Apache Dubbo Explained
 Harshit Nagpal
Harshit Nagpal
Suppose you are living in an era before messaging was invented now your friend lives in a different city and you want to send a message to your friend.
How will you be able to do that? ………… You will use some courier or mail services.
Now, when we think about this, it feels like it is a task with a lot of burdens, So when messaging was invented it was a big relief for the entire world, now we can communicate, with our friends and family who live far from us, with the help of messaging we all can seamlessly communicate with anyone we want to without any hassle, the whole process is so smooth and fast.
Apache Dubbo is a high-performance RPC (Remote Procedure Call) framework. In simpler terms, it's a way for different applications or services to communicate with each other.
In simple terms, we can think of APACHE DUBBO as WhatsApp for software.
UNDERSTANDING DISTRIBUTED SYSTEMS
Now before we dive deeper into what is Apache dubbo and what problem it solves. We need to understand some basic terms so that we can have a better context to understand its entire functionality.
As the name suggests distributed systems are simply just a bunch of systems or computers connected to communicate with each other and handle very heavy tasks together so that the task can be finished very quickly and the load is equally distributed among all the interconnected computers.
Why Use Distributed Systems?
Scalability: If you need more power or storage, you can add more nodes rather than needing to upgrade one giant machine.
Reliability: If one node fails, others can potentially take over, preventing a complete system shutdown.
Performance: Tasks can be divided and executed simultaneously across multiple nodes, potentially speeding up overall processing.
Geographic Distribution: Nodes can be located closer to users around the world, reducing latency (delays) in accessing data or services.
For more depth, you can refer to these links:
https://www.splunk.com/en_us/blog/learn/distributed-systems.html
UNDERSTANDING RPC FRAMEWORK
Now above, we talked about distributed systems, but because these systems are distributed and softwares running on multiple computers needs to be connected the question arises how do they connect with each other? …………………They do so by using frameworks like RPC.
We all do online transactions and most of us are well aware of its procedure, when we authenticate, the authentication, request goes out to the server somewhere present in the world, and then from there, it invokes an OTP notification response. Now in most cases, it is done with the help of REST and HTTP, but it is very complex to deploy each and every endpoint in your code, and with every endpoint, the request is going out again and again.
Now this is the problem that is solved by RPC. It takes out the complexities. It makes the communication call look so easy that it seems to us that it is a local call but internally it is a remote network call. RPC is a way to standardize the way of communication no matter what language you are using, no matter how you are working, and no matter which ecosystem you are in. It is all uniform.
RPC makes our code so beautiful by taking out the complexities, that we don't even need to worry about how this remote call is happening.
HOW DOES RPC WORK INTERNALLY?
Let's break down the internal workings of a typical RPC framework.
CORE COMPONENTS
Stubs (Client & Server): These are the pieces of code that make the 'magic' of RPC happen.
Client Stub: This pretends to be the actual remote function on the client side. It handles packaging call data and sends it to the server.
Server Stub: Unpacks the request, calls the real function on the server, and packages the result to send back.
Serialization/Marshalling:
Marshaling: The process of converting function names, parameters (e.g., numbers, objects), and other data into a standard format suitable for transmitting over the network. Popular formats include JSON or Protocol Buffers.
Unmarshalling: The reverse process - taking the network message and extracting the data to be used by the remote function.
Network Transport: The underlying mechanism that carries the messages between the client and server. This is often built on top of standard networking protocols like TCP or HTTP.
RPC Runtime: The engine of the framework that handles client stub creation, network communication management, data format conversions, and error handling.
Step-by-Step Process
Client Call: The client program makes what looks like a normal function call, but it's really calling the client stub.
Stub Magic: The client stub:
Gathers the function name and arguments.
Marshals these into a standard message format.
Uses the RPC runtime to send the message over the network to the server.
Reaching the Server: The server-side RPC runtime receives the message.
Server-Side Handling:
The server stub unmarshals the message to obtain the original function name and arguments.
Calls the actual remote function with the provided parameters.
Packing the Response:
The server stub marshals the function's return value into a message.
The RPC runtime sends this message back to the client.
The Illusion Completes:
The client-side RPC runtime receives the response.
The client stub unmarshals the data.
Returns the value to the client application as if the original local function call just finished.
