Container Networking Explained (Part V)
 Ranjan Ojha
Ranjan OjhaWe have come a long way in our series. By now you should be able to by just looking at network interfaces, routes, and iptables, defined in the Kubernetes node machine understand how the containers are talking with each other in the same node. It is time for us to expand to a multi-node system. While Docker has a Docker swarm mode that also allows us to expand into multi-node systems, most people will agree that Kubernetes is the way to go.
Just like how I started with Docker networking specification, the detailed specification for Kubernetes CNI can be read here and is the perfect starting position. For the vast majority of you who just want to get down and dirty without going through all the pages of specification, here is a list of things that a CNI is expected to accomplish.
Given a container (a container is defined as a network isolation domain, like containers in docker and pod in Kubernetes), CNI must be able to connect the container to the host system using the provided IP addresses, and interface name. This is known as the connectivity rule.
Given a container running in Kubernetes cluster. You should be able to reach any pod running on any node in the cluster without NAT. This is known as the reachability rule.
Until now all the work we have done with veth devices, macvlan, ipvlan, they all belong to the first rule. Their sole aim is to connect our container to the host system. In Kubernetes, it is the role of CNI plugins to accomplish these goals.
Fun fact: Flannel a popular networking option for Kubernetes doesn't even have it's own cni plugin. It simply delegates this work to already provided reference plugins.
And what about reachability? There are 2 ways to go about this.
Underlay network
Overlay network
Underlay network
Using our VM example configuration, to utilize an underlay network we simply connect all our VM to the same switch. Well, we want all of our VM's to be in the same broadcast domain. This configuration has lower overhead when compared to overlay networks however requires that you be in control of the networking stack of the nodes, which is not always possible, especially in a cloud environment. However, this is the option you should choose whenever possible as they have the lowest overhead.
Funfact: using VLAN you can have your devices be connected on same switch but be on different broadcast domains.
Overlay network
In situations where an Underlay network is not possible, we can use an Overlay network. With an overlay network, we create a virtual L2 network on top of a running L3 network. This is the option you have to use if you are connecting nodes across different networks, and also the one we will be focussing on in this post. We will be using vxlan for this. vxlan works with the help of 2 vtep devices. A vtep device (VXLAN terminal end point) is linked to an actual network interface that communicates with the outside world. All the traffic intended to be encapsulated is then sent through this vxlan interface, the interface then wraps the packet in a UDP packet and sends it to the other vtep device where it is unwrapped by vtep before being sent out to the application. One of the reasons I selected vxlan is because most of the CNI currently out there use it for configuring their overlay network.
Some of the few limitations of vxlan,
Because the specification of
vxlanstates that the ethernet packet encapsulated byvxlanshould not be fragmented, the size of the ethernet packet must be smaller than when it's sent out a using regular interface. This is to account for the additionalvxlanheader that has to be added before sending out the packet.vxlanuses plain UDP packets, so the ethernet packets encapsulated are themselves unencrypted. If it is a security requirement, then you have to configure additional IPSEC.
Configuring vxlan
Setting up Management Network
Before setting up vxlan between 2 nodes, it is necessary for us to set up a management network between them. This is the network that for instance if you are setting up a Kubernetes yourself, connects nodes before you start up any CNI. Generally, a management network setup is the responsibility of sysadmins maintaining the nodes, while cluster administrators are responsible for the CNI network.
Below is the setup I am going with.
