CrowdStrike Chaos: What We Can Learn from the Global Outage
 Ujjwal Jha
Ujjwal Jha
Did you wake up to a world without computers one recent morning? If you did, you're not alone. A recent incident involving CrowdStrike, a cybersecurity giant, caused a massive global outage, bringing businesses, airlines, and even government agencies to a standstill.
What Happened?
An update to CrowdStrike caused a string reaction of the blue screen of death. Think of a hypothetical situation where, one fine day, every piece of Windows-based machinery in the world simply gave a big hacker’s salute and wouldn’t start up again. It was the stuff of nightmares as far as IT departments all around the globe were concerned. But as developers, we are not simply sitting and whining. This incident is a goldmine of lessons.
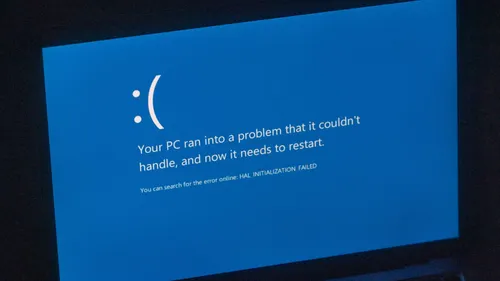
Lesson From The Trenches
Testing, Testing, Testing: This incident underscores the critical importance of rigorous testing. It's not just about unit tests or integration tests. We need to simulate real-world conditions as closely as possible. Imagine if CrowdStrike had a more robust testing environment that included various hardware configurations and operating systems.
Dependency Hell: This incident highlights the risks of relying on third-party software. While it's often convenient to use off-the-shelf solutions, we need to be aware of the potential consequences. Diversifying the tech stack and having backup plans can be lifesavers.
Incident Response: How did your organization handle the outage? Did you have a plan in place? How quickly were you able to recover? Every outage is a learning opportunity. Review your incident response procedures and identify areas for improvement.
Communication is Key: Clear and timely communication is essential during a crisis. CrowdStrike faced a barrage of criticism for their initial response. Learn from their mistakes and develop a communication strategy for when things go wrong.
What Can You Do?
Share your thoughts: Have you experienced similar issues? How did you handle them? Let's learn from each other.
Improve your craft: Dedicate time to improving your testing practices, dependency management, and incident response plans.
Stay informed: Keep up with industry news and best practices.
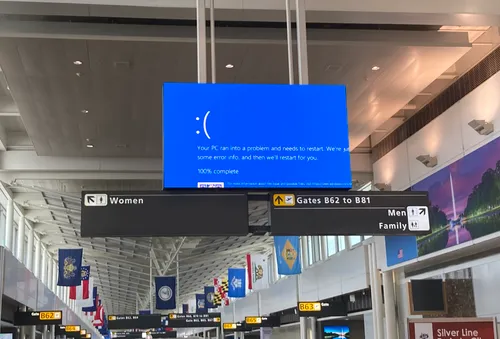
The CrowdStrike incident was a wake-up call for the entire tech industry. It's a reminder that even the biggest and best can stumble. By learning from these mistakes, we can build more resilient and reliable systems.
What are your thoughts on the CrowdStrike incident? Share your experiences and insights in the comments below.
Subscribe to my newsletter
Read articles from Ujjwal Jha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by