Building an Effective Enterprise LLM/SLM Evaluation Framework: Key Strategies and Tools
 Pablo Salvador Lopez
Pablo Salvador Lopez
Struggling to figure out how to evaluate and benchmark your GenAI apps? This article gives you an easy-to-follow guide for bulk evaluation and benchmarking of your GenAI applications. It talks about why a continuous evaluation framework is important, Responsible AI practices, customizing evaluation metrics for specific use cases, and the differences between offline and online evaluations. Plus, it introduces tools like PromptFlow and Azure AI Foundry to help you build a scalable enterprise LLM evaluation system.
🤔 What to know before you start building
🤖 The Challenges of Evaluating GenAI Outputs
Imagine you’re building an AI assistant for customer service. You start with straightforward, well-defined tasks within the Retrieval-Augmented Generation (RAG) framework. But as you dive deeper into optimizing performance, things get more complex—post-processing responses, setting up guardrails to prevent inappropriate answers, interpreting code, routing tasks to the correct models, combining multiple models, and managing memory efficiently. It can quickly become overwhelming, especially when it comes to figuring out how to measure these improvements.
The challenge is clear: developers need to know what to evaluate and when. For many hands-on practitioners, aligning chatbot performance with traditional business metrics isn't easy. I get it—this is a whole new paradigm, particularly for those accustomed to more predictable areas of software development. And trust me, this becomes even more critical when transitioning from a small proof-of-concept to a full-scale GenAI production system. It’s like upgrading from a toy car to a real one—you need to understand how every part functions to ensure a smooth ride. Many tasks in this space aren’t deterministic by nature, adding to the complexity.
That’s why the goal of this article is to provide a framework to help both developers and business leaders evaluate the quality of their GenAI applications using tools and processes that align application results with expectations. Let's commit to at least "centralize measuring," which is already a win for many enterprises where evaluations and tools are all over the place.
Evaluation, yes my friends, is a continuous process...
Through my work with many large companies, I've seen a common misunderstanding about evaluating Generative AI (GenAI) applications, especially chatbots that "talk" to different customers. Many think these LLMs (the brains of the chatbot) can be judged with just a few test prompts or tiny golden datasets. But this method misses the variety in human interactions. People communicate, write, and express themselves in different ways, and evaluating GenAI models needs to consider this diversity.
As A Survey on Evaluation of Large Language Models points out, understanding machine intelligence requires continuous, in-depth evaluation. Just as the Turing Test once served as a benchmark for assessing machine intelligence, modern AI models now demand more comprehensive, real-world testing. Unlike older models, LLMs are capable of handling a much broader range of tasks, which necessitates more nuanced evaluation methods.
Therefore, evaluating Large Language Models (LLMs) is no longer a one-time task. With the rise of LLMOps—similar to MLOps but specifically for LLMs—practices like Continuous Integration, Continuous Evaluation, and Continuous Deployment (CI/CE/CD) have become crucial for maintaining model quality over time. This shift marks a change from traditional, deterministic software development to a continuous cycle of evaluation and improvement. This is especially important when automating the adoption of new, large pre-trained models (LLMs), which can significantly change behavior based on their training strategy. For example, an evaluation that focuses only on Responsible AI (RAI) metrics may miss important performance issues, leading to validation data that doesn't align with your prompts or prompt engineering efforts. In simple terms, your automation might work correctly, but it might not evaluate the new LLM candidate properly before it's used in production. So, what seems like a smarter addition might not be suitable for your specific domain problem.
The evaluation process isn’t just about measuring one area. Many fall into the trap of treating benchmarks like MMLU and TruthfulQA as the gold standard for LLM evaluations. However, these benchmarks fail to capture the complexity of real-world interactions. As highlighted in the A Survey on Evaluation of Large Language Models paper, systems integrated into customer-facing applications need ongoing, domain-specific testing. For instance, evaluations should focus on a deep understanding of human interaction, as explored in Beyond Accuracy: Behavioral Testing of NLP Models. Moreover, real-time performance, especially in domain-specific tasks, is critical, as emphasized in Evaluating Large Language Models Trained on Code. (Highly recommend those reads)
In short, LLM evaluations must be continuous and domain-specific, combining both offline and real-time testing to ensure consistent performance.
🧭The importance of a Evaluation Framework
If you've made it this far, you're probably thinking about building an LLM/SLM evaluation framework at an enterprise level. Whether you realize it or someone has nudged you... without it, launching a GenAI solution is like sailing without a compass 😬—developers see the tech's brilliance, but business leaders need measurable success indicators to steer the ship.
