Azure Data Factory CI/CD with GitHub and Azure Pipelines
 Bob Blackburn
Bob Blackburn
Without source control for Azure Data Factory (ADF), you only have the option to publish your pipeline. And, it has to validate. Now with source control, we can save intermediate work, use branches, and publish when we are ready. The next step is CI/CD. Let’s look at how we can use Azure Pipelines to accomplish this.
Topics
- Setup
- Build Pipeline
- Release Pipeline
- Environment parameters (i.e. for UAT and Production)
- Production release
- Specify the release to publish
- Enable Continuous Integration
Setup
For this demo, we have a simple pipeline that copies files in ADLS from one folder to another. We are also using Key Vault to demonstrate updating to the production key vault in the release parameters. You should have your project in GitHub or Azure DevOps.
Build Pipeline
In DevOps, create a new pipeline.

Next select classic editor

Select the repository. Note: GitHub recently changed the master branch to the main branch for new repos.

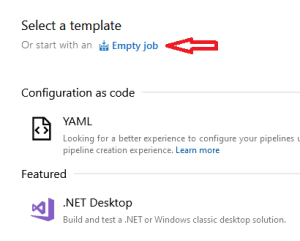
Select Empty job
Update the name and choose a ubuntu version for performance for Agent Specification.

Highlight Agent Job 1 and hit the ‘+ ‘.
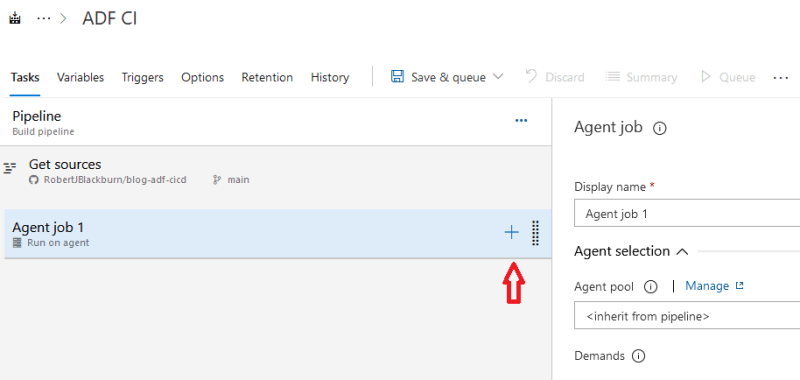
Search for ‘publish’ and select Publish build artifacts.

With the task highlighted, click the ellipsis on the Path to publish.
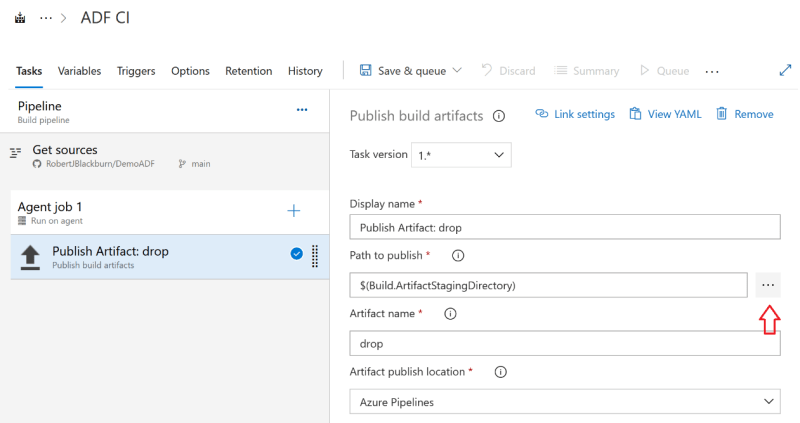
Select the folder to build. Here we select ADFCICD.

If you do not have a top-level folder, disconnect your Data Factory from GitHub and reimport it, and specify a Root Folder. See below.

For this demo, we selected our path. Click Save & queue then Save and run

After a few seconds, we get a success message and see the artifact was produced.
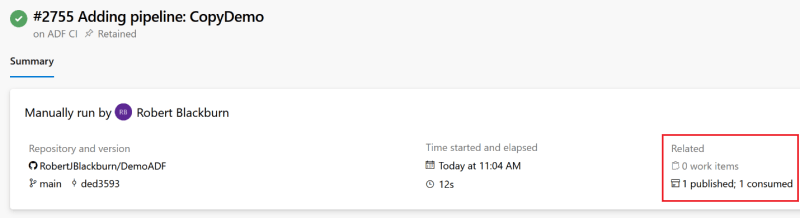
Click on the published link and we can see our Data Factory objects.

