Optimizing Workload Distribution in Microservice Architectures: A Comprehensive Guide to Load Balancers
 Nikhil Vibhani
Nikhil Vibhani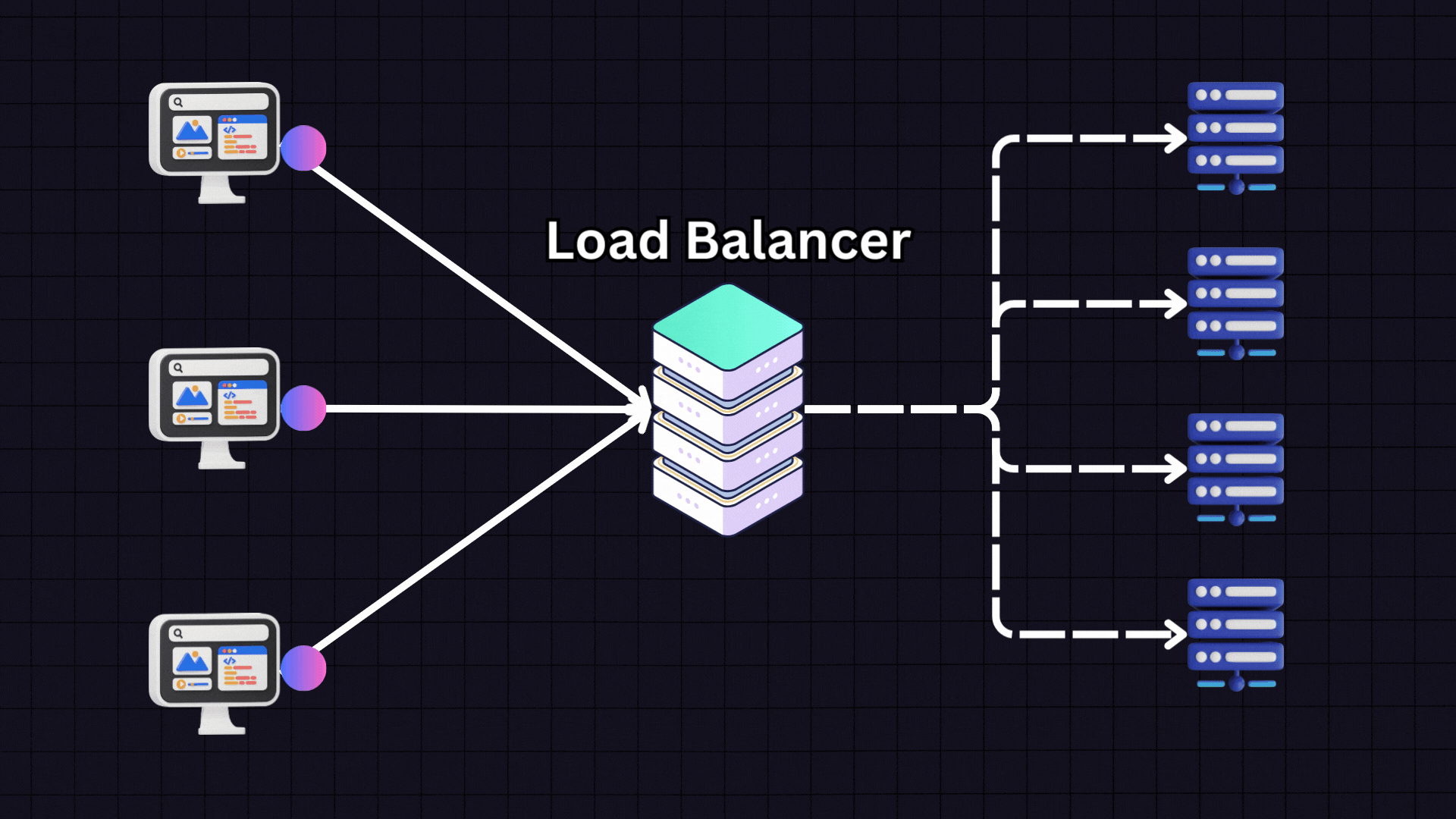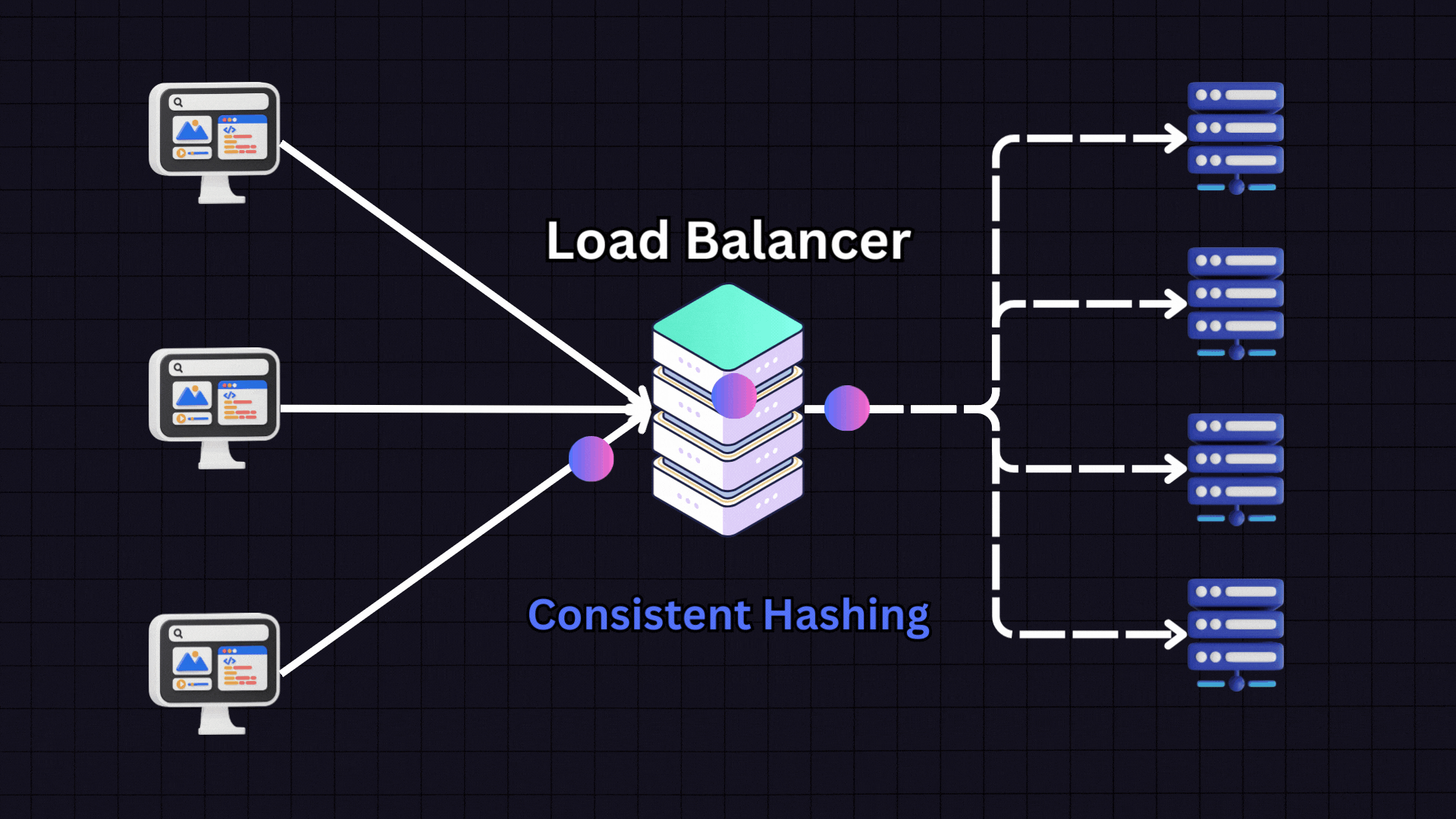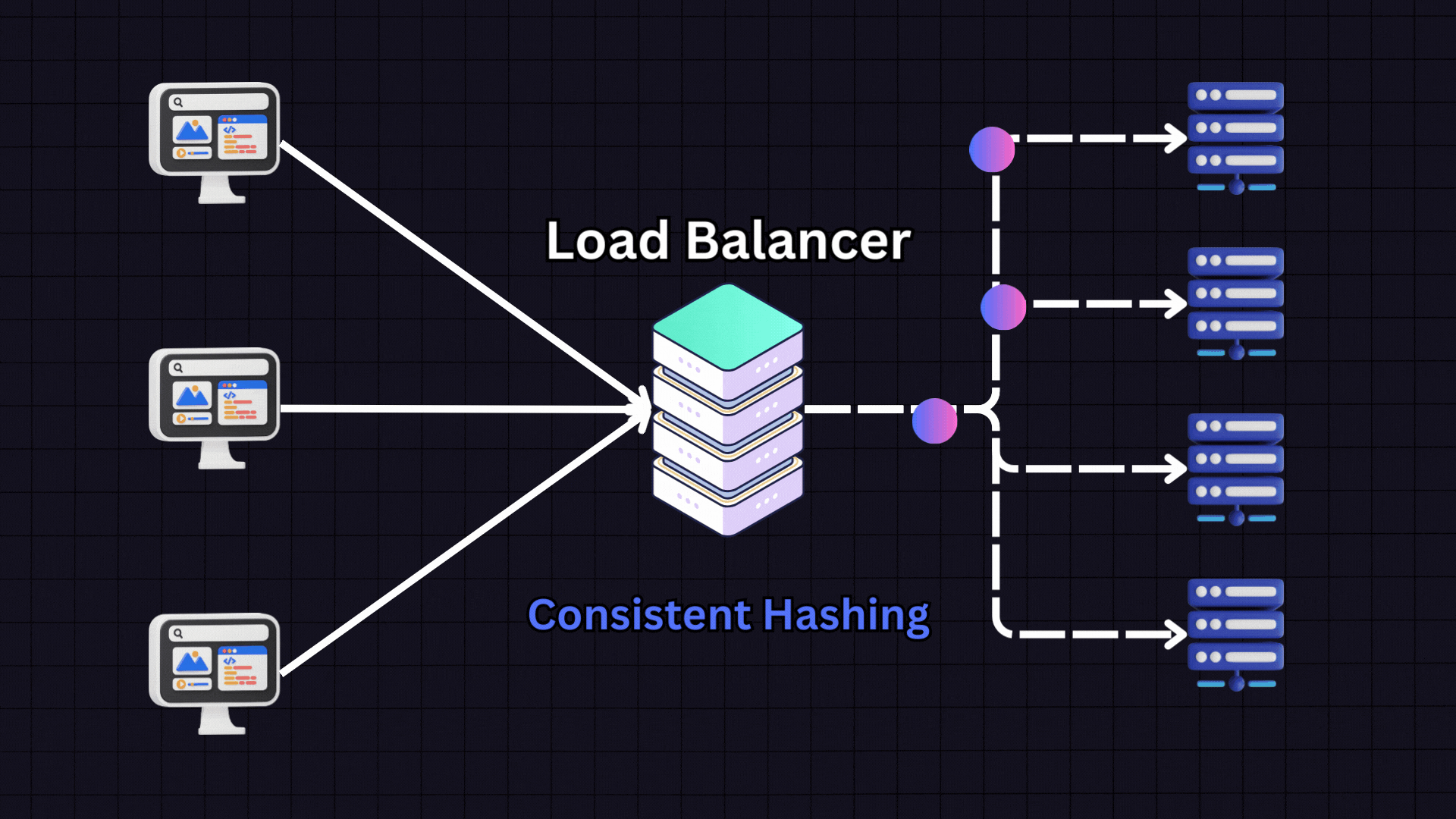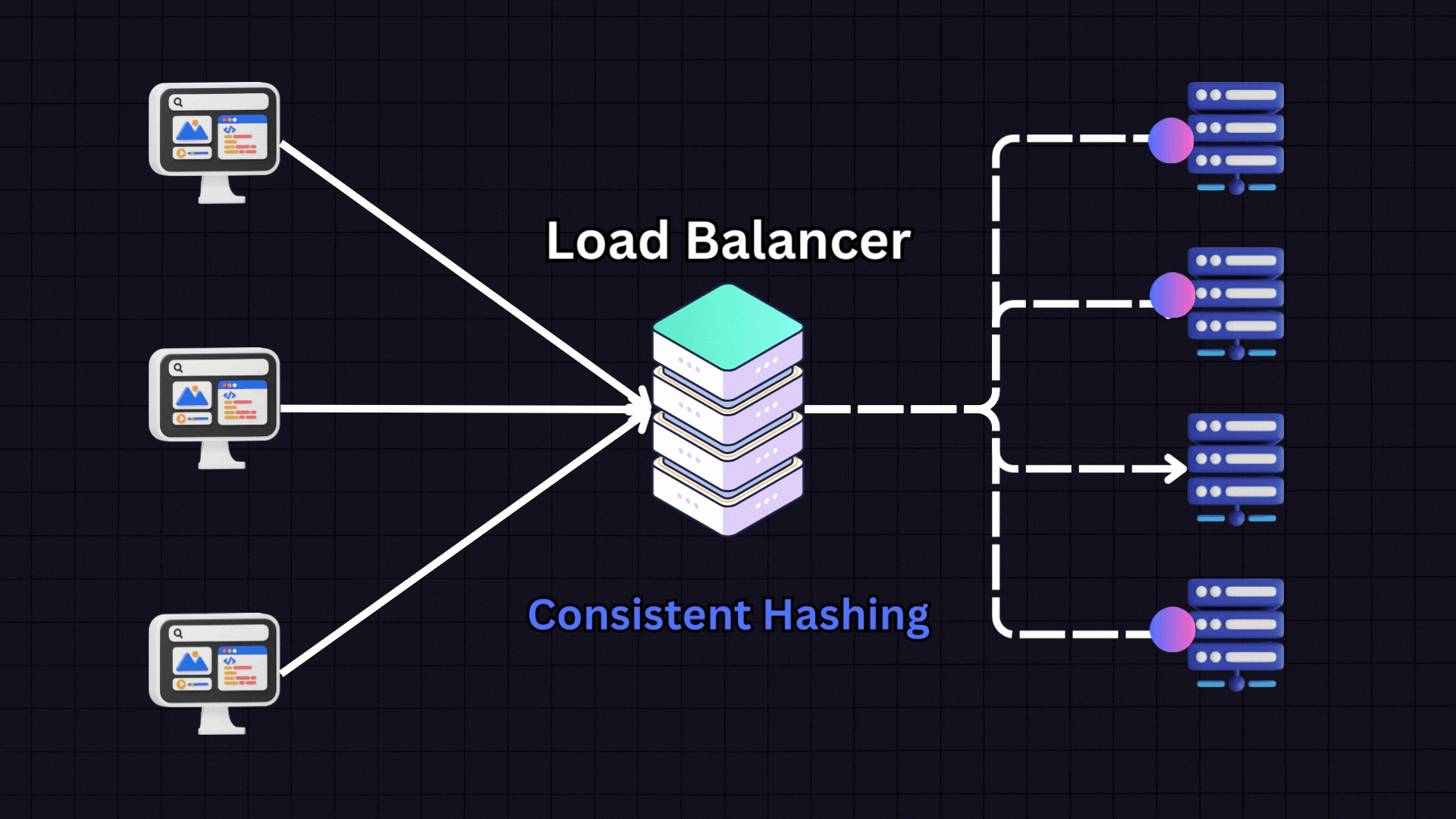
Introduction
In large-scale distributed applications, handling thousands of requests per second is common. Eventually, the need for horizontal scaling becomes clear: relying on a single machine to manage all incoming requests is no longer feasible. Horizontal scaling involves distributing the workload across multiple servers, ensuring that each server processes a portion of the total requests based on its capacity, performance, and other criteria.
Load balancing plays a crucial role in this setup by efficiently managing how requests are distributed across servers. In this article, we will explore various load-balancing strategies, examining their unique properties and applications. It’s important to note that there isn’t a one-size-fits-all solution; the optimal strategy depends on the specific needs and configurations of your system.
The Role of Load Balancers
Load balancers can operate at different levels within an application architecture, optimizing request routing across various components. For example, in a typical web application with a frontend, backend, and database layers, multiple load balancers may be used:
Between clients and frontend servers: To manage incoming user requests and distribute them among frontend servers.
Between frontend and backend servers: To balance the load of internal requests generated by the frontend.
Between backend servers and the database: To distribute queries and updates across database instances.
