Building a Weather Dashboard: A Data Engineer’s Journey from Lagos to Ibadan
 Freda Victor
Freda Victor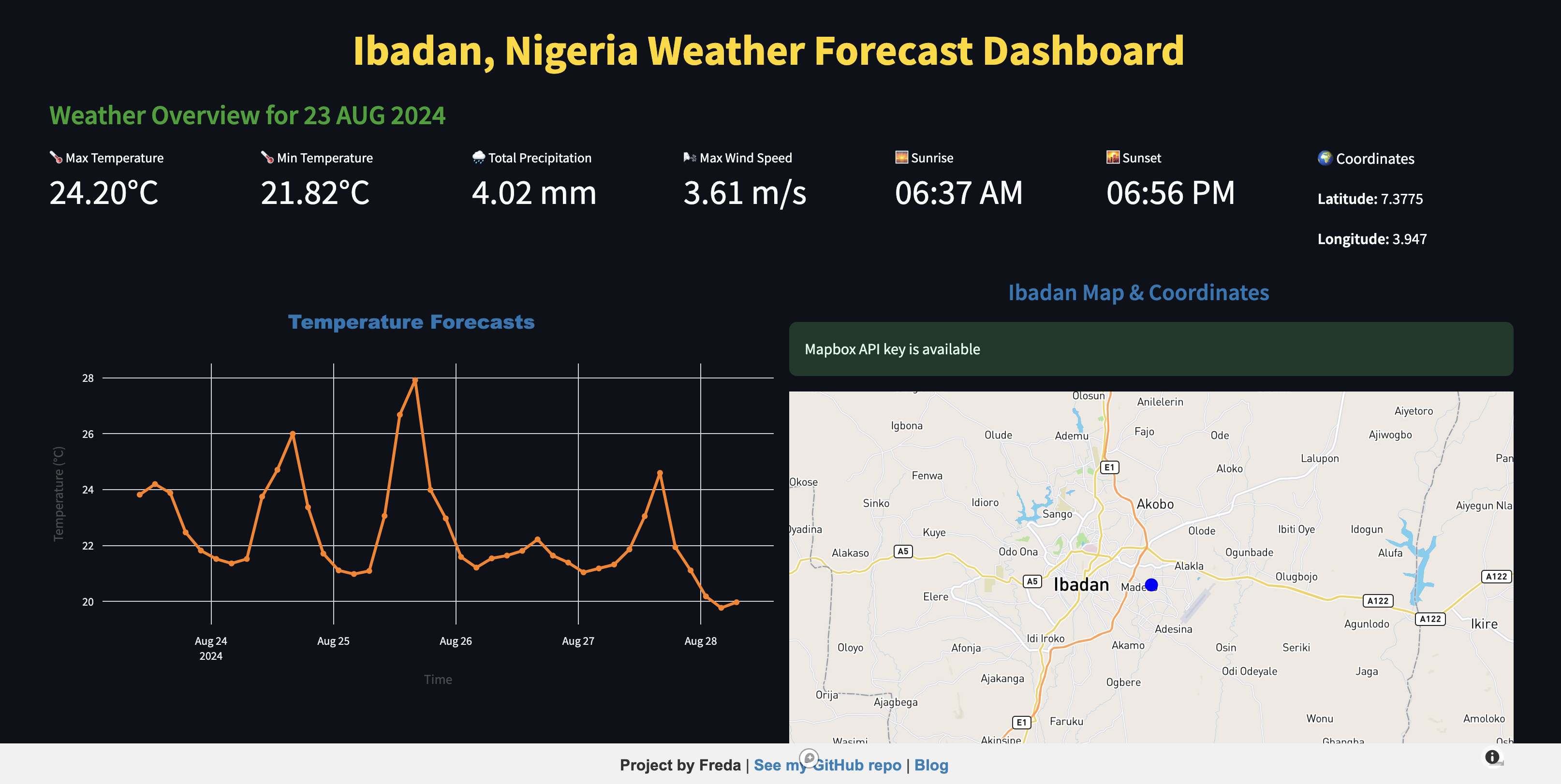
Discover the journey of building a weather dashboard from Lagos to Ibadan. Learn how to collect, transform, and visualize real-time weather data using PySpark, Streamlit, and Plotly. Perfect for data enthusiasts and engineers!
