How to Implement Data Replication and Versioning in Golang
 Adewole Caleb Erioluwa
Adewole Caleb ErioluwaTable of contents

My recent study of the replication chapter of the DDIA text was quite intense, and not so much fun since I had to process a lot of information. On the bright side, I gained practical insight into how to replicate data and why it is important in a distributed system. One interesting discussion is the meaning of durability in terms of replication, we will talk about that later in this article.
To keep things visual, let's imagine a client-server(s) interaction where the client uploads a video file in chunks to any server geographically present in the client's location.
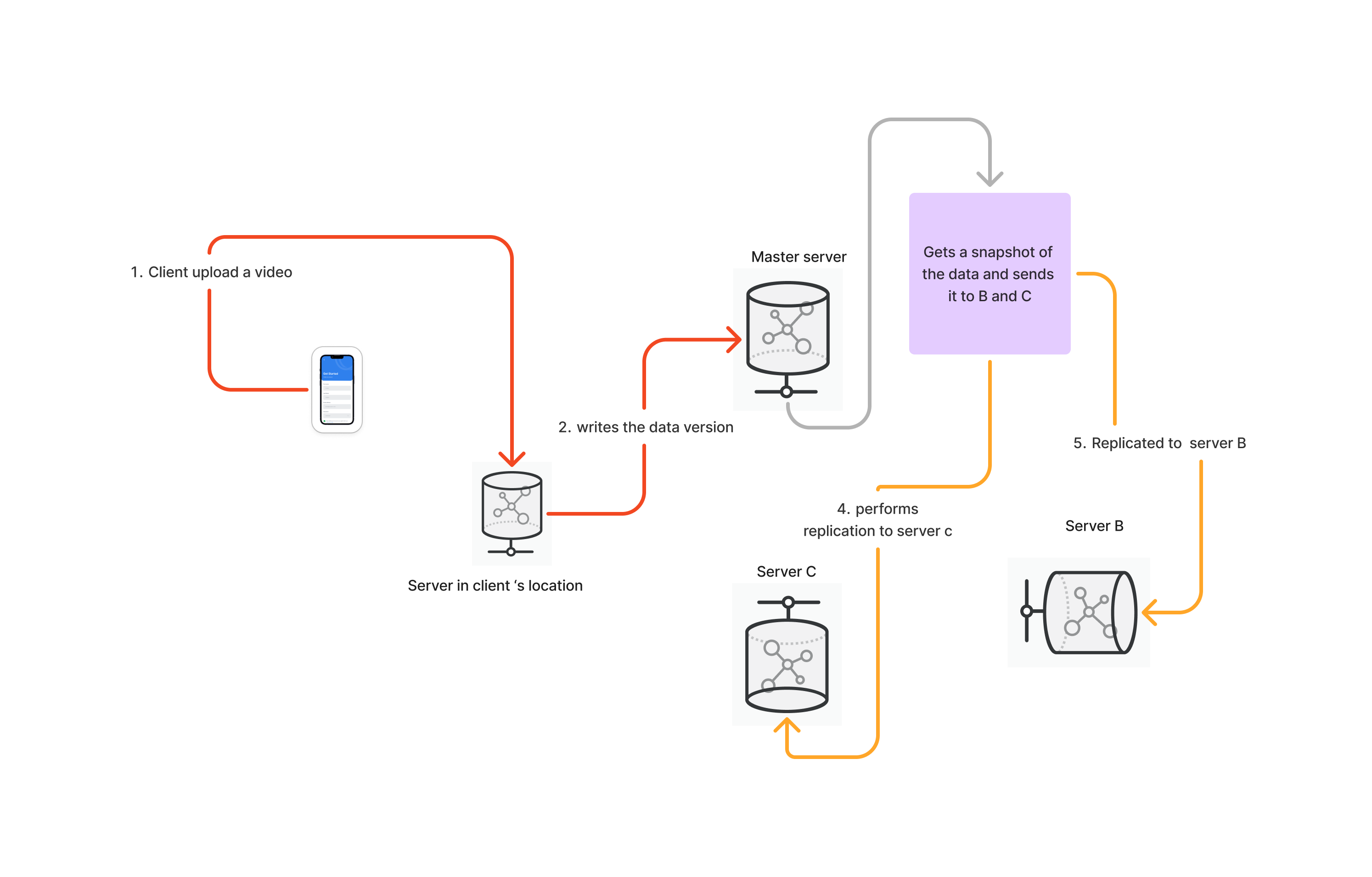
After the chunks are uploaded to the server, the chunk metadata, including the chunk ID, is sent to the master server. This allows the master server to assign a chunk version for data synchronisation between servers with the video chunk files and to identify stale chunks. If one of the chunks is updated, the version on the server must be changed so that the master server can determine which upload server has stale data and then replicate the updated data to that server.
