Cómo preparar tu máquina para proyectos de ciencia de datos.
 Raul Mercado
Raul Mercado
Cuando queremos aprender ciencia de datos y machine learning, lo primero que necesitamos es configurar nuestra laptop. Si no quieres pasar por todo ese proceso, lo más fácil es ir a Google Colab y empezar a crear tus primeros notebooks desde el primer segundo.
Sin embargo, Google Colab tiene limitaciones de procesamiento y memoria, por lo que si deseas usarlo en proyecto más grandes vas a tener que sacar tu tarjeta de crédito.
La otra alternativa es configurar tu laptop para esos menesteres, y es lo que te voy a enseñar a hacer en este post.
Hay varios lenguajes de programación que puedes usar para ciencia de datos, pero el más popular hasta ahora es Python. Algunos sistemas operativos ya lo traen por defecto, como Linux y MacOS, pero la versión con la que vienen suele ser la 2. La versión mas actual es la 3, pero no necesitamos instalarlo desde la página de Python.
Lo que vamos a hacer es instalarlo como parte de otro software llamado miniconda, el cual ya trae por defecto a Python como parte de su instalación. Miniconda te servirá para crear notebooks, los cuales son los archivos en los que se va a escribir el código para ciencia de datos.
Se llama miniconda porque existe otra versión, Anaconda, la cual trae un IDE mas completo y viene con una lista de software adicional que puedes instalar. La única desventaja que le veo es que al ser más sencillo de instalar, te vas a perder el detalle de su instalación, el cual puede darte una mayor comprensión de como se instalan las librerías.
Lo otra gran diferencia con respecto a miniconda es que Anaconda pesa muchísimo mas, y la verdad es que no es necesario instalarlo para realizar proyectos mas complejos. Ya depende de ti. Después no me digas que no te lo advertí :)
Para instalar miniconda nos vamos a su página web, el cual te mostrará algo parecido a esto:
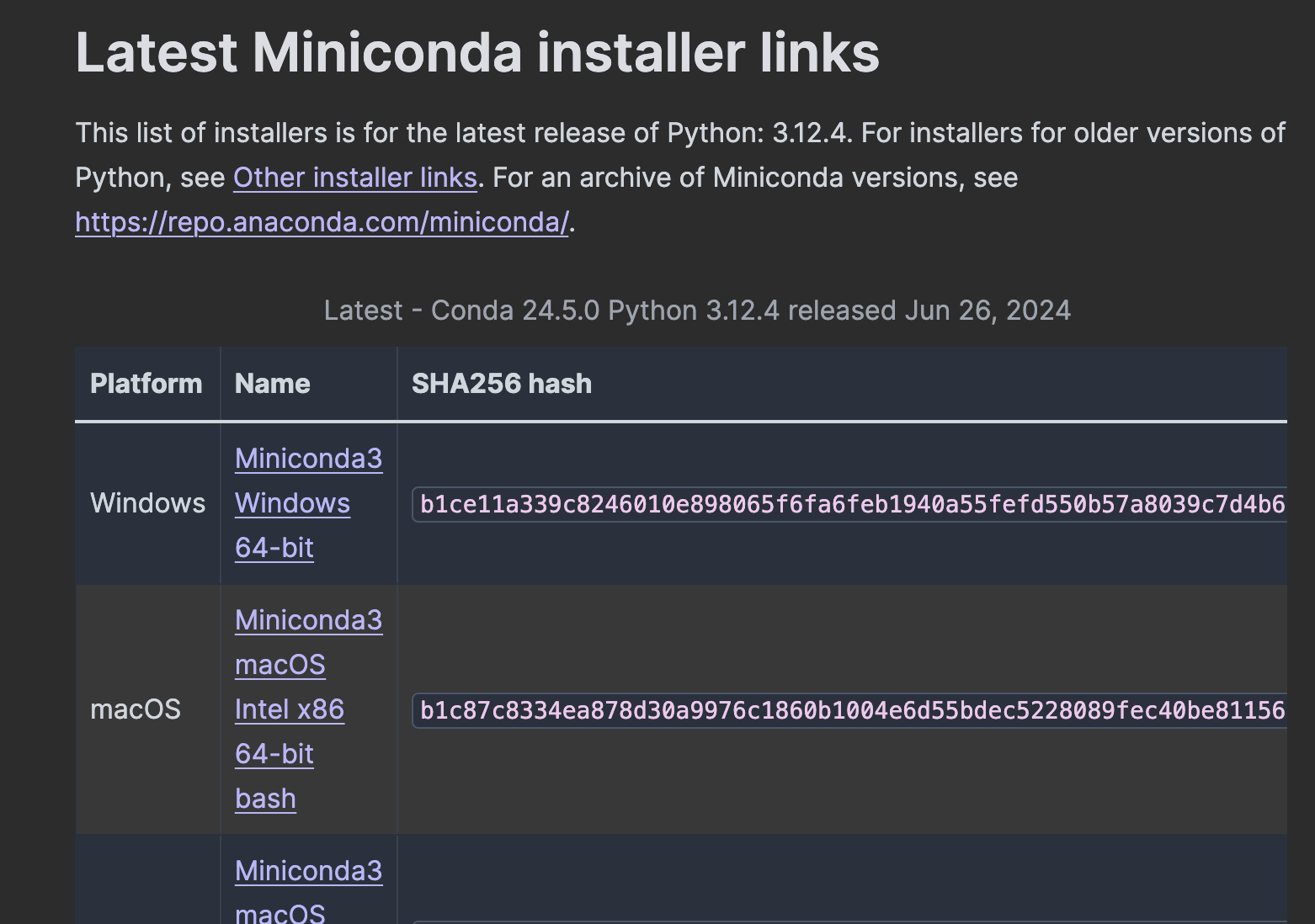
En esta lista podremos ver diversos tipos de archivos de instalación. En el caso de Windows es más sencillo porque solo existe un solo archivo para descargar. En el caso de macOS, tenemos varias opciones dependiendo de la arquitectura de tu procesador. Voy a seguir con el flujo de macOS que es el sistema operativo que tengo. Para los otros sistemas operativos, no debería de ser ningún problema, pero si tuvieras algún inconveniente, no dudes de alcanzarme tus inquietudes en la sección comentarios.
