Week 12: Mastering Hive 📈
 Mehul Kansal
Mehul Kansal
Hey fellow data engineers! 👋
This week's blog explores the architecture of Hive, offering insights into its components like data storage and metadata management. It also covers the different types of tables Hive supports, essential optimizations for improving query performance, and advanced features such as transactional tables. So, let's take a deep dive.
Hive overview
Hive is an open-source data warehouse that enables analytics at a massive scale and enables querying petabytes of data residing in distributed storage using Hive Query Language (HQL).
It comprises of two parts: actual data (present in distributed storage) and metadata (schema for data present in metastore database).
We can determine the location where the data should be stored using "hive.metastore.warehouse.dir" property. Thereafter, we can begin creating databases and tables as follows.
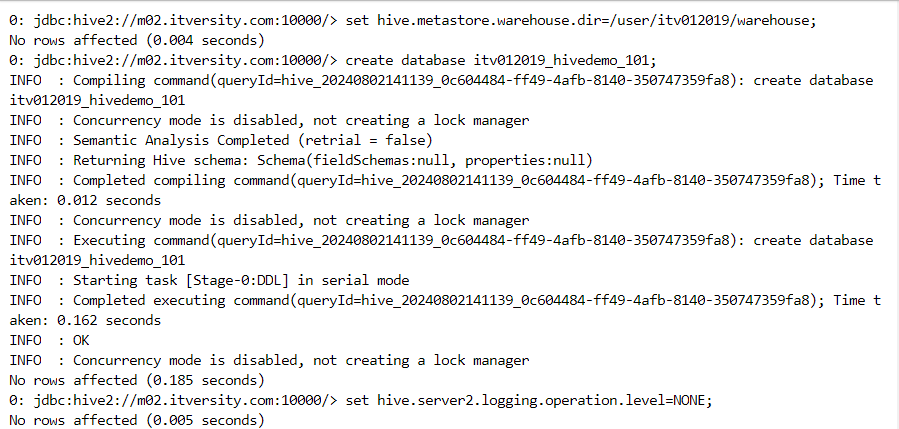
- Hive query language (HQL) has SQL-like syntax.
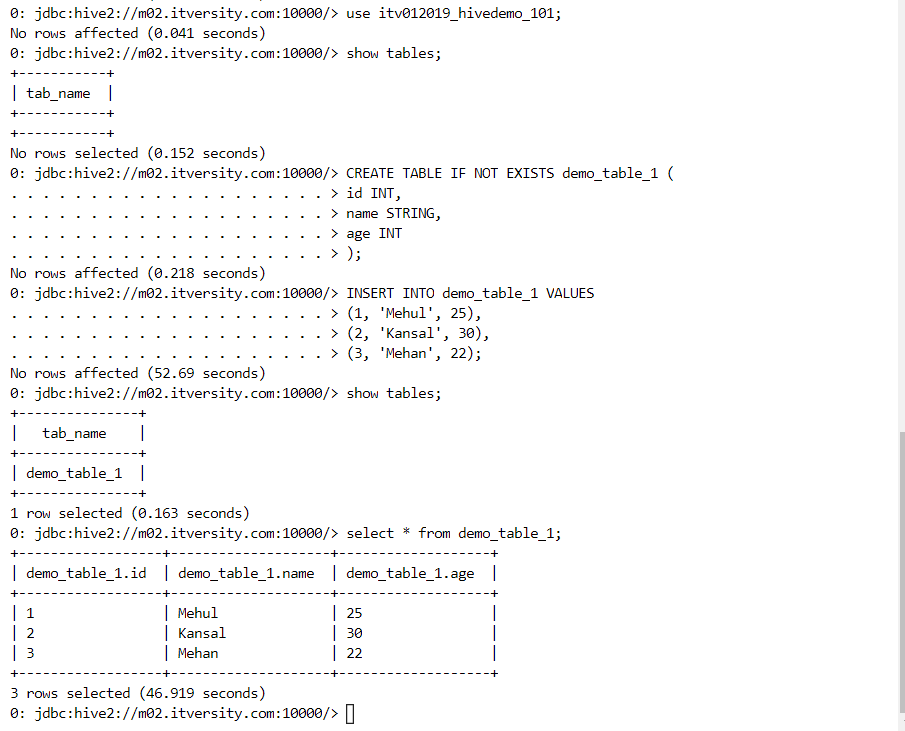
- As we can see, data gets stored under the mentioned directory.

- If the database needs to be dropped, it must be empty, hence the tables inside the database need to be dropped first.

Types of tables in Hive
Managed table: Both the data and the metadata are managed and controlled by Hive.
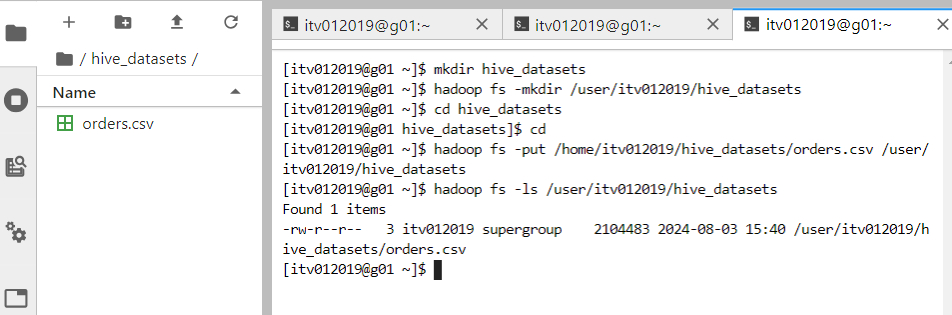
- Firstly, we copy the required 'orders' data from local environment to HDFS.
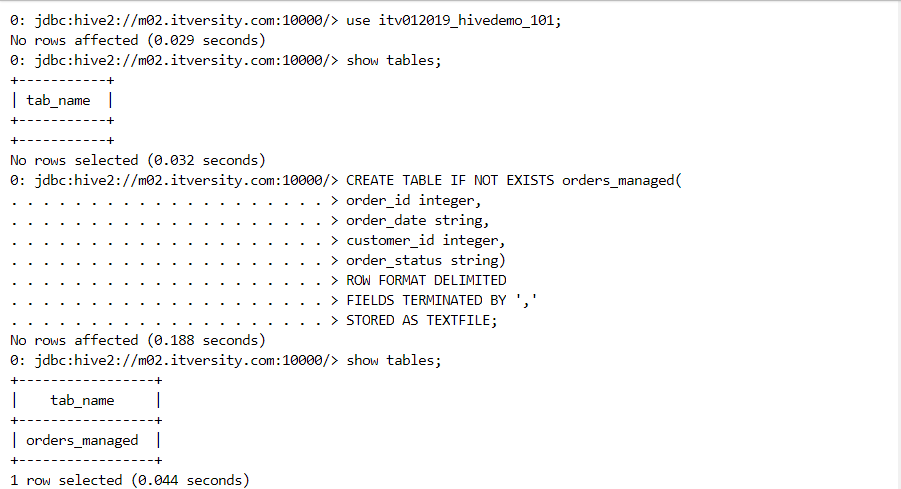
- We create an empty managed table.
- We load the data into the managed table.
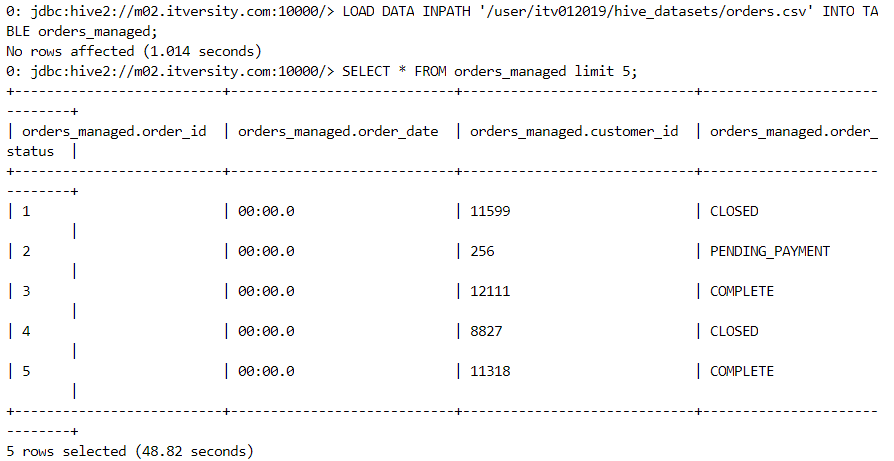
- Upon the loading of data, the data gets moved from the local environment into the Hive warehouse directory.

