White Paper Summaries | Apache Flink
 Amr Elhewy
Amr Elhewy
Hello folks! In this summary we're going to be talking about Apache Flink. We're going to dive into what it is, what problems does it aim to solve and a few deep dives here and there. Let's start
Introduction
Apache Flink is an open-source system for processing streaming and batch data. Flink is built on the philosophy that many classes of data processing applications, including real-time analytics, continuous data pipelines, historic data processing (batch), and iterative algorithms (machine learning, graph analysis) can be expressed and executed as pipelined fault-tolerant dataflows.
There exists mainly two types of data processing;
Data stream processing(real time)
Batch processing(static)
Both have their use cases according to different business models. However recently there has been an increase in the processing of real time data whether it be logs, changes to the application state, readings, etc..
However most streams aren't being treated actually as streams, they're being processed in batches (static) where the batch could be over a specific time period for example. Data collection tools, workflow managers, and schedulers orchestrate the creation and processing of batches. However these approaches suffer from high latency (imposed by batches), high complexity (connecting and orchestrating several systems, and implementing business logic twice), as well as arbitrary inaccuracy, as the time dimension is not explicitly handled by the application code.
Apache Flink follows a paradigm that embraces data-stream processing as the unifying model for real-time analysis, continuous streams, and batch processing both in the programming model and in the execution engine. Flink supports different notions of time (event-time, ingestion-time, processing-time) in order to give programmers high flexibility in defining how events should be correlated.