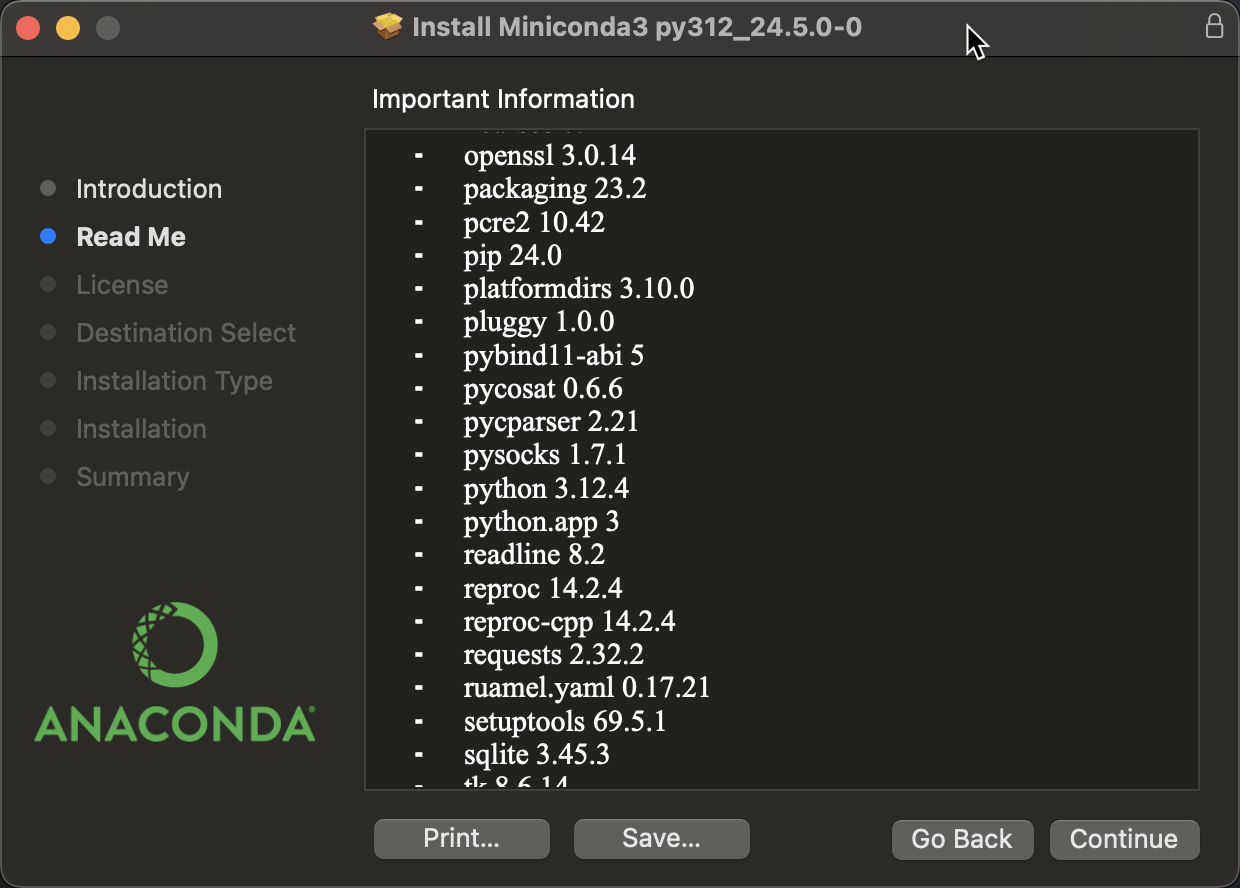
En la primera ventana del asistente de instalación, verás una lista de librerías que se van a instalar. Si buscas Python, podrás saber la versión que se instalará:
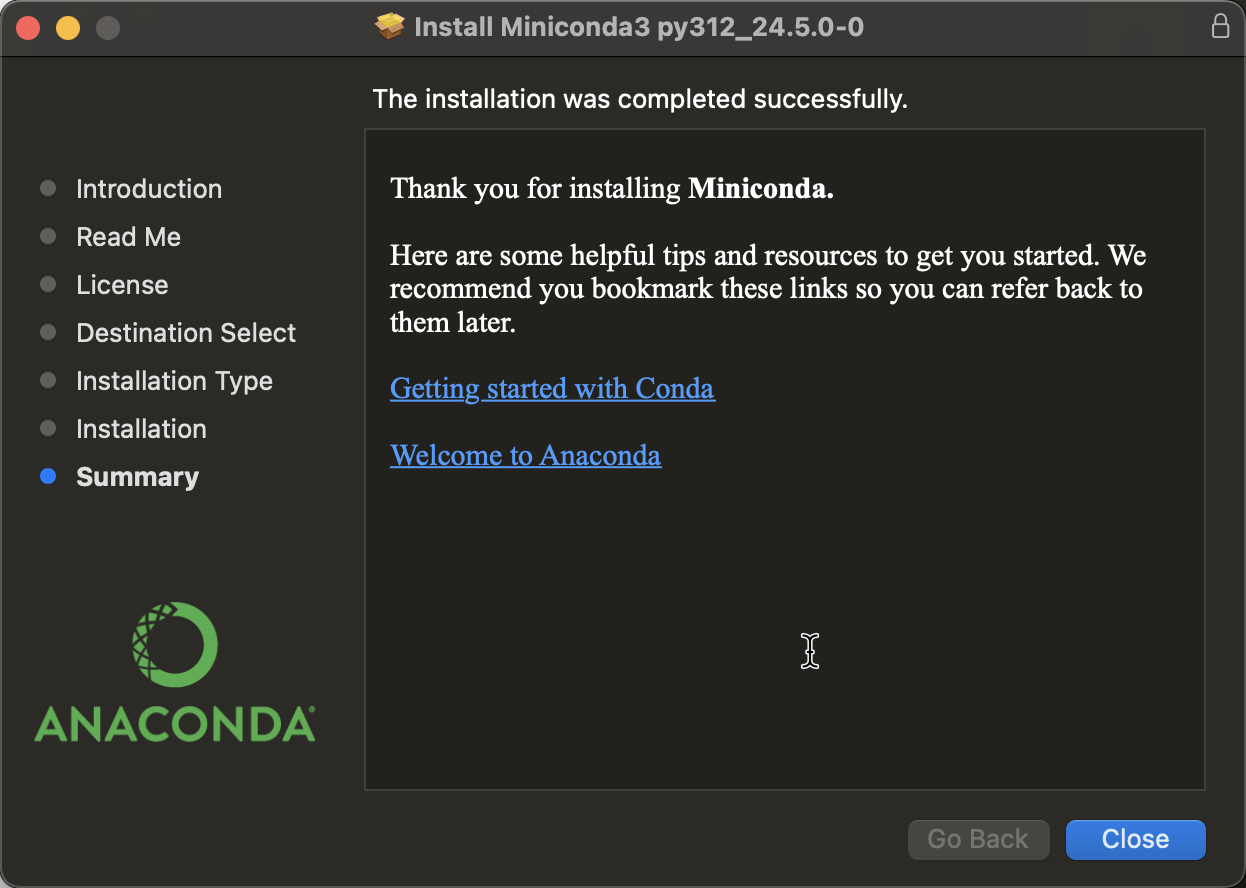
Si durante la instalación te sale un mensaje de error porque ya existe la carpeta de una versión anterior, te recomiendo que la elimines y vuelvas a proceder con la instalación. Finalmente te aparecerá una pantalla de que la instalación fue satisfactoria:
Ahora, abre una terminal y escribe: python. Te debería aparecer la versión ahora:
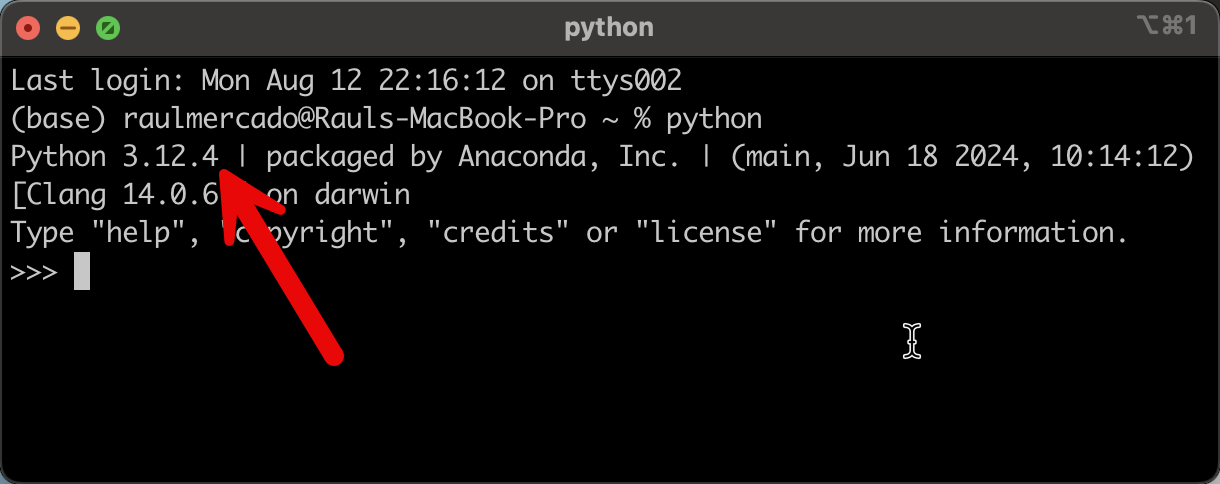
¡Felicidades! Ya tienes Python y miniconda instalado. Para poder ejecutar miniconda, es necesario ir a la carpeta donde se ha instalado, y ejecutar el comando conda. En el caso de macOS, la ruta donde se ha instalado es /opt/miniconda3/bin. Cuando se ejecute el comando veremos una pantalla como la siguiente:
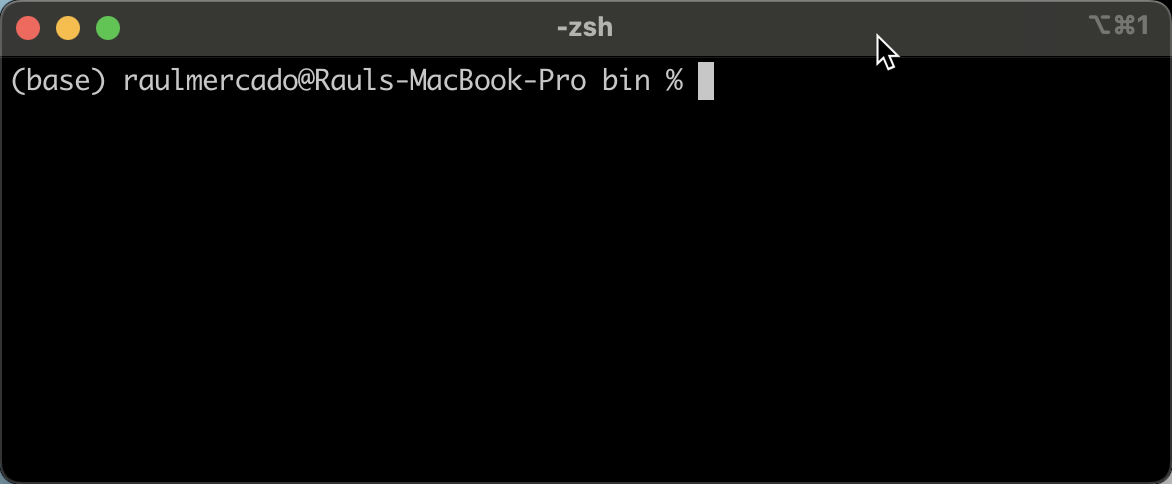
