PageRank using mapreduce on hadoop
 yugal kishore
yugal kishoreThis is a guide to making page-rank project using hadoop for data analysis, you can also use this as a cloud computing project
To see how to install hadoop you can refer Code With Arjun’s guide:
https://codewitharjun.medium.com/install-hadoop-on-ubuntu-operating-system-6e0ca4ef9689
After successfully installing hadoop on ubuntu or any other system, depending on how well you have configured hadoop, you can either follow this guide completely(I was not able to properly configure hadoop, so everytime I run hadoop, I use the following commands) or skip to Step 2. I have installed hadoop on ubuntu, so incase you are running hadoop on windows or mac-os a few commands will be slighty different, if you are familiar with using your command prompt or bash shell, they you will be able to easily convert the commands in this guide to your system’s respective commands
So let’s start this guide
Step1. Run this command in your terminal to travel hadoop directory
cd hadoop-3.2.3/etc/hadoop
or travel to where your hadoop installation was done, next execute
ssh localhost
now run these two commands together and press y and press enter to accept new key creation
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
the new key will be outputed once on the terminal if the key creation was successfull, next run this command
chmod 0600 ~/.ssh/authorized_keys
then run this command
hadoop-3.2.3/bin/hdfs namenode -format
wait for some time, if prompted to grant permission, press y and press enter, after successful execution, run this command
export PDSH_RCMD_TYPE=ssh
Step2. Now start hadoop on your system, if you have properly configured hadoop, you can start this guide from here:
start-all.sh
this will take some time, but if everything goes well, then open
localhost:9870
on your browser, and you will see hadoop home page
now come back to your terminal and type the following command
cd
this command brings you back to your home directory, now make a folder in a location of your choice, or the home directory itself if you are a beginner and clone this github repo
Step 3. Make sure an ubuntu git installation exists
sudo apt install git
now to check if git is successfully installed run this command
git --version
Step 4. Now run the command to clone the repo
https://github.com/yugal-kishore143/pagerank.git
now travel back to the home directory
cd
and travel to the project folder(pagerank), you can either run this command, or just travel to where the pagerank folder exists
cd pagerank
Step 5. Compile and Build the maven project
mvn clean package
this will create a jar file
in case you get errors, then copy the pom.xml code and upload to chat-gpt and ask it to help you, or you can run “mvn clean” once and then re-run
“mvn clean package”
I prefer to keep input files in the project directory itself so as to remember where it is kept, i have created two input files, “input1.txt” and “input2.txt” in the repo.
Step 6. Create a folder in hadoop file system
If it already exists make sure you remove it using the following command(s)(this command removes even output folder, you can use this command in case you want to change your input and re-run the execution of the pagerank program)
hadoop fs -rm -r /output
hadoop fs -rm -r /input
now create the input folder in hadoop file system
hadoop fs -mkdir /input
Step 7. Attach your input file
make sure you are in your project folder(pagerank)
hadoop fs -put input1.txt /input
or attach the second input file if you want a longer, more complex input
hadoop fs -put input2.txt /input
in case you already attached “input1.txt” but wanted to attach “input2.txt” you neex to remove the first file you attached and then attach your desired file, as if two input files exist, the program outputs a weird output to remove the file you attached, you can run “hadoop fs -rm -r -f /input/input1.txt” or “hadoop fs -rm -r -f /input/input2.txt” depending on the file you want to remove, and now just attach the file you want, by running either of the two commands in Step 7.
