Domain Driven Design의 구현
 Jong-Dae Park
Jong-Dae Park1] 잘못된 Domain Model(Anemic Domain Model)
1. Technical Responsibilities에 따라 분리한 package
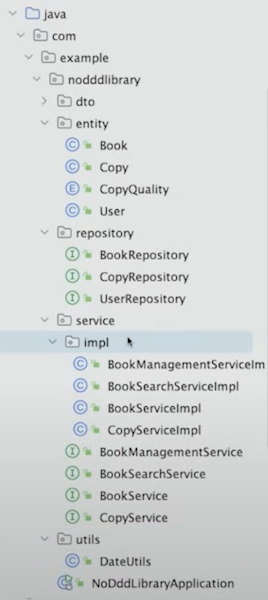
DTO, Entity, Repository 등으로 technical responsibilities에 따라 단순히 분리하였다.
2. 도메인 모델이 아닌 mutable한 JPA Entity
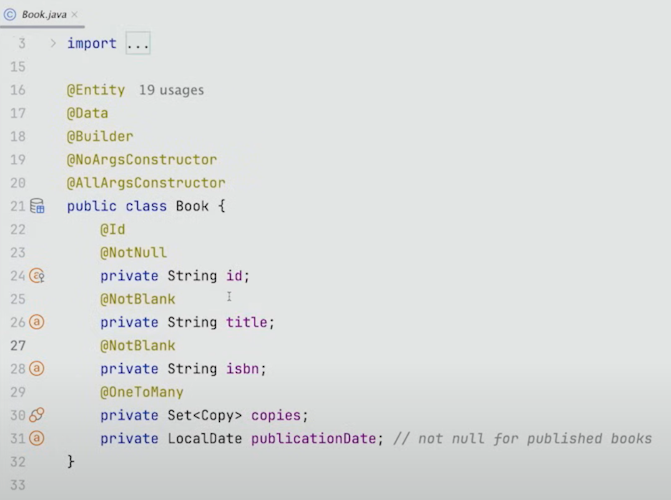
Book이 도메인 모델처럼 보이지만, 실제로는 단지 JPA Entity를 표현하고 있는 것을 볼 수 있다. 또한 mutable하다.
3. 비슷한 이름의 다수의 Services
이 애플리케이션에서 로직이 어떻게 일어나는지, 어떻게 사용해야 하는지 알기 위해서는 service class를 가야 한다.

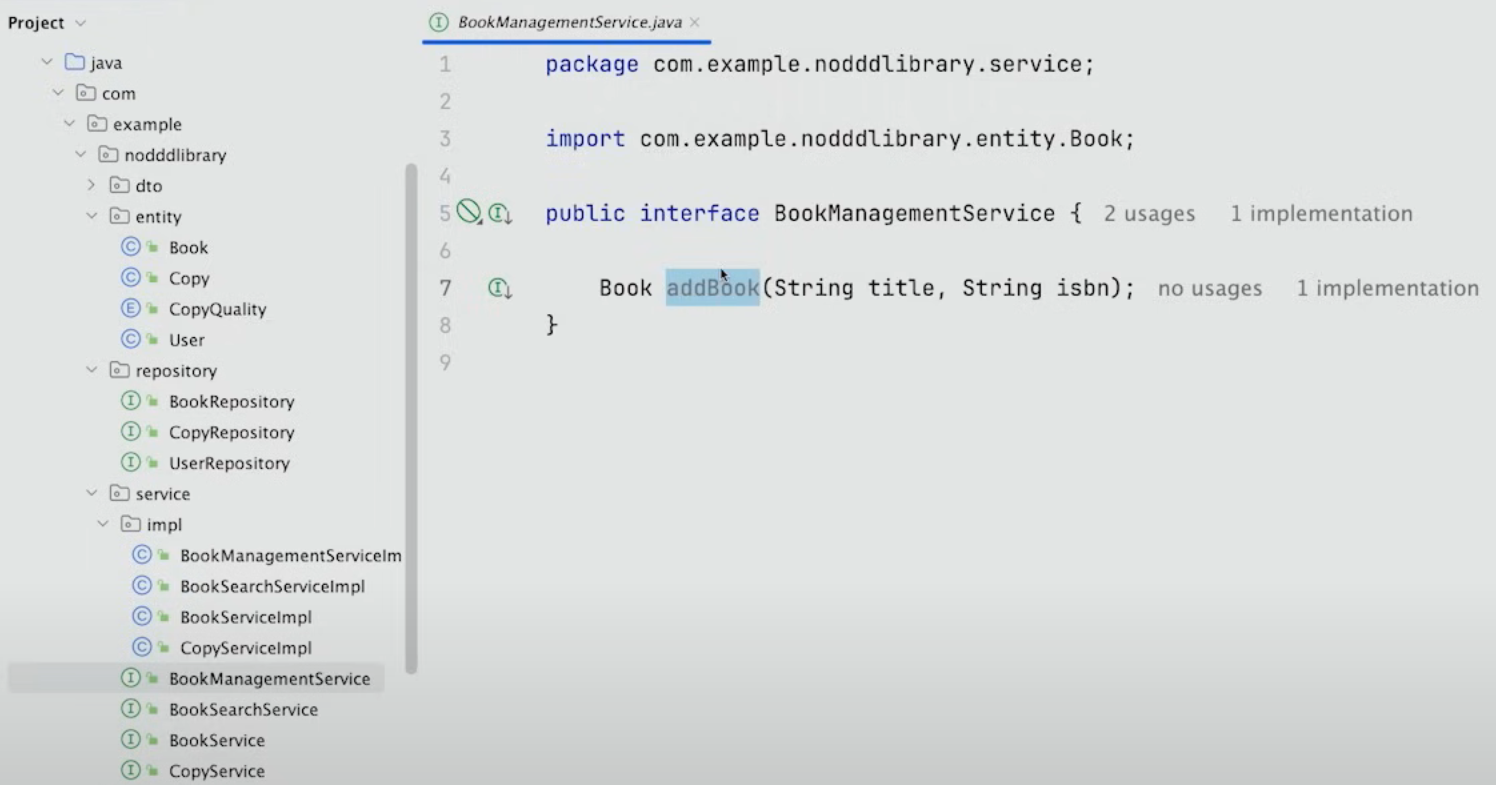
다만 이렇게 BookManagementService와 BookService가 있을 경우 어떤 것을 사용해야 될지, 두 서비스의 책임이 뭔지 혼란스럽게 된다.
4. 특징
Anemic Domain Model의 특징은 다음과 같다.
어떤 것이 가능한지, 어떤 것이 유효하고 유효하지 않은지와 모든 상태변화, 로직이 이런 서비스에 구현되어 있다.
Entity가 있지만, Entity에 business rule을 구현한 것이 아니고 단순히 data container의 역할로서만 사용된다.
토이 프로젝트나 작은 프로젝트, 서비스에 적용 가능하다.
프로젝트의 크기가 점점 커질수록, 한 서비스 클래스에 연관되지 않은 수많은 메서드가 존재하게 되어 점점 커지게 되고 서비스 클래스는 다양한 책임을 가지게 된다.
그 이유는 다음 그림 같은 메서드들이 Controller등에 데이터를 expose하기 위해서 만들어지기 때문에, 다른 애플리케이션 서비스의 한 부분에 사용되기 때문이다.
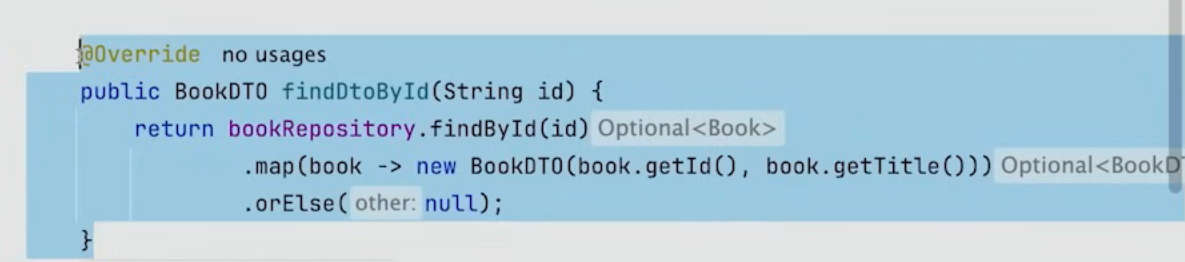
2] User Story
도메인 모델을 구성하기 위해서는 User Story를 잘 분석해야 한다.
도서관의 일을 코드로 녹인다고 가정해보자.

ex) 사서인 나는 책의 ISBN과 bar code를 스캔하여 Book의 Copy를 빌릴 수 있게 등록하고 싶다.
bar code는 도서관에서 만들어지며 각 책의 Copy 마다 붙여진다. 각 Book의 Copy는 고유한 bar code를 가진다.
이러한 user story를 단순한 task로 여길 수가 있다.
사실 user story는 단순한 task가 아니라 사용자가 애플리케이션을 통해 원하는 실제 일을 나타낸다.
따라서 이러한 user story에는 ubiquitous language(도메인 전문가, 아키텍트, 개발자 등 프로젝트 구성원 모두에게 공유된 언어)의 한 형태인 keyword가 있다.
이 Keyword를 잘 분석하여 user story를 코드에 녹여야 한다.
위의 그림에서 보면, librarian은 Book의 Copy를 등록하고 싶어하고, 그러면 Book과 Copy가 있어야 하고, Book은 ISBN이 있어야되고, Copy는 bar code가 있어야 한다.
또한 보면 bar code는 ISBN과 동일해야 한다. ISBN은 랜덤 숫자가 아니고 유효한지 아닌지 체크할 수 있다. 사용자는 책을 빌리고 돌려줄 수 있다. 등등...