Batch programs are special cases of streaming programs, where the stream is finite, and the order and time of records does not matter (all records implicitly belong to one all-encompassing win- dow). However, to support batch use cases with competitive ease and performance, Flink has a specialized API for processing static data sets, uses specialized data structures and algorithms for the batch versions of opera- tors like join or grouping, and uses dedicated scheduling strategies. The result is that Flink presents itself as a full-fledged and efficient batch processor on top of a streaming runtime
System Architecture
Now that we have a good overview on what Flink does, let's talk about its architecture
Flink consists of four main layers;
Deployment
Core
API
Libraries
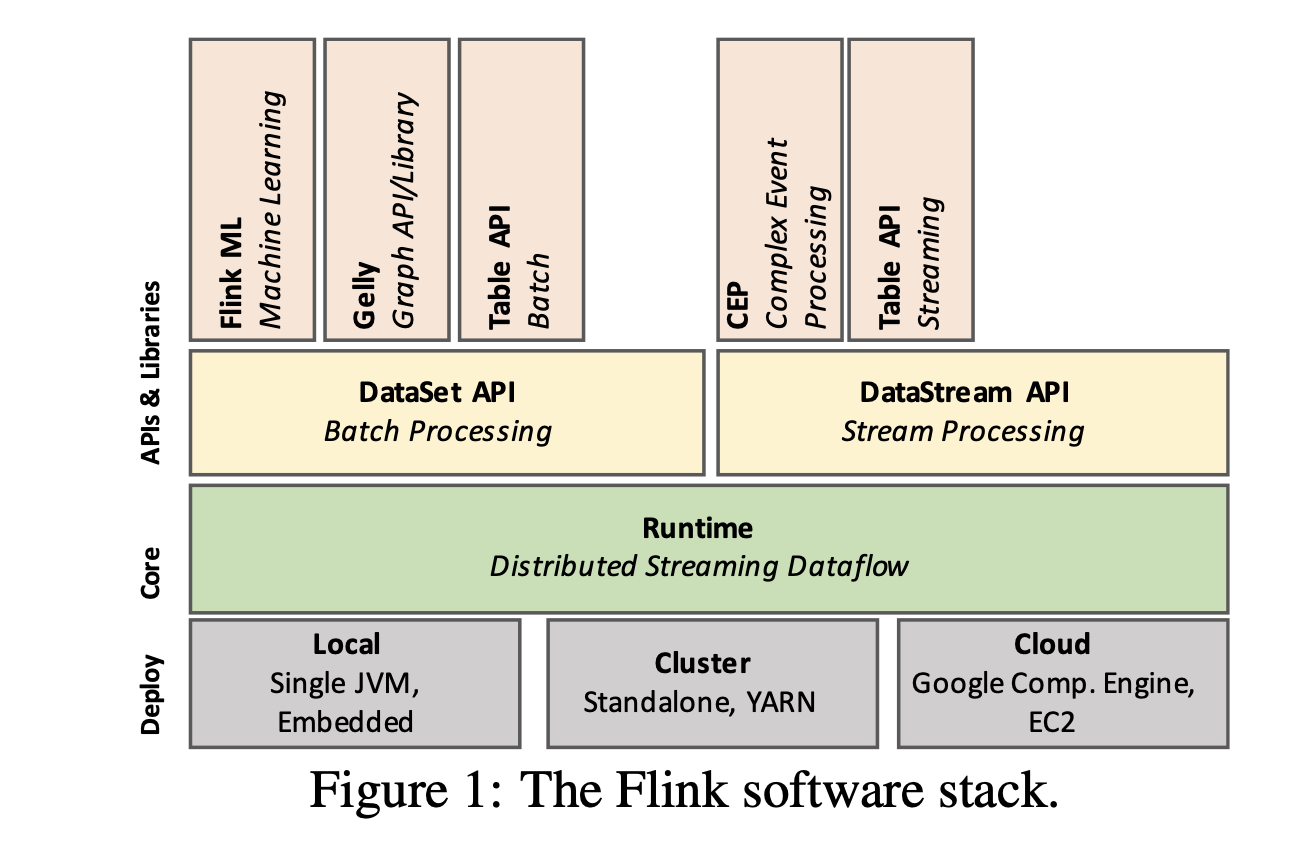
The core of Flink is the distributed dataflow engine, which executes dataflow programs.
A Flink runtime program is a DAG of stateful operators connected with data streams.
Directed Acyclic Graph (DAG):
The program is represented as a DAG, where each node is a computation (e.g., a function, a transformation) and each edge represents the flow of data between these nodes.
The edges indicate the direction of data flow, from data sources through transformations to outputs.
There are two core APIs in Flink:
The DataSet API for processing finite data sets (often referred to as batch processing)
The DataStream API for processing potentially unbounded data streams (often referred to as stream processing).
Flink’s core runtime engine can be seen as a streaming dataflow engine, and both the DataSet and DataStream APIs create runtime programs executable by the engine.
As such, it serves as the common fabric to abstract both bounded (batch) and unbounded (stream) processing.