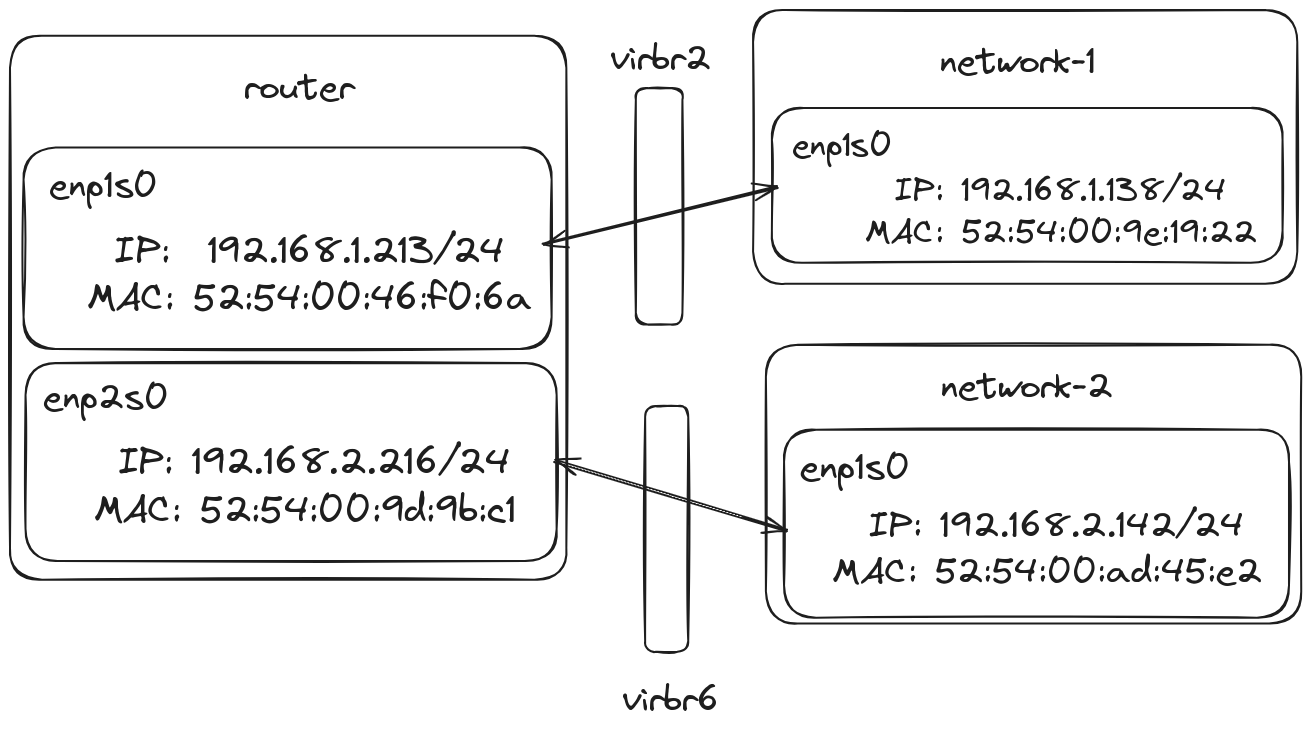
All of these machines are libvirt VMs running using KVM. These VMs are connected using 2 different NAT networks on libvirt. Each of these NAT network correspond to the virtual bridge network, virbr2 and virbr6, on the physical network. 2 VMs are individually on different networks and named network-1 and network-2. There is a third VM that is connected to both networks. This VM works as our router, routing traffic between the 2 devices. DHCP has been enabled on the NAT network.
Note: We could have setup our host device as a router too. However, the steps are more involved as libvirt adds default rules to the
iptablesornftablesblocking the network access between the 2 bridges.
Just connecting all of these VMs on a network however is not enough to get us started just yet, we now need to manually configure the static routes in the VM and setup IP masquerading rules as well. This is because our default route is actually the bridge, in the host system but our router in this case is another VM.
Adding static routes
fedora@network-1:~$ sudo ip r add 192.168.1.0/24 via 192.168.1.213 dev enp1s0 src 192.168.1.138
fedora@network-1:~$ ip r
default via 192.168.1.1 dev enp1s0 proto dhcp src 192.168.1.138 metric 100
192.168.1.0/24 dev enp1s0 proto kernel scope link src 192.168.1.138 metric 100
192.168.2.0/24 via 192.168.1.213 dev enp1s0 src 192.168.1.138
fedora@network-2:~$ sudo ip r add 192.168.1.0/24 via 192.168.2.216 dev enp1s0 src 192.168.2.142
fedora@network-2:~$ ip r
default via 192.168.2.1 dev enp1s0 proto dhcp src 192.168.2.142 metric 100
192.168.1.0/24 via 192.168.2.216 dev enp1s0 src 192.168.2.142
192.168.2.0/24 dev enp1s0 proto kernel scope link src 192.168.2.142 metric 100
Here, we have added new routes on each of the machines pointing to the router for every traffic destined to the other network.