- Inserts are possible in Hive but take considerable time because Hive is primarily meant for analytical processing.
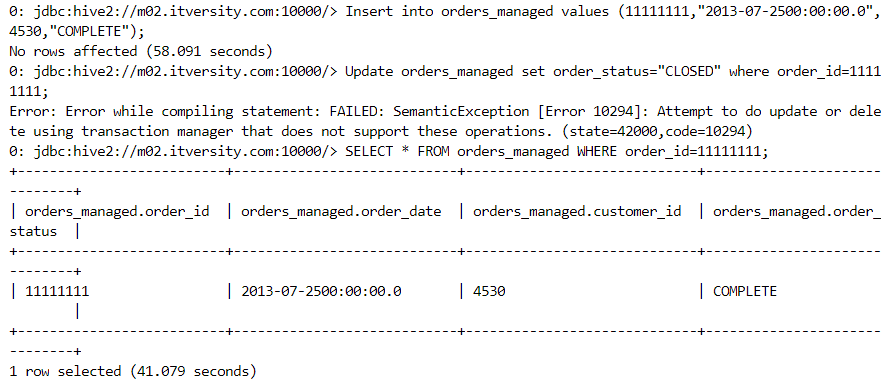
- In the folder, new file gets created upon insertion.

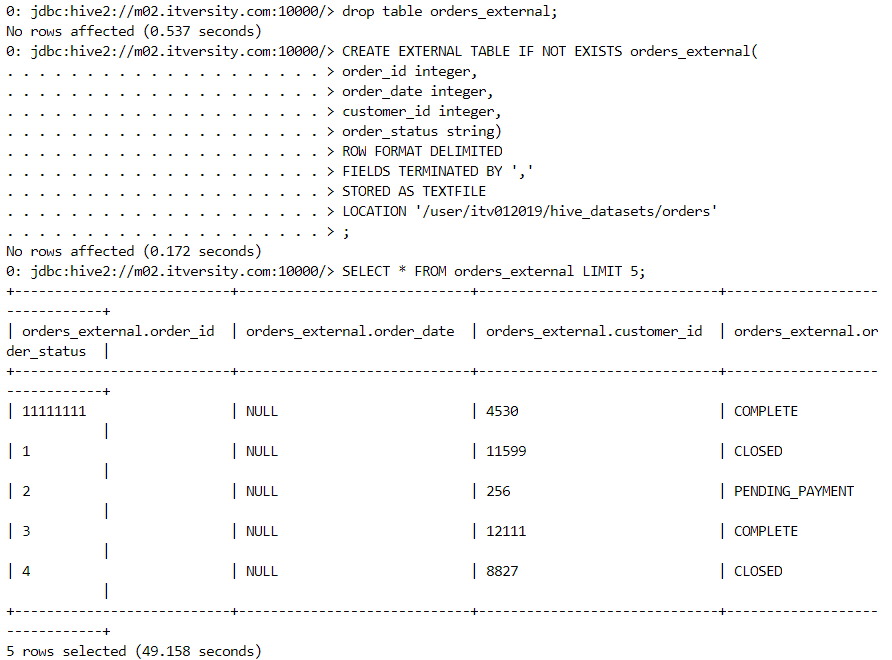
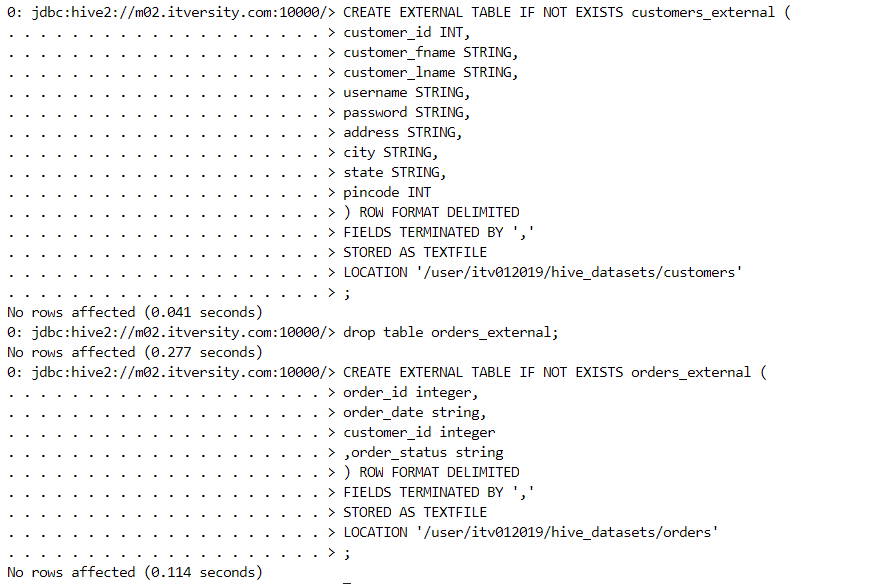
External table: Only the metadata is managed and controlled by Hive.
- Firstly, we determine the location where the data for external table resides.

