Arquitectura Hexagonal con Java y Spring 2
 Gabriel Eguia
Gabriel Eguia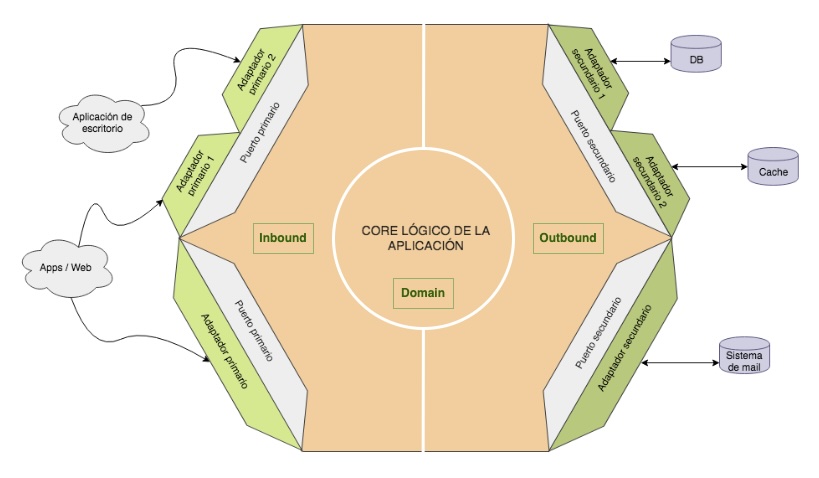
Este tutorial es la segunda parte de “Arquitectura Hexagonal con Java y Spring”, el cuál fue pensado originalmente por el gran Miguel Marroquí como una serie en la cual se pudiera ir viendo paso a paso como ir modificando un proyecto para ir incorporando distintas estrategias de arquitectura limpia, los problemas que intentan solucionar y las ventajas de cada uno. Entre los conceptos que tratamos en esta entrega se encuentran la arquitectura hexagonal, el patrón de puertos y adaptadores y Domain-Driver Design (DDD), los cuales asumimos que el lector ya se encuentra familiarizado.
Está claro que todas estos conceptos son para aplicar en proyectos de mayor envergadura que el que utilizamos como ejemplo, y que deben ser aplicados sólo si nos reportan algún beneficio o si en nuestro proyecto se nos presenta alguno de los problemas que estas buenas prácticas intentan solucionar. En ningún caso se deben interpretar estos conceptos como dogmas o leyes a seguir a rajatabla. Si nuestro proyecto es pequeño o no presenta ninguno de estos problemas, implementar estos conceptos podría equivaler a “matar moscas a cañonazos”, resultando en un sobre-diseño y agregando seguramente complejidad innecesaria. Las herramientas son para utilizarlas en los casos concretos para los que fueron pensadas, no de forma indiscriminada. No alimentemos a los haters! XD
Migue, ¡espero estar a la altura!.
Importante! Este artículo es una continuación de “Arquitectura Hexagonal con Java y Spring”, y parte del código de este. Si aún no lo leíste, te invito a hacerlo.
Introducción
En el artículo anterior, vimos la necesidad y los beneficios de separar “físicamente” nuestra lógica de negocio del detalle de la implementación. Esto lo resolvimos aplicando el concepto de puertos y adaptadores. De esta forma, se evita ensuciar nuestro modelo con código relativo a infraestructura (controladores REST, llamadas a bases de datos, etc).
Pero a pesar de que todo este código de la infraestructura no es más que herramientas que nuestra lógica de negocio utiliza, mezclar el código de nuestros controladores REST y de la base de datos en un mismo módulo puede parece algo antinatural, ya que mientras el primero le dice a nuestra lógica que hacer, al segundo es el dominio quien le indica que hacer. Esta es una diferencia fundamental con muchas implicaciones.
Otro problema que vemos en este enfoque es: ¿Qué impide que alguien, por error, termine inyectando un repositorio JPA en un controlador REST? Nada. ¿Qué sucede si en el futuro necesitamos cambiar nuestra base a Mongo, por ejemplo? Tendremos que modificar nuestro controlador, ya que este tiene un fuerte acoplamiento con la implementación de la base de datos.
Para separar estos detalles y evitar estos problemas, podemos profundizar un poco más en el patrón de Puertos y Adaptadores.
Un poco de teoría
El patrón de diseño “Puertos y Adaptadores” establece que existen puertos primarios y secundarios. Los primarios o de entrada (driving port) permiten exponer funcionalidad hacia afuera de nuestra aplicación -como una interfaz de línea de comandos o una API REST- mientras que los secundarios o de salida (driven port) son interfaces que utiliza nuestra aplicación para acceder a cosas fuera de si misma -como una base de datos u otra API.