🌦️ Introduction
Weather forecasting plays a crucial role in our daily lives—deciding if you need to grab an umbrella ☂️ or helping industries like agriculture and aviation plan for upcoming conditions. But behind each forecast, there’s an ocean of raw data 📊 that needs to be tamed and transformed into useful insights. That's where Data Engineering comes in.
In simple terms, Data Engineering is all about managing data—collecting it, cleaning it, and making sure it’s ready for use. When it comes to weather, we’re talking about vast amounts of data being captured every second from sources like satellites 🛰️, sensors, and weather stations. This data is messy and unstructured at first, so it’s the job of a data engineer to wrangle it into something understandable, usable, and, most importantly, actionable.
Planning to move to Ibadan 🏙️, I thought it would be interesting to see how the weather compares to what I was used to in Lagos 🌆. So, I decided to build a weather dashboard specifically for Ibadan. The goal? To take all that raw weather data 🌧️, process it using Python 💻, and present it in a way that’s both easy to understand and visually appealing 🎨. Whether you’re a local checking out today’s forecast or a data enthusiast interested in weather patterns, this dashboard has something for everyone.
What makes this project interesting from a data engineering perspective is how it handles the full lifecycle of data: from fetching weather data from APIs, transforming it into meaningful metrics like temperature 🌡️ and humidity 💧, and finally visualising it using graphs 📈 and maps 🗺️. Along the way, I’ll break down the steps and show you how I built this dashboard, making it a fun ride 🚀 for both beginners and experienced data experts alike!
⚙️ Project Overview
Curious about Ibadan, I wanted to see how the weather compares to Lagos, so I built a weather forecast dashboard using PySpark to process and visualise weather data. The goal? To fetch raw weather data from an API, clean it up with PySpark, and display it interactively for easy analysis.
Tools & Technologies:
The project primarily leverages PySpark for data handling, alongside other key technologies:
PySpark ⚡: This was the main tool used to process and transform weather data. PySpark's distributed computing power made it easy to work with real-time weather data efficiently.
Pandas 🐼: For some smaller data manipulations, Pandas helped in cleaning and structuring data.
Streamlit 📊: Used for creating the interactive weather dashboard.
Plotly 📈: To visualise weather data in graphs and charts.
APIs 🌍: The weather data was sourced from the OpenWeatherMap API, which provided real-time data for Ibadan. Mapbox API provided the Ibadan Interactive Map.
The Process:
+---------------------+ +-----------------+ +----------------------+
| | | | | |
| 1. Data Ingestion | | 2. Data | | 3. Data |
| - API Call | -> | Cleaning | -> | Transformation |
| - JSON Parse | | - PySpark | | - Group, Aggregate |
| | | | | - Calculate Metrics |
+---------------------+ +-----------------+ +----------------------+
↓ ↓ ↓
+---------------------+ +-----------------+ +----------------------+
| | | | | |
| 4. Data Storage | -> | 5. Visualisation| -> | 6. Streamlit Dash |
| - CSV / Parquet | | - Seaborn/Plotly| | - Display Charts |
| | | - Map (Mapbox) | | - User Interaction |
+---------------------+ +-----------------+ +----------------------+
↓ ↓ ↓
+----------------------+ +----------------+ +----------------------+
| | | | | |
| 7. Deployment | | 8. Blog / | | 9. GitHub |
| - Streamlit Cloud | -> | Documentation | -> | - Code Hosting |
| | | | | - README.md |
+----------------------+ +----------------+ +----------------------+
Data Collection with APIs:
I used the OpenWeatherMap API to fetch real-time weather data for Ibadan. The data was collected in JSON format, including metrics like temperature, humidity, wind speed, and cloud coverage.
