Does Size Matter? What else is important in choosing a Snowflake Warehouse?
 John Ryan
John Ryan
Having worked with over 50 Snowflake customers globally, I'm frequently asked the question:
"What warehouse size do I need?"
The answer (familiar to any experienced IT specialist), is..."It depends".
In this article, I'll discuss warehouse size and why although important, it's often a distraction from the real challenge - delivering excellent throughput, performance and value for money.
TL;DR Take-Aways
Size Isn't everything: Warehouse Size is not that important. Get over it.
Don't Scale Up: Although remarkably easy, it's a great way to burn through cash (and eventually lose your job).
Warehouse Count Matters: If you have more than 20 warehouses - you're probably wasting hundreds of thousands of dollars.
Never give a user what they want: You need to find out what they need!
What Problem(s) are we trying to Solve?
While working for a London based investment bank, I spent a year migrating an Oracle 11g data warehouse to a bigger machine having already spent a eighteen months tuning the existing system to improve query performance.
We'd cut hours off the batch ELT execution time, but we still struggled with end-user query performance. The diagram below illustrates the challenge we faced.

Our challenge was we had a hugely over-complex ELT process loading and transforming millions of trades every three hours, but during busy periods it took four hours to complete - effectively running continuously.
On the other hand, we had hundreds of frustrated traders and data analysts needing sub-second query response times. The diagram below illustrates how this played out, with end-users (in blue) fighting for machine resources with the batch ETL system (in red).
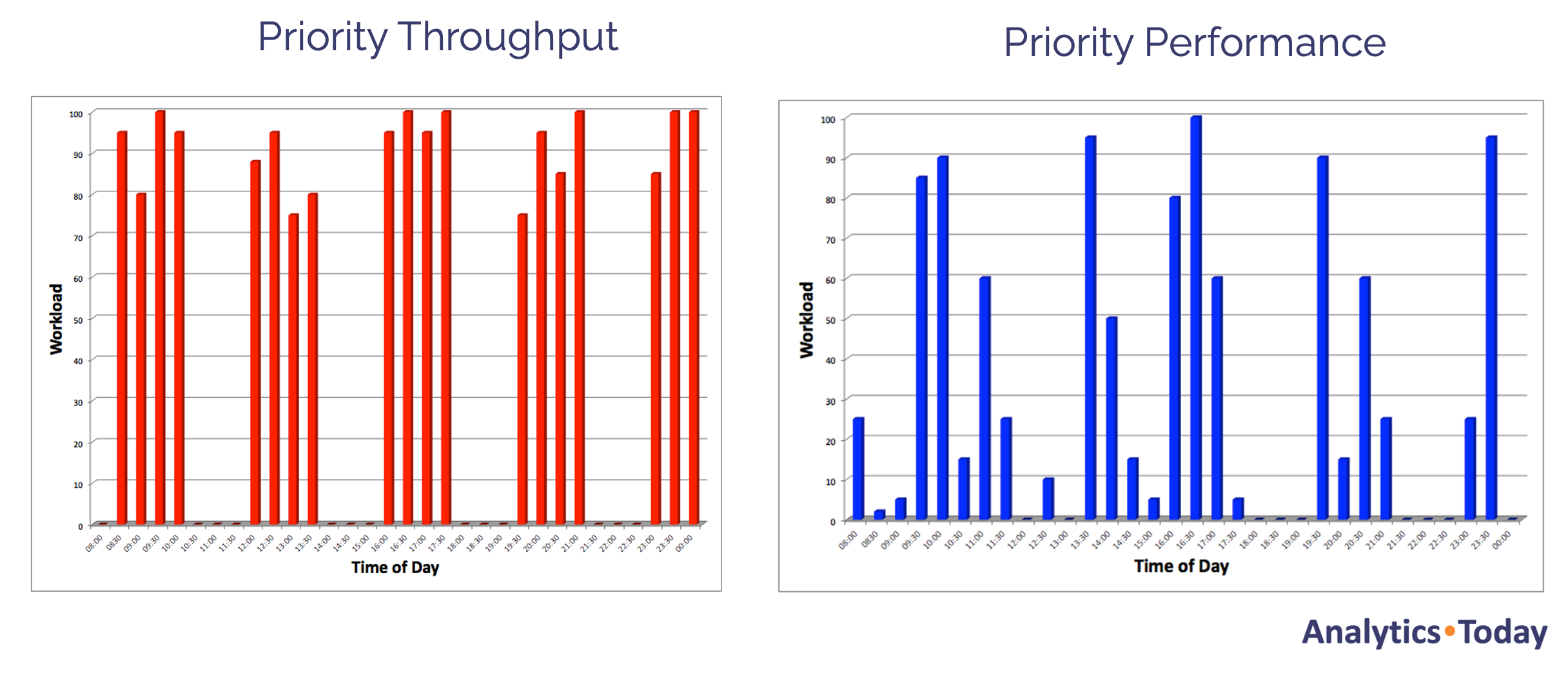
"Inside Every Big Problem, is Hundreds of Little Problems Dying to get Out".