What a Well-Designed Validation Framework Will Bring to Your Organization
Clarity and Transparency: From development to the boardroom, everyone will clearly understand the metrics that define
qualityfor a particular GenAI application. This ensures the model's performance isn’t a black box but a well-understood system where each metric tells part of the story.Alignment with Business Goals: Business leaders will see how technical metrics translate into business value. An effective framework bridges this gap, showing how improvements in accuracy, relevance, or ethical standards directly impact customer satisfaction, operational efficiency, and compliance.
Building Trust: Trust is essential for getting GenAI solutions into production. A transparent evaluation framework builds trust by showing that the model has been thoroughly tested and meets high standards of performance and responsibility (RAI).
Continuous Improvement: The framework not only measures current performance but also highlights areas for improvement. This iterative approach ensures the GenAI solution evolves to meet changing needs and challenges, maintaining its relevance and effectiveness over time.
📈 Building Out Your Evaluation Strategy
It's tempting to dive into the latest tools and research without a solid plan, but I've seen many enterprises rush into open-source solutions without considering long-term alignment with their strategy. The reality is: if a tool meets only 50% of your needs, you'll have to build the rest. Don't forget to factor in the total cost of ownership (TCO)—development, maintenance, and scaling across your organization.
Understand What to Measure
Responsible AI (RAI) Practices
RAI is essential in LLM evaluation to ensure ethical use and minimize risks. Focus on:
Transparency: Clearly communicate data sources, model limitations, and decision-making processes.
Accountability: Maintain thorough documentation and audits.
Continuous Monitoring: Regularly update models to reduce biases and improve fairness.
Tailor Metrics to Use Cases
Different applications need specific evaluation criteria:
Summarization: Coherence, relevance, conciseness.
Q&A: Accuracy, precision, recall.
NER: Precision, recall, F1-score.
Customization matters. For example, in translation tasks, your team might create unique metrics to provide a domain-specific measurement. This helps your company understand the ROI and how well those translations are performing.
Intent Accuracy: Preserves the original meaning.
Contextual Relevance: Ensures translations fit the context.
Cultural Sensitivity: Evaluates cultural appropriateness for the target audience.
Understanding How to Measure Needs
When developing and evaluating models, it's important to recognize the distinct roles of offline and online evaluations, and how each serves its own purpose.
Take Google Translate, for instance. In the early days, its offline evaluations focused on accuracy and language rules using large, predefined datasets. But once real users started interacting with it, the tool needed continuous adjustments to account for cultural nuances and context that the offline tests had missed. Over time, online evaluations, with real user feedback, helped refine its accuracy and relevance.
Offline Evaluation is key during the development phase. It involves testing models with specific datasets, allowing for controlled and repeatable assessments. This method focuses on things like factuality, logic, and expected behaviors, letting developers fine-tune their models without the unpredictability of live data.
Online Evaluation, however, comes into play once the model is live, assessing performance in real-world conditions. It captures real user interactions, revealing complexities that offline tests may miss. A model that excels in offline evaluation might still stumble when faced with unexpected queries or changing trends in the real world.
For GenAI enterprises—especially those building chatbots—a combination of both methods is essential. Offline evaluation sets a solid foundation during the early stages, while online evaluation becomes critical once the chatbot is in production, helping you measure real-world impact and continuously improve performance.
Choosing the Right Platform and Tools for Your Enterprise
At this point, it’s clear that you need a customizable tool or platform that fits your specific needs—one that can seamlessly evaluate Responsible AI (RAI) principles while managing both offline and online evaluations.
As a technical lead, executive, or decision-maker, you often find yourself balancing what you, as a developer, prefer versus what the company needs. Let me help simplify that decision. I strongly advocate for an open-source approach—leveraging a toolkit with a robust Python SDK, enterprise-grade security, scalability, and seamless cloud integration. This combination doesn’t just meet immediate needs but future-proofs your platform, transforming it from functional to truly exceptional.
I want to emphasize cloud integration here. The goal isn’t to build something as complex as Azure, with large teams continuously adding features that don’t align with your roadmap. Instead, the focus should be on finding a technology with strong community support and seamless integration with your chosen cloud provider—Azure, in this case—so you can scale efficiently without unnecessary overhead.
In this article, we are going to explore why PromptFlow and Azure AI Foundry are my choices—they not only meet our current needs but also align perfectly with the future of our industry, backed by Microsoft's robust support. By leveraging PromptFlow as a tool and Azure AI Foundry as the platform, you can create a comprehensive and scalable enterprise LLM evaluation system.
