Convert HTML to PDF
 Anjanesh Lekshminarayanan
Anjanesh Lekshminarayanan
One very frequently wanted requirement was to convert HTML to PDF. And all this while I was using mPDF which so far does a very good job in PDF creation. Though this one is PHP based, there are some equivalents out there for Python like xhtml2pdf and WeasyPrint, but the more assured ones are which are browser-based libraries like pyhtml2pdf which has a dependency of Chrome webdriver. Now if you're on a desktop version of an OS and have Chrome installed then you're good but if you have to install Chrome webdriver on a server like Ubuntu, it can be a real nightmare.
Also, if you want to use the latest and greatest features available in HTML5 and CSS3 we need to use Chrome (Chromium) because mPDF's creator himself has mentioned on newer CSS support will most likely not be implemented - quote from GitHub link :
mPDF as a whole is a quite dated software. Nowadays, better alternatives are available, albeit not written in PHP.
Use mPDF if you cannot use non-PHP approach to generate PDF files or if you want to leverage some of the benefits of mPDF over browser approach – color handling, pre-print, barcodes support, headers and footers, page numbering, TOCs, etc. But beware that a HTML/CSS template tailored for mPDF might be necessary.
If you are looking for state of the art CSS support, mirroring existing HTML pages to PDF, use headless Chrome.
mPDF will still be updated to enhance some internal capabilities and to support newer versions of PHP, but better and/or newer CSS support will most likely not be implemented.
I was okay with not having what was new 5 years ago like flex and grid but not today.
Until I stumbled upon browserless.io - it's like searching for a invisible needle in a burning haystack if you're not using the keyword docker in the search box. browserless does all the dirty work of installing not just chromium headless, but firefox and webkit headless as well. With browserless, you can open any URL or read an HTML page from a file parse the contents programmatically like you would normally do. The open-source code for the implementation is at https://github.com/browserless/browserless and can be installed on your server.
So far, to HTML to PDF conversion in browserless is only supported by the chromium driver and not firefox and webkit drivers.
cd test
mkdir html2pdf
cd html2pdf
python3 -m venv env
source env/bin/activate
pip install playwright
playwright install
The final playwright install should show something like this :
Downloading Chromium 128.0.6613.18 (playwright build v1129) from https://playwright.azureedge.net/builds/chromium/1129/chromium-mac-arm64.zip
138.1 MiB [====================] 100% 0.0s
Chromium 128.0.6613.18 (playwright build v1129) downloaded to /Users/anjanesh-m2/Library/Caches/ms-playwright/chromium-1129
Downloading FFMPEG playwright build v1009 from https://playwright.azureedge.net/builds/ffmpeg/1009/ffmpeg-mac-arm64.zip
1 MiB [====================] 100% 0.0s
FFMPEG playwright build v1009 downloaded to /Users/anjanesh-m2/Library/Caches/ms-playwright/ffmpeg-1009
Downloading Firefox 128.0 (playwright build v1458) from https://playwright.azureedge.net/builds/firefox/1458/firefox-mac-arm64.zip
79.6 MiB [====================] 100% 0.0s
Firefox 128.0 (playwright build v1458) downloaded to /Users/anjanesh-m2/Library/Caches/ms-playwright/firefox-1458
Downloading Webkit 18.0 (playwright build v2051) from https://playwright.azureedge.net/builds/webkit/2051/webkit-mac-14-arm64.zip
68.2 MiB [====================] 100% 0.0s
Webkit 18.0 (playwright build v2051) downloaded to /Users/anjanesh-m2/Library/Caches/ms-playwright/webkit-2051
If you're on Ubuntu it may ask you to install some dependencies which you can do so using sudo apt-get install - the list of dependencies will be mentioned right after when you execute playwright install
Some of the dependencies for Ubuntu :
sudo apt-get install libwoff1 libopus0 libwebpdemux2 libharfbuzz-icu0 libenchant-2-2 libsecret-1-0 libhyphen0 libflite1 libegl1 libevdev2 libgles2 gstreamer1.0-libav
If you're experiencing difficulty on Windows try this :
cd test
mkdir html2pdf
cd html2pdf
python -m venv env
.\env\Scripts\Activate.ps1
python -m pip install playwright
python -m pip show playwright
Name: playwright
Version: 1.46.0
Summary: A high-level API to automate web browsers
Home-page: https://github.com/Microsoft/playwright-python
Author: Microsoft Corporation
Author-email:
License: Apache-2.0
Location: C:\test\htm2pdf\env\Lib\site-packages
Requires: greenlet, pyee
Required-by:
cd C:\test\htm2pdf\env\Scripts
playwright install
cd C:\test\htm2pdf
Now create a file called convert.py with the following python code :
import asyncio
from playwright.async_api import async_playwright
async def html_to_pdf(html_file_path, pdf_file_path):
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page()
# HTML file
with open(html_file_path, 'r') as file:
html_content = file.read()
await page.set_content(html_content)
# Save as PDF
await page.pdf(path=pdf_file_path, print_background=True)
await browser.close()
html_file = 'example.html'
pdf_file = 'output.pdf'
asyncio.run(html_to_pdf(html_file, pdf_file))
Now download this example.html file either from my AWS S3 link or my Bunny link.
