Top 5 Vector Databases in 2024
 Eswara Sainath
Eswara Sainath
Introduction
We are drowning in data! It's mind-boggling to think that over 80% of data is going to be unstructured by 2025- think emails, social media posts, images, and videos. The explosive growth of AI has turned this data deluge into both a goldmine and a headache. The real challenge is storing vast amounts of data, searching effectively, and retrieving it efficiently! That's where things get tricky.
Enter vector databases - the unsung heroes of the AI revolution. These powerhouses are purpose-built to wrangle high-dimensional data, which is the lifeblood of cutting-edge applications in natural language processing, computer vision, and recommendation systems. Trust me, once you see them in action, you'll wonder how we ever managed without them.
In this deep dive, we'll peel back the layers of vector databases. We'll explore their inner workings, uncover the popular use cases, and spotlight the top 5 vector databases that are setting the pace in 2024. If you're a seasoned data scientist or just starting out in the world of AI, get ready for an exciting journey into the future of data management.
What are Vector Databases?
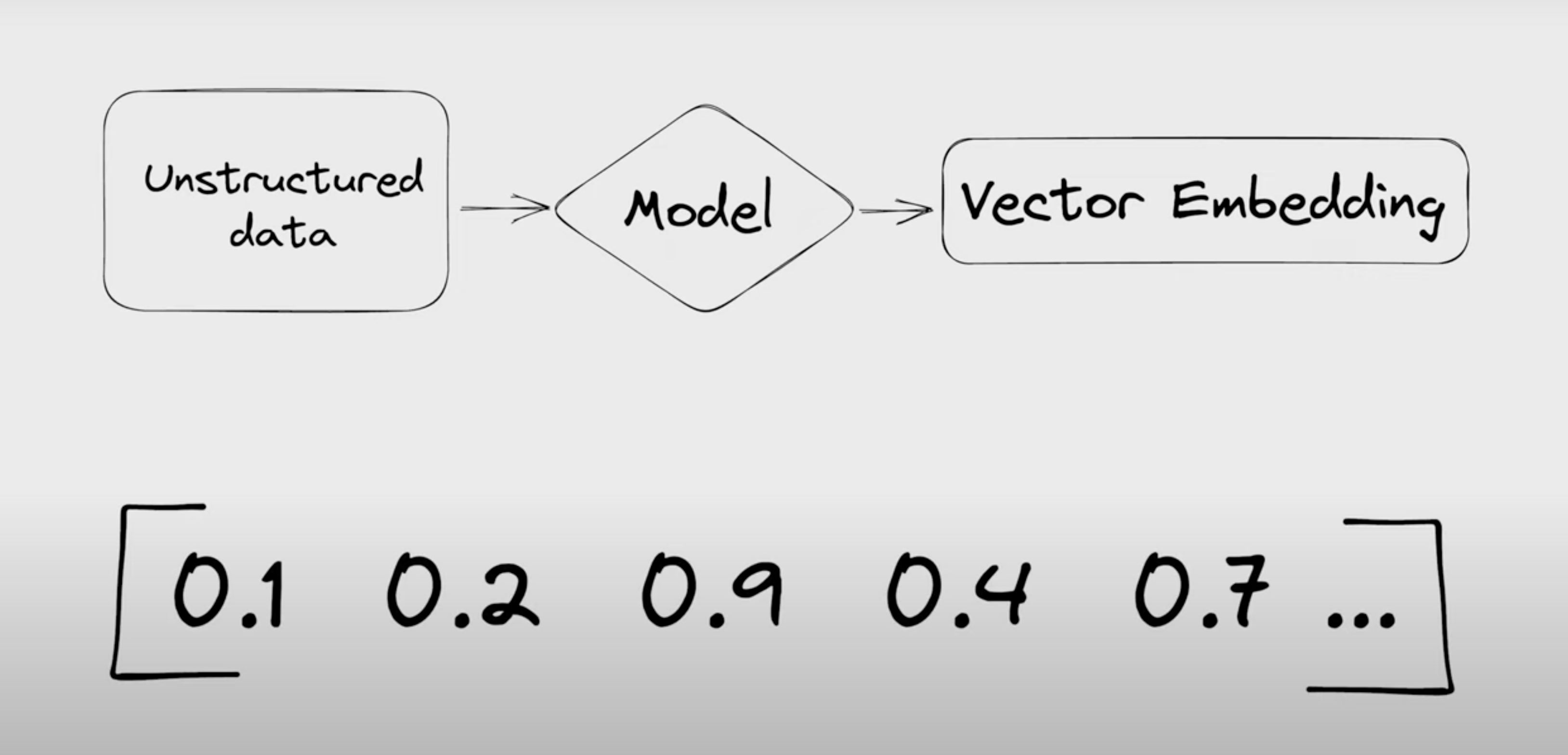
Vector databases store high-dimensional data as vectors, allowing for efficient similarity search and retrieval. Unlike traditional databases that store scalar data (like integers or strings), vector databases are optimized for handling the complex, high-dimensional data produced and utilized by AI and ML models. This enables applications to perform fast and accurate searches based on vector similarity, which is crucial for many tasks such as image recognition, text embedding, and other AI-driven applications.
