The Puzzling Failure of Multimodal AI Chatbots
 Chia Yew Ken
Chia Yew Ken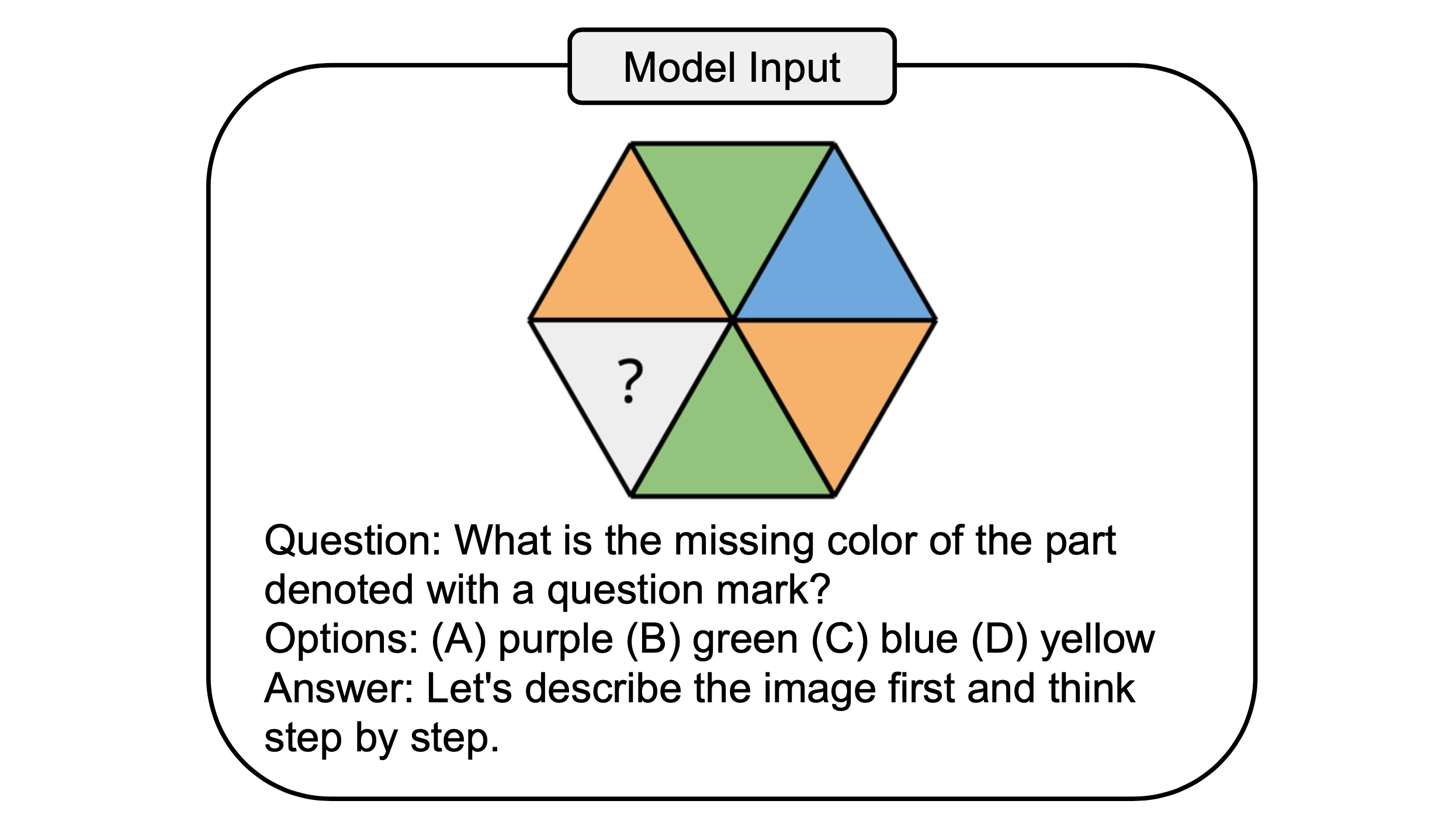
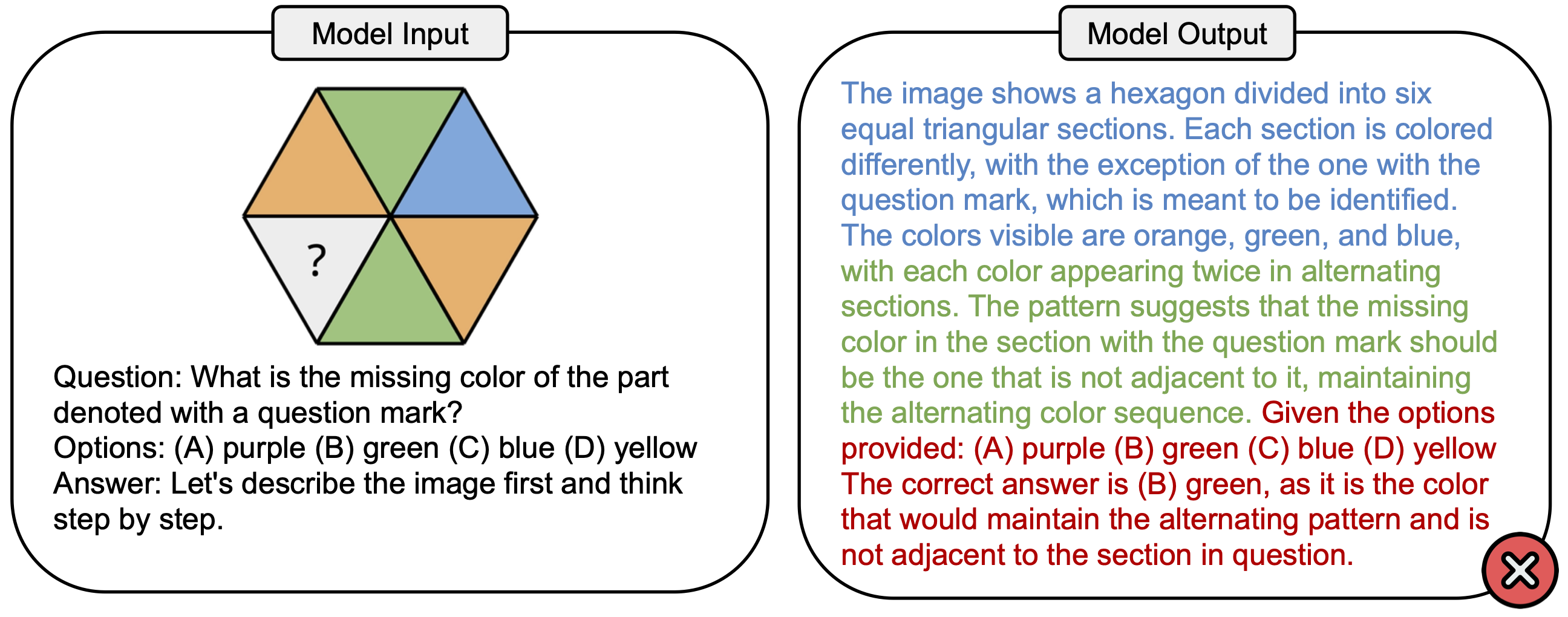
Chatbot models such as GPT-4o and Gemini have demonstrated impressive capabilities in understanding both images and texts. However, it is not clear whether they can emulate the general intelligence and reasoning ability of humans. To investigate this, we introduce PuzzleVQA, a new benchmark of multimodal puzzles to explore the limits of current models. As shown above, even models such as GPT-4V struggle to understand simple abstract patterns that a child could grasp.