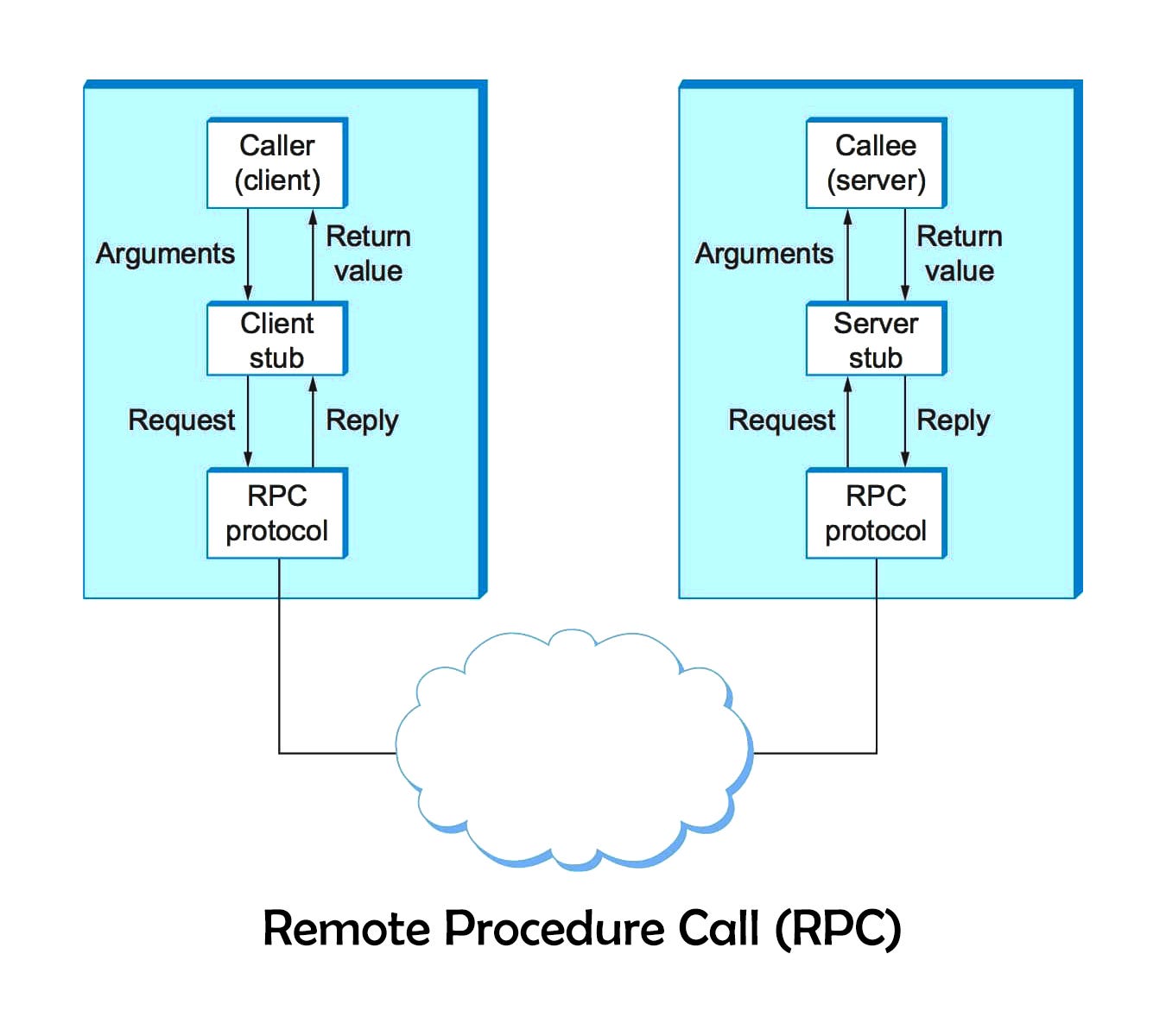
Image Credit: RPC
HISTORY OF APACHE DUBBO
Early Beginnings
Alibaba's Challenge: Back in the late 2000s, Alibaba, the Chinese e-commerce giant, faced the immense challenge of scaling its rapidly growing online marketplace. They had a complex system of interconnected services that needed to communicate efficiently.
The Birth of Dubbo (2008-2011): Alibaba's engineers developed Dubbo in-house as an RPC framework to address their specific needs for:
High Performance: Handling Alibaba's massive scale.
Service Management: Seamlessly managing and coordinating a large number of services.
Resilience: Ensuring their distributed system remained stable in the face of failures.
Open Source Journey
2011-2012: Alibaba realized the potential benefits of sharing Dubbo with the wider developer community and open-sourced it.
Gaining Popularity: Dubbo quickly gained traction, especially in China, due to its performance, reliability, and features catering to distributed systems.
Community Growth: A vibrant community of developers and companies began contributing to and using Dubbo.
Donation to Apache Software Foundation
2018: Dubbo reached a major milestone by becoming an Apache incubator project. This signified its maturity and wider adoption.
2019: Dubbo graduated as a top-level Apache project, solidifying its standing in the open-source world.