따라서 user story를 분석하면 이렇게 큰 도서관 문제를 작은 두 개의 문제로 나눌 수 있다.
첫 번째는 사람들이 책을 검색하고 이용할 수 있는지 찾아볼 수 있는 카탈로그(catalog)를 만드는 것이다.
두 번째는 책을 빌리는 것(lending)인데 빌리는 것은 좀 더 복잡하게 늦게 반납하면 요금을 부과한다거나, 등등의 로직을 더 추가할 수 있다.
3] 구현
1. catalog
첫번째는 카탈로그를 만드는 일이다.
catalog에서 시작할 것이므로, catalog package를 만든다.
이 catalog라는 outer ring 안에 application services, domain model, infrastructure, 등의 package로 구성한다.
1) Book
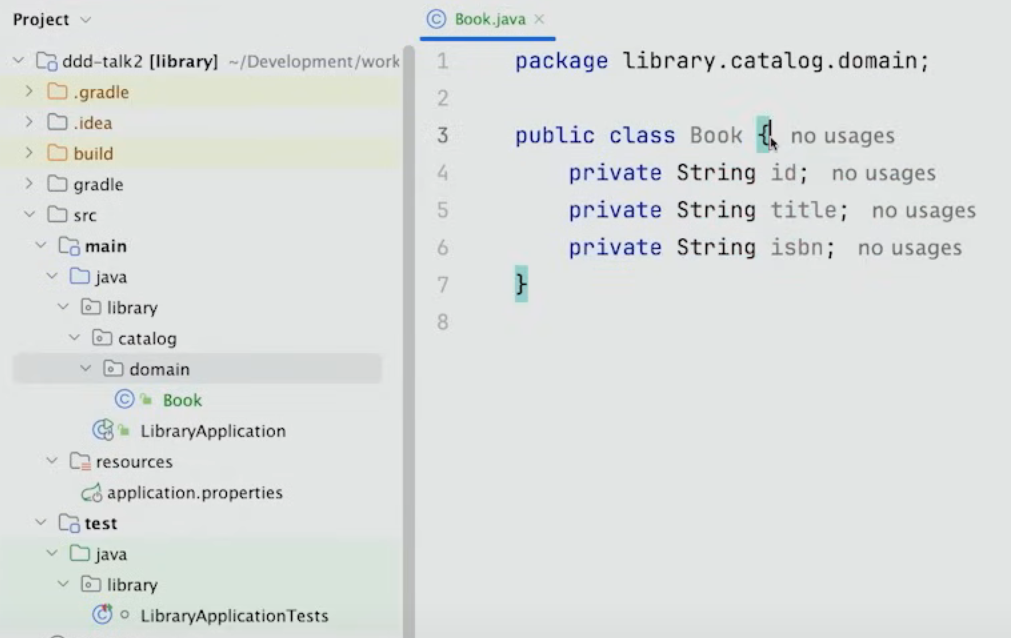
catalog 안에 도메인을 생성하고, Book을 생성한다.
그렇지만 마음대로 바꿀 수 있는 data structure를 만드는 것이 아니라 도메인 안에서 Book을 가지고 무엇을 할 수 있는지 나타내는 적절한 클래스를 만들어야 한다.
지금 보면, 모든 필드가 String으로 생성되어 있는데 사실 String은 특정한 규칙이나 도메인을 위한 어떠한 것도 설정할 수 없다.
- ISBN
Book 도메인에 있어서 ISBN은 굉장히 중요한 개념이다.
따라서 ISBN은 String이 아닌 그 자신만의 타입을 받을 가치가 있다.
따라서 ISBN record를 생성한다.
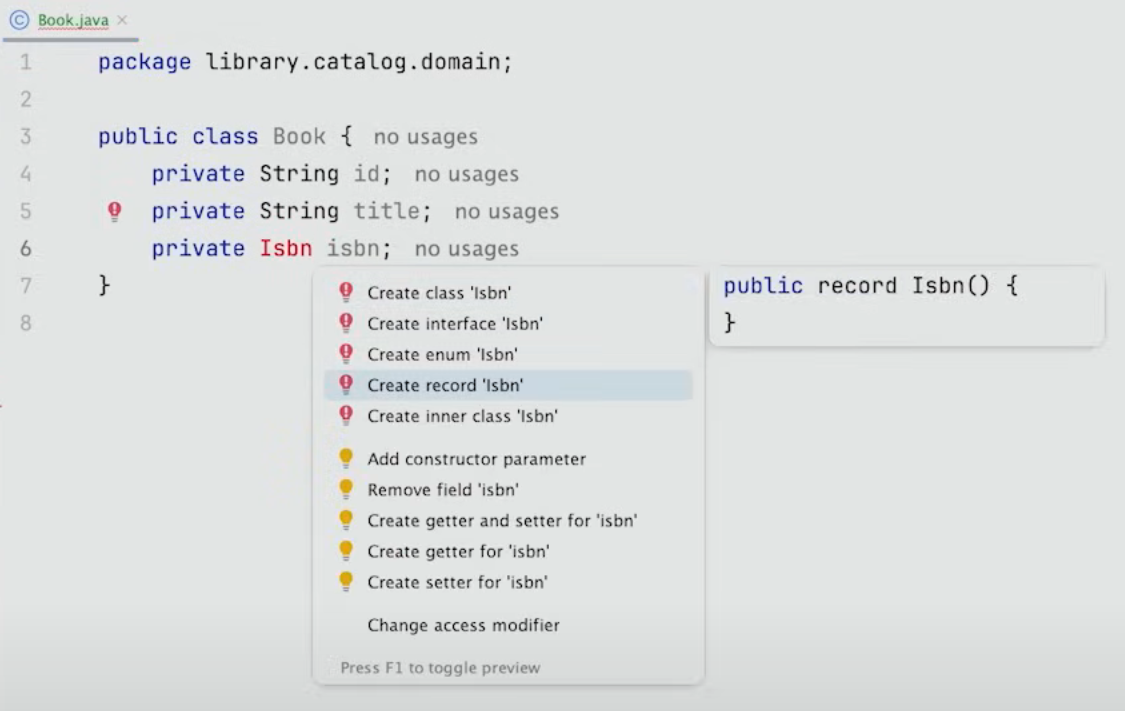
ISBN은 바뀌지 않으므로 immutable하고 Value Object를 나타내기에 좋은 record로 생성한다.
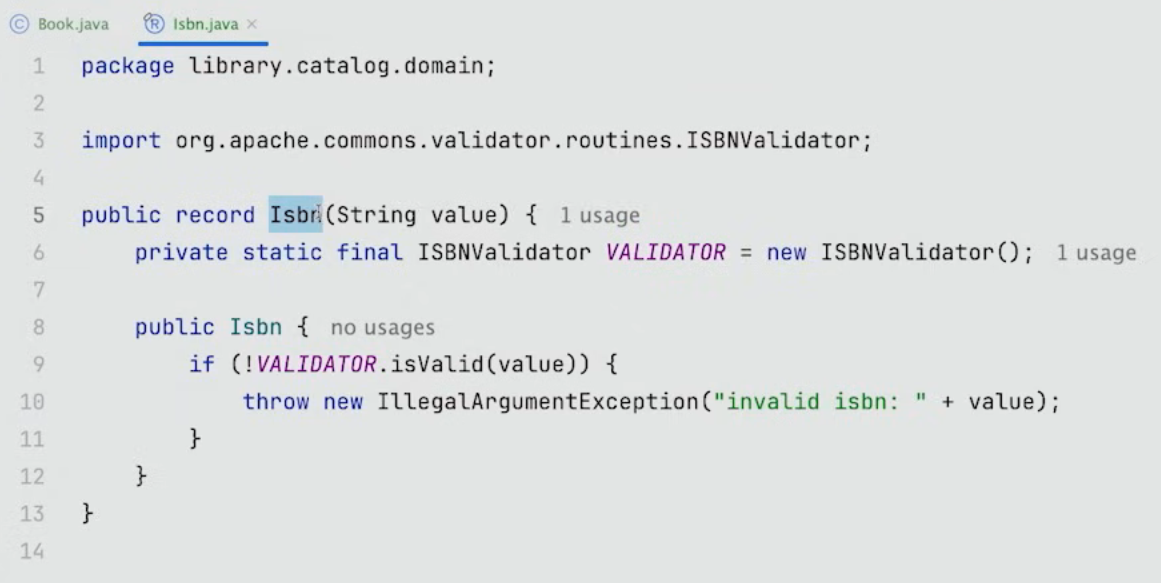
하지만 ISBN은 String을 가지고 있는 단순한 컨테이너가 아니다.
ISBN을 생성할 때는 invalid data로 생성하면 안된다.
따라서 위와 같이 유효성 체크를 넣어준다.
그렇게 되면 Book은 다음과 같이 구성된다.
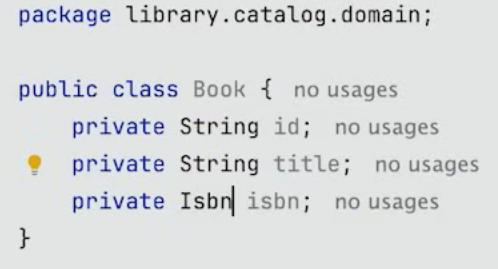
이렇게 구성해 놓았을 경우, Book은 ISBN의 validation을 신경 쓸 필요가 없다.
사실 application의 어느 곳에서도 ISBN의 validation을 신경 쓸 필요가 없어지게 된다.
3) id
DB에 id를 UUID를 사용하여 저장한다고 하면 다음과 같이 설정해 줄 수 있다.
