Build your own SQLite, Part 2: Scanning large tables
 Geoffrey Copin
Geoffrey Copin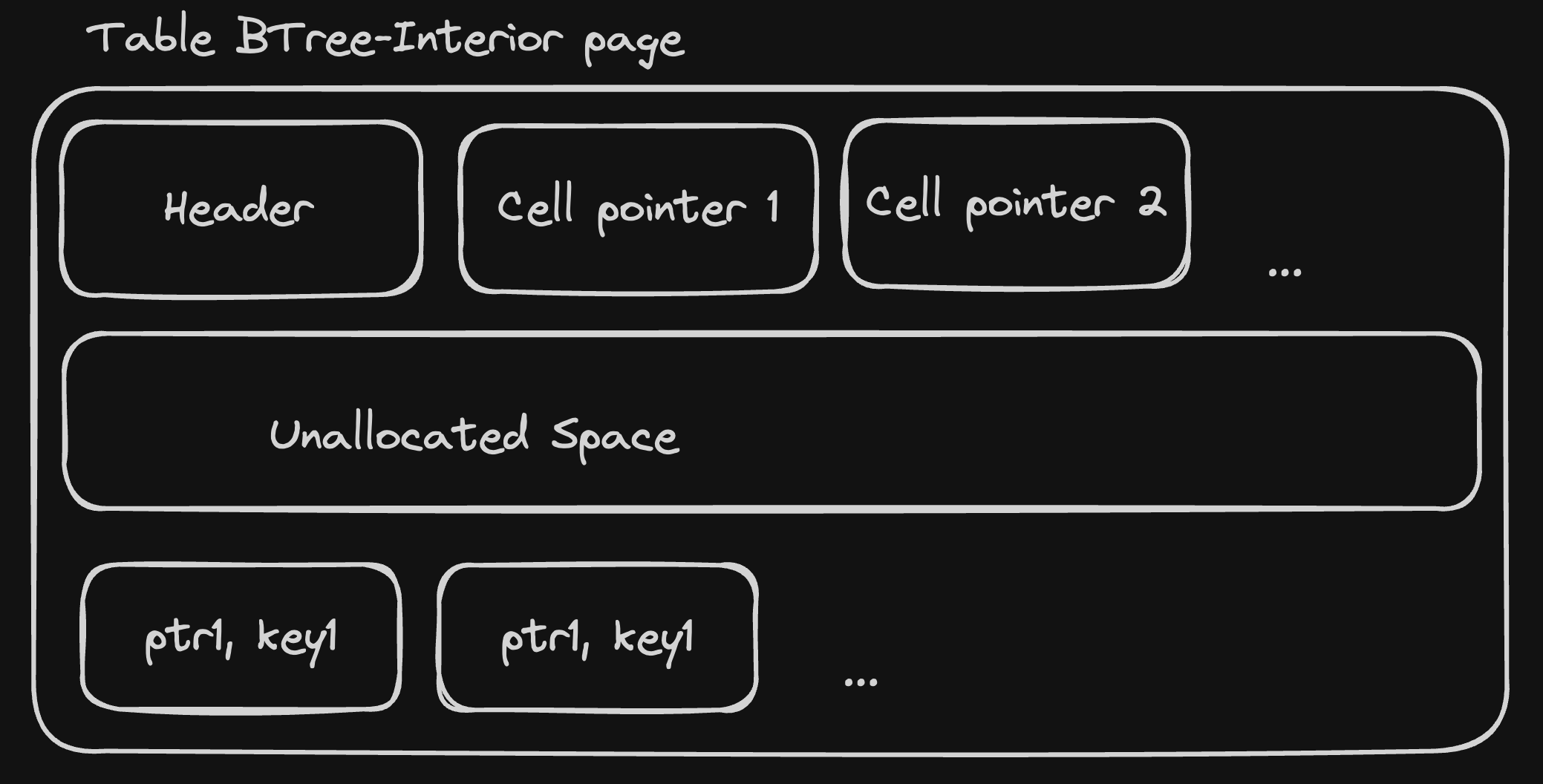
In the previous post, we discovered the SQLite file format and implemented a toy version of the .tables command, allowing us to display the list of tables in a database. But our implementation has a jarring limitation: it assumes that all the data fits into the first page of the file. In this post, we'll discover how SQLite represents tables that are too large to fit into a single page, this will make our .tables command more useful, but also lay the groundwork for our query engine.