now to check if the file was properly attached go to your browse, make sure you are in localhost:9870
click on “Utilities” as shown in the picture below and then click on “Browse the file system”
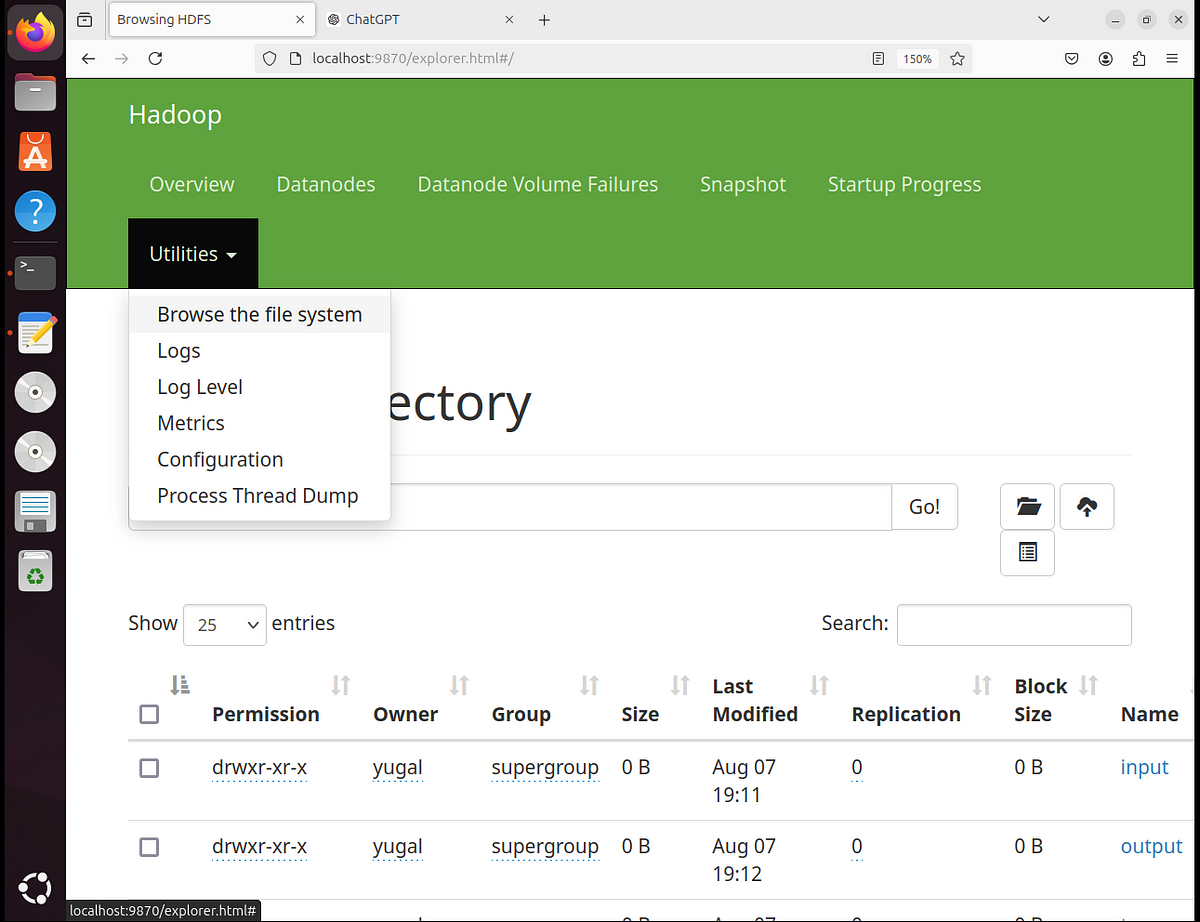
as seen in the picture above, you will get list of folder, in the right you can see input and output in blue, output folder will be automatically created after you execute the main java command to run the program, to see if your input file is successfully attached, click on input folder and if your input file is attached, you can see its name in the right, my file’s name was plaintext.txt which I have underlined to show, now click on it, then click on “head the file(first 32K)” you will be able to see the input file contents if the file was uploaded properly
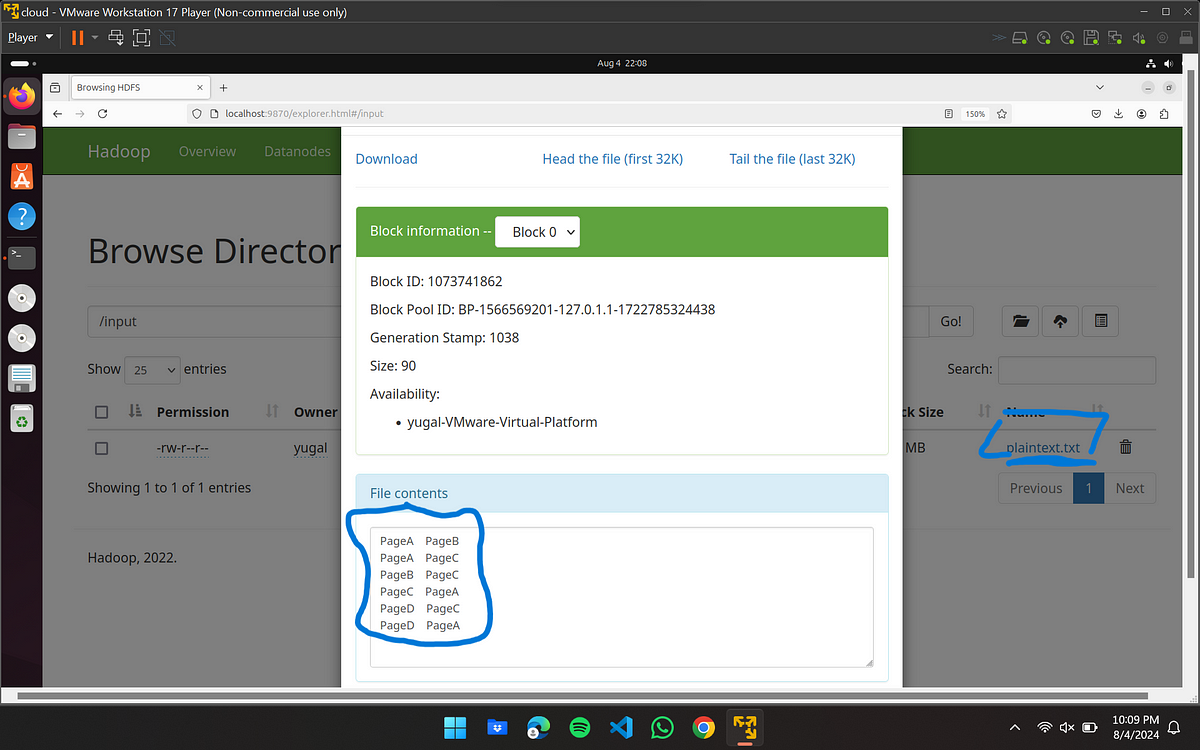
input file successfully uploaded and seen on hadoop interface
Step 7(b). (Ignore if no issues)