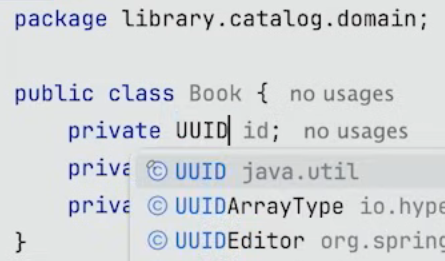
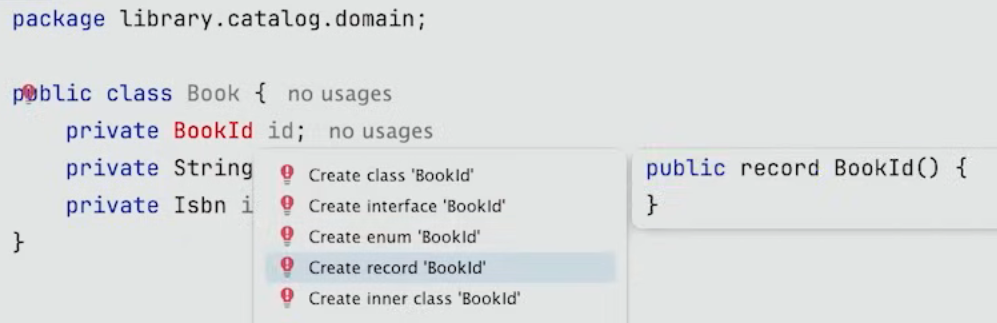
하지만 더 좋은 방법은 다음과 같이 각각의 Entity나 Aggregate를 위한 dedicated id class(전용 ID 클래스)를 생성하는 것이다.
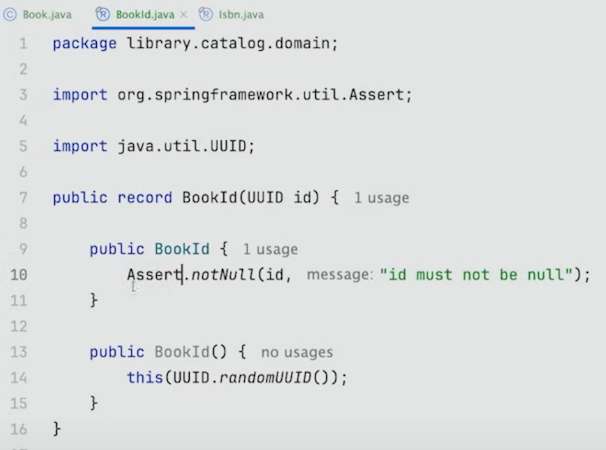
이것은 UUID의 value container이다.
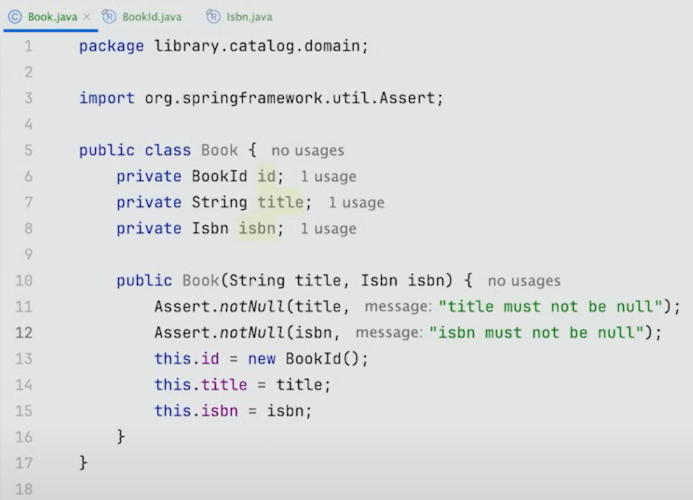
또한 Entity가 invalid 상태에서 존재할 수 없게 해야 하므로, 이렇게 title과 ISBN이 null이 되지 않게 구성하면 된다.
4) Repository
또한 이런 data를 DB에 persist(영구적으로 저장)해야 하므로 Repository를 만든다.
그렇지만 Repository는 Data Access Object(DAO)가 아니고 Domain Model의 한 부분이다.
Repository는 Aggregate 나 Entity의 collection처럼 행동한다.
5) JPA Entity vs Separate Domain Models
이제 Repository를 생성하면, 2가지 옵션이 있다.
하나는 도메인 모델을 프레임워크와 분리시켜 pure하게 유지하는 것이고,
또 다른 하나는 JPA Entity를 도메인 모델로 사용하는 것이다.
(1) Separate Domain Models(BookEntity)의 단점
어떤 사람들은 DDD Entity와 JPA Entity는 다르고 섞으면 안된다고 이야기한다.
하지만 도메인 모델을 JPA Entity로 설정하지 않고 JPA를 사용할 때는 추가 작업이 들어가야 한다.
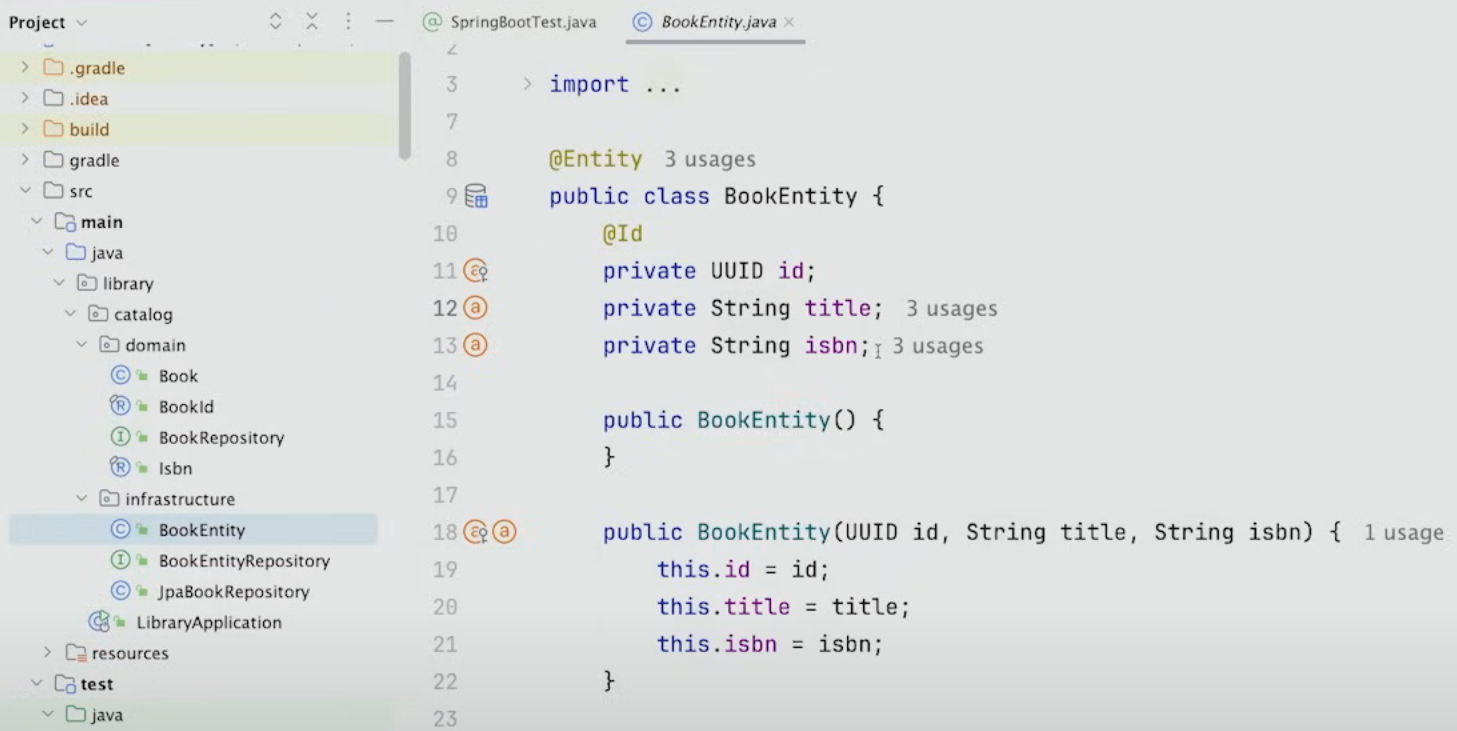
이렇게 Domain Package에 Book class를 두고, 실질적으로 infrastructure에 Book의 복제본인 BookEntity가 추가로 들어가야 한다.
그러면 필드가 거의 비슷하게 들어가고, hibernate나 JPA가 처리할 수 있는 타입만 사용할 수 있다.
hibernate나 JPA가 사용자가 전달하는 모든 Java type을 처리할 수 있는 것이 아니기 때문이다.
따라서 Entity는 Table에 해당하는 Data Container가 되기 쉽다.