Setting up MASQUERADE rule
fedora@router:~$ sudo iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o enp2s0 -j MASQUERADE
fedora@router:~$ sudo iptables -t nat -A POSTROUTING -s 192.168.2.0/24 -o enp1s0 -j MASQUERADE
fedora@router:~$ sudo iptables-save
# Generated by iptables-save v1.8.10 (nf_tables) on Wed Aug 7 12:38:00 2024
*nat
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [115:10091]
-A POSTROUTING -s 192.168.1.0/24 -o enp2s0 -j MASQUERADE
-A POSTROUTING -s 192.168.2.0/24 -o enp1s0 -j MASQUERADE
COMMIT
# Completed on Wed Aug 7 12:38:00 2024
Similarly, we set MASQUERADE rule for all the traffic going to the respective network through the interface.
Testing setup
We rely on our trusty ping utility for testing the network connection between VMs to ensure our management network is up and running.
fedora@network-1:~$ ping 192.168.2.142 -c3
PING 192.168.2.142 (192.168.2.142) 56(84) bytes of data.
64 bytes from 192.168.2.142: icmp_seq=1 ttl=63 time=1.03 ms
64 bytes from 192.168.2.142: icmp_seq=2 ttl=63 time=0.695 ms
64 bytes from 192.168.2.142: icmp_seq=3 ttl=63 time=0.627 ms
--- 192.168.2.142 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2021ms
rtt min/avg/max/mdev = 0.627/0.782/1.025/0.173 ms
fedora@network-2:~$ ping 192.168.1.138 -c3
PING 192.168.1.138 (192.168.1.138) 56(84) bytes of data.
64 bytes from 192.168.1.138: icmp_seq=1 ttl=63 time=0.911 ms
64 bytes from 192.168.1.138: icmp_seq=2 ttl=63 time=0.970 ms
64 bytes from 192.168.1.138: icmp_seq=3 ttl=63 time=0.761 ms
--- 192.168.1.138 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 0.761/0.880/0.970/0.087 ms
Note: if Ping works but you are unable to reach using other services, then the issue is with firewall.
Planning for IP