Puedes apreciar que al inicio del prompt, hay una palabra: (base). Esto se conoce como entorno (environment). Aquí es donde empieza lo divertido. Es casi seguro que vas a tener muchos proyectos de Data Science, y cada uno de esos proyectos va a necesitar un conjunto de librerías distintos. Claro, hay librerías que son muy comunes a todos los proyectos, pero habrán otras que no lo son.
Lo otro que nos podemos encontrar es la dependencia de versiones. Normalmente las librerías (o también llamados paquetes) necesitan de otras librerías. Sin embargo, como las librerías se van actualizando, es necesario especificar también que versión específica de esas librerías se necesitan, porque a veces cuando aparecen nuevas versiones, la funcionalidad puede cambiar y el código ya no se va a ejecutar igual.
Lo mismo puede pasar con tus proyectos de ciencia de datos. Puede que tu proyecto A necesite la versión 1.0 de la librería X. Y después de un año, tu proyecto B necesite la versión 2.0 de la librería X. ¿Cómo haces para que tu proyecto A no se corrompa? Bienvenido a los ambientes, o en inglés, environments.
Los environments son espacios de trabajo que cuentan con su propio conjunto de librerías, por lo que dos espacios de trabajo pueden tener versiones distintas de las mismas librerías sin que éstas colisionen. Puedes tener un environment que se llame ProyectoA, y otro environment que se llame ProyectoB, y las librerías de estos dos proyectos nunca se van a juntar. Fantástico ¿no?.
Volviendo al tema del prompt, ¿recuerdas de la palabra (base)? Pues es es el entorno por defecto con el que viene conda. Eventualmente, con el paso del tiempo, tendrás varios entornos, y para listarlos deberás ejecutar el siguiente comando:
conda env list
Te mostrará algo similar a lo siguiente:
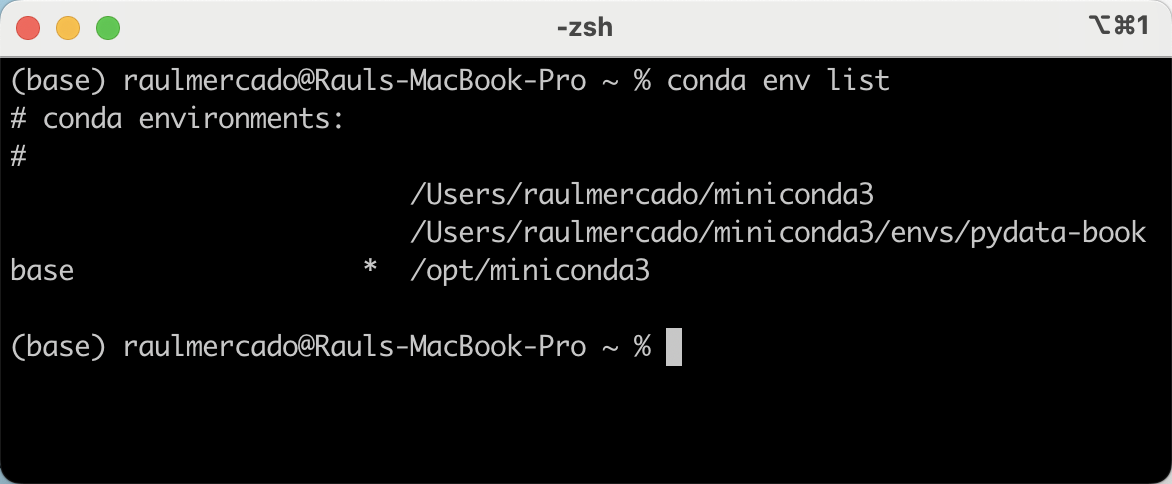
Podemos ver que en esta lista hay 3 columnas, la primera muestra el nombre del environment, que por ahora solo muestra (base), luego vemos un asterisco, lo que significa que es el environment por defecto, y finalmente la ruta desde donde se carga miniconda.
