No Data, No Problem: Ingesting FAKE Data Might Increase Your Productivity 🚀🚀🚀
 Marwane Chahoud
Marwane Chahoud
Introduction
Whether you join a data engineering project or start one from scratch with a team, you will surely face many problems. One common issue, which can sometimes be a major obstacle, is missing data! In a real-world project, your team often depends on another team to provide or grant access to their data. In this blog, I'm suggesting a methodology I started using to overcome this problem by mocking data.
Use-case
I've faced this problem before: "starting a project but the data isn't ready yet!" As a data engineer, the simplest thing I can do to help the team be more productive and focus on delivering resilient data pipelines is to mock the data. But how? By using Python 😉

The steps to mock your data are as follows:
Ask the right person in your organization for a data sample or data scheme (ex: what a JSON look like? data schema? etc.)
write your Python script (aka mock script)
and start ingesting!
The example we will be using to illustrate how to mock the data is the Android mobile payment from Google as described below:
"transactionInfo": {
"currencyCode": "USD",
"countryCode": "US",
"totalPriceStatus": "FINAL",
"totalPrice": "12.00",
"checkoutOption": "COMPLETE_IMMEDIATE_PURCHASE"
}
I took only the transactionInfo property to keep it simple!
To ingest data, I'll be using elastic on Kubernetes (ECK), if you don't know what is ECK check my previous blog.
Prerequisite
For this blog you need:
python and pip installed
docker-desktop or equivalent
ECK cluster (we will cover the deployment manifest only)
Tools
For the mock script, we will be using Faker, a Python package that generates fake data based on providers. It can be used for creating sample data, stress testing your database, anonymizing data, and more.
Faker providers: https://faker.readthedocs.io/en/master/index.html#contentsSince we'll ingest data in an elastic cluster, we'll be using python elasticsearch client for indexing data
Demo
Preparing the environment
- create a file named
requirements.txtand paste the following:
elasticsearch==8.6.0
Faker
- open a terminal from your workspace and run the following command to install both Faker and elasticsearch APIs:
pip install -r requirements.txt
- apply the following eck yaml deployment to spin up a single node elastic cluster using
kubectl apply -f eck.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: eck
---
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
namespace: eck
spec:
version: 8.6.0
nodeSets:
- name: default
count: 1
config:
node.store.allow_mmap: false
---
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: quickstart
namespace: eck
spec:
version: 8.6.0
count: 1
elasticsearchRef:
name: quickstart
config:
csp.strict: false # delete this in production
- open two terminals and in each port forward elasticsearch and kibana because we will need them later:
kubectl port-forward service/quickstart-es-http -n eck 9200:9200
kubectl port-forward service/quickstart-kb-http -n eck 5601:5601
- retrieve the elasticsearch password of the user elastic:
kubectl get secret quickstart-es-elastic-user -o go-template='{{.data.elastic | base64decode}}' -n eck
# for me the password is: 3mRv07k6QPBun5k37Lz5x58B
Once all is set up, we will write our script to ingest FAKE data!
Faking it!