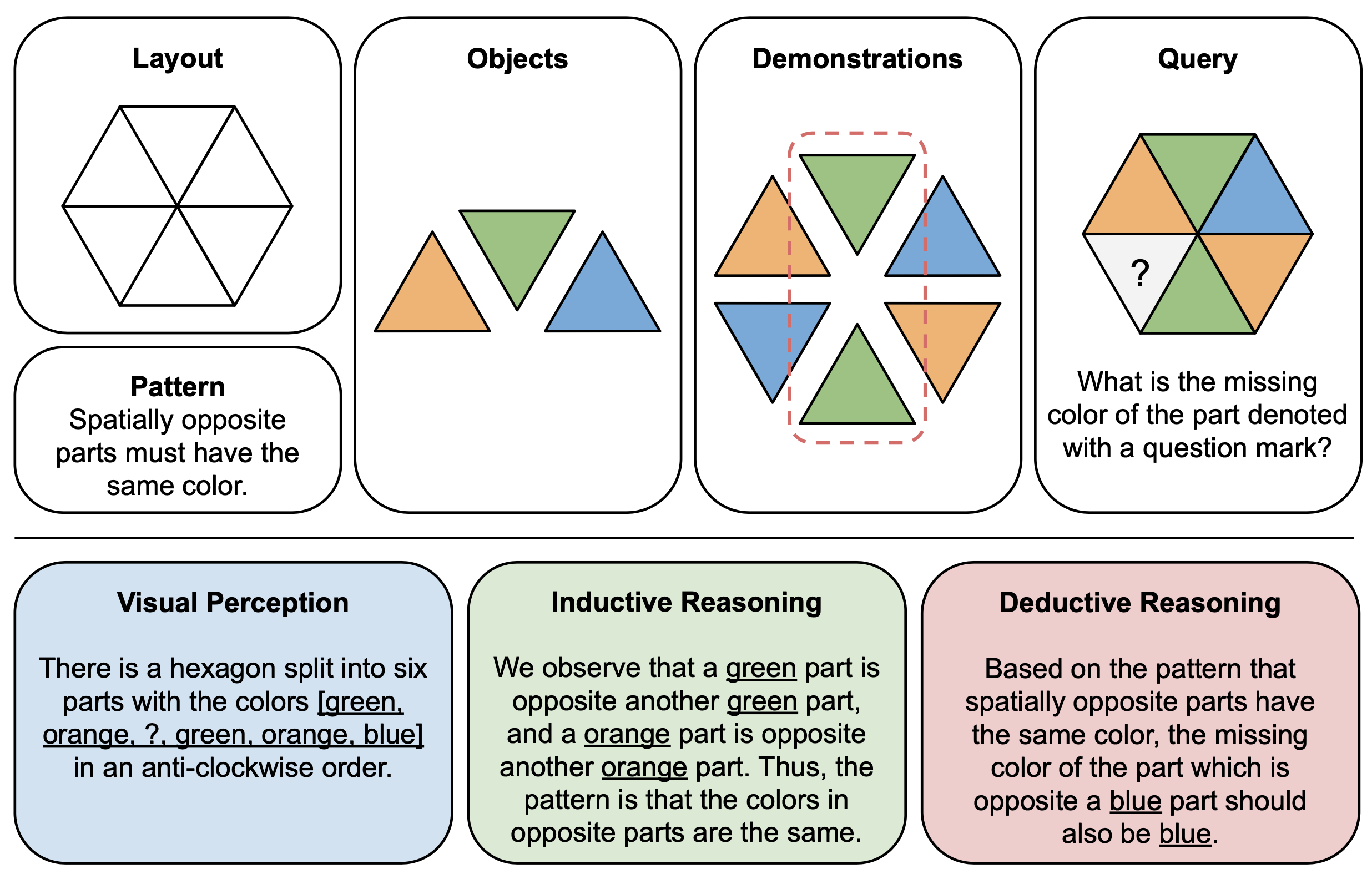
To construct our puzzle dataset, we first identify the key components of each puzzle:
Objects: The conceptual elements that interact within the puzzle, such as numbers, colors, shapes, and size.
Layout: The spatial arrangement of objects that provides visual context.
Pattern: The relationship that governs the interaction amongst objects. For example, a pattern may be that spatially opposite parts must have the same color.
Demonstrations: Multiple instances of interacting objects that collectively represent the underlying pattern. Without demonstrations, the pattern would become ambiguous.
Query: The natural language question that directs the multimodal model how to solve the puzzle by determining the missing object.
At the same time, we can also decompose the puzzle solving process into three main stages: visual perception of the objects in the puzzle, inductive reasoning to recognize the pattern shown, and deductive reasoning to find the missing part based on the pattern. In total, our benchmark consists of 2000 puzzle instances.