Flink bundles domain-specific libraries and APIs that generate DataSet and DataStream API programs, currently, FlinkML for machine learning, Gelly for graph processing and Table for SQL-like operations.
Flink Cluster Architecture
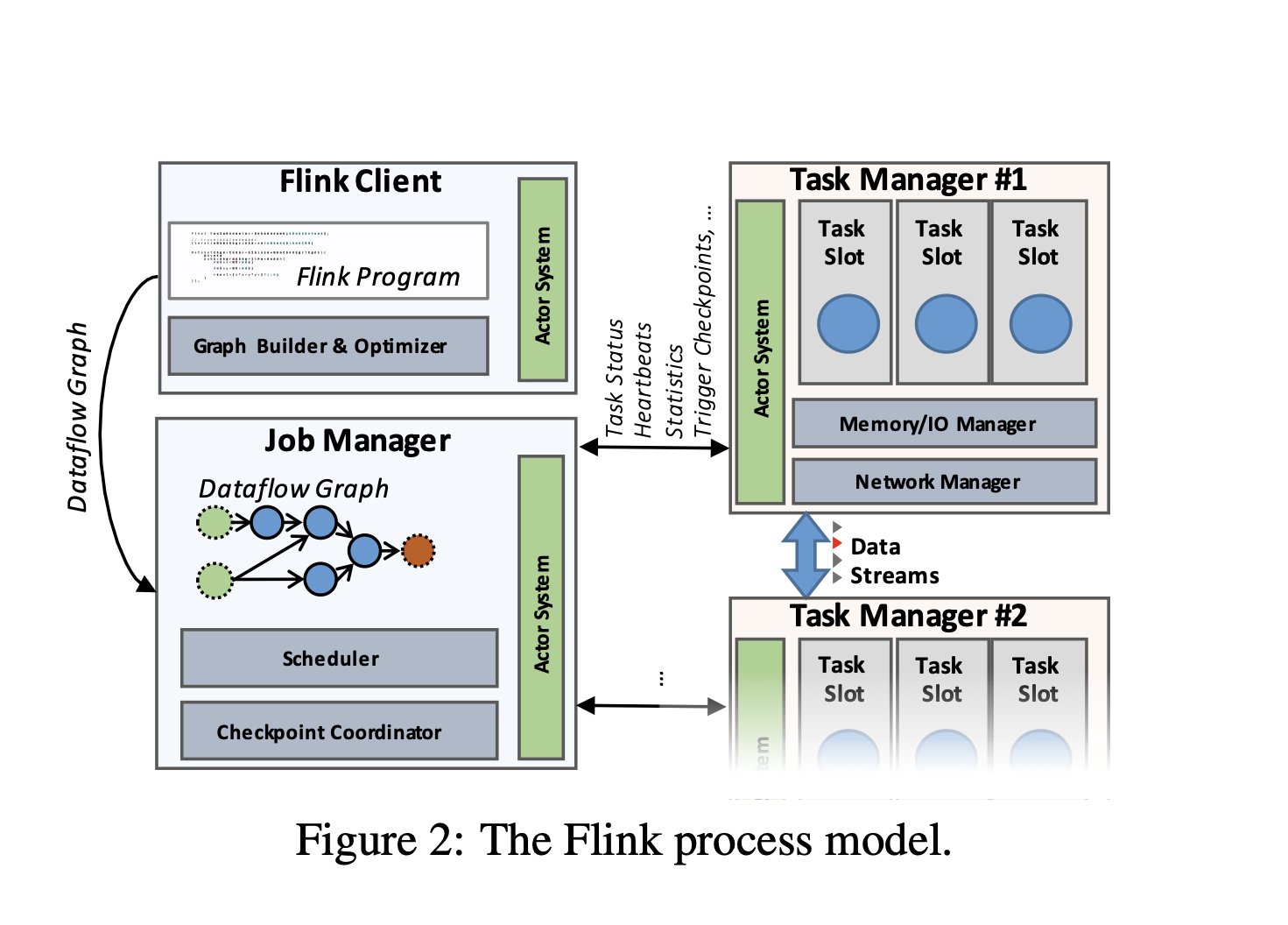
Flink cluster comprises three types of processes:
Client
Job Manager
At least one Task Manager
The client takes the program code, transforms it to a dataflow graph, and submits that to the JobManager. This transformation phase also examines the data types (schema) of the data exchanged between operators and creates serializers and other type/schema specific code.
DataSet programs (batch) additionally go through a cost-based query optimization phase, similar to the physical optimizations performed by relational query optimizers.
The JobManager coordinates the distributed execution of the dataflow, It tracks the state and progress of each operator and stream, schedules new operators, and coordinates checkpoints and recovery.
In a high-availability setup, the JobManager persists a minimal set of metadata at each checkpoint to a fault-tolerant storage, such that a standby JobManager can reconstruct the checkpoint and recover the dataflow execution from there.
The actual data processing takes place in the TaskManagers. A TaskManager executes one or more operators that produce streams, and reports on their status to the JobManager. The TaskManagers maintain the buffer pools to buffer or materialize the streams, and the network connections to exchange the data streams between operators.
An operator is a node in the DAG mentioned above, it's a processing step that the stream goes into.
Streaming Dataflows
Although users can write Flink programs using a multitude of APIs, all Flink programs eventually compile down to a common representation: the dataflow graph.
The dataflow graph is executed by Flink’s runtime engine, the common layer underneath both the batch processing (DataSet) and stream processing (DataStream) APIs.