As said earlier we'll be using Faker to ingest fake data. The following code has 3 parts:
establishing a connection with elasticsearch cluster
structuring and generating fake data based on the given scheme
indexing the data to elasticsearch
The code doing it all:
import os,sys
import time
from faker import Faker
from datetime import datetime, timezone
import random
from elasticsearch import Elasticsearch
# Read input from environment variables
HOST = os.environ.get("ES_HOST", "localhost")
USER = os.environ.get("ES_USER", "elastic")
PASSWORD = os.environ.get("ES_PASSWORD", "3mRv07k6QPBun5k37Lz5x58B")
PORT = os.environ.get("ES_PORT", "9200")
SCHEME = os.environ.get("ES_HTTP_SCHEME", "https")
TIMEOUT = os.environ.get("ES_TIMEOUT", 60)
INDEX_NAME = "myindex"
fake = Faker()
# Construct Elasticsearch client
try:
es = Elasticsearch(
SCHEME+"://"+HOST+":"+PORT,
basic_auth=(USER, PASSWORD),
verify_certs=False, # dont do it in production
request_timeout=TIMEOUT
)
except Exception as e :
print("An exception occurred during connecting to elasticsearch, see: " + str(e))
print(es.info())
while True:
try:
dt_obj = datetime.fromtimestamp(time.time(), tz=timezone.utc)
ft_time = dt_obj.strftime('%Y-%m-%dT%H:%M:%S')
# Generate a document
doc = {
"@timestamp": ft_time,
"user_agent": fake.chrome(),
"transactionInfo": {
"currencyCode": fake.currency_code(),
"countryCode": fake.country_code(),
"totalPriceStatus": "FINAL",
"totalPrice": fake.pricetag(),
"checkoutOption": "COMPLETE_IMMEDIATE_PURCHASE"
},
"transactionId": fake.uuid4()
}
print("Inserting\n")
print(doc)
# Insert the document, create the data stream before
obj = es.index(index=INDEX_NAME, body=doc)
print(obj)
# Wait a random amount of time before inserting the next document
time.sleep(random.uniform(1, 5))
except Exception as e :
print("An exception occurred during inserting to elasticsearch, see: " + str(e))
and execute it: python index.py
As you can see, I added some fields to the transaction documents to make them more realistic, such as the @timestamp and user_agent fields. These are fields you would typically find on an e-commerce website!
After indexing a few data, the output of the python script should be similar to this:
InsecureRequestWarning: Unverified HTTPS request is being made to host 'localhost'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#tls-warnings
warnings.warn(
{'name': 'quickstart-es-default-0', 'cluster_name': 'quickstart', 'cluster_uuid': '58FWbUB2RZCFORZOTcGK8A', 'version': {'number': '8.6.0', 'build_flavor': 'default', 'build_type': 'docker', 'build_hash': 'f67ef2df40237445caa70e2fef79471cc608d70d', 'build_date': '2023-01-04T09:35:21.782467981Z', 'build_snapshot': False, 'lucene_version': '9.4.2', 'minimum_wire_compatibility_version': '7.17.0', 'minimum_index_compatibility_version': '7.0.0'}, 'tagline': 'You Know, for Search'}
Inserting
{'@timestamp': '2024-08-20T12:28:47', 'user_agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 8_4_1 like Mac OS X) AppleWebKit/534.1 (KHTML, like Gecko) CriOS/15.0.882.0 Mobile/19T537 Safari/534.1', 'transactionInfo': {'currencyCode': 'MYR', 'countryCode': 'BB', 'totalPriceStatus': 'FINAL', 'totalPrice': '$50,451.34', 'checkoutOption': 'COMPLETE_IMMEDIATE_PURCHASE'}, 'transactionId': '12a2931c-a10d-4194-a0b0-72156e5622c2'}
C:\Users\User\blog\generating fake data\index.py:57: DeprecationWarning: The 'body' parameter is deprecated and will be removed in a future version. Instead use the 'document' parameter. See https://github.com/elastic/elasticsearch-py/issues/1698 for more information
obj = es.index(index=INDEX_NAME, body=doc)
C:\Users\User\AppData\Local\Programs\Python\Python312\Lib\site-packages\urllib3\connectionpool.py:1103: InsecureRequestWarning: Unverified HTTPS request is being made to host 'localhost'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#tls-warnings
warnings.warn(
{'_index': 'myindex', '_id': '6_3Cb5EBA1P9K0SA3UtZ', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 416, '_primary_term': 1}
#...
You can ignore the warnings. If you want to deploy this code in production please update it based on elasticsearch python API.