If indeed we had Snowflake, we could have solved the problem by executing each workload on a separate virtual warehouse. They could even have a different warehouse size as illustrated in the diagram below.
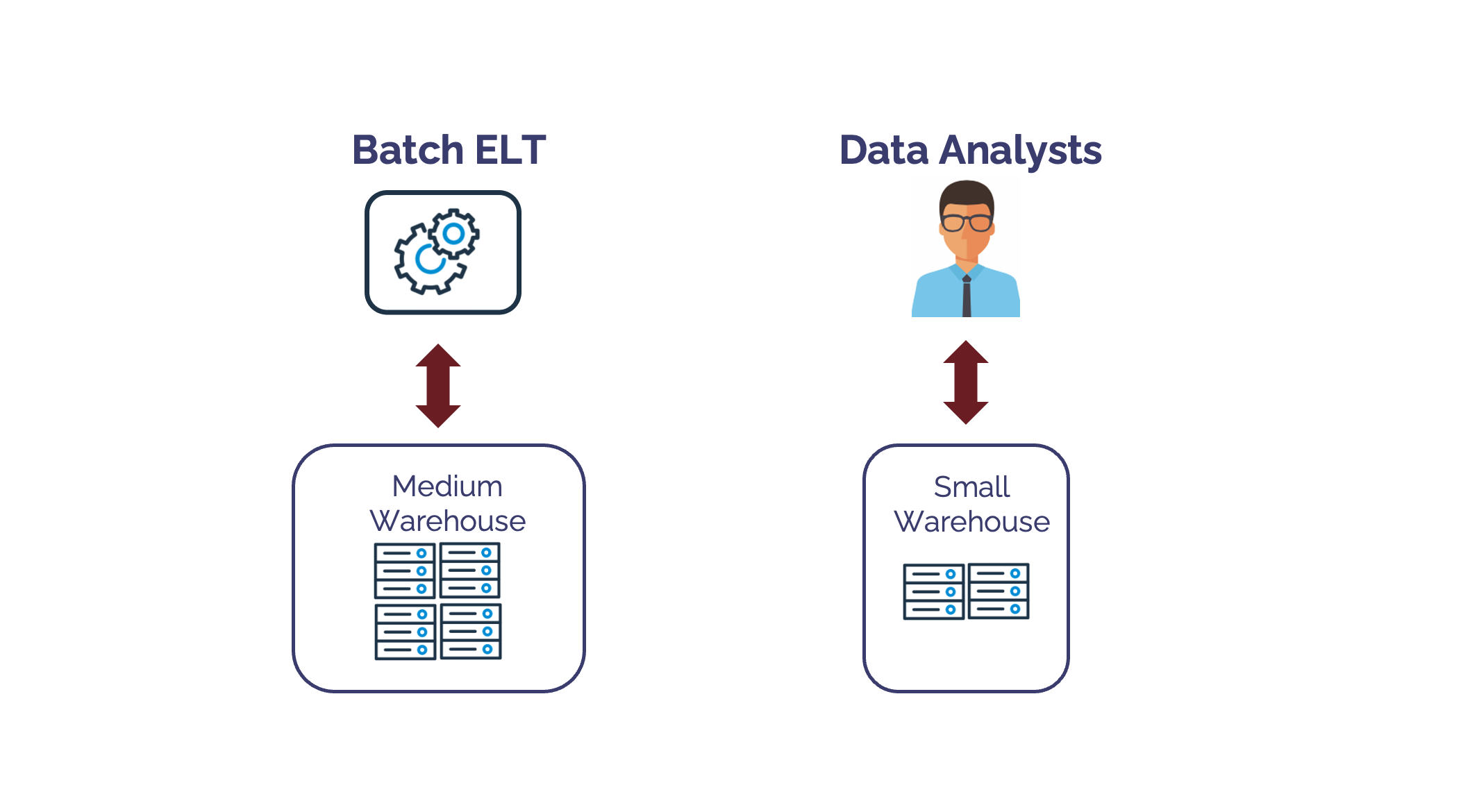
However, if we focus too much upon warehouse size, we're missing the point.
The real challenge is contention for resources between batch processing and end-user queries, and the fact that batch transformations prioritize throughput, whereas end-users need fast query performance. This leads to the first best practice: Separate your workloads.