PySpark for Data Transformation:
Using PySpark within VS Code, I loaded the raw JSON data into DataFrames. By defining custom schemas, I was able to manage complex, nested data structures like weather conditions, temperature details, and wind metrics. I then applied various transformations to clean, filter, and format the data, ensuring it was ready for analysis and visualisation.
Overcoming Challenges:
One challenge I faced was that when saving the processed data to disk, PySpark partitioned it into multiple files (e.g., part-00000.csv), which wasn’t ideal for a small dataset. To solve this, I coalesced the data into a single partition before saving, ensuring that all the data was neatly stored in a single CSV file. Also deploying the app on Streamlit initially caused issues due to missing dependencies in the repository. I added a requirements.txt file to the project, which listed all necessary dependencies for Streamlit to run the app correctly.
Building the Dashboard:
With the data processed and cleaned, I used Streamlit to create an interactive weather dashboard. The dashboard displays key weather metrics like temperature, humidity, and wind speed for the current day, alongside a 5-day forecast.
Visualising with Plotly (Streamlit) and Seaborn (Notebook):
I used Plotly and Seaborn to generate dynamic and static charts, including time series graphs of temperature and humidity, giving users an easy way to interpret the weather trends over time.
Target Audience: Data enthusiasts who want to see how PySpark and Streamlit can be used to transform and visualise real-time data.
Data Collection Process
The first step in building the weather dashboard was collecting real-time weather data for Ibadan. For this, I used the OpenWeatherMap API, which provides detailed weather forecasts for any location worldwide.
API Setup
To get started, I created an account on OpenWeatherMap and obtained an API key, which is required for accessing the data. The API allows you to query weather forecasts for a specific location by specifying parameters like latitude, longitude, and the desired units (metric in this case).
For Ibadan, I used the following parameters:
Latitude: 7.42
Longitude: 3.93
Units: Metric (for Celsius temperatures)
API Key: (Stored securely in a
.envfile)
API Request:
Using the requests library in Python, I sent a GET request to the API endpoint. The API returned weather data in JSON format, which included details like:
Temperature 🌡️
Feels-like temperature
Humidity 💧
Wind speed and direction 🍃
Cloudiness ☁️
Sunrise and sunset times 🌅
Here’s a simplified example of the API request I used:
import requests
import os
from dotenv import load_dotenv
# Load environment variables from the .env file
load_dotenv()
# Fetch the API key from the environment
api_key = os.getenv("OPENWEATHER_API_KEY")
# Define the API URL with Ibadan's coordinates
api_url = f'https://api.openweathermap.org/data/2.5/forecast?lat=7.42&lon=3.93&appid={api_key}&units=metric'
# Send the request and receive the response
response = requests.get(api_url)
data = response.json()
About the Data:
The API provides a 5-day weather forecast with 3-hour intervals, meaning that for each day, you receive eight forecast entries, each including the temperature, humidity, wind speed, and more. This data is highly detailed but unstructured, so it required careful handling to transform it into a usable format.
⚡ Data Transformation with PySpark
Once the raw weather data was collected from the API, the next step was to transform it into a structured format that could be easily analysed and visualised. This is where PySpark came into play, providing the power of distributed computing to handle data efficiently, even when scaling up.
Loading the Data into PySpark
I used PySpark within VS Code to load the raw JSON data into DataFrames, a structure that allows for distributed processing and easy manipulation of large datasets.
Here’s how I set up the PySpark session:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder \
.appName("PySpark Weather Project") \
.master("local[*]") \
.getOrCreate()
# Verify Spark session
print(spark)
With the SparkSession ready, I loaded the API's JSON response into a DataFrame, making it easier to work with the structured weather data.
Schema Definition
The JSON data from the API contained several nested fields, including temperature, wind, and weather descriptions. To manage this complexity, I defined a custom schema using PySpark’s StructType and StructField objects. This allowed me to handle the nested structures effectively and extract the relevant information.