A motivating example
Let's begin our journey with a much larger test database:
for i in {1..1000}; do
sqlite3 res/test.db "create table table$i(id integer)"
done
cargo run --release -- res/test.db
rqlite> .tables
Without much surprise, our small program isn't able to display the list of tables. The reason for that is quite simple: database pages are typically 4096 bytes long, which is far from enough to store 1000 tables. But why did our code fail, instead of displaying the first records that fit into the first page?
B-tree interior pages
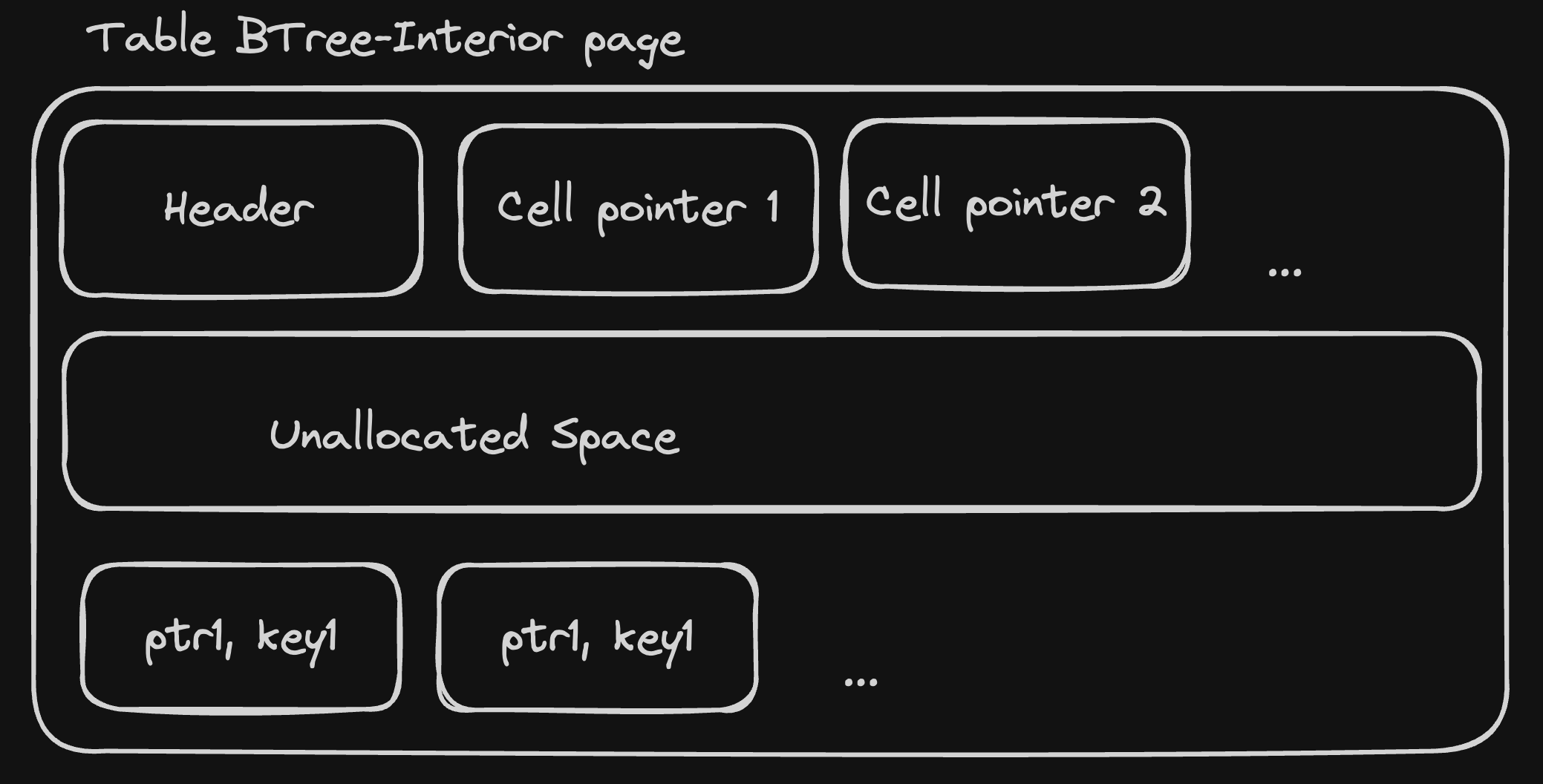
When a table is too large to fit into a single page, SQLite splits it into multiple pages, of different types:
leaf pages, that contains the actual records
interior pages, that store information about which page contains the records for which table.