Introducing Prompt Flow and Azure AI Foundry
Why Prompt Flow?
When you start using PromptFlow, you'll notice that its simplicity is one of its best features. The python SDK makes the whole development process easier, allowing you to prototype, experiment, iterate, and deploy your GenAI flows quickly. That's why it's the perfect fit for automating, running, and scaling evaluation metrics on a large scale.
Flexibility in Tracing:
Adaptability and Control: You can integrate your own applications into Prompt Flow for batch testing and evaluation. For example, I used it to test a new recommendation algorithm across multiple datasets.
Advanced Tracing Capabilities: You can run local evaluations and log results directly to the cloud. I found it handy to trace runs in Azure AI Foundry and even in local environments.
Efficient Tracking: Cloud-based sessions make tracking and examining details easy. I often use the trace view to dive deep into performance metrics.
Centralized Evaluation History:
Central Repository: Store and track all your historical evaluations. I keep all my test data here for easy access.
Enhanced Analysis: Visualize evaluation results and compare different test cases. This feature helped me identify the best-performing models quickly.
Asset Reutilization: Reuse previous evaluation assets to streamline workflows. I often reuse my old test setups to save time on new projects.
Streamlined Deployment:
- Supports LLMOps Practices: After testing and optimizing, deploy your evaluation flows to Azure AI Foundry. This ensures secure and scalable operations. I use it to maintain a smooth CI/CD pipeline for my projects.
Why Azure AI Foundry?
Collaboration: We can work together on projects, share our knowledge, and keep track of versions. This is a game-changer for teamwork.
All-in-One Platform: It lets us streamline everything from development and evaluation to deployment and monitoring.
Scalable Solutions: With Azure AI Foundry, we get secure, scalable, and reliable solutions for our development needs. It's the backbone of our projects.
Comprehensive Monitoring: Azure AI Foundry offers post-deployment monitoring, providing trace data for each request, aggregated metrics, and user feedback for further optimization. This is crucial for maintaining high performance.
Automatic Monitoring: Automatic trace monitoring provides detailed analytical information for each request, ensuring continuous improvement. It's like having an extra pair of eyes on your project.
✨ Making It Real: Building Our Validation Framework
Alright, we’ve chosen the tool and platform, identified what we want to measure, and figured out how to do it. Now, it’s time to put everything into action.
Here's what we are going to do:
Run Our First Prototype Evaluation
Evaluating the ⚙️ Retrieval System/QA: Assess the effectiveness of the LLM-based system as a whole. This includes testing its ability to understand context and achieve accuracy within your specific domain.
🛡️ Evaluating Responsible AI (RAI): Ensure the model aligns with Responsible AI principles by evaluating ethical considerations, fairness, and transparency. This step is crucial to meeting responsible AI standards.
Customize the Validation Framework to Fit Your Needs
Build our ground truth dataset
Combine built-in PromptFlow validation with your own code (metrics)
So, let’s get started and build something great! Access all the code here
Run Our First Prototype Evaluation
Install the libraries and set up environment variables
# Install necessary libraries
# !pip install promptflow-azure
# !pip install promptflow-evals
# Importing necessary libraries from PromptFlow for evaluation
from promptflow.evals.evaluate import evaluate
from promptflow.core import AzureOpenAIModelConfiguration
from promptflow.evals.evaluators import QAEvaluator, ContentSafetyEvaluator
import os
# Initialize the Azure OpenAI Model Configuration
# This configuration sets up the connection to the Azure OpenAI service using the provided credentials and deployment information.
model_config = AzureOpenAIModelConfiguration(
azure_endpoint=azure_endpoint or os.environ.get("AZURE_OPENAI_ENDPOINT"),
api_key=api_key or os.environ.get("OPENAI_API_KEY"),
azure_deployment=azure_deployment or os.environ.get("AZURE_AOAI_COMPLETION_MODEL_DEPLOYMENT_ID"),
api_version=api_version or os.environ.get("DEPLOYMENT_VERSION"),
)
Understanding Built-in Promptflow Evaluations
The PromptFlow Evaluation Framework comes with a suite of built-in tools to check how well language models are doing in different situations. These evaluations are designed at everything from the quality of the content created to its safety and suitability.
