How I made my language 500x faster - Language Customizer
 Rhythm Deolus
Rhythm Deolus
The Recap
So, previously I had made tree-walk interpreter for my customizable language along with a playground website to try it out and customize it. It was all great but with a lot of flaws, like:
It didn't have standard keywords for flow control such as
break,continue, andgotoIt had a lot of edge cases where it broke.
Keywords could only be alphanumeric
The website was executing the code in a single thread that made it unusable till the execution completes.
But worst of all, it was a tree-walk interpreter, as those are slow and can never be used for practical purpose.
So, I am going to address this major issue in this article and maybe add more flaws in the process.
The Calm Before the Storm
Why is it that a tree-walk interpreter is slow?
Well let's look at how compilers or interpreters actually work and how our interpreter differs from them.
Compilers and interpreters are usually divided into two phases: Front-end and Back-end.
No, it's not the same Front-end and Back-end as in web development.
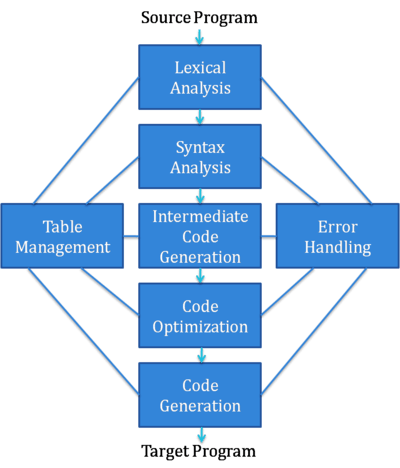
In the Front-end, you take a source code and convert it into something resembling a machine code, it's called intermediate coded representation, or it could be something called bytecode in case of interpreter. These representations are machine independent.
In the Back-end, we take the generated representation and either compile that code to machine code in case of a compiler or interpret it using a virtual machine.
In case of the Front-end, we have
Lexer that converts the source code into a stream of tokens.
Parser that takes stream of tokens and converts them into an AST (Abstract Syntax Tree)
Semantic Analysis that checks the AST for any logical inconsistencies and simplifies the AST,
Intermediate Code generation that takes the AST and converts it into a machine independent code.
So, in all of this where does our interpreter lies?
Well, we have the Lexer, the Parser but after that our interpreter branches of to a world of its own. We take the AST from the Parser and start interpreting it through a virtual machine right there!
What's wrong with that? Surely, we are skipping quite a lot of steps and that should be a good thing, right?
A lot of computation is saved by avoiding those steps, that is true. But those are necessary and one time cost with little overhead to improve the quality of code drastically.
Interpreting an AST is okay if you are just making a proof-of-concept, which is what I was going for in the beginning, but it can never be used in any practical scenarios.
To list why it is slow:
AST uses pointers and they tend to be slower.
Frequent memory allocation for any evaluated value.
Not an exhaustive list, but you get the point.
What are we to do now?
Well, you know how they say, "Sometimes you have to tear things down to build them back up stronger."
The Setback
We'll throw away our code and build it all again. Yes, we'll also throw away our code along with the Lexer and the Parser. "But why can't we repurpose our code for those?" Shut up you winey little child! It's the new beginnings...
So, what will it be this time? Definitely not JavaScript.
I mentioned in the previous article that I would use C to rewrite the interpreter, convert source code to bytecode and interpret it using a virtual machine, those were all false promises.
I changed my mind and now we'll be using Rust and LLVM to build our Interpreter.
"Still compiling it to bytecode and use virtual machine?" No! we'll use LLVM to handle our backend and not worry about the minute details of how our code looks for individual machine targets.
What is it LLVM?
LLVM (Low Level Virtual Machine) is set of compiler and toolchain technologies. Well basically it makes our job easier by providing us an IR (Intermediate Representation) to target our code and an API to help us convert our AST to that IR. From their own the LLVM can do all the heavy lifting, like: optimization passes, JIT (Just-in-Time) compilation.
Why Rust though?
Honestly, I just wanted to learn Rust and thought this would be a good way to do that, and boy was I wrong.
The New Beginnings
Here we go, this is what I got so far.