Dataflow Graph
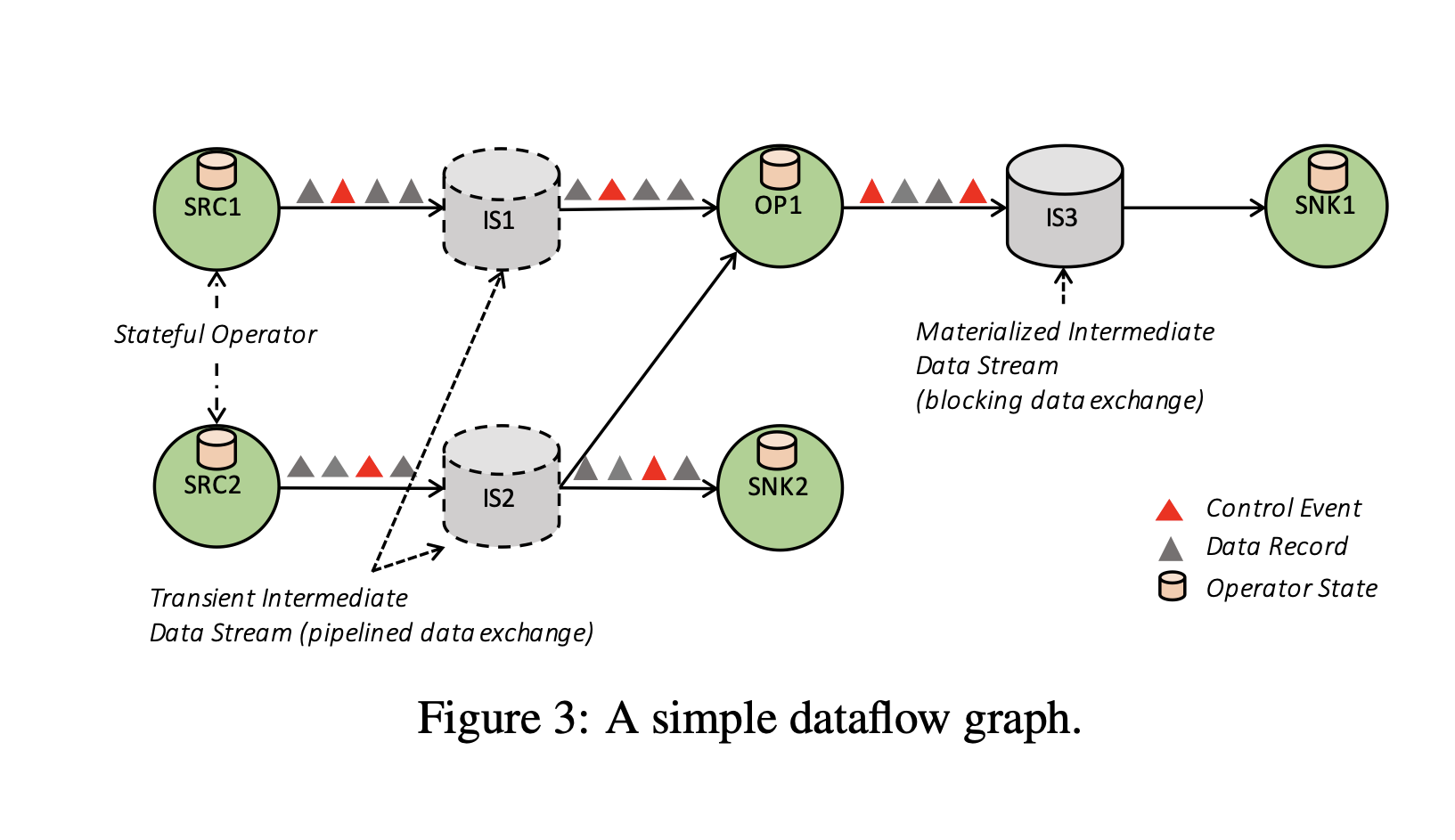
The dataflow graph as depicted in Figure 3 is a directed acyclic graph (DAG) that consists of the following:
Stateful Operators
Data streams that represent data produced by an operator and are available for consumption by operators.
Since dataflow graphs are executed in a data-parallel fashion, In a data-parallel execution model, the same operation is applied to different partitions of the dataset at the same time across multiple computing resources (e.g., CPUs, machines in a cluster).
Instead of processing one piece of data after another (sequential processing), the system processes many pieces of data in parallel.
Operators are parallelized into one or more parallel instances called subtasks, and streams are split into one or more stream partitions (one partition per producing subtask). The stateful operators, which may be stateless as a special case implement all of the processing logic (e.g., filters, hash joins and stream window functions).
Streams distribute data between producing and consuming operators in various patterns, such as point-to-point, broadcast, re-partition, fan-out, and merge.
So the main idea is to split the data between the producer and consumer, parallelizing it over the operators.
Data Exchange through Intermediate Data Streams
Flink’s intermediate data streams are the core abstraction for data-exchange between operators. An intermediate data stream represents a logical handle to the data that is produced by an operator and can be consumed by one or more operators.