Separate Workloads to Avoid Contention
While the size of the warehouse is important, it's even more important to separate workloads by type. Broadly speaking, workload types include:
Data Loading: Using COPY commands to load data into Snowflake. Data Loading tends to favor an
XSMALLwarehouse as each file loads on a single CPU and in most cases cannot benefit from scaling up the warehouse. Equally, a second dedicated warehouse for large data loads is also recommended where sensible.Huge Batch Transformations: Which tend to process large data volumes and require more complex SQL operations including sort operations. These prioritize throughput over performance of individual queries, and tend to be submitted on a regular schedule. Finally, unlike end-user queries, individual query response time is not as critical as getting the overall job done as quickly as possible.
Real-Time Processing: Which tend to process smaller, incremental data sets but need very fast performance.
Data Analysis or Data Science: These workloads tend to scan massive data volumes (which need a bigger warehouse), while also prioritizing query performance (as queries are submitted by users).
End User Dashboards: These workloads tend to scan smaller data volumes where individual query performance is critical even as the number of concurrent users increase.
While the recommendations above may appear common sense, I seldom find them used. In fact, the most common deployment method I've seen is separation of workloads by team.
Avoid Workload Separation by Team
The diagram below illustrates a situation I've seen in almost every large Snowflake deployment I've worked on.
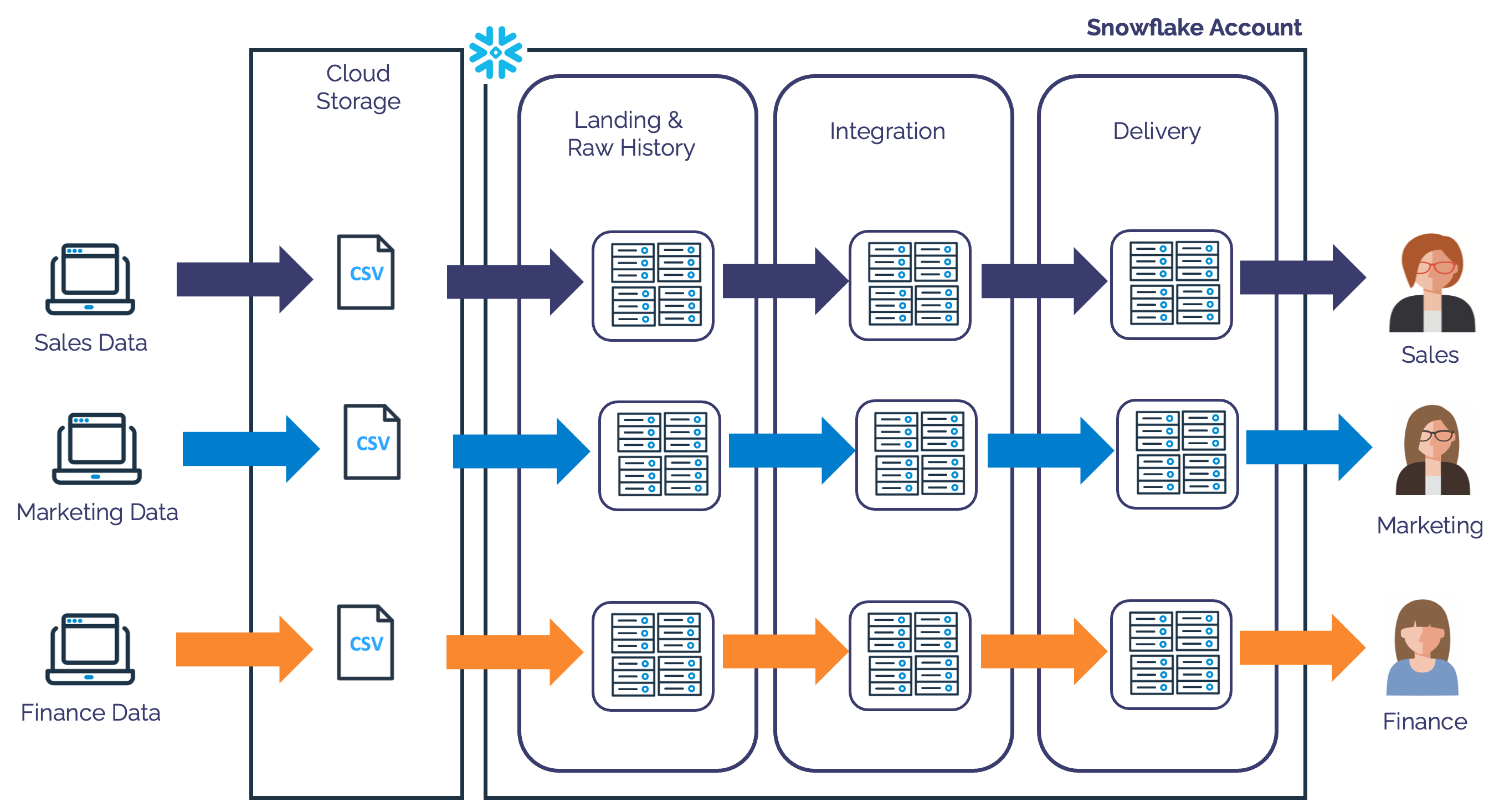
The above diagram shows how each team is given a set of warehouses, one for Sales, another for Marketing and yet another for Finance workloads. This separation is often driven by the need to chargeback warehouse costs to different teams, but it's both unnecessary and hugely inefficient.