How do they work?
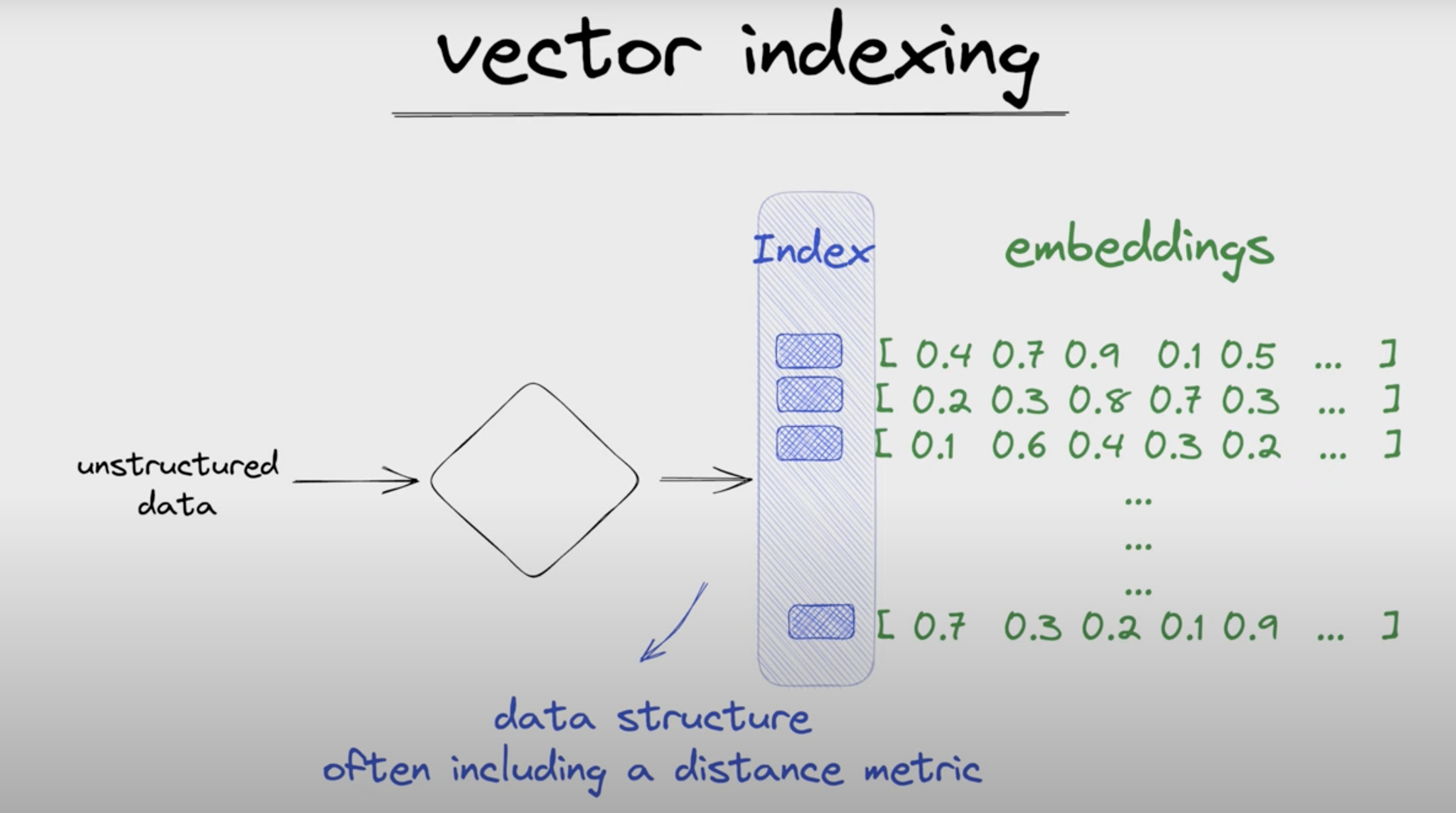
It works by storing and managing high-dimensional vector data, typically generated from machine learning models. When a query vector is inputted, the database calculates the similarity or distance between the query vector and stored vectors using various metrics, such as cosine similarity or Euclidean distance. This process involves advanced indexing techniques to quickly retrieve the closest vectors, ensuring efficient and scalable search capabilities. The result is a highly optimized system for tasks like similarity search, recommendation engines, and real-time data analysis, enabling applications to leverage large-scale, high-dimensional data effectively.
Storage Techniques
Vector databases employ various storage techniques to handle the complexity and volume of high-dimensional data:
Sharding: Divides the data into smaller, manageable pieces, distributing them across multiple servers to improve performance and scalability.
Partitioning: Splits data into separate sections based on specific criteria, allowing for more efficient data access and management.
Caching: Stores frequently accessed data in memory to speed up retrieval times.
Replication: Creates copies of data across different servers to ensure data availability and reliability.
Search Methods
Search methods in vector databases are generally categorized into:
Similarity Search: Calculating the distance or similarity between the query vector and stored vectors, and retrieving the closest vectors based on this calculation.
Semantic Search: It involves understanding the meaning and context of the search query and matching it with relevant documents or data based on their semantic content.
