Enhanced Insight into Disaster Recovery Solutions on AWS
 Farrukh Khalid
Farrukh Khalid
In today's digital age, it's more important than ever to protect our data. Just imagine waking up one day to find that your business has come to a standstill because all your important data is gone due to an unexpected disaster. It sounds scary, right? Well, this is something that happens to many companies. That's why having a good Disaster Recovery (DR) strategy is very crucial. AWS offers many tools and services to help businesses protect themselves against such disasters. This article will guide you through understanding and setting up effective DR solutions on AWS, ensuring that your business's critical data is safe and sound even when things go south.
Decoding RPO and RTO: The Cornerstones of DR Strategies
At the core of any effective DR strategy lies two critical metrics: Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
RPO quantifies the maximum acceptable amount of data loss measured in time. For instance, an RPO of two hours implies that, in the event of a disaster, the system must recover up to the state it was two hours before the incident. This measure determines the frequency of backups required to meet critical business needs.
Conversely, RTO measures the duration required to restore systems post-disaster. For instance, An RTO of four hours indicates the amount of time it will take to restore the applications to a production state after a disaster strikes.
Understanding both of these indicators is critical because they influence decisions about redundancy levels, backup frequency, and recovery methods for a robust DR plan.

AWS Services: Tailoring RPOs and RTOs to Business Needs
AWS offers a range of services to meet different RPO and RTO needs. These include synchronous replication for near-zero RPO and asynchronous replication for improved performance with slightly higher RPO.
Synchronous Replication: Achieves an RPO measured in milliseconds, ideal for applications demanding minimal data loss. However, it incurs higher costs due to the immediate confirmation requirement for data replication across systems.

Asynchronous Replication: Strikes a balance between performance and data loss tolerance, offering RPOs ranging from seconds to minutes. This method is suitable for applications where slight data loss is acceptable in exchange for improved performance.

Snapshots and Backups: Appropriate for scenarios with higher acceptable recovery point objectives (RPOs) (minutes to hours), involving periodic data backups stored across regions to enhance disaster recovery capabilities.

Scope of Impact in Events of Disaster
It's very crucial to understand the scope of the impact of various disaster events when designing a resilient architecture. AWS provides robust solutions to mitigate the risks associated with localized and regional disasters through Multi-AZ and Multi-Region strategies. Let's take a closer look at an expanded version of these strategies to help improve your disaster recovery planning.
Localized Disruptions:
Power outages, flooding, hardware failures, and network issues can typically affect a single data center or Availability Zone (AZ).
Regional Disruptions:
Large-scale natural disasters, major infrastructure failures, and regional network outages.
The impact can affect multiple data centers and Availability Zones within a single AWS Region.
Global Disruptions:
Catastrophic events impacting multiple regions, as well as widespread cyber-attacks, can potentially disrupt services across numerous AWS regions globally.
AWS Disaster Recovery Approaches
Multi-AZ approach for Local Redundancy
Each AWS Region is made up of several Availability Zones (AZs), with each AZ containing one or more data centers located in different geographic locations. This setup highly reduces the likelihood of a single event affecting more than one AZ. A Multi-AZ strategy is specifically created to handle disruptions within a specific region, ensuring that there is high availability and fault tolerance within a single AWS Region.
Benefits:
High availability within a single region.
Protection against localized disruptions such as power outages and flooding.
Lower latency due to the geographic proximity of AZs within the same region.
Implementation:
1. Compute Layer:
- Deploy Amazon EC2 instances across multiple AZs.
2. Storage Layer:
Use Amazon EBS volumes replicated across availability zones.
Store critical data in Amazon S3 with Multi-AZ replication.
3. Database Layer:
Configure Amazon RDS with Multi-AZ deployments.
Utilize DynamoDB with Multi-AZ replication.
4. Backup and Snapshot Management:
Enable AWS Backup to manage backups across availability zones.
Utilize Amazon EBS Snapshots and RDS Automated Backups to ensure data availability.
Multi-Region approach for Regional Protection
AWS offers various resources to support a multi-region approach for your workload. This strategy provides business assurance in the face of events that could impact multiple data centers across different locations. Implementing a multi-region strategy improves disaster recovery capabilities by safeguarding against regional disruptions.
Benefits:
Enhanced business continuity and disaster recovery.
Protection against regional disasters that affect multiple Availability Zones.
Increased fault tolerance and data redundancy across geographically dispersed regions.
Implementation:
1. Compute Layer:
- Deploy standby EC2 instances in a secondary region.
2. Storage Layer:
- Replicate S3 objects across regions using S3 Cross-Region Replication (CRR).
3. Database Layer:
Use Amazon RDS Cross-Region Read Replicas.
Implement DynamoDB Global Tables for multi-region replication.
Backup and Snapshot Management:
Configure AWS Backup for cross-region backups.
4. Monitoring and Management:
Utilize monitoring services like AWS CloudWatch and CloudTrail for monitoring and logging.
Use AWS Config to track resource configurations and changes across regions.
Implement AWS Lambda for custom automation and backup management tasks.
Crafting Disaster Recovery Strategies on AWS
DR strategies can be broadly categorized into two types active/passive and active/active. Each approach is designed to meet different business needs and has its unique characteristics, benefits, and use cases.