The next step in our setup is to decide on the IP for the overlay network. Again, one could run their own DHCP server on the overlay network, but we will be doing manual IP assignment. In Kubernetes, this work is done by the IPAM plugin.
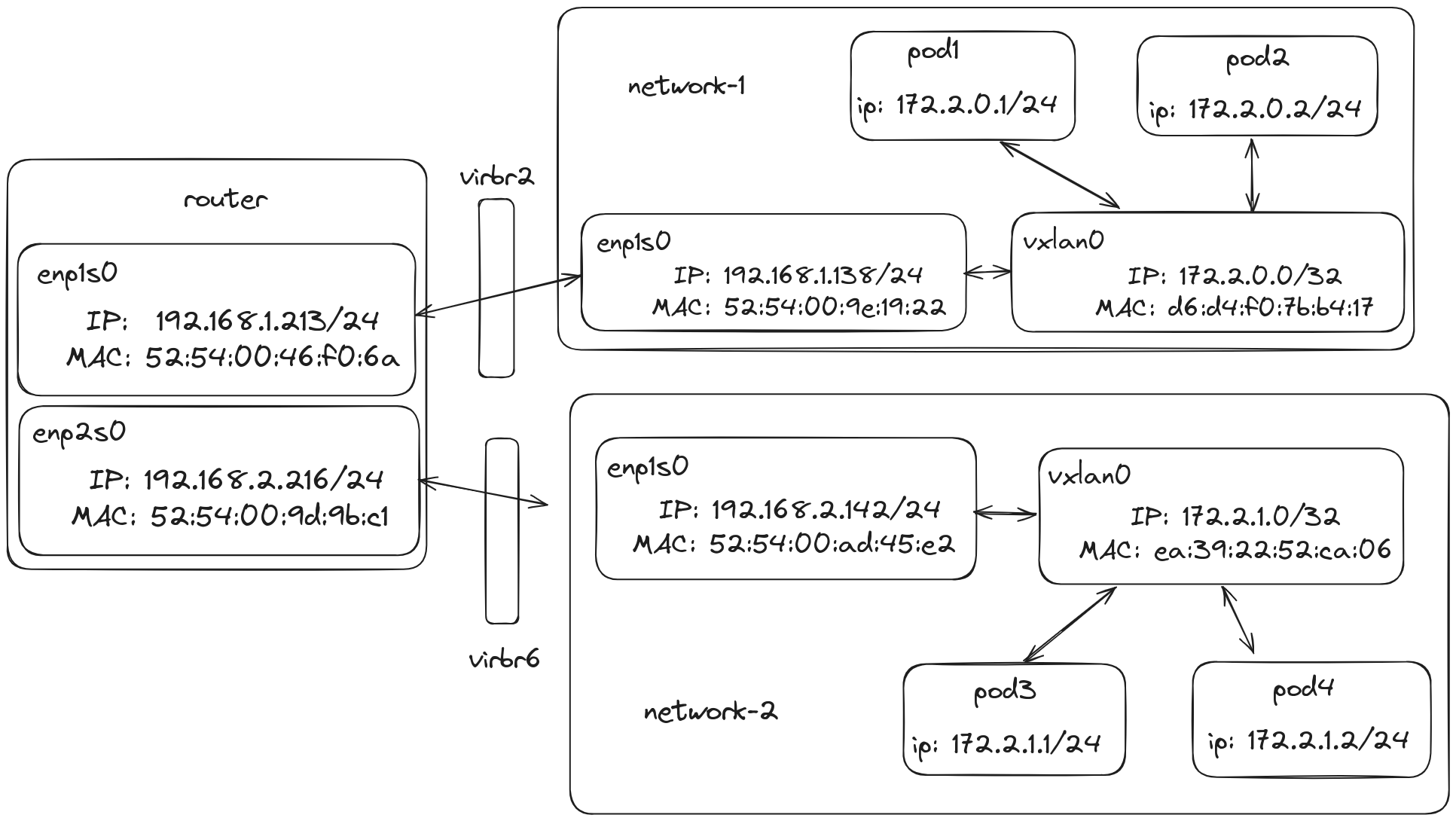
I will be using network 172.2.0.0/16 for my overlay network. I will also be borrowing ideas from IPAM, and similarly configure each of my nodes to be in, 172.2.x.0/24 network with an address of 172.2.x.0/32. This allows my network to support 256 nodes. Each of the containers running in the node then will be assigned an IP from the 172.2.x.0/24 range. This means all pods in the same /24 network group are in the same host node. A picture is always worth a thousand words, so let me show my plan in a table and diagram below.
Here is the IP plan for our cluster,
| Node | IP | Subnet |
| network-1 | 172.2.0.0/32 | 172.2.0.0/24 |
| network-2 | 172.2.1.0/32 | 172.2.1.0/24 |

In the above image, the only thing missing is the MAC addresses of the vxlan0 themselves and that is what we will fill as we go on.
Setting up vxlan
Modes of vxlan
We will be using the Linux Kernel implementation of a vtep device to create our vxlan between host machines. This is also how both flannel and calico work. The Linux implementation for vtep device can use unicast or multicast IP for learning the network. This works by sending out ARP requests of the unknown addresses on the configured IP addresses unicast or multicast then receiving the reply on the same path. However, both flannel and calico instead opt for nolearning mode. Instead, they configure both fdb and arp entries themselves.
Creating vtep interfaces
We start with our familiar, iproute2 command utility to create vxlan.