Just a quick gist right 😅 ?
Let's go a step further by understanding what durability is and what replication is. Then, we'll see how they relate to each other so we can use this understanding to figure out how to apply replication in our application.
Durability - What it is.
Does it last long? Sure it does, therefore it is durable. Is that all that it is to durability?
No, that is a literal meaning of durability. This is not applicable in distributed computing as things are expected to fail or have faults. It could be hardware or software-related ones.
Durability in distributed systems means that once data is saved, it will remain intact even if there are failures, crashes, or other issues. This ensures that once an operation is finished, its results are permanently stored and cannot be lost, even if the system encounters hardware or software problems.
The next question is how do we avoid losing data once saved since hardware and software will fail. Well, let's try replicating the data.
Voila, replication 🫠.
Replication?
Of course, it means to clone the data. Have you ever seen Naruto?
I sometimes wish I could create shadow clones to help me complete all my tasks while I relax and listen to music. Just kidding! 😅
Replication means creating duplicate copies of data or services across multiple nodes, servers, or machines. This redundancy improves system reliability, availability, and performance by ensuring continuous access to resources despite failures or increased demand, thereby leading to durability.
There is a thin line between durability and replication as replicated data tend to be durable . Most people think of durability from a singular point of view I guess.
Durability concerning distributed systems involves having multiple copies of data over several nodes.
Versioning