The challenges with this deployment include:
Poor Infrastructure Management: As each team manages it's own warehouses, the size, configuration and infrastructure management is distributed across the entire business. As it's not feasible for each team to have a Snowflake expert, it often leads to wasteful deployment and poor throughput and query performance.
Workload Contention: Data Engineering teams focus on code and delivery schedules and often lack the skills and experience to manage conflicting workloads. This leads to the same machine being used for mixed purposes including end-user queries and batch processing on the same warehouse.
Significant Waste: It's not unusual to find over a hundred virtual warehouses with multiple same-size machines executing similar workloads. This leads to significant waste as there's often many warehouses running at low utilization with similar workloads executed by different teams.
Focus on the Workload not Warehouse Size
The most common question I'm asked by Data Engineers is:
"What warehouse size should I run this query on".
I would describe this sort of thinking as: "Looking down the wrong end of a telescope". There are several critical mistakes implied by the above question:
Focusing on the Query: Most transformation pipelines involve a sequence of operations, (or a Job), not just a single query. Focussing on an individual query is missing the bigger picture. It's not feasible to execute every query on the optimum warehouse. We need to focus on the JOB.
Focusing on the Warehouse Size: While a bigger warehouse often leads to faster results it's not always the case. You need to focus on the workload size - the time taken to process the data and deliver results.
Ignoring the Priority: One of the most important requirement of any task is "How quickly do you need the results?". This indicates the priority, whether the workloads needs faster performance, high throughput or neither. If a batch process taking 30 minutes is acceptable, why bother running it on a larger warehouse with a potentially higher cost?
Ignoring Configuration Options: Virtual Warehouses can be configured with an
AUTO_SUSPENDtime,WAREHOUSE TYPE(memory size),CLUSTER_COUNTandSCALING POLICYin addition to warehouse size. You should be aware of these options when deciding which warehouse to use.Ignoring Performance Options: Snowflake provides several performance tuning options including, Query Acceleration Service, Cluster Keys and Search Optimization Service to help maximize query performance. A focus on warehouse size ignores these options.
Ignoring the Cost: The question about warehouse size implies the need to maximize query performance, but this hyper-focus on performance leads to ignoring query cost. The diagram below illustrates the real balance every Data Engineer needs to be aware of, balancing the conflicting requirements of Throughput, Performance and Cost.