INTRODUCTION TO APACHE DUBBO
Under the banner of microservices, Apache Dubbo simplifies life for developers by handling service communication and governance. This open-source framework, available in languages like Java and Golang, lets microservices seamlessly discover and chat with each other. Its built-in governance features streamline tasks like service discovery, load balancing, and traffic control. Designed for scale, Dubbo empowers you to tailor traffic routing and logging with custom logic. The next-generation, cloud-native Dubbo3 builds upon this foundation, enhancing the ease of use, security, and ability to handle massive microservice deployments within a cloud infrastructure.
Dubbo Architecture: A Layered Journey
Dubbo adopts a layered architecture, separating concerns and promoting modularity. Each layer interacts with others to provide efficient service communication and governance. Here's a breakdown:
1. Service Interface Layer:
Defines service contracts through interfaces and methods, acting as a blueprint for communication.
Decouples providers and consumers, enabling independent development and evolution.
2. Service Implementation Layer:
Where the actual business logic resides, written in various languages supported by Dubbo.
Providers implement the service interface, while consumers call these methods to access functionality.
3. Remote Procedure Call (RPC) Layer:
Handles the technical aspects of remote invocation, including serialization, network communication, and deserialization.
Dubbo supports multiple protocols like Dubbo, HTTP, and gRPC, offering flexibility based on your needs.
4. Cluster & Router Layer:
Ensures high availability and scalability of services.
Clusters manage pools of providers, distributing incoming requests among them using load-balancing strategies.
Routers enable selective routing based on predefined rules (e.g., user ID, version).
5. Registry Layer:
Acts as a central repository for service metadata (provider locations, interfaces, etc.).
Consumers discover available services through the registry.
Dubbo supports multiple registry options (ZooKeeper, Consul, etc.) for flexibility and redundancy.
6. Container Layer:
Provides a lightweight runtime environment for both providers and consumers.
Popular containers include Spring Boot and Spring Cloud, managing the lifecycle of services and facilitating communication.
7. Monitor Layer:
Collects statistics on service calls, providing insights into performance and usage patterns.
This layer is crucial for troubleshooting issues and optimizing service deployment.
8. Extension Points:
Allow for customization of various aspects through plugins and custom implementations.
This enables tailoring Dubbo to specific needs and integrating with diverse technologies.
Key Architectural Principles:
Loose Coupling: Separates service interfaces from implementation, promoting independent development and evolution.
Decentralization: No central coordinator or server, making the system fault-tolerant and scalable.
Extensibility: Modular design allows for customization through extension points.
Multi-protocol Support: Enables communication across diverse environments and languages.
Service Governance: Built-in features for service discovery, load balancing, traffic shaping, and monitoring.
Beyond the Layers:
Mesh Service Integration: Dubbo integrates seamlessly with service mesh solutions like Istio for advanced traffic management and security.
Cloud-Native: Dubbo3 emphasizes cloud-native development, working well with Kubernetes and other cloud infrastructure.
Remember: This is a simplified overview. Each layer possesses sub-components and intricate interactions. Dubbo's documentation and official website provide further in-depth details for exploration.
ARCHITECTURE
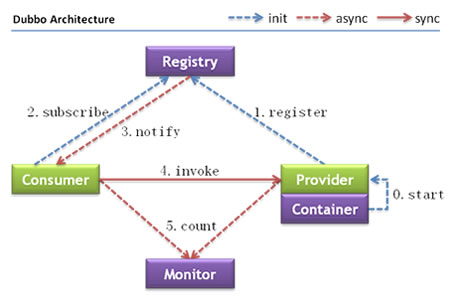
Node role description
| Node | Role Description |
| Provider | The service provider of the exposed service |
| Consumer | The service consumer who invokes the remote service |
| Registry | Registry for service registration and discovery |
| Monitor | A monitoring center that counts service calls and call times |
| Container | service running container |
DESCRIPTION OF CALLING RELATIONSHIPS
The service container is responsible for starting, loading, and running the service provider.
When the service provider starts, it registers the services it provides with the registration center.
When a service consumer starts, it subscribes to the registration center for the services it needs.
The registration center returns the service provider address list to the consumer. If there is a change, the registration center will push the change data to the consumer based on the long connection.
The service consumer, from the provider address list, selects a provider to call based on the soft load balancing algorithm, and if the call fails, selects another provider to call.
Service consumers and providers accumulate the number of invocations and invocation time in memory, and regularly send statistical data to the monitoring center every minute.
The Dubbo architecture has the following characteristics, namely connectivity, robustness, scalability, and upgradeability to future architectures.
