Exploring LlamaIndex Workflows: A Step-by-Step Guide to Building a RAG System with Azure AI Search and Azure OpenAI
 Farzad Sunavala
Farzad Sunavala
LlamaIndex has introduced a new way to orchestrate complex AI applications through workflows, an event-driven framework that simplifies the creation of tasks like retrieval-augmented generation (RAG) systems. This blog will walk you through the basics of LlamaIndex workflows by diving into a Jupyter notebook that demonstrates how to set up and run a RAG workflow with reranking using GPT-4o, Azure AI Search, and Azure OpenAI.

What Are Workflows in LlamaIndex?
Workflows in LlamaIndex are designed to be asynchronous and event-driven, meaning each step in the workflow runs only when the appropriate event is triggered. This allows you to create sophisticated, multi-step processes while keeping your codebase clean and easy to manage.
For example, you can use workflows to build a RAG system where you first ingest documents, then retrieve relevant information based on a query, rerank the results using a language model, and finally synthesize a coherent response. Each of these tasks is handled by different steps within the workflow.
Setting Up the Environment
Before diving into the code, you’ll need to install several libraries. These include LlamaIndex, Azure services for embeddings and LLMs, and additional packages for observability and async handling. Here’s the setup:
!pip install azure-identity
!pip install azure-search-documents==11.4.0
!pip install -U llama-index
!pip install llama-index-embeddings-azure-openai
!pip install llama-index-llms-azure-openai
!pip install llama-index-vector-stores-azureaisearch
!pip install nest-asyncio
!pip install python-dotenv
!pip install "llama-index-core>=0.10.43" "openinference-instrumentation-llama-index>=2.2.2" "opentelemetry-proto>=1.12.0" opentelemetry-exporter-otlp opentelemetry-sdk
Initializing Azure Services
You’ll begin by setting up Azure OpenAI services for both the language model and embeddings. The following code snippet demonstrates how to initialize these services:
import os
from dotenv import load_dotenv
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
from azure.search.documents.indexes import SearchIndexClient
from llama_index.core import (
StorageContext,
SimpleDirectoryReader,
VectorStoreIndex,
)
from llama_index.embeddings.azure_openai import AzureOpenAIEmbedding
from llama_index.llms.azure_openai import AzureOpenAI
from llama_index.vector_stores.azureaisearch import (
AzureAISearchVectorStore,
IndexManagement,
)
from llama_index.core.response_synthesizers import CompactAndRefine
from llama_index.core.postprocessor.llm_rerank import LLMRerank
from llama_index.core.workflow.context import Context
from llama_index.core.workflow.decorators import step
from llama_index.core.workflow.events import Event, StartEvent, StopEvent
from llama_index.core.workflow.workflow import Workflow
from llama_index.core.schema import MetadataMode
from llama_index.core.response.notebook_utils import display_response
from llama_index.core.vector_stores.types import VectorStoreQueryMode
# Load environment variables
load_dotenv()
# Environment Variables
AZURE_OPENAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
AZURE_OPENAI_API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME = os.getenv(
"AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME"
) # I'm using GPT-3.5-turbo
AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME = os.getenv(
"AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME"
) # I'm using text-embedding-ada-002
SEARCH_SERVICE_ENDPOINT = os.getenv("AZURE_SEARCH_SERVICE_ENDPOINT")
SEARCH_SERVICE_API_KEY = os.getenv("AZURE_SEARCH_ADMIN_KEY")
INDEX_NAME = "llamindex-workflow-demo"
PHOENIX_API_KEY = os.getenv("PHOENIX_API_KEY")
# Initialize Azure OpenAI and embedding models
llm = AzureOpenAI(
model=AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME,
deployment_name=AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME,
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version="2024-02-01",
)
embed_model = AzureOpenAIEmbedding(
model=AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME,
deployment_name=AZURE_OPENAI_EMBEDDING_DEPLOYED_MODEL_NAME,
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version="2024-02-01",
)
# Initialize search clients
credential = AzureKeyCredential(SEARCH_SERVICE_API_KEY)
index_client = SearchIndexClient(
endpoint=SEARCH_SERVICE_ENDPOINT, credential=credential
)
search_client = SearchClient(
endpoint=SEARCH_SERVICE_ENDPOINT, index_name=INDEX_NAME, credential=credential
)
Key Components of a Workflow
Events
Events are objects that are passed between workflow steps. They can carry data and signal other steps to take action. In the provided notebook, two custom events are defined:
RetrieverEvent: This event carries the nodes retrieved from the vector store.
RerankEvent: This event carries the nodes after they have been reranked.
class RetrieverEvent(Event):
"""Result of running retrieval"""
nodes: list[NodeWithScore]
class RerankEvent(Event):
"""Result of running reranking on retrieved nodes"""
nodes: list[NodeWithScore]
Steps
Ingest Step
The Ingest Step ingests documents from a specified directory and creates a vector index.