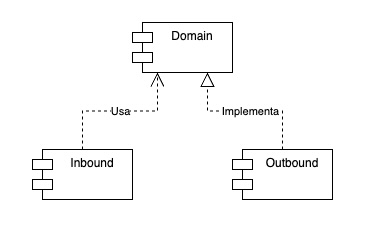
Esto nos permitiría separar el detalle de implementación en capas o módulos separados, y seguir manteniendo nuestra lógica de negocio completamente aislada de estos detalles de implementación. Podemos llamar a estas capas “Inbound” para los adaptadores primarios y “Outbound” para los secundarios, manteniendo la capa de “Domain para el modelo y lógica de negocio.
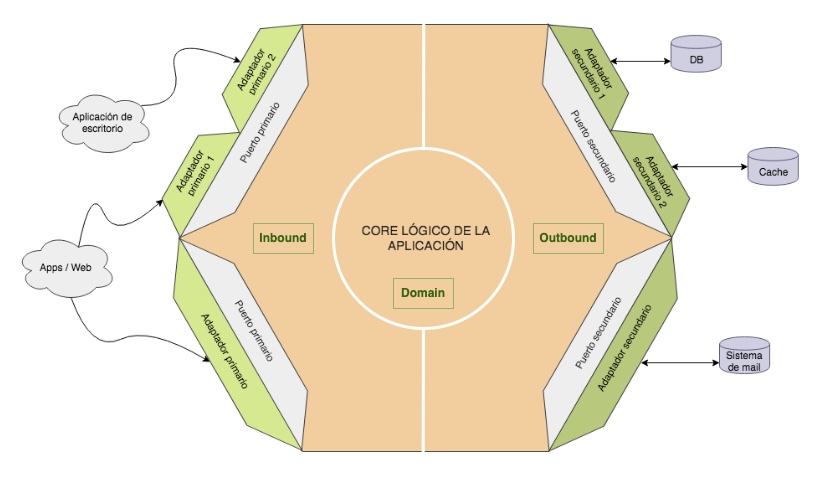
Si seguimos las enseñanzas del tío Bob (Robert C. Martin) en “Arquitectura limpia”, la mejor forma mantener el core de nuestra aplicación completamente independiente de los otros módulos es invertir el sentido de las dependencias, utilizando interfaces y/o inyección de dependencias. De esta forma, los adaptadores secundarios implementarán interfaces de los puertos secundarios en el módulo outbound, mientras que los adaptadores primarios, que implementan las interfaces de los puertos primarios en el propio módulo domain, son inyectados en el módulo inbound en los controladores y otros objetos que necesitan hacer uso de los mismos.
Preparando los nuevos módulos y ordenando nuestro código
Vamos a crear los nuevos módulos (ya borraremos los viejos más adelante, cuando hayamos verificado que todo funciona correctamente -para eso son los tests!), y a acomodar el código existente.
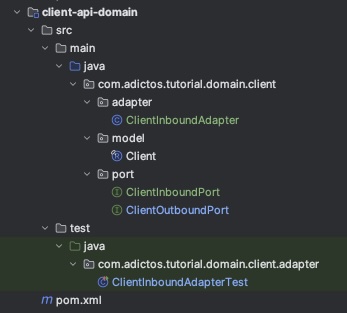
Para empezar, las interfaces de los puertos primarios y secundarios las llevaremos al módulo domain, ya que es la lógica de negocio la que define cómo se debe interactuar con ella y es esta quien sabe que datos necesita de los puertos secundarios para poder ejecutar. Separamos también el adaptador primario, que era una inner class, y le damos entidad propia como clase. Por último, vamos a aprovechar para renombrarlos puertos y adaptadores y poder distinguir los primarios (inbound) de los secundarios (outbound).
Nuestro módulo Domain quedaría así:
Luego, refactorizamos el código de los adaptadores primarios y secundarios, y los movemos a los módulos inbound y outbound respectivamente. Si pensamos los adaptadores como un análogo o símil de los “servicios” del Domain-Driver Design, podemos organizarlos siguiendo lo que nos aconseja DDD:
Los adaptadores que solo representan lógica de negocio e interactúan con objetos del dominio, se deben encontrar en el core domain.
Los adaptadores que interactúan con entidades externas, deben estar en la capa de infraestructura outbound, como por ejemplo
ClientJpaAdapter.