- We create the external table and can see the data inside it.
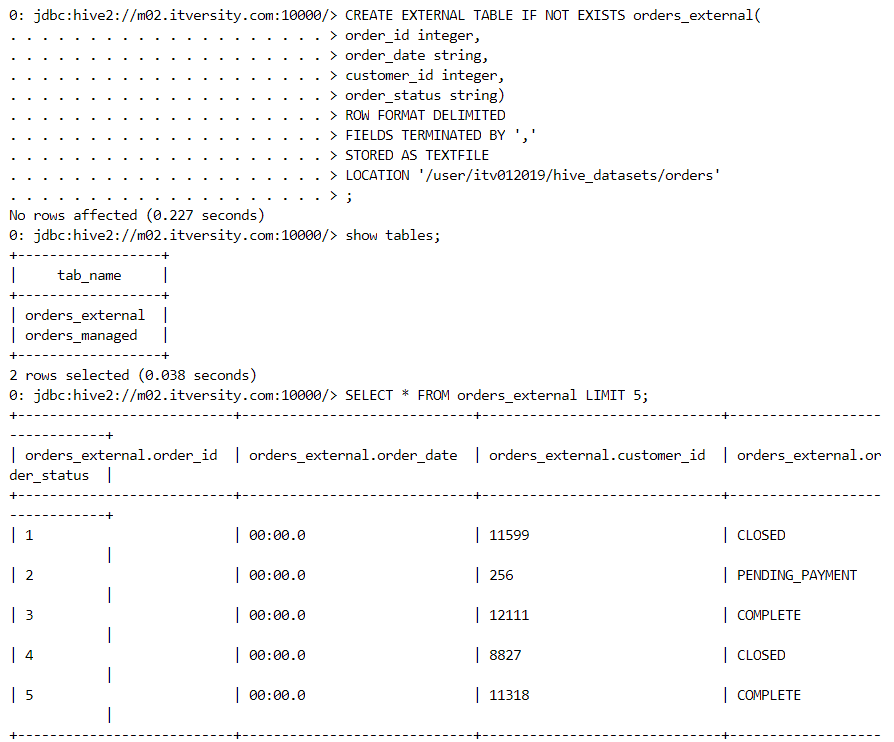
- We can execute simple queries.
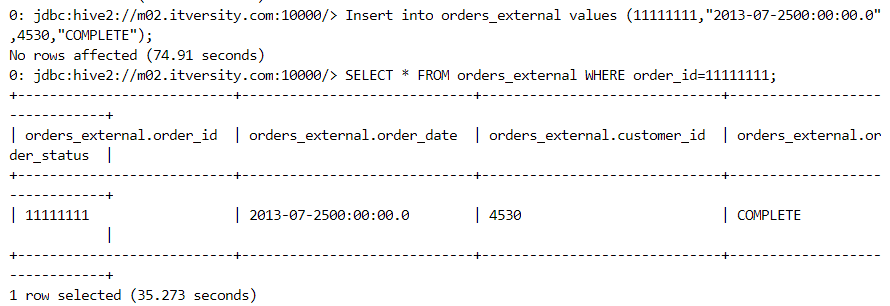
- Suppose we try to insert values into the table that are incompatible with the datatype mentioned in table creation definition. We get NULLs at the corresponding places.
Hive optimizations
There are two levels of optimizations in Hive: table structure level (partitioning and bucketing) and query level (join optimizations).
Partitioning
- In order to structure the data in such a way that the results can be fetched by scanning as minimal data as possible, we partition the data on a predicate column with less distinct values (order_status).
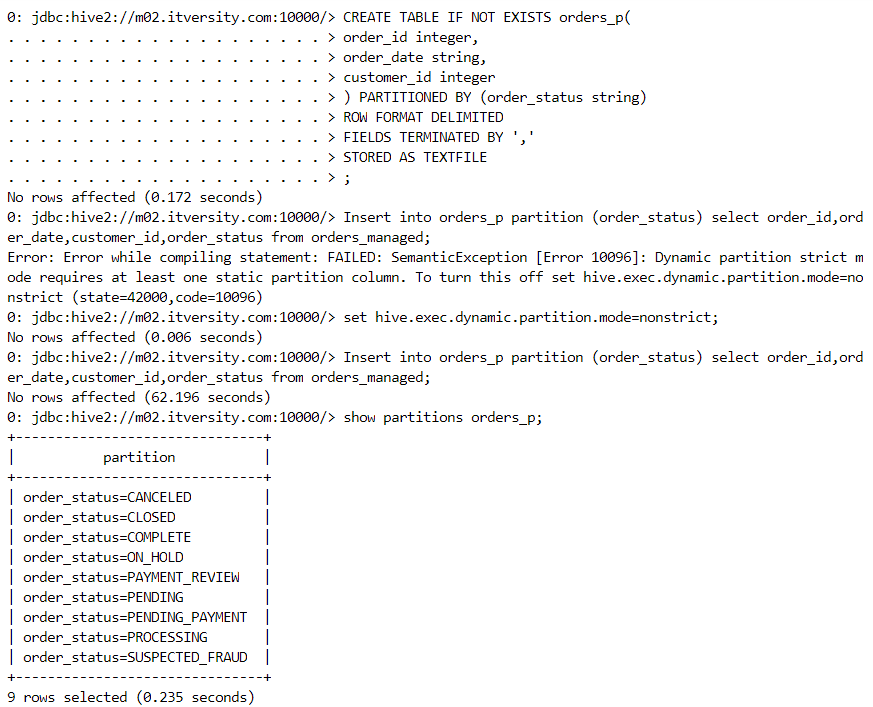
- Partitioning creates folders that consist of filtered values based on the filter condition.
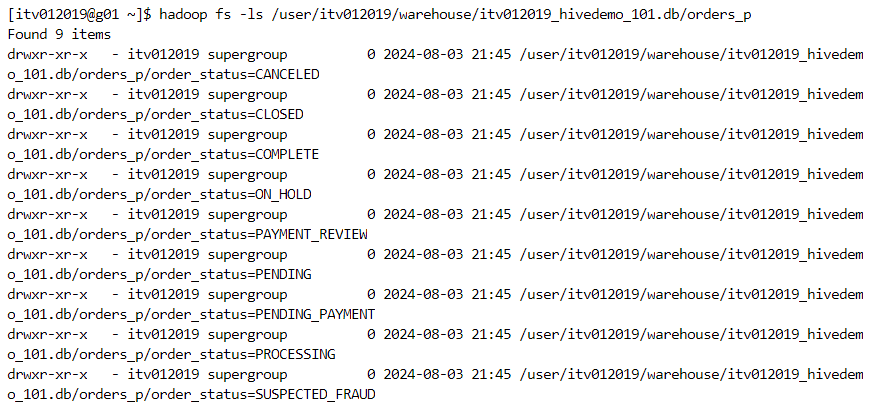
- Insert command invokes a map-reduce job internally to load the data.
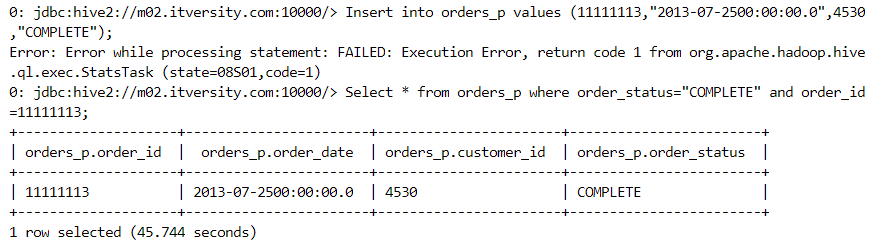
- An incremental file gets added to the folder that gets detected automatically when a select query is executed.

Bucketing
- In order to scan as minimal data as possible when the number of distinct columns is high, we use bucketing because it creates a fixed number of buckets with files.
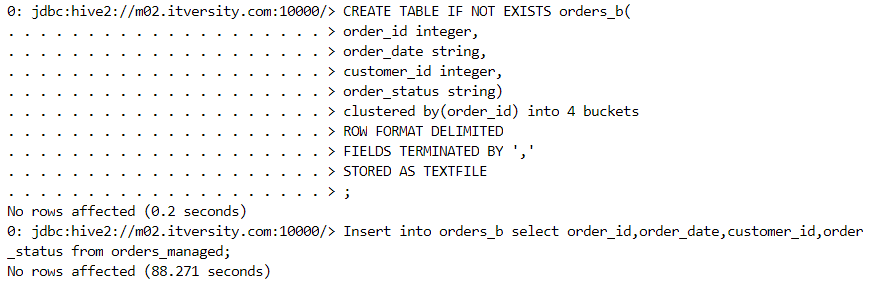
- A hash function determines that a value goes into which particular bucket.