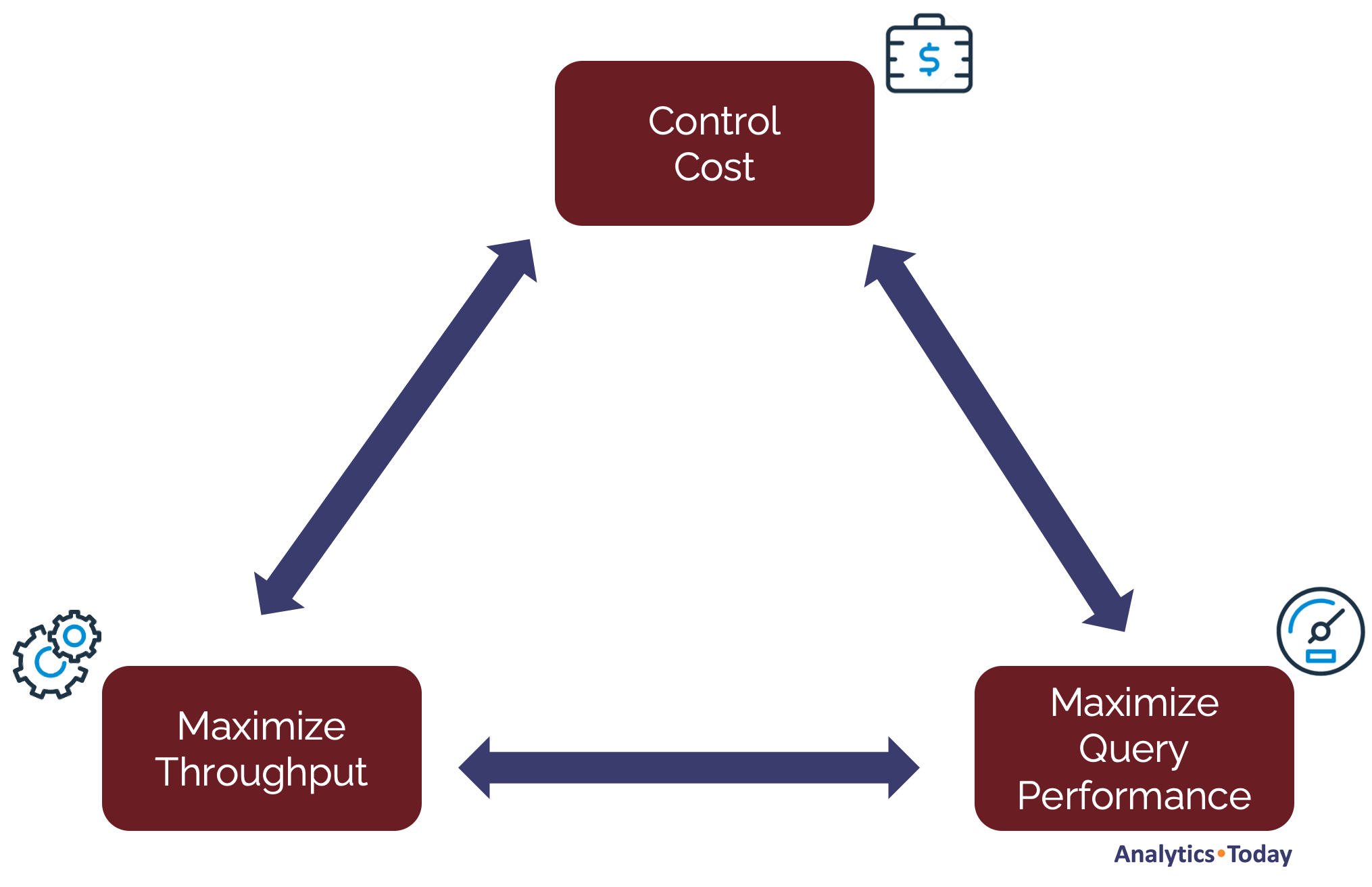
The biggest single difference between an on-premises databases and Snowflake is that on-premises systems have a fixed up-front cost and limited resources, whereas on Snowflake the cost depends upon usage and machine resources are unlimited.
We therefore need to be aware of all three potential priorities, and (for example, with over-night batch processing), if neither throughput nor performance is critical, we must focus on cost.
Workload Frequency and Warehouse Size
Another common warehouse deployment mistake I see is high frequency tasks on an inappropriate (too large) warehouse. This is often driven by the need to quickly deliver near real-time incremental results to end-users. It typically involves a short, repeatedly executed scheduled job which is run every few minutes, running 24x7 on a MEDIUM or LARGE warehouse.
To understand why this is a bad mistake, consider how Snowflake bills for warehouse time.
When a warehouse is resumed, there is a minimum 60 second charge, and a minimum AUTO_SUSPEND of 60 seconds (although the default time is 10 minutes).
Even assuming the minimum 60 second auto-suspend time, a job which runs every five minutes and executes for just two minutes has an actual charge of three minutes as a result of the AUTO_SUSPEND time.
Any job executed every five minutes executes 105,120 times per year, and assuming $3.00 per credit costs $15,768. If however, the job were executed on a MEDIUM size warehouse, the costs increases to over $63,000.
Worst still, since each query in the job is short and processes relatively small data volumes, there's little benefit in increasing warehouse size as the queries won't run much faster, but the cost of the AUTO_SUSPEND time has increased to over $21,000 - more than the original cost on an XSMALL warehouse.
Avoid Resizing the Warehouse
Snowflake recommends experimenting with different warehouse sizes and because it's easy to resize, most customers starting with a SMALL virtual warehouse and then increase the size as performance demands.

The diagram above illustrates a common scenario whereby users start with a SMALL warehouse, then increase size to a MEDIUM and then LARGE. As additional workloads are added, they find query performance suffers, but they also discover that increasing warehouse size again to an XLARGE leads to a significant increase in cost, so the warehouse is resized back down again.
As a Snowflake Solution Architect and Instructor to hundreds of Snowflake Data Engineers, and I've consistently advised:
"Don't increase the Virtual Warehouse Size"
To understand why, consider the "Workload Frequency" section above. It's likely that any virtual warehouse will include a combination of workloads, from huge batch jobs run once per day, to short, fast jobs run every few minutes.