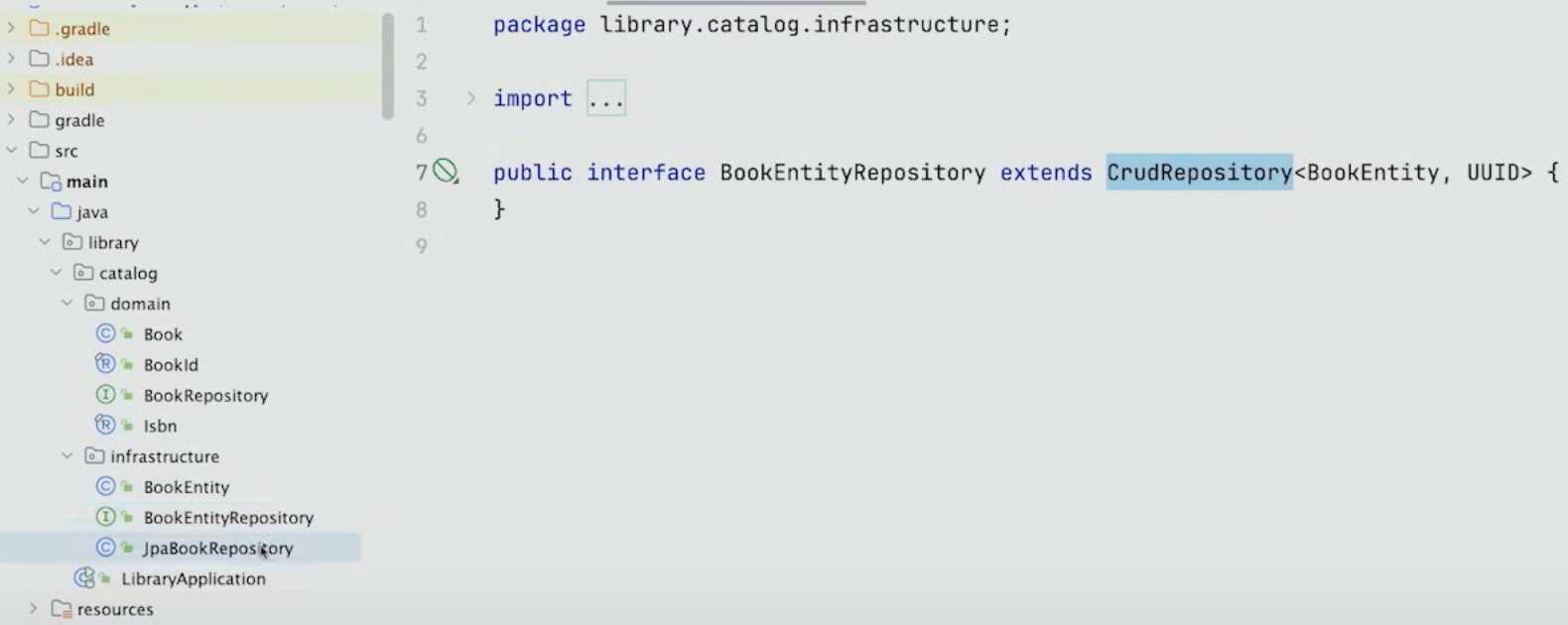
그리고 우리는 이렇게 BookEntity를 위한 Spring Data Repository를 만들고 Book이라는 도메인의 Repository를 구현한 JpaBookRepository라는 mapping layer를 만들어야 한다.

여기서는 Book을 BookEntity로 매핑하는 역할을 한다.
또한 data를 fetching할 때 같은 일을 해야 한다.
fetch해서 BookEntity를 Book으로 만들기 때문이다. 이것은 좋은 방법이 아니다.
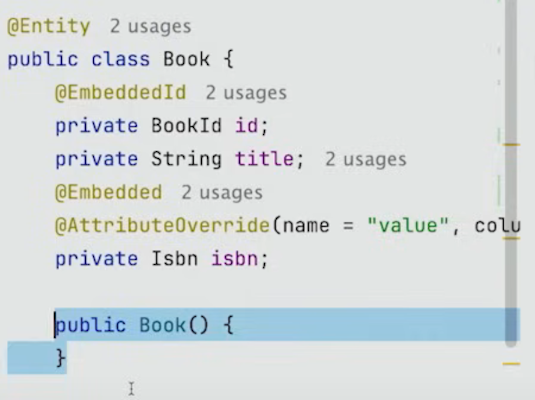
(1) JPA Entity(Book)
JPA는 record로 매핑하거나 다른 데이터 타입으로 매핑하는 것에 효과적이다.
우리는 이 Book class를 크게 손보지 않고도 JPA Entity로 바꿀 수 있다.
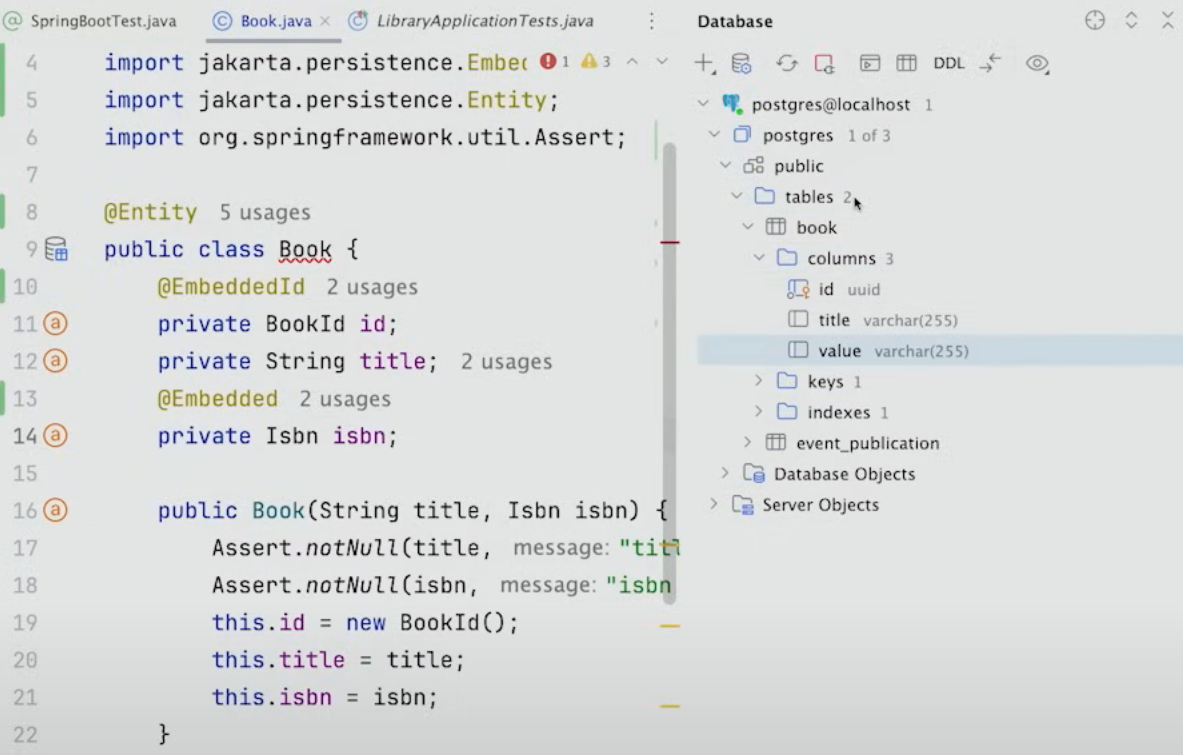
식별자인 BookId가 record로 구현되어있으므로, @Id를 사용할 수 없다.
하지만 @EmbeddedId를 사용하면, 적용이 된다.
ISBN도 비슷하게, Isbn이 record지만 @Embedded을 사용하면 된다.
다만 이렇게 테이블을 생성할 경우, value가 들어가는 것을 볼 수 있다.
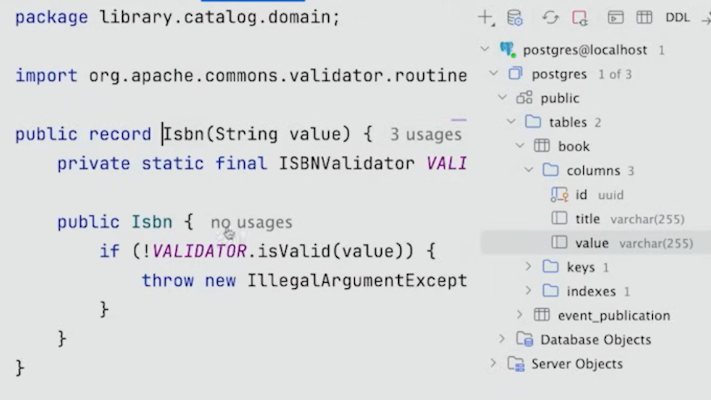
value는 이렇게 Isbn record의 파라미터에서 온 것이다.
따라서 value를 원하지 않으므로, 다음과 같이 @AttributeOverride를 사용해서 바꿔준다.
@Embedded
@AttributeOverride(name = "value", column = @Column(name = "isbn"))
private Isbn isbn;
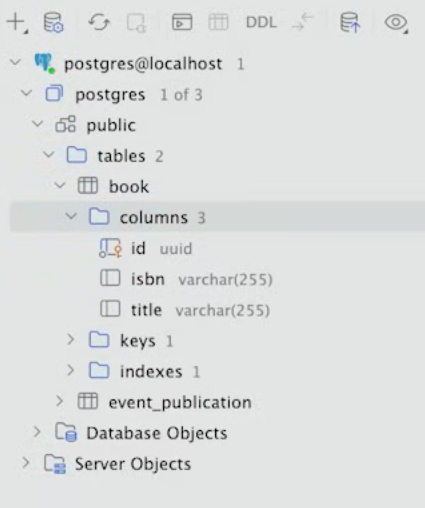
이렇게 JPA Entity를 만든다.
6) Copy
또 다른 Entity인 Copy에 대한 user story를 생각해보면 다음과 같다.
모든 도서관은 Book의 Copy에 자신만의 barcode를 붙여 스캔하면 Book의 독립적인 Copy를 추적하게 해야 하므로 BarCode를 넣어야 한다.
또한 Copy는 Book 한 개와 연관되어 있다. 예를 들어, 책 1개에 5개의 copy본이 있을 수 있다.
이에 대해서 생각해 보았을 때, Copy를 만들면 다음과 같이 구성하게 된다.
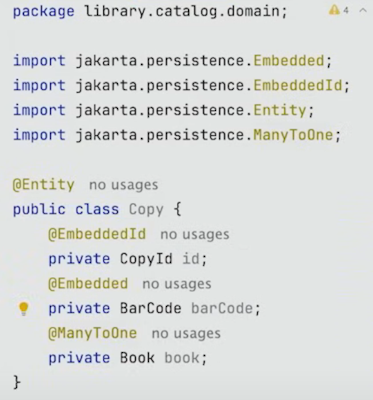
전통적인 JPA 방식으로는, @ManyToOne을 사용하여 위의 그림처럼 Book의 참조를 만든다.