fedora@network-1:~$ sudo ip link add vxlan0 type vxlan id 10 local 192.168.1.138 dstport 4789 nolearning dev enp1s0
fedora@network-1:~$ sudo ip a add 172.2.0.0/32 dev vxlan0
fedora@network-1:~$ sudo ip link set vxlan0 up
fedora@network-1:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:9e:19:22 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.138/24 brd 192.168.1.255 scope global dynamic noprefixroute enp1s0
valid_lft 2405sec preferred_lft 2405sec
inet6 fe80::5054:ff:fe9e:1922/64 scope link noprefixroute
valid_lft forever preferred_lft forever
4: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether d6:d4:f0:7b:b4:17 brd ff:ff:ff:ff:ff:ff
inet 172.2.0.0/32 scope global vxlan0
valid_lft forever preferred_lft forever
inet6 fe80::d4d4:f0ff:fe7b:b417/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
fedora@network-2:~$ sudo ip link add vxlan0 type vxlan id 10 local 192.168.2.142 dstport 4789 nolearning dev enp1s0
fedora@network-2:~$ sudo ip a add 172.2.1.0/32 dev vxlan0
fedora@network-2:~$ sudo ip link set vxlan0 up
fedora@network-2:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:ad:45:e2 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.142/24 brd 192.168.2.255 scope global dynamic noprefixroute enp1s0
valid_lft 2463sec preferred_lft 2463sec
inet6 fe80::5054:ff:fead:45e2/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether ea:39:22:52:ca:06 brd ff:ff:ff:ff:ff:ff
inet 172.2.1.0/32 scope global vxlan0
valid_lft forever preferred_lft forever
inet6 fe80::e839:22ff:fe52:ca06/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
Note: The MTU for vxlan0 is 50 bytes less than for regular interfaces, this is to account for the extra header added by vxlan.
Dissecting the command we just entered, we create an interface vxlan0 of type vxlan. Similar to VLAN, it is possible to tag VXLAN with an ID that allows us to have more than 1 VXLAN overlay setup over the same management network. The local address is the address that our device has identifies itself on the interface. For dstport, I have chosen 4789, which is the number assigned for vxlan communication by IANA. But Linux implementation came before this was specified and uses 8472 by default. This is still the default value to maintain backward compatibility. Similarly nolearning is to disable the learning feature as we will be doing manual management, and finally we select the local interface through which we want the communication to happen through. This is the management network interface.
Funfact: You can let the Kernel provide you with a unique name. Instead of
vxlan0you set the name asvxlan%d, The kernel will fill out the%dpart with an id that isn't currently occupied.
A point to note is that we have specified the IP of the interface to be /32. This is because Linux Kernel will automatically add routes to the routing table otherwise which will mess up our manual routes.
We can now also fill in our diagram,
Connecting vxlan
Until now the steps are largely similar to what we have done in the past. Create an interface, add IP, set the interface up, and maybe add routes then start using them. However, before adding routes, we have to populate the arp and fdb tables. These used to be populated by the Kernel before, but we are doing things manually. Also this step must be done before adding routes, as otherwise the Kernel will attempt to fill out these tables which it won't be able to since we haven't setup the necessary infrastructure.
To quote calico on the use of arp and fdb tables,
ARP/NDP entries and FDB entries are confusingly similar(!) Both are MAC/IP tuples, but they mean very different things. ARP/NDP entries tell the kernel what MAC address to use for the inner ethernet frame inside the VXLAN packet. FDB entries tell the kernel what IP address to use for the outer IP header, given a particular inner MAC. So, ARP maps IP->(inner)MAC; FDB maps (inner)MAC->(outer)IP.
source: Calico(github)
Adding to arp table
We use our trusty iproute2 tool to add IP neighbors, and fill in the ARP table for our overlay network.
fedora@network-1:~$ sudo ip neigh add 172.2.1.0 lladdr ea:39:22:52:ca:06 nud permanent dev vxlan0
fedora@network-1:~$ sudo ip neigh show
192.168.1.213 dev enp1s0 lladdr 52:54:00:46:f0:6a STALE
172.2.1.0 dev vxlan0 lladdr ea:39:22:52:ca:06 PERMANENT
192.168.1.1 dev enp1s0 lladdr 52:54:00:75:f0:ad REACHABLE
fedora@network-2:~$ sudo ip neigh add 172.2.0.0 lladdr d6:d4:f0:7b:b4:17 nud permanent dev vxlan0
fedora@network-2:~$ sudo ip neigh show
192.168.2.1 dev enp1s0 lladdr 52:54:00:81:ec:c9 REACHABLE
192.168.2.216 dev enp1s0 lladdr 52:54:00:9d:9b:c1 STALE
172.2.0.0 dev vxlan0 lladdr d6:d4:f0:7b:b4:17 PERMANENT
Note: You can use the diagram above if you ever get confused on which mac address belongs to which device and interface.