This is a small code for calculating the 30th Fibonacci number:
def fib(var n) {
if (n == 1 or n == 2) return 1;
return fib(n-1) + fib(n-2);
}
print fib(30);
Time taken by our tree walk interpreter 18.9 seconds.
Time taken by our new JIT compiled interpreter 0.041 seconds.
That's a lot faster, 461 times faster to be exact, which is more practical.
"So, the title was a clickbait?" Hey, still in the same figures.
Let's compare it with C,
#include<stdio.h>
int fib(int n) {
if (n == 1 || n == 2) return 1;
return fib(n - 1) + fib(n - 2);
}
int main() {
printf("%d", fib(30));
return 0;
}
It takes GCC 0.069 seconds to compile this code and 0.014 seconds to execute it. so, at total it takes 0.083 seconds.
So, our language is faster than C! right? Well... no. GCC is known for its slow compilation and since our language doesn't have a very convoluted syntax it is easier to parse, and the interpreter does not do a lot of optimization passes so it is faster to compile.
The compile time for our language was 0.023 seconds and the execution time is 0.018 seconds so our language will definitely be slower for what counts, the Execution Time.
Hey, still its only 1.28 times slower than C that's a big feat! and 5 times faster than Python, but Python is known to be slower, so we don't count that.
Now the time to name this language and I shall name it 'Mismo', which is Spanish for 'same'.

The Lost World
While making this leap, we have left few things behind.
One of which is that the language right now only supports floating pointers as datatypes. Since our language is dynamically typed and LLVM IR supports statically typed variables, implementing dynamically typed variables would need some workarounds that I haven't gotten to yet.
Another thing we have lost for now is Closures. In our tree-walk interpreter it was easy to enclose the environment of a closure by just setting it as one of its properties. Then while resolving any variable reference, we can just look at that environment. But in case of our new implementation there is no object to set its property and the LLVM handles the allocation of variables on its own.
So, how to combat it? All the variables that our closure captures need to be passed to it through parameters, or we could use something called trampoline intrinsic in LLVM. I'll decide which to go with later.
We didn't just lose some functionalities; we've also introduced some bugs as well.
Currently, there are a lot of untested edge cases where the things break. One example is indirect recursion.
def first() {
second();
}
def second() {
first();
}
first();
This doesn't work. I won't bother you with why exactly, but I promise you that it isn't because of my stupidity.
I have also not addressed a lot of error cases, and the code just compiles for those cases and does nothing just skips over them like it didn't even happen. I kind of am proud to have implemented one of my personality traits in this language.
Despite our new world lacking some important things, it is promising.
The Promised Land
"So, what if our language is even less practical now? look how fast it run!"
Let's not be blinded by speed. What use is that speed if you can't even write a decent code with it?
So, things we need to work on now are
Implement different datatypes and make variables dynamically typed.
Bring back our beloved closures!
Integrate this new implementation to our playground website.
And just work out a good error handling system.
For Integrating it to our website, we would need to setup API points and a server-side sandbox environment probably using a docker container.
Why can't we use something like Web Assembly as I promised in my previous article?
Well, we can but the bundle size of our new language is around 1 GB as it also includes LLVM toolchain in it as well. You wouldn't want to wait for 1 GB of assets to download before you can access a website, would you?
For dynamically typed variables, we'll use structs in LLVM which are just like structs in C. We'll have an abstract struct that can contain any datatype, and we can figure out what type it is by one of the fields in that struct.
Another thing our promised land holds is a RELP. There exists a RELP right now but it's the bare minimum I'll be improving it further.
The End After the Beginning
"Let the past die. Kill it if you have to. That’s the only way to become what you were meant to be" ― Kylo Ren
There is no looking back now. The path has been set and we just need to walk it.
If you read this far, I appreciate you giving your time to this. Hopefully my next article wouldn't be as delayed as this one. If you have any specific parts that you'd like for me to delve further into and explain in a separate article, you could tell me in the comment section.
Here is the GitHub repo if you wish to look at the source code and understand it for yourself:
https://github.com/RhythmDeolus/mismo

Subscribe to my newsletter
Read articles from Rhythm Deolus directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by