If you run python convert.py you should see a PDF generated like this in the same current folder.
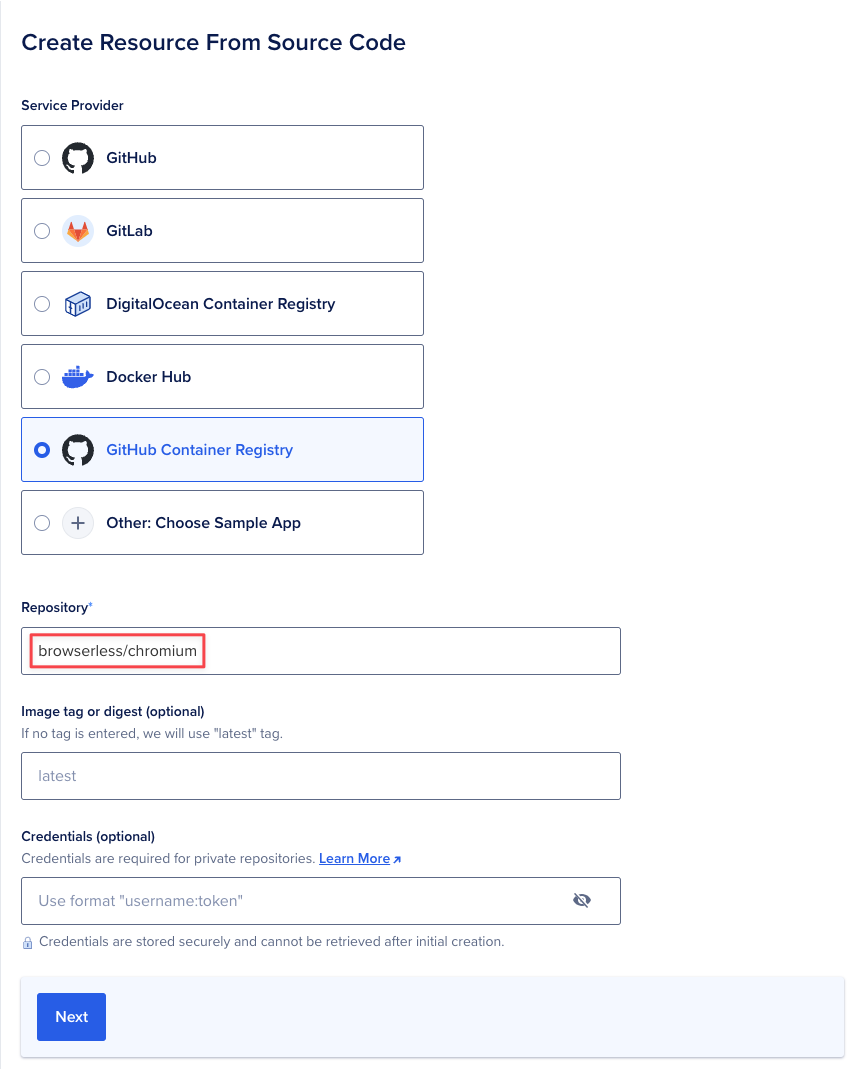
If you're interested in running browserless as a standalone service in a separate app, and can spare atleast $5 a month, try using DigitalOcean App Platform where you can provide a GitHub Container Registry URL which is docker pull ghcr.io/browserless/base:latest as mentioned here : https://github.com/browserless/browserless/pkgs/container/base
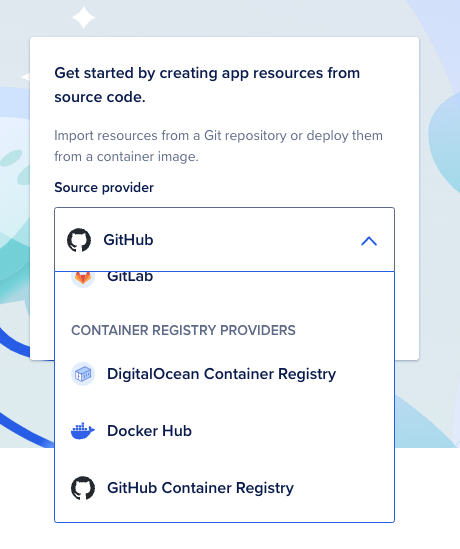
Enter the following details (in red) :
Use port 3000
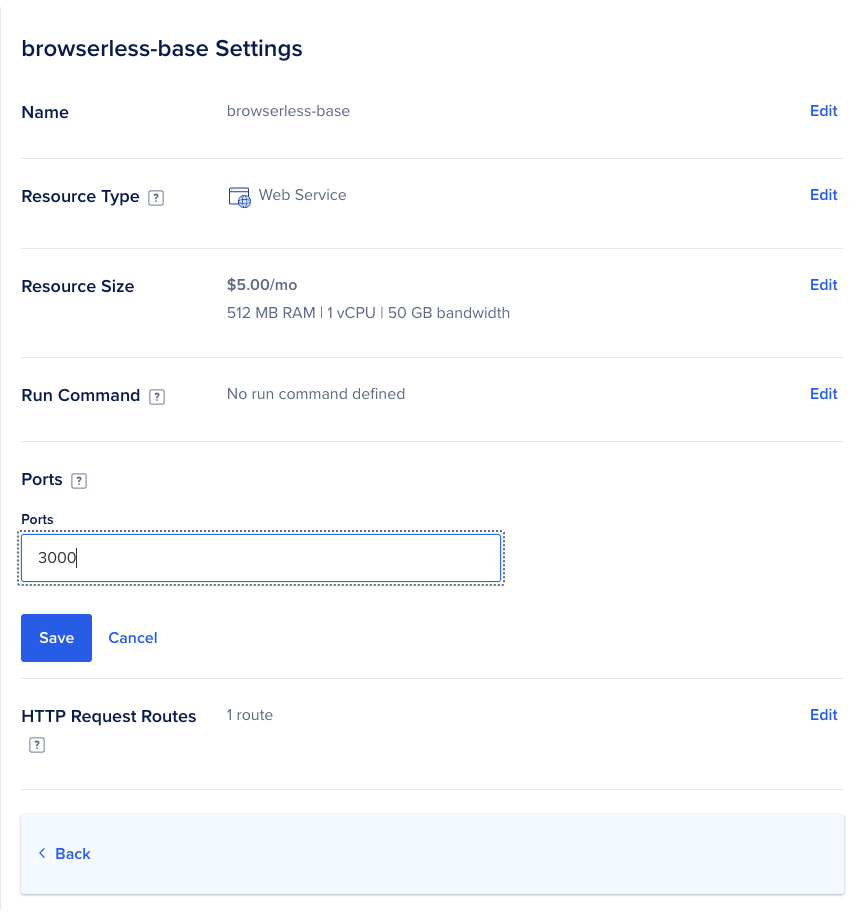
This is the general idea - once docker is setup on a DigitalOcean App you can call the App URL as a service to send in the HTML content and generate the PDF as output.
Replace the URL (production-sfo.browserless.io) in the code mentioned here (https://docs.browserless.io/Libraries/playwright#python-playwright) with the DigitalOcean App Platform URL. It should work. And instead of p.firefox.connect it should be p.chromium.connect.
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.firefox.connect('wss://production-sfo.browserless.io/firefox/playwright?token=GOES-HERE')
context = browser.new_context()
page = context.new_page()
page.goto('http://www.example.com', wait_until='domcontentloaded')
print(page.content())
context.close()
When I was in college in Coimbatore way back in 2001 I went to the main street in RS Puram just walking past all the shops on one side of the road. I finally hit a sign that read Your Search Ends here and saw there were no more shops as it was more-or-less like a dead end. Hopefully your search for a PDF generator too ends here !
Subscribe to my newsletter
Read articles from Anjanesh Lekshminarayanan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Anjanesh Lekshminarayanan
Anjanesh Lekshminarayanan
I am a web developer from Navi Mumbai. Mainly dealt with LAMP stack, now into Django and getting into Laravel and Google Cloud. TensorFlow in the near future. Founder of nerul.in and gaali.in