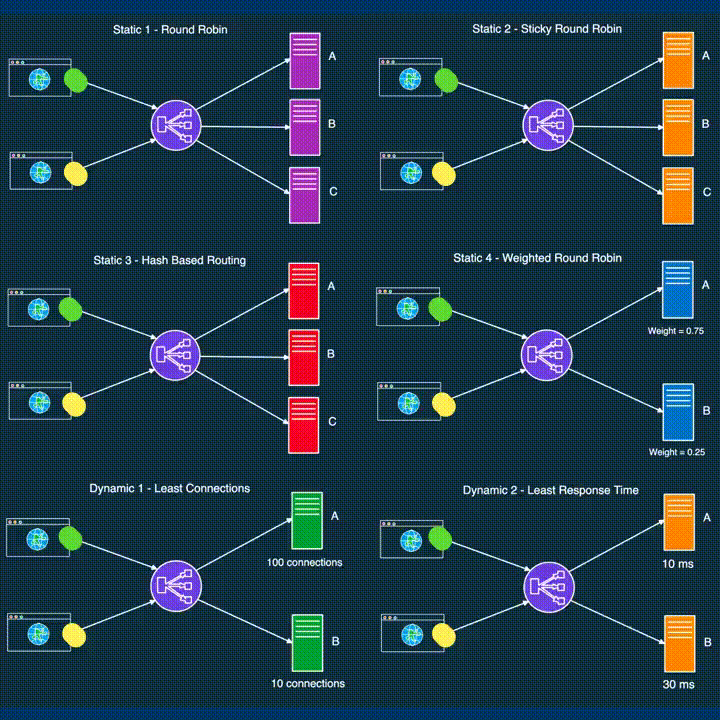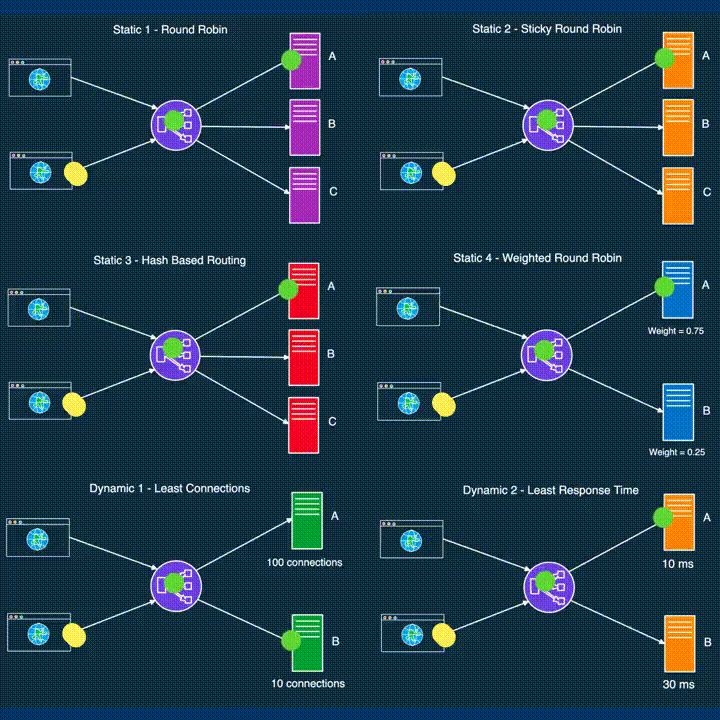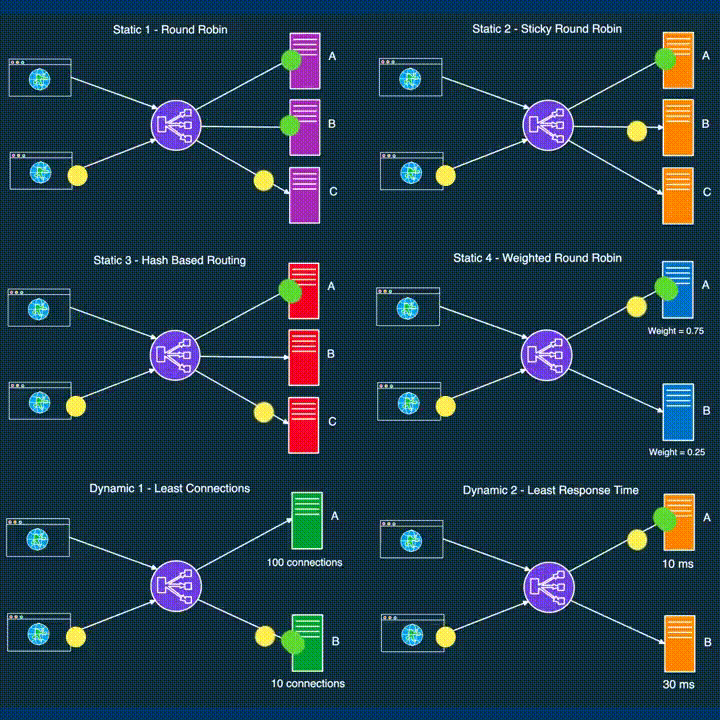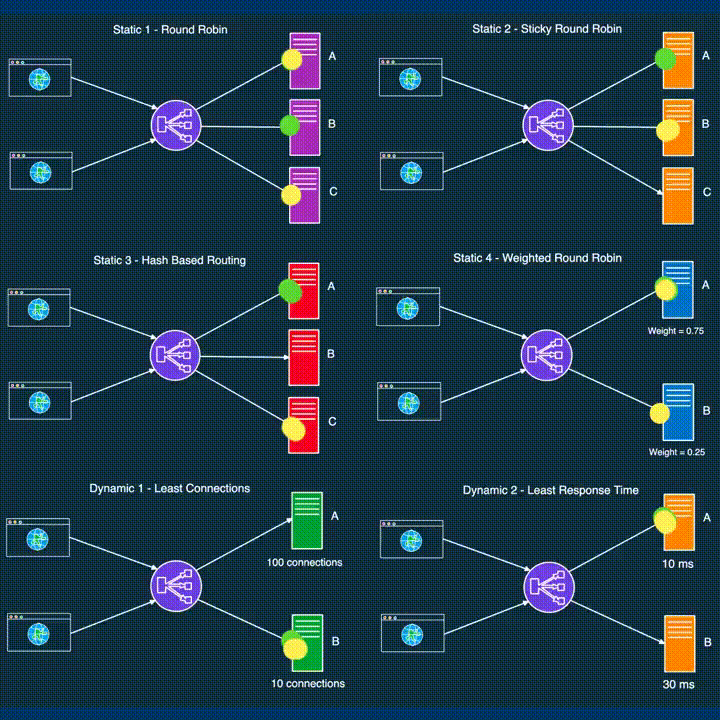
While load balancers function at different layers, the same balancing strategies can often be applied across these layers, adapting to the unique demands of each component.