Each evaluator is meticulously designed to address specific technical scenarios and requirements. For instance, the RelevanceEvaluator requires a question, answer, and context to determine how relevant the given answer is to the question within the specified context. This evaluator is crucial for applications like virtual assistants or customer support chatbots, where the relevance of responses is vital for maintaining user satisfaction.
| Category | Evaluator Class | Required Data Fields | Example | Purpose and Applications |
| Performance and Quality | GroundednessEvaluator | answer, context | {"answer": "Paris.", "context": "France is a country in Europe. Its capital is Paris."} | Measures how well the answer is grounded in the provided context. Useful for fact-checking applications. |
| RelevanceEvaluator | question, answer, context | {"question": "What is the capital of France?", "answer": "Paris.", "context": "France is a country in Europe. Its capital is Paris."} | Assesses the relevance of the answer to the given question and context. Ideal for QA systems. | |
| CoherenceEvaluator | question, answer | {"question": "What is the capital of France?", "answer": "Paris is the capital of France."} | Evaluates the logical flow and coherence of the conversation. Useful for dialogue systems. | |
| FluencyEvaluator | question, answer | {"question": "What is the capital of France?", "answer": "Paris is the capital of France."} | Checks the linguistic fluency and readability of the answer. Important for content generation. | |
| SimilarityEvaluator | question, answer, ground_truth | {"question": "What is the capital of France?", "answer": "Paris is the capital of France.", "ground_truth": "The capital of France is Paris."} | Compares the similarity between the generated answer and a ground truth answer. Useful for automated grading systems. | |
| F1ScoreEvaluator | answer, ground_truth | {"answer": "Paris is the capital of France.", "ground_truth": "The capital of France is Paris."} | Calculates the F1 score based on the overlap between the generated answer and the ground truth. Useful for evaluating model precision and recall. | |
| Risk and Safety | ViolenceEvaluator | question, answer | {"question": "What is the capital of France?", "answer": "Paris."} | Detects violent content in the model's responses. Essential for content moderation. |
| SexualEvaluator | question, answer | {"question": "What is the capital of France?", "answer": "Paris."} | Identifies sexual content in responses. Critical for maintaining content appropriateness. | |
| SelfHarmEvaluator | question, answer | {"question": "What is the capital of France?", "answer": "Paris."} | Screens for self-harm related content in answers. Important for user safety. | |
| HateUnfairnessEvaluator | question, answer | {"question": "What is the capital of France?", "answer": "Paris."} | Detects hate speech and unfairness in content. Vital for ethical AI applications. | |
| Composite | QAEvaluator | question, answer, context, ground_truth | {"question": "What is the capital of France?", "answer": "Paris is the capital of France.", "context": "France is a country in Europe. Its capital is Paris.", "ground_truth": "The capital of France is Paris."} | Combines quality evaluators for QA pairs. Useful for comprehensive QA system evaluation. |
| ChatEvaluator | question, answer, context, ground_truth | {"question": "What is the capital of France?", "answer": "Paris is the capital of France.", "context": "France is a country in Europe. Its capital is Paris.", "ground_truth": "The capital of France is Paris."} | Integrates quality evaluators for chat messages. Ideal for evaluating chatbots. | |
| ContentSafetyEvaluator | question, answer, context, ground_truth | {"question": "What is the capital of France?", "answer": "Paris is the capital of France.", "context": "France is a country in Europe. Its capital is Paris.", "ground_truth": "The capital of France is Paris."} | Combines safety evaluators for QA pairs. Essential for ensuring content safety in QA systems. | |
| ContentSafetyChatEvaluator | question, answer, context, ground_truth | {"question": "What is the capital of France?", "answer": "Paris is the capital of France.", "context": "France is a country in Europe. Its capital is Paris.", "ground_truth": "The capital of France is Paris."} | Merges safety evaluators for chat messages. Crucial for safe interactions in chat applications. |
How do they work? These evaluations are GPT-based, operating under the concept of "LLM evaluates LLM." The Microsoft PromptFlow team has refined the prompts for each evaluation through extensive prompt engineering iterations and packaged them into an SDK that's easy to use. This setup supports bulk processing and parallelization, making it highly efficient.
Evaluating the ⚙️ Retrieval System/QA
QAEvaluator runs evaluations in bulk and compares results against the ground truth:
📊 What metrics are we evaluating?
F1 Score: Balance between precision and recall (0-1).
Groundedness: Factual accuracy (0-5).
Relevance: Content relevance (0-5).
Coherence: Logical flow (0-5).
Fluency: Readability (0-5).
Similarity: Match to expected response (0-5).