In case your input file was not successfully uploaded it could be due to no datanodes present, this could be due to your hadoop configuration files now being properly set up, to make sure you have a datanode running, click on “datanodes” and make sure a data node is present, if no data node is present, then something is missing in your configuration files(mostly hdfs-site.xml)
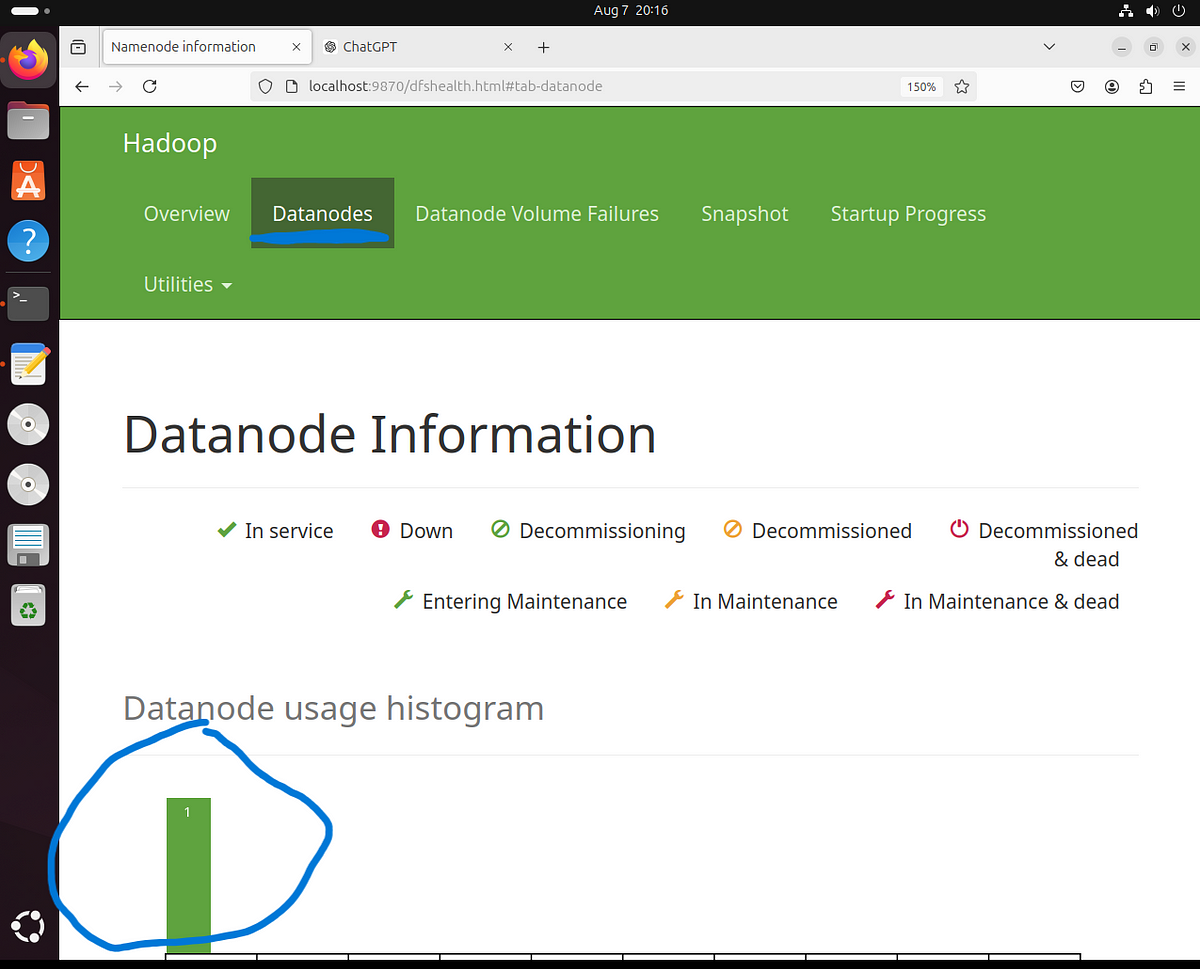
now click on “Utilities” again and press “Browse the file system”, now
Step 8. Come back to the terminal and run the following command to execute java program
hadoop jar target/pagerank-1.0-SNAPSHOT.jar com.example.pagerank.PageRank /input /output
wait for sometime, depending on your input file execute time can go longer, in case you want to check the status of execution, you can right click on the link generated in your terminal and click on open-link, now view the execution logs on this website
in the terminal, after successful execution, you can either see your output on the hadoop interface in the browser like this(
type “\output” to travel to output folder