After a few minutes, create a Kibana data view and your data is ready on elastic:
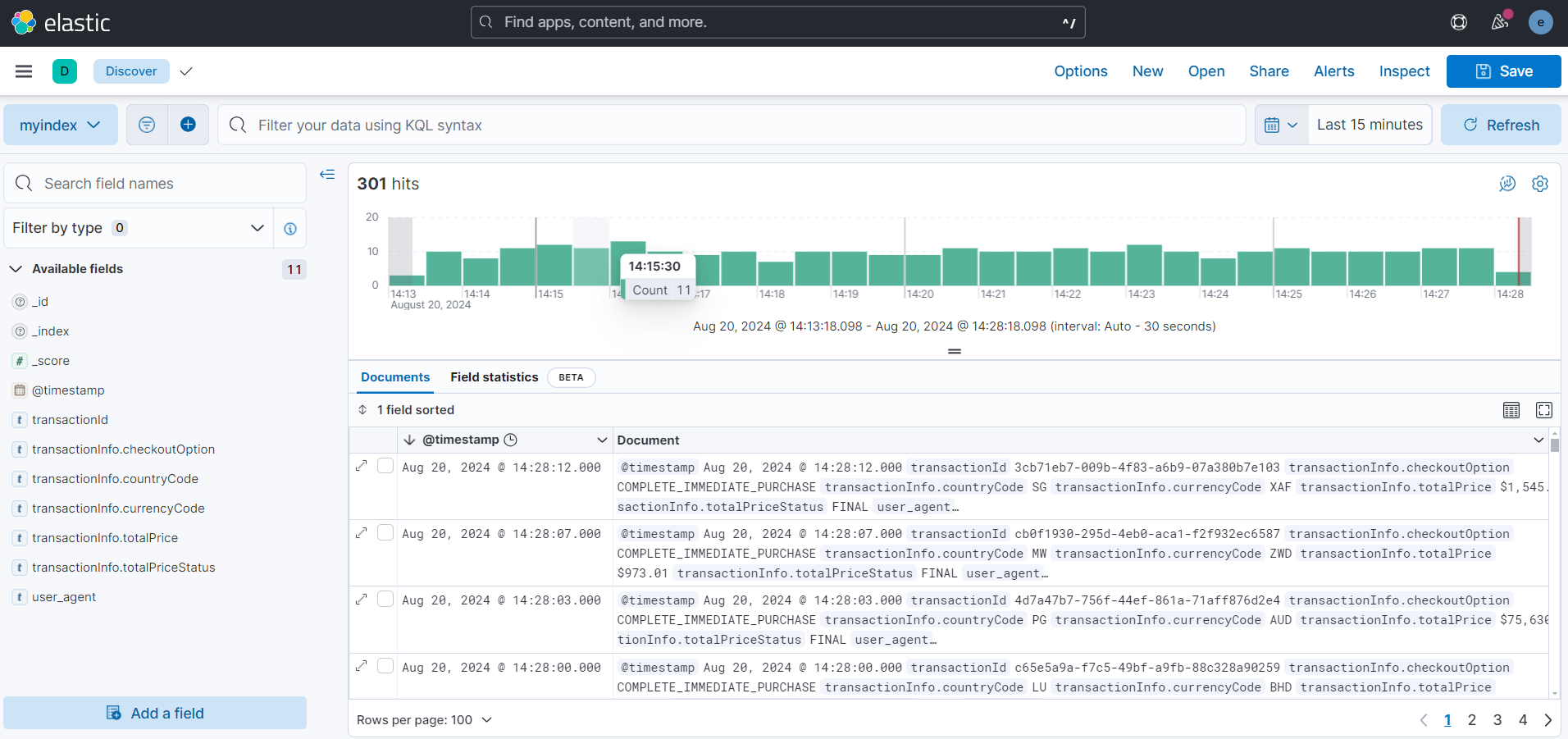
Conclusion
This quick blog was a way to illustrate how to overcome such a problem when data isn't ready, but always prioritize working with production data as soon as it becomes available to ensure accuracy and reliability.
Subscribe to my newsletter
Read articles from Marwane Chahoud directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Marwane Chahoud
Marwane Chahoud
Hey everyone! I'm a data engineer & an Elastic Certified based in France. My main stack is Elastic and Kubernetes, here to learn and share :)