Here’s an example of the schema I used for the weather data:
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, LongType
weather_schema = StructType([
StructField("dt", LongType(), True), # Timestamp
StructField("main", StructType([
StructField("temp", DoubleType(), True),
StructField("feels_like", DoubleType(), True),
StructField("temp_min", DoubleType(), True),
StructField("temp_max", DoubleType(), True),
StructField("pressure", DoubleType(), True),
StructField("humidity", DoubleType(), True)
]), True),
StructField("wind", StructType([
StructField("speed", DoubleType(), True),
StructField("deg", DoubleType(), True)
]), True),
StructField("weather", StructType([
StructField("description", StringType(), True)
]), True)
])
This schema helped flatten the nested JSON data, making the relevant fields—like temperature, wind speed, and weather descriptions—easy to access and use for further processing.
Data Cleaning and Transformation
Once the data was loaded into the DataFrame and structured using the schema, I applied several transformations to clean and format it:
Handling missing values: I used PySpark’s
fillna()method to fill any missing values in critical fields like temperature or humidity.Standardising timestamps: The API provided timestamps in Unix format, so I converted these to readable dates and times using PySpark’s
from_unixtime()function.Creating new metrics: I calculated new fields such as the "feels-like" temperature, which provides a more accurate reflection of perceived temperature.
Here’s an example of a transformation that formatted the timestamps:
from pyspark.sql.functions import from_unixtime, col
# Convert Unix timestamp to readable date-time format
df = df.withColumn("date_time", from_unixtime(col("dt")))
Challenges & Solutions
One challenge I encountered was how PySpark partitions data by default when writing to disk. Instead of saving one CSV file, it created multiple partitioned files. To resolve this, I used PySpark's coalesce() function to reduce the data to a single partition, ensuring it was saved as one file:
# Combine all partitions into a single CSV file
df.coalesce(1).write.csv("output/weather_data.csv")
⚡ Data Transformation with PySpark
Once the raw weather data was collected from the API, the next step was to transform it into a structured format that could be easily analysed and visualised. This is where PySpark came into play, providing the power of distributed computing to handle data efficiently, even when scaling up.
Loading the Data into PySpark
I used PySpark within VS Code to load the raw JSON data into DataFrames, a structure that allows for distributed processing and easy manipulation of large datasets.
Here’s how I set up the PySpark session:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder \
.appName("PySpark Weather Project") \
.master("local[*]") \
.getOrCreate()
# Verify Spark session
print(spark)
With the SparkSession ready, I loaded the API's JSON response into a DataFrame, making it easier to work with the structured weather data.
Schema Definition
The JSON data from the API contained several nested fields, including temperature, wind, and weather descriptions. To manage this complexity, I defined a custom schema using PySpark's StructType and StructField objects. This allowed me to handle the nested structures effectively and extract the relevant information.
Here’s an example of the schema I used for the weather data:
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, LongType
weather_schema = StructType([
StructField("dt", LongType(), True), # Timestamp
StructField("main", StructType([
StructField("temp", DoubleType(), True),
StructField("feels_like", DoubleType(), True),
StructField("temp_min", DoubleType(), True),
StructField("temp_max", DoubleType(), True),
StructField("pressure", DoubleType(), True),
StructField("humidity", DoubleType(), True)
]), True),
StructField("wind", StructType([
StructField("speed", DoubleType(), True),
StructField("deg", DoubleType(), True)
]), True),
StructField("weather", StructType([
StructField("description", StringType(), True)
]), True)
])
This schema helped flatten the nested JSON data, making the relevant fields—like temperature, wind speed, and weather descriptions—easy to access and use for further processing.
Data Cleaning and Transformation
Once the data was loaded into the DataFrame and structured using the schema, I applied several transformations to clean and format it:
Handling missing values: I used PySpark’s
fillna()method to fill any missing values in critical fields like temperature or humidity.Standardising timestamps: The API provided timestamps in Unix format, so I converted these to readable dates and times using PySpark’s
from_unixtime()function.Creating new metrics: I calculated new fields such as the "feels-like" temperature, which provides a more accurate reflection of perceived temperature.