SERVICE GOVERNANCE: THE HEART OF DUBBO
Service Registry and Discovery: To facilitate seamless communication between microservices, Dubbo employs service registries such as Zookeeper, Nacos, or Consul. These service registries essentially function as central directories. Their primary role is to serve as a common platform where individual microservices can register their availability and specify their exact locations. This is a crucial aspect in a distributed system environment where services need to interact with each other frequently. By indicating their availability in a central registry, the microservices provide essential data that can be used for service discovery.
This system of centralized registration significantly optimizes the process of service discovery. It allows for a dynamic and automated process of discovering services, which is a huge step forward compared to the traditional method of hardcoded addresses. With hardcoded addresses, each service needs to know the exact location of other services it wants to interact with. This not only increases complexity but also makes the system rigid and difficult to manage.
On the other hand, with a dynamic discovery process facilitated by a service registry, services can easily find each other based on the data available in the registry. This eliminates the need for hardcoded addresses and enhances flexibility. As services come online or go offline, their status is updated in the registry. Other services can then access this updated information from the registry, allowing them to adapt to changes in real time and maintain continuous and efficient communication.
This dynamic discovery process not only simplifies inter-service communication but also contributes to the overall reliability and resilience of the system. In case of service failures or network issues, the system can quickly identify the problem based on the status data in the registry and initiate appropriate failover mechanisms. Thus, Dubbo's use of service registries for service registration and discovery is an integral part of its efficient and robust architecture.
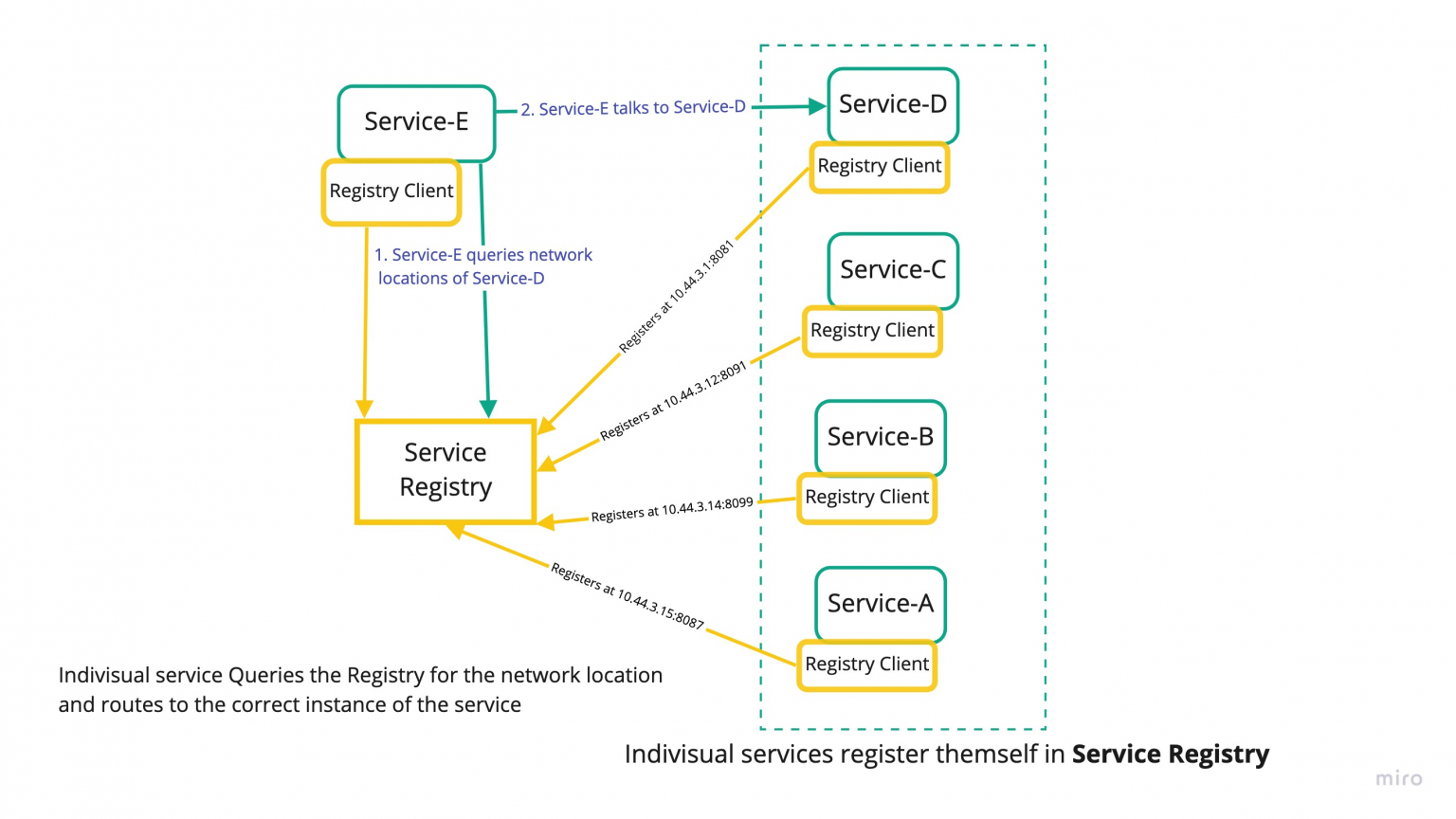
Image Credit: Service Discovery
In-Depth Overview of Load Balancing Strategies:
To streamline and optimize the distribution of incoming requests among available service instances, Dubbo employs a variety of algorithms, each with a unique approach to load balancing:
Random Strategy: As the name suggests, this strategy randomly selects a service instance to handle an incoming request. This method is akin to a lottery system where each service instance has an equal chance of being selected, regardless of the order in which they are arranged or their capacity. This approach is simple, and fair and ensures that every service instance has an opportunity to participate in processing requests. However, its major drawback is that it does not consider the load or capacity of each instance, which can lead to uneven distribution of requests if some instances are more powerful or less busy than others.
