Building SmartDoc with RAG and Qdrant
 Oduor Jacob Muganda
Oduor Jacob Muganda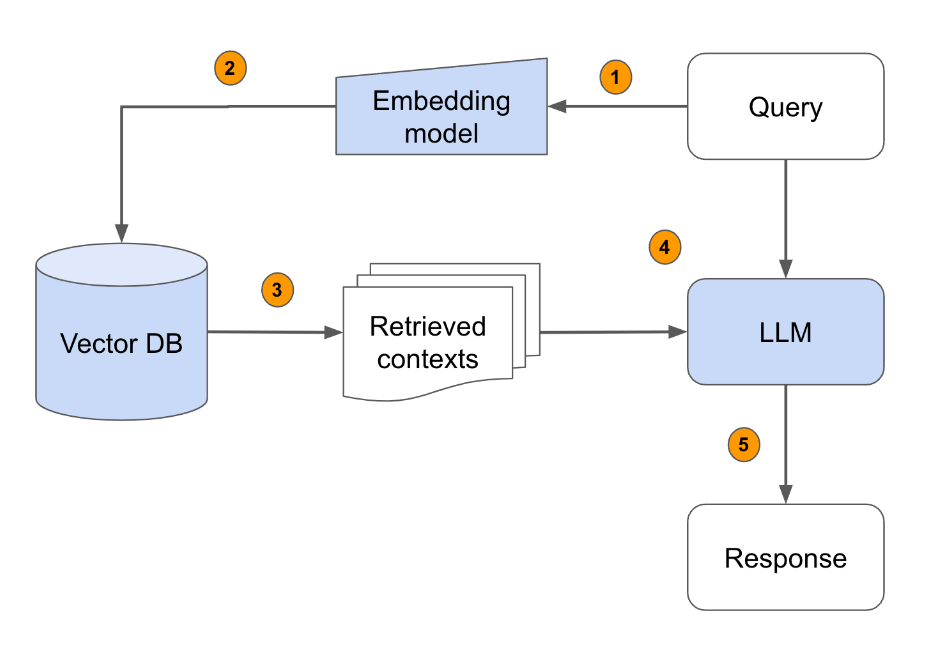
SmartDoc is an advanced document search engine leveraging Retrieval-Augmented Generation (RAG) and the Qdrant vector database. This guide covers setting up the environment, backend development, frontend development, and testing.
Combining RAG and Vector Databases
When used together, RAG and vector databases complement each other to enhance search and information retrieval tasks:
Vector Storage and Retrieval: The vector database stores vector embeddings of documents. When a query is made, the database performs a similarity search to retrieve the most relevant documents based on their vector representations.
Contextual Generation: Once relevant documents are retrieved, the RAG model uses these documents to generate a response. This ensures that the response is not only based on the retrieved documents but is also tailored to the query context.
Prerequisites
Before starting, ensure you have:
Python (preferably 3.8+)
Node.js and npm
Docker for running Qdrant
Step 1: Setting Up the Environment
Create and Activate a Python Virtual Environment
python -m venv env source env/bin/activate # On Windows use `env\Scripts\activate`Install Backend Dependencies
Install the required Python packages:
pip install fastapi uvicorn haystack qdrant-client sentence-transformersCreate a React App
Create a new React application for the frontend:
npx create-react-app document-search cd document-search
Step 2: Backend Development
Create the FastAPI Application
Create a file named
main.pyin your project directory. This will handle the backend API:from fastapi import FastAPI, HTTPException from pydantic import BaseModel from sentence_transformers import SentenceTransformer from haystack.pipelines import GenerativeQAPipeline from haystack.nodes import DenseRetriever, FARMReader from qdrant_client import QdrantClient from qdrant_client.http.models import PointStruct app = FastAPI() # Initialize Qdrant client qdrant_client = QdrantClient(url='http://localhost:6333') # Load Sentence Transformer model model = SentenceTransformer('all-MiniLM-L6-v2') # Define Haystack components retriever = DenseRetriever(document_store=qdrant_client) reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2") pipe = GenerativeQAPipeline(reader=reader, retriever=retriever) class QueryModel(BaseModel): query: str @app.post("/search/") async def search(query_model: QueryModel): query = query_model.query # Perform search using RAG pipeline result = pipe.run(query=query, params={"Retriever": {"top_k": 5}, "Reader": {"top_k": 1}}) return {"results": result} if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8000)Explanation:
FastAPI: Framework for creating the backend API.