Release Pipeline
In the release Pipeline, we will publish the changes to the Dev environment.
In DevOps, Pipelines, Releases, click on New, New Release Pipeline. If you don’t have any existing release pipelines, you can click the Create release button.

For the Template, select Empty job.

We will use ‘ADF Dev’ for the Stage name and click Add an Artifact
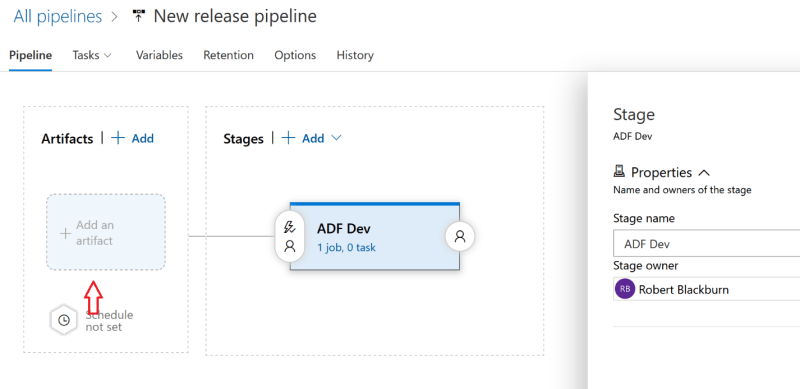
Select the Source (build pipeline). Click Add.
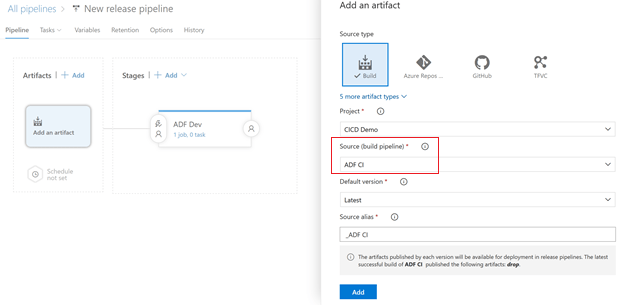
Next, we add our publish task. Click on the task link.

On the Agent job, click the ‘+’.

We are going to install a DevOps Task from the marketplace. It allows for easy customization of parameters and helps streamline the process. One caution to be aware of is that it will automatically create a Data Factory if it does not exist. That’s something to mindful of if you misspell something and cannot find it. Documentation can be found here.
Search for ‘adf’ and select Deploy Azure Data Factory by SQLPlayer.
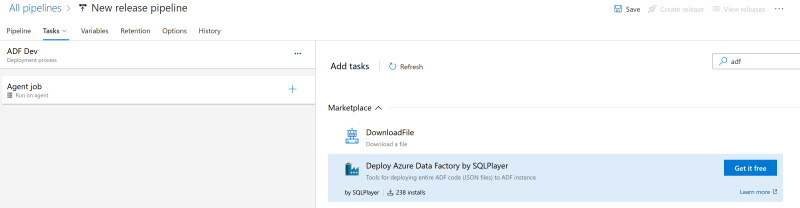
After you install it, it will be an available task. Select the task and click Add.

Configure options
- Select Azure Subscription.
- Select Resource Group Name.
- Enter the target ADF name. Can be existing or a new one will be created.
- ADF Path. Use the ellipsis to search for the drop folder in your build artifact.
- Enter Target Region.
Name the release and Save. Click OK for the default folder.

After we save it, the Create release is available. Click Create release.
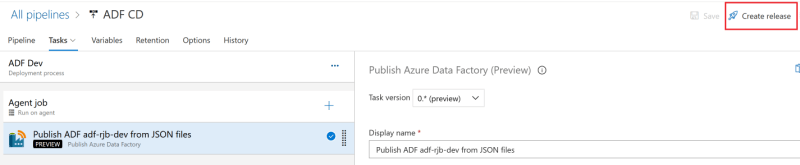
In the pop-up window, click Create.
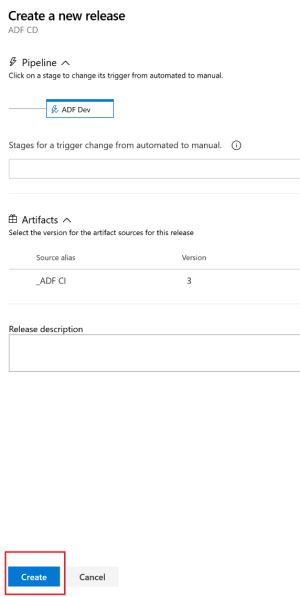
When we go back to the release, we can see it succeeded.
Environment parameters
To publish to other environments such as UAT and Production, we have to be able to change settings. One of the main features of this ADF Publish task is the parameters are stored in a CSV file. Once set up and added to the repo, you can publish it without updating the settings manually. The Publish task and repo are public on GitHub and can be found here.
In our Data Factory, we are using the Dev key Vault. Here we see it in the repo. Edited with Visual Studio Code.