Interior tables have the same high-level structure as leaf pages, with two key differences:
instead of storing record, they store a tuple
(key, child_page_number)wherechild_page_numberis a 32 bits unsigned integer representing the page number of the "root" page of a subtree that contains records with keys lower or equal tokey. Cells in interior pages are logically ordered bykeyin ascending order.the header contains an extra field, the "rightmost pointer", which is the page number of the "root" of the subtree that contains records with keys greater than the largest key in the page.
With this new knowledge, we can update our page data structure. We'll start by adding the new optional rightmost_pointer field to the page header. We'll also add a byte_size method that returns the size of the header, depending on wheter the rightmost_pointer field is set or not, and add a new variant to our PageType enum to represent interior pages.
// src/page.rs
#[derive(Debug, Copy, Clone, Eq, PartialEq)]
pub enum PageType {
TableLeaf,
+ TableInterior,
}
#[derive(Debug, Copy, Clone)]
pub struct PageHeader {
pub page_type: PageType,
pub first_freeblock: u16,
pub cell_count: u16,
pub cell_content_offset: u32,
pub fragmented_bytes_count: u8,
+ pub rightmost_pointer: Option<u32>,
}
+impl PageHeader {
+ pub fn byte_size(&self) -> usize {
+ if self.rightmost_pointer.is_some() {
+ 12
+ } else {
+ 8
+ }
+ }
+}
Let's modify the parsing function to take the new field into account:
// src/pager.rs
+ const PAGE_LEAF_TABLE_ID: u8 = 0x0d;
+ const PAGE_INTERIOR_TABLE_ID: u8 = 0x05;
fn parse_page_header(buffer: &[u8]) -> anyhow::Result<page::PageHeader> {
- let page_type = match buffer[0] {
- 0x0d => page::PageType::TableLeaf,
+ let (page_type, has_rightmost_ptr) = match buffer[0] {
+ PAGE_LEAF_TABLE_ID => (page::PageType::TableLeaf, false),
+ PAGE_INTERIOR_TABLE_ID => (page::PageType::TableInterior, true),
_ => anyhow::bail!("unknown page type: {}", buffer[0]),
};
let first_freeblock = read_be_word_at(buffer, PAGE_FIRST_FREEBLOCK_OFFSET);
let cell_count = read_be_word_at(buffer, PAGE_CELL_COUNT_OFFSET);
let cell_content_offset = match read_be_word_at(buffer, PAGE_CELL_CONTENT_OFFSET) {
0 => 65536,
n => n as u32,
};
let fragmented_bytes_count = buffer[PAGE_FRAGMENTED_BYTES_COUNT_OFFSET];
+ let rightmost_pointer = if has_rightmost_ptr {
+ Some(read_be_double_at(buffer, PAGE_RIGHTMOST_POINTER_OFFSET))
+ } else {
+ None
+ };
Ok(page::PageHeader {
page_type,
first_freeblock,
cell_count,
cell_content_offset,
fragmented_bytes_count,
+ rightmost_pointer,
})
}
We decide whether to parse the rightmost_pointer field depending on the value of the page_type byte (0x0d for leaf pages, 0x05 for interior pages).