Here’s an example of a transformation that formatted the timestamps:
from pyspark.sql.functions import from_unixtime, col
# Convert Unix timestamp to readable date-time format
df = df.withColumn("date_time", from_unixtime(col("dt")))
Challenges & Solutions
One challenge I encountered was how PySpark partitions data by default when writing to disk. Instead of saving one CSV file, it created multiple partitioned files. To resolve this, I used PySpark's coalesce() function to reduce the data to a single partition, ensuring it was saved as one file:
# Combine all partitions into a single CSV file
df.coalesce(1).write.csv("output/weather_data.csv")
📈 Visualising Data with Plotly
Turning raw weather data into something visual and interactive is key to helping users truly understand it. That's why I used Plotly for this project, a powerful library that seamlessly integrates with Python and offers interactive, sleek visualisations. With Plotly, users can not only view the weather forecast but also engage with the data—zooming in, panning, and hovering to explore insights in greater detail.
Why Plotly?
Plotly is known for its interactive charts that make it easy to explore data visually. Rather than just looking at static numbers, users can dive into the trends. For instance, hovering over data points reveals precise values, and the ability to zoom in on specific parts of the chart helps users explore the data on a deeper level. This functionality brings the weather forecast to life, making it more engaging and informative.
Creating the 5-Day Temperature Forecast
One of the most important aspects of a weather dashboard is knowing what’s ahead—especially when it comes to temperature 🌡️. With Plotly, I created an interactive 5-day temperature forecast that allows users to see the expected highs and lows for Ibadan over the next few days. Each data point represents a 3-hour interval, ensuring a detailed, real-time view of the changing weather.
Here’s the code snippet I used to build the temperature forecast chart:
import plotly.express as px
# Create a line chart for the temperature forecast
fig = px.line(df, x="date_time", y="temp", title="5-Day Temperature Forecast")
# Display the chart in Streamlit
st.plotly_chart(fig)
This simple yet powerful graph gives users a clear sense of the upcoming temperature trends. The hover feature allows users to pinpoint the exact temperature at any given time during the 5-day period, making it both informative and interactive.
Humidity and Wind Speed Visualisations
In addition to temperature, understanding humidity 💧 and wind speed 🍃 is crucial for gauging comfort and planning activities. Using Plotly, I created similar interactive line charts for both humidity and wind speed. These graphs provide a fuller picture of the forecast, letting users explore multiple weather variables in one go.
Here's how I created the humidity chart:
# Create a line chart for the humidity forecast
fig_humidity = px.line(df, x="date_time", y="humidity", title="Humidity Forecast")
# Display the chart in Streamlit
st.plotly_chart(fig_humidity)
Similarly, for wind speed:
# Create a line chart for the wind speed forecast
fig_wind = px.line(df, x="date_time", y="wind_speed", title="Wind Speed Forecast")
# Display the chart in Streamlit
st.plotly_chart(fig_wind)
These additional visualisations help users see how the weather will evolve in more detail—whether it’s planning for a windy day or seeing how humidity will affect the perceived temperature.
Interactive Features That Enhance User Experience
What makes these charts stand out are their interactive elements:
Zoom and Pan: Users can zoom into specific timeframes (e.g., focusing on a single day within the 5-day forecast) or pan across the chart to explore different sections.
Hover for Details: Hovering over any point on the graph reveals the exact value of that weather metric (temperature, humidity, or wind speed) at that specific time.
Live Updates: The data in these graphs is refreshed regularly, meaning users get a real-time look at how the forecast changes.
The Impact of Visualising the Weather
Raw data can often feel overwhelming, but turning it into a visual format can make it immediately understandable. With Plotly’s interactive charts, users don’t just see numbers—they can explore trends, spot patterns, and gain deeper insights into how the weather is evolving. Whether it’s seeing a spike in temperature or anticipating a humid day, these charts allow users to make informed decisions with ease.