Nearest Neighbor Search (NNS): Finds the closest data points to a given query in high-dimensional space.
Approximate Nearest Neighbor Search (ANNS): Uses algorithms to quickly find approximate nearest neighbors, trading off some accuracy for speed.
Common algorithms used in these searches
KD-tree: A tree-based data structure for organizing points in a k-dimensional space.
Ball-tree: Similar to KD-tree but more efficient for high-dimensional data.
Locality Sensitive Hashing (LSH): Hashing technique that ensures similar items are hashed to the same bucket.
Hierarchical Navigable Small World (HNSW) graphs: Graph-based structure that provides efficient search by navigating through small-world properties.
Quantization-Based Approaches
To handle the storage and retrieval of high-dimensional vectors efficiently, quantization-based approaches like Product Quantization (PQ) and its variants are used. These methods compress vectors into smaller representations, reducing storage requirements and improving retrieval speed.
Use cases
Vector databases are instrumental in various AI and ML applications, including:
Natural Language Processing (NLP): Enhancing search engines, chatbots, and language translation by enabling fast and accurate text similarity searches.
Computer Vision: Powering image recognition, facial recognition, and object detection by efficiently comparing high-dimensional image embeddings.
Recommendation Systems: Providing personalized recommendations by analyzing user behavior and preferences encoded as vectors.
Large Language Models (LLMs): Enhancing LLMs by providing long-term memory, enabling semantic search, and supporting retrieval-based text generation.