Vamos a crear un nuevo ambiente que lo llamaremos prueba:
conda create --name prueba
Durante el proceso de creación, te va a pedir si deseas continuar, presionamos la tecla "y". Después de ello ya tenemos nuestro nuevo ambiente creado. Volvemos a ejecutar conda env list para ver ahora nuestro flamante nuevo ambiente:
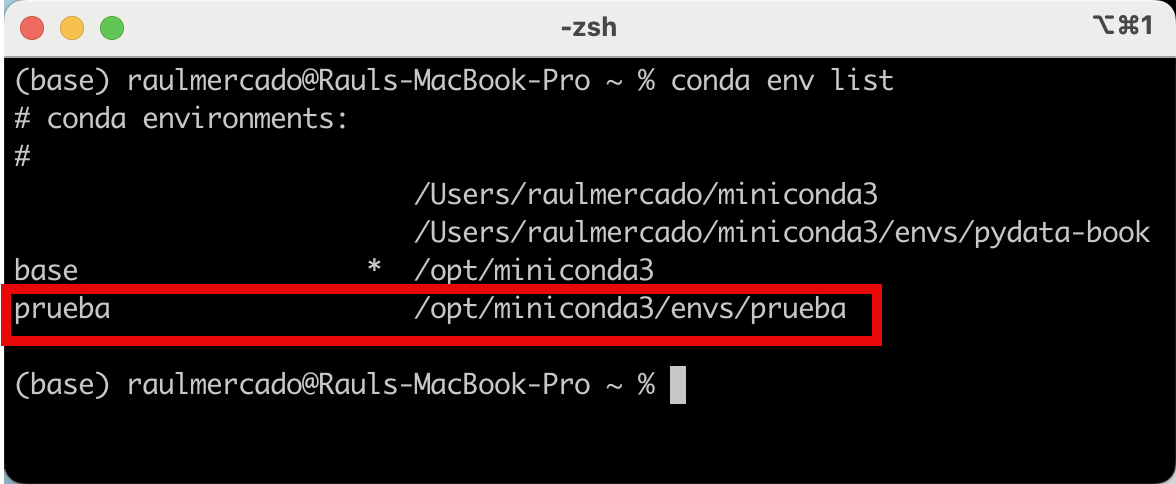
Como aún el ambiente por defecto es base, necesitamos hacer el cambio al nuevo ambiente prueba; para ello ejecutamos:
conda activate prueba
ahora podemos ver que prueba es el ambiente por defecto:
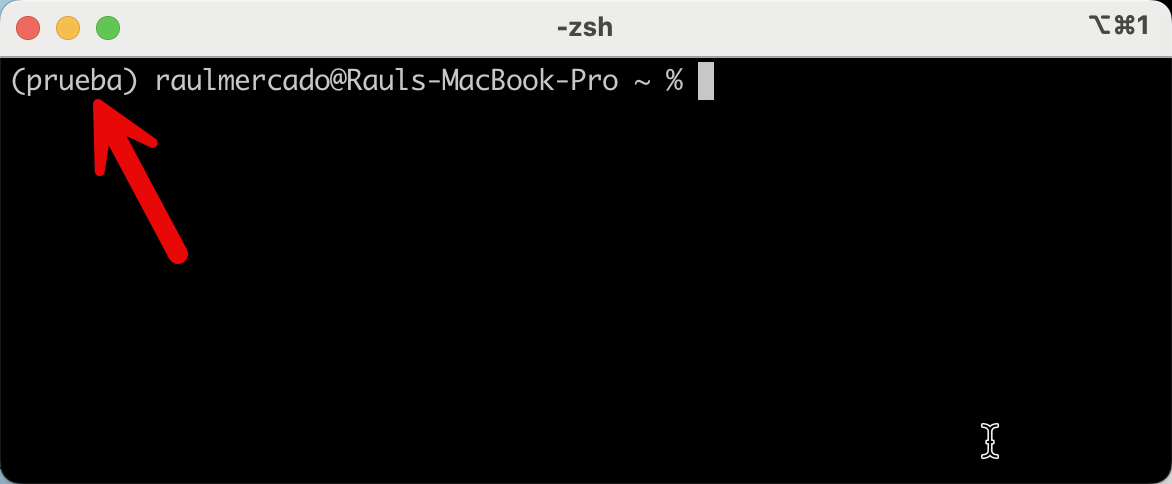
Ahora necesitamos habilitar Jupyter en este nuevo environment. Para ello vamos a necesitar instalar el paquete jupyter, ejecutando el siguiente comando:
conda install jupyter
Después de pedirte la confirmación de la instalación, procederá a realizar la instalación no solo del paquete jupyter, sino de todas las dependencias que necesita para que se pueda ejecutar satisfactoriamente.
