Understanding the Spark Execution Model
 Shreyash Bante
Shreyash Bante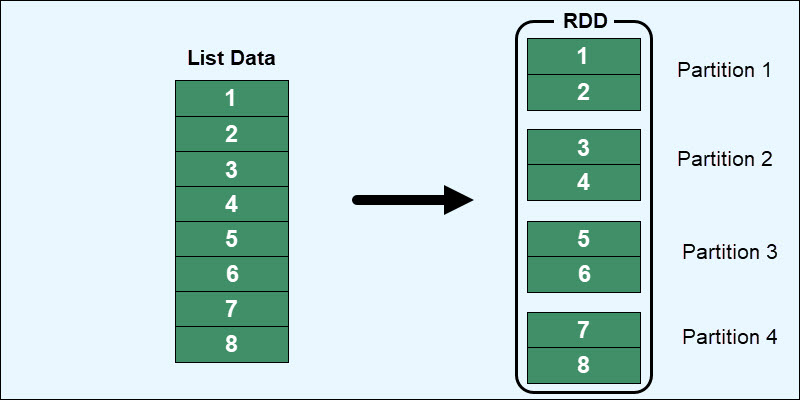
Apache Spark's execution model is one of the reasons it stands out as a powerful tool for big data processing. At its core, Spark's execution model revolves around two main concepts: transformations and actions. To understand how Spark operates, it’s essential to grasp these concepts and how they interact within the Spark ecosystem.
Transformations and Actions
In Spark, transformations are operations that create a new dataset from an existing one. These are lazy operations, meaning they don’t compute their results right away. Instead, they build up a lineage of transformations to apply when an action is finally called. This approach helps optimize the data processing by reducing the amount of data shuffled across the network and allowing Spark to execute the jobs more efficiently.
In Apache Spark, the lineage graph (also known as the RDD lineage or dependency graph) shows the sequence of transformations applied to an RDD, allowing Spark to track which operations were performed and to recompute lost data if needed. This graph is crucial for understanding how data flows through a Spark application and for debugging purposes. we will be deep-diving into Databricks UI at a later stage
Some common transformations include map(), filter(), and reduceByKey(). These functions transform the data in some way but do not immediately produce output.
Actions, on the other hand, trigger the execution of the transformations that have been defined. When an action like collect(), count(), or saveAsTextFile() is called, Spark computes the result by performing the transformations that were previously set up. This is where the actual data processing occurs.
Resilient Distributed Datasets (RDDs)
One of the core abstractions in Spark is the Resilient Distributed Dataset (RDD). RDDs represent a collection of items distributed across many nodes in a cluster that can be processed in parallel. RDDs are fault-tolerant, meaning they can recover from node failures through a lineage graph that tracks the transformations to rebuild lost data.
RDDs form the foundation of Spark's data processing, allowing operations to be applied across the cluster's nodes.
Spark Jobs, Stages, and Tasks
When you run an action in Spark, it triggers a job. A job is the highest-level unit of computation in Spark and is made up of one or more *stages. Each stage consists of a set of tasks that can be executed in parallel. Tasks within a stage operate on a subset of the data, called a *partition.
Stages are determined by Spark's understanding of the operations that can be performed without requiring a shuffle of data. A shuffle, which involves redistributing data across the nodes, occurs when Spark needs to group or aggregate data differently, often leading to a boundary between stages.
DAG (Directed Acyclic Graph) Scheduler
The execution of jobs in Spark is orchestrated by the DAG Scheduler. Spark translates the user-defined transformations into a DAG, where each node represents a transformation, and each edge represents a data dependency. The DAG Scheduler then divides the DAG into stages and tasks, scheduling them to be executed on the cluster.
Optimizing Execution
Understanding Spark's execution model allows you to optimize your jobs. For example, you can minimize the number of shuffles by carefully ordering transformations or increasing parallelism by adjusting the number of partitions. Efficient execution can greatly improve performance and reduce costs, especially in large-scale data processing environments.
To sum it up
a spark code is divided into Jobs -> Stages->Tasks. Tasks have data on which they execute in parallel. and all optimization lies in where and how you can utilize the total compute you have by distributing data optimally. this distribution of data includes broadcast joins, cache, bucketing, Repartitioning, and correct utilization of Databricks UI to find bottlenecks.
Subscribe to my newsletter
Read articles from Shreyash Bante directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shreyash Bante
Shreyash Bante
I am a Azure Data Engineer with expertise in PySpark, Scala, Python.