Introduction to Apache Kafka: Core Concepts and Its Role in Modern Data-Driven Applications
 Pravesh Sudha
Pravesh Sudha
💡 Introduction
According to official docs:
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation. It is designed to handle real-time data feeds through a high-throughput, low-latency platform. Kafka is used for building real-time data pipelines and streaming applications.
💡 Challenges Before Apache Kafka
Before Kafka, developers faced several challenges when working with large-scale data systems:
Scalability: Traditional message brokers struggled to scale horizontally to handle large volumes of data, leading to bottlenecks in processing.
Fault Tolerance: Ensuring that data was reliably delivered without loss, even in the case of system failures, was a complex task that required significant effort to implement and maintain.
Integration Complexity: Systems that needed to interact with multiple data sources often required custom connectors and integrations, which were not only difficult to maintain but also prone to errors.
High Latency: Legacy systems typically relied on batch processing, which introduced latency between the generation of data and its processing, making real-time analytics difficult to achieve.
Data Consistency: Maintaining data consistency across multiple distributed systems was challenging, particularly in scenarios where data needed to be replicated or synchronised between different services.
💡 How Kafka Solves These Problems
Apache Kafka addresses these issues with the following key features:
Scalability: Kafka's distributed architecture allows it to scale horizontally by adding more brokers (servers) to the cluster. This makes it possible to handle massive amounts of data efficiently.
Fault Tolerance: Kafka stores data across multiple nodes using partition replication. If one node fails, the data is still accessible from another, ensuring high availability and fault tolerance.
Real-Time Processing: Kafka's design supports real-time data streaming with low latency, enabling businesses to process data as it arrives and react to events in real time.
Decoupling Producers and Consumers: Kafka decouples data producers and consumers, allowing them to operate independently. This reduces the complexity of integrating multiple systems and makes the architecture more flexible and resilient.
Durability and Reliability: Kafka ensures data durability by persisting messages on disk and allowing them to be replayed by consumers. This makes it possible to recover from failures and ensures that no data is lost.
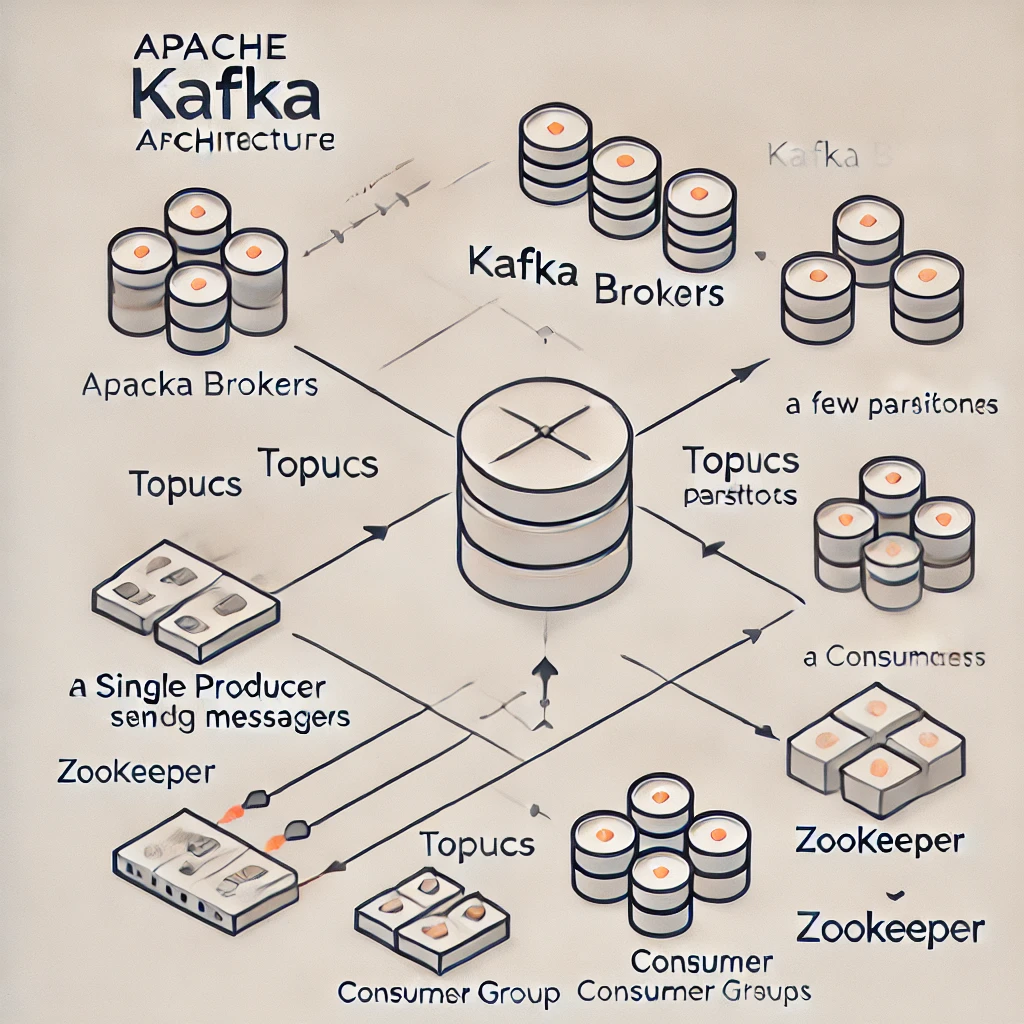
💡 Kafka Architecture
Understanding Kafka's architecture is key to appreciating its power and flexibility. Here's a breakdown of the core components:
Brokers: Kafka runs on a cluster of servers, each of which is called a broker. A Kafka cluster can have one or more brokers, and each broker can handle hundreds of partitions.
Topics and Partitions: Data in Kafka is categorized into topics, and each topic is divided into partitions. A partition is an ordered, immutable sequence of records that Kafka appends to. Partitions enable parallel processing and make Kafka scalable.