# Import necessary modules
from promptflow.evals.evaluate import evaluate
from promptflow.core import AzureOpenAIModelConfiguration
from promptflow.evals.evaluators import QAEvaluator
# Initialize the QA evaluator with the model configuration
qa_evaluator = QAEvaluator(model_config=model_config, parallel=True)
# Optional: Define the Azure AI project configuration
azure_ai_project = {
"subscription_id": subscription_id,
"resource_group_name": resource_group_name,
"project_name": project_name
}
# Perform the evaluation using the QA evaluator
result = evaluate(
data=temp_file.name,
evaluators={
"qa_evaluator": qa_evaluator,
},
evaluator_config={
"qa_evaluator": {
"question": "${data.question}",
"answer": "${data.answer}",
"context": "${data.context}",
"ground_truth": "${data.ground_truth}",
},
},
azure_ai_project=azure_ai_project
)
QA Evaluator Initialization: The
QAEvaluatoris initialized with themodel_config, enabling parallel processing if necessary.Optional Azure AI Project: If you have specific Azure AI project details, you can include them in the
azure_ai_projectdictionary. Otherwise, this part can be omitted or set toNone.Evaluation Execution: The
evaluatefunction is used to run the QA evaluator on the provided data. Theevaluator_configdictionary defines how the data fields map to the evaluation criteria.
Results:
{'f1_score': 0.9786, 'gpt_coherence': 5.0, 'gpt_fluency': 5.0, 'gpt_groundedness': 3.52, 'gpt_relevance': 3.64, 'gpt_similarity': 5.0}
🛡️ Evaluating Responsible AI (RAI):
ContentSafetyEvaluator runs evaluations in bulk and compares results against the ground truth:
📊 What metrics are we evaluating?
Self-Harm Defect Rate: Frequency of self-harm content in generated text. (0-1)
Sexual Defect Rate: Occurrence of inappropriate sexual content. (0-1)
Hate Unfairness Defect Rate: Presence of hate speech or unfair content. (0-1)
Violence Defect Rate: Level of violent content in the outputs. (0-1)
# Import necessary modules
from promptflow.evals.evaluate import evaluate
from promptflow.evals.evaluators import ContentSafetyEvaluator
# Initialize the RAI evaluator with the project scope and parallel processing enabled
rai_evaluator = ContentSafetyEvaluator(project_scope=azure_ai_project, parallel=True)
# Optional: Define the Azure AI project configuration
azure_ai_project = {
"subscription_id": subscription_id,
"resource_group_name": resource_group_name,
"project_name": project_name
}
# Perform the evaluation using the ContentSafetyEvaluator
result = evaluate(
data=temp_file.name,
evaluators={
"content_safety_evaluator": rai_evaluator,
},
evaluator_config={
"content_safety_evaluator": {
"question": "${data.question}",
"answer": "${data.answer}",
},
},
azure_ai_project=azure_ai_project
)
# Display the results
print(result)
ContentSafetyEvaluator needs the azure_ai_project for project scope, enabling parallel processing if needed.Evaluation Execution: The evaluate function runs the ContentSafetyEvaluator on the provided data. The evaluator_config dictionary defines how the data fields map to the evaluation criteria.
Results:
{'self_harm_defect_rate': 0.0, 'sexual_defect_rate': 0.0, 'hate_unfairness_defect_rate': 0.01, 'violence_defect_rate': 0.0}
Customize the Validation Framework to Fit Your Needs
Building Your Golden Dataset
Your golden dataset is the ultimate reference for your models, providing a high-quality, annotated collection of data that acts as the ground truth for evaluating model outputs.
Benchmarking: It sets the standard for evaluating model performance, ensuring consistency and accuracy.
Integrated Evaluation: In PromptFlow, it plays a central role in automating repeatable evaluations, helping refine and improve models.
Best Practices for Building a Golden Dataset:
Diverse and Representative: Ensure your dataset covers a wide range of scenarios your model may face. For example, in a customer support chatbot, include simple queries and complex problem-solving tasks.
High-Quality Annotations: Accurate labeling is critical. Each entry should be precisely annotated with correct answers and relevant context, regularly reviewed to maintain quality.
Continuous Updates: Keep your dataset up to date with new data reflecting user behavior, trends, or changes in your model to ensure evaluations stay relevant.
Data Enrichment Strategies:
Paraphrasing: Use tools like GPT-4 to rephrase existing queries, offering more variety and helping the model handle different interpretations.