Intermediate streams are logical in the sense that the data they point to may or may not be materialized on disk.
Pipelined Streams: These are used in Apache Flink to allow different parts of a dataflow (producers and consumers) to run at the same time. Data is sent from one operator to the next without waiting for the entire dataset to be processed first. This allows for faster, real-time processing.
If a downstream operator (consumer) is slow, it can slow down the upstream operator (producer), creating "backpressure." Flink manages short-term fluctuations in data flow using buffers.
Blocking Streams: These are used when you need to fully process and store data from one operator before moving on to the next.
The producing operator finishes its work and stores all its output before the consuming operator starts processing. This separates the two operators into distinct stages.
Since all data is stored before being passed on, blocking streams use more memory and may write data to disk if needed.
There’s no backpressure since the next stage only starts after the current stage is fully complete.
Blocking streams are useful when you need to isolate operators (like in complex operations such as sorting) to prevent issues like distributed deadlocks in the system.
When Flink processes data, it splits data into chunks called buffers before sending them from one operator (producer) to another (consumer).
A buffer can be sent as soon as it’s full, or
It can be sent after a certain amount of time, even if it’s not full. (timeout)
Here comes the tradeoff between latency and throughput;
Latency: How quickly data is processed and moved through the system.
Throughput: How much data the system can handle in a given time period.
Low Latency: To achieve low latency (faster response times), Flink sends buffers more quickly, even if they’re not full. This means data moves through the system faster, but the throughput (amount of data processed) might be lower. (or even small buffers)
High Throughput: To achieve higher throughput (processing more data), Flink waits until buffers are full before sending them. This increases the amount of data processed at once but can slow down the response time, leading to higher latency. (larger buffers also)
Flink allows you to balance between how fast data is processed (latency) and how much data is processed at once (throughput) by adjusting how buffers are handled. Shorter timeouts mean faster data movement but lower throughput, while longer timeouts mean higher throughput but slower data movement.
Apart from exchanging data, streams in Flink communicate different types of control events. These are special events injected in the data stream by operators, and are delivered in-order along with all other data records and events within a stream partition. The receiving operators react to these events by performing certain actions upon their arrival. Examples are;
Checkpoint Barriers; used to create a snapshot of the data processing at a specific point in time.
Watermarks; markers in the data stream that show how far along the system is in processing time-based events.
Iteration Barriers; used in specialized algorithms that require multiple passes over the data (iterative algorithms).
Streaming dataflows in Flink do not provide ordering guarantees after any form of repartitioning or broadcasting and the responsibility of dealing with out-of-order records is left to the operator implementation.