Active-Passive Strategy
An active-passive disaster recovery (DR) strategy involves having one active site that handles all the production workload while a passive (standby) site remains idle or runs minimal services. The passive site is activated only when the active site fails. This approach ensures that there is always a backup site ready to take over in case of a disaster.
Use Case:
Ideal for applications that require a backup site but can tolerate some downtime during the failover process. It is a cost-effective solution for disaster recovery where budget constraints are a consideration.

Active-Active Strategy
An active-active disaster recovery strategy involves running production workloads simultaneously across multiple active sites, typically in different regions. Both sites actively handle traffic and workloads, providing continuous availability and load balancing. This approach ensures that if one site fails, the other site(s) can immediately take over without any noticeable downtime.
Use Case
Essential for mission-critical applications where any downtime or data loss is unacceptable. Suitable for businesses that require the highest level of availability and are willing to invest in full redundancy across multiple sites.

AWS offers a range of DR strategies tailored to different levels of criticality and budgetary constraints that fall under the classifications of active/passive and active/active strategies. These strategies provide varying levels of cost, complexity, and recovery objectives, allowing businesses to choose the best fit for their needs.
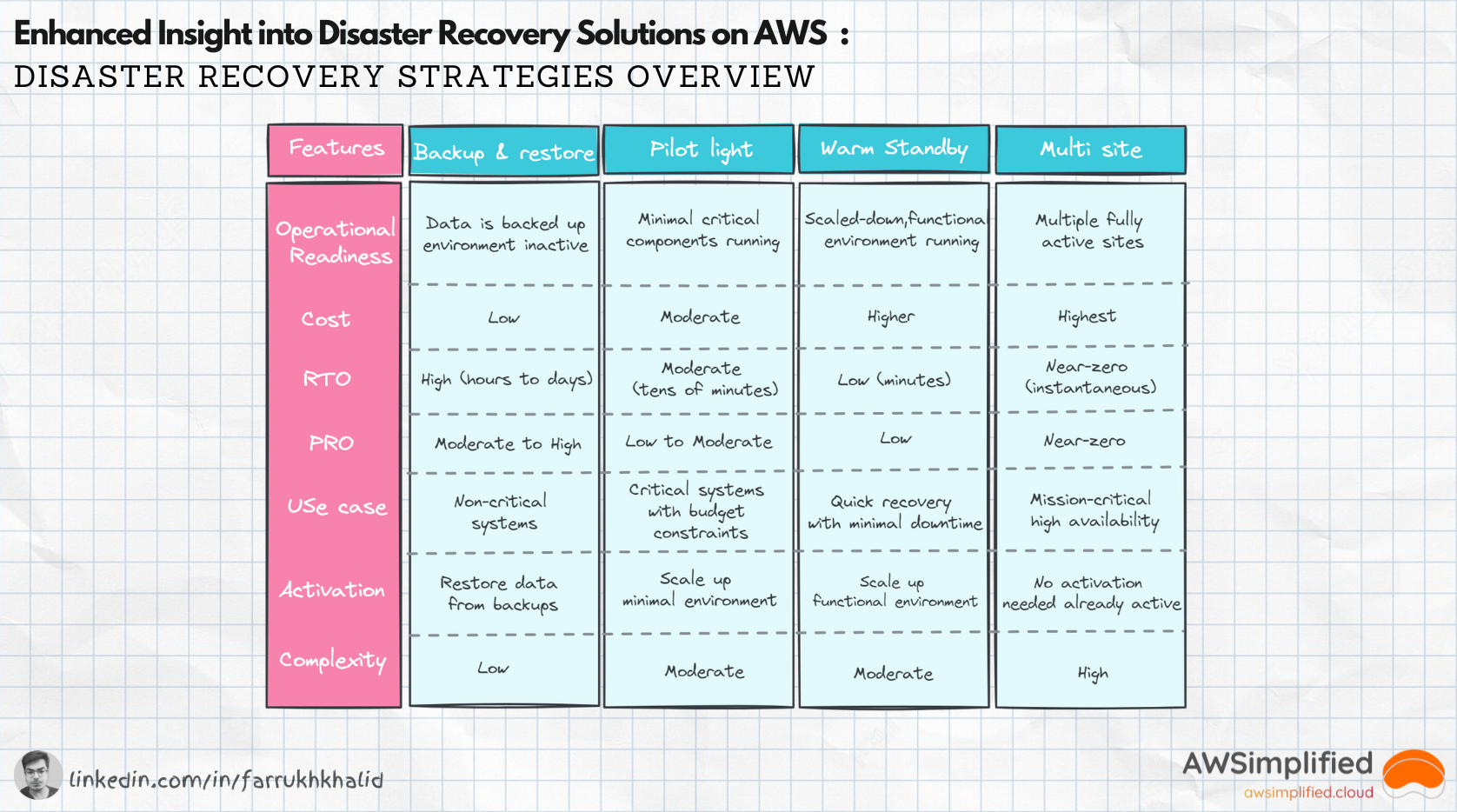
Backup and Restore: This disaster recovery strategy is the most cost-effective option and is suitable for non-critical systems where some degree of data loss and downtime is tolerable. The main focus is on storing regular backups of your data and configurations in a secure location. In a disaster, these backups can be restored to recover the system.
Key Features:
Cost: Low to minimal, as it primarily involves storage costs for backups.
Recovery Time Objective (RTO): High, since restoring backups can take considerable time.
Recovery Point Objective (RPO): Moderate to high, as there may be some data loss depending on the frequency of backups.
Use Case:
Ideal for applications that do not require immediate availability and can tolerate hours or even days of downtime during recovery.