@step(pass_context=True)
async def ingest(self, ctx: Context, ev: StartEvent) -> StopEvent | None:
documents = SimpleDirectoryReader(dirname).load_data()
storage_context = StorageContext.from_defaults(vector_store=vector_store)
ctx.data["index"] = VectorStoreIndex.from_documents(...)
return StopEvent(result=f"Indexed {len(documents)} documents.")
Retrieve Step
The Retrieve Step retrieves relevant nodes (aka chunks) from the indexed documents based on a query.
@step(pass_context=True)
async def retrieve(self, ctx: Context, ev: StartEvent) -> RetrieverEvent | None:
retriever = index.as_retriever(vector_store_query_mode=VectorStoreQueryMode.HYBRID, similarity_top_k=5)
nodes = retriever.retrieve(query)
return RetrieverEvent(nodes=nodes)
Rerank Step
The Rerank Step reranks the retrieved nodes using a language model. Note, this is step is optional but highly recommended. In this example, I'm using a LLM (GPT-4o) to rerank but you can use rerankers such as Azure AI Search's Semantic Ranker. See Azure AI Search: Outperforming vector search with hybrid retrieval and ranking capabilities - Microsoft Community Hub
Synthesize Step
The Synthesize Step synthesizes a final response using the reranked nodes.
@step(pass_context=True)
async def synthesize(self, ctx: Context, ev: RerankEvent) -> StopEvent:
summarizer = CompactAndRefine(llm=llm, streaming=True, verbose=True)
response = await summarizer.asynthesize(query, nodes=ev.nodes)
return StopEvent(result=response)
Workflow Execution
Once all the steps are defined, you can execute the workflow by creating an instance of the workflow class and calling its run method. Here’s how to run the workflow for document ingestion and querying:
class RAGWorkflow(Workflow):
@step(pass_context=True)
async def ingest(self, ctx: Context, ev: StartEvent) -> StopEvent | None:
"""Entry point to ingest a document, triggered by a StartEvent with `dirname`."""
dirname = ev.get("dirname")
if not dirname:
return None
documents = SimpleDirectoryReader(dirname).load_data()
storage_context = StorageContext.from_defaults(vector_store=vector_store)
ctx.data["index"] = VectorStoreIndex.from_documents(
documents=documents,
embed_model=embed_model,
storage_context=storage_context,
)
return StopEvent(result=f"Indexed {len(documents)} documents.")
@step(pass_context=True)
async def retrieve(self, ctx: Context, ev: StartEvent) -> RetrieverEvent | None:
"Entry point for RAG, triggered by a StartEvent with `query`."
query = ev.get("query")
if not query:
return None
print(f"Query the database with: {query}")
# store the query in the global context
ctx.data["query"] = query
# get the index from the global context
index = ctx.data.get("index")
if index is None:
print("Index is empty, load some documents before querying!")
return None
retriever = index.as_retriever(vector_store_query_mode=VectorStoreQueryMode.HYBRID, similarity_top_k=5)
nodes = retriever.retrieve(query)
print(f"Retrieved {len(nodes)} nodes.")
return RetrieverEvent(nodes=nodes)
@step(pass_context=True)
async def rerank(self, ctx: Context, ev: RetrieverEvent) -> RerankEvent:
# Rerank the nodes
ranker = LLMRerank(choice_batch_size=5, top_n=3, llm=llm)
print(ctx.data.get("query"), flush=True)
new_nodes = ranker.postprocess_nodes(ev.nodes, query_str=ctx.data.get("query"))
print(f"Reranked nodes to {len(new_nodes)}")
return RerankEvent(nodes=new_nodes)
@step(pass_context=True)
async def synthesize(self, ctx: Context, ev: RerankEvent) -> StopEvent:
"""Return a streaming response using reranked nodes."""
summarizer = CompactAndRefine(llm=llm, streaming=True, verbose=True)
query = ctx.data.get("query")
response = await summarizer.asynthesize(query, nodes=ev.nodes)
return StopEvent(result=response)
# Initialize Workflow
w = RAGWorkflow()
# Ingest the document (example with a specific file 'data/txt/state_of_the_union.txt')
await w.run(dirname="data/txt")
# Run a query
result = await w.run(query="does the president have a plan for covid-19")
# Function to display custom response
def display_custom_response(response):
print("=== GPT-4o-Generated Response ===")
display_response(response)
print("\n=== Details of Source Documents ===\n")
for node in response.source_nodes:
print(node.get_content(metadata_mode=MetadataMode.LLM))
print("-" * 40 + "\n")
# Await and collect the full response
final_response = ""
async for chunk in result.async_response_gen():
final_response += chunk
# Create a mock response object for display
class MockResponse:
def __init__(self, response, source_nodes):
self.response = response
self.source_nodes = source_nodes
mock_response = MockResponse(final_response, result.source_nodes)
# Display the response using the custom display function
display_custom_response(mock_response)
Final Response: Yes, the president has a comprehensive plan for COVID-19. The plan includes staying protected with vaccines and treatments, preparing for new variants, ending the shutdown of schools and businesses, and continuing to vaccinate the world. The plan emphasizes the importance of vaccines, treatments, and testing, as well as the need for readiness against new variants. It also focuses on reopening schools and businesses safely and providing global vaccine support.