Round Robin Strategy: This strategy takes a more orderly approach by distributing incoming requests sequentially across all available instances. Imagine a group of people sitting in a circle and passing a ball around. The ball (request) goes from one person (instance) to the next in a cyclic manner, ensuring that each person gets a turn to hold the ball before it starts the rotation again. This method ensures a more even distribution of requests than the random strategy, but like the random strategy, it does not take into account the capacity of each instance.
Weighted Strategy: Taking a more nuanced approach, the weighted strategy assigns different weights to each service instance, thereby influencing the proportion of requests that each instance will handle. This strategy is akin to a weighted lottery, where instances with higher weights (i.e., higher capacity or efficiency) have a higher chance of being selected to process requests. This allows for more control over the distribution of requests and can lead to a more efficient use of resources, especially in scenarios where service instances have different capabilities or workloads.
Consistent Hashing Strategy: This strategy introduces a level of predictability and efficiency into the load-balancing process. It ensures that requests for the same data or resource consistently target the same service instance. Imagine a library where each book (request) has a designated shelf (instance). Whenever you want to find a particular book, you always know which shelf to look at. This strategy is particularly beneficial in scenarios where data locality and caching can improve system efficiency and reduce response times. However, it requires a good hashing function to ensure a uniform distribution of requests.
These strategies, when implemented correctly, can significantly enhance the performance and reliability of service communication in a distributed system. They ensure that no single service instance is overwhelmed with requests, while others remain idle. This leads to a more balanced and efficient use of resources, ultimately improving the overall user experience.
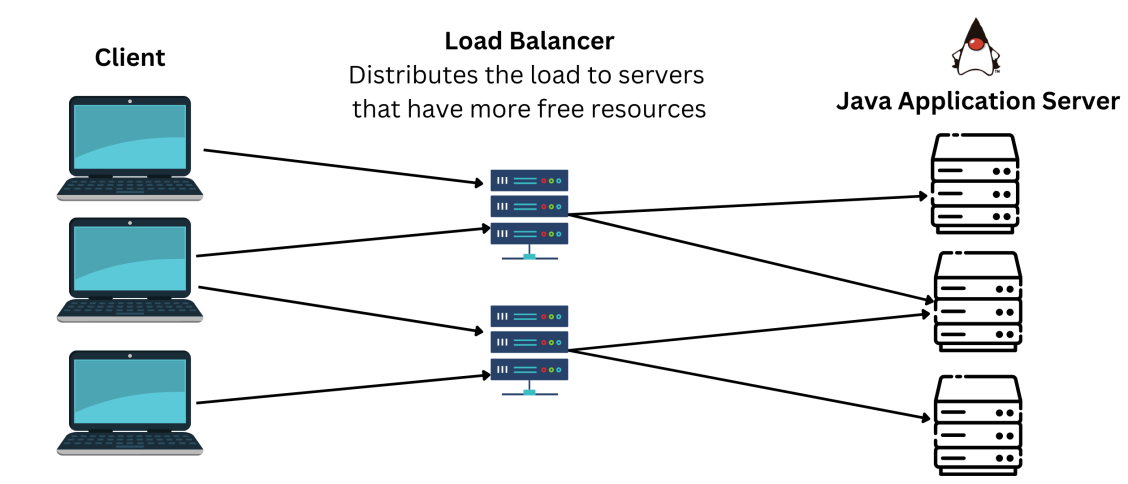
Image Credit: Load Balancing
Fault Tolerance:
Apache Dubbo is designed with a keen understanding of the complexities and challenges inherent in distributed systems. A crucial aspect of these challenges is the inevitability of failures. Whether it's due to network issues, hardware failures, or software bugs, problems can and will occur. To manage and mitigate the impact of these failures, Dubbo incorporates several robust mechanisms for fault tolerance:
Retries: This mechanism is designed to handle temporary failures that might occur due to transient network issues or momentary service unavailability. If a request fails for some reason, Dubbo doesn't just throw up its hands and give up. Instead, it attempts to resend the failed request a preset number of times. This retry logic can greatly improve the reliability of the system by ensuring that transient failures don't result in permanent request failures. It's akin to knocking on a door several times if there's no answer at first - sometimes, persistence pays off!