Producers: Producers are the applications that publish messages to Kafka topics. They can choose the specific partition within a topic to which they want to send the message.
Consumers: Consumers are the applications that read data from Kafka topics. They can read messages in real-time as they are produced.
Consumer Groups: A consumer group is a group of consumers that work together to consume messages from a topic. Kafka ensures that each message in a partition is read by only one consumer in the group, which allows for load balancing and fault tolerance.
ZooKeeper: Kafka relies on Apache ZooKeeper to manage and coordinate the Kafka brokers. ZooKeeper is responsible for leader election among brokers, configuration management, and maintaining metadata about the Kafka cluster.
The Image below represents a virtual depiction of the architecture:
💡 Consumer Groups in Kafka
Consumer groups are a powerful feature of Kafka that allows you to scale out the processing of messages. Here's how they work:
Parallelism: Each partition of a topic can be consumed by a different consumer within a consumer group. This allows for parallel processing of messages, which can significantly increase throughput.
Fault Tolerance: If a consumer in a group fails, Kafka automatically reassigns the partitions it was handling to the remaining consumers in the group, ensuring that processing continues without interruption.
Exactly-Once Semantics: Kafka can guarantee that each message is processed exactly once by a consumer group, even in the face of failures, which is crucial for maintaining data consistency.
Offset Management: Kafka tracks the offset (position) of the last consumed message for each consumer group, ensuring that each message is consumed only once and in the correct order.
💡Conclusion
Apache Kafka has revolutionised the way organisations handle and process data in real-time. By addressing the challenges of scalability, fault tolerance, and integration complexity, Kafka enables developers to build robust, scalable data pipelines that can handle the demands of modern applications. Its architecture, built on distributed principles, ensures high availability, low latency, and data durability, making it the go-to choice for real-time data streaming. With the added power of consumer groups, Kafka allows for efficient and fault-tolerant processing of large data streams, solidifying its position as a cornerstone of modern data infrastructure.
Whether you're dealing with real-time analytics, event sourcing, or building a microservices architecture, Kafka provides the foundation you need to process and analyze data at scale. As businesses continue to generate and rely on vast amounts of data, Kafka's role in the tech stack is only set to grow, making it an essential tool for developers and organizations alike.
If you enjoyed my blog, don't forgot to follow me on Hashnode, LinkedIn and Twitter (X), keep learning.
Till then, Happy Coding :)
Subscribe to my newsletter
Read articles from Pravesh Sudha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pravesh Sudha
Pravesh Sudha
Bridging critical thinking and innovation, from philosophy to DevOps.