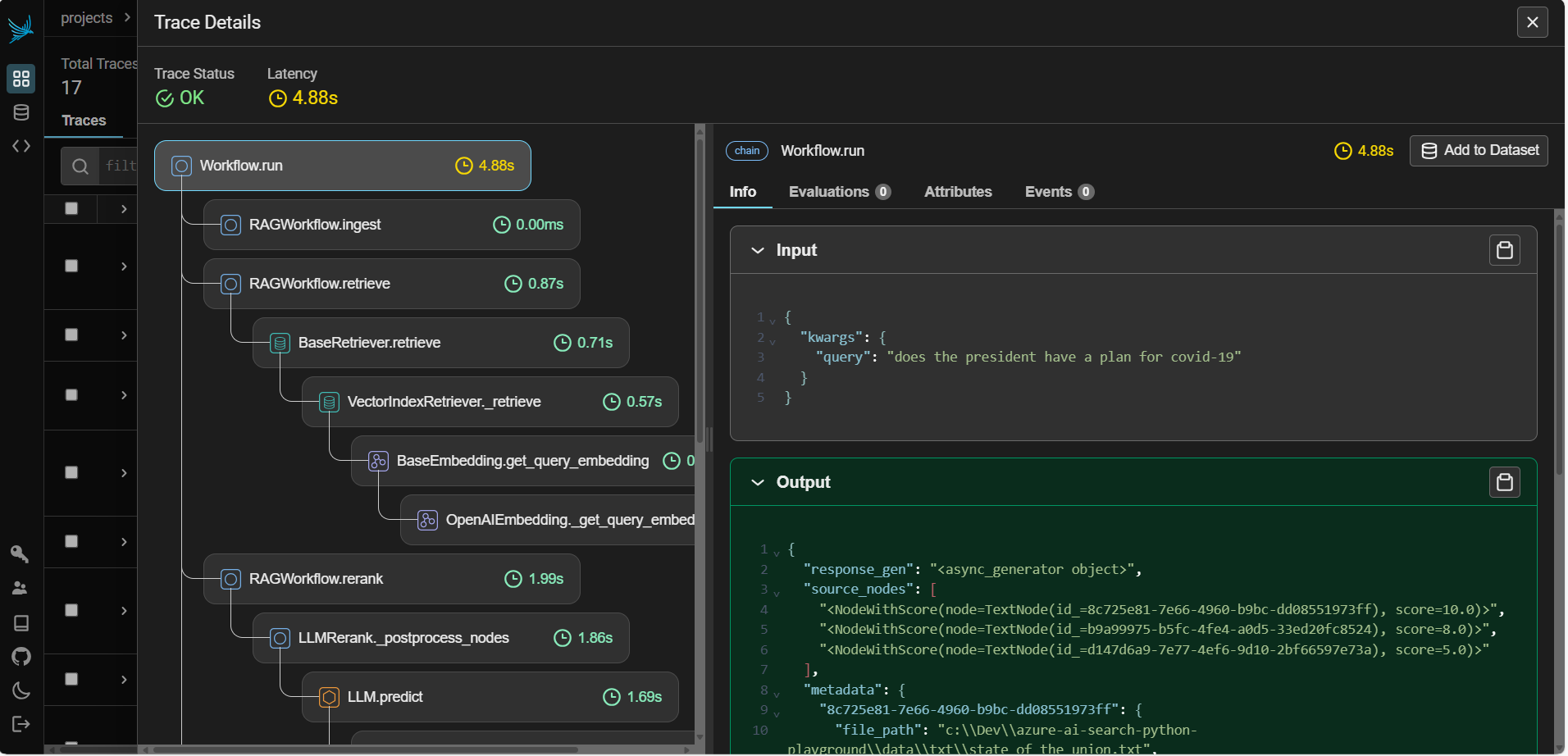
You can observe your query traces in Arize Phoenix through the LlamaIndex orchestrator. It's an amazing user interface that is great for production monitoring or simple debugging.
Conclusion
LlamaIndex workflows offer a powerful, event-driven framework to build complex AI applications like RAG systems. By chaining together custom events and steps, you can create workflows that are both flexible and scalable. This notebook serves as a practical guide to getting started with LlamaIndex workflows, enabling you to build and manage AI applications more efficiently. I look forward to building more examples using workflows.
Full Notebook Here: azure-ai-search-python-playground/azure-ai-search-llamaindex-workflows.ipynb at main · farzad528/azure-ai-search-python-playground (github.com)
Subscribe to my newsletter
Read articles from Farzad Sunavala directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Farzad Sunavala
Farzad Sunavala
I am a Principal Product Manager at Microsoft, leading RAG and Vector Database capabilities in Azure AI Search. My passion lies in Information Retrieval, Generative AI, and everything in between—from RAG and Embedding Models to LLMs and SLMs. Follow my journey for a deep dive into the coolest AI/ML innovations, where I demystify complex concepts and share the latest breakthroughs. Whether you're here to geek out on technology or find practical AI solutions, you've found your tribe.