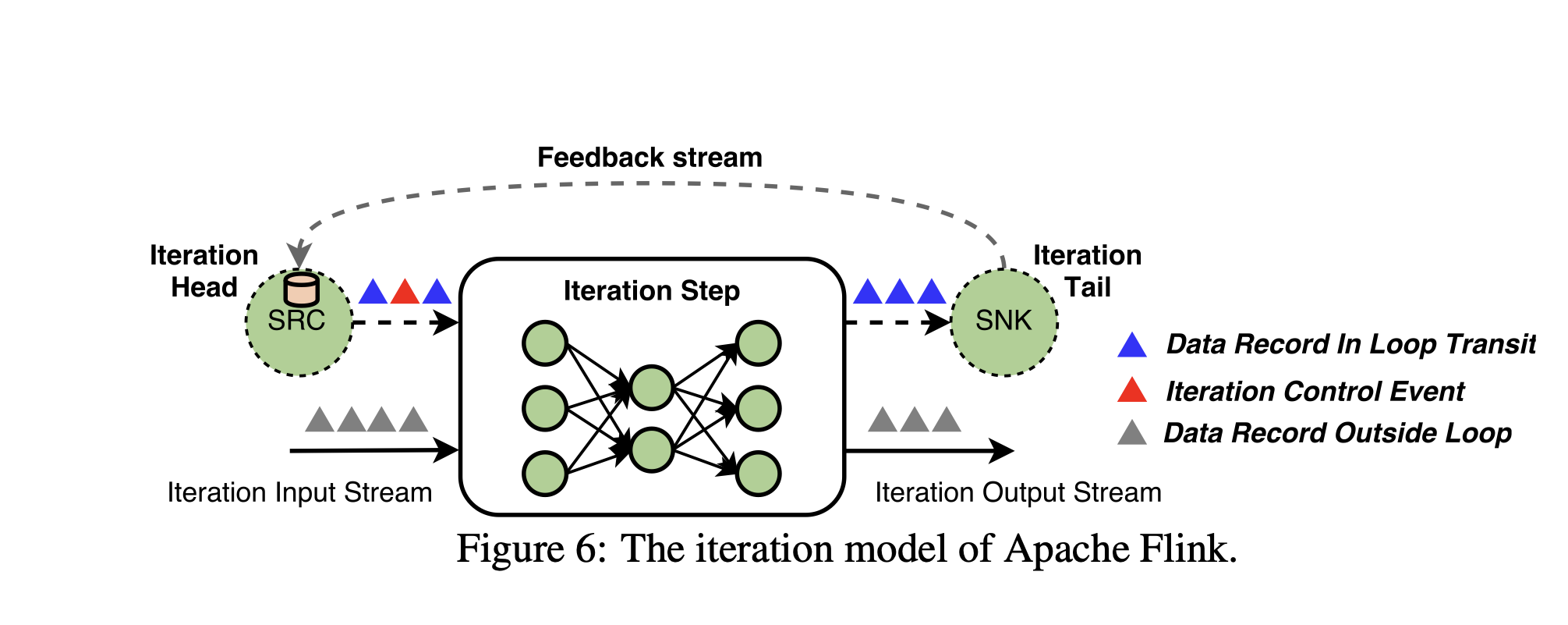
Iterative Dataflow
Iterations are important for tasks like graph processing and machine learning, where you often need to repeatedly process data to refine results. In some systems(traditional approaches), you either submit a new job for each iteration or add more nodes to the processing graph.
In Flink, iterations are managed by special operators called iteration steps. These steps allow the processing of data to repeat in a controlled manner.
Flink’s iteration steps use feedback edges to create loops in the data processing pipeline. This enables data to flow back into the iteration step, allowing for iterative processing.
Flink uses head and tail tasks (thought as operators) to manage the flow of data through the iteration steps. These tasks handle the data records that are fed back into the iteration, ensuring that the processing is coordinated.
Fault Tolerance
Flink offers reliable execution with strict exactly-once-processing consistency guarantees and deals with failures via checkpointing and partial re-execution.
The general assumption the system makes to effectively provide these guarantees is that the data sources are persistent and replayable.
Examples of such sources are files and durable message queues (e.g., Apache Kafka).
As mentioned before, Flink uses a system called checkpointing to make sure that, even if something goes wrong, your data processing continues exactly where it left off without losing or duplicating data.
Data streams can be huge and never-ending, so if you had to start over after a failure, it could take months to catch up. That would be impractical.
To avoid this, Flink regularly saves snapshots of the current state of the data processing, including the exact position in the data stream. If something fails, Flink can quickly recover using these snapshots, so it doesn’t have to reprocess everything from the beginning.
The core challenge they faced when saving snapshots is that when dealing with data processing, you need to ensure that all parallel operators (processing units) take a snapshot of their state at the same logical time. This means capturing a consistent view of the entire data processing system without stopping it.
So they introduced something called Asynchronous Barrier Snapshotting (ABS)
Special markers (called barriers) are inserted into the data streams. These barriers represent a specific point in time.
When a barrier reaches an operator, it marks that operator’s state as part of the current snapshot. Data before the barrier is included in the snapshot, and data after the barrier is not.
This process allows Flink to take snapshots without stopping the entire data processing system, thus keeping the system running smoothly.
Each partition of a stream operates independently and will have its own barriers. When a barrier is inserted into the stream, it travels through each partition separately.
The barriers represent the same logical time across all partitions, but they may not arrive simultaneously at every partition due to differences in processing speed and network delays.
How it exactly works in depth
Alignment phase: Each operator in the data pipeline receives barriers from upstream operators. Before taking a snapshot, the operator makes sure that it has received all barriers from all of its input streams. This ensures that the snapshot reflects a consistent point in time across all inputs.
