Building a Robust Market Data Pipeline with Upstox API in Python Using `asyncio` and InfluxDB
 Swaraj Singh
Swaraj SinghIntroduction
In the realm of algorithmic trading, real-time market data is crucial. It informs trading decisions and strategies, ensuring they are based on the most up-to-date information. In this article, I will discuss the data feed service I developed for the Upstox broker, designed to receive real-time trading data via websocket and store it in a database. The application is built with a focus on efficiency and reliability, utilizing asynchronous programming to manage multiple tasks concurrently.
Github repo: SsinghBh/TradeDataFeed (github.com)
Background and Context: The choice of Upstox as the broker for this project was a practical one. As an Upstox user, I found their platform and API documentation comprehensive, making it a suitable choice for building a real-time data feed service. The implementation leverages parts of the example code provided by Upstox on their GitHub and official documentation. These scripts, which include functionalities like setting up websocket connections and handling data with protobuf, served as a foundation upon which I built the application.
Architecture and Design
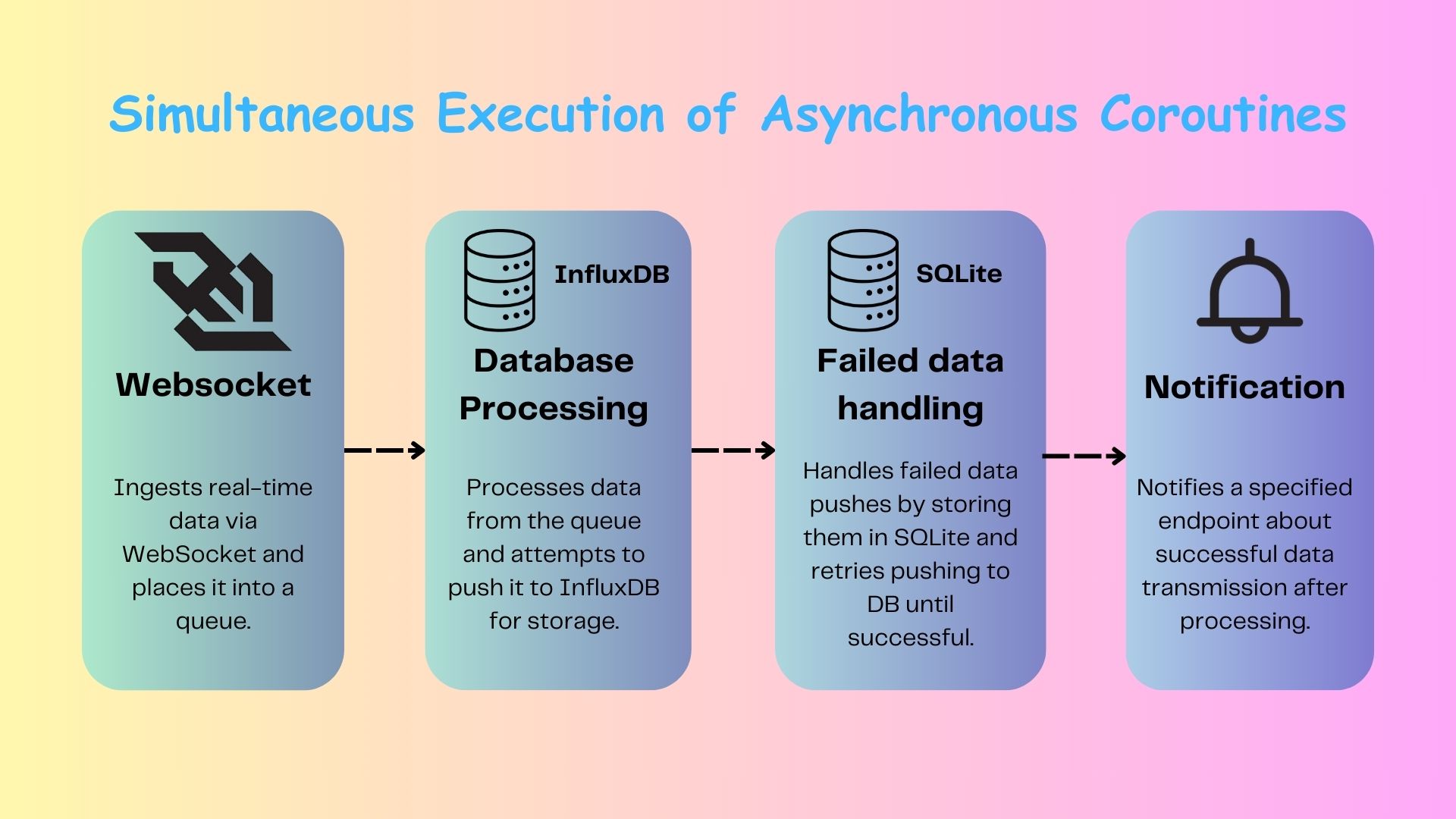
The architecture of the data feed service is structured around a series of asynchronous coroutines, each fulfilling a distinct role in the data processing pipeline. This setup ensures that data flows smoothly from reception to storage, even in the event of failures.
Data Ingestion via WebSocket: At the core of the system is a coroutine dedicated to establishing and maintaining a websocket connection with Upstox. This coroutine requests an access token—either provided directly or fetched via a configurable endpoint—and begins receiving market data. The received data is then placed into an asynchronous queue for further processing.
Data Processing and Storage: Another coroutine continuously monitors the queue, extracting data and preparing it for storage. The primary storage solution is InfluxDB, chosen for its efficiency in handling time-series data. If a push to InfluxDB fails, the data is temporarily stored in SQLite, an embedded database, ensuring no data is lost.
Backup Data Handling: A third coroutine periodically checks the SQLite database for any data that failed to push to InfluxDB. It retries these failed operations, ensuring eventual consistency and data integrity.
Notification System: The final coroutine is responsible for notifying a specified endpoint whenever new data is successfully ingested. This notification system, which is also configurable, can be used for alerting or triggering downstream processes.
Technology Choices
The decision to use InfluxDB as the primary database was driven by its suitability for time-series data and its ease of deployment within a Docker environment. SQLite (an embedded database) was selected as a secondary, fallback database due to its simplicity and reliability.
To streamline deployment, the entire application is containerized using Docker. This not only ensures consistency across different environments but also simplifies the setup process. The Docker setup includes a Docker Compose file, which can start both the data feed service and an InfluxDB container with a single command. This choice reflects a focus on ease of use and scalability.
Deployment and Configuration
The deployment process is straightforward using Docker. The application can be run alongside an existing InfluxDB instance or spin up a new InfluxDB container using Docker Compose. Configuration parameters, such as the database credentials and API endpoints, are passed as environment variables, providing flexibility and security.
Challenges and Solutions
Developing a real-time data processing system presents several challenges, particularly in handling high-frequency data and ensuring system resilience. Asynchronous programming was a natural choice for this project, allowing the application to manage multiple operations concurrently without blocking. This is crucial for maintaining low latency and ensuring that data is processed as soon as it arrives.
Another significant challenge was managing data integrity, especially in scenarios where the primary database (InfluxDB) might be temporarily unavailable. The implementation of a fallback mechanism using SQLite provides a robust solution, ensuring that data is not lost and can be synchronized with InfluxDB once the service is restored.
Conclusion
This real-time data pipeline provides a reliable solution for market data handling, combining real-time processing with fault tolerance. We look forward to expanding its capabilities and exploring new use cases.
Subscribe to my newsletter
Read articles from Swaraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by