Pilot Light: In a pilot light strategy, a minimal version of the critical parts of your application is always running in the cloud that can be rapidly scaled up in the event of a disaster. This approach offers a balance between cost and recovery time.
Key Features:
Cost: Moderate, as only essential services are running continuously.
RTO: Lower than backup and restore, as the core services are already operational.
RPO: Low to moderate, depending on how frequently the minimal environment is updated.
Use Case:
Suitable for critical applications that require faster recovery times but where budget constraints prevent a full standby solution.

Warm Standby: A warm standby strategy involves maintaining a scaled-down but fully functional version of your production environment. In the event of a disaster, this environment can be quickly scaled up to handle production load, ensuring faster recovery times.
Key Features:
Cost: Higher than pilot light, as more resources are continuously running.
RTO: Low, due to the already operational environment that can be scaled up quickly.
RPO: Low, with minimal data loss as the environment, is frequently synchronized with production.
Use Case:
Best for applications that require quick recovery with minimal downtime and can justify the higher cost due to the importance of the service.

Multi-Site: Multi-site strategy can have active-active or active-passive configuration based on your business needs, this strategy ensures very minimal RPO and RTO by running your application in multiple AWS regions. In an active-active setup, traffic is distributed across multiple regions, while in an active-passive setup, one region acts as a backup.
Key Features:
Cost: Highest, due to full redundancy and continuous operation across multiple regions.
RTO: Near-zero, as both sites are active and can take over immediately.
RPO: Near-zero, with real-time data synchronization between regions.
Use Case:
Multi-site strategy is beneficial for mission-critical applications, where any downtime or data loss is unacceptable but the high cost of full redundancy is justified.

Wrapping up, we've explored how disaster events can threaten your workload availability, but using AWS Cloud services can help mitigate or remove these threats. Understanding your workload and business requirements is essential for choosing the right DR strategy. AWS provides many tools to help businesses stay safe. By planning and formulating DR strategies ahead of time, we can safeguard our business and ensure smooth operation even during tough times. Preparing for disasters is about maintaining the strength and reliability of our operations and workload. As technology evolves, so do the challenges we encounter. But with AWS, we're well-equipped to handle whatever comes our way.
Subscribe to my newsletter
Read articles from Farrukh Khalid directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by