Si deseas ver la lista de paquetes que se han instalado en tu environment, ejecuta el siguiente comando:
conda list
Si, ya se, no te esperabas una lista tan grande de paquetes, siendo que solo instalaste Jupyter, pero que le podemos hacer! Esas son todas las dependencias que Jupyter necesita. Dentro esa lista vemos que el paquete Jupyter se ha instalado:
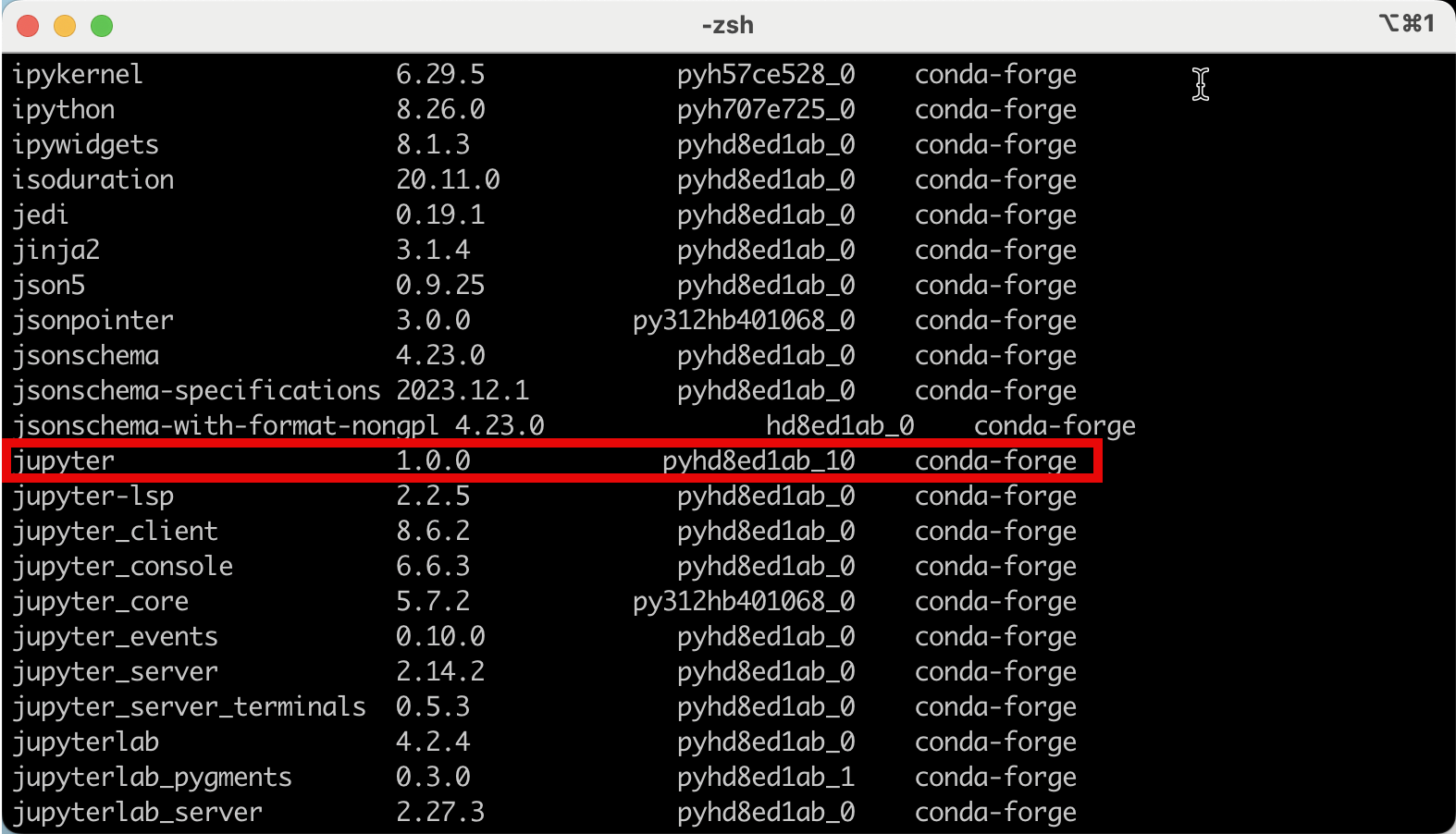
Ahora ya podemos abrir nuestro primer notebook, simplemente ejecutamos:
jupyter notebook
Y esperamos a que el servicio se ejecute en el browser. Veremos algo similar a esto:
Para este momento te recomiendo que tengas una carpeta de trabajo de tus notebooks. En esta misma interfaz web podemos navegar hasta esa carpeta, en mi caso es la siguiente:
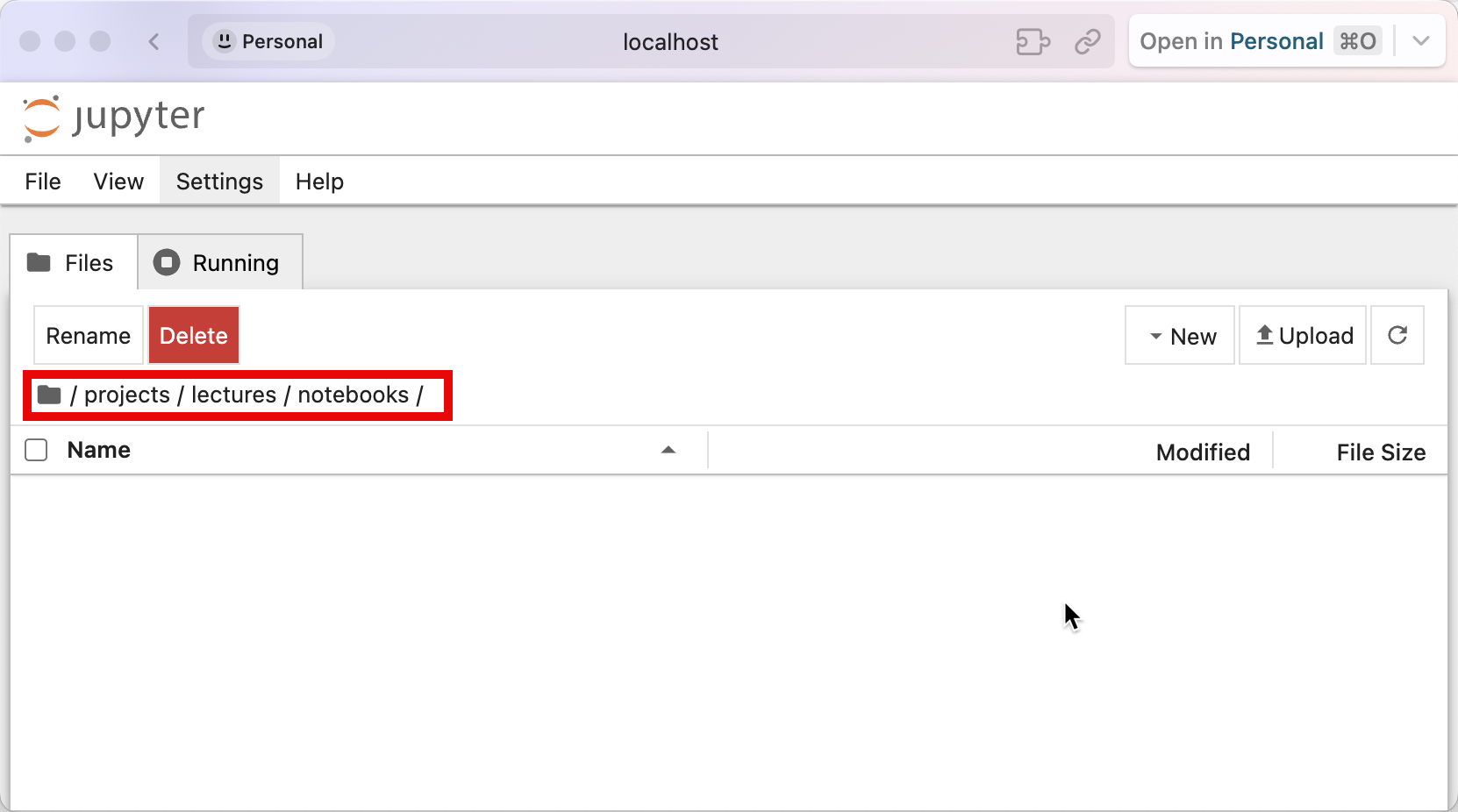
Damos click en new y elegimos Python3 (ipykernel)
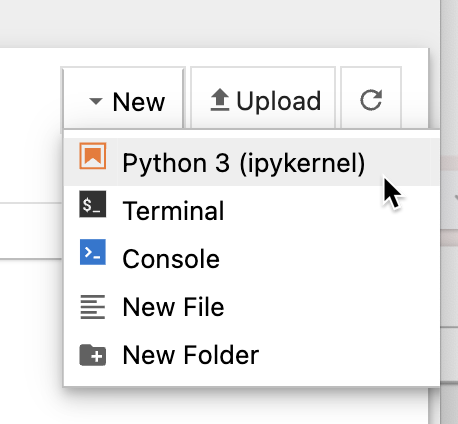
Te va a cargar un notebook nuevecito, listo para ser usado:
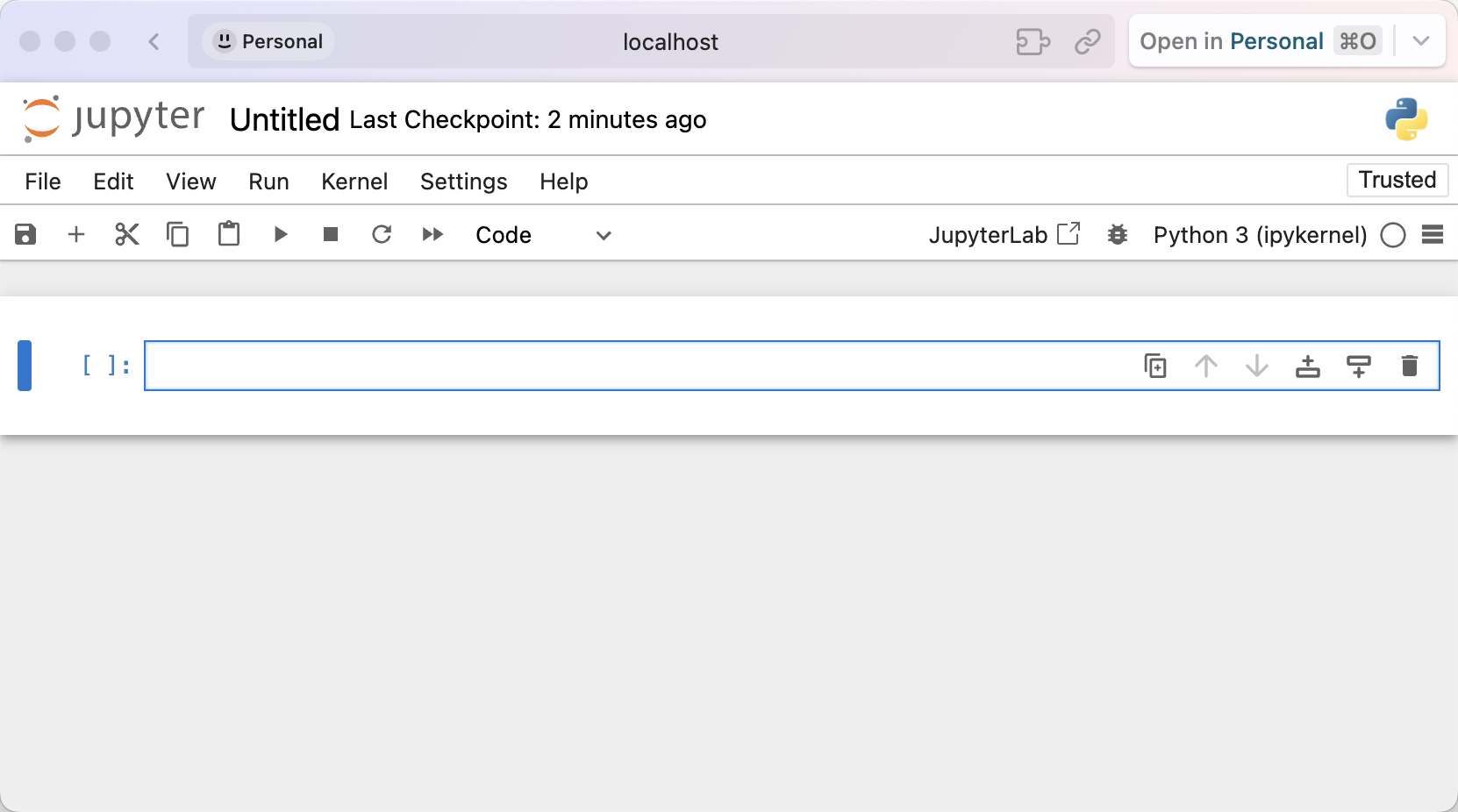
El rectángulo azul que ves se llama celda, y un notebook se compone de muchas de ellas. Vamos a ejecutar nuestro primer hola mundo allí, escribimos:
