Is it the model or the data that's low rank?
 RJ Honicky
RJ Honicky
I mentioned this little bit of analysis that I recently did during the Latent Space Paper Club, and got a lot of positive feedback, so I did a quick writeup.
The recently released Apple Intelligence Foundation Language Models paper has spark a lot of interest in their strategy for “quantization loss recovery,” in which the researchers quantized their models, and then trained a LoRA adapter using full precision weights with the purpose of recovering the quantization loss. If you’ve been reading my blog, you’ll know that researchers recently named this approach (or something very similar) Quantization Aware LoRA, or QA-LoRA.
Here are two papers that are close to what the Apple researchers seems to have done:
EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models
I also wonder if some of the efficiency gains we've seen with the "turbo" versions of GPT4 and Claude 3 Haiku might also be using similar techniques.
Apple’s 10 billion tokens
Apple trained their 3B parameter model with around 3.1T tokens (this is a big simplification, you should read the paper if you haven’t already. It’s a great read!) so about 1000 tokens/parameters. Man, we’ve come a long way since the 20 tokens-per-parameter Chinchilla days! In any event, they trained their “quantization recovery LoRA” using 10B tokens of the same pre-training data they used to train the model (although they don’t mention how the sampled from the original pre-training data). This represents about 0.15% of the original pre-training data, but it is not clear if this same ratio will work on a model trained on a smaller training set.
What about SVD?
My first thought is “did Apple do way more than they needed to?” (The guys and gals at Apple are obviously very smart, so more of a rhetorical question). How about we take the residual from the quantized weights and find a low rank approximation of it using SVD (this can be done efficiently for low ranks). This is a more direct approach than post quantization fine tuning for 10 billion tokens (!)
From a mathematical perspective
$$SVD(W) = SVD(W_q + W_r) \neq SVD(W_q) + SVD(W_r)$$
E.g. SVD, matrix inversion, etc. is not a linear transformation. This suggests that maybe whatever low rank the weight matrices happen to have will be lost in quantization. But obviously Apple is finding a low rank approximation of the residual.