Synthetic Data: Generate synthetic data with LLMs to fill gaps and ensure comprehensive coverage of potential user queries.
Linking Dataset to Evaluations in PromptFlow
In PromptFlow, the golden dataset becomes a crucial component in validating your model’s performance, especially when using tools like the RelevanceEvaluator. This evaluator requires specific data fields such as question, answer, and context to effectively measure how well the model responds in real-world scenarios.
For instance, in a QA system, you might include the following data:
Question: "What is the capital of France?"
Expected Answer: "Paris"
Context: Additional information about France, such as geographic or historical details, ensuring the model’s response aligns with the full scope of the question.
When preparing your dataset for PromptFlow, consider the data structure needed to fit the prompt model's expectations:
Question Field: This field represents the user query. It should be clear, varied, and reflective of real-world usage, including possible phrasing variations like "Which city is the capital of France?" or "What's France's capital?"
Answer Field: This field holds the correct or expected response. It must be accurate, concise, and contextually relevant to the question. In our example, the answer would be "Paris."
Context Field: This is the background or additional information supporting the answer. In PromptFlow, context can enhance the model’s relevance score by providing crucial information the model needs to generate a more precise and complete response. For example, your context might include details like "Paris has been the capital of France since the 10th century."
How the Data Structure Works in PromptFlow:
Your dataset should be formatted to match the prompt model’s structure
{
"dataset": [
{
"question": "What is the capital of France?",
"answer": "Paris",
"context": "Paris has been the capital of France since the 10th century and is known for its cultural and historical significance."
},
{
"question": "Which city is the capital of Germany?",
"answer": "Berlin",
"context": "Berlin, the capital of Germany, is known for its history, especially during the Cold War era."
}
]
}
How to Integrate Custom Evaluation with PromptFlow
Integrating custom evaluation methods with PromptFlow enhances the precision and depth of your AI systems performance assessment. Here’s a step-by-step guide on how to combine your custom SemanticSimilarityEvaluator with PromptFlow’s built-in evaluation tools.
Step 1: Define Your Custom Evaluator
We selected bert-base-uncased as the pre-trained model for our custom evaluator because BERT (Bidirectional Encoder Representations from Transformers) excels in understanding the context of words in a sentence. BERT’s bidirectional nature allows it to consider both previous and next words in a sequence, making it particularly powerful for capturing semantic nuances, which is crucial for evaluating the similarity between responses and ground truth in natural language processing tasks
Here’s how you define the custom SemanticSimilarityEvaluator:
from typing import TypedDict
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
# Define a dictionary to hold similarity scores
class SimilarityScore(TypedDict):
semantic_similarity: float
# Custom evaluator class
class SemanticSimilarityEvaluator:
def __init__(self, model_name: str = 'bert-base-uncased'):
"""
Initialize the evaluator with a pre-trained model for generating embeddings.
:param model_name: Name of the pre-trained model from Hugging Face Transformers.
"""
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
def __call__(self, *, response: str, ground_truth: str) -> SimilarityScore:
"""
Calculate the semantic similarity between the AI's response and the ground truth.
:param response: The response generated by the AI bot.
:param ground_truth: The correct answer for comparison.
:return: A dictionary containing the semantic similarity score.
"""
response_embedding = self._get_embedding(response)
ground_truth_embedding = self._get_embedding(ground_truth)
similarity = self._calculate_cosine_similarity(response_embedding, ground_truth_embedding)
return {"semantic_similarity": similarity}
def _get_embedding(self, text: str) -> torch.Tensor:
"""
Convert the text into a numerical embedding using BERT.
:param text: The text to convert.
:return: The embedding as a torch tensor.
"""
inputs = self.tokenizer(text, return_tensors='pt', truncation=True, padding=True)
outputs = self.model(**inputs)
return outputs.last_hidden_state.mean(dim=1)
def _calculate_cosine_similarity(self, tensor1: torch.Tensor, tensor2: torch.Tensor) -> float:
"""
Calculate the cosine similarity between two tensors.
:param tensor1: The embedding of the first text (AI response).
:param tensor2: The embedding of the second text (ground truth).
:return: The cosine similarity score, ranging from -1 (opposite) to 1 (identical).