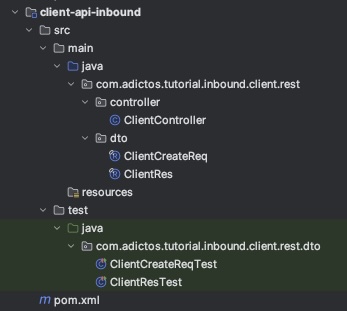
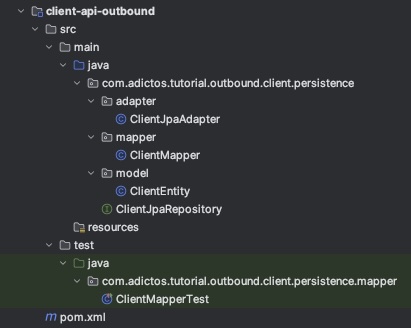
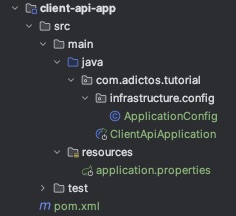
Ahora, resta decidir que hacer con la configuración de Spring que nos queda en el módulo de infraestructura. Podemos o bien renombrar el módulo a, por ejemplo, application o spring-application, o moverlo a uno de los módulos ya existentes. Al ser esto un API REST, creo que es una buena idea colocarlo en el módulo inbound, ya que este es el punto de entrada a la app y donde están los controladores de nuestra API, pero esto implicaría que este módulo tenga una dependencia con el módulo outbound (Spring necesita hacer el scan de componentes para poder iniciar la aplicación), lo cuál es lo que queríamos evitar. Entonces, optamos por darle un nombre con sentido a este módulo y ajustar el POM para tener las dependencias necesarias:
<dependencies>
<dependency>
<groupId>com.adictos.tutorial</groupId>
<artifactId>client-api-domain</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.adictos.tutorial</groupId>
<artifactId>client-api-inbound</artifactId>
<version>0.0.1-SNAPSHOT</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.adictos.tutorial</groupId>
<artifactId>client-api-outbound</artifactId>
<version>0.0.1-SNAPSHOT</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
</dependencies>
Finalmente, podemos borrar el módulo application.
De esta forma, el flujo de control de nuestra aplicación quedaría así:
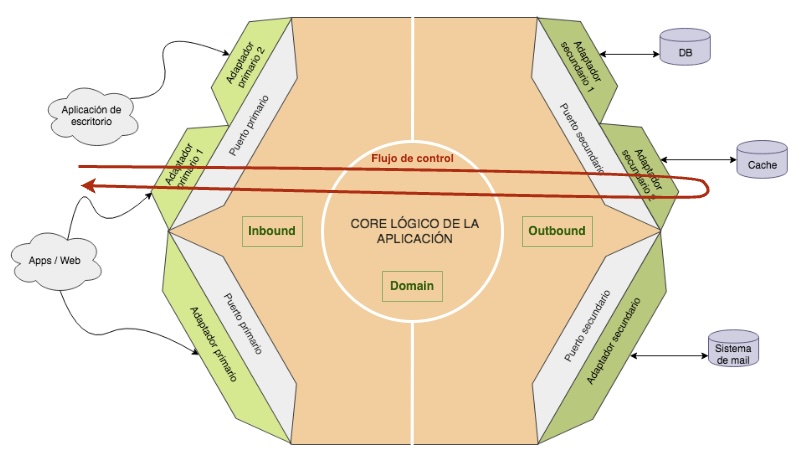
Conclusiones
Cómo se puede apreciar, agregar un nuevo adaptador primario o secundario en esta arquitectura es muy sencillo, ya que podemos hacerlo creando los paquetes necesarios dentro del módulo correspondiente o, si nos interesa mantener una separación más estricta, teniendo módulos separados para cada adaptador. Agregar o eliminar un adaptador no afecta de ninguna forma al resto de los módulos ni a la lógica de negocio, lo que da una gran flexibilidad a nuestra arquitectura.
Cabe destacar que esta organización de nuestra arquitectura no impediría que un adaptador primario haga uso directo de un puerto secundario y “saltear” así la lógica de negocio, pero nos asegura que nuestros adaptadores primarios están completamente desacoplados de los secundarios y un cambio en el tipo de base de datos no impactaría en nuestro controlador REST.
Les dejo el enlace al repo de GitHub para que puedan ver el código con más detalle, y les cuento que hay una versión anterior de este artículo en Adictos al trabajo.
Subscribe to my newsletter
Read articles from Gabriel Eguia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gabriel Eguia
Gabriel Eguia
Full Stack Developer. Application Analyst, Designer and Developer in many programming languages. Best practices, Clean Code, DevOps and Software craftsmanship enthusiastic. My goals are to grow in my career, learning new technologies and becoming a technical leader and referent, leading and influencing teams, and helping teammates to grow.