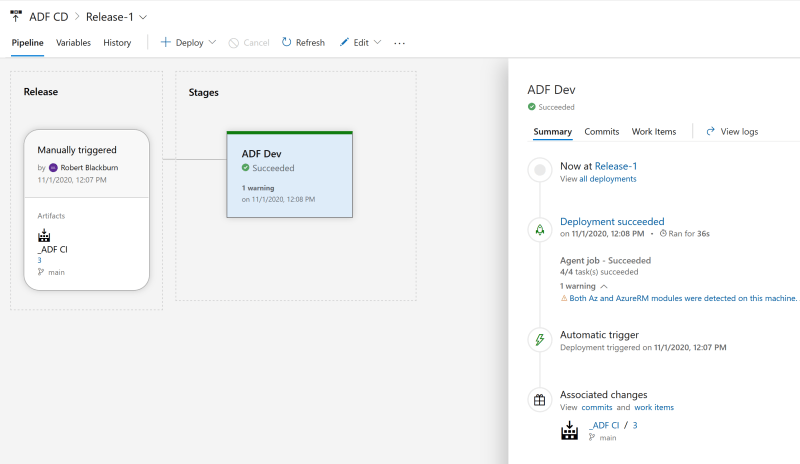
Create one configuration file per environment. We currently have an empty production environment; we will use that in our example.
Add a folder called ‘deployment’ to the repo. Create a CSV file in the format of config-.csv. Ours will be ‘config-prod.csv’.
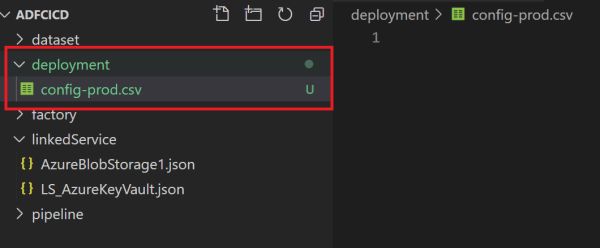
The CSV file has four columns. For additional examples, see task documentation.
- Type (Name of the folder)
- Name (Name of the object)
- Path (after Properties in JSON)
- Value (the new value of setting)
From our current key vault definition

We get our config file.

Save and push changes to the repo. When we check the repo in GitHub, we can see our config file.

Go back to the build pipeline and run it so the config file will be in the build artifact.
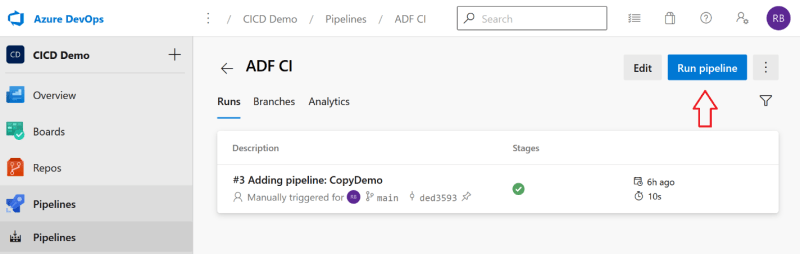
After it is published, we can see the config file in the artifact.
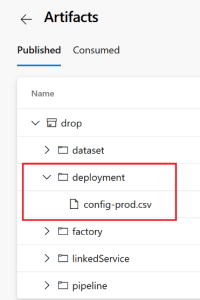
Production Release
Since we don’t want to publish to production automatically, a new release will be created to allow publishing with just one click.
From the release pipeline, press the ellipsis next to Create release and choose Clone.

Update the pipeline name, Target Azure Data Factory Name, Resource Group if different, and add the Environment (stage). Since we used the ‘deployment’ folder and followed the recommended naming convention, we only have to specify the stage name from the second part of our config file name ‘config-prod.csv’. If not, select File Path and browse to the config file location.

