Part 3: What Does It Mean to "Run" a Program?
 Greg Alt
Greg Alt
This is the third part of a series of blog posts taking a deep look into Ada Lovelace's 1843 computer program, starting with Part 1: First Look at the First Program
In my earlier posts, I gave a quick read through of Ada Lovelace’s program in her “Note G” and some background on the math it implements. I'd like to attempt to run it, but that immediately raises a question, what does it mean to “run” a program? In this post, I'll look at this question in preparation for my first run of Lovelace's program.
A Modern Program
Let's take a look at what it takes to run a somewhat modern example, a program to print out the factorial of a number given as a command line argument. The code is short but non-trivial, using a few different features of the C programming language. For our purposes, now, it's an example of source code that can be compiled and run on most modern computers.
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
int n = atoi(argv[1]);
int factorial = 1;
while(n > 1) {
factorial *= n;
n--;
}
printf("%d\n", factorial);
return 0;
}
What Does “Running” Mean Now?
Even for a simple program, the typical way to run this is actually a complex multi-step, automated process. People rarely now directly write in machine language or even directly load machine language into memory and start its execution. Running “natively” involves something like this:

Source code is generally written in a high level language, such as C in the example above.
A compiler parses and converts the source code to an intermediate representation and then to object code.
A linker then turns a collection of object code files into an executable, but that is a bit of a misnomer as it can’t be executed directly.
The executable is stored as bits on a storage device like a hard drive.
The executable must be loaded by an operating system’s loader, which generally does more than just copying bits into RAM. Data and code need to be copied into locations in memory, based on information in the executable and requirements of the operating system. This often involves some fixup of data and branch addresses to relocate the code.
Finally it’s possible to jump to the start of the executable code in memory and begin execution.
Interpreters Are Another Way
Another way to run a program, without compiling it first, is an interpreter. This can be a more straightforward way to run source code. At their most simple, an interpreter parses the source code similarly as a compiler might, but rather than generate object code, it immediately runs different routines in the interpreter based on the different statements in the source code. In this sense, the computer is running the interpreter program and it’s the interpreter that is acting like a virtual machine with possibly very different capabilities than the underlying hardware.
Due largely to speed concerns, modern interpreters are often complex hybrids, compiling source code just in time (JIT) either directly to native machine language or to a lower level byte code that can be run in a faster virtual machine.
The Process of “Running” in Three Eras
When looking at running software, it's useful to divide things into three broad eras.
- First was the 1840s, with Lovelace's program intended for Babbage's Analytical Engine.
- Next was the 1940s, as programmers ran programs for the very first time on the first operational electronic computers.
- And finally, the 1950s and 1960s marked the start of the modern era, with programmers building foundational software tools like operating systems, assemblers, and compilers.
The Modern Era: 1950s to Present
The modern way of running programs hasn’t fundamentally changed since the 1950s and 60s, when compilers and operating systems were first developed. Still in the modern era, but before compilers for high level languages like Fortran were developed, a similar process was used in the 1950s for much simpler assemblers. Assemblers turn assembly language programs into object code, much like a compiler.
Assembly language is a compromise between compiling source code written in a high-level language and writing directly in machine language. A human can read and write assembly language much more easily than they can directly write the machine language used in executable code, but the format is simple and highly restricted to make the work of an automated assembler much simpler than for a higher level compiler.
Earlier Eras: 1840s and 1940s
How did the earlier eras, in the 1840s and 1940s, compare with the modern era?
Looking at the different pieces, the degree of manual human involvement, and the tools used, we can see that the expected process for the Analytical Engine of the 1840s from writing low-level code to running it was very similar to the process actually used in the 1940s, both distinct from the much more automated, modern process from the 1950s to the present. This is a bit simplified, especially as multiple teams were rapidly evolving both the hardware and their processes in the late 1940s, but the rough comparison is striking:
| 1840s | 1940s | 1950s+ | |
| Write Assembly Code | Human w/ pencil | Human w/ pencil | Human w/ keyboard |
| Convert to Machine Code | Human w/ pencil | Human w/ pencil | Assembler |
| Store Machine Code | Human manually cut | Human w/ Keypunch | Assembler to file |
| Load Machine Code | Human operator | Human operator | OS loader |
| Execute Machine Code | Cards run directly | RAM operations run | RAM operations run |
“Running” in the 1950s+ Era, an Example
To give a another modern example, here’s the process I used to create and run an x86 DOS assembly language factorial program. This assembly language version is similar to the C version I gave above, though with more limited range of numbers.
The 1980s DOS tools are archaic now, but the process and types of tools would be somewhat familiar to programmers in both the 1950s and the 2020s. There are many DOS emulators available, but this web-based one is nice to play with.
- The programmer uses a keyboard to type the assembly language source code:
mov ch, 0
mov cl, [82]
sub cl, 30 ; cl = 1 digit num from command line
mov ax, 1
mul cx
loop 10c ; cx = factorial
mov bx, a
xor dx,dx
div bx
push dx
inc cx
test ax,ax
jnz 113 ; div by 10, push remainder, until quotient is 0
mov ah, 02
pop dx
add dl, 30
int 21
loop 11d ; pop from stack, add '0' and print
ret
- Using the built-in assembler in debug.com, this is automatically converted to hexadecimal machine code:
0100 B5 00 8A 0E 82 00 80 E9-30 B8 01 00 F7 E1 E2 FC
0110 BB 0A 00 31 D2 F7 F3 52-41 85 C0 75 F6 B4 02 5A
0120 80 C2 30 CD 21 E2 F6 C3-
- Which is then stored in an executable file on disk: factorial.com
-n factorial.com
-rcx 28
-w
Writing 0028 bytes
- And then it can be loaded by the operating system and machine code directly run in memory:
A>factorial 5
120
A>factorial 8
40320
Notice that the assembly language source code was typed on a standard keyboard in a highly-constrained, precise, and unforgiving language. After that, the bulk of the work to assemble, store, load, and run the program was all automated using software tools.