State Saving: After confirming all barriers are received, the operator saves its current state (e.g., contents of windows or custom data structures) to durable storage, such as HDFS or another storage system.
Barrier Forwarding: Once the state is safely backed up, the operator forwards the barrier to the next operators downstream. This continues until all operators have taken their snapshots and forwarded the barriers.
Complete Snapshot: The snapshot process is complete when all operators have registered their states and forwarded the barriers. The snapshot captures all operator states as they were when the barriers passed through, ensuring a consistent global snapshot.
Recovery Process:
Restoring State:
From Snapshots: When a failure occurs, Flink restores all operator states from the last successful snapshot.
Restarting Streams: Input streams are restarted from the point of the latest barrier that has a snapshot. This limits the amount of data that needs to be reprocessed to just the records between the last two barriers.
Benefits of ABS:
It guarantees exactly-once state updates without ever pausing the computation
The checkpointing mechanism is independent of other control messages in the system, like events triggering window computations. This means it doesn’t interfere with other data processing features.
ABS is not tied to any specific storage system. The state can be backed up to various storage systems depending on the environment, like file systems or databases.
Stream Analytics on Top of Dataflows
Flink’s DataStream API is designed for stream processing, handling complex tasks like time management, windowing, and state maintenance. It builds on Flink’s runtime, which already supports efficient data transfers, stateful operations, and fault tolerance. The API allows users to define how data is grouped and processed over time, while the underlying runtime manages these operations efficiently and reliably.
The Notion of Time
Flink distinguishes between two notions of time;
Event time; which denotes the time when an event originates (e.g., the timestamp associated with a signal arising from a sensor, such as a mobile device)
Processing-time, which is the wall-clock time of the machine that is processing the data.
There can be differences (skew) between event-time and processing-time, leading to potential delays when processing events based on their actual event-time.
Hence they introduce Watermarks;
Watermarks are special events used to track the progress of time within a stream processing system. They help the system understand which events have been processed and which are still pending.
A watermark includes a time attribute t, indicating that all events with a timestamp lower than t have been processed.
Watermarks originate from the sources of the data stream and travel through the entire processing topology. As they move, they help maintain a consistent view of time across different operators.
Operators like map or filter just forward the watermarks they receive. Operators that perform calculations based on watermarks (e.g., event-time windows) compute results triggered by the watermark and then forward it. For multiple inputs, the operator forwards the minimum of the incoming watermarks to ensure accurate results.
Flink programs that are based on processing-time rely on local machine clocks, and hence possess a less reliable notion of time, which can lead to inconsistent replays upon recovery. However, they exhibit lower latency. Programs that are based on event-time provide the most reliable semantics, but may exhibit latency due to event-time-processing-time lag. Flink includes a third notion of time as a special case of event-time called ingestion-time, which is the time that events enter Flink. That achieves a lower processing latency than event-time and leads to more accurate results in comparison to processing-time.
Stateful Stream Processing
State is critical to many applications, such as machine-learning model building, graph analysis, user session handling, and window aggregations. There is a plethora of different types of states depending on the use case. For example, the state can be something as simple as a counter or a sum or more complex, such as a classification tree or a large sparse matrix often used in machine-learning applications. Stream windows are stateful operators that assign records to continuously updated buckets kept in memory as part of the operator state.
State Management in Flink
Explicit State Handling:
State Registration: Flink allows users to explicitly manage state within their applications. This means users can define and work with state in a clear and controlled way.
Operator Interfaces/Annotations: Flink provides interfaces or annotations that enable you to register local variables within an operator's scope. This ensures that the state you define is closely associated with the specific operator that needs it.
Operator-State Abstraction:
Key-Value States: Flink offers a high-level abstraction for state management. You can declare state as partitioned key-value pairs, which allows for efficient and flexible management of state within streaming applications.
Associated Operations: Along with declaring state, Flink provides operations to interact with this state, such as reading, updating, and deleting state entries.
State Backend Configurations:
StateBackend Abstractions: Users can configure how state is stored and managed using StateBackend abstractions. This includes specifying the storage mechanism (e.g., file system, database) and how the state is checkpointed.
Custom State Management: This flexibility allows for custom state management solutions tailored to specific application needs and performance requirements.