Assuming a virtual warehouse suspends after 60 seconds, a job which runs for an hour spends just 1.6% of the time waiting to suspend, whereas a job which runs for two minutes spends an additional 50% of the time waiting to suspend.
When you increase warehouse size, you double the cost per hour, but you're also doubling the cost of the idle time.
Mixed Workload: A Case Study
I recently worked with a Snowflake customer to help reduce costs when they were spending millions of dollars per year. Their most expensive warehouse wasn't as you might expect, an X6LARGE size, but a MEDIUM size warehouse that accounted for around $200,000 per year.
The graph below illustrates the results of my analysis where I found 70% of queries completed in under five seconds while just 1% took over an hour. Clearly we had identified a warehouse with a highly mixed workload.
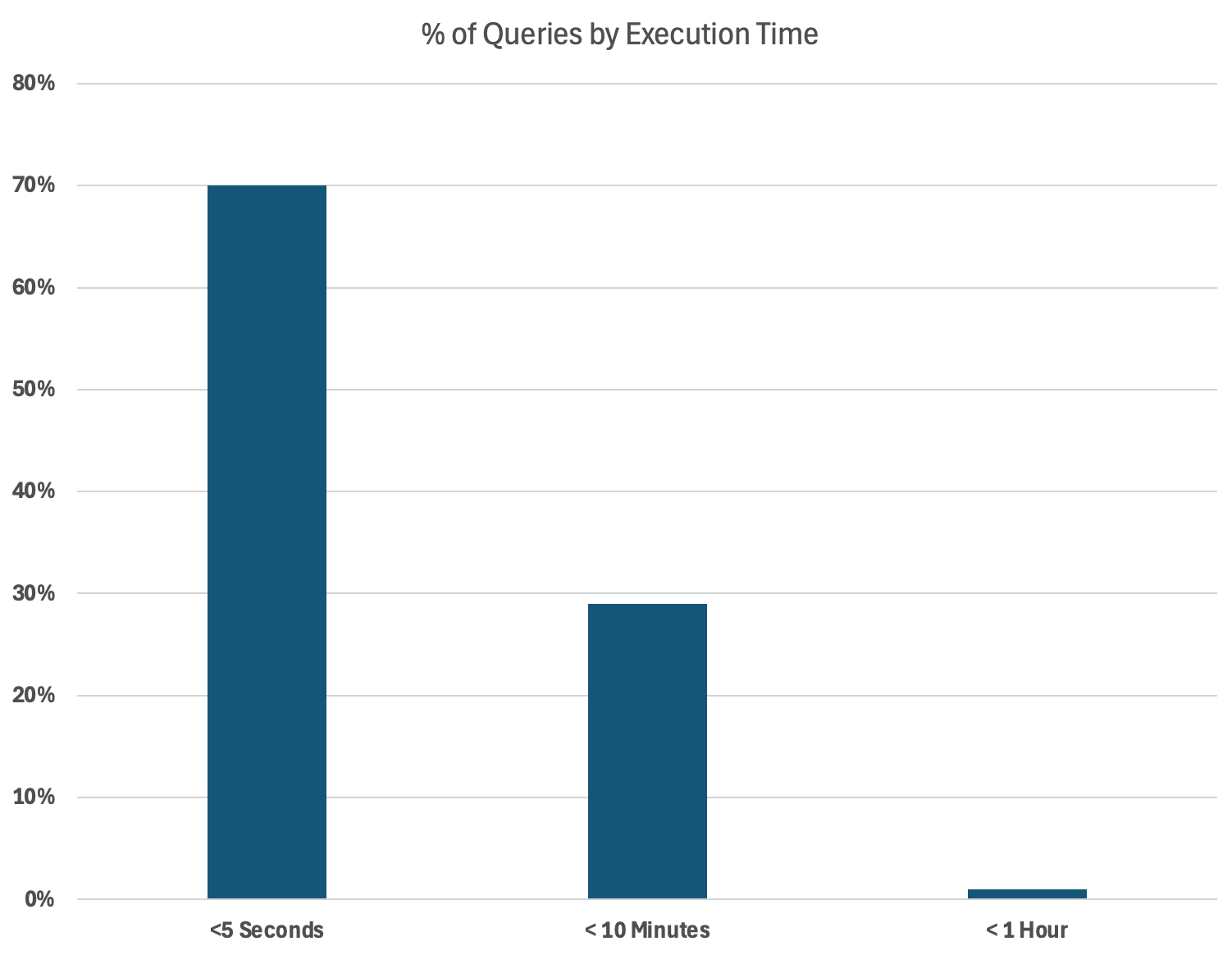
There were two important insights from the above:
With 70% of queries completing in under five seconds on a warehouse with a small number of queries (just 1%), taking up to an hour to complete, this is clearly a warehouse with a mixed workload.