"""
return F.cosine_similarity(tensor1, tensor2).item()
Step 2: Combine Custom and Built-in Evaluations
Once the custom evaluator is defined, you can integrate it into PromptFlow's evaluation process alongside built-in evaluators. Here’s how you can do it:
# built-in eval
qa_eval = F1ScoreEvaluator()
context_similarity = SimilarityEvaluator(model_config)
# custom eval
semantic_similarity_eval = SemanticSimilarityEvaluator(model_name='bert-base-uncased')
result = evaluate(
data=r"C:\path\to\your\data\evaluations\jsonl\F1ScoreEvaluator.jsonl",
evaluators={
"qa_eval": qa_eval,
"context_similarity": context_similarity,
"semantic_similarity": semantic_similarity_eval
},
evaluator_config={
"qa_eval": {
"answer": "${data.answer}",
"ground_truth": "${data.ground_truth}",
},
"context_similarity": {
"question": "${data.question}",
"answer": "${data.answer}",
"ground_truth": "${data.ground_truth}",
},
"semantic_similarity": {
"response": "${data.answer}",
"ground_truth": "${data.ground_truth}",
}
},
azure_ai_project=azure_ai_project
)
Step 3: Understand the Combined Results
'metrics': { 'qa_eval.f1_score': 0.7724547511300002, 'context_similarity.gpt_similarity': 2.5714285714285716, 'semantic_similarity.semantic_similarity': 0.9273403247166668 }
qa_eval.f1_score(0.77): Reflects the accuracy of the AI's response.context_similarity.gpt_similarity(2.57): Measures how well the response fits the context.semantic_similarity.semantic_similarity(0.93): Indicates a strong semantic match between the response and the ground truth.
Step 4: Monitor Runs in Azure AI Foundry
If you’ve added your Azure AI Foundry credentials, you can easily monitor your runs directly within the platform. This setup is ideal for tracking performance, ensuring reusability, and seamlessly sharing results with your team—all while adhering to your enterprise development environment standards. Each project and team can have a secure, isolated environment, ensuring that evaluations are both efficient and protected.
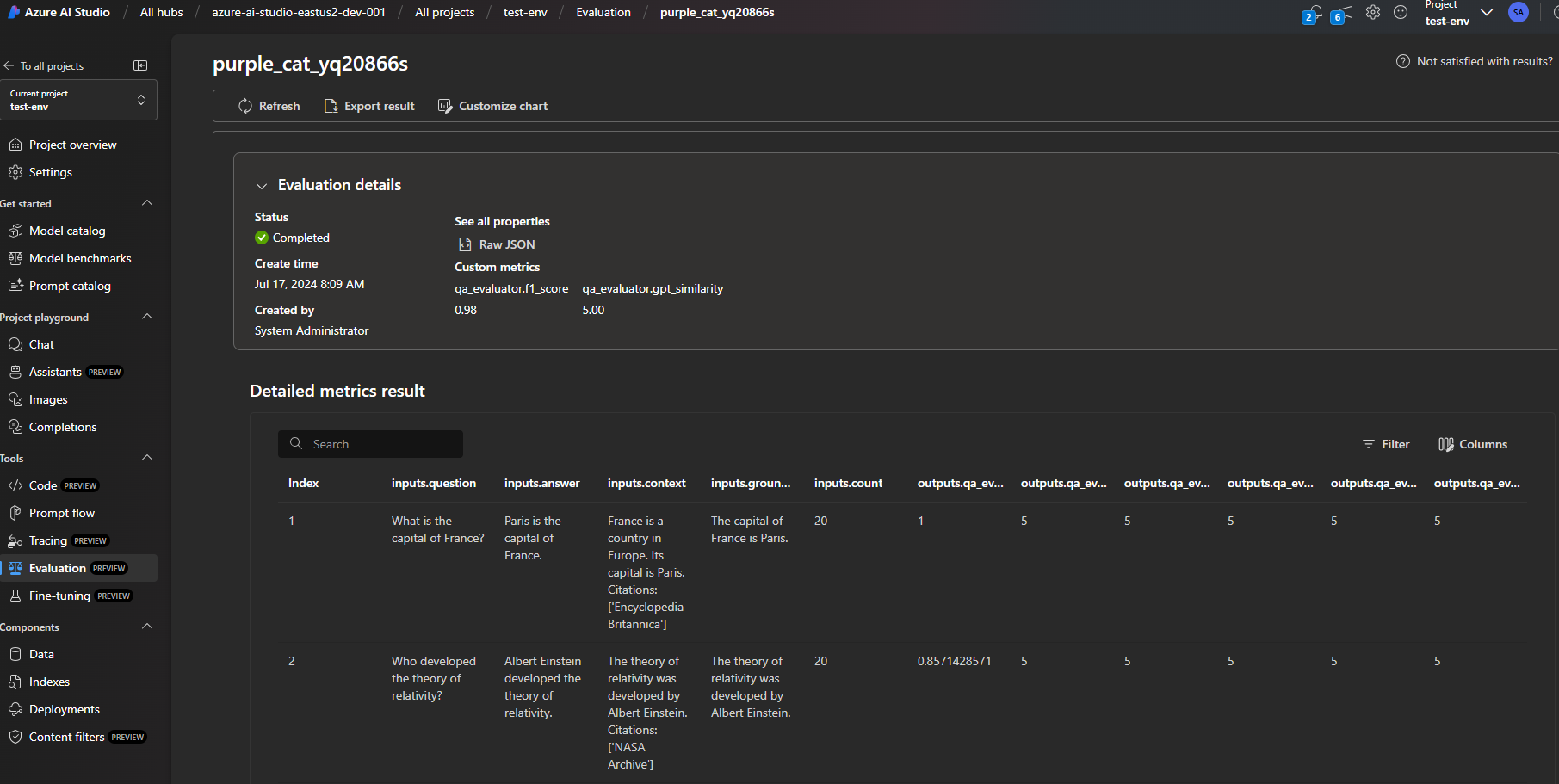
What We’ve Learned and How We’ve Done It
Navigating the complexities of evaluating and benchmarking GenAI applications can feel daunting, but with the right tools and framework, it becomes a manageable and rewarding process. This article has walked you through the essential steps to build a robust evaluation framework for your GenAI applications, integrating custom evaluation methods with built-in tools like PromptFlow and leveraging platforms like Azure AI Foundry.
Here’s what we’ve learned:
The Importance of Continuous Evaluation:
- In the ever-evolving world of GenAI, a one-time evaluation isn't enough. Continuous evaluation, coupled with tools that adapt to changing data and user behaviors, is key to maintaining the effectiveness and relevance of your AI models.
Customizing Evaluations to Fit Your Needs:
- We explored how to build and integrate custom evaluators, like the