Adding to fdb table
To add an entry into fdb table we will need to use bridge command, which is also a part of iproute2 utility.
fedora@network-1:~$ sudo bridge fdb add ea:39:22:52:ca:06 dev vxlan0 dst 192.168.2.142
fedora@network-1:~$ sudo bridge fdb show dev vxlan0
ea:39:22:52:ca:06 dst 192.168.2.142 self permanent
fedora@network-2:~$ sudo bridge fdb add d6:d4:f0:7b:b4:17 dev vxlan0 dst 192.168.1.138
fedora@network-2:~$ sudo bridge fdb show dev vxlan0
d6:d4:f0:7b:b4:17 dst 192.168.1.138 self permanent
Adding to route table
fedora@network-1:~$ sudo ip r add 172.2.1.0/24 via 172.2.1.0 dev vxlan0 onlink
fedora@network-1:~$ ip r
default via 192.168.1.1 dev enp1s0 proto dhcp src 192.168.1.138 metric 100
172.2.1.0/24 via 172.2.1.0 dev vxlan0 onlink
192.168.1.0/24 dev enp1s0 proto kernel scope link src 192.168.1.138 metric 100
192.168.2.0/24 via 192.168.1.213 dev enp1s0 src 192.168.1.138
fedora@network-2:~$ sudo ip r add 172.2.0.0/24 via 172.2.0.0 dev vxlan0 onlink
fedora@network-2:~$ ip r
default via 192.168.2.1 dev enp1s0 proto dhcp src 192.168.2.142 metric 100
172.2.0.0/24 via 172.2.0.0 dev vxlan0 onlink
192.168.1.0/24 via 192.168.2.216 dev enp1s0 src 192.168.2.142
192.168.2.0/24 dev enp1s0 proto kernel scope link src 192.168.2.142 metric 100
Again, the command is mostly similar with the difference that it now also has onlink. Generally, Linux Kernel verifies the route you have added and does a few checks when you add route, which in our case will fail. onlink tells the Kernel to skip these tests and trust that you know what you are doing. Both flannel and calico setup the routes in a similar way.
Testing setup
For testing network connectivity we will be using ping,
fedora@network-1:~$ ping 172.2.1.0 -c3
PING 172.2.1.0 (172.2.1.0) 56(84) bytes of data.
64 bytes from 172.2.1.0: icmp_seq=1 ttl=64 time=0.817 ms
64 bytes from 172.2.1.0: icmp_seq=2 ttl=64 time=0.637 ms
64 bytes from 172.2.1.0: icmp_seq=3 ttl=64 time=0.671 ms
--- 172.2.1.0 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2080ms
rtt min/avg/max/mdev = 0.637/0.708/0.817/0.078 ms
fedora@network-2:~$ ping 172.2.0.0 -c3
PING 172.2.0.0 (172.2.0.0) 56(84) bytes of data.
64 bytes from 172.2.0.0: icmp_seq=1 ttl=64 time=0.811 ms
64 bytes from 172.2.0.0: icmp_seq=2 ttl=64 time=0.630 ms
64 bytes from 172.2.0.0: icmp_seq=3 ttl=64 time=0.754 ms
--- 172.2.0.0 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2059ms
rtt min/avg/max/mdev = 0.630/0.731/0.811/0.075 ms
Adding containers
To prove that our network is indeed cluster ready, I will be running my own "containers". Containers in this case are a network isolation domain achieved using network namespacing. I won't be diving into details as I have already highlighted them in past posts.