다만 이것은 DDD에서 Aggregate나 Entity를 구현할 때 권장되는 방식이 아니다.
왜냐하면, Book은 Book 고유의 Repository를 가진 Entity이기 때문이다.
그 말은 Book과 Copy는 분리된 각각의 Aggregate라는 것이다.
좀더 자세히 살펴보면, Copy Entity에게 Book을 제어할 권한을 주지 않는다는 뜻과 같다. Copy가 관심있는 것은 오직 연관된 immutable한 Book의 id 뿐이다.
따라서 다음과 같이 구현한다.
@Embedded
@AttributeOverride(name = "id", column = @Column(name = "book_id"))
private BookId bookId;
7) default 생성자
Hibernate는 기본적으로 생성자를 만드는 것을 요구한다.
그렇지만 이렇게 public으로 구현하면, Entity나 이미 정한 규칙을 느슨하게 만들 수 있다.
다행히도, public으로 설정할 필요가 없으므로 다음과 같이 default로 만들어서 package private하게 만들어 패키지 외부에서 사용하지 못하게 만들면 된다.
Book() {
}
8) Use Case class
use case로는 ISBN으로 Book을 찾아 catalog에 추가하는 작업과 Book의 Copy를 등록하는 것을 할 것이다.
(1) RegisterBookCopyUseCase
먼저 Book의 Copy를 등록하는 Use Case 작업이다.
use case는 application ring 안의 서비스에서 구현된다.
보통은 BookService, CopyService로 만들어서 Book과 Copy에 관련된 모든 메서드를 넣어 사용한다.
이 방식은 결국 서로 관련 없는 절차들의 집합으로 끝나게 되는 정말 좋은 방법이다.
그 결과 유지보수하기 매우 어려운 클래스가 되고, 테스트 유지보수도 어려워진다.
따라서 좋은 방법은 clean architecture에서 concept을 따온 use case를 구현하는 것이다.
단순하게 생각하면, 서비스 클래스의 각각의 메서드를 분리된 클래스로 만드는 것이라고 보면 된다.
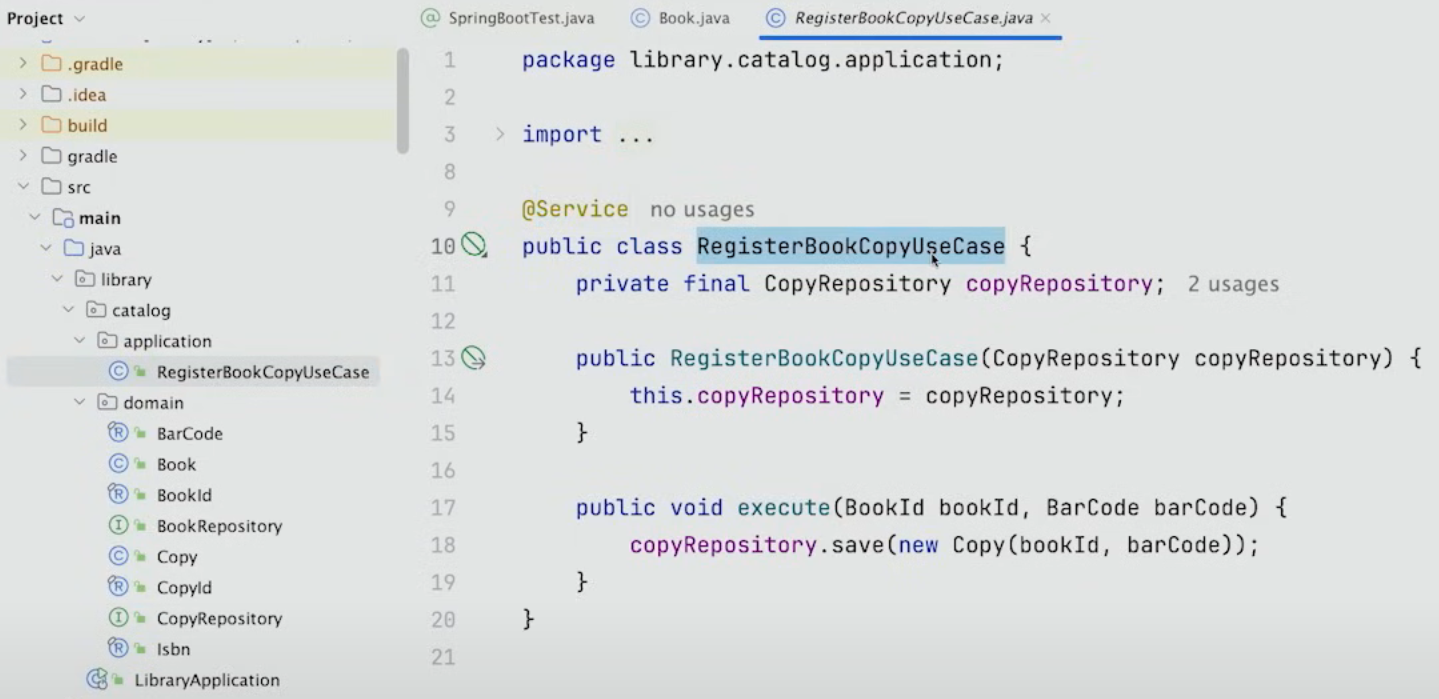
따라서 위와 같이, execute라는 단 하나의 메서드를 가진 RegisterBookCopyUseCase class를 만든다.
execute 메서드에서 Value Object를 사용하는 장점은 bookId와 barCode가 단순한 String이 아니기 때문에 이 메서드를 호출할 때 두 개를 실수로 바꾸지 않게 된다는 것이다. (String bookId, String barCode일 경우 barCode를 bookId 자리에 쓸 수 있음)
(2) AddBookToCatalogUseCase
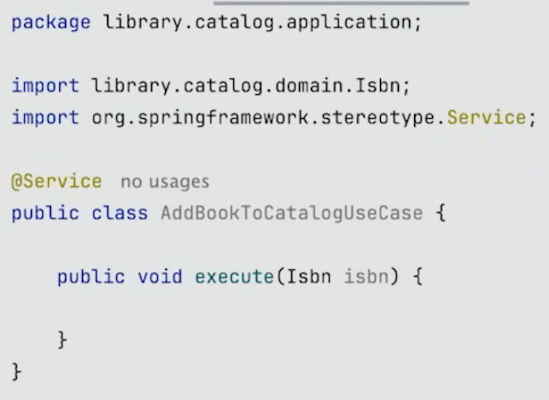
그 다음은 ISBN으로 Book을 찾고 catalog에 Book을 추가하는 AddBookToCatalogUseCase class를 구현해줄 것이다.
잘못된 방법
먼저 잘못된 방법을 설명하자면, 보통의 경우에 ISBN으로 Book을 찾기 위해 외부 service에 HTTP call을 만들 것이므로 이것을 넣을 적절한 위치는 infrastructure package이므로 infrastructure package에 BookSearchService를 만들게 된다.
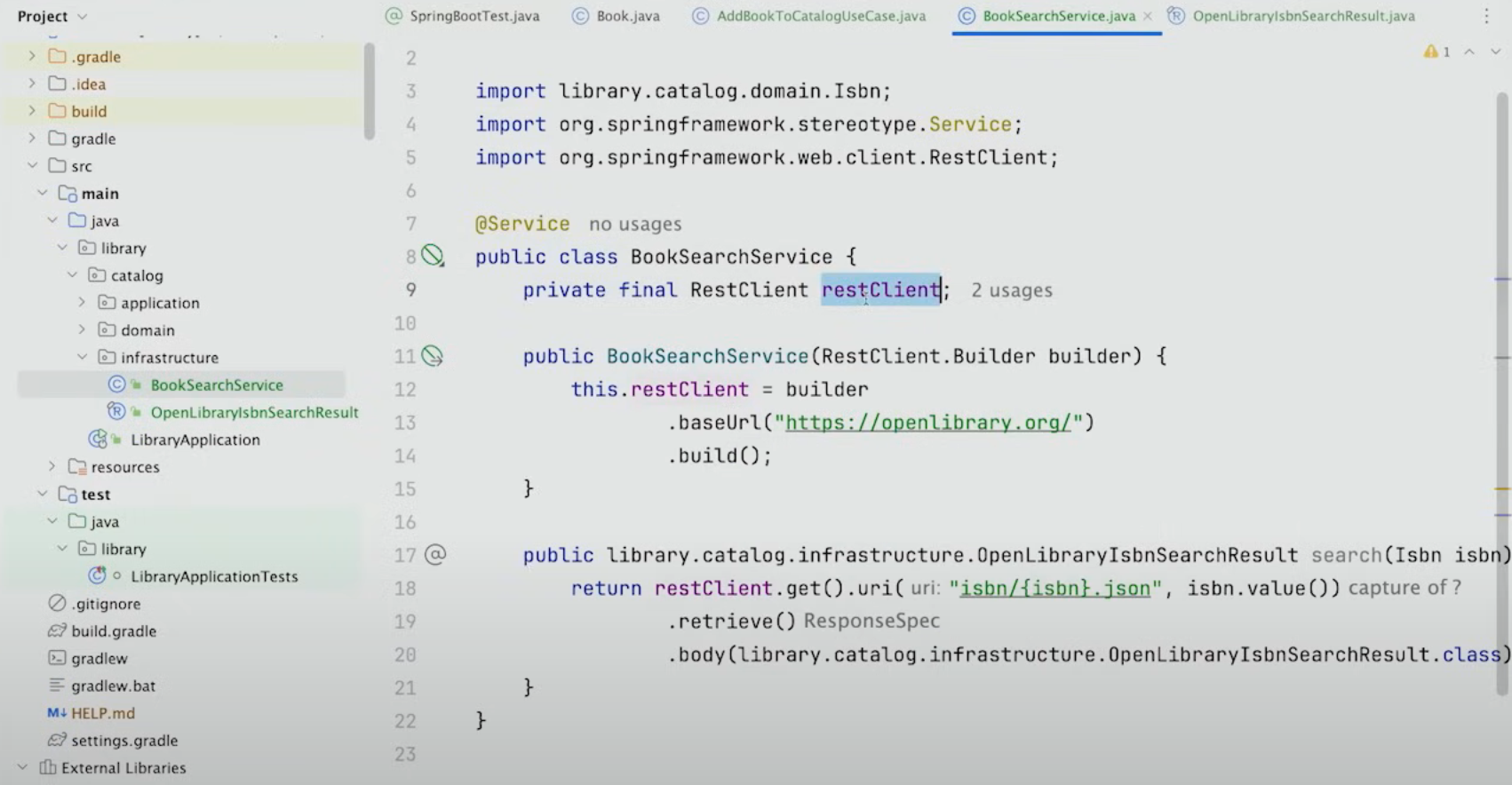
따라서 이렇게 BookSearchService를 생성하고 외부 요청으로 json data를 OpenLibraryIsbnSearchResult record로 매핑하는 메서드를 생성하게 된다.