SemanticSimilarityEvaluator, into PromptFlow. By doing so, you can tailor the evaluation process to meet the specific needs of your application, ensuring that your AI not only produces accurate results but also understands context and nuances.
- We explored how to build and integrate custom evaluators, like the
Using the Right Tools for the Job:
- Tools like PromptFlow and Azure AI Foundry were highlighted for their ability to streamline the evaluation process, from prototyping to deployment. These platforms offer the flexibility and scalability required to manage complex AI systems at an enterprise level.
The Power of a Well-Designed Evaluation Framework
A well-designed evaluation framework provides clarity and transparency, aligning technical performance with business objectives. It also allows you to measure how effectively your LLM applications perform across various dimensions, offering valuable insights for optimization and scaling.
By following the steps and best practices outlined in this article, you’re not just evaluating your AI models—you’re setting the foundation for a scalable, reliable, and ethically GenAI system.
Now, it’s time to take these insights and apply them to your own projects. Start experimenting, refine your evaluation strategies, and build something great! (Access all the code here) 🚀
Did you find it interesting? Subscribe to receive automatic alerts when I publish new articles and explore different series.
More quick how-to's in this series here: 📚🔧 Azure AI Practitioner: Tips and Hacks 💡
Explore my insights and key learnings on implementing Generative AI software systems in the world's largest enterprises. GenAI in Production 🧠
Join me to explore and analyze advancements in our industry shaping the future, from my personal corner and expertise in enterprise AI engineering. AI That Matters: My Take on New Developments 🌟
And... let's connect! We are one message away from learning from each other!
🔗 LinkedIn: Let’s get linked!
🧑🏻💻GitHub: See what I am building.
Subscribe to my newsletter
Read articles from Pablo Salvador Lopez directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pablo Salvador Lopez
Pablo Salvador Lopez
As a seasoned engineer with extensive experience in AI and machine learning, I possess a blend of skills in full-stack data science, machine learning, and software engineering, complemented by a solid foundation in mathematics. My expertise lies in designing, deploying, and monitoring GenAI & ML enterprise applications at scale, adhering to MLOps/LLMOps and best practices in software engineering. At Microsoft, as part of the AI Global Black Belt team, I empower the world's largest enterprises with cutting-edge AI and machine learning solutions. I love to write and share with the AI community in an open-source setting, believing that the best part of our work is accelerating the AI revolution and contributing to the democratization of knowledge. I'm here to contribute my two cents and share my insights on my AI journey in production environments at large scale. Thank you for reading!