Checkpointing and Durability:
- Exactly-Once Semantics: Flink’s checkpointing mechanism ensures that any registered state is durable and maintained with exactly-once update semantics. This means that state changes are reliably recorded and can be accurately recovered in case of failures.
Stream Windows
Incremental computations over unbounded streams are often evaluated over continuously evolving logical views, called windows. Apache Flink incorporates windowing within a stateful operator that is configured via a flexible declaration composed out of three core functions:
Window assigner
Trigger (optional)
Evictor.
Window assigner:
assigns each record to one or more logical windows.
Examples:
Time Windows: Based on timestamps (e.g., 6-second windows).
Count Windows: Based on the number of records (e.g., 1000 records).
Sliding Windows: Overlapping windows that can cover multiple periods or counts (e.g., a window every 2 seconds).
- Trigger:
Determines when the operation associated with the window is performed.
Examples:
Event Time Trigger: The operation happens when a watermark passes the end of the window.
Count Trigger: The operation happens after a certain number of records (e.g., every 1000 records).
Evictor:
Decides which records to keep within each window.
Examples:
- Count Evictor: Keeps a fixed number of the most recent records (e.g., the last 100 records).
Batch Analytics on Top of Dataflows
Streaming and Batch Processing: Flink uses the same runtime engine for both streaming and batch computations. This means that both types of workloads benefit from the same execution infrastructure.
Handling Batch Computations:
Blocking Data Streams: For batch processing, large computations can be broken into isolated stages using blocked data streams. These stages are executed sequentially, which allows for efficient processing and scheduling.
Turning Off Periodic Snapshotting: When the overhead of periodic snapshotting (used for fault tolerance) is high, it is turned off. Instead, fault recovery is managed by replaying lost data from the most recent materialized intermediate stream, which could be from the source.
Blocking Operators:
Definition: Blocking operators (like sorts) are those that wait until they have consumed their entire input before proceeding. The runtime does not differentiate between blocking and non-blocking operators.
Memory Management: These operators use managed memory, which can be on or off the JVM heap. If their memory usage exceeds available memory, they can spill data to disk.
DataSet API:
Batch Abstractions: The DataSet API provides abstractions specifically for batch processing. It includes a bounded DataSet structure and transformations like joins, aggregations, and iterations.
Fault-Tolerance: DataSets are designed to be fault-tolerant, ensuring reliable processing of batch data.
Query Optimization:
Optimization Layer: Flink includes a query optimization layer that transforms DataSet programs into efficient executable plans. This optimization helps improve performance and resource utilization.
Flink uses advanced techniques to optimize query execution, considering network, disk, and CPU costs, and incorporates user hints for better accuracy.
Memory Management: Flink improves memory efficiency by serializing data into segments, processing data in binary form, and minimizing garbage collection.
Batch Iterations: Flink supports various iteration models and optimizes iterative processes with techniques like delta iterations for efficient computation.
This approach enables Flink to effectively manage and optimize both streaming and batch processing tasks, leveraging a unified runtime and specialized APIs for different types of workloads.
Summary
In this article, we dove deep into Apache Flink, exploring its core functionalities and advanced techniques. Key topics covered include:
Unified Data Processing: We examined how Flink’s runtime supports both streaming and batch processing, allowing seamless handling of continuous and bounded data.
Fault Tolerance: We detailed Flink’s checkpointing mechanism, which ensures exactly-once processing guarantees by capturing consistent snapshots of operator states and stream positions.
State Management: We explored Flink’s approach to explicit state handling, including state abstractions and custom configurations for flexible state storage and checkpointing.
Windowing: We discussed Flink’s robust windowing system, which supports a variety of time-based and count-based windows, and handles out-of-order events.
Batch Processing Optimization: We covered how Flink adapts its runtime for batch processing with techniques like blocking operators and efficient data management.
Query Optimization: We looked into Flink’s advanced query optimization strategies, including cost-based planning and handling of complex UDF-heavy DAGs.
Memory Management: We analyzed Flink’s memory management practices, including serialized data handling and off-heap memory usage to reduce garbage collection overhead.
Overall, the article provided an in-depth look at how Flink handles data processing, fault tolerance, state management, and optimizations for both streaming and batch scenarios. Hope you guys enjoyed and till the next one!
References
Subscribe to my newsletter
Read articles from Amr Elhewy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by