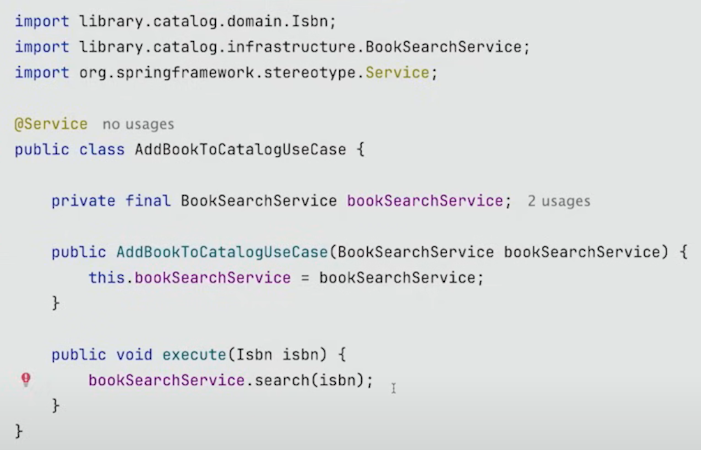
그렇게 되면 찾는 메서드는 위와 같이 만들어지게 된다.
하지만 중요한 점은, 이것은 잘못된 방식이다. 의존성 역전 원칙을 위반했기 때문이다.
application이 infrastructure에 의존하고 있다.
즉, 상위 수준 모듈이 하위 수준 모듈에 의존하고 있다.
따라서 반대로, infrastructure의 service가 다른 도메인이나 application에 의존해야 한다.
올바른 방법
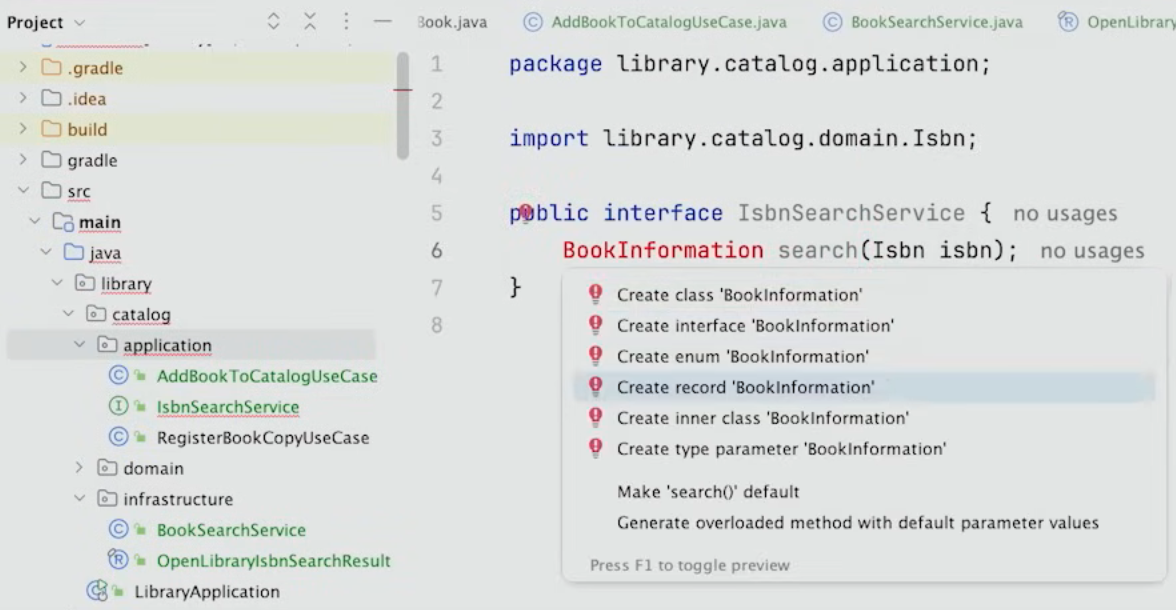
따라서 application에 IsbnSearchService interface를 생성한다.
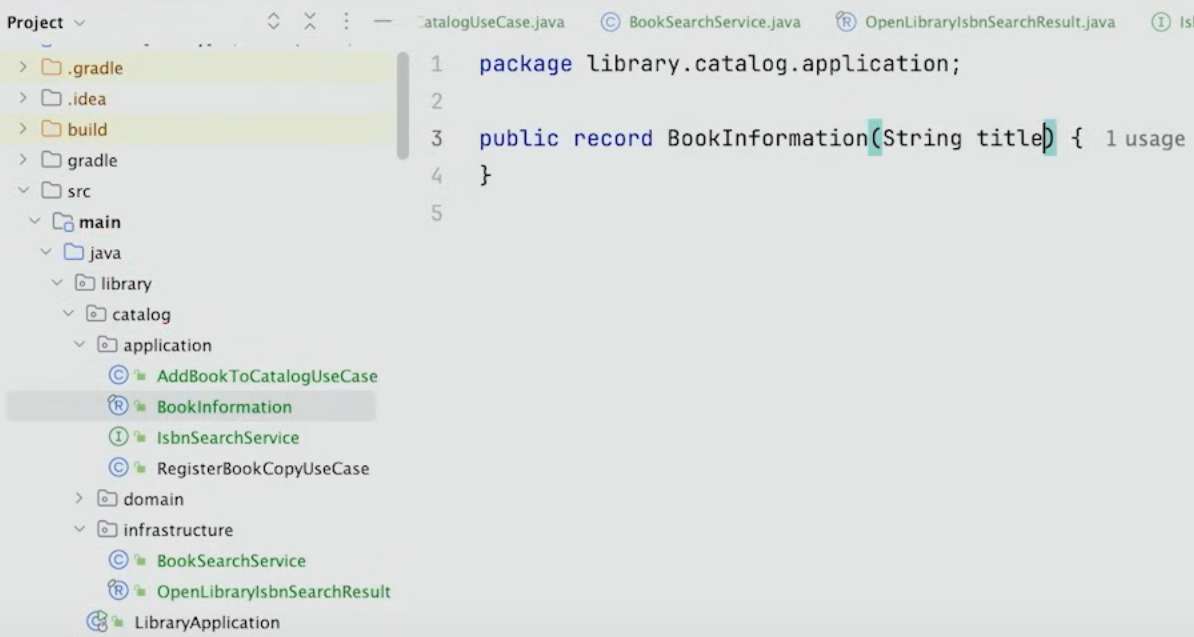
또한 application Service의 일부인 BookInformation을 생성한다.
왜 BookInformation을 domain에 넣지 않고 application에 넣었을까?
그 이유는 이 서비스(IsbnSearchService)는 도메인의 일부가 아니기 때문이다.
Librarian과 Library가 일하는 방식에 대해 논의한 결과가 아니기 때문이다.
이것은 단지 개발자의 결정으로 생성된 것이고, 편의를 위해 추가한 것이기 때문이다.
따라서 이것은 application의 한 부분이다.