Queries taking under 5 seconds are considerably more cost effective on a smaller warehouse. My personal benchmark tests demonstrate that queries taking around 5 seconds run around 30% faster when executed on a
MEDIUMrather thanXSMALLwarehouse, but the charge rate is 400% higher.
Further investigation revealed that the warehouse had been increased to a LARGE size, but was quickly reversed as the cost increased significantly and the customer simply accepted the poor performance.
In conclusion:
70% of the queries complete in under 5 seconds are running these on a MEDIUM size warehouse is hugely wasteful.
It's likely the warehouse size was increased to
MEDIUMsize to ensure the longer running queries (the 1% of queries taking 10-60 minutes) finished quickly.It would be sensible to identify the longer running queries and move them to a
MEDIUMsize warehouse, and then resize the warehouse to aSMALLorXSMALLto save money.
Snowflake Virtual Warehouse Sizing: What are we doing wrong?
Let's quickly summarize the mistakes being made:
Deployment by Team: Allocation of warehouse is delegated to individual teams without the expertise or experience to manage these remarkably expensive resources.
Mixed Workloads: As there's little understanding of workload allocation, warehouses tend to have a mixed workload with short frequently executed jobs on the same warehouse as long running queries. This makes it increasingly expensive to scale up for performance.
Focusing on Warehouse Size: As it's easy to resize a warehouse and it often results in a 50% performance improvement, this becomes a the simple fix for performance issues.
Reliance on Scaling up: It's easy to scale up a warehouse size. However, because warehouses run a mixed workload, it becomes increasingly expensive to scale up, and instead we rely upon scale out which simply multiplies out the extent of inefficient workload deployment.
Focus on Performance: Everyone would prefer their results delivered more frequently and faster which leads to a focus on query performance tuning, ignoring the need to control costs or maximize throughput.
Ignorance of Configuration or Performance Tools: As warehouse size is a simple concept, we ignore the more sophisticated options including the
SCALING POLICYor advanced features like Cluster Keys.
Virtual Warehouse Sizing: Best Practices
"Never give a customer what they asks for! Give them what they NEED! And remember, it's your job to understand what they need" - Dr David. Pearson
Understand System Requirements: Be aware of the trade-off of Cost, Performance and Throughput. If you're aware of the the conflicting requirements you might deliver a solution that gives the best value to the business - and keep yourself in a job.
Understand the Business Requirements: Keeping in mind the overall requirements, agree the need for both data refresh frequency and query performance. Make business users aware of the real cost of their request. For example a job executing every five minutes on an