SentenceTransformer: Model to convert text into vectors.
DenseRetriever and FARMReader: Components of Haystack used for retrieval and reading.
GenerativeQAPipeline: Combines retrieval and generation for enhanced responses.
Vectorize and Store Documents
Create a script named
index_documents.py:from sentence_transformers import SentenceTransformer from qdrant_client import QdrantClient model = SentenceTransformer('all-MiniLM-L6-v2') qdrant_client = QdrantClient(url='http://localhost:6333') def vectorize_document(text: str): return model.encode(text).tolist() def store_document(doc_id: str, text: str): vector = vectorize_document(text) qdrant_client.upsert(collection_name='documents', points=[{ 'id': doc_id, 'vector': vector, 'payload': {'text': text} }]) # Example usage store_document("1", "Example document text to index.")Explanation:
vectorize_document: Converts text to a vector representation.
store_document: Stores the vectorized document in Qdrant.
Step 3: Frontend Development
Create the Search Interface
Update
src/App.js:import React, { useState } from 'react'; function App() { const [query, setQuery] = useState(''); const [results, setResults] = useState([]); const handleSearch = async () => { const response = await fetch('http://localhost:8000/search/', { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify({ query }), }); const data = await response.json(); setResults(data.results); }; return ( <div> <h1>SmartDoc: AI-Powered Contextual Document Search</h1> <input type="text" value={query} onChange={(e) => setQuery(e.target.value)} placeholder="Enter your query" /> <button onClick={handleSearch}>Search</button> <div> <h2>Results</h2> <pre>{JSON.stringify(results, null, 2)}</pre> </div> </div> ); } export default App;Explanation:
handleSearch: Sends a POST request to the FastAPI backend with the user query.
Results Display: Shows the search results returned from the backend.
Run the React App
npm startExplanation:
- npm start: Launches the React development server.
Step 4: Running and Testing
Start Qdrant
Use Docker to run Qdrant:
docker run -p 6333:6333 qdrant/qdrantExplanation:
- docker run: Runs Qdrant as a Docker container, exposing it on port 6333.
Run the FastAPI Server
uvicorn main:app --reloadExplanation:
- uvicorn: Runs the FastAPI server with auto-reload enabled.
Start the React Frontend
npm startExplanation:
- npm start: Launches the React application.
Test Your Application
Open your browser and go to
http://localhost:3000. Enter a query and test the functionality.
Conclusion
You’ve now built SmartDoc, an advanced document search engine utilizing RAG and Qdrant. This application demonstrates how modern AI techniques can be used to enhance document retrieval. Here’s a summary of what you’ve accomplished:
Backend: Implemented using FastAPI, integrating RAG for contextual document retrieval.
Vector Storage: Managed with Qdrant, which stores and retrieves vectorized document data.
Frontend: Created with React to provide an intuitive user interface.
Happy coding! If you need further assistance, don’t hesitate to ask!
Subscribe to my newsletter
Read articles from Oduor Jacob Muganda directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Oduor Jacob Muganda
Oduor Jacob Muganda
👨💻 Experienced Software Developer & AI Engineer 👨🔬 Passionate about leveraging cutting-edge technology to solve complex problems and drive innovation. I specialize in building robust software solutions and extracting actionable insights from data. Thereby automating the software applications to make the autonomous. 🖥️ As a Software Developer: Proficient in multiple programming languages including Python, JavaScript, Java, and C++. Skilled in full-stack web development, with expertise in frontend (HTML/CSS/JavaScript) and backend (Node.js, Django, Flask). Experienced in developing scalable web applications, e-commerce platforms, and social media platforms. 📊 As a Machine Learning Engineer: Expertise in data analysis, machine learning, and predictive modeling using Python libraries such as NumPy, Pandas, Scikit-learn, TensorFlow, and PyTorch. Skilled in data visualization and storytelling with tools like Matplotlib, Seaborn, and Plotly. Proficient in handling big data with technologies like Apache Spark and Hadoop. 🚀 I thrive on tackling challenging problems and transforming data into actionable insights that drive business growth and innovation. Whether it's developing a user-friendly web application or building predictive models to optimize business processes, I'm dedicated to delivering impactful solutions that exceed expectations. Let's connect and collaborate on exciting projects that push the boundaries of technology and AI engineering! 🌟