Content Moderation: Automatically detecting and filtering inappropriate or harmful content by comparing new data against a database of known examples. Read more about content moderation using AI.
Top 5 Vector Databases
Here are the top 5 vector databases that are currently popular in 2024, based on their performance, scalability, and adoption in the industry:
1. Pinecone
Overview:Pinecone offers a fully managed vector database service optimized for fast and scalable similarity searches. It supports various AI and ML applications with its robust infrastructure.
Key Features: High performance, easy integration with existing workflows, and seamless scaling.
Used by: Microsoft, Accenture, Notion, Hubspot, Shopify, Clickup, Gong, Zapier and a lot more. Go through their customer list here.
2. Milvus
Overview:Milvus is an open-source vector database designed for handling massive-scale vector data. It supports both NNS and ANNS and integrates well with various ML frameworks.
Key Features: High scalability, flexible deployment options, and strong community support.
Used by: Salesforce, Zomato, Grab, Ikea, Paypal, Shell, Walmart, Airbnb, and a lot of other companies. Go through the use cases here.
3. Qdrant
Overview:Qdrant is an advanced vector search engine designed for high-dimensional data processing. It provides a scalable solution for similarity search and machine learning model integration.
Key Features: Real-time updates, precise search capabilities, and efficient vector storage.
Used by: Discord, Johnson & Johnson, Perplexity, Mozilla, Bosch. Go through the customer list here.
4. Chroma
Overview:Chroma is a versatile vector database that excels in managing and retrieving high-dimensional data. It's optimized for AI-driven applications, offering powerful tools for developers.
Key Features: High flexibility, strong API support, and seamless integration with AI pipelines.
Used by: Leading tech firms and startups rely on Chroma for its adaptability and efficient data handling.
5. Weaviate
Overview:Weaviate is a cloud-native, GraphQL-based vector database designed for large-scale, AI-powered applications. It provides powerful search and retrieval functionalities for vector data.
Key Features: Easy-to-use GraphQL interface, schema flexibility, and native integration with various ML tools.
Used by: Red Hat, Stack overflow, Mutiny, Red bull, Writesonic.
6. Pgvector (Bonus Section)
PostgreSQL with pgvector Extension
Overview: PostgreSQL with the pgvector extension adds support for vector data types, enabling the use of PostgreSQL as a vector database. This integration allows for the handling of high-dimensional data and similarity searches within a familiar and robust relational database environment.
Key Features:
Seamless Integration: Works within the PostgreSQL ecosystem, leveraging existing tools and skills.
Versatility: Supports a wide range of AI, ML, and data analysis applications.
Scalability: Benefits from PostgreSQL's proven scalability and performance optimizations.
Extensibility: Can be extended with other PostgreSQL features and extensions to enhance functionality.
Used by: While specific usage examples might not be as widely publicized as dedicated vector databases, organizations that already rely on PostgreSQL for their database needs can easily adopt pgvector for vector data processing, benefiting from PostgreSQL’s reliability and extensive community support.
Conclusion
Vector databases are essential for handling the high-dimensional data required by modern AI and ML applications. By enabling fast and efficient similarity searches, they play a crucial role in enhancing the performance and capabilities of these applications. The top vector databases for 2024, including Pinecone, Milvus, Qdrant, Chroma, Weaviate, and PostgreSQL with the pgvector extension, exemplify the versatility and power of this technology, offering robust solutions for a wide range of use cases.
Selecting the right vector database depends on your specific needs, including scalability, integration capabilities, and community support. Pinecone and Milvus stand out for their high performance and scalability, making them ideal for large-scale deployments. Qdrant and Chroma offer unique features that cater to niche requirements, while Weaviate provides a comprehensive suite of tools for AI-driven applications. PostgreSQL with pgvector offers a seamless integration into existing PostgreSQL environments, making it an excellent choice for those looking to leverage vector search capabilities without moving away from their trusted relational database system.
Subscribe to my newsletter
Read articles from Eswara Sainath directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by