To identify the latest data chunk we have on each server, should any one of the servers go down, versioning was introduced. Not only does this help identify the latest data but it helps to also reconcile data when conflict happens.
There are various ways to manage conflict but that is out of the scope of this article.
Anyway to the juicy part of the article, let's see some code snippets on how data can be replicated using version numbers. We will be using the version number, in this case, to track how the difference between the latest chunk and potentially new or stale chunk so we can decide whether or not the data is valid . This will tell us whether or not we can perform a replication by getting a snapshot of the latest data and storing on the server.
Let's assume the client sends a sequence of bytes to the server in chunks of 10MB each then, we represent the metadata information of each chunk like so:
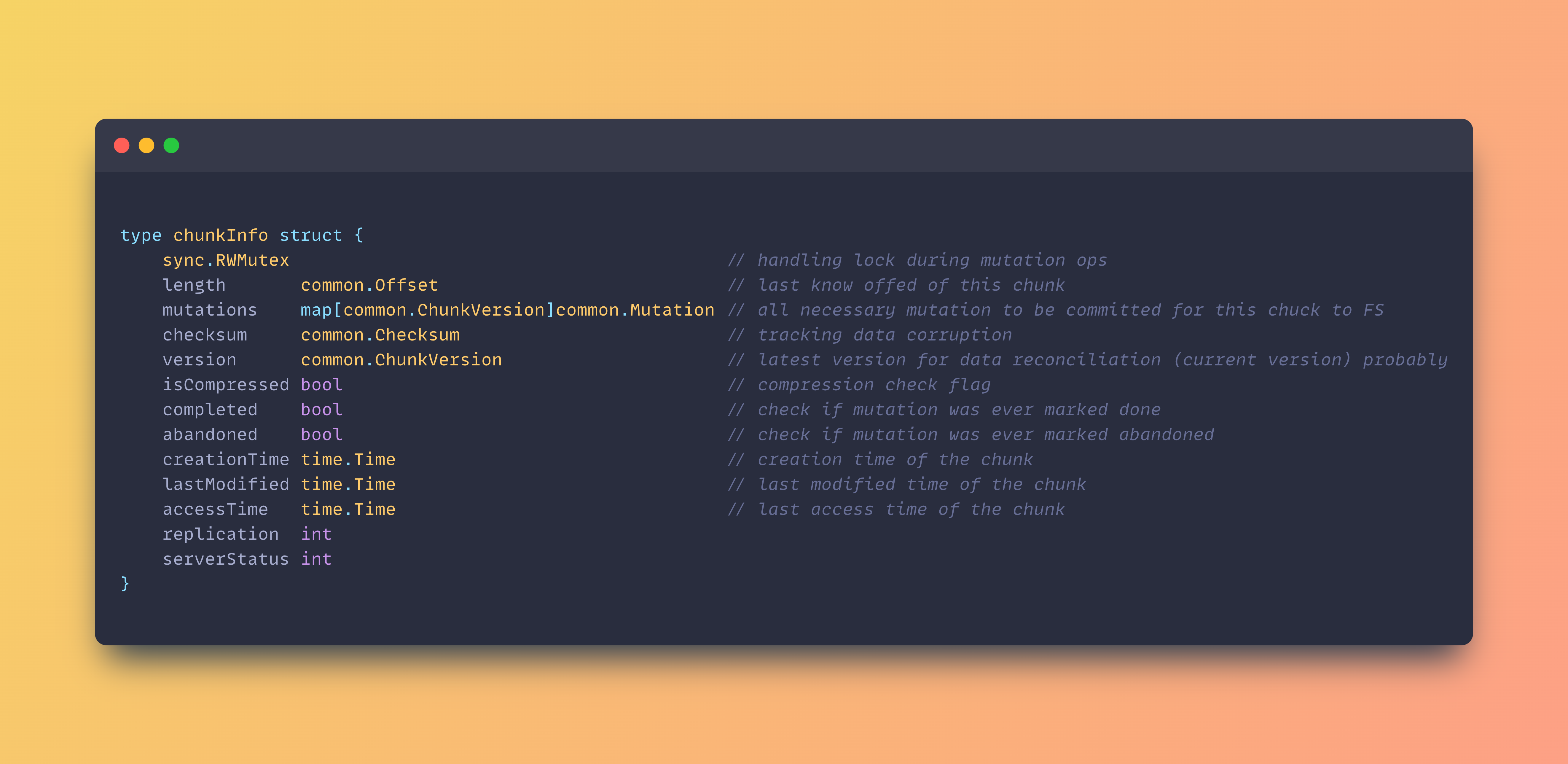
Before a write to the server begins, when the client starts sending chunks, the master server assigns a new chunk version number to the pending write operation. Depending on the architecture, the master server might be notified to replicate the data after a successful write, or the actual server might forward the data to other servers so they can also commit the data.
Remember that the chunk version is also forwarded to the other servers .
So why the version number?
Yes, we need the version number in case something goes wrong with one of our servers, like a failure or an environmental issue. If the server comes back online and synchronises with the master (the coordinator), the information on the server might be outdated. The master server needs to inform the rebooting server about which data to erase and which new version of the data to write.