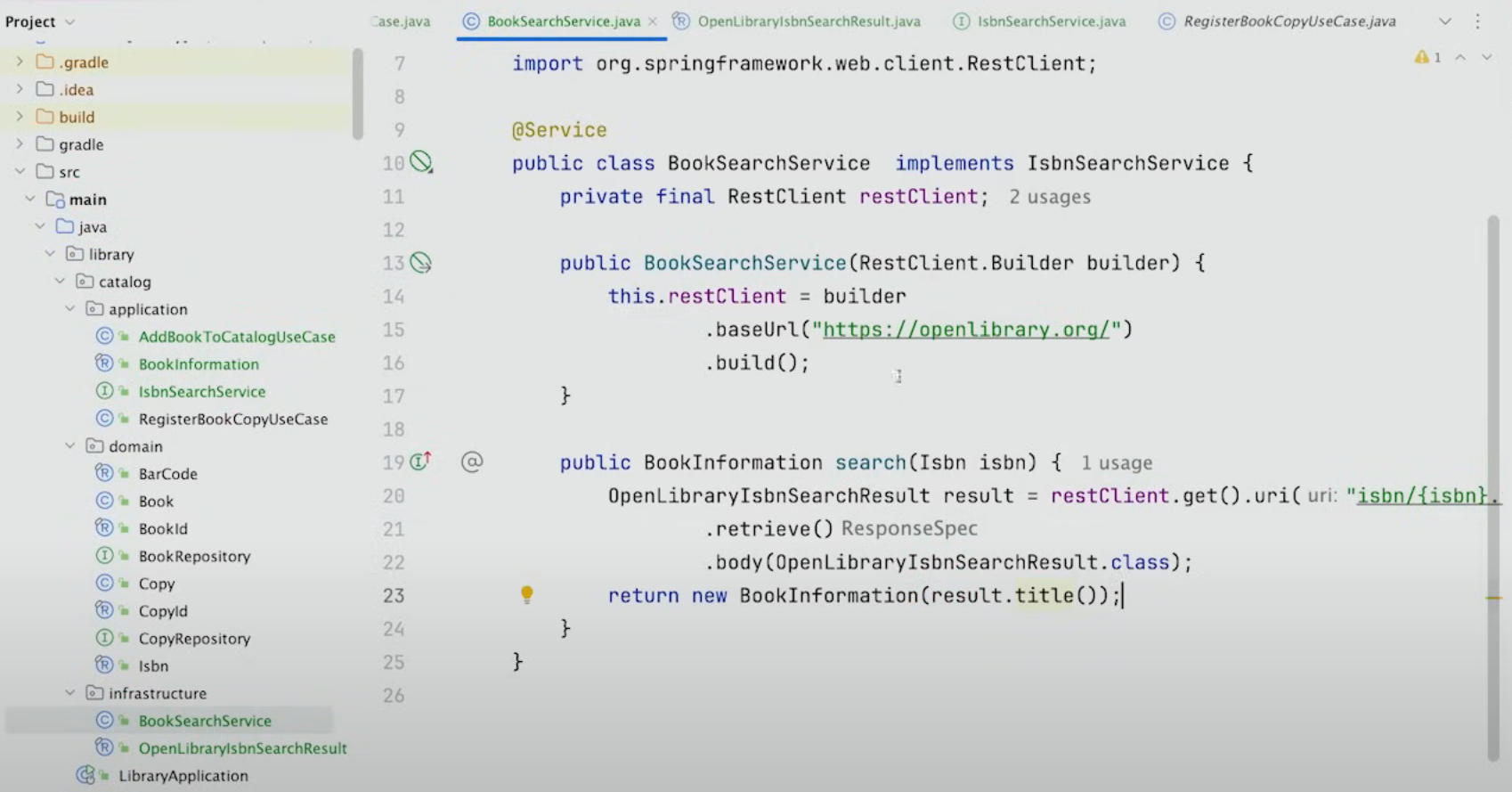
그 후 BookSearhService가 IsbnSearchService의 구현체로 되게 적용시켜주고, search 메서드는 BookInformation을 반환하도록 구현한다.

UserCase 클래스에서 IsbnSearchService를 호출하도록 바꾸는 것도 해주고, 마지막으로 execute 메서드를 완성해주면 된다.
이렇게 함으로써, BookSearchService와 OpenLibraryIsbnSearchResult는 다른 layer에서 전혀 참조되지 않는다.
따라서 다음과 같이 default(package private)로 변경 가능하다.
@Service
class BookSearchService implements IsbnSearchService {
}
record OpenLibraryIsbnSearchResult(...) {}
9) UseCase annotation
위와 같이 할 경우 AddBookToCatalogUseCase에도 @Service가 있고 BookSearchService에도 @Service가 있어 헷갈릴 수 있다.
또한 UseCase class는 실제로 서비스가 아닌 use case이므로, @UseCase를 생성하여 붙여준다.


@Retention 은 Annotation 이 실제로 적용되고 유지되는 범위를 의미하므로 컴파일 이후에도 JVM 에서 참조가 가능한 RUNTIME으로 설정해주고, 클래스에다가 붙일 것이므로 타입선언시 사용한다는 의미로 Target은 Type으로 설정한다.
또한 Service의 역할을 하므로 @Service를 붙인다.@Service안에 Target과 Retention이 있지만, @UseCase의 사용 목적과 범위를 명확하게 나타내기 위해 명시적으로 추가해준다.
이렇게 @UseCase를 설정해놓으면 몇몇 행동을 추가할 수 있다.
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Service
@Validated
public @interface UseCase {
}
예를 들어, 위과 같이 구현하면 UseCase class에서 @NotNull 같은 validation annotation을 추가할 수 있다.
또한 use case에 유용한 특정 AOP Aspect를 설정하여 execution time을 측정한다던지, logging을 한다던지 할 수 있다.
10) Lending Domain
책을 빌리고 반납하는 Lending domain을 구현하기 위해서는 Loan(대여)이 필요하다.
책을 빌리면 우리는 대여를 생성하므로 추적하기 위해 Loan class를 만들어야 한다.

UseCase를 보면 굉장히 단순하다는 것을 알 수 있다.
그 이유는 모든 Setter와 모든 잠재적인 조건문 등 모든 것을 domain class에 넣었기 때문이다.
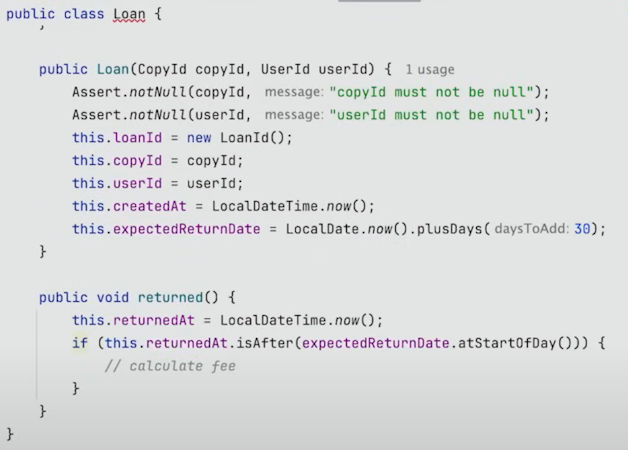
모든 제한 조건들은 domain과 entities에 있어야 한다.
그런데 책을 빌릴 때 이미 빌린 Copy본을 또 빌릴 수 없다.
따라서 보통은 해당 로직을 구현하기 위해 다음과 같이 exeucte 메서드(서비스)에 if문으로 넣게 된다.

하지만 이것은 문제의 여지가 있다.
책을 빌릴 때 가능한지 아닌지 체크하는 것은 도메인 layer에 있어야 하는데, application ring안으로 들어와 버린 것이기 때문이다.
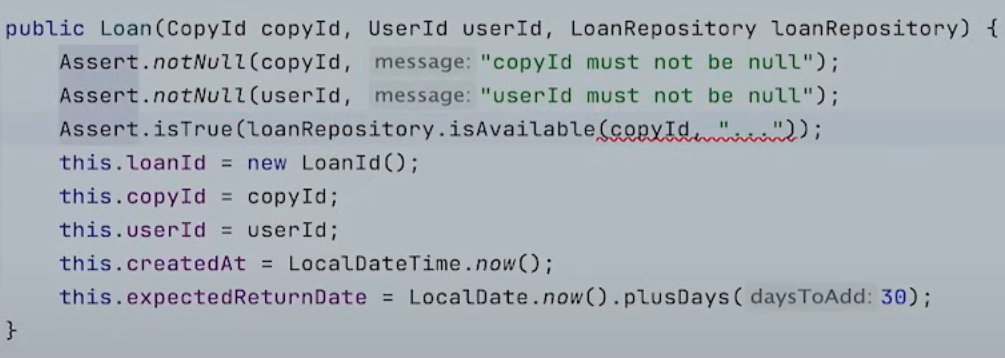
그렇게 하는 대신 위와 같이 Loan을 생성할 때 repository를 넘겨서 체크해야 한다.
이렇게 하면, application이나 use case에 침범하는 일이 없다.
Lending domain의 패키지 구조는 다음과 같다.
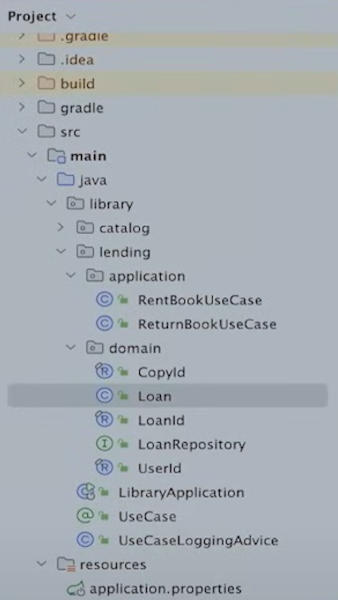
4] Module Verification
이렇게 두 개의 catalog와 lending으로 잘 나누었다면, 이것을 훼손하는지 체크하기 위해 Spring Modulith의 module verification을 사용할 수 있다.
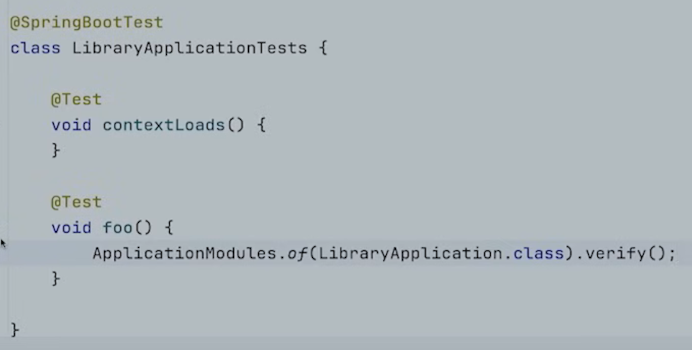
이렇게 foo 메서드로 체크를 할 수 있다.
5] Module interact
catalog와 lending이 서로 상호작용해야할 때는 어떻게 해야 할까?
catalog module에서 Book이 빌려진 상태인지 아닌지 체크해야 될 때를 구현해 보자.
