Apache Spark Architecture
 Shreyash Bante
Shreyash Bante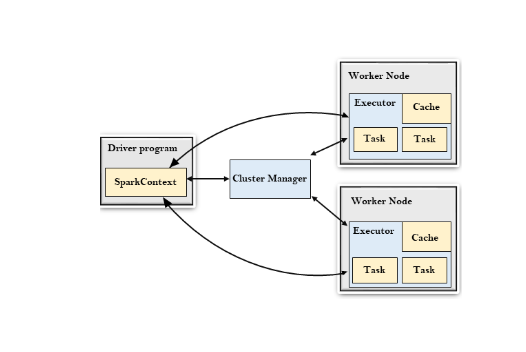
Apache Spark’s architecture is a cornerstone of its ability to efficiently process large-scale data. It is designed around the concept of distributed computing, which enables it to process massive datasets quickly and reliably across a cluster of computers. Below, we'll break down the key components and processes involved in Spark's architecture:
1. Spark Cluster Architecture
At a high level, a Spark cluster consists of the following main components:
Driver Program:
The Driver is the central coordinator of a Spark application. It is responsible for converting user code into tasks that can be executed by the cluster. The Driver program defines the main function, orchestrates the execution, and interacts with the cluster manager.
Key Responsibilities:
Job Execution: The Driver breaks down the Spark job into tasks and stages.
Task Scheduling: It sends tasks to be executed by the Executors.
Monitoring: The Driver monitors the execution and handles task failures.
Cluster Manager:
The Cluster Manager is responsible for managing the resources across the cluster. Spark can work with various cluster managers like Apache Hadoop YARN, Apache Mesos, or its own built-in cluster manager, Standalone.
Key Responsibilities:
Resource Allocation: The Cluster Manager allocates resources (CPU, memory) to different Spark applications running on the cluster.
Node Management: It tracks the status of nodes and ensures efficient utilization of resources.
Workers/Executors:
Executors are the worker nodes in the cluster responsible for executing tasks assigned by the Driver. Each Spark application has its own set of Executors.
Key Responsibilities:
Task Execution: Executors run the actual tasks on the data.
Data Storage: They store data in memory or disk for future operations, which is crucial for Spark's in-memory processing.
Reporting: Executors report the status of tasks back to the Driver.
2. Execution Flow in Spark
Here’s how a typical Spark job is executed:
Job Submission:
- The user submits a Spark application (job) to the Driver program. This application is usually written in one of the supported languages like Scala, Python, or Java.
Task Scheduling:
- The Driver program translates the application code into a Directed Acyclic Graph (DAG) of stages. Each stage is further divided into tasks, which are the basic units of work.
DAG Scheduler:
- The DAG Scheduler determines the optimal execution plan. It groups tasks into stages based on data shuffling dependencies. A stage corresponds to a series of transformations that can be computed without requiring data to be shuffled across the cluster.
Task Assignment:
- The Task Scheduler assigns tasks to Executors based on data locality, trying to minimize data transfer across the network.
Task Execution:
- Executors process the tasks in parallel, performing operations like map, filter, and reduce on the data.
Data Shuffling:
- When operations require data to be redistributed (e.g., groupByKey), Spark performs a shuffle. Data from different partitions is exchanged across the cluster to form new partitions.
Result Collection:
- After completing all stages, the final result is collected and sent back to the Driver program, where it can be stored, displayed, or further processed.
3. Spark Components In-Depth
Resilient Distributed Dataset (RDD):
Definition: RDDs are immutable, distributed collections of objects. They are fault-tolerant and can be rebuilt if a node fails, using lineage information.
Operations:
Transformations: Lazy operations that define a new RDD (e.g., map, filter).
Actions: Operations that trigger execution and return a result (e.g., count, collect).
Directed Acyclic Graph (DAG):
Definition: The DAG is a representation of the sequence of computations performed on the data. It is built from a series of transformations on RDDs.
Importance: The DAG Scheduler optimizes the execution by minimizing shuffles and maximizing parallelism.
In-Memory Processing:
Definition: Spark processes data in memory whenever possible, which significantly reduces disk I/O operations and speeds up the overall processing.
Benefits: This approach is particularly effective for iterative algorithms, which require multiple passes over the same data.
4. Spark Deployment Modes
Standalone Mode:
- Spark’s built-in cluster manager is used to allocate resources and manage jobs. This mode is simple to set up and is commonly used for small clusters.
YARN Mode:
- When deployed on Hadoop clusters, Spark can run alongside other Hadoop services, sharing resources managed by YARN.
Mesos Mode:
- Apache Mesos can be used as the cluster manager, allowing Spark to run alongside other applications like Kubernetes.
Kubernetes Mode:
- Spark can be deployed on Kubernetes clusters, which provides flexibility in containerized environments.
5. Fault Tolerance in Spark
RDD Lineage:
- If a partition of an RDD is lost, Spark can recompute it using the lineage information. This ensures that data processing is resilient to node failures.
Task Retries:
- If a task fails due to executor or node failure, Spark automatically retries the task on another executor.
Conclusion
Apache Spark's architecture is designed to make distributed data processing fast, scalable, and fault-tolerant. Its ability to perform in-memory processing, combined with the flexibility to work with various cluster managers and data sources, makes it an essential tool for big data applications. By understanding the architecture, you can better optimize your Spark jobs and take full advantage of its powerful features.
Subscribe to my newsletter
Read articles from Shreyash Bante directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shreyash Bante
Shreyash Bante
I am a Azure Data Engineer with expertise in PySpark, Scala, Python.