Next, we'll update the Page struct to reflect the fact that both leaf and interior pages share the same structure, with the only difference being the content of the cells:
// src/page.rs
#[derive(Debug, Clone)]
- pub struct TableLeafPage {
+ pub struct Page {
pub header: PageHeader,
pub cell_pointers: Vec<u16>,
- pub cells: Vec<TableLeafCell>,
+ pub cells: Vec<Cell>,
}
- #[derive(Debug, Clone)]
- pub enum Page {
- TableLeaf(TableLeafPage),
- }
+ #[derive(Debug, Clone)]
+ pub enum Cell {
+ TableLeaf(TableLeafCell),
+ TableInterior(TableInteriorCell),
+ }
+ impl From<TableLeafCell> for Cell {
+ fn from(cell: TableLeafCell) -> Self {
+ Cell::TableLeaf(cell)
+ }
+ }
+ impl From<TableInteriorCell> for Cell {
+ fn from(cell: TableInteriorCell) -> Self {
+ Cell::TableInterior(cell)
+ }
+ }
+ pub struct TableInteriorCell {
+ pub left_child_page: u32,
+ pub key: i64,
+ }
This change calls for a major update of our parsing functions, reproduced below:
// src/pager.rs
fn parse_page(buffer: &[u8], page_num: usize) -> anyhow::Result<page::Page> {
let ptr_offset = if page_num == 1 { HEADER_SIZE as u16 } else { 0 };
let content_buffer = &buffer[ptr_offset as usize..];
let header = parse_page_header(content_buffer)?;
let cell_pointers = parse_cell_pointers(
&content_buffer[header.byte_size()..],
header.cell_count as usize,
ptr_offset,
);
let cells_parsing_fn = match header.page_type {
page::PageType::TableLeaf => parse_table_leaf_cell,
page::PageType::TableInterior => parse_table_interior_cell,
};
let cells = parse_cells(content_buffer, &cell_pointers, cells_parsing_fn)?;
Ok(page::Page {
header,
cell_pointers,
cells,
})
}
fn parse_cells(
buffer: &[u8],
cell_pointers: &[u16],
parse_fn: impl Fn(&[u8]) -> anyhow::Result<page::Cell>,
) -> anyhow::Result<Vec<page::Cell>> {
cell_pointers
.iter()
.map(|&ptr| parse_fn(&buffer[ptr as usize..]))
.collect()
}
fn parse_table_leaf_cell(mut buffer: &[u8]) -> anyhow::Result<page::Cell> {
let (n, size) = read_varint_at(buffer, 0);
buffer = &buffer[n as usize..];
let (n, row_id) = read_varint_at(buffer, 0);
buffer = &buffer[n as usize..];
let payload = buffer[..size as usize].to_vec();
Ok(page::TableLeafCell {
size,
row_id,
payload,
}
.into())
}
fn parse_table_interior_cell(mut buffer: &[u8]) -> anyhow::Result<page::Cell> {
let left_child_page = read_be_double_at(buffer, 0);
buffer = &buffer[4..];
let (_, key) = read_varint_at(buffer, 0);
Ok(page::TableInteriorCell {
left_child_page,
key,
}
.into())
}
Scanning logic
Our scanning logic will need to be updated to handle interior pages. We can no longer simply iterate over the cells of a page and call it a day. Instead, we'll need to implement a depth-first algorithm that recursively explores the tree, starting from the root page.
To make our task easier, let's introduce a new PositionedPage struct that stores a page, along with the index of the current cell we're looking at:
// src/pager.rs
#[derive(Debug)]
pub struct PositionedPage {
pub page: Page,
pub cell: usize,
}
impl PositionedPage {
pub fn next_cell(&mut self) -> Option<&Cell> {
let cell = self.page.get(self.cell);
self.cell += 1;
cell
}
pub fn next_page(&mut self) -> Option<u32> {
if self.page.header.page_type == PageType::TableInterior
&& self.cell == self.page.cells.len()
{
self.cell += 1;
self.page.header.rightmost_pointer
} else {
None
}
}
}
The next_cell method returns the content of the current cell and increments the cell index, so calling it repeatedly will yiels the content of all the cells in the page.
The next_page method is a bit more complex: it returns the rightmost_pointer of the current page if it's an interior page and we just visited the last cell, otherwise it it returns None.
