le partage des connaissances et encourage activement cette pratique. Enthousiaste des nouvelles technologies, domotique, IOT et adepte du bricolage, je suis également sportif, intégrant l’activité physique dans mon quotidien.