Failover: Failover is a critical feature in any distributed system. In the world of distributed services, it's possible that some service instances may become unavailable due to various issues. Dubbo is prepared for this. If it detects that a service instance is down or unresponsive, it doesn't just fail the request. Instead, it automatically redirects the request to another, alternative service instance. This failover mechanism ensures that the overall system availability is not compromised due to the failure of a single service instance. It's like having a backup plan when the first plan doesn't work out - the goal is still achieved, just through a different route.
Circuit Breakers: In an electrical system, a circuit breaker is a safety device that breaks the flow of electricity when there's a risk of an overload or short circuit. Apache Dubbo incorporates a similar concept in its architecture with its circuit breaker feature. This mechanism is designed to prevent cascading failures in the system by temporarily blocking requests to services that appear to be overloaded or unresponsive. Rather than allowing these issues to propagate through the system and potentially bring down other services, the circuit breaker 'trips' and stops the flow of requests to the problematic service. Once the service is back to normal, the circuit breaker resets, and requests can flow again. This proactive measure can be a lifesaver in ensuring the stability and resilience of the entire system in the face of localized issues.
These fault tolerance features make Apache Dubbo a reliable choice for managing communication in distributed systems. By expecting and preparing for failures, Dubbo ensures that your distributed applications remain available and responsive, providing a seamless experience for your users.
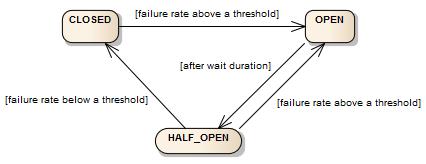
Traffic Control:
Dubbo provides a comprehensive set of tools to precisely manage and control service interactions, ensuring high performance, stability, and adaptability in a distributed environment. Here are some key traffic control features:
Rule-based Routing: Dubbo empowers developers to direct traffic based on customizable rules. This means that network traffic can be intelligently routed according to various parameters, such as the service version, the geographical region from which it's being accessed, or specific user attributes. For example, you could set up rules that direct users of a certain version of your app to specific versions of your services, or route traffic differently based on the user's geographical location to provide a consistent user experience across different regions. This affords you a high degree of flexibility and control in managing your services, allowing you to optimize network traffic and resource usage to meet your specific requirements.
Blue-Green Deployments: Dubbo supports blue-green deployment strategies, a major advantage when it comes to maintaining service uptime and minimizing disruption during updates or changes. This feature enables the gradual rollout of new versions of services, allowing you to test and introduce new features while keeping the current live version (blue) intact. Once the new version (green) is fully tested and ready, traffic can gradually be shifted from the blue environment to the green one. This ensures a smooth transition and minimizes the risk of disruptions or negative impacts on users.
Rate Limiting: To ensure your services remain stable and responsive even under heavy load, Dubbo provides a rate-limiting feature. This allows you to limit the volume of incoming requests within a certain time window. For instance, if you know your service can comfortably handle 1000 requests per minute, you can set this as a limit to prevent your service from being overwhelmed by an unexpected surge in traffic. This protective measure is crucial for maintaining service availability and responsiveness, preventing system crashes, and delivering a reliable user experience.
DUBBO’S TRIPLE PROTOCOL
Introduction
The Triple agreement is an HTTP-based RPC communication protocol specification designed by Dubbo3. It is fully compatible with the gRPC agreement and supports communication models such as Request-Response and Streaming flow, which can run simultaneously on HTTP/1 and HTTP/2.
The Dubbo framework provides a multilingual realization of the Triple Agreement. They can help you build browsers, and gRPC-compatible HTTP API interfaces: you only need to define a standard Protocol Buffer format service and realize business logic. Dubbo is responsible for helping to generate language-related Server Stub, Client Stub, And seamless access to the entire call process such as routing, service discovery, etc. Dubbo system. The Triple agreement in Go, Java, and other languages realizes support for HTTP/1 transmission layer communications. Compared to the official realization of gRPC, the agreement provided by the Dubbo framework is simpler and more stable, helping you to develop and manage micro-service applications more easily.