We'll also update our Cursor so that it owns it's payload instead of borrowing it through a Pager:
// src/pager.rs
#[derive(Debug)]
- pub struct Cursor<'p> {
+ pub struct Cursor {
header: RecordHeader,
- pager: &'p mut Pager,
- page_index: usize,
- page_cell: usize,
+ payload: Vec<u8>,
}
This change will allow us to avoid borrowing the Pager mutably from the Cursor and the Scanner at the same time, which would lead to a difficult-to-solve lifetime issue.
With that out of the way, we can focus on the tree scanning logic. We'll maintain a stack of PositionedPage to keep track of the parent pages we've visited. At every step of the walk, there are a few cases to consider:
if the current page is a leaf page and we haven't visited all the cells yet, we'll just have to build a
Cursorwith the current cell's payload and return it.if the current page is an interior page, we'll push the next page (either from the current cell or the rightmost pointer) to the stack and continue the walk.
if we've visited all the cells of the current page, we'll pop the stack and continue the walk from the parent page.
This logic is implemented in the new Scanner struct:
// src/pager.rs
#[derive(Debug)]
pub struct Scanner<'p> {
pager: &'p mut Pager,
initial_page: usize,
page_stack: Vec<PositionedPage>,
}
impl<'p> Scanner<'p> {
pub fn new(pager: &'p mut Pager, page: usize) -> Scanner<'p> {
Scanner {
pager,
initial_page: page,
page_stack: Vec::new(),
}
}
pub fn next_record(&mut self) -> anyhow::Result<Option<Cursor>> {
loop {
match self.next_elem() {
Ok(Some(ScannerElem::Cursor(cursor))) => return Ok(Some(cursor)),
Ok(Some(ScannerElem::Page(page_num))) => {
let new_page = self.pager.read_page(page_num as usize)?.clone();
self.page_stack.push(PositionedPage {
page: new_page,
cell: 0,
});
}
Ok(None) if self.page_stack.len() > 1 => {
self.page_stack.pop();
}
Ok(None) => return Ok(None),
Err(e) => return Err(e),
}
}
}
fn next_elem(&mut self) -> anyhow::Result<Option<ScannerElem>> {
let Some(page) = self.current_page()? else {
return Ok(None);
};
if let Some(page) = page.next_page() {
return Ok(Some(ScannerElem::Page(page)));
}
let Some(cell) = page.next_cell() else {
return Ok(None);
};
match cell {
Cell::TableLeaf(cell) => {
let header = parse_record_header(&cell.payload)?;
Ok(Some(ScannerElem::Cursor(Cursor {
header,
payload: cell.payload.clone(),
})))
}
Cell::TableInterior(cell) => Ok(Some(ScannerElem::Page(cell.left_child_page))),
}
}
fn current_page(&mut self) -> anyhow::Result<Option<&mut PositionedPage>> {
if self.page_stack.is_empty() {
let page = match self.pager.read_page(self.initial_page) {
Ok(page) => page.clone(),
Err(e) => return Err(e),
};
self.page_stack.push(PositionedPage { page, cell: 0 });
}
Ok(self.page_stack.last_mut())
}
}
#[derive(Debug)]
enum ScannerElem {
Page(u32),
Cursor(Cursor),
}
Putting it all together
The only change that remains to be made is to update the display_tables function to account for the change in next_record signature:
// src/main.rs
fn display_tables(db: &mut db::Db) -> anyhow::Result<()> {
let mut scanner = db.scanner(1);
- while let Some(Ok(mut record)) = scanner.next_record() {
+ while let Some(mut record) = scanner.next_record()? {
let type_value = record
.field(0)
.context("missing type field")
.context("invalid type field")?;
if type_value.as_str() == Some("table") {
let name_value = record
.field(1)
.context("missing name field")
.context("invalid name field")?;
print!("{} ", name_value.as_str().unwrap());
}
}
Ok(())
}
We can now display our (long!) list of tables:
cargo run --release -- res/test.db
rqlite> .tables
Conclusion
Our scanning logic is now able to handle tables that span multiple pages, thanks to the introduction of interior pages. This is a major milestone in our journey to build a fully functional database! In the next post, we'll learn how to parse simple SQL queries and will lay the groundwork for our query engine.
Subscribe to my newsletter
Read articles from Geoffrey Copin directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by