Let's see a sample code of such a scenario
When any server goes down or reboots, it first contacts the master server to tell the master server of all the potentially doomed data it has. As shown below:
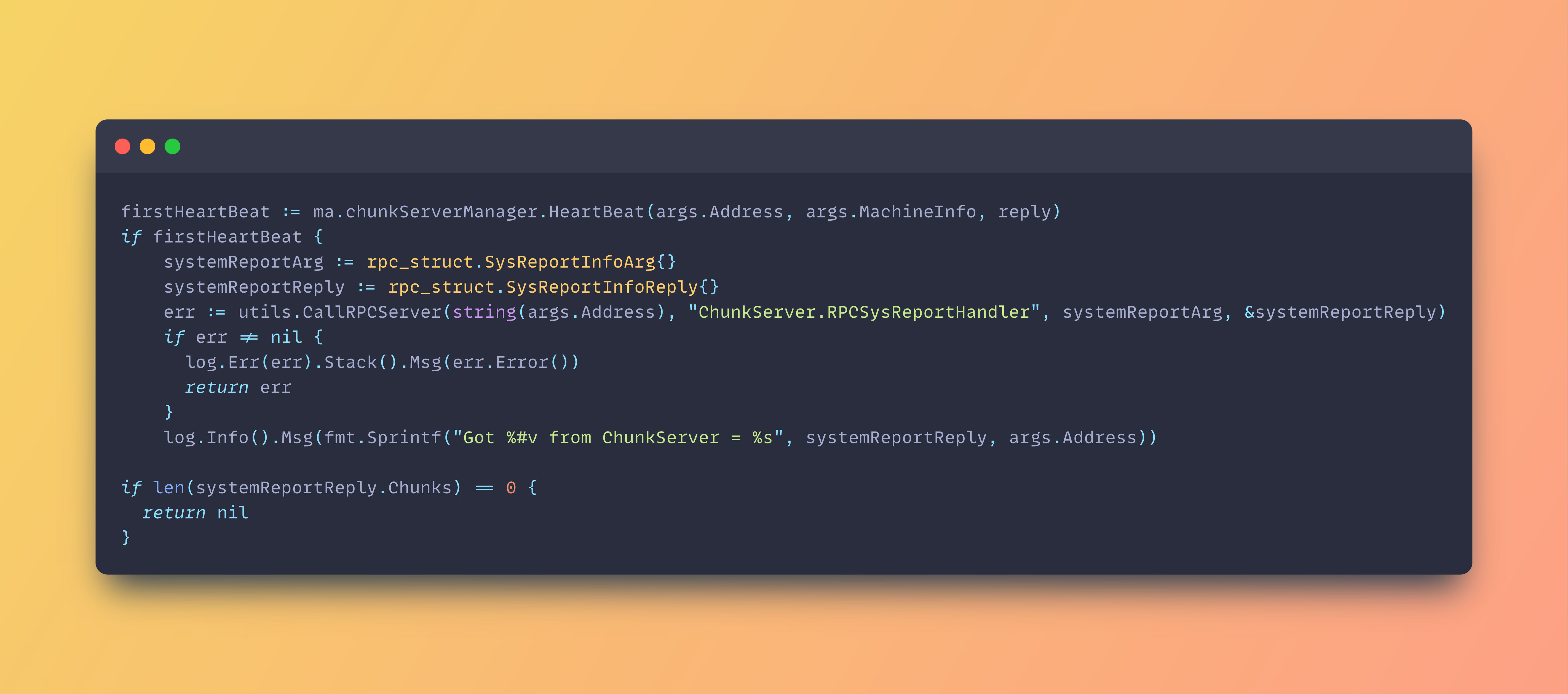
The master server acts like a teacher who checks the freshness of each assignment (chunks/data) given to the student (the server) using the version number present on both sides.
If the data is stale, the master server tells the server to remove the old data. Then, the master server replicates the latest snapshot of the data from another server to the one retrieving it.