Words like “program” are a bit ambiguous as this is clearly one program. It also has four aspects of it that can each be considered programs. There's the assembly source code, the hexadecimal machine code displayed, the executable factorial.com file stored on disk, and the machine code after being loaded into memory. People might reasonably talk about “running” any one of them, even though the last one is the only one that directly “runs” in a strict sense.
“Running” Before Automated Tools, 1840s and 1940s
There were a brief few years, though, where programmers wrote code and ran it on actually existing computers but with no automated compilers or assemblers and only the most trivial of loaders. The bulk of the work to get the hand-written program running was manual human effort:
Programmers would write code either directly in machine language or in a more human readable low level assembly language, handwriting out a series of instructions on paper, called programme sheets or coding sheets.
This code would then be converted by a human to something the computer could more directly run, either by manually flipping switches on a console according to all of the binary data, or by punching cards or paper tape similarly.
A very simple loader program would copy the data from cards or console switches directly into memory.
In 1947, Kathleen Booth wrote a report on programming the A.R.C.1, an early computer built at Princeton. The report was typed for publication, but the code shown is still arranged in two dimensions to highlight conditionals, and characters not available on the keyboard are hand-drawn. Here is a short program to calculate a square root:
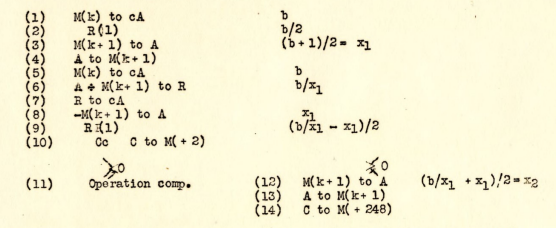
By the 1950s, first assembly code and then higher level source code in languages such as Fortran or COBOL were entered in machine-readable media such as punched cards, though with some manual effort. The programmers would carefully write out the code on a special grid coding sheet. A keypunch operator would then punch cards to match. This meant only characters available on the keypunch could be used. Assemblers or compilers would then automatically generate machine-readable machine code from that, also punched on cards.
Here's an example of a Fortran punched card, for the single line statement, "Z(1) = Y + W(1)":

(image info: https://commons.wikimedia.org/wiki/File:FortranCardPROJ039.agr.jpg )
Syntax Errors and Language Precision
One interesting effect of this transition was the hard requirement of precisely specified programming languages with restricted notation able to be entered with a standard keyboard. Rich mathematical notation and programs as two dimensional diagrams with lines and arrows became impossible, because the first assemblers and compilers weren’t very smart. The tiniest typo or omission would generate a syntax error, as you were no longer relying on a human understanding the intent.
Before automated assemblers and compilers, programmers would try to be as precise and accurate as possible, but trivial syntax errors would not have shut down the conversion process if intent was clear. Even today, with smarter compilers, it's common to forget a semicolon in C and have a build fail with a syntax error telling you exactly where to put the semicolon.
A human, especially the programmer themselves, wouldn’t need to halt the process if they could work out the intent. In the 1940s, after several iterations of the process of writing and running programs, programmers saw the importance of removing all ambiguity and thoroughly, manually checking code before attempting a run. That didn’t catch all bugs, of course, but experience taught them the importance of eliminating bugs as early in the process as possible.
The Table Language of Lovelace’s Program
With a better understanding of what it means to "run" a program across the different eras, let's turn back to Ada Lovelace’s program to compute Bernoulli numbers. The source code language was a table, first hand drawn and then typeset for publication. Bold horizontal lines between rows had semantic meaning, as did the English text for the loop. Variables had both subscripts and superscripts and two dimensional mathematical notation was used. All of this would have been impossible in rigid keyboard-based programming languages from the late 20th century.
But the expectation for running code in the 1840s was similar as in the 1940s. It’s not clear if Babbage and Lovelace envisioned an intermediate handwritten machine language explicitly specifying how all of the cards would be punched. That could be used to trivially guide manual punching of cards. Alternatively, humans might have been expected to do the conversion from table to cards directly in their head. Either way, the important thing for the conversion would have been a clear understanding by a human of the intent of each operation.
Once the cards were created, they could be loaded physically onto the analytical engine. Then execution could be started by stoking the fire in the boiler and an operator pulling whatever levers were required to set it in motion.
All of this background leads to the next question: How am I going to run this program?
In my next blog post, I'll answer that question with my plan for running Lovelace's program, and I'll take a stab at a first run and see how it goes.
- Booth, Andrew D; Britten, Kathleen HV (1947). Coding for A.R.C. Institute for Advanced Study, Princeton. In this squareroot code, (10) checks if the calculation is done. If not, (12)-(13) prepares for the next iteration and (14) jumps back in a loop. Note that adding +248 is the equivalent of subtracting 8 given the instruction address space allows 256 instructions.
Subscribe to my newsletter
Read articles from Greg Alt directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by