Hive join optimizations
- Since joins involve shuffling of data, these are time consuming. Hence, if complex join operations get optimized, performance increases substantially.
Map-side join:
We broadcast the smaller table that can fit into the memory, across all the nodes in the cluster. So, each node gets a complete view of the smaller table and a partial view of the larger table.
Let's say we have the following two tables.
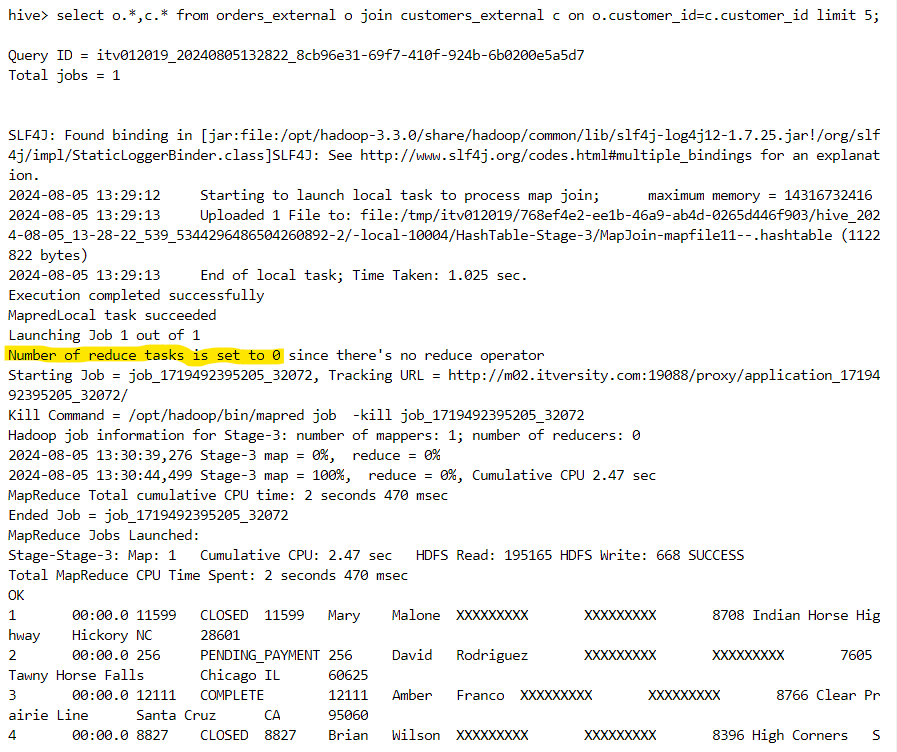
- Upon performing the join operation, we notice that there is no reducer involved in the job thus invoked, indicating that map-side join has taken place.
- Map-side join took place because of the following property.

- Now, if we set this property to false, map-side join will no longer be invoked and a reducer will get associated with the job.
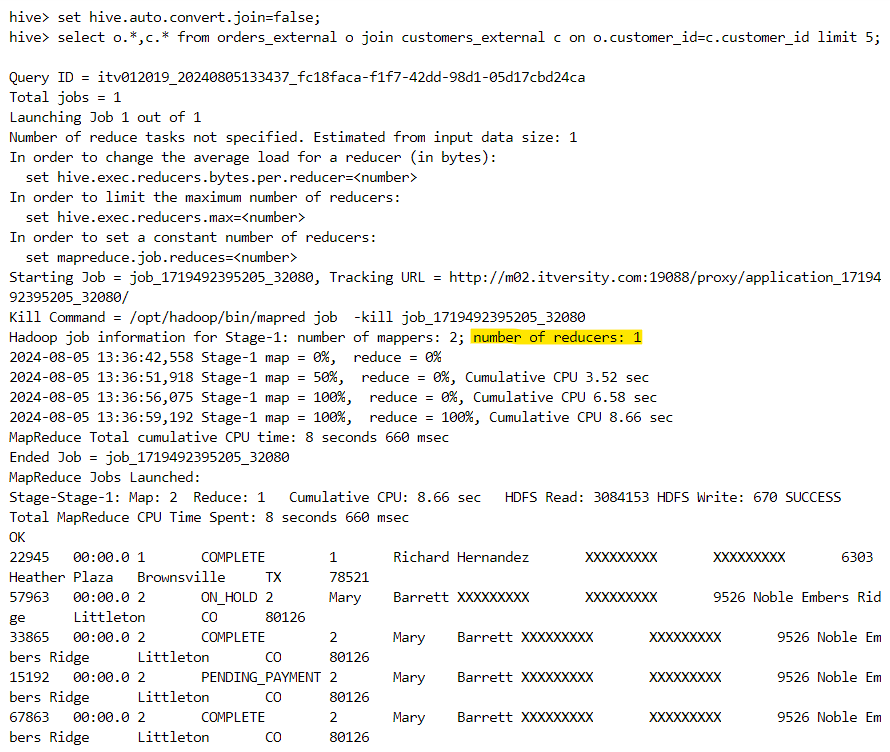
Bucket map join:
When we need to optimize the join of two large tables, we use bucket map join that requires the following two constraints:
Both the tables must be bucketed on the join column.
The number of buckets in one table should be an integral multiple of the number of buckets in the other table.
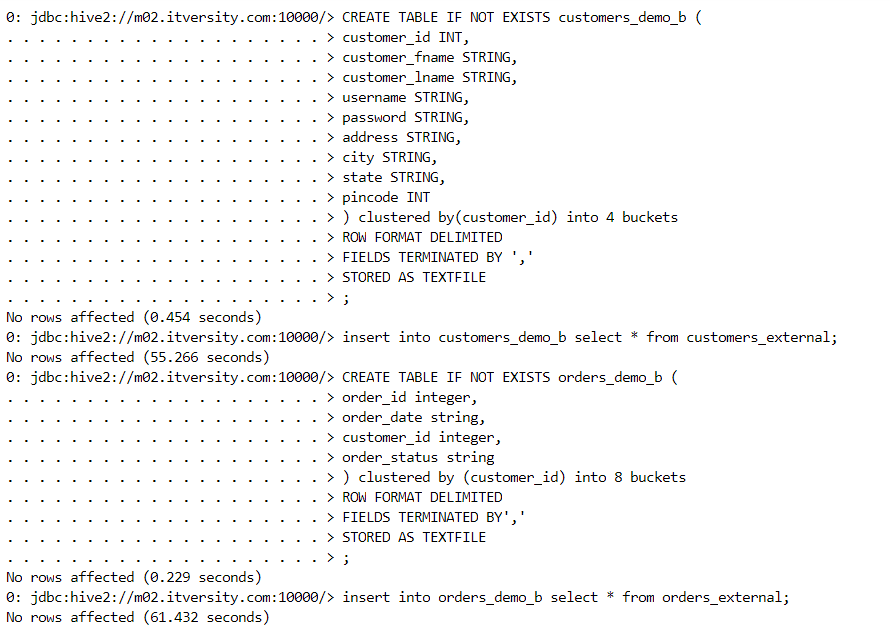
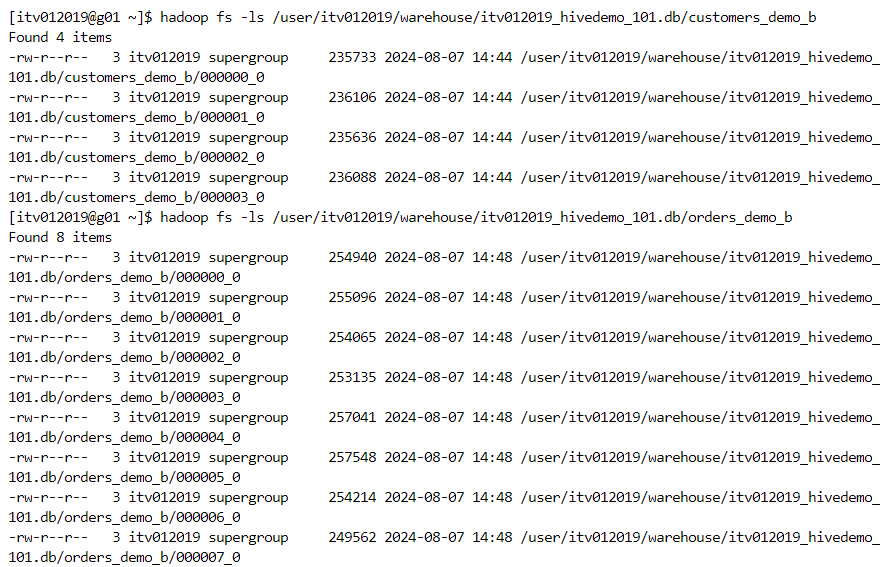
- The number of buckets can be confirmed with the file structure.
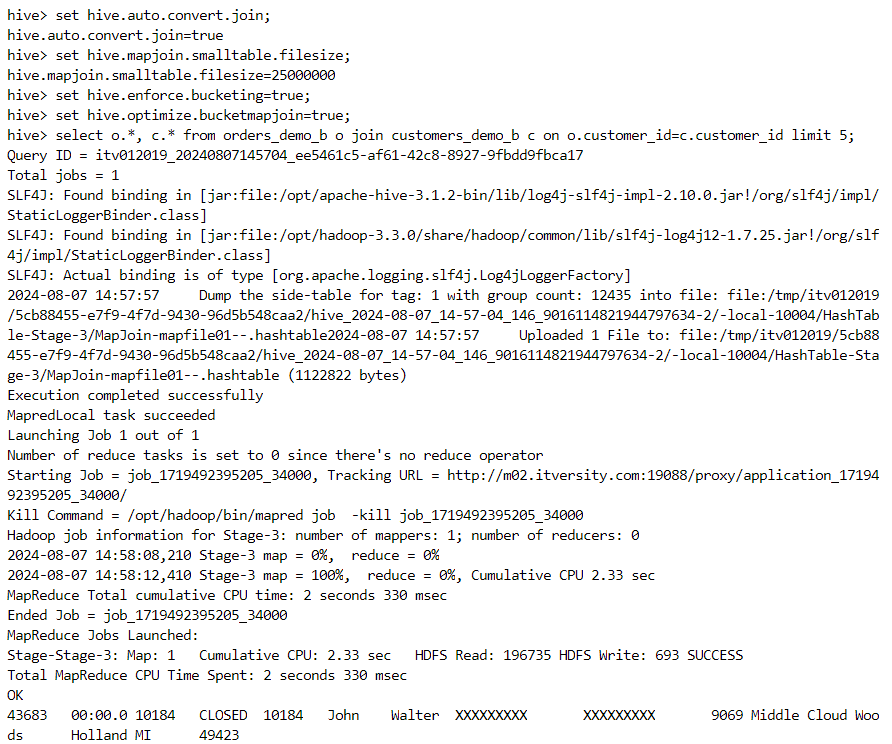
- Now, we set the 'hive.optimize.bucketmapjoin' to true and invoke the bucket map join as follows.
Sort merge bucket join:
- The following pre-processing constraints need to be set before performing the sort merge bucket join.