In order to get a sense of this, I created a notebook that iterates through the a few layers of EleutherAI/pythia-160m-deduped and show the top singular values, comparing the original weight matrix, the quantized weight matrix and the residual matrix.
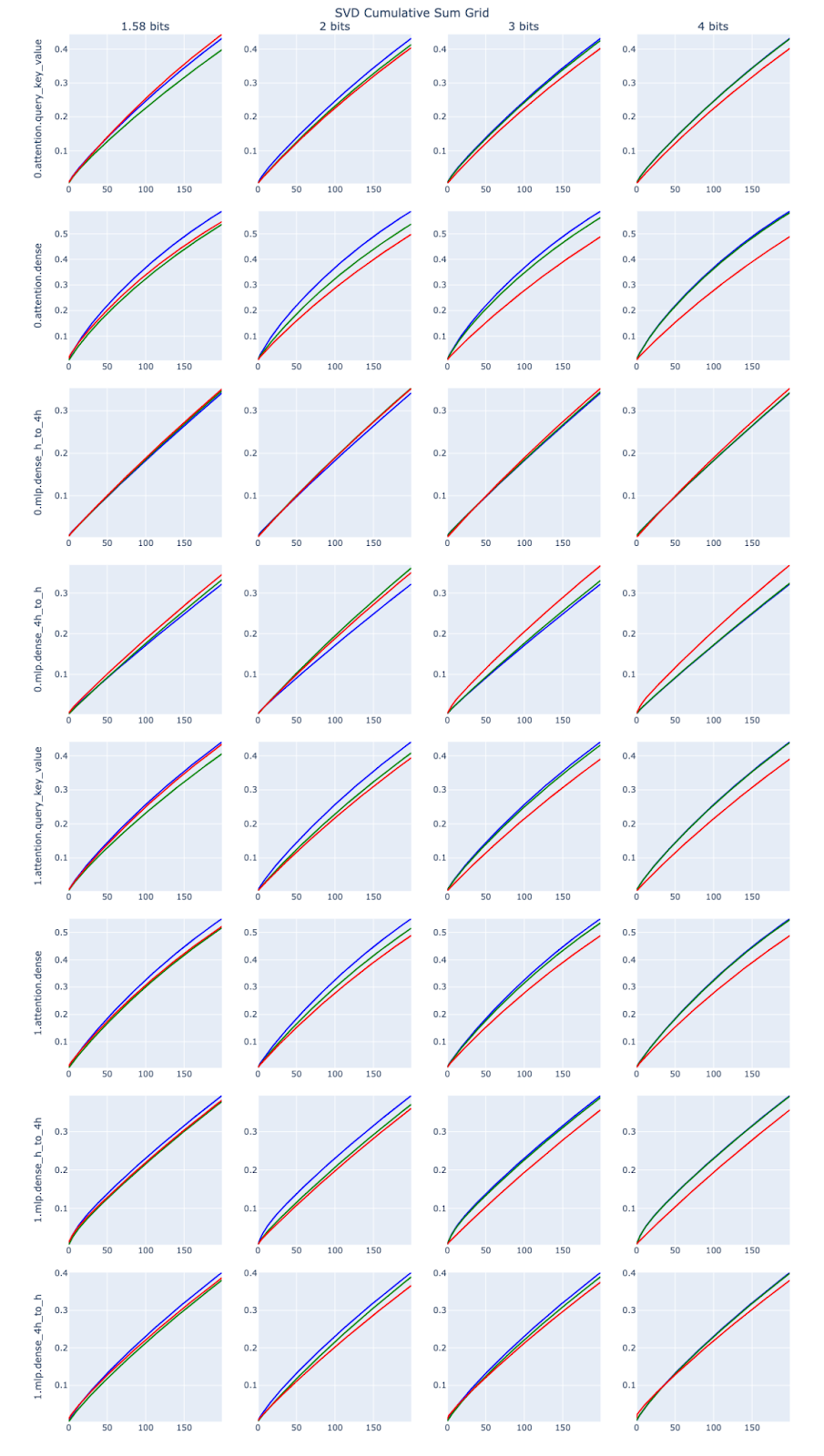
Here we see the cumulative sum of the first 200 singular values (e.g. eigenvalues) for the first two layers. Blue is unquantized, green is quantized and red is the residual. The shape of the curve doesn’t seem to be dramatically affected by quantization, so the first takeaway might be that we might be able to recover some loss using a low rank approximation of the residual. When red is the top line, the residual kinda-sorta has lower rank than the original matrix, and a LoRA might be more effective to recover the loss from quantization, but it is unclear by how much.
On the other hand, we have this very different plot:
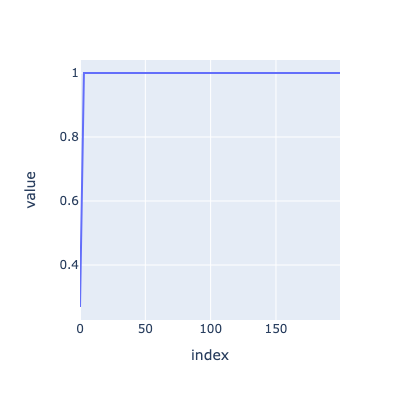
The above plot is what a truly rank 4 matrix would look like. So at first glance, it looks like low rank approximations of our weights shouldn’t work at all, since the weight matrices don’t seem to have low rank.
But LoRA does work…
On the other hand, LoRA does actually work quite well, both for general purpose fine-tuning, and apparently for quantization loss recovery… what’s going on?
This suggested to me that the span of the data itself is low rank, so a low rank approximation is enough to fine-tune or recover quantization loss. Indeed, when I took a look, the papers about this that the LoRA paper cites talk about the data and problem space, not the models. This means that we will probably need to actually train a LoRA to recover the quantization loss, although it might help to initialize the weight matrices using SVD.
This was surprising to me: I though that the model weights were low rank, but they don't seem to be. It's the "intrinsic dimension" of the problem itself! This is very interesting, and impacts how I think about this problem.
Fortunately, Pythia is a set of awesome research LLMs from EleutherAI that provide both the weights and the training data (plus everything else you need to recreate the weights). We can try quantizing and then training a “loss recovery” adapter against the original training data (~0.15%?).
I've already gotten started, stay tuned!
Subscribe to my newsletter
Read articles from RJ Honicky directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by