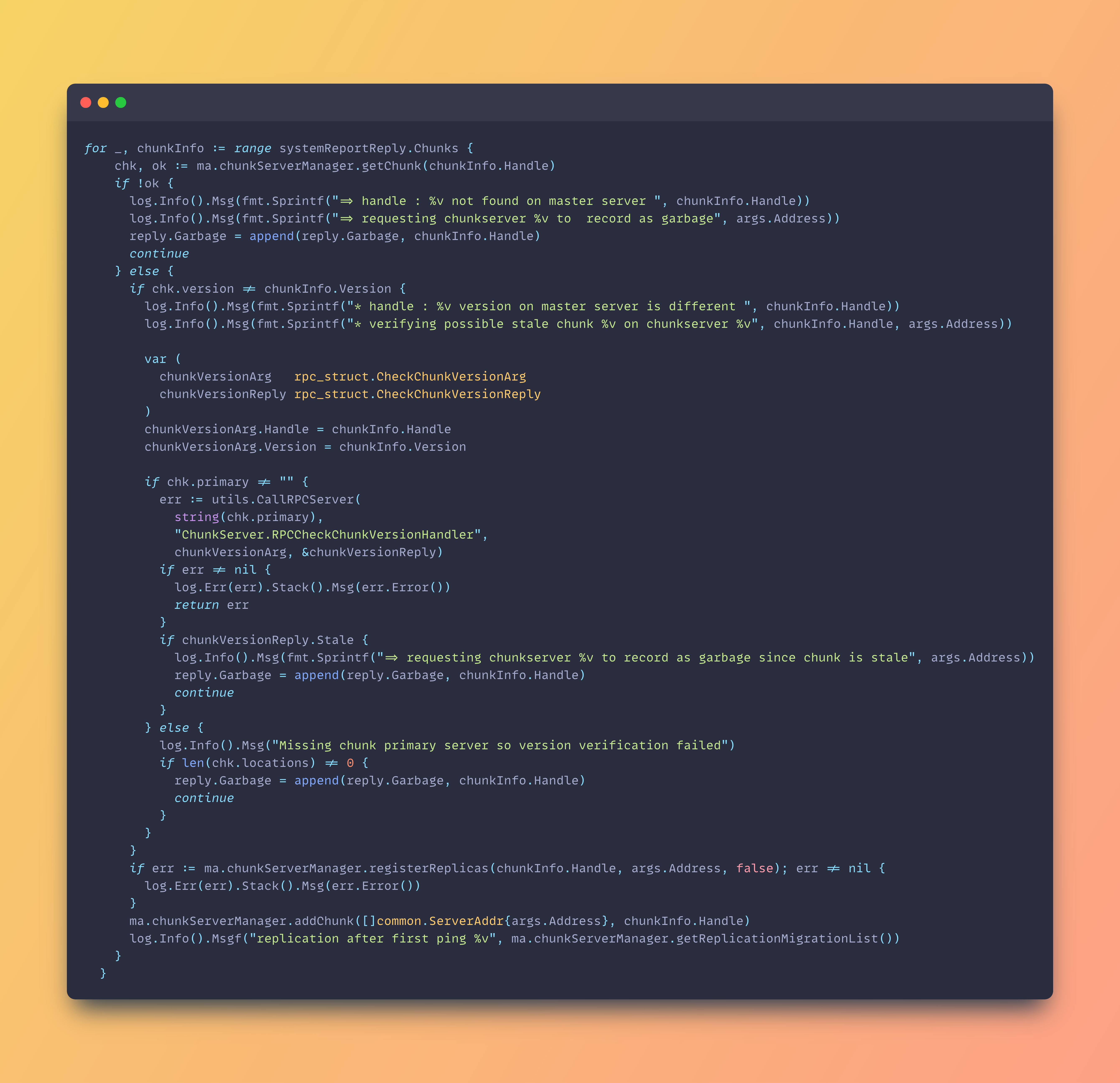
On the server's end, it reports back to the master on the staleness status of a specific data chunk as shown below
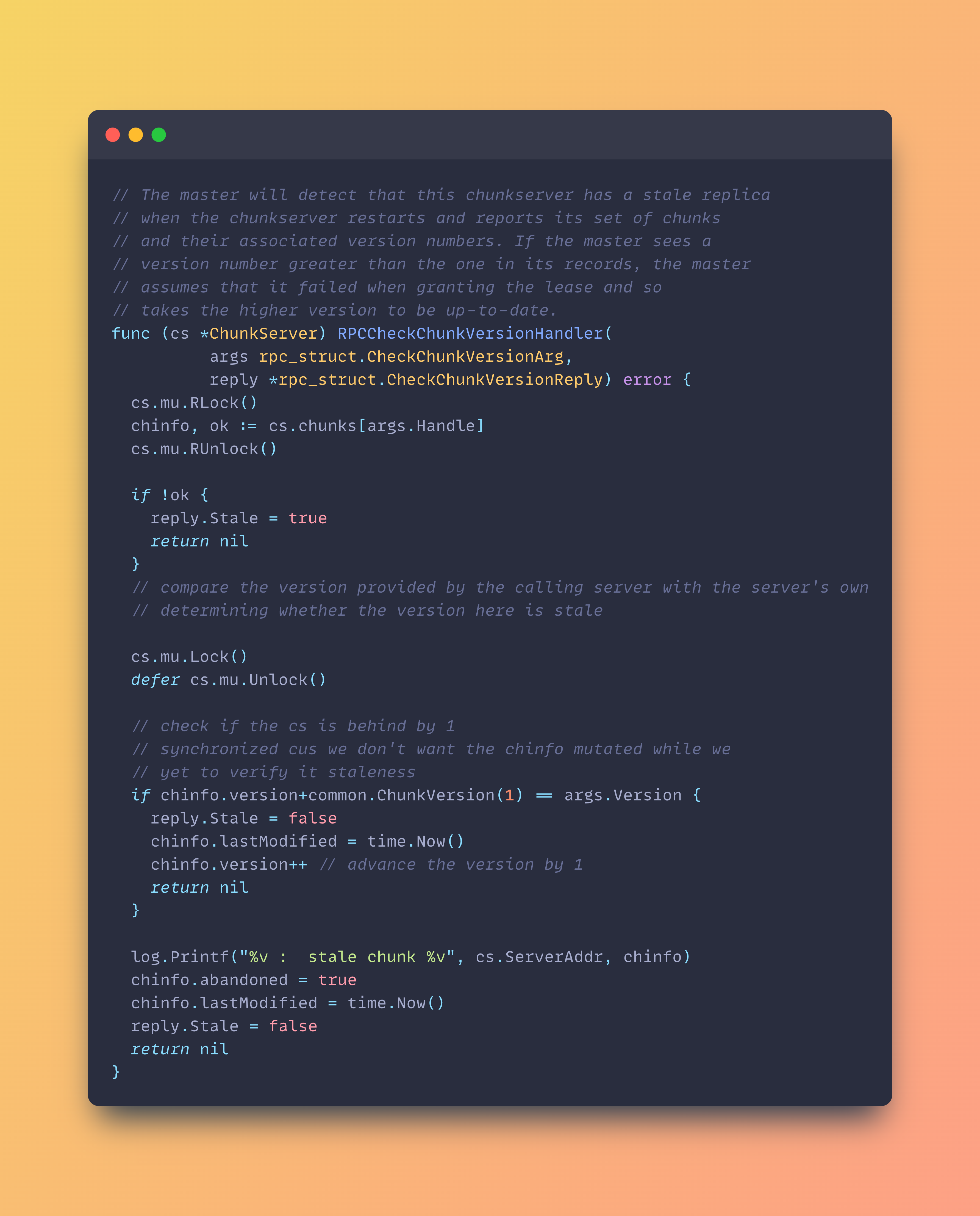
Although this looks a bit linear, there are quite a bit more asynchronous processes involved. By this, I mean the background process doing checks on the chunk meta information. There are various ways to do replication and this depends on the application in question. It could be synchronous or asynchronous.
After the above verification process, the master server can then go ahead and gather all the data that needs replication and push the data to the respective servers. A typical example is :
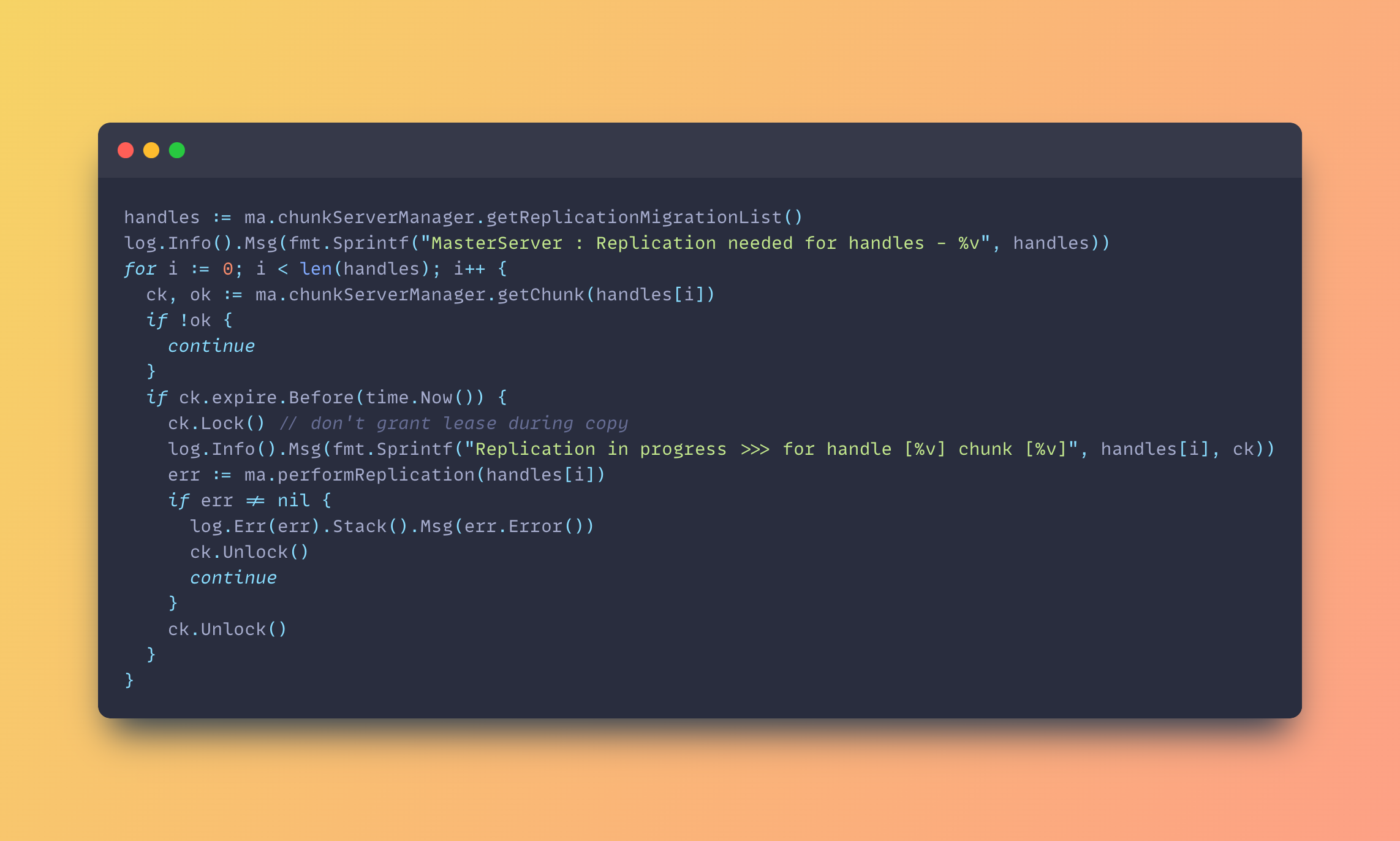
A key takeaway from these is that versioning helps to prevent staleness and also helps to resolve conflict depending on the use case.