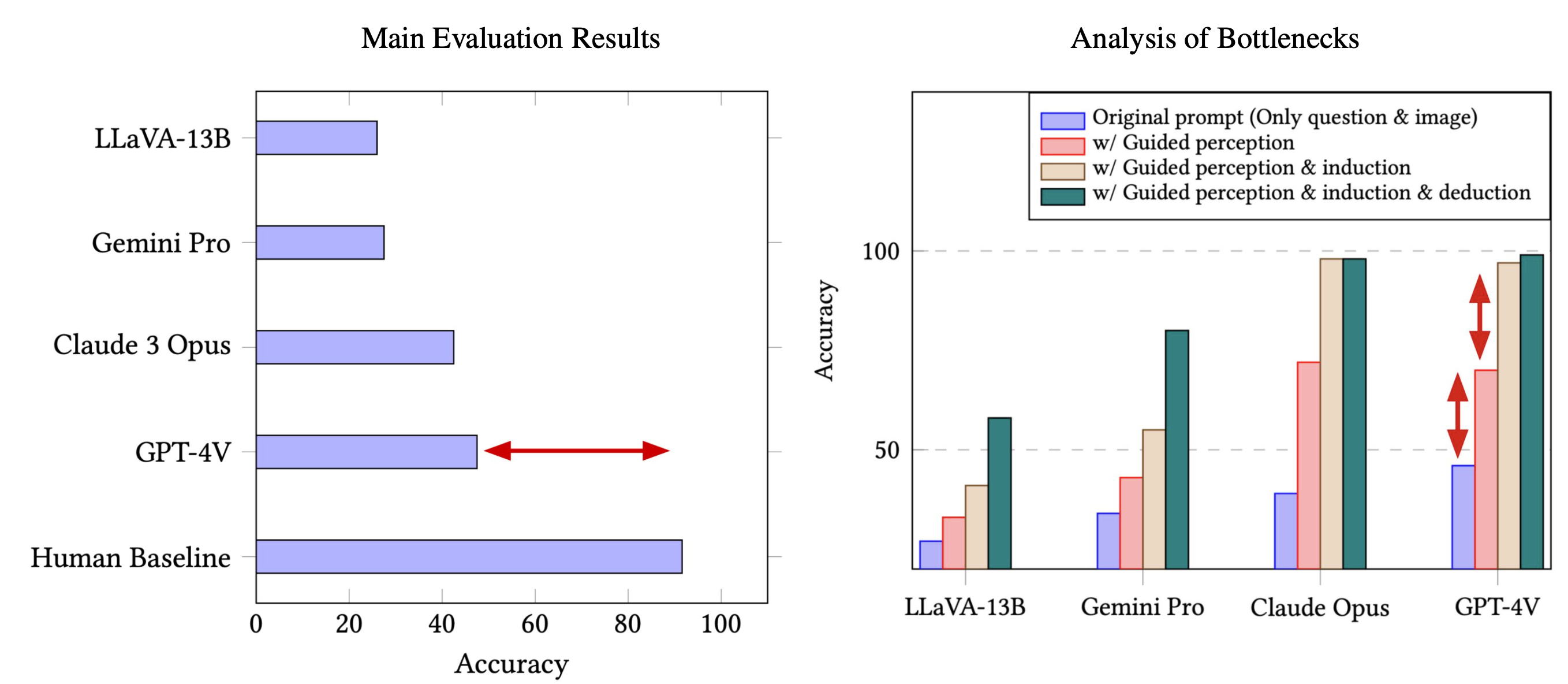
Despite the apparent simplicity of the puzzles, we observe surprisingly poor performance for current multimodal AI models. Notably, there remains a massive gap towards human performance. Thus, the natural question arises: what caused the failure of the models? To answer this question, we ran a bottleneck analysis by progressively providing ground-truth "hints" to the models, such as image captions for perception or reasoning explanations. As shown above, we found that leading models face key challenges in visual perception and inductive reasoning. This means that they are not able to accurately perceive the objects in the images, and they are also poor at recognizing the correct patterns.

As shown above, we are still far away from models that can reliably emulate general intelligence, even in simple abstract scenarios. Current multimodal AI chatbots have severe limitations in visual perception and can even hallucinate non-existent objects. Beyond perception, we also have to improve their inductive reasoning to recognize and understand patterns in the real world. This research work will be presented at the ACL 2024 conference, and you can find out more at our website or paper. Thanks for reading!
Subscribe to my newsletter
Read articles from Chia Yew Ken directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Chia Yew Ken
Chia Yew Ken
Hi! I'm a 2nd year PhD Student with SUTD and Alibaba. My research interests currently include zero-shot learning, structured prediction and sentiment analysis.