The following constraints need to be met for this join:
Both the tables must be bucketed on the join column.
Number of buckets in both the tables should be identical.
Both the tables should be sorted on the join column.

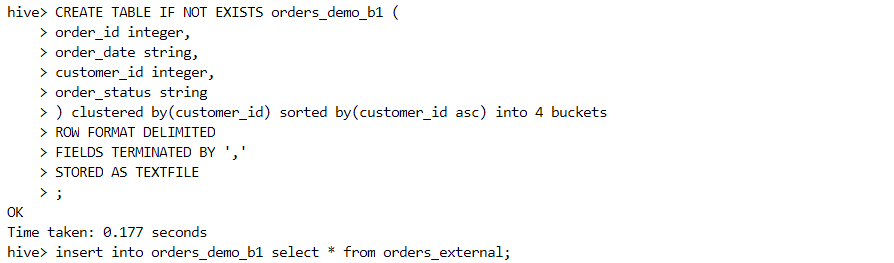
- The number of buckets can be confirmed from the file structure.
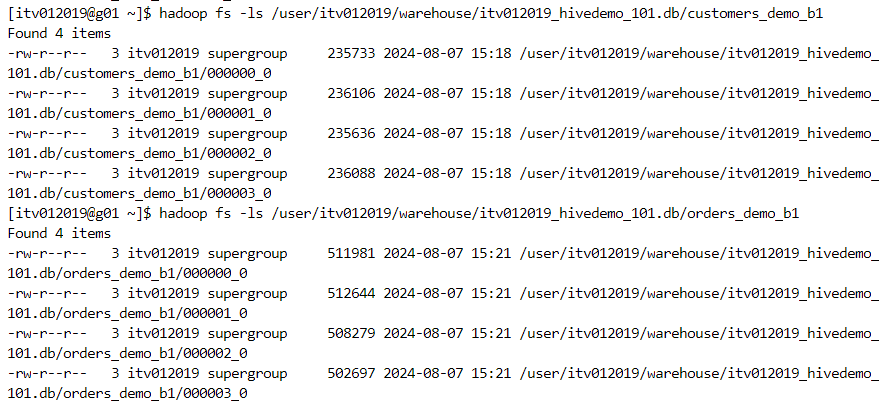
- Finally, the join function gets invoked.
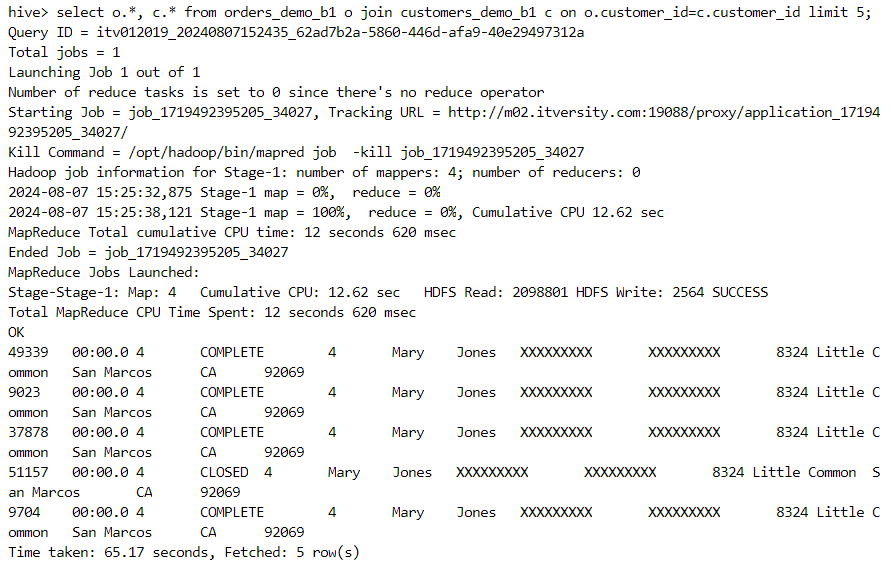
- In order to get a detailed look of the job executed underneath, we can execute the following query.
explain extended select o.*, c.*
from orders_demo_b1 o join customers_demo_b1 c
on o.customer_id=c.customer_id limit 5;
- It is quite evident that the sort merge bucket join took place, indeed.
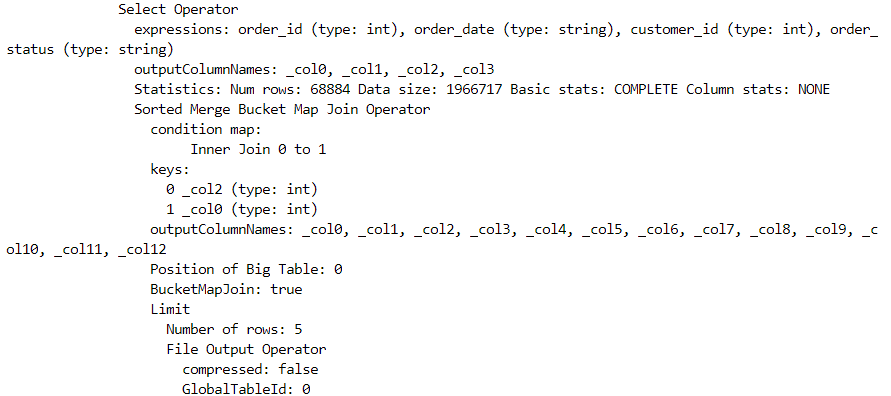
Hive transactional tables
Although Hive is a data warehouse and not a database, sometimes a need for performing transactions arises.
After configuring the required properties for transactions, we create transactional tables out of managed tables as follows.