For some language versions, the Dubbo framework also provides a programming model that is more in line with language characteristics, that is, the service definition and development model that does not bind IDL. For example, in Dubbo Java, you can choose to use Java Interface and Pojo definition Dubbo service, And publish it as a microservice based on Triple protocol communication.
Agreement Specification
Based on the Triple agreement, you can achieve the following goals:
When Dubbo as Client
Dubbo Client can access the Triple protocol service issued by Dubbo Service End (Server), as well as the standard gRPC service end.
Call standard gRPC service end, send Content-type request for standard gRPC type: application/grpc+proto, and application/grpc+json
Call Dubbo service end, send Content-type request for Triple type: application/JSON, application/triple+wrapper
When Dubbo as Server
Dubbo Server defaults to release support for the Triple and gRPC agreements simultaneously, and the Triple agreement can work simultaneously on HTTP/1, and HTTP/2. Therefore, the Dubbo Server can process the Triple agreement request sent by the Dubbo customer, the standard gRPC agreement request, and the HTTP request sent by the cURL and browser. The distinction between Content is:
Processing requests of Content-type sent by gRPC customers as standard gRPC type: application/grpc, application/grpc+proto, application/grpc+json
Processing requests of Content-type for Triple type sent by Dubbo client: application/json, application/proto, application/grpc+wrapper
Handling requests for Content sent by cURL, browser, etc. for Triple type: application/json, application/proto, application/grpc+wrapper
Check the details here Triple Specification.
Relationship with gRPC agreement
As mentioned above, Triple is fully compatible with the gRPC agreement. Since gRPC has officially provided a multilingual framework, why does Dubbo have to re-implement it through Triple? The core objectives mainly include the following two points:
First of all, in terms of protocol design, Dubbo refers to the two agreements between gRPC and gRPC-Web to design a self-defined Triple agreement: Triple is a RPC agreement based on the HTTP transmission layer agreement, which is fully compatible with gRPC and can run at HTTP/1, HTTP/2 above.
Secondly, the Dubbo framework follows the design concept that conforms to the positioning of the framework itself in the realization of each language. Compared with the framework library such as grpc-java and grpc-go, the Dubbo agreement is simpler and more pure, and attempts to circumvent gRPC. A series of problems in the official library.
gRPC itself is very good as an RPC agreement specification, but we found that there are a series of problems in the actual use of the native gRPC library, including the realization of complexity, binding IDL, difficulty in debugging, etc., Dubbo starts from practice in agreement design and realization, very Good evasion of these problems:
The native gRPC is limited to the HTTP/2 interactive specification, and cannot provide an interactive method for browsers and HTTP API. You need additional proxy components such as grpc-web, grpc-gateway to achieve. In Dubbo, you can directly access the Dubbo HTTP/2 service with curl and browser.
The gRPC official library compulsorily binds Proto Buffer. The only development option is to use IDL to define and manage services, which is a very large burden of use for some users with low multilingual demands. Dubbo, while supporting IDL, provided language-specific service definitions and development methods for Java, Go, etc.
In the development stage, the services released under the gRPC agreement are very difficult to debug. You can only use gRPC-specific tools, many of which are relatively rudimentary & immature. Starting from Dubbo3, you can directly use curl | jq or Chrome developer tools to commission your service, and you can call the service directly by entering the JSON structure.
First, the gRPC agreement library has a scale of more than 100,000 lines of code, but Dubbo (Go, Java, Rust, Node.js, etc.) has only a few thousand lines of code for the realization of the agreement, which makes code maintenance and problem investigation easier.
The gRPC realization library provided by Google does not use mainstream third-party or language official agreement libraries but chooses to maintain a set of implementations by itself, making the entire maintenance and ecological expansion more complicated. For example, grpc-go has maintained an HTTP/2 library instead of the go official library used. While Dubbo used the official library, it maintained the same performance level compared to the HTTP agreement library maintained by gRPC itself.
The gRPC library only provides the realization of the RPC agreement, which requires you to do a lot of extra work to introduce service governance capabilities. Dubbo itself is a micro-service development framework that does not bind the agreement. The implementation of the built-in HTTP/2 agreement can be better linked to Dubbo's service governance capabilities.
Simple
The Dubbo framework focuses on the Triple agreement itself, and the selection of the bottom network communication, HTTP/2 protocol analysis, etc. depends on those network libraries that have undergone long-term inspection. For example, Dubbo Java is built on Netty, and Dubbo Go is the official Go HTTP library directly used.
The Triple agreement provided by Dubbo is very simple, corresponding to the protocol component in Dubbo. You can figure out the code of the Dubbo agreement in just one afternoon.
