Understanding Database Connections and Connection Pooling
 Luis Gustavo Ganimi
Luis Gustavo Ganimi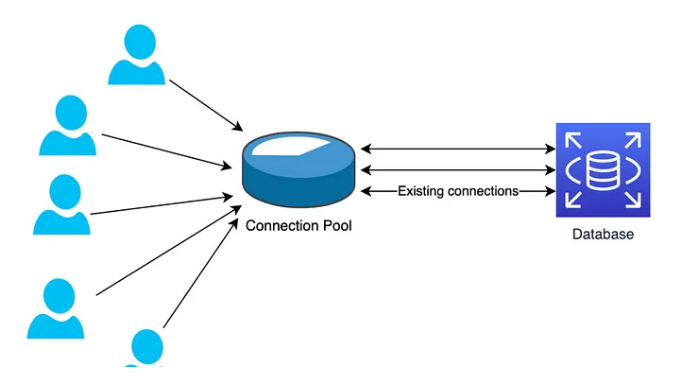
What is a Connection in Databases?
A database connection is a communication channel between a database and its clients, such as an application or a tool like DataGrip or Prisma Client. This connection allows the client to send queries, update data, and interact with the database. The lifecycle of a connection typically involves:
Establishing the Connection: The client requests a connection to the database, which involves authenticating and establishing a network path.
Query Execution: Once connected, the client can execute queries and receive responses.
Closing the Connection: After the operations are complete, the connection can be closed, freeing up resources.
Creating a new connection for each request can be resource-intensive and slow, particularly in high-traffic environments. This is where connection pooling comes into play.
What is Connection Pooling?
Connection pooling is a technique used to manage a pool of reusable database connections. Instead of opening a new connection for every request, a pool maintains a set of active connections that can be reused. This approach significantly improves performance and resource utilization.
Key benefits include:
Reduced Overhead: Reusing existing connections minimizes the time and resources needed to open new ones.
Improved Performance: With a pool of connections, the time to “open” a connection is almost zero, as connections are pre-established and ready for use.
Efficient Resource Management: Connection pooling helps in balancing the load and preventing database overload by controlling the number of concurrent connections.
How Does Connection Pooling Work?
Pool Initialization:
When an application or ORM (Object-Relational Mapping) tool starts, it initializes a connection pool with a configurable size and timeout settings.
For example, Prisma, an ORM, handles connection pooling internally. By default, it sets the pool size to
num_physical_cpus * 2 + 1, but this can be adjusted based on specific requirements.
Handling New Queries:
When a new query is received, the pool manager reserves an idle connection from the pool to process the query.
If no idle connections are available, the pool manager opens additional connections up to a predefined limit, known as
connection_limit.If the pool reaches its maximum size and no connections are available, incoming queries are placed in a FIFO (First In First Out) queue. Queries are processed in the order they are received.
Timeout and Error Handling:
- If a query cannot be processed before the
pool timeoutperiod elapses, the system throws an exception with an error. This error indicates that the query could not be executed due to a timeout, and the system moves on to process the next query in the queue.
- If a query cannot be processed before the
Best Practices for Connection Pooling:
Configure Pool Size Appropriately: Set the pool size based on your application’s needs and database capacity to avoid overloading the database.
Monitor Pool Performance: Regularly monitor connection pool metrics to ensure efficient operation and adjust configurations as needed.
Handle Timeouts Gracefully: Implement error handling to manage situations where queries are delayed or cannot be processed due to connection limitations.
By understanding and effectively managing database connections and pooling, you can optimize performance, resource utilization, and overall application efficiency.
Subscribe to my newsletter
Read articles from Luis Gustavo Ganimi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by