- The following command can be run to determine whether a table is transactional or not.
DESCRIBE FORMATTED orders_trx1;
- A transactional is created, indeed.
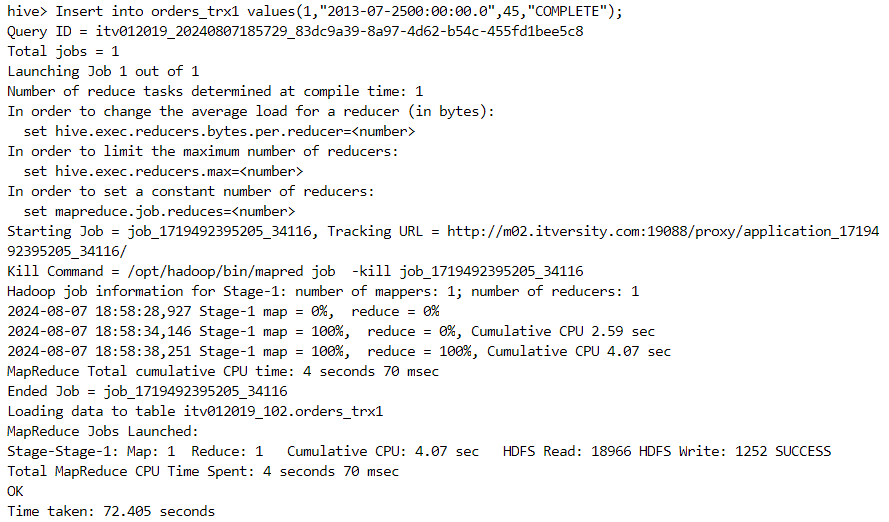
- Insert command can be performed. Also, all transactions are auto-commit in case of transactional tables.
- The data gets stored in ORC format as follows.

- An update command can be performed as follows.
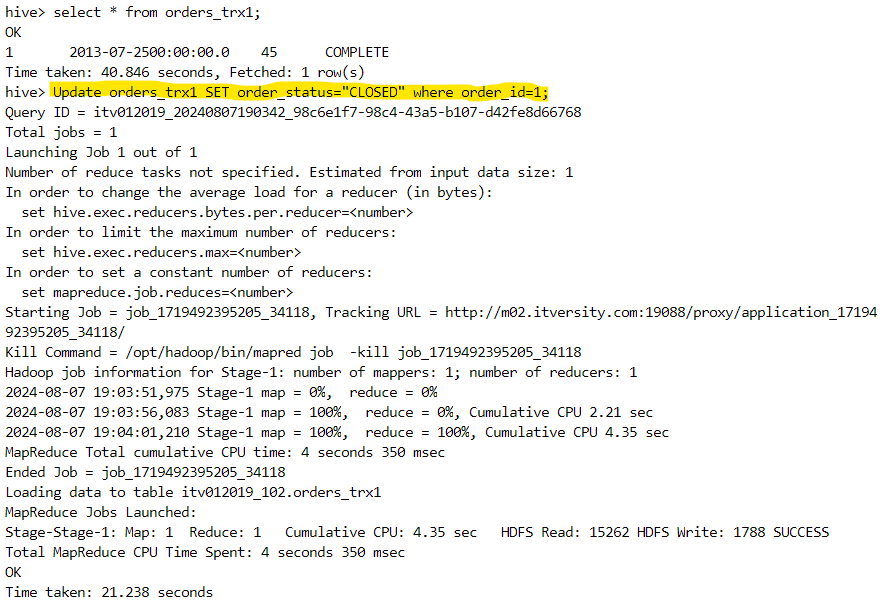
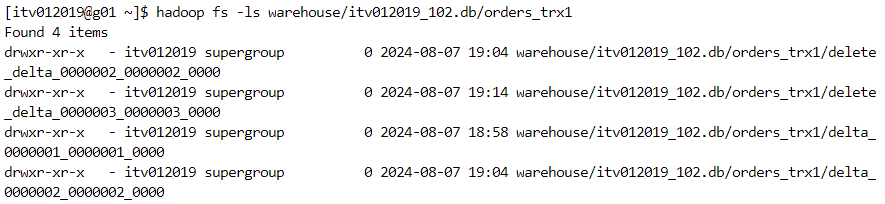
- Since updating a row is equivalent to deleting the pre-existing row and inserting the new modified row, one file for each operation gets created.

- Deletion can also be performed.
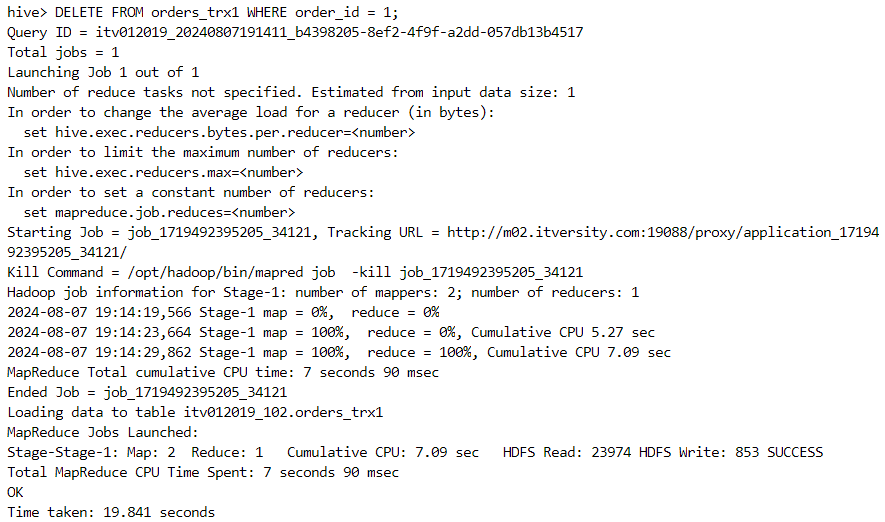
- One file gets created for the deletion operation.
Insert-only transactional table
- As the name suggests, only insert operations can be performed on the following table.
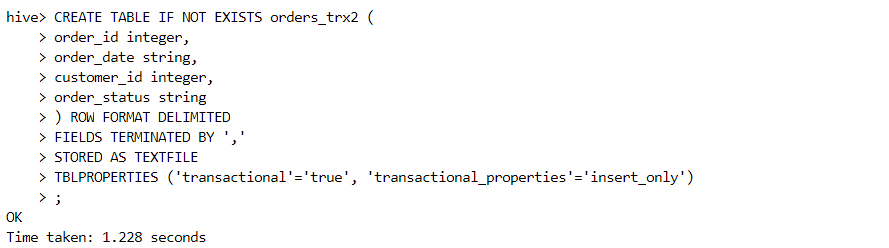
- The following command confirms if the table is insert-only or not.
describe formatted orders_trx2;

- Update and delete operations give an error on this table.

Scenario:
Consider a scenario where we have to convert a Hive external table into a Hive transactional table.
The data for the external table resides at the following location.

