Dimensional Data Model for Ride-Sharing App Analytics
 Analytics Engineering Digest
Analytics Engineering Digest
Cover photo credits: Ehsan Haque via Pexels
"Dimensional models are gracefully extensible to accommodate change. The predictable framework of a dimensional model withstands unexpected changes in user behavior"
- Ralph Kimball
Understanding the Business Process
When designing the data model of a data warehouse for a ride-sharing platform, or any other industry, it is crucial that we understand the core business process. The questions "what business process are we trying to capture and model?" and "what do we want to measure?" should always arise.
In this case, we want to know the number of daily users, the number of drivers available at various times throughout the week, the percentage of cancelled rides, the revenue generated, among other key metrics. These metrics are useful to decision makers to assess where they should shift their focus.
To generate these metrics, we need to capture the rides and all the details surrounding the rides. In our model the ride is the primary grain, and it establishes a solid foundation for analysis and reporting. In this blog post, we discuss the dimensional modeling approach for the data warehouse, the fact table, and also the dimension tables.
Let's dive right in!
Core Components of the Dimensional Model
In case you're not familiar with Kimball's dimensional modeling approach, this approach focuses on structuring data into fact and dimension tables for efficient analytics. It prioritizes business needs over technical considerations.
Before we design the tables, let's try to understand the entities, which later will be come the dimensions, and how the are related.
The things and people involved are the entities and they are related via relationships. The entities will become the dimension tables, and the relationships is how we connect these dimensions via the fact table. The fact table is where we track the measurable activity, and its grain is determined by the business process we want to measure.
The entities involved are the customer, the driver, the vehicle, the payment method, and the promotions. Notice the ride is central to the whole process, and the ride has multiple stages. It's starts with the request, the acceptance, the pick up and the drop off. We'll capture these stages using timestamps.
Implementation of our Data Model
Disclaimer: This model is for educational purposes, and companies like Uber, Lyft, Yandex, Cabify, and DiDi have large data teams dedicated to creating cutting edge data models.
We create the fact table fact_rides and the dimension tables dim_customers, dim_drivers, dim_vehicles, dim_promo, dim_payments, and dim_date.
Since it makes sense to define the grain at the ride level, our fact table's unique identifier, or primary key, will be the rider_id. The foreign keys will be the primary keys of the dimension tables, such as, customer_id, vehicle_id, driver_id, promo_id, date_id Our fact table will have have additional attributes such as timestamps for the request, the cancellation (if any), the pick up, and the drop off. Additionally, it will include the cost of the ride, the distance traveled.
CREATE TABLE fact_rides (
ride_id BIGINT PRIMARY KEY,
date_id BIGINT,
request_ts TIMESTAMP,
pickup_ts TIMESTAMP,
dropoff_ts TIMESTAMP,
cancel_ts TIMESTAMP,
is_request_rush_hour BOOLEAN,
pickup_address VARCHAR(255),
dropoff_address VARCHAR(255),
distanced_traveled_km DECIMAL(10, 2),
driver_id BIGINT,
vehicle_id BIGINT,
customer_id BIGINT,
payment_id BIGINT,
ride_cost_usd DECIMAL(10, 2),
ride_tax_usd DECIMAL(10, 2),
promo_id BIGINT,
rating_for_driver INT,
rating_for_customer INT,
FOREIGN KEY (date_id) REFERENCES dim_date(date_id),
FOREIGN KEY (driver_id) REFERENCES dim_drivers(driver_id),
FOREIGN KEY (vehicle_id) REFERENCES dim_vehicles(vehicle_id),
FOREIGN KEY (customer_id) REFERENCES dim_customers(customer_id),
FOREIGN KEY (promo_id) REFERENCES dim_promos(promo_id),
FOREIGN KEY (payment_id) REFERENCES dim_payments(payment_id)
);
Our next step is to create the dimensions tables using the attributes of each of those entities.
We start with the customer. Some of the attributes below are obvious, such as name, address, and email. These are used to calculate how active the customers are in the past week or past four weeks.
CREATE TABLE dim_customers (
customer_id BIGINT PRIMARY KEY,
first_name VARCHAR(100),
middle_name VARCHAR(100),
last_name VARCHAR(100),
address VARCHAR(255),
city VARCHAR(255),
state VARCHAR(255),
zip_code VARCHAR(255),
country VARCHAR(225)
phone_number VARCHAR(20),
email VARCHAR(100),
dob DATE,
sign_up_date DATE,
rides_last7d INT,
rides_last_28d INT,
rides_total INT,
rating_current DECIMAL(2, 1)
);
Next we create the remaining dimensions table, such as, dim_drivers, dim_vehicles, dim_date, dim_promos, and dim_payments.