Save changes.
Our production environment is empty.
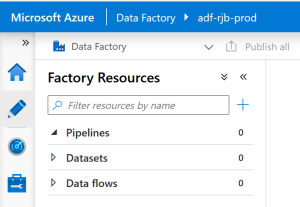
On our Prod pipeline, Create release.
We get the message the release succeeded.
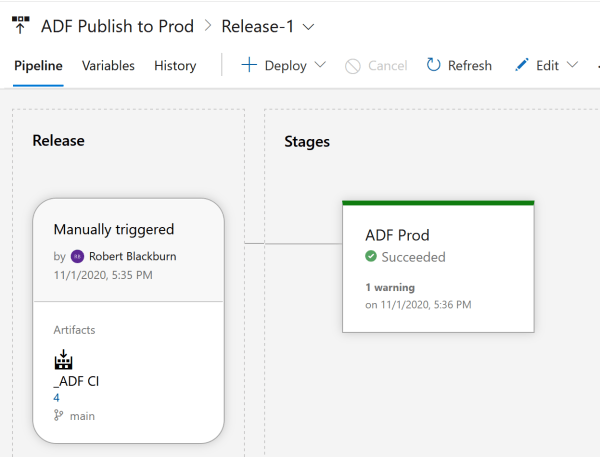
Let’s take a look at the production ADF after hitting refresh.

And finally, verify the correct key vault is being used.
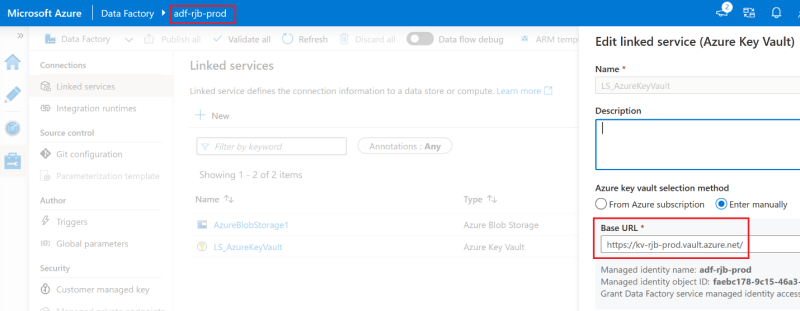
Specify the release to publish
When publishing to environments other than Development, we want to choose the build instead of always taking the latest build.
When we are ready to publish to production, we check the version in UAT. Pretend our Prod release is UAT and we see Build 4 is in UAT.
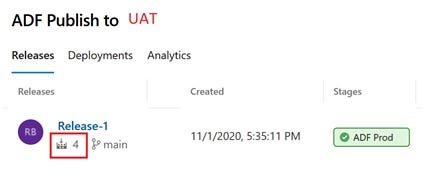
Edit the Release Pipeline to select the build version for production. Click on the Artifact, Change the Default version to Specific Version, and in the drop-down select version 4.

Save the changes and Create Release to publish version 4.

Enable Continuous Integration
Go back to the Build pipeline and select Edit. On the Triggers tab check Enable continuous integration. Click Save & queue then click save.
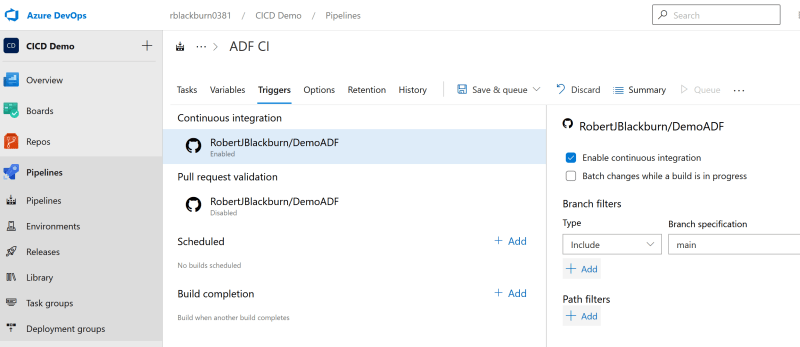
On the release pipeline for Dev, set the schedule for each night if there were changes. Save changes.

Conclusion
We can now enjoy many benefits including:
- Maintain one repo.
- Can save our work in branches.
- Automatically deploy to dev or another environment on a schedule.
- Publish to production in one click.
Related
CI/CD with GitHub Database Projects and Azure Pipelines
Originally published at https://robertjblackburn.com on November 2, 2020.
Subscribe to my newsletter
Read articles from Bob Blackburn directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by