print("Hola mundo!")
El código que acabamos de escribir está hecho en Python. Para poder ejecutar esa celda, hacemos click en el botón play:
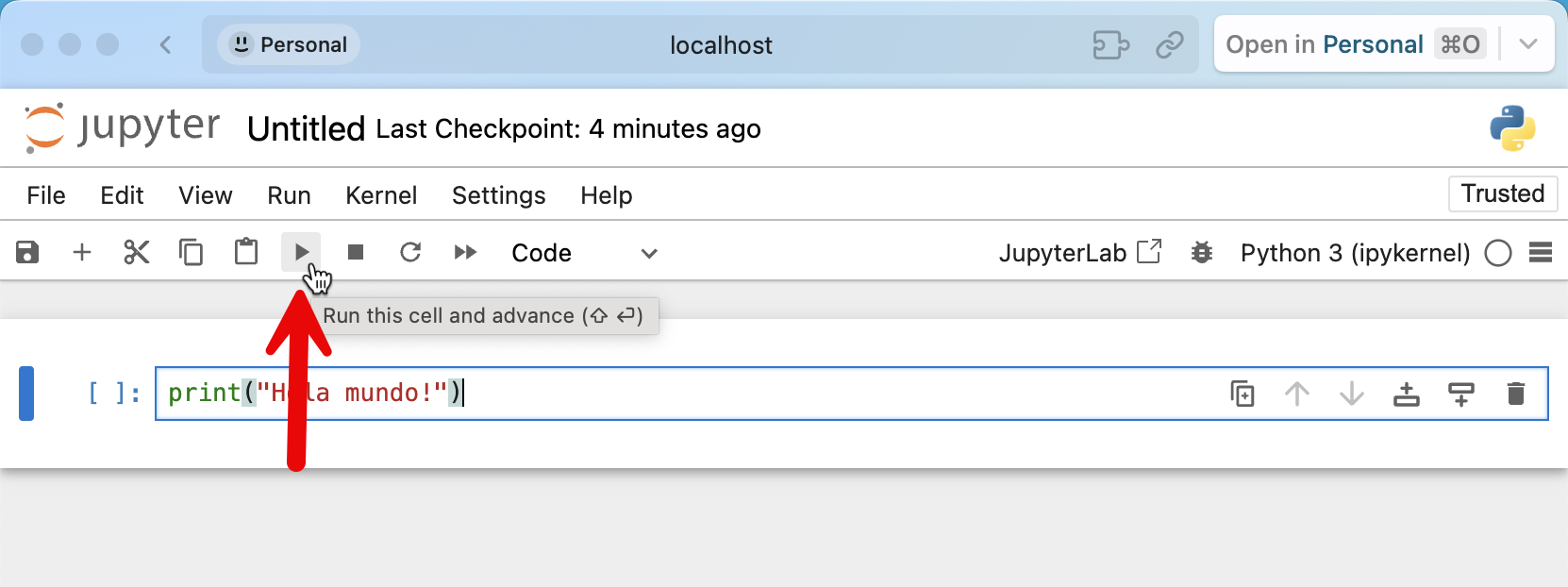
¡Y tendremos nuestra primera ejecución! ¡Felicitaciones! Has ejecutado tu primer notebook de forma satisfactoria. A partir de aquí podríamos continuar con la sintaxis de Python, pero creo que por ahora es suficiente. ¡Nos vemos en un próximo post!
Subscribe to my newsletter
Read articles from Raul Mercado directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by