🎓 Lessons Learned
Building the weather dashboard was a valuable learning experience, especially in combining PySpark, Streamlit, Git, and VS Code for the first time. It was full of "aha" moments, challenges, and problem-solving, all of which strengthened my skills in data engineering and version control.
1. PySpark for Data Engineering
Using PySpark to handle real-time weather data taught me the importance of efficiently managing and transforming large datasets. From custom schemas for nested JSON structures to optimising data outputs, PySpark’s scalability proved vital for this project.
2. Streamlit and Git Integration
Deploying the dashboard on Streamlit required careful management of code with Git for version control. This was my first time using Streamlit and Git together, and it provided key insights:
Versioning: Learning to track changes, experiment with branches, and push updates to GitHub for deployment was crucial for keeping the project clean and organised.
Deployment: Setting up automatic deployment via GitHub for the first time was an eye-opener, especially when debugging deployment errors related to dependencies.
3. Debugging and Problem-Solving
Using VS Code for development made debugging more efficient. I encountered several issues while deploying the dashboard and managing API data, but the combination of Git’s versioning and VS Code’s debugging tools helped resolve these challenges quickly.
4. Data Visualisation with Plotly
Plotly’s interactive visualisations transformed raw data into engaging, user-friendly graphs. The ability to zoom, hover, and pan made the forecast data far more accessible, helping users explore temperature, humidity, and wind speed trends effortlessly.
5. Working with APIs
Handling real-time data from the OpenWeatherMap API reinforced the importance of managing API requests, securing API keys, and parsing JSON responses efficiently for real-time data apps.
🚀 Future Improvements
While this project resulted in a functional weather dashboard, there are several ways I could enhance it moving forward:
1. Add More Weather Metrics: Including additional data points like air quality, UV index, or precipitation probability would provide more comprehensive weather insights for users.
2. Expand to Multiple Cities: Currently, the dashboard focuses on Ibadan. I plan to allow users to input their city and view forecasts for other locations, making the dashboard more dynamic.
3. Automate Data Updates with Cloud Services: Implementing cloud-based scheduling services like AWS Lambda or Google Cloud Functions would allow for automated data refreshes, ensuring the dashboard is always up-to-date.
4. Performance Optimisations: As the dataset grows or more cities are added, I would explore optimising the PySpark processes and Streamlit’s performance to handle larger data volumes more efficiently.
🌟 Conclusion
This project was not just about building a weather dashboard—it was about learning how to transform raw data into meaningful insights using powerful tools like PySpark and Streamlit. From collecting real-time weather data to processing it efficiently to visualising it with interactive charts, this journey gave me a deeper appreciation for the entire data engineering pipeline.
For those interested in exploring further, you can check out the full project repository, where I’ve documented the code and processes in detail. You can also view the live dashboard in action to see how it visualises Ibadan’s weather forecast in real-time.
If you found this blog helpful or want to follow along on my journey as I explore more Data Engineering projects, here’s how you can stay connected:
Like & Subscribe: Be sure to subscribe for more blogs on data engineering, where I’ll share my experiences, challenges, and tips.
Check out my LinkedIn: Connect with me on LinkedIn to stay updated on my latest projects and industry insights.
Explore the Project Repository: Dive into the full codebase on GitHub to see how I built the weather dashboard from scratch.
Visit the Live App: Want to see the weather forecast for Ibadan in action? Check out the live dashboard here: Streamlit App.
Thank you for reading! Feel free to reach out if you have any questions or comments, or if you just want to geek out about data engineering!
Subscribe to my newsletter
Read articles from Freda Victor directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Freda Victor
Freda Victor
I am an Analytics Engineer skilled in Python, SQL, AWS, Google Cloud, and GIS. With experience at MAKA, Code For Africa & Co-creation Hub, I enhance data accessibility and operational efficiency. My background in International Development and Geography fuels my passion for data-driven solutions and social impact.