XSMALLwarehouse costs over $15,000 per year whereas the same job executed once per hour costs just $1,300.Deploy by Workload not Team: The diagram below illustrates an optimum warehouse deployment whereby workloads deployed to reduce contention between workloads rather than by different teams.
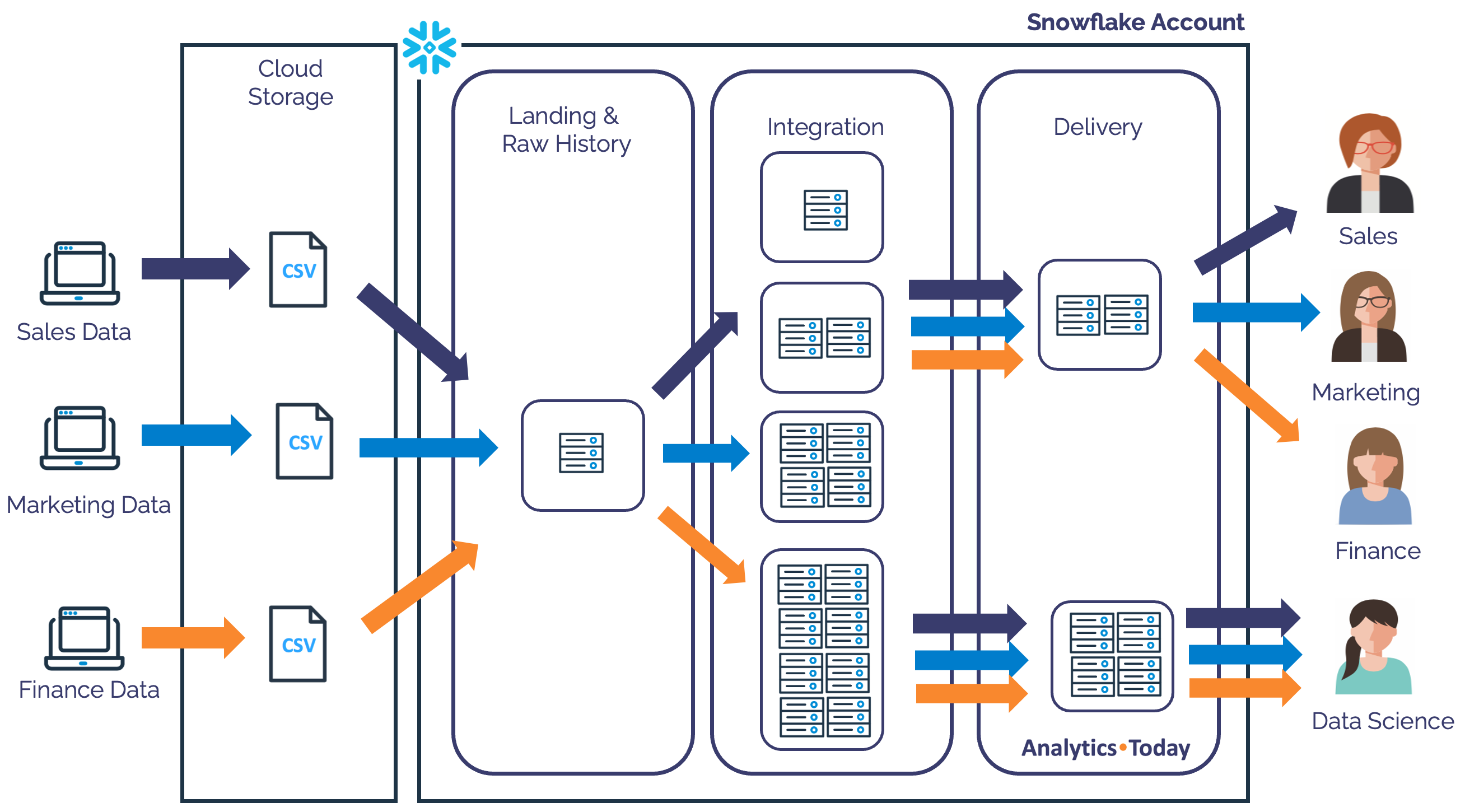
The above diagram illustrates how a single XSMALL warehouse is used for data loading, while there's a range of different size transformation warehouses for ELT processing. Finally, users with similar workload sizes share warehouses while Data Scientists use a much larger dedicated warehouse based upon workload size and performance needs.
Focus on the JOB not the Query: Around 80% of Snowflake compute costs are the result of scheduled jobs, and it's easy to identify the steps in a job using the QUERY_TAG. Using this technique, we can quickly summarize costs and execution time by JOB, and ensure each job is assigned to the correct warehouse size. It can also be used to quickly identify frequently executed short jobs on large warehouses. Moving these from a
MEDIUMto anXSMALLwill reduce costs by 75%.Move the JOB instead of resizing the warehouse: To avoid (or resolve) a mixed workload, having identified the poorly deployed jobs, move them to an appropriate warehouse size. This means moving jobs that spill to storage to a larger warehouse, while short, frequently executed jobs are moved to a smaller (less expensive) warehouse.
Understand Snowflake Performance Features: In addition to a range of features to tune query performance, Snowflake supports a number of warehouse parameters, along with advanced features including Cluster Keys, Query Acceleration Service and Search Optimization Service to help improve query performance. While increasing warehouse size might improve performance, in many cases it won't help, in which case alternative techniques need to be considered.
Control Warehouse Deployment: Avoid a sprawl of hundreds of virtual warehouses with inappropriate (and undocumented) configuration and mixed workloads. Provide a centrally coordinated centre of excellence to oversee warehouse deployment and monitor key warehouse metrics to maximize business value.
Deliver more performance and cost savings with Altimate AI's cutting-edge AI teammates. These intelligent teammates come pre-loaded with the insights discussed in this article, enabling you to implement our recommendations across millions of queries and tables effortlessly. Ready to see it in action? Request a recorded demo by just sending a chat message (here) and discover how AI teammates can transform your data team
Subscribe to my newsletter
Read articles from John Ryan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
John Ryan
John Ryan
After 30 years of experience building multi-terabyte data warehouse systems, I spent five incredible years at Snowflake as a Senior Solution Architect, helping customers across Europe and the Middle East deliver lightning-fast insights from their data. In 2023, I joined Altimate.AI, which uses generative artificial intelligence to provide Snowflake performance and cost optimization insights and maximize customer return on investment.