- The schema definition for the external table looks as follows.
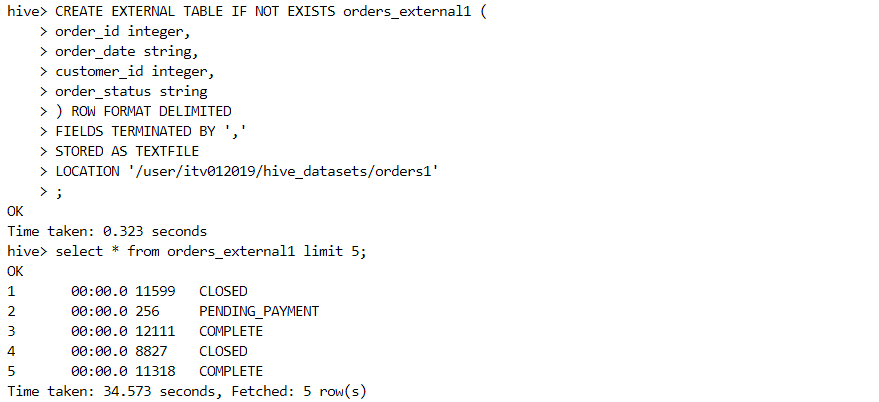
- The 'describe' command confirms that the table is external.
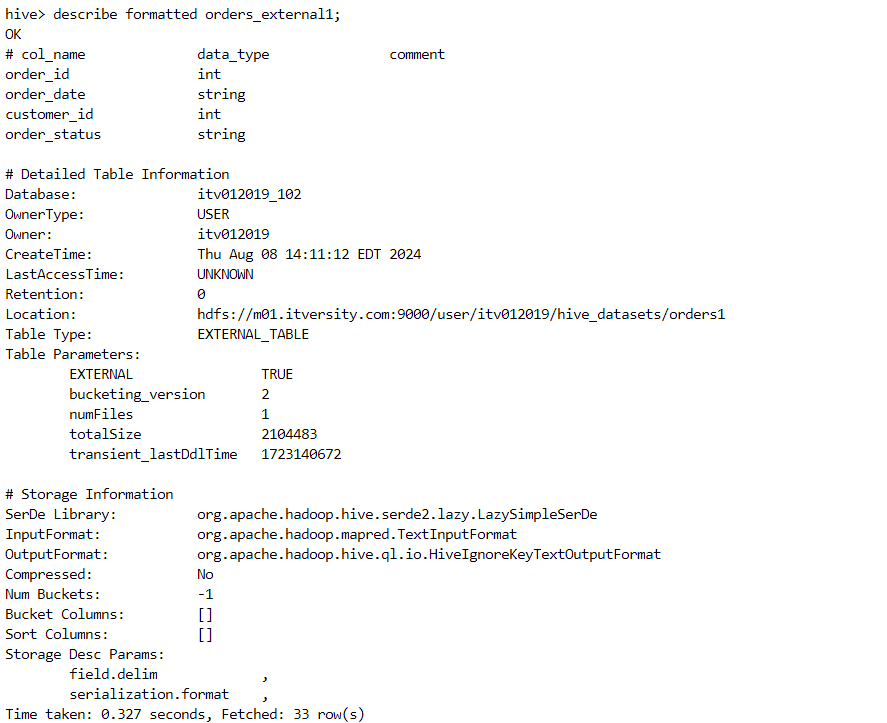
- In order to convert the above table into a transactional table, we need to first convert into a managed table. We do this as follows.
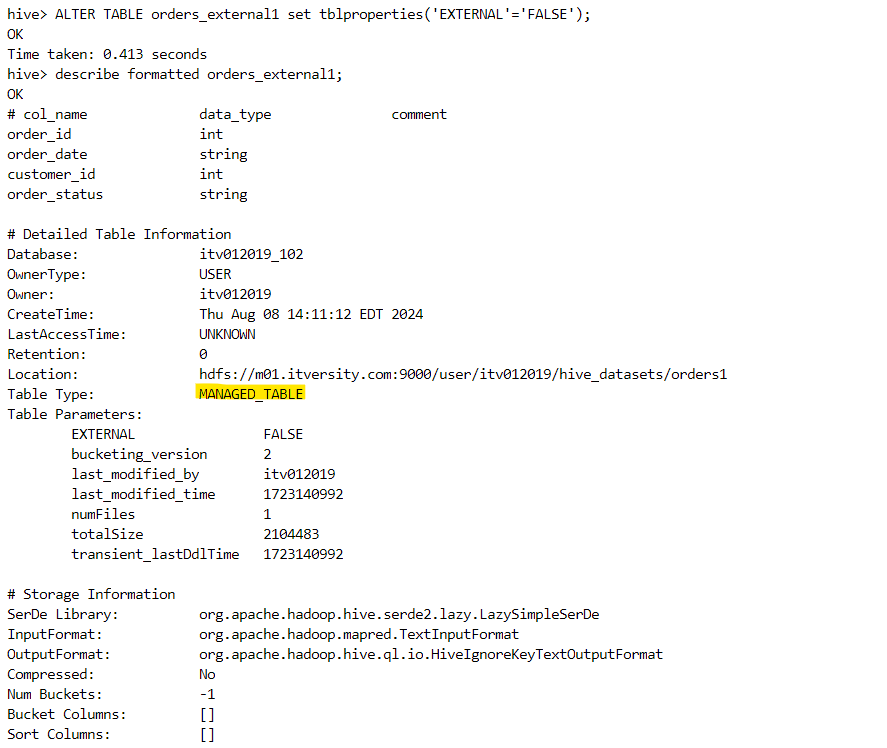
- Finally, we can convert the managed table into a transactional table as follows.
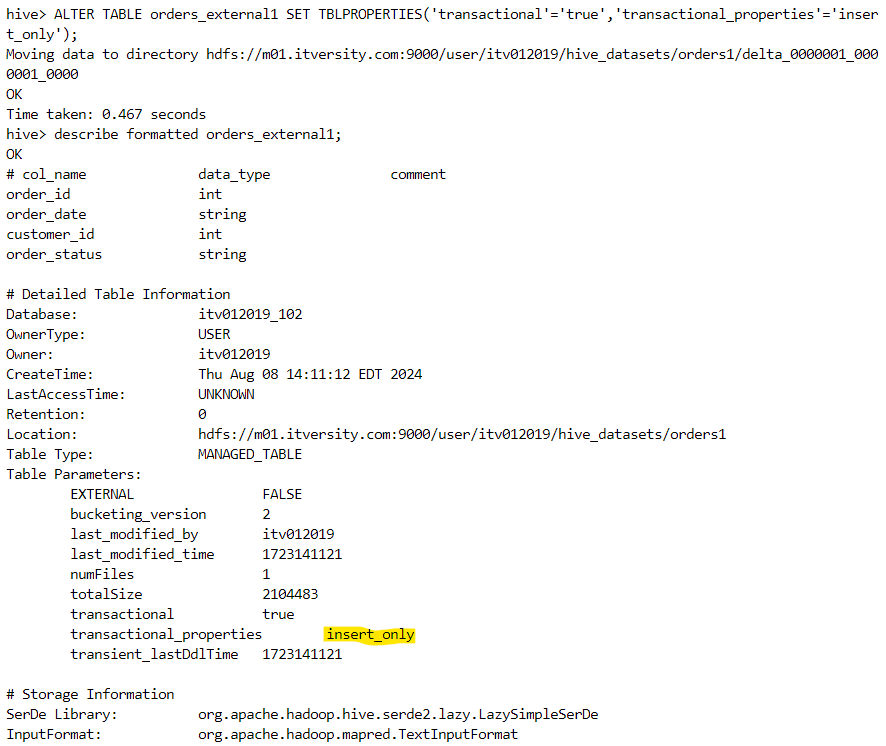
Hive-Spark integration
- We can create a table in Hive and then process the data using Spark SQL. In this way, we can avoid Hive queries that involve MapReduce jobs that can be time consuming.
Hive MSCK repair
MSCK repair is used to correct any metadata changes made at the backend, hence not recognized by Hive or Spark.
Suppose we have the following table.
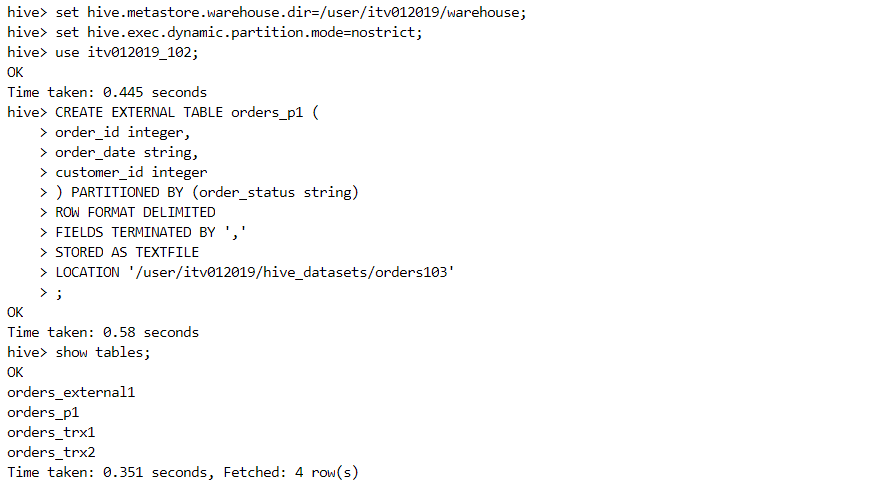
- The table is empty initially.
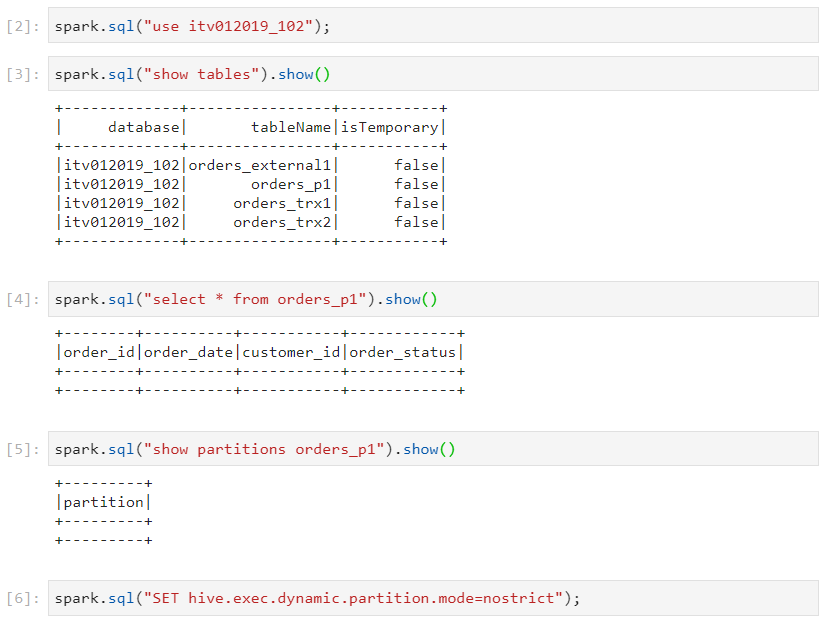
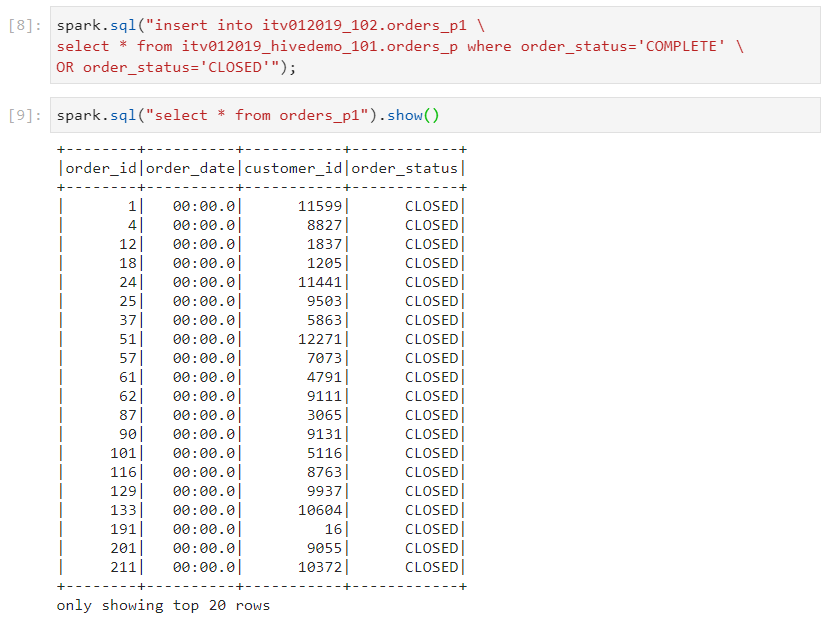
- We insert only the data that have the 'order_status' as 'COMPLETE' and 'CLOSED'.
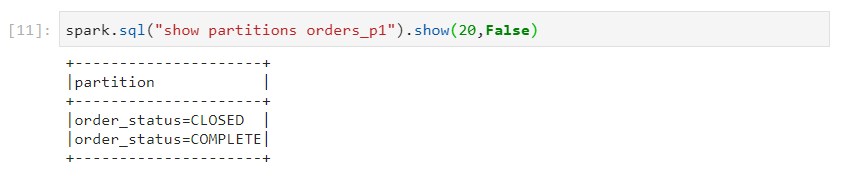
- Now, we can see the partitions based on these two criteria.
- These partitions get reflected in folder structure as well.

