Exploring the Cyclic Property in C Language
 Dibyashree Chakravarty
Dibyashree Chakravarty
Have you ever encountered unexpected results in C programming? Let's delve into an intriguing concept that explains why some values behave oddly, showcasing a fascinating trick with character variables. Imagine we have a C program where we declare a character variable ch and assign it a value. Here’s the code:
#include <stdio.h>
int main() {
char ch = 129;
printf("ch as integer = %d\n", ch);
printf("ch as character = %c\n", ch);
return 0;
}
Now, you might expect ch to hold the value 129 and print it out, right? But when you run this program, you’ll see something surprising! Instead of printing 129, you’ll get a different number and a weird character. Let’s dive in and find out why this happens.
What’s Going On?
In C, the char data type is usually an 8-bit signed integer. This means it can store values from -128 to 127. When we assign a value outside this range, like 129, something interesting happens: it wraps around in a circle, just like a clock!
Think of it like this: if you’re standing on a circular track and start walking, you’ll eventually come back to where you started after completing a full circle. Similarly, in C, when you go past the maximum value that an 8-bit integer can hold, it wraps around to the other side.
You can think of a clock too: Look at the following diagram. Like we represent the number line in a 3 sections -ve,0,+ve which leads to infinite in both side, this is a circular representation of the bits . The clockwise turn shows the unsigned bits starting from zero to 127 (for n bit range in signed: 0 to (2^{n}) , for signed 8 bit the range will be: -(2^{n}) to [(2^{n})-1] ). We the maximum value is encountered the it wrap around to other side.
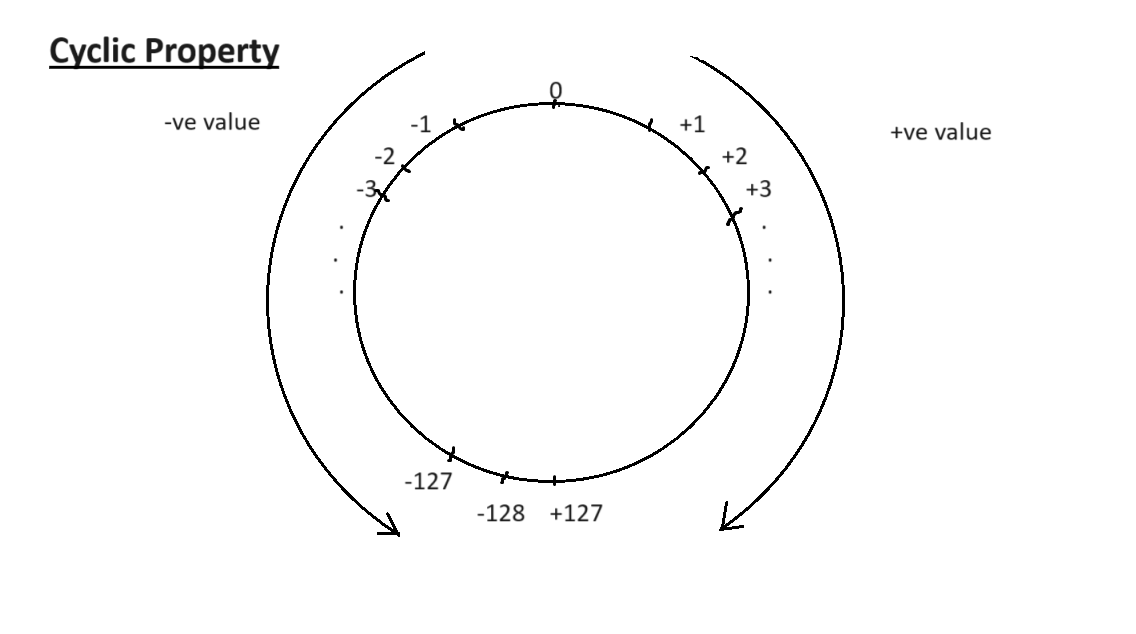
Using this second method if we want to find the value of 129 , we move clockwise to find the 129th value which is the next of 128 i.e. -127. The integer output will therefore be -127 and its equivalent ASCII character ( move anti clockwise and get the 127th position of the unsigned clock cycle to find out the digit . Thus you will get the 129 digit in the unsigned clock cycle and the digit having 129 ASCII value will get printed.) will be printed as output.
Breaking It Down
Here’s how it works in our program:
Overflow: The
chartype can hold numbers from -128 to 127. When you assign 129 toch, it’s like taking a step beyond the edge of the circle.Wrapping Around: Because 129 is 2 steps beyond 127 (the max value), it wraps around to -127. So,
chactually holds the value -127.
Why Should You Care?
Understanding this cyclic property is super important in programming. It helps us to avoid bugs and write better code, especially when working with low-level data or limited-range data types.
How Java handles characters?
Java handles characters differently. In Java, the char data type is 2 bytes (16 bits) because it uses the UTF-16 encoding to represent characters.
Why Java char is 2 Bytes:
Unicode Representation:
Java uses Unicode to represent characters instead of ASCII. Unicode is a standard that includes a wide range of characters from many different languages and symbol sets.
Unicode assigns a unique number (code point) to each character. To support this, Java needs to handle a large range of characters.
UTF-16 Encoding:
To represent Unicode characters, Java uses UTF-16 encoding. UTF-16 uses 16 bits (2 bytes) for most characters, which covers the Basic Multilingual Plane (BMP) where most common characters are found.
Characters in the BMP are directly represented with a single 16-bit value.
Supplementary Characters:
- Some Unicode characters are not in the BMP and require more than 16 bits to represent. These characters are represented using a pair of 16-bit values, known as surrogate pairs.
Breakdown:
2 Bytes (16 Bits): This allows Java to represent any character in the BMP directly.
Surrogate Pairs: For characters outside the BMP, UTF-16 uses two 16-bit values to represent a single character.
Example:
Character 'A': The Unicode code point for 'A' is 65, which fits in 16 bits. So, it's directly represented in a single
charvalue.Character '𠀀' (a character outside the BMP): This character requires two
charvalues in UTF-16 encoding. Java handles this using surrogate pairs.
Final Thoughts
Exploring the cyclic property in C and how it impacts character values reveals a fascinating aspect of programming. By understanding how values wrap around when they exceed their limits, you can better grasp why certain outputs might seem surprising.
In C, this wrapping behavior is a natural result of using fixed-width data types like char, which can only hold a limited range of values. The same principle applies to many low-level operations and data types, making it crucial for writing robust and error-free code.
On the other hand, Java's approach to characters with its 2-byte char type and UTF-16 encoding highlights the importance of supporting a diverse range of characters across different languages and symbols. This design allows Java to handle a wide array of characters, both within and beyond the BMP, ensuring compatibility with modern text processing needs.
Understanding these differences and concepts not only enhances your coding skills but also deepens your appreciation for how various programming languages handle data. So, whether you're working with C's cyclic properties or Java's Unicode characters, keep these insights in mind to navigate your coding challenges with confidence.
Happy coding, and may your programs always wrap around smoothly!
Subscribe to my newsletter
Read articles from Dibyashree Chakravarty directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by