In short, we will add a bridge network on both hosts. The pods will then be attached to the bridge using veth pairs as,
fedora@network-1:~$ sudo ip netns add pod1
fedora@network-1:~$ sudo ip netns exec pod1 ./echo-server &
fedora@network-1:~$ sudo ip link add br0 type bridge
fedora@network-1:~$ sudo ip link veth0 type veth peer name vceth0
fedora@network-1:~$ sudo ip link set vceth0 netns pod1
fedora@network-1:~$ sudo ip link set veth0 master bridge
fedora@network-1:~$ sudo ip a add 172.2.0.1/24 dev br0
fedora@network-1:~$ sudo ip link set br0 up
fedora@network-1:~$ sudo ip link set veth0 up
fedora@network-1:~$ sudo ip netns exec pod1 ip link set lo up
fedora@network-1:~$ sudo ip netns exec pod1 ip a add 172.2.0.2/24 dev vceth0
fedora@network-1:~$ sudo ip netns exec pod1 ip link set vceth0 up
fedora@network-1:~$ sudo ip netns exec pod1 ip r add default via 172.2.0.1 dev vceth0 src 172.2.0.2
fedora@network-1:~$ sudo ip netns exec pod1 ip r
default via 172.2.0.1 dev mvlan0 src 172.2.0.2
172.2.0.0/24 dev mvlan0 proto kernel scope link src 172.2.0.1
fedora@network-1:~$ sudo ip netns add pod2
fedora@network-1:~$ sudo ip netns exec pod2 ./echo-server &
fedora@network-1:~$ sudo ip link add br0 type bridge
fedora@network-1:~$ sudo ip link veth0 type veth peer name vceth0
fedora@network-1:~$ sudo ip link set vceth0 netns pod1
fedora@network-1:~$ sudo ip link set veth0 master bridge
fedora@network-1:~$ sudo ip a add 172.2.1.1/24 dev br0
fedora@network-1:~$ sudo ip link set br0 up
fedora@network-1:~$ sudo ip link set veth0 up
fedora@network-1:~$ sudo ip netns exec pod1 ip link set lo up
fedora@network-1:~$ sudo ip netns exec pod1 ip a add 172.2.1.2/24 dev vceth0
fedora@network-1:~$ sudo ip netns exec pod1 ip link set vceth0 up
fedora@network-1:~$ sudo ip netns exec pod1 ip r add default via 172.2.1.1 dev vceth0 src 172.2.1.2
fedora@network-1:~$ sudo ip netns exec pod1 ip r
default via 172.2.1.1 dev mvlan0 src 172.2.1.2
172.2.1.0/24 dev mvlan0 proto kernel scope link src 172.2.1.2
Testing Connectivity
Now, that we have the pods running we verify the rules laid out to us in CNI specification.
fedora@network-1:~$ ping 172.2.1.2 -c3
PING 172.2.1.2 (172.2.1.2) 56(84) bytes of data.
64 bytes from 172.2.1.2: icmp_seq=1 ttl=63 time=0.942 ms
64 bytes from 172.2.1.2: icmp_seq=2 ttl=63 time=0.916 ms
64 bytes from 172.2.1.2: icmp_seq=3 ttl=63 time=0.602 ms
--- 172.2.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 0.602/0.820/0.942/0.154 ms
fedora@network-1:~$ sudo ip netns exec pod1 ping 172.2.1.2 -c3
PING 172.2.1.2 (172.2.1.2) 56(84) bytes of data.
64 bytes from 172.2.1.2: icmp_seq=1 ttl=62 time=0.675 ms
64 bytes from 172.2.1.2: icmp_seq=2 ttl=62 time=0.594 ms
64 bytes from 172.2.1.2: icmp_seq=3 ttl=62 time=0.682 ms
--- 172.2.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2043ms
rtt min/avg/max/mdev = 0.594/0.650/0.682/0.039 ms
fedora@network-1:~$
fedora@network-1:~$ curl -s 172.2.1.2:8000/echo | jq
{
"header": {
"Accept": [
"*/*"
],
"User-Agent": [
"curl/8.6.0"
]
},
"body": "Echo response"
}
fedora@network-1:~$ sudo ip netns exec pod1 curl -s 172.2.1.2:8000/echo | jq
{
"header": {
"Accept": [
"*/*"
],
"User-Agent": [
"curl/8.6.0"
]
},
"body": "Echo response"
}
As you can see we are now able to reach the pods from nodes in different networks and also have pod-to-pod communication without any NAT, fulfilling all the requirements for a CNI.
With this, we have largely accomplished what we set out to do, Creating our very own container networking system. While we are still missing out on a lot of things, CNI architecture diagrams should now start to make a lot of sense. My goal with this series was to understand how CNI really work under the hood, and I believe we have touched on most of the major systems already. Any addition to this series I now make will mostly be looking at various systems in isolation.
Subscribe to my newsletter
Read articles from Ranjan Ojha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by