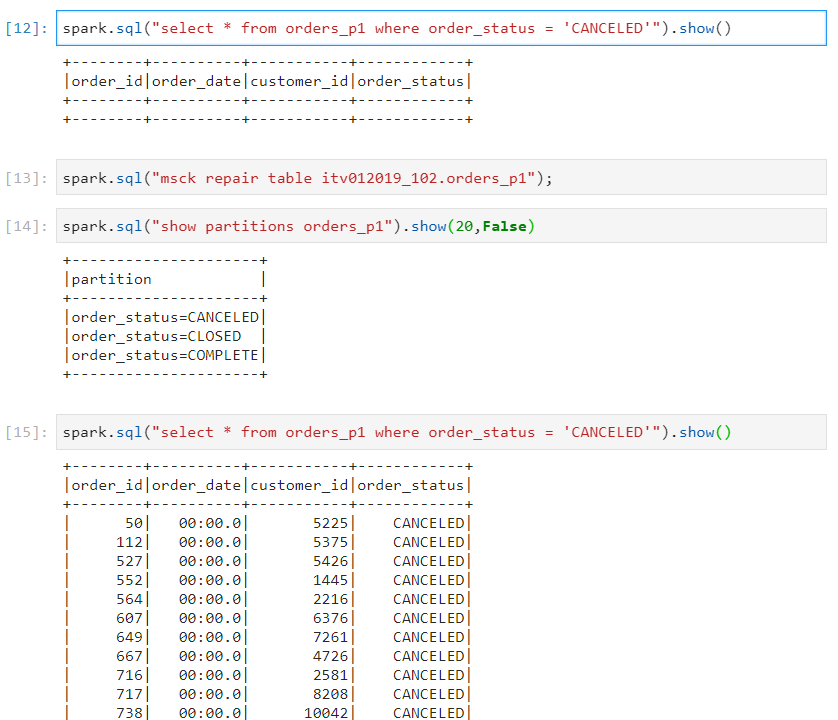
- Now, suppose we insert the data for 'order_status' having value as 'CANCELED' at the folder structure level. Since the change is made at the backend, Hive or Spark will not reflect the new partition.
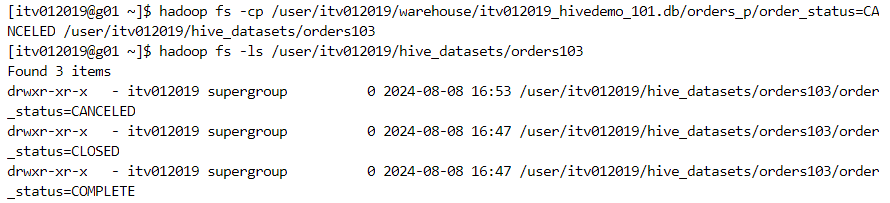
- In order to reflect this change, we need to run 'MSCK REPAIR' command and the corresponding data for 'CANCELED' will start appearing.
Conclusion
In summary, Hive is a versatile tool that bridges the gap between traditional relational databases and big data analytics. With its ability to manage both data and metadata, perform complex join operations, and integrate with tools like Spark, Hive offers a robust platform for data warehousing.
Stay tuned for more such blogs!
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by