Health Checks: Maintaining System Stability
In a multi-server environment, any server can become overloaded, lose network connectivity, or even fail completely. Regular health checks are essential to monitor the status of each server and ensure continuous operation. A monitoring service periodically sends test requests to all servers, evaluating their responses to determine if they are functioning correctly.
Key metrics typically monitored include response time and the number of active connections or tasks. If a server fails to respond within a specified time frame, the monitoring service triggers an alert or initiates a recovery procedure to restore the server's functionality as quickly as possible.
By analyzing these health check statistics, load balancers can dynamically adjust their algorithms to optimize request processing times, aligning with the principles of dynamic balancing algorithms discussed below.
Static vs. Dynamic Load Balancing Algorithms
Load balancing algorithms can be broadly classified into two categories: static and dynamic.
Static algorithms rely on predefined, unchanging parameters such as CPU capacity, memory limits, and connection timeouts. These algorithms are straightforward but less adaptable to rapid changes in server performance, making them ideal for environments where workloads are predictable and evenly distributed over time.
Dynamic algorithms adjust in real-time based on the current state of the system. By continuously monitoring server performance and load, these algorithms can redistribute tasks more efficiently, responding to changing conditions and ensuring balanced workloads. However, this adaptability requires additional computational resources and can impact overall system performance.
Common Load Balancing Strategies
Below are some of the most widely used load-balancing strategies, each with its variations and applications:
Random: This strategy assigns incoming requests to servers randomly. It's simple and effective when servers have similar performance characteristics and are not frequently overloaded.
Round Robin and Variants:
Round Robin: Requests are distributed sequentially across servers. Once the last server is reached, the cycle starts again with the first server.
Weighted Round Robin: Servers are assigned weights based on their capabilities, with requests distributed proportionally to these weights, ensuring servers with higher capacity handle more requests.
Sticky Round Robin: This variation maintains session affinity by routing subsequent requests from the same client to the same server, enhancing data locality and reducing latency.
Least Connections: Requests are sent to the server with the fewest active connections, making it a dynamic strategy well-suited for environments where server load can vary significantly.
Least Response Time: This strategy directs requests to the server with the lowest average response time, often used in combination with the least connections approach for even better load distribution.
IP Hashing: Utilizes the client's IP address to consistently route requests to the same server, enhancing data locality and reducing overhead from data retrieval across servers.
URL Hashing: Similar to IP hashing, but uses the request URL to determine server assignment. This approach is particularly effective for scenarios where requests need to be processed based on specific content categories or domains.
Combination Strategies: By integrating multiple load-balancing techniques, it's possible to create custom strategies that meet specific system requirements. For example, a voting mechanism can aggregate decisions from several algorithms to select the most suitable server for each request.
Conclusion
Load balancing is a critical aspect of system design, especially for high-traffic applications. This article has explored various static and dynamic algorithms, each offering different levels of complexity and trade-offs between performance and computational resources. The choice of a load-balancing algorithm should be guided by the specific needs of your system, considering factors like server capabilities, workload characteristics, and desired response times. By understanding and effectively implementing these strategies, software engineers can ensure optimal performance and reliability in distributed applications.
Subscribe to my newsletter
Read articles from Nikhil Vibhani directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by