Mass production environment inspection
Since the release of Dubbo3, the Triple agreement has been widely applied to Alibaba and many community benchmark companies, especially some agents and gateway communication scenes. On the one hand, Triple has been proven to be reliable and stable through large-scale production practices. On the other hand, Triple's simple, easy to debug, and unbound IDL design are also important factors for its widespread application.
Native multi-protocol support
When the service is released externally with the Dubbo framework as the service end, you can support the Triple, gRPC, and HTTP/1 agreements at the same port, which means you can access the services issued by the Dubbo service end in various forms. All requests will eventually be forwarded to the same business logic to realize, This provides you with greater flexibility.
Dubbo is fully compatible with gRPC agreements and related features including streaming, trailers, error details, etc. You choose to use the Triple agreement ( directly in the Dubbo framework. In addition, you can also choose to use the original gRPC agreement ), and then you can directly Use the Dubbo client, curl、Browser waiting to access the service you posted. In terms of ecological interoperability with gRPC, any standard gRPC client can normally access Dubbo service; Dubbo client can also call any standard gRPC service, which is provided here Examples of interoperability
The following is an example of using cURL customer access Dubbo service end Triple protocol service:
curl \\
--header "Content-Type: application/json" \\
--data '{"sentence": "Hello Dubbo."}' \\
<https://host>:port/org.apache.dubbo.sample.GreetService/sayHello
One-stop service governance access
We all know that Dubbo has rich micro-service governance capabilities, such as service discovery, load balance, traffic control, etc., which is also the advantage of our development and application using the Dubbo framework. To use gRPC protocol communication under the Dubbo system, there are two ways to achieve it. One is to introduce the officially released binary package of gRPC directly in the Dubbo framework, and the other is to provide the source code of gRPC agreement compatibility within Dubbo. achieve.
Compared to the first way to introduce binary dependence, the Dubbo framework was implemented through the built-in Triple agreement, which originally supported the gRPC agreement. The advantage of this method is that the source code is completely controlled by itself, so the realization of the agreement is more in line with the Dubbo framework. Close,A service governance system that can more flexibly access Dubbo.
Java Language
In the implementation of the Dubbo Java library, in addition to the IDL method, you can use the Java Interface method to define services, which can greatly reduce the cost of using gRPC protocols for many Java users who are familiar with the Dubbo system.
In addition, the Java version of the agreement is basically the same in performance as the grpc-java library, and even in some scenarios, the performance is better than grpc-java. And all this is based on the fact that the realization of the Dubbo version agreement is much less complicated than the gRPC version because grpc-java maintains a set of customized versions of the netty agreement.
Go Language Realization
Dubbo Go recommends the IDL development model. The protocol inserts supporting Dubbo are used to generate stub codes. You only need to provide the corresponding business logic to realize it. You can access the gRPC service released by Dubbo Go through curls and browsers.
CONCLUSION
In conclusion, Apache Dubbo stands as a robust open-source framework designed to simplify the challenges of microservices communication and governance. With support for languages like Java and Golang, Dubbo enables seamless interaction among microservices, emphasizing loose coupling and decentralized architecture.
Dubbo's layered architecture organizes functionalities into distinct layers, each responsible for specific aspects of service communication and governance. From service interface definition to remote procedure calls, cluster management, and registry functionalities, Dubbo's architecture is built for scalability and extensibility.
The heart of Dubbo lies in its service governance features, utilizing service registries for dynamic service discovery and load-balancing strategies such as random, round-robin, and weighted approaches. The framework ensures fault tolerance through mechanisms like retries, failover, and circuit breakers, acknowledging the inherent challenges of distributed systems.
Dubbo goes beyond the basics with advanced traffic control mechanisms, offering rule-based routing, blue-green deployments, and rate limiting for optimized service interactions. The framework integrates seamlessly with service mesh solutions like Istio and emphasizes cloud-native development, aligning well with Kubernetes and other cloud infrastructures.
A notable feature is Dubbo's Triple Protocol, an HTTP-based RPC communication protocol that is fully compatible with gRPC. Dubbo's Triple Protocol simplifies service development by providing language-specific service definitions without the need for Interface Definition Language (IDL). This simplicity, combined with its extensive use in large-scale production environments, highlights Dubbo's practicality and reliability.
In essence, Dubbo emerges as a comprehensive solution for managing microservices communication, offering a well-architected framework with a focus on simplicity, flexibility, and adaptability to diverse environments and languages. Developers can leverage Dubbo's features to build scalable, fault-tolerant, and highly performant microservices architectures.
Subscribe to my newsletter
Read articles from Harshit Nagpal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by