이때 누가 빌리고 언제 반납했는지 카탈로그는 관심이 없다.
available한지 아닌지만 궁금하기 때문에 이 Copy에 available한 지 알려주는 필드를 추가해준다.
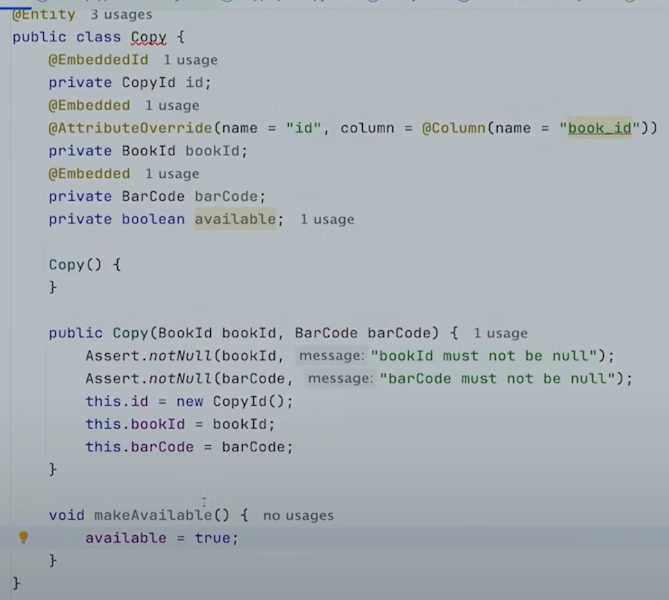
Setter를 추가할 수 있지만 의미있는 메서드 이름을 만들기 위해서 그렇게 하지 않았다.
그럼 이제 책을 반납했다는 UseCase인 ReturnBookUseCase가 호출될 때 어떻게 lending에서 책이 available한 지 알릴 수 있을까?
가장 나쁜 방법은 ReturnBookUseCase의 execute 메서드에 CopyRepository를 가져와서 Book을 fetch해서 상태를 바꾸고 저장하는 것이다.
이런 방식은 catalog module에 대한 매우 높은 의존성을 lending module에 심어주게 된다.
해답은 우리의 Loan Entity를 Spring Data의 AbstractAggregateRoot를 상속받아 Aggregate로 만드는 것이다.
AbstractAggregateRoot의 가장 중요한 능력 중 하나는 그것이 event를 등록하여 Entity에 무슨 일이 생겼을 경우 event를 트리거할 수 있다는 것이다.
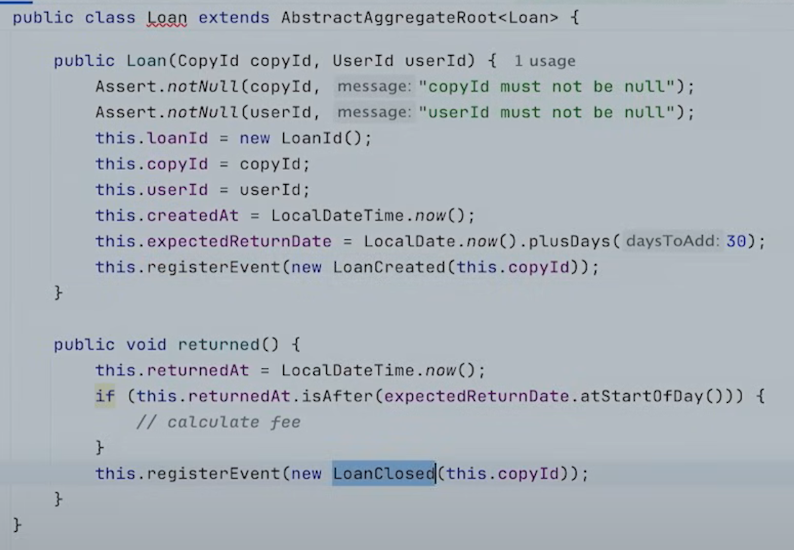
이 이벤트인 LoanCreated와 LoanClosed는 이 생성자나 returned 메서드에서 publish 되는 것은 아니다.

바로 여기에서, new Loan될 때 publish될 이벤트가 등록되고 save를 호출하면 이벤트가 publish되는 것이다.
그 후에 다른 모듈이 이 이벤트를 listen할 수 있다.
따라서 lending module은 이 이벤트에 관심있는 것이 어떤 건지 모르고 신경쓰지 않는다. 또한 제대로 실행되었는지 신경쓰지도 않는다.
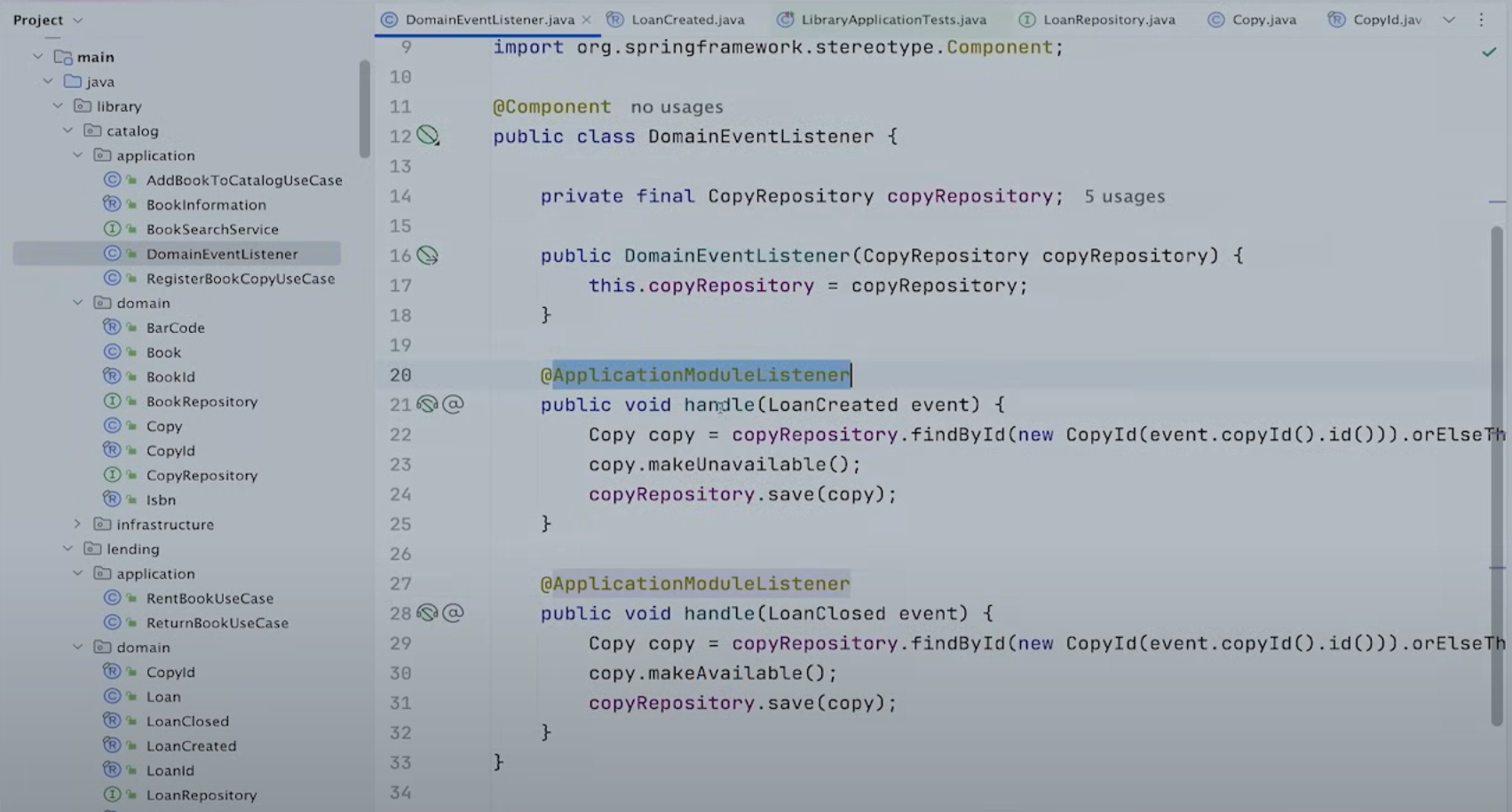
그러나 catalog module은 @ApplicationModuleListener를 통해 이 이벤트를 listen하여 특별한 행동을 할 수 있다.
Spring Modulith에서 DB에 발행 정보를 저장하므로 @ApplicationModuleListener는 리스너가 실패하더라도 애플리케이션의 요구 사항에 따라 재시도 메커니즘을 적용할 수 있다.
따라서 Eventual Consistency를 구현해준다.
Eventual Consistency
분산 시스템에서 데이터 일관성을 유지하기 위한 모델 중 하나이다.
데이터의 즉각적인 일관성을 보장하지는 않지만, 일정 시간이 지난 후에는 모든 노드(또는 시스템)에서 동일한 데이터를 볼 수 있도록 결국에는 일관성을 확보하는 것을 말한다.
Next Plan
여러 도메인을 가져와서 그리드로 한번에 보여주어야 하는 Use Case가 있을 경우 어떻게 구현해야 할지 생각하여 추가하기
Validation은 도메인 모델 생성할때만 사용하면 충분한지 알아보고 만약 특정 Use Case에서 Validation이 필요하고 그것이 도메인 모델 생성 Validation과 동일할 때는 없는지 생각하여 추가하기
영상에 나온 Implementing DDD with the Spring Ecosystem by Michael Plöd 참고하여 도메인 모델링에 대해 공부하기
Spring Modulith 공부하기
References
Subscribe to my newsletter
Read articles from Jong-Dae Park directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by