click on the file named “part-r-00000”
click on “Head the file (first 32K)”
your output file will be displayed in the box called file contents below)
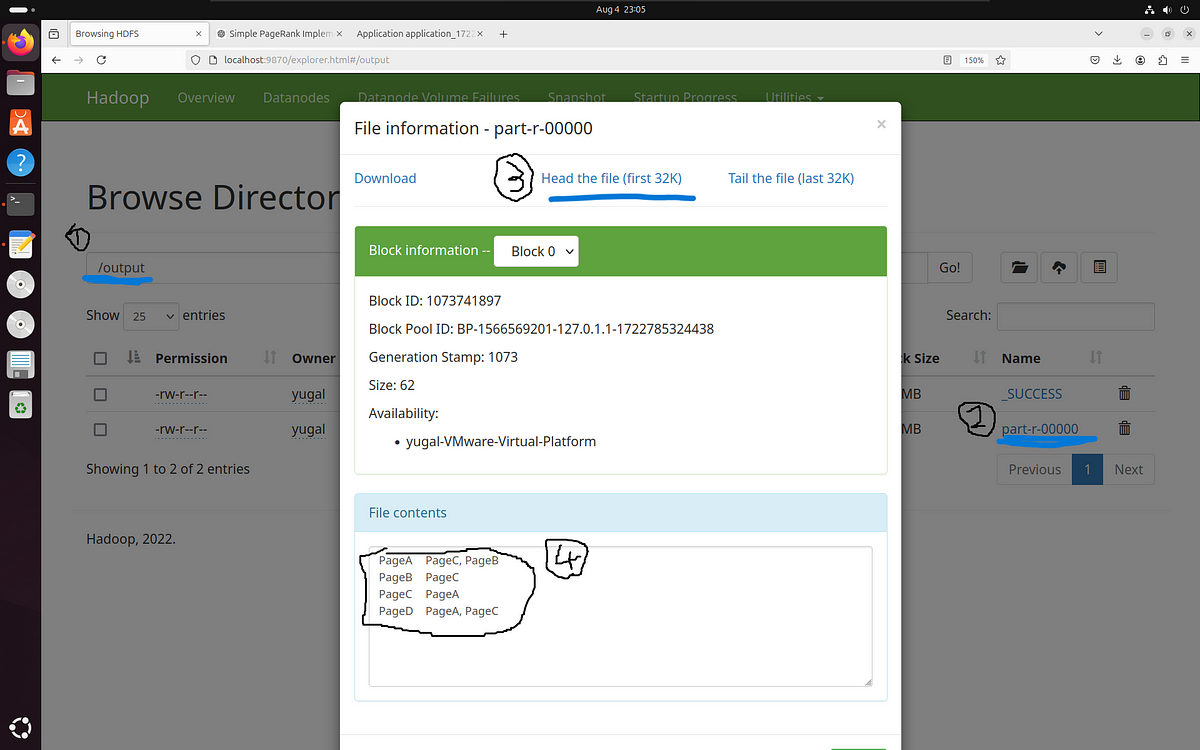
reference for accessing the output file on the hadoop interface
or you can see the output file contents by running the following command in your terminal
hadoop fs -cat /output/part-r-00000
Congratulations! You have now successfully executed your page rank program.
You can also follow these two youtube videos for execution from Step 5 onwards
https://www.youtube.com/watch?v=az5AfuJuF4U
https://www.youtube.com/watch?v=WrEfqozkpQ8
If you want to re-run with different inputs you can go back to Step 6 and continue
Note: In case you are getting output same as your input file then make sure that in your input file the data is separated by a single tab space between a key and value(the two columns) and not normal spaces
Subscribe to my newsletter
Read articles from yugal kishore directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by