Reading books and having practical implementation can go a long way in helping one develop technical depth.
I am Caleb and you can reach me on Linkedin or follow me on Twitter. @Soundboax
Subscribe to my newsletter
Read articles from Adewole Caleb Erioluwa directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Adewole Caleb Erioluwa
Adewole Caleb Erioluwa
I'm all about building scalable and robust applications, bringing over 5+ years of experience. As a Backend Software Engineer, I've driven efficiency improvements of up to 60%, thanks to my expertise in Go and JavaScript. In my current role at Cudium, as a Senior Software Engineer, I've integrated backend systems with third-party applications, boosting our understanding of user engagement by 85%. Beyond coding, I enjoy mentoring, documentation, and spearheading security features for a safer application. During my internship at Nomba, I honed skills in Node JS, MongoDB, and Java, improving data persistence for vendor services and reducing fraudulent transactions by over 60%. At Kudi.ai, I implemented transactional features, optimized legacy code, and crafted an account balance slack notification service, boosting stakeholder efficiency by 75%. At Airgateway, I was focused on enhancing support for agencies in their airline bookings. When not in the tech world, you'll find me strumming a guitar, hitting the dance floor, or belting out a tune. Let's connect over coffee and chat about tech, career journeys, or the latest music trends! I'm always looking to expand my network. Feel free to reach out at caleberioluwa@gmail.com