CREATE TABLE dim_drivers (
driver_id BIGINT PRIMARY KEY,
first_name VARCHAR(100),
middle_name VARCHAR(100),
last_name VARCHAR(100),
address VARCHAR(255),
city VARCHAR(255),
state VARCHAR(255),
zip_code VARCHAR(255),
country VARCHAR(225)
phone_number VARCHAR(20),
email VARCHAR(100),
dob DATE,
driver_license VARCHAR(20),
driver_license_iss_date DATE,
driver_license_exp_date DATE,
driver_license_state VARCHAR(2),
driver_license_is_active BOOLEAN,
sign_up_date DATE,
rides_last7d INT,
rides_last_28d INT,
rating DECIMAL(2, 1),
complaints_last7d INT,
complaints_last28d INT,
complaints_total INT
);
CREATE TABLE dim_vehicles (
vehicle_id BIGINT PRIMARY KEY,
year_vehicle INT,
make VARCHAR(50),
model VARCHAR(50),
trim VARCHAR(50),
color VARCHAR(50),
sign_up_date DATE,
inspection_iss_date DATE,
inspection_exp_date DATE,
is_active BOOLEAN
);
CREATE TABLE dim_promos (
promo_id BIGINT PRIMARY KEY,
start_date DATE,
end_date DATE,
is_active BOOLEAN,
promo_amount INT,
promo_pct INT
);
Often overlooked because it isn't a thing or person, the dim_date table is a must when building a data warehouse. This table isn't be unique to this model, but it is necessary for running meaningful analytics on this data. It makes the life of every data analyst and data scientist easier, because it allows them to slice metrics by weekday vs weekend, by week number, by quarter, etc.
CREATE TABLE dim_date (
date_id BIGINT PRIMARY KEY,
date_dt DATE
year INT,
month INT,
day INT,
quarter INT,
yyyy_mm VARCHAR(6),
yyyy_qtr VARCHAR(6),
week_start_date DATE,
week_end_date DATE,
month_start DATE,
month_end DATE,
month_name VARCHAR(10),
week_day VARCHAR(10),
week_num INT,
is_weekend BOOLEAN
);
Now we have functional model, and it roughly looks like this. This is also known as STAR schema, with the fact table in the middle and the dimension table around it.
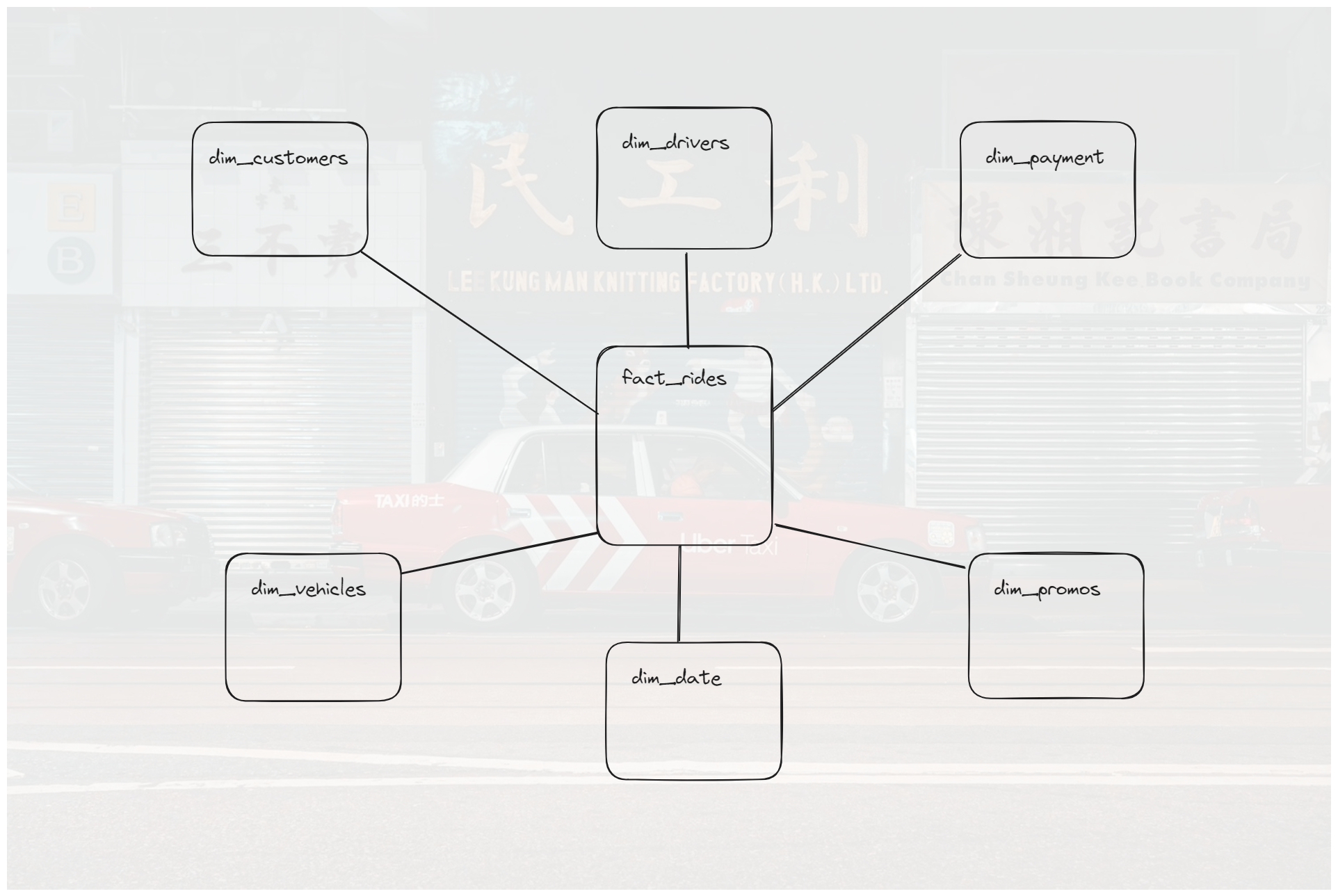
Using SQL to Create Metrics and Answer Business Questions
Now that we've created the tables, let's answer some questions using SQL.
- Find the average daily rides for the current year
WITH daily_rides AS (
SELECT date_id
, COUNT(ride_id) AS total_rides
FROM fact_rides
WHERE 1=1
AND EXTRACT(YEAR FROM date_id) = EXTRACT(YEAR FROM CURRENT_DATE)
AND cancel_ts IS NULL -- filters out cancelled rides
GROUP BY date_id
)
SELECT AVG(total_rides) AS avg_daily_rides_ytd
FROM daily_rides;
- Find the average rides on weekend late nights for the current year
WITH weekend_night_rides AS (
SELECT fr.date_id
, COUNT(fr.ride_id) AS weekend_night_rides
FROM fact_rides fr
INNER JOIN dim_date dd
ON fr.date_id = dd.date_id
WHERE 1=1
AND dd.is_weekend = 'Y'
AND cancel_ts IS NULL
AND EXTRACT(HOUR FROM fr.request_ts) >= 20
AND EXTRACT(HOUR FROM fr.request_ts) <= 2
AND EXTRACT(YEAR FROM fr.date_id) = EXTRACT(YEAR FROM CURRENT_DATE)
GROUP BY fr.date_id
)
SELECT AVG(weekend_night_rides) AS avg_weekend_night_rides_ytd
FROM weekend_night_rides;
- Find the average number of Saturday night drivers
WITH saturday_night_drivers AS (
SELECT fr.date_id
, COUNT(DISTINCT fr.driver_id) AS drivers
FROM fact_ride_details fr
INNER JOIN dim_date dd
ON frd.date_id = dd.date_id
WHERE 1=1
AND EXTRACT(HOUR FROM fr.request_ts) >= 20
AND EXTRACT(HOUR FROM fr.request_ts) <= 2
GROUP BY fr.date_id
)
SELECT AVG(drivers) AS avg_saturday_night_drivers
FROM saturday_night_drivers;
The Power of Dimensional Modeling for Ride-Sharing
By constructing a well-defined dimensional model, ride-sharing companies can effectively analyze their operations, identify trends, and make data-driven decisions. The foundation laid in this blog post provides a framework for building a robust data warehouse that supports various analytical needs. To further optimize performance and scalability, consider implementing indexing, partitioning, and implementing data quality measures.
By leveraging the power of dimensional modeling, businesses can unlock the full potential of their data and gain a competitive edge.
Hope you found this helpful!
Subscribe to my newsletter
Read articles from Analytics Engineering Digest directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Analytics Engineering Digest
Analytics Engineering Digest
Analytics Engineer Digest is dedicated to sharing expert insights and practical knowledge in the field of analytics engineering. With a focus on data modeling, data warehousing, ETL/ELT processes, and the creation of high-quality datasets, this blog serves as a resource for building scalable data architectures that drive business success. Readers can explore real-world data models, interview preparation tips, and best practices for crafting metrics, dashboards, and automated workflows using SQL, Python, and AWS tools. Analytics Engineer Digest is committed